








 该专栏为热销专栏榜 第32名
该专栏为热销专栏榜 第32名 超级会员免费看
超级会员免费看


【AI 天才研究院】DeepSeek R1 核心技术原理之 : Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for efficient
自GPT采用Transformer架构取得成功以来,经典Transformer架构一直是很多大模型的标配。但这不意味着Transformer是完美无缺的。DeepSeek在Transformer架构的基础上也做了很多创新,主要包括两个方面:
(1)多头潜在注意力即MLA
(2)混合专家模型即MoE。
MLA用于高效推理,源自DeepSeek V2的原创,其显著降低了推理显存的消耗。MLA主要通过改造注意力算子压缩KV 缓存大小,将每个查询KV量减少93.3%,实现了在同样容量下存储更多KV缓存,极大提升了推理效率。
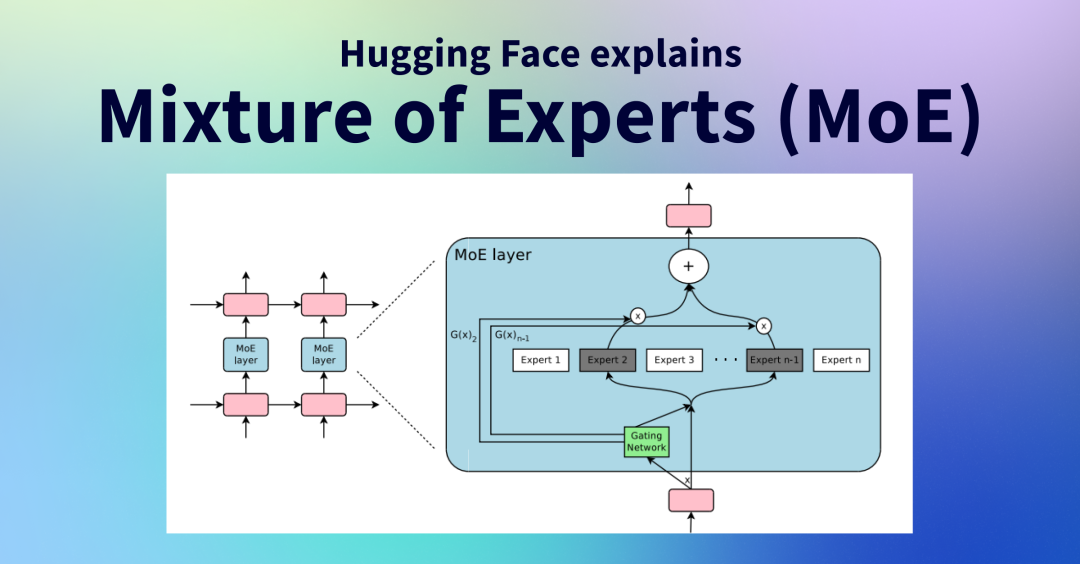
MoE 用于高效训练,其由多个专家模型组成,通过部分激活给定任务所需的特定专家,而不是激活整个神经网络,从而降低计算消耗。MoE非DeepSeek原创,但DeepSeek早在V2之前的 代码和数学模型,就从稠密架构转向 MoE架构。V3模型中更是大胆地使用了高难度的256个路由专家和1个共享专家,并创新的采用冗余专家,来实现负载均衡策略和训练目标。
Dense的缺点就是参数量大,硬件消耗大,这也导致之前的大模型价格高。MoE由多个子模型(即“专家expert”)组成,每个子模型都是一个局部模型,专门处理输入空间的一个子集。
相当于把dense大模型变成很多个sparse(稀疏)的专家(expert)小模型,通过多个模型聚合来达到和dense大模型相当的能力。转成MoE架构,DS-V2不仅激活参数量大大减少,并且性能提升很高。
举个例子,传统的大模型就好比一家几个顶级厨师的餐厅,每个厨师擅长所有的菜系,但当大量复杂的菜品出现时,厨师忙不过来反而会造成效率低下。MoE模型则相当于招了更多的没那么高级厨师来说,但是每个厨师会不同的菜系,在面对复杂的菜品时,模型能够根据菜品的特点,智能地将其分配给最合适的厨师处理,从而提高处理效率,减少不必要的资源浪费。
可能有人有会问,MoE这么好为什么国外大模型不爱用呢?
其实主要原因就是MoE大模型有个问题叫负载均衡(load balance),会导致训练不稳定。这会导致一个问题,就是训练过程中会采用所谓的专家并行(expert parallelism)机制,通过将不同的expert放到不同的显卡上来加速训练,而load balance问题会导致某些重要的expert计算量更大,最终结果就是不重要的expert所在的显卡跑不满,效率不够高。
DeepSeek-V2则在一些现有的解决load balance问题的方法基础上,引入了额外的损失函数(即设备级平衡损失和通信平衡损失,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











