 Transformer模型详解:深度学习与自然语言处理的新里程碑
Transformer模型详解:深度学习与自然语言处理的新里程碑




 Transformer是一种深度学习模型,广泛应用在NLP任务中,如机器翻译和文本分类。模型基于Self-Attention机制,包含编码器和解码器,解决了传统序列模型如RNN的并行计算难题。训练采用最大似然估计方法。Transformer的出现推动了预训练模型如BERT和GPT的发展,尽管计算复杂度高,但在NLP领域有巨大潜力。
Transformer是一种深度学习模型,广泛应用在NLP任务中,如机器翻译和文本分类。模型基于Self-Attention机制,包含编码器和解码器,解决了传统序列模型如RNN的并行计算难题。训练采用最大似然估计方法。Transformer的出现推动了预训练模型如BERT和GPT的发展,尽管计算复杂度高,但在NLP领域有巨大潜力。
文章目录
摘要
Transformer是一种非常流行的深度学习模型,广泛应用于自然语言处理领域,例如机器翻译、文本分类、问答系统等。Transformer模型是由Google在2017年提出的,其优点在于可以在处理长文本时保持较好的性能,并且可以并行计算,提高训练速度。
Transformer模型包含两个部分:编码器和解码器。编码器主要负责将输入序列转化为一个定长的向量表示,解码器则将这个向量解码为输出序列。
Transformer模型是基于Self-Attention机制构建的。Self-Attention机制是一种能够计算序列中不同位置之间关系的方法。在Transformer中,每个输入经过Embedding层后,被分为多个子序列,每个子序列经过多层Self-Attention和全连接层,最终通过一个线性变换得到输出。
Abstract
Transformer is a very popular deep learning model, which is widely used in the field of natural language processing, such as machine translation, text classification, question answering system and so on. Transformer model was put forward by Google in 2017. Its advantage is that it can maintain good performance when dealing with long texts, and it can calculate in parallel to improve training speed. Transformer model consists of two parts: encoder and decoder. The encoder is mainly responsible for converting the input sequence into a fixed-length vector representation, and the decoder decodes this vector into an output sequence.
Transformer model is based on Self-Attention mechanism. Self-Attention mechanism is a method that can calculate the relationship between different positions in a sequence. In Transformer, each input is divided into multiple subsequences after passing through the Embedding layer, and each subsequence passes through multiple layers of Self-Attention and full connection layer, and finally the output is obtained through a linear transformation.
Transformer
Transformer的诞生
在自然语言处理任务中,往往需要对句子进行编码表示,以便后续任务使用。传统的序列模型,例如RNN和LSTM,能够在某种程度上解决这个问题,但是由于序列模型的特殊结构,使得其难以并行计算,并且在处理长文本时,性能下降明显。因此,Google提出了一种全新的模型——Transformer。
模型结构
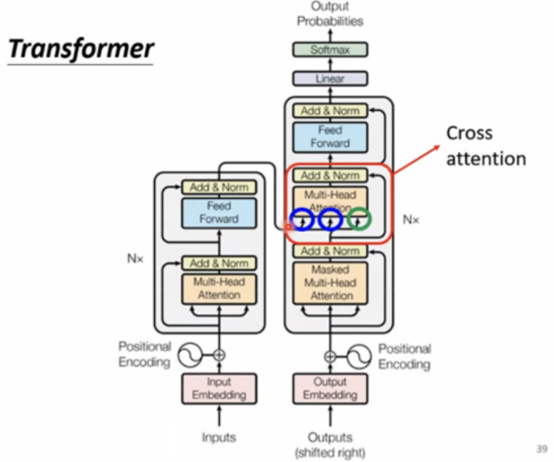
基于self-attention的机制,包括encoder编码器和decoder解码器两部分。上周周报已推导self-attention的计算公式如下:
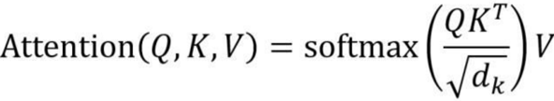
dk是Q,K矩阵的列数,即向量维度。
Encoder
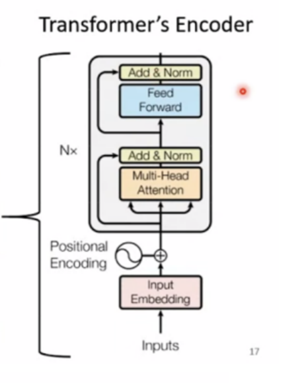
在encoder编码器中,每一层包括两个子层:Multi-Head Attention和全连接层。Multi-Head Attention层将输入序列中的每个位置都作为查询(Q)、键(K)和值(V),计算出每个位置和所有位置之间的注意力分布,得到一个加权和表示该位置的上下文信息。全连接层则对该上下文信息进行前向传播,得到该层的输出。
Decoder
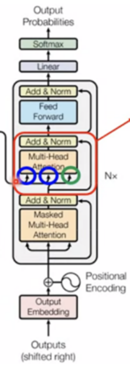
在解码器中,除了编码器中的Multi-Head Attention和全连接层,还增加了一个Masked Multi-Head Attention层。该层和编码器中的Multi-Head Attention类似,但是在计算注意力分布时,只考虑该位置之前的位置,从而避免了解码器中使用未来信息的问题。
模型训练
Transformer模型的训练过程通常使用最大似然估计(MLE)来完成。即对于给定的输入序列,模型预测输出序列的概率,并最大化其概率值。同时,为了避免过拟合,通常还会加入正则化项,例如L2正则化等。
MLE最大似然估计
概率与似然
概率(函数):参数已知,观察数据。
似然(函数):数据已知,评估参数。
概率质量函数(PMF)是用于描述离散随机变量的概率分布的函数。对于给定的随机变量取值,概率质量函数给出了该取值发生的概率。概率质量函数的输入是随机变量的取值,输出是对应取值的概率。
似然函数(Likelihood Function)是用于估计模型参数的函数。对于给定的模型参数值,似然函数衡量了观测数据出现该参数值的可能性。似然函数的输入是模型参数的取值,输出是在给定参数下观测数据出现的可能性。
概率质量函数和似然函数的区别在于它们关注的对象不同。概率质量函数是给定参数值时,计算随机变量的取值的概率;而似然函数是给定观测数据时,评估参数值的可能性。因此,似然函数通常用于参数估计,而概率质量函数用于描述随机变量的分布。
当我们有一个固定参数集的模型并且我们对可能生成的数据类型感兴趣时,通常会考虑概率。相反,当我们已经观察到数据并且我们想要检查某些模型参数的可能性时,就会使用似然。
用抛硬币来举例说明概率与似然的区别:

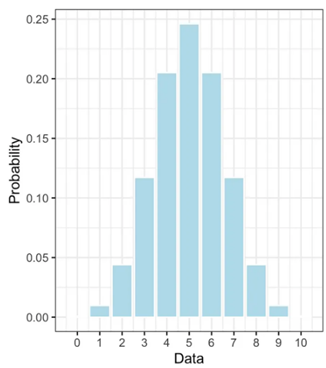

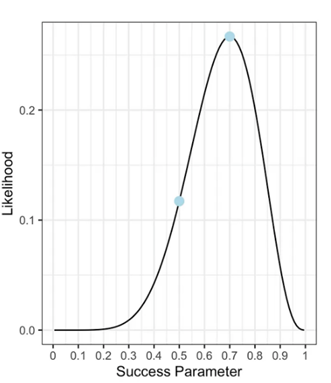
Maximum Likelihood Estimation
最大似然估计是一种使用观测数据来估计未知参数的方法。其工作原理是通过寻找最大化似然函数的参数组合,以使在假设的模型下,我们所观察到的数据具有最高的概率。


总结
Transformer模型作为一种新兴的深度学习模型,在自然语言处理领域中得到了广泛的应用。其强大的上下文信息处理能力,使得Transformer模型在自然语言生成、文本分类、语义理解等任务中表现出色。在Transformer模型的基础上,BERT、GPT-2、T5等预训练模型不断涌现,取得了越来越好的效果。Transformer模型也存在一些问题,例如计算复杂度高、需要大量的训练数据等,但总的来说,应用前景广阔,未来还有很大的发展空间。

















 312
312




 到【灌水乐园】发言
到【灌水乐园】发言







