



数据可视化实验:时间数据的可视化
一、引言与实验原理
时间是一个非常重要的维度与属性。时间序列数据存在于社会的各个领域,如:天文观测数据、气象图像、临床诊断记录等。诊断记录包括病人的每次看病的病情记录以及心电图等扫描仪器的数据记录等。金融和商业交易记录如股市每天的交易价格及交易量、超市中每种商品的销售情况等。不管是延续性还是暂时性的时间数据,可视化的最终的目的就是从中发现趋势。时间型数据包含时间属性,不仅要表达数据随时间变化的规律,还需表达数据分布的时间规律。它可以分为连续性和离散型时间数据。
这里就讲述下离散型数据的堆叠柱形图,堆叠柱形图的几何形状和常规柱形图很相似,在柱形图中,数据值为并行排列,而在堆叠柱图则是一个个叠加起来的。它的特点就是如果数据存在子分类,并且这些子分类相加有意义的话,此时就可以使用堆叠柱形图来表示。本次实验结合本章讲述的堆叠柱形图的列子,这里我们要画的是极坐标系-堆叠柱状图,也是南丁格尔玫瑰图。由于半径和面积的关系是平方的关系,南丁格尔玫瑰图会将数据的比例大小夸大,尤其适合对比大小相近的数值;由于圆形有周期的特性,所以玫瑰图也适用于表示一个周期内的时间概念,比如星期、月份。下面就用 Python 程序来实现。
二、实验目的与实验环境
本次实验学习的是数据可视化技术的基础操作。使用Pycharm Community Edition 2024.1.1软件。实验内容主要包括:
1.掌握时间数据在大数据中的应用
2.掌握时间数据可视化图表表示
3. 利用 Python 程序实现堆叠柱形图可视化
三、实验步骤
1. 下载数据源(http://datasets.flowingdata.com/hot-dog-places.csv)历年热狗大胃王比赛的前三名的成绩

里面的数据格式如下:
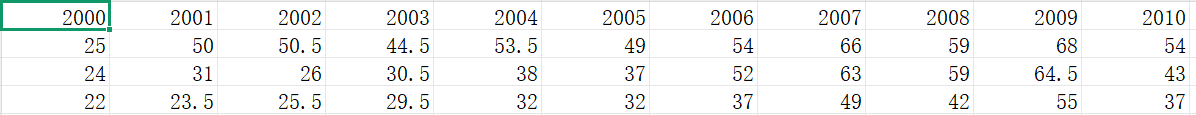
2. 打开cmd ,安装Python所需要的第三方的包,输入pip install pyecharts
3. 打开Pycharm Community Edition 2024.1.1
点击新建–python文件
在下面的界面开始编写程序
代码如下所示
from pyecharts.charts import Polar
years = ["2000", "2001", "2002", "2003", "2004", "2005", "2006", "2007", "2008", "2009", "2010"]
series1 = [25, 50, 50.5, 44.5, 53.5, 49, 54, 66, 59, 68, 54]
series2 = [24, 31, 26, 30.5, 38, 37, 52, 63, 59, 64.5, 43]
series3 = [22, 23.5, 25.5, 29.5, 32, 32, 37, 49, 42, 55, 37]
polar = Polar()
polar.add_schema(
radiusaxis_opts=opts.RadiusAxisOpts(type_="category", data=years), # 半径轴为年份
angleaxis_opts=opts.AngleAxisOpts(type_="value") # 角度轴为值
)
polar.add("Series1", series1, type_="bar", stack="stack1")
polar.add("Series2", series2, type_="bar", stack="stack1")
polar.add("Series3", series3, type_="bar", stack="stack1")
polar.render("polar_stacked_bar.html")
图表生成如下所示:
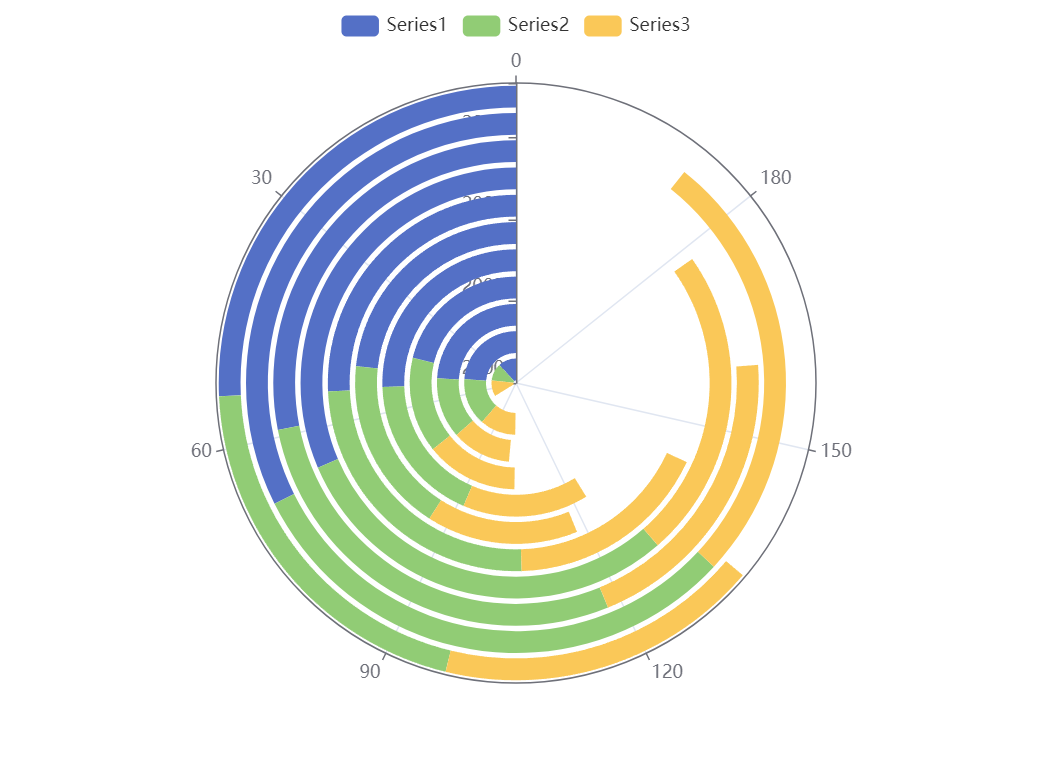
from pyecharts.charts import Polar
years = ["2000", "2001", "2002", "2003", "2004", "2005", "2006", "2007", "2008", "2009", "2010"]
series1 = [25, 50, 50.5, 44.5, 53.5, 49, 54, 66, 59, 68, 54]
series2 = [24, 31, 26, 30.5, 38, 37, 52, 63, 59, 64.5, 43]
series3 = [22, 23.5, 25.5, 29.5, 32, 32, 37, 49, 42, 55, 37]
polar = Polar()
polar.add_schema(
angleaxis_opts=opts.AngleAxisOpts(type_="category", data=years), # 角度轴表示年份
radiusaxis_opts=opts.RadiusAxisOpts(type_="value") # 半径轴表示数值
)
polar.add("A", series1, type_="bar", stack="stack1")
polar.add("B", series2, type_="bar", stack="stack1")
polar.add("C", series3, type_="bar", stack="stack1")
polar.set_global_opts(
title_opts=opts.TitleOpts(title="极坐标堆叠柱形图(圆边表示时间)"),
legend_opts=opts.LegendOpts()
)
polar.render("polar_stacked_bar_angle_time.html")
图表生成如下所示:
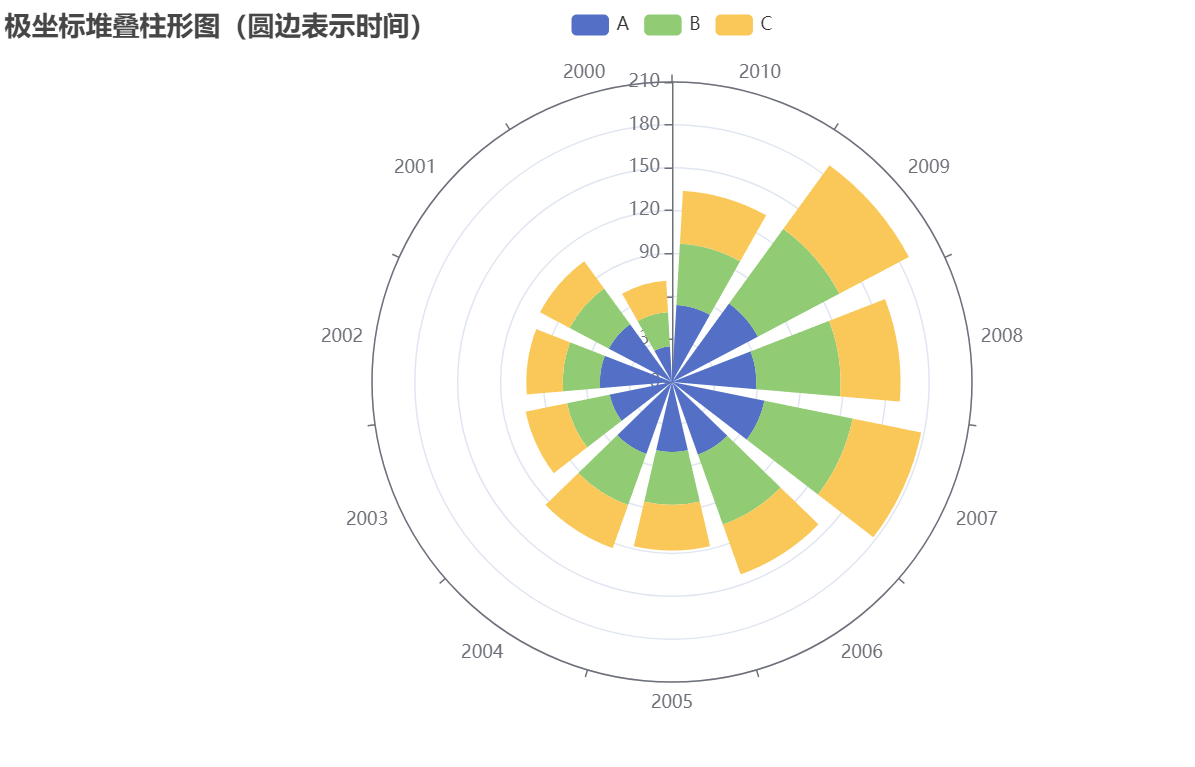
用其他图表对信息进行处理,代码如下所示
from pyecharts import options as opts
from pyecharts.charts import Bar
years = [str(y) for y in range(2000, 2011)]
data1 = [25, 50, 50.5, 44.5, 53.5, 49, 54, 66, 59, 68, 54]
data2 = [24, 31, 26, 30.5, 38, 37, 52, 63, 59, 64.5, 43]
data3 = [22, 23.5, 25.5, 29.5, 32, 32, 37, 49, 42, 55, 37]
bar = (
Bar()
.add_xaxis(years)
.add_yaxis("Series 1", data1, gap="10%")
.add_yaxis("Series 2", data2, gap="10%")
.add_yaxis("Series 3", data3, gap="10%")
.set_global_opts(
title_opts=opts.TitleOpts(title="分组柱状图"),
yaxis_opts=opts.AxisOpts(name="数值"),
xaxis_opts=opts.AxisOpts(name="年份", axislabel_opts={"rotate": 45}),
datazoom_opts=[opts.DataZoomOpts()]
)
)
bar.render("grouped_bar.html")
图表如下所示
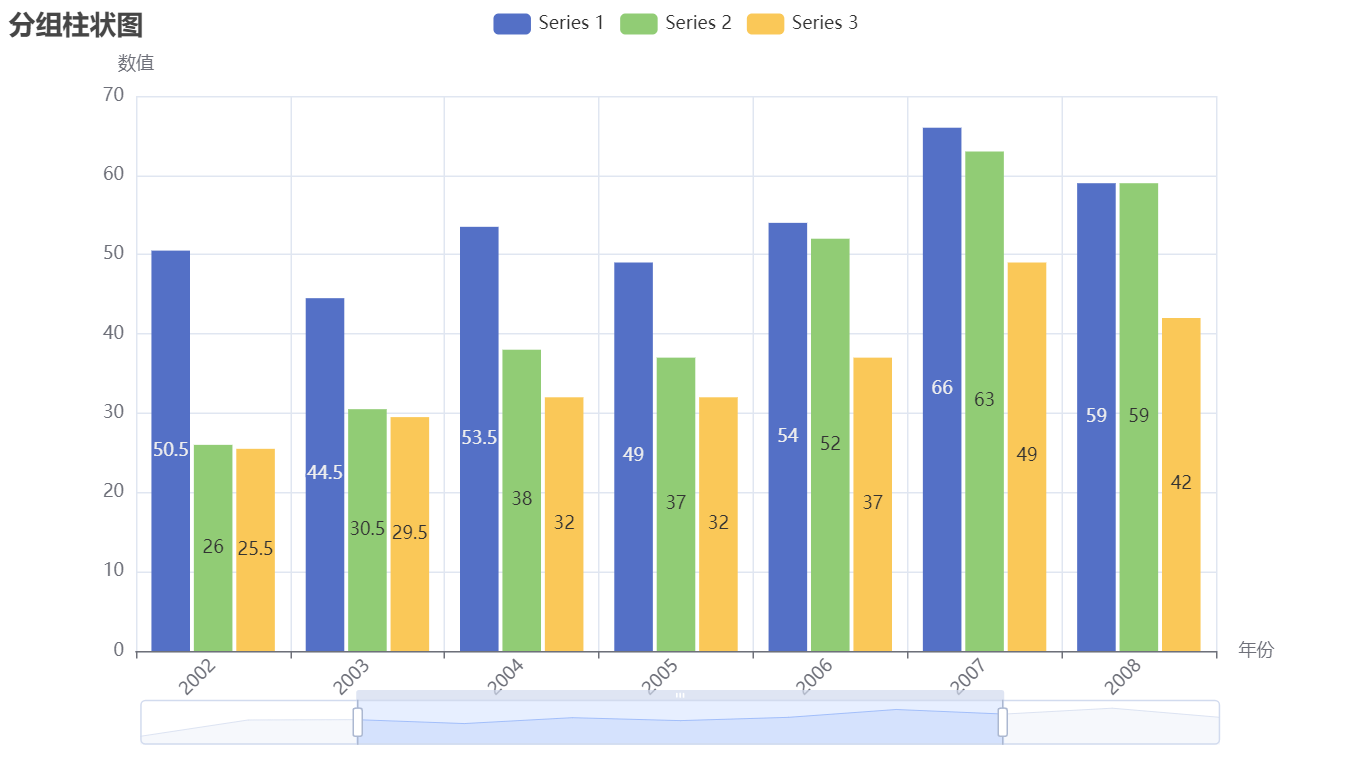
四、总结与心得
通过本次数据可视化实验,我深入理解了时间序列数据在可视化分析中的重要性及其应用场景。实验中以历年热狗大胃王比赛成绩数据为样本,结合堆叠柱形图与南丁格尔玫瑰图的绘制,直观展现了时间维度下数据的分布规律与趋势变化。在实现过程中,我深刻体会到图表类型选择对数据表达的关键影响:南丁格尔玫瑰图通过极坐标系将年份映射为圆周角度,利用半径长度反映数值大小,其视觉冲击力强,尤其适合呈现周期性时间数据,但需注意因面积与半径平方关系可能导致的数值比例夸大问题;而分组柱状图则以传统直角坐标系清晰展示各年份不同系列数据的对比,更利于精确比较具体数值。实验过程中,通过PyEcharts库的灵活配置,我掌握了如何调整坐标轴、堆叠效果及交互功能,进一步认识到工具使用需与实际分析目标紧密结合。此外,数据可视化的核心在于通过图形化手段揭示数据背后的故事,无论是趋势分析还是异常值发现,都需要在图表设计中平衡准确性、直观性与艺术性。此次实践不仅巩固了时间数据可视化的技术能力,更让我意识到,在未来的数据分析中,需根据场景需求合理选择可视化方法,才能最大化挖掘数据价值。

















 4744
4744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









