






 本文介绍Stanford大学研发的信息抽取系统DeepDive。该系统利用因子图模型、吉布斯采样及权重学习等方法实现关系抽取。通过迭代学习与用户反馈不断提升准确性。
本文介绍Stanford大学研发的信息抽取系统DeepDive。该系统利用因子图模型、吉布斯采样及权重学习等方法实现关系抽取。通过迭代学习与用户反馈不断提升准确性。
最近在看关系抽取的一些相关的算法和开源工具,了解到了deepdive这一个开源的系统。最近几篇文章就大致介绍一下这个系统的算法原理和一个例子。
首先简单介绍一下关系抽取,关系抽取就是判断一个一句话中出现的两个实体是否存在某种已经定义好的关系。比如下面这个句子:

对于这样一次判断的过程,输入是句子+实体对。输出是夫妻关系这样一个类别。传统的关系抽取过程可以看成是对目标实体对和句子的一个多分类问题。
deepdive (http://deepdive.stanford.edu/) 是斯坦福大学开发的信息抽取系统,系统集成了文件分析、信息提取、信息整合、概率预测等功能。deepdive系统运行过程中包括一个重要的迭代环节。即每轮输出生成后,用户需要对运行结果进行错误分析,通过特征调整、更新知识库信息、修改规则等手段干预系统的学习,这样的交互与迭代计算能使得系统的输出不断得到改进。
首先来简单介绍一下deepdive的算法原理,主要分为以下几个内容:
1.因子图模型
2.吉布斯采样
3. 权重学习
1.因子图模型
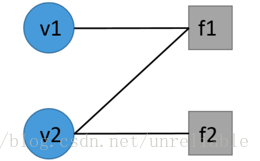
因子图是概率图模型的一种,在因子图中,有两类节点,变量节点和因子节点。每一个变量节点表示一个特定事件发生的概率。比如我们可以将小明是否抽烟看成一个变量节点,如果他抽烟。则节点值为1,否则则节点取值为0。在deepdive中,所有的变量节点都是布尔类型的。因子节点表示一种一阶谓词逻辑和其对应的特定的权重w,定义了变量节点之间的关系。我们可以把他们看成一些关于变量节点的函数。
接下来看一个例子,构造如上所示的一个因子图:
变量节点(V):
v1:小明是否有癌症
v2:小明是否抽烟
因子节点(F,W):
f1(v2, v1), w1:小明如果抽烟那么他有癌症
f2(v2), w2:我们认为小明是抽烟的
f1(0,0) = 1, f1(0,1) =1, f1(1,0) = 0 , f1(1,1) = 1
f2(1) = 1, f2(0) = 0
概率计算:

边缘概率:


















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









