




 本文介绍了XGBoost,一种流行的基于GBDT的集成学习算法,重点讲解了其目标函数、模型优化策略(如列采样和正则项)、与CART的关系以及其在Python等语言中的应用。XGBoost通过优化和并行计算提升模型性能,防止过拟合。
本文介绍了XGBoost,一种流行的基于GBDT的集成学习算法,重点讲解了其目标函数、模型优化策略(如列采样和正则项)、与CART的关系以及其在Python等语言中的应用。XGBoost通过优化和并行计算提升模型性能,防止过拟合。
概述
XGBoost是GBDT算法的一种变种,是一种常用的有监督集成学习算法;是一种伸缩性强、便捷的可并行构建模型的Gradient Boosting算法。
XGBoost官网:
http://xgboost.readthedocs.io;
XGBoost Github源码位置
https://github.com/dmlc/xgboost;
XGBoost支持开发语言:Python、R、Java、Scala、C++、GPU等。
XGBoost安装
• 安装方式一:
编译Github上的源码,参考http://xgboost.readthedocs.io/en/latest/build.html
• 安装方式二:
python的whl文件进行安装,要求python版本3.5或者3.6;
下载链接:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost;
安装参考命令:pip install f:///xgboost-0.7-cp36-cp36m-win_amd64.whl
• 安装方式三:
直接pip命令安装:pip install xgboost
CART、GBDT
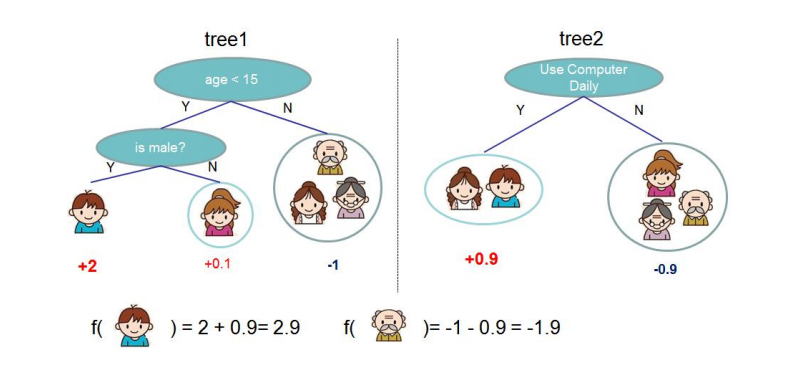
GBDT算法的底层一般采用CART树。
GBDT和CART都是决策树算法的变种,但是它们的实现方式和应用场景有所不同。
CART(Classification and Regression Tree)是一种二叉决策树,它可以用于分类和回归任务。它通过选择一个最优的特征,将数据集划分为两个子集,然后对每个子集递归地进行划分,直到满足某个停止条件为止。在分类任务中,CART使用基尼系数或信息增益作为特征选择的依据,而在回归任务中,它使用平方误差或平均绝对误差作为损失函数。
GBDT(Gradient Boosting Decision Tree)是一种集成学习算法,它通过组合多个决策树来提高模型的预测性能。在GBDT中,每个决策树都是在前面所有决策树的残差基础上进行训练的。GBDT的特征选择是通过梯度提升的方式进行的,它使用损失函数的负梯度来选择最优的特征。
因此,可以说GBDT是基于CART的算法,但是它们的实现方式和应用场景有所不同。
模型
- 目标函数
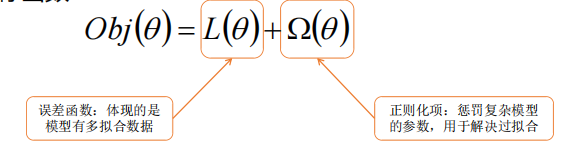
XGBoost

GBDT的目标函数: o b j = ∑ i = 1 n l ( y i , y ^ i ( t ) ) obj=\sum_{i=1}^{n} l(y_i,\hat y_i^{(t)}) obj=∑i=1nl(yi,y^i(t))
XGBoost的目标函数: o b j = ∑ i = 1 n l ( y i , y ^ i ( t ) ) + ∑ i = 1 t Ω ( f i ) \scriptsize{ obj = \sum_{i=1}^{n} l(y_i,\hat y_i^{(t)})+\sum_{i=1}^{t}\Omega(f_i) } obj=∑i=1nl(yi,y^i(t))+∑i=1tΩ(fi)
f t ( x ) = w q ( x ) Ω ( f ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \scriptsize{ f_t(x)=w_{q(x)} \quad\quad\quad \Omega(f)=\gamma T + \frac{1}{2}\lambda \sum_{j=1}^{T}w_j^2 } ft(x)=wq(x)Ω(f)=γT+21λ∑j=1Twj2
我们希望CART树长得越矮越好,越矮的CART树叶子节点越少,则数据集进入CART后分到每个节点上的数据就会变多,那么异常值对结果产生的影响就会变小
为此引入了对叶子结点的惩罚项 Ω ( f ) \Omega(f) Ω(f);
T为叶子节点数,引入γ的目的是对叶子节点数进行惩罚;
引入 ∑ j = 1 T w j 2 \scriptsize{ \sum_{j=1}^{T} w_j^2 } ∑j=1Twj2的目的是对叶子分类结果进行惩罚,λ为惩罚系数;
XGBoost公式推导
- 第t次迭代后,模型的预测等于前t-1次的模型加上第t棵树的预测:
y ^ i ( t ) = y ^ i ( t − 1 ) + f t ( x i ) \scriptsize{ \hat y_i^{(t)}=\hat y_i^{(t-1)}+f_t(x_i) } y^i(t)=y^i(t−1)+f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









