



 自注意力机制解决了RNN在处理序列数据时的并行计算问题和长距离依赖问题,通过(key,query,value)三元组捕捉全局上下文。多头机制允许从不同角度获取特征表达,而位置编码则确保模型考虑序列位置信息。堆叠多层self-attention和使用残差连接能构建更复杂的结构。
自注意力机制解决了RNN在处理序列数据时的并行计算问题和长距离依赖问题,通过(key,query,value)三元组捕捉全局上下文。多头机制允许从不同角度获取特征表达,而位置编码则确保模型考虑序列位置信息。堆叠多层self-attention和使用残差连接能构建更复杂的结构。
文章目录
摘要
有时候我们期望网络能够看到全局,但是又要聚焦到重点信息上。比如在做自然语言处理时,句子中的一个词往往不是独立的,和它上下文相关,但和上下文中不同的词的相关性又是不同的,所以我们在处理这个词时,在看到它的上下文的同时也要更加聚焦与它相关性更高的词,这就需要用到自注意力机制。
自注意力机制在序列模型中取得了很大的进步。上下文信息对于很多视觉任务都很关键,如语义分割、目标检测。自注意力机制通过(key、query、value)的三元组提供了一种有效的捕捉全局上下文信息的建模方式。
Abstract
Sometimes we expect the network to see the overall situation, but we should focus on the important information. For example, when doing natural language processing, a word in a sentence is often not independent and related to its context, but its relevance to different words in the context is different. Therefore, when dealing with this word, we should pay more attention to words with higher relevance while seeing its context, which requires the use of self-attention mechanism.
Self-attention has made great progress in sequence model. Context information is crucial for many visual tasks, such as semantic segmentation and object detection. Self-attention provides an effective modeling method to capture global context information through the triplet of (key, query, value).
Self-attention
Self-attention的优势
在之前,NLP领域通常使用LSTM(RNN)来处理序列数据。例如在执行翻译任务时,需要考虑源句内部的关系、目标句内部的关系、原句与目标句之间的关系。然而RNNseq2seq模型只捕捉了原句与目标句之间的关系,因此RNN/LSTM产生了如下两个缺点:
A: 需要考虑前序信息,不能并行运算,导致训练所需时间较长。
B: 当序列长度过长的时候,由于模型深度增加,序列开始的部分对末端部分的影响几乎消失,虽然通过记忆网络、attention机制的加入可以降低一部分影响,但这种问题依旧存在。由于对于长距离的信息不能有效的提取和记忆,会导致信息的大量丢失。
Self-attention可以很好的处理上面两个问题,首先,self-attention通过位置编码保证序列
关系,计算上不依赖序列关系,所以可以实现完全的并行,其次,在计算相关性时候,任何
一个点都会与整个序列中的所有输入做相关性计算,避免了长距依赖的问题。
Self-attention的原理
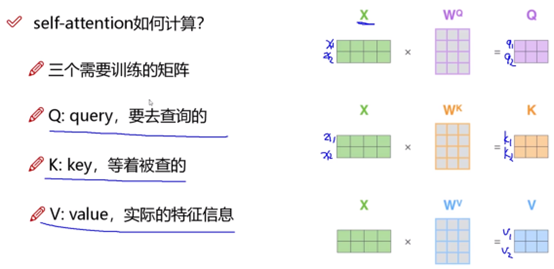
首先以两个词的输入为例来解释self-attention的大致过程:

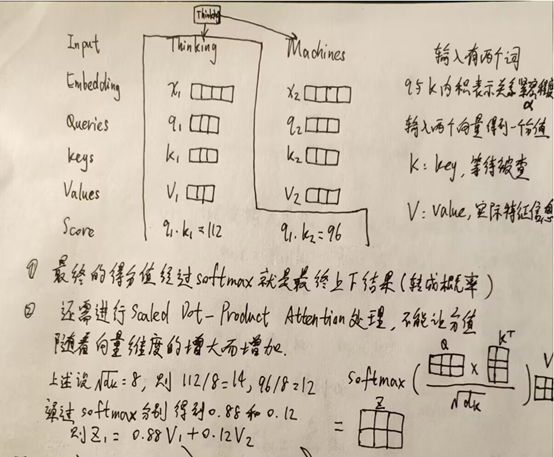
此时每个词看的是整个输入序列,不再只看之前的序列,并且是并行计算,同时计算出所有的输出结果。
再以四输入四输出为例进行补充说明:

只有Wq、Wk、Wv是机器需要学习的参数。
Multi-headed机制
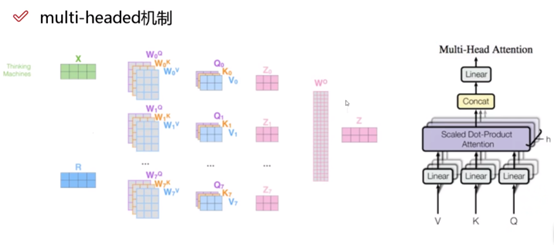
在CNN中,可以设置不同的filter来进行卷积,self-attention中也可以设置多组q,k,v的值得到不同的特征表达,这就是multi-headed机制。一般情况下,只做8组head即可,通过不同的head得到多个特征表达。多组结果z可以拼接在一起通过全连接层进行降维得到最终的结果。
堆叠多层

Self-attention输入输出都是向量,可以将self-attention也进行多层堆叠。10层以上都是很常见的。
位置信息表达
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于放哪都无所谓,但是这跟实际情况不符合,为了模型能对位置有额外的认识,需要进行位置编码。
Self-attention补充
结果需要通过Add和normalize,并且也可以类似CNN使用残差网络同等映射,以防在堆叠过程中出现结果变差的情况。
总结
本周继续学习了transformer中的核心机制self-attention并进行手动模拟推导,这有利于进一步理解transformer。本周学习内容的总和实际相当于是transformer中的encoder。decoder与encoder类似,只是attention的计算略有不同以及添加mask机制。在decoder中,只能利用序列中已得出的结果,不能用后面未推导出的部分。

















 1100
1100




 到【灌水乐园】发言
到【灌水乐园】发言







