




ARM Mobile Studio性能优化(一)
https://unity.cn/projects/arm-mobile-studioxing-neng-you-hua-yi
这篇文章我们开始继续 Streamline 的学习,透过 Streamline 的参数来学习 GPU 的原理是件,非常有意义的事情,在学习之前我们先来回顾一下 Mali 的 GPU 架构的历史。
第一代架构 Mali Utgard GPU,是 Mali 最早的 GPU 架构,它支持 OpenGL ES 2.0 核心包括 Mali-400 Mali-470 Mali-550 ,由于现在已经没有手机用这个架构了,所以可以不用看了。
第二代架构 Mali Midgard GPU,支持 OpenGL ES 3.0 和 OpenCL 支持的型号包括 Mali-T600, Mali-T700, and Mali-T800,现在可能还有一部分低端机在使用它。
第三代架构 Mali Bifrost GPU,支持的型号包括 Mali-G30, Mali-G50, and Mali-G70,我手上 的这台 Oppo R15 就搭载着 Helio P60 GPU 是 Mail-G72 Mp3 架构显卡由联发科生产。G70 系列显卡算是 2017 年的旗舰款了,现在可以算中低端性能机器。
第四代架构 Mali Valhall GPU,支持的型号包括 Mali-G5x and Mali-G7x,从 2018 年开始量 产。比如华为的 p40Pro 就搭载着麒麟 990,GPU 是 16 核 Mali-G76 GPU 由华为海思生产。
这里如果对硬件不太清楚的小伙伴可能会有疑问,ARM、高通、海思、联发科、Mali、华为、 小米、OPPO、台积电它们之间到底是啥关系?为什么所有手机 CPU 架构都使用 ARM 的?
ARM 厉害就在于它保持中立,自己不生产芯片,只卖 CPU 和 GPU 的架构。这样苹果、高 通、海思、联发科就可以购买它的架构后来自己生产。这就好比 ARM 是游戏引擎、游戏厂 商拿了游戏引擎的源码就可以开发属于自己的游戏引擎和游戏一样。
试想一下,如果 ARM 生产芯片,会不会给自家芯片加点什么特殊东西?那么谁还敢买它的 架构呢?所以保持中立是最正确的。当然苹果高通他们拿了 ARM 架构还会自己修改,这样 才能让自己的 CPU 进一步优化。
CPU 大家都使用 ARM 的架构,但是 GPU 上确不是。苹果和高通都自己设计 GPU 架构,高 通早年买了 AMD/ATI 的移动 GPU 方案自己定制了 Adreno,不得不说在安卓市场上最强的 芯片还是高通。2020 年 8 月份安卓手机性能排行榜前十名全是高通骁龙 865,即将登场的 高通骁龙 875 更是不得了。
华为的海思和联发科都是买了 ARM 的 CPU 和 GPU 架构,来自己生产设计芯片,华为厉害 就在于这样可以软硬件一起做,进一步提升手机性能。还有些其他厂商,比如小米 Oppo 等, 可以直接买了高通或者联发科的芯片来生产手机。这就好比我们做游戏,大厂都会买 Unity 的源码来定制一样,只有深度定制后才能发挥游戏的最高性能。所以说苹果才是深度定制的 最强玩家,从芯片的架构设计、软硬件、全都自己搞,这样的手机性能才能发挥极致。
有了芯片的架构还没完,总得生产出来吧,现在的芯片都是 7 纳米 5 纳米工艺,人眼都是 无法看见的,这时候就需要台积电了(不得不说台积电真是牛啊),可见从芯片的架构到消 费者中间有这么多环节。
在回到开发上,芯片生产商比如高通,显然不愿理透露太多芯片原理性的东西。因为它是直 接面对消费者,而 ARM 就不一样它是卖架构的,所以它会尽可能的透明原理,所以在 ARM 的官网上可以查到非常多的资料有助于我们学习,借助学习 Streamline 我也有了不少心得,希望更多的朋友一起讨论学习,可能有些东西我理解的也不正确,希望大家互相学习互相讨论。
OK 废话就不多说了,我们进入正题。首先我们来看看Mali现在主流的GPU架构Midgard 、 Bifrost、Valhall 的区别.
Bifrost 引入了 Index-Driven Geometry Pipeline (IDVS)翻译过来就是索引驱动几何管线。 先来看看早期的 Midgard 架构,Vertex Shading 走完后才进 Primitive Assembly 图元装配。 顶点着色里不仅需要处理坐标可能还需要处理别的,如果能单独把顶点拿出来提前处理,提前过滤掉需要被裁剪的图元,这样就能减少 Vertex Shading 的计算量。

Bifrost架构将Vertex Shading拆成两部分,在裁剪剔除(Clipping&Culling)之前先处理位置着色,这样就能提前过滤掉不再锥形体以内的图元,然后在执行通过的Varying Shading,这样就减少了原本顶点着色的计算量了。

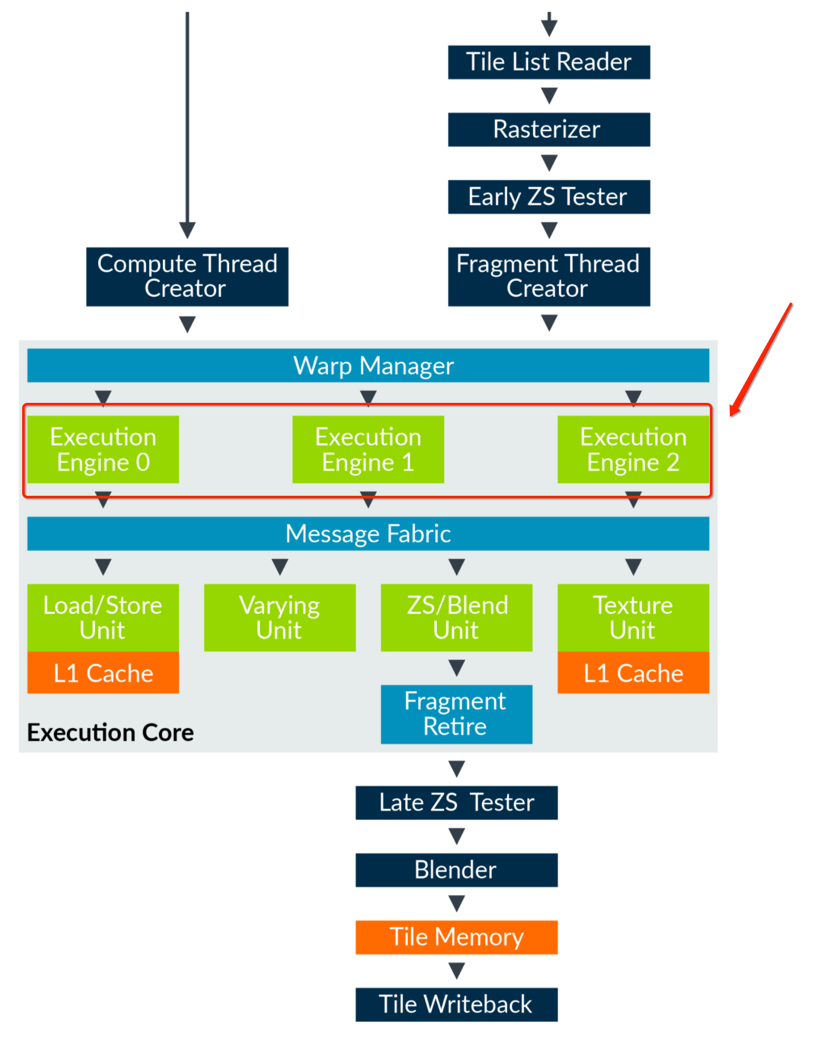
Bifrost 架构的着色核心,注意看 Execution Engine
在看看 Valhall 架构的着色核心,注意看 Processing Unit。
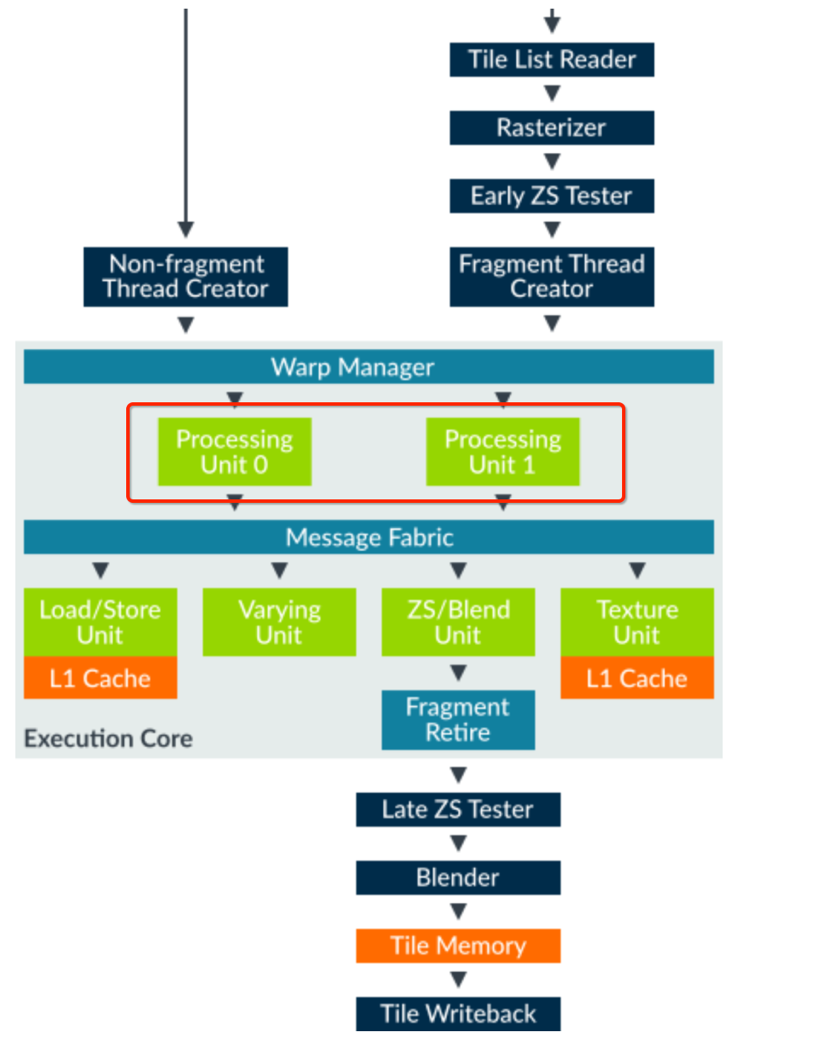
可以看到原本 Execution Engine 的被改成了 Processing Unit,它将原本数学计算管线分成了三部分,FMA 处理复杂的数学运算、CVT 处理简单的数学运算、SFU 处理特殊功能。 Load/Store Unit:加载/储存单元,负责和纹理采样以外的内存访问、比如内存访问、缓存区访问、它还拥有一个 16KB 的 L1 缓存。
Varying Unit:差值单元,比如顶点 shader 里的数据,插值后才会返回给片元着色器上。 ZS/Blend Unit:混合单元,负责将颜色写入缓存中。
Texture Unit:纹理单元,负责所有的纹理内存访问,一个时钟周期会采样 2x2 也就是 4 个像素。 所以如果我们的游戏 bound 在了 GPU 上,那就一定是以上 5 个单元出了问题。通过 Streamline 我们就可以知道到底卡在了那里。Streamline的使用方法可以看我上一篇文章
前面的图介绍了每个 Shader Core 中的结构,那么手机 GPU 中一般会有多核核心,也就是 多个 Shader Core。我手上的这台 Oppo R15 使用的是 Mali-G72 GPU,ARM 提供了 1-32 个 核心的自由拓展,联发科的这个 GPU 只拓展了 3 个核心。
如下图可以看出每个 Shader Core 都共享了 L2 缓存,缓存的大小在 64-128KB 之间也可以 由芯片生产商自由拓展,另外厂商还可以拓展储器的存储器端口的数量和总线宽度。
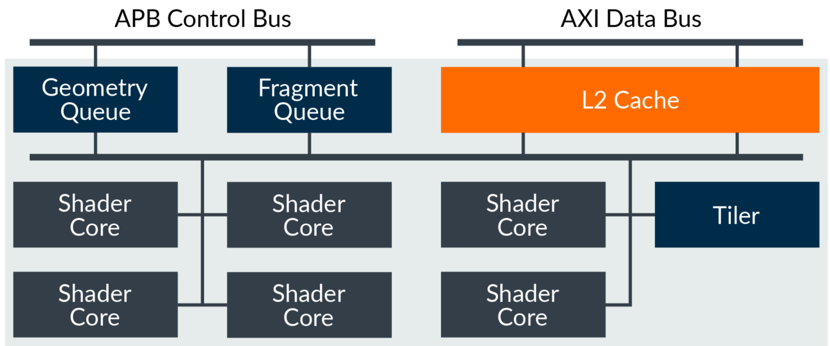
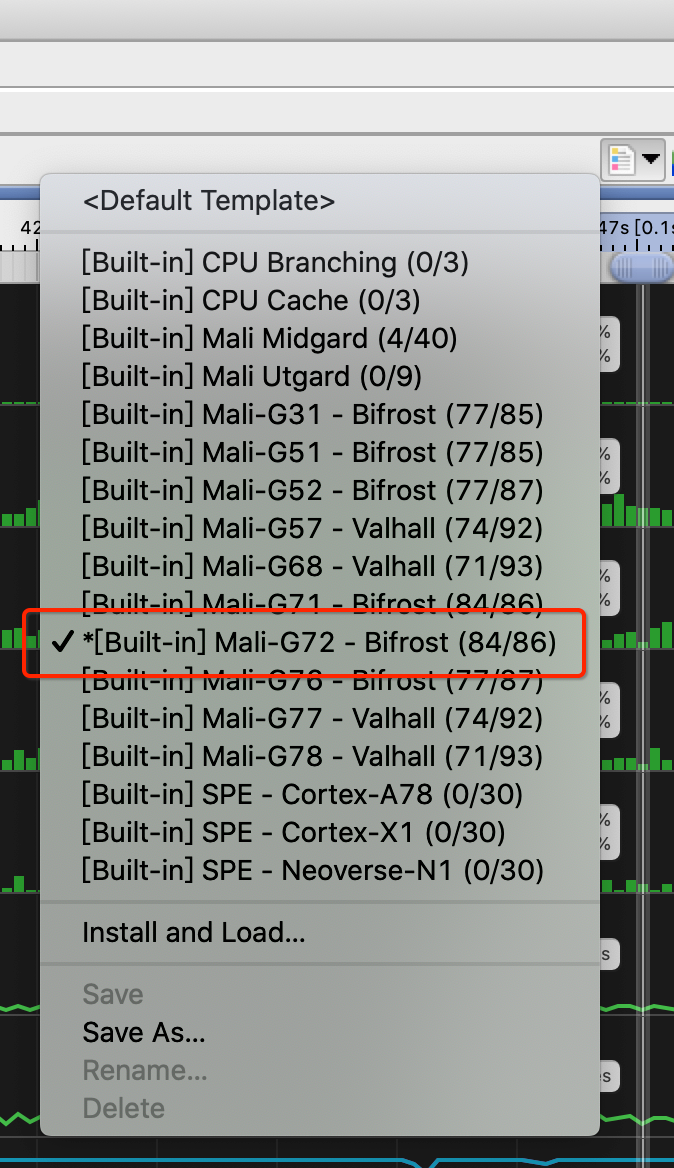
Valhall 架构可以每个时钟每个内核写入两个 32 位像素,这样如果配备 4 个核心每个时钟周 期的读取和写入操作共 32X2X4=256 内存带宽。 Streamline 的启动可以参考我的上一篇文章,为了数据的更加精准,这里需要选择你测试的 手机,我这里选择 G72-Bifrost。
Cortex-A53,这里是用的 4 个小核,通过我实际测试小核用的几率非常小。
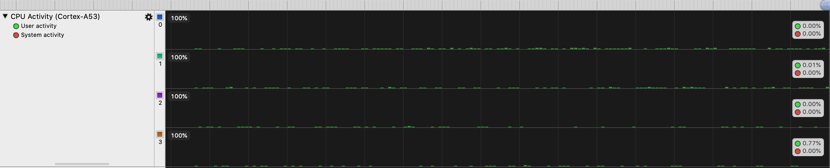
Cortex-A73,这里是用的 4 个大核,Unity 项目实际会一直使用大核。通过左侧的 User Activity 和 System Activity 可以看出每个大核的的压力,可以看出系统并没有占用,而是我们自己的 游戏占用的比较大。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









