




 本文详细介绍了BEVFormer的架构,包括ResNet-101-DCN+FPN的backbone和neck,Encoder的TemporalSelf-Attention和SpatialCross-Attention模块,以及Decoder的3D目标检测过程。重点讨论了输入数据格式、特征提取、BEV特征生成、正负样本定义和损失计算等关键环节。
本文详细介绍了BEVFormer的架构,包括ResNet-101-DCN+FPN的backbone和neck,Encoder的TemporalSelf-Attention和SpatialCross-Attention模块,以及Decoder的3D目标检测过程。重点讨论了输入数据格式、特征提取、BEV特征生成、正负样本定义和损失计算等关键环节。
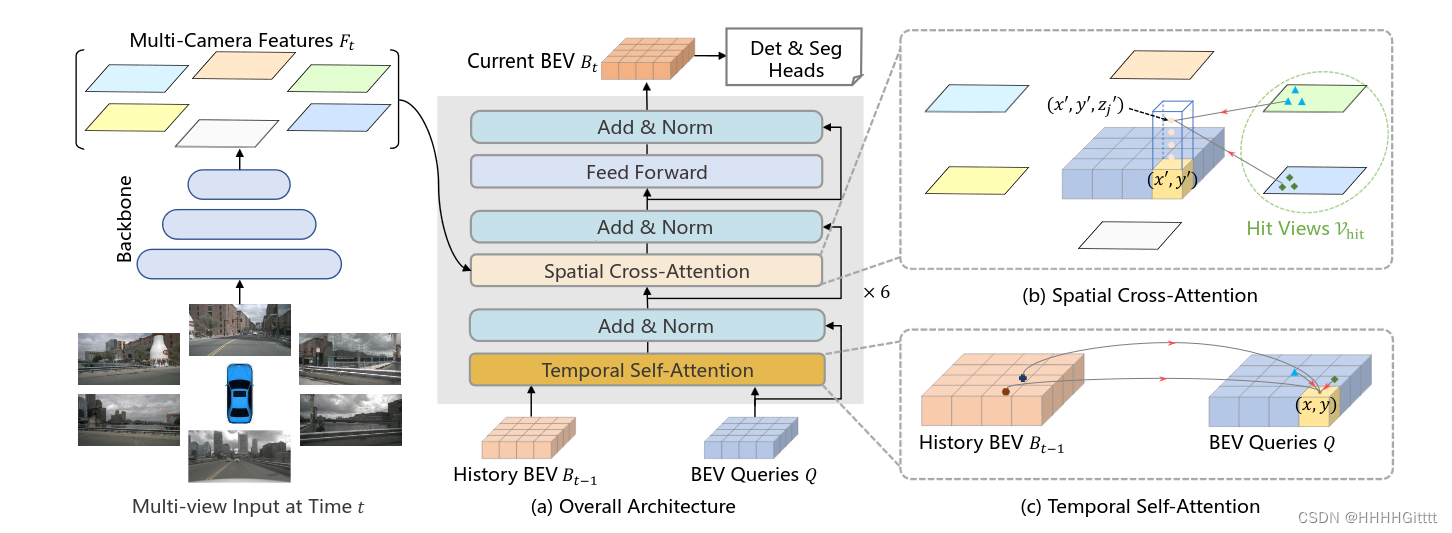
转载自: 万字长文理解纯视觉感知算法 —— BEVFormer - 知乎
BEVFormer 的 Pipeline
- Backbone + Neck (ResNet-101-DCN + FPN)提取环视图像的多尺度特征;
- 论文提出的 Encoder 模块(包括 Temporal Self-Attention 模块和 Spatial Cross-Attention 模块)完成环视图像特征向 BEV 特征的建模;
- 类似 Deformable DETR 的 Decoder 模块完成 3D 目标检测的分类和定位任务;
- 正负样本的定义(采用 Transformer 中常用的匈牙利匹配算法,Focal Loss + L1 Loss 的总损失和最小);
- 损失的计算(Focal Loss 分类损失 + L1 Loss 回归损失);
- 反向传播,更新网络模型参数;
接下来文章作者将从输入数据格式,网络特征提取,BEV特征产生,BEV 特征解码完成 3D 框预测、正负样本定义、损失计算这六个方面完成 BEVFormer 的解析;
输入数据格式
对于 B
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1883
1883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









