 Uni-NaVid:统一视频导航VLA模型
Uni-NaVid:统一视频导航VLA模型





前言
本文一开始是此文《NaVid——基于单目RGB捕获的视频让VLM规划「连续环境中VLN」的下一步:无需地图/里程计/深度信息(含后续升级版Uni-NaVid的详解)》第二部分
但为解读的更深、更透,故今独立出来,成此文
- 毕竟今非昔比了
以前侧重教育的时候,课程都合作老师们讲
无需像如今这般深度专研 也不必像如今这般和团队实践 更不必像如今这般每天看paper - 终归是,23年起变了,24年起更变了(侧重具身开发),一切不一样了
第一部分 Uni-NaVid(NaVid升级版):一种用于统一具身导航任务的Video-based VLA
1.1 引言、相关工作、问题表述
1.1.1 引言
如Uni-NaVid原论文所说,具身导航[112,85]是智能机器人至关重要的能力,已在机器人领域引起了广泛关注。为了实现高效的具身导航,机器人必须能够根据人类指令在物理环境中自主移动
然而,导航任务的类型差异巨大,大多数现有研究仅针对特定任务设计,例如
- 视觉与语言导航
44-Beyond the nav-graph: Visionand-language navigation in continuous environments
46- Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding - 目标物体导航
12- Object goal navigation using goal-oriented semantic exploration - 具身问答
21-Embodied question answering
90- Embodied question answering in photorealistic environments with point cloud perception - 以及跟随任务
113- Efficient motion planning based on kinodynamic model for quadruped robots following
persons in confined spaces
36-Robust kalman filters based on gaussian scale mixture distributions with application to target tracking
68-Habitat 3.0: A co-habitat for humans,avatars and robots
因此,目前大多数方法仅针对单一类型的导航任务开发,往往依赖专用模块和特定任务的数据集。这种狭窄的研究范围限制了其在多用途导航应用中的适用性,也阻碍了不同导航任务之间潜在协同效应的发挥
开发一个多功能导航模型面临重大挑战,因为这需要对导航任务进行统一——比如对异构数据进行建模与集成以实现联合使用
- 最初的尝试采用模仿学习IL
85- Towards versatile embodied navigation
93- Towards target-driven visual navigation in indoor scenes via generative imitation learning
66-Vision-based navigation with language-based assistance via imitation learning with indirect intervention
或强化学习RL
106- Poliformer: Scaling on-policy rl with transformers results in masterful navigators
97-Benchmarking reinforcement learning techniques for autonomous navigation
以在仿真环境或有限多样性的真实环境中学习通用导航技能
然而,由于仿真器的渲染质量和多样性有限,这些方法通常会遇到“仿真到现实”(sim-to-real)鸿沟,并且在不同导航任务中的泛化能力较差
27- Navigating to objects in the real world
5- Sim-to-real transfer for vision-and-language navigation
40- Sim2real predictivity: Does evaluation in simulation predict realworld performance? - 近期的研究
120-Navgpt: Explicit reasoning in vision-and-language navigation with large language models
114- Towards learning a generalist model for embodied navigation
61-Instructnav: Zero-shot system for generic instruction navigation in unexplored environment
60-Discuss before moving: Visual language navigation via multi-expert discussions
78- Lmnav: Robotic navigation with large pre-trained models of language, vision, and action
尝试通过预训练的大型语言模型(LLMs)实现更高程度的统一
然而,由于LLM推理的低频率,这些方法在一定程度上通过采用离散化建模方式简化了问题。它们依赖于预定义的图结构进行决策学习,这牺牲了输出的灵活性,并为真实世界的部署带来了额外的挑战
在本研究中,来自1 CFCS, School of Computer Science, Peking University、2 Galbot、3Beijing Academy of Artificial Intelligence的研究者提出了 Uni-NaVid,这是一种基于视频的VLA模型,旨在统一多种常见的导航任务需求

Uni-NaVid以第一视角的 RGB 视频流和自然语言指令作为输入,能够直接为连续环境下的导航生成低层级动作
- 其对应的paper为:Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
其Submitted on 9 Dec 2024 (v1), last revised 6 Feb 2025 (this version, v2)
——
其对应的作者为
Jiazhao Zhang1,2、Kunyu Wang3、Shaoan Wang1,2、Minghan Li2、Haoran Liu1,2
Songlin Wei1,2、Zhongyuan Wang3、Zhizheng Zhang2,3,†、He Wang1,2,3,† - 其对应的项目地址为:pku-epic.github.io/Uni-NaVid/
其对应的GitHub为:github.com/jzhzhang/Uni-NaVid
————
代码基于LLaMA-VID和NaVid
截止到25年11月,以下代码均已发布
Training Code
Offline Evaluation Code
Benchmark Evalation Codd:VLN-CE、EVT-Bench
A small split of VLN-CE RxR data
且为了实现多任务导航并支持高效导航,Uni-NaVid 在视频基础的 VLM [51] 上进行了扩展,主要包括两个关键组件:
- 基于在线 token 合并机制的高效 VLA 架构,使得能够高效处理在线采集的视频流以进行大语言模型推理
在导航过程中,智能体需要处理大量在线捕获的帧,这导致了内存过载和计算延迟,尤其是在基于LLM的方法中[111,61]
————
为此,作者提出了一种在线Token合并机制:对于较近的历史帧采用较低的压缩比,而对较远的历史帧采用较高的压缩比。该合并机制以实时方式运行,最大化地复用先前的导航历史
通过这种方式,Uni-NaVid能够学习到紧凑的表征,不仅保留了细粒度的空间信息,还保留了结构化的时间信息,从而通过减少Token数量加快模型推理速度 - 涵盖四类广泛研究的导航任务——视觉与语言导航、目标物体导航、具身问答以及跟随人类、总计 360 万个样本的大规模数据集
对于其中的对于跟随人类任务,作者构建了一个全新的语言引导下的人类跟随基准,用于数据采集和评估
且Uni-NaVid采用前瞻性预测,一次性生成未来时间段内的动作,而非逐步生成。这使得Uni-NaVid能够实现5Hz的推理频率,便于在真实环境中部署由VLA模型驱动的非阻塞式导航机器人
1.1.2 相关工作
第一,对于多任务具身导航
具身导航[2, 94, 112]要求智能体根据人类指令在未知环境中进行导航。关于具身导航已有大量文献,本文重点关注涉及视觉信息与语言指令的四类主流任务:
- 视觉与语言导航[4,44,46]
- 目标物体导航[12]
- 具身问答[21]
- 以及跟随人类[37,68,118,119]
早期关于通用具身导航模型的研究[85,93,66,97],采用多任务导航数据集并直接学习导航技能,在多任务表现上取得初步成功
- 然而,这些方法在新环境中部署时,尤其是在真实世界场景下,性能出现下降
近年来,先进方法[114,61,35,60,121,78]利用大语言模型的泛化能力提升多任务导航性能。这些模型在各类导航任务中展现出良好的泛化能力,但依赖大量提示,影响了时间效率 - 相比之下,Uni-NaVid基于视频的大语言模型采用端到端训练方式,适用于多任务导航,在如跟随人类等任务中展现出强大的泛化能力与计算效率
第二,对于具身导航数据集
为了训练和评估具身导航任务中策略的性能,已经提出了大量的数据集及相应的基准测试[23,123,59,64]。这些数据集在具身导航领域中起着至关重要的作用
- 对于视觉与语言导航(vision-and-language navigation)
最广泛使用的数据集是Room-2-Room(R2R)[4]和Room-cross-Room(RxR)[47],它们提供了导航指令以及地标的真实轨迹
作者关注于R2R和RxR在连续环境下的一个变体,称为VLN-CE[44],该数据集在实际应用中更加实用 - 对于目标物体导航(object goalnavigation)
有几个著名的基准测试,如HM3D[69]、MP3D[11]和Aithor[124],这些基准建立在不同的场景环境和模拟器之上
本文采用了Habitat[76]上的HM3D数据集,该数据集与VLN-CE具有相同的动作设置 - 对于具身问答(EQA)
有多个关注EQA不同属性的数据集,如MP3D-EQA[90]、MT-EQA[103]、Graph-EQA[83]和MX-EQA[38]
作者选择了维护良好且拥有最新基线的MP3D-EQA数据集 - 对于跟随人类[116,117]的基准
目前尚无提供人类文本描述的基准
因此,作者基于Habitat 3.0[68]自建了基于文本描述的人类跟随基准
需要注意的是,不断有新的基准被提出,涵盖了多样化的导航属性
当然了,作者的目标是基于主流数据集对他们的方法进行训练和评估,以清晰地证明他们方法的性能
关于上面的一些概念,可以参见此文《VLN领域的“ImageNet”打造之路:从MP3D数据集、MP3D仿真器到Room-to-Room(R2R)、RxR、VLN-CE》
第三,对于用于导航的大型语言模型
大型语言模型(LLMs)[20,54,122]由于其在理解和规划方面的泛化能力,已被引入到机器人导航领域
- 一种直接的方法[120,61,60,78]是以零样本方式使用现成的大型语言模型。这些方法利用视觉基础模型[22,54]将周围环境以文本形式描述,从而提示语言模型选择能够引导智能体的地标
然而,将密集的视觉信息抽象为文本,并依赖离散地标,会导致环境观测变得稀疏,并且仅适用于静态环境 - 另一种方法[111,106]是端到端训练基于视频的大型语言模型与低层次动作相结合,从而实现连续移动。但在长时序任务中,该方法面临效率挑战
相比之下,Uni-NaVid 实现了一种在线视觉token合并策略,优化了长时序任务的训练效率,并支持在真实环境中的非阻塞执行
1.1.3 问题表述
首先是导航任务定义
- 作者将 Uni-NaVid 的通用导航任务定义如下:在时间点
,给定由
个单词组成的自然语言指令
和一个自我中心的 RGB 视频
(包含一系列帧
),智能体需要规划接下来的k 个动作
,以在新环境中完成指令(在作者的实验中,k=4)
个人插一嘴,根据环境(拍摄的视频)和指令,预测动作,确实是妥妥的VLA啊,和让机器人根据摄像头拍摄到的环境和人类指令,规划接下来的k个工作,一模一样,^_^ - 在此,作者采用了广泛使用的动作设定 [76,12,44,21],要求智能体执行低级动作
,包括{FORWARD,TURN-LEFT,TURN-RIGHT,STOP}
需要注意的是,作者的任务设定与现有的具身导航任务[76,12,44,21]兼容,其中离散的低层动作[76,12,44,21]表示小幅旋转(30度)或前进(25厘米),因此能够灵活地应用于如避障等连续环境
其次,以下是完整概述
如图2所示,Uni-NaVid由三个主要组件组成『该方法仅以单视角RGB帧{x1, ···, xT}和自然语言指令I作为输入。对于每一帧,作者通过视觉编码器提取64个视觉token,并利用在线token合并技术加速模型推理,同时保留精炼的视觉信息。合并后的视觉token与指令token一同输入大型语言模型,以获得导航动作或用于具身问答的答案』:
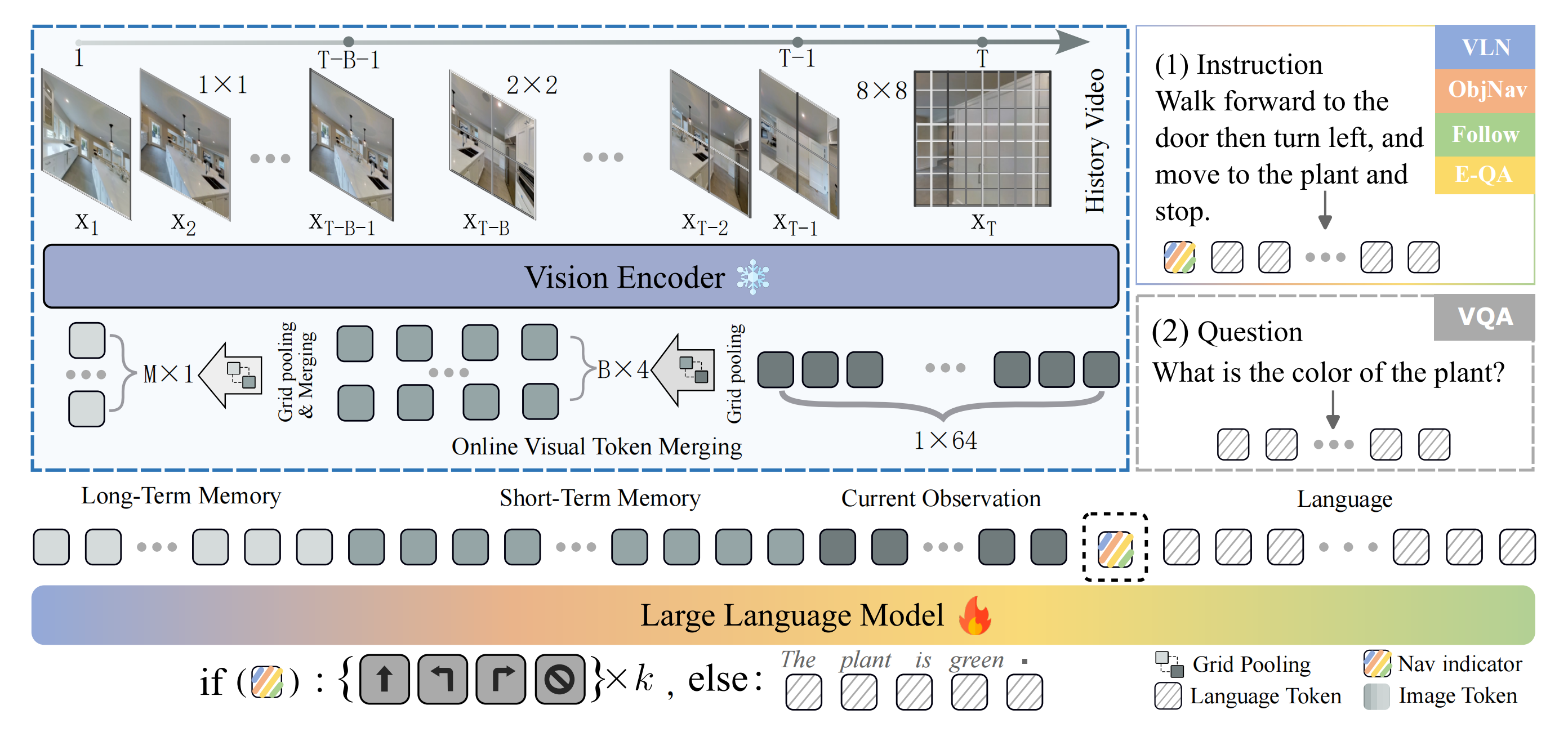
- 视觉编码器
首先,在线捕获的视频流通过视觉编码器(实现中采用EVA-CLIP [82])进行编码,从而以Token的形式提取逐帧视觉特征,作者将其称为视觉Token - 在线Token合并机制
随后,视觉Token通过在线Token合并机制在空间和时间维度上进行合并 - 以及大语言模型(LLM)
接下来
合并后的视觉Token通过MLP投影器映射到与语言Token对齐的特征空间,这些被称为视觉观测Token
视觉观测Token与语言观测Token被拼接后输入到大语言模型(LLM),LLM推理出代表接下来四个动作的四个动作Token
1.2 UNI-NAVID模型
1.2.1 观测编码
给定截至时间T的自我中心视频,记为,作者将视频编码为一系列以token形式表示的视觉特征
- 对于每一帧
,作者首先使用视觉编码器(实现中采用EVA-CLIP [82])获取其视觉特征token
其中为图像块数量(
为嵌入维度
- 视觉特征为智能体提供了丰富的信息,使其能够理解自身的导航历史并规划后续动作
然而,在导航过程中,视觉token数量(T×Nx)逐步增加,导致大语言模型(LLM)的推理时间也随之延长(通常每次推理需1–2秒)[111]
这种延迟的增加使基于LLM的导航在实际环境中的部署变得不切实际
故,也就有了上文提到过的在线视觉token合并
1.2.2 在线视觉token合并
为了在保留足够导航视觉信息的前提下减少视觉token的数量,作者设计了一种token合并机制。该策略的核心见解在于,最近的观测对于导航更为关键,而连续帧之间(时间上)以及相邻像素之间(空间上)的视觉信息可能存在冗余——事实 也确实如此
具体执行时,作者先后做了以下两大措施
首先是视觉token分组
借鉴Atkinson-Shiffrin记忆模型[6,80],作者将视觉token分为
- 当前视觉token
- 短期视觉token
- 长期视觉token
这些视觉token根据其与当前帧 的时间戳进行分组,并且对于每一组视觉token,作者在不同的池化分辨率下应用网格池化操作:
其中GridPool (·) 是一种网格池化操作[51,111],在空间上将tokens 从 压缩到
,而B(设为64)是较短记忆缓冲区的长度
- 在这里,作者采用
,从而分别得到视觉tokens 为
,
,
- 且
当前视觉tokens封装了全面的视觉信息,使智能体能够感知其当前环境并规划后续轨迹
同时,和
从捕获的视频流中提取了丰富的时序信息,帮助智能体理解其导航历史
如原论文中所说的
- 需要注意的是,这些超参数是通过经验实验获得的,旨在在可控的token数量与充分的视觉信息表达之间实现最佳平衡
- 且当内存容量和计算资源不是限制因素时,这些超参数还可以进一步调整。关于α的详细说明和消融实验,我们在补充材料中进行了阐述
其次是在线视觉token处理
在导航过程中,智能体会持续观察到新的帧。然而,如果在每一步都对所有帧执行编码与分组(公式2),将会带来巨大的计算开销
- 为了解决这一问题,作者实现了一种在线视觉token处理机制,以最大化对先前生成的视觉token的复用
具体来说,当在时刻接收到新帧时,作者仅对时刻
的最早短期视觉token应用网格池化
这些处理后的token随后分别被整合进短期和长期视觉token中
- 且为了防止长期视觉token
具体而言,作者根据与最近的长期视觉token
之间的余弦相似度,对长期视觉token进行合并
,则根据最新长期视觉token中此前已合并帧的数量(记为 K)将其合并:
[80])时,作者插入新的长期视觉token
这种在线视觉token 处理以高度紧凑的形式保留了导航视觉历史「长度为」
值得注意的是,只有在组边界处的视觉token需要并行化的网格池化,从而使该过程在计算上高效,并且天然适合于实际导航任务中的在线部署
作者在算法1中给出了token 合并技术的描述

总之,与现有的视频大语言模型 [111,80,51] 相比,这种在线融合策略显著降低了推理时间,平均每次推理仅需0.2秒。这一改进在处理较长视频序列时尤为明显
1.2.3 行动规划
在获得融合后的视觉token(由语义特征[82]提取)后,作者采用视觉-语言模型中已有的方法[54,51]来实现视觉与语言的对齐,从而使大语言模型(LLM)能够有效地解析视觉信息
- 具体而言,作者利用跨模态投影器
将所有融合后的视觉token
投影为与LLM输入表征空间兼容的视觉观测token
其中,PV (·) 被实现为一个两层的MLP [54],并以端到端的训练方式进行优化 - 对于指令编码,作者使用现成的LLM(Vicuna-7B [20])的语言分词器和嵌入层,将导航指令编码为语言观测token ELT
然后将视觉观测tokenEVT 、导航任务指示符⟨NAV ⟩和语言观测token ELT 进行拼接,形成最终的输入token 序列。这里,导航任务指示符⟨NAV ⟩参考了[111,67],用于加速特定任务学习并获得一致的输出格式 - 最后,完整的输入token 序列被输入到LLM 中,以推理出四个动作token{EAT , · · · , EAT +3},如下面所述
Input: {Long term tokens}{Shot term tokens}{Current tokens} <NAV > {Instruction}
Output: <Action 0><Action 1><Action 2><Action 3>
作者在补充材料中包含了关于输入token 格式的讨论
动作token属于离散动作集合{FORWARD, TURN-LEFT, TURN-RIGHT, STOP}。按照现有导航设置中的标准配置[76, 106],FORWARD动作对应前进25厘米,TURN-LEFT和TURN-RIGHT分别表示30°旋转。该配置与所有训练导航数据(见第V节)保持一致
经验上,作者发现预测接下来的四步能够获得最佳性能,这促使Uni-NaVid能够预测长时间跨度的动作序列,同时考虑到足够的观测信息以实现准确预测。这种多步预测还支持异步部署,使实际环境中的导航不受阻塞。详细说明请参见补充材料
// 待更


















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











