




 本文深入探讨哈希表的工作原理,包括哈希函数的性质、静态哈希的不足及解决方案,如动态调整桶数量的可扩展哈希,以及处理哈希冲突的方法,如拉链法、线性探测法等。
本文深入探讨哈希表的工作原理,包括哈希函数的性质、静态哈希的不足及解决方案,如动态调整桶数量的可扩展哈希,以及处理哈希冲突的方法,如拉链法、线性探测法等。
部分内容参考文档:
- https://blog.youkuaiyun.com/caianye/article/details/5839917
- https://www.cnblogs.com/penghuwan/p/8458269.html#_label0
为什么要使用哈希表
Hashing
Hash函数的性质:
一致性:具有相同关键字的值被赋给同一个桶中。
随机性:每个桶将会有相同数据的记录,而不考虑文件中关键字的真实分布。
最坏性:把所有的关键字映射到同一个桶中,使得访问时间和文件中关键字的数量成正比。
Static Hashing:
如果没有空间剩余,将会分配overflow buckets, 用链表把它们连接起来。(长的链表降低了性能)
Deficiency:
一:如果初始桶的数量很少,随着文件的增长,性能将会因为太多的overflow buckets下降。
二:如果分配期望增长的空间,那么大量的空间在开始的时候都浪费了。
三:如果数据库比较小,空间再次浪费了。
One Solution: 周期的用新的Hash函数重新组织文件。
缺点是:昂贵,打乱了正常的操作。
Better solution: 动态的改变桶的数目。
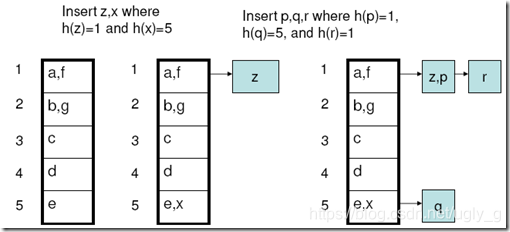
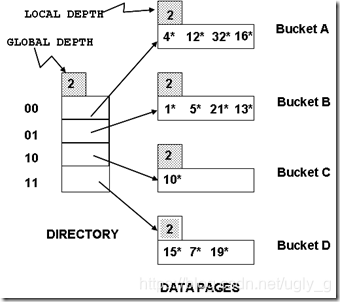
Extendible Hashing
既然桶装满了,为何不用双倍的桶来组织文件?
一:只需要分裂溢出的桶。(但是读写所有的文件是很昂贵的)
Idea:使用指向桶的指针目录,通过双倍指针目录来双倍桶。因为指针目录比文件小,所以双倍指针目录会更划算。
symbol table(潜在无穷的集合)
碰撞是一定会有的,函数不可能设计成一对一的。所以问题转化为如何处理碰撞。
collisions(冲突)
The birthday problem
删除:
计算哈希地址
简单的关键字取得策略:
①h(k) = k mod m
e.g. m = 12, k=100 ,h(k)=4
②二进制表示后几位
③m取素数能表示比较均匀的分布
关于同义词(k1,k2)
k1≠k2
h(k1)=h(k2)
怎么设计哈希函数:

如果是字符串,则设计其转化为十进制数。

task:
①怎么判断哪个哈希函数分布值更均匀:
②怎么解决冲突:
- 拉链法
- 线性探测法
- 再哈希法
- instread of a hash table, we use a table of linked list
- keep a linked list of keys that hash to the same value

relocation scheme
①Linear Probing - f(i)=i
为什么链表链在前面更简单?
设计表的结构,怎么构造表?
再哈希
当插入的数大于预估
double hashing example
http://www.cplusplus.com/forum/general/88539/
比较好的哈希函数是time33算法。PHP的数组就是把这个作为哈希函数。
核心的算法就是如下:
unsigned long hash(const char* key){
unsigned long hash=0;
for(int i=0;i<strlen(key);i++){
hash = hash*33+str[i];
}
return hash;
}

















 3103
3103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









