






N-Gram模型介绍
本文将以实践的方式讨论N-Gram原理与其应用,我对N-Gram的接触来源与一个文本分类的实验,发现在原有的分词基础上引入N-Gram会提升分类准确率,因此在此讨论什么是N-Gram?它有什么作用?
N-Gram常用的有三种:unigram,bigram,trigram 分别对应一元,二元,三元
以“我想去成都吃火锅”为例,对其进行分词处理,得到下面的数组:[“我”,“想”,“去”,“成”,“都”,“吃”,“火”,“锅”]
这就是uningram,分词的时候对应一个滑动窗口,窗口大小为1,所以每次只取一个值,同理假设使用bigram就会得到
[“我想”,“想去”,“去成”,“成都”,“都吃”,“吃火”,“火锅”],N-gram模型认为词与词之间有关系的距离为N,如果超过N则认为它们之间没有联系,所有就不会出现"我成",“我去”这些词。
如果使用trigram,则就是[“我想去”,“想去成”,“去成都”,…]。N理论上可以设置为任意值,但是一般设置成上面3个类型就够了。
N-Gram模型应用
假设我们有下面的语料
“我想去成都吃火锅”
“你会成功”
“我想吃火锅”
“成都火锅好吃”
对上面的语料使用bigram模型统计词频处理,为每个二元词分配一个概率,或者统计单个词条件下后面一个词出现的概率,这两种概率有什么用呢?
首先以一种概率可以应用在名词提取,比如说语料库中,“成都”,“火锅”出现频率较高,将会被分配较高的概率,因此可以考虑将这两个词作为名词提取出。
第二种概率可以以条件概率的形式给出,就比较明显用处了。如P(“都”|“成”),P(“锅”|“火”)将会被分配给较高的概率,因此可以用在智能提示上面,加上我输入一个“成”,模型将会将返回在“成”的条件下,下个词出现频率较高的词,这里解释可能有点绕口,看下面的公式:
P(“都”|“成”)=2/3>P(“功”|“成”)=1/3
那么我们很有必要认为用户下一个词输入的是“都”,而不是“功”。或者直接给个列表,按照概率的方式排序,像这样:
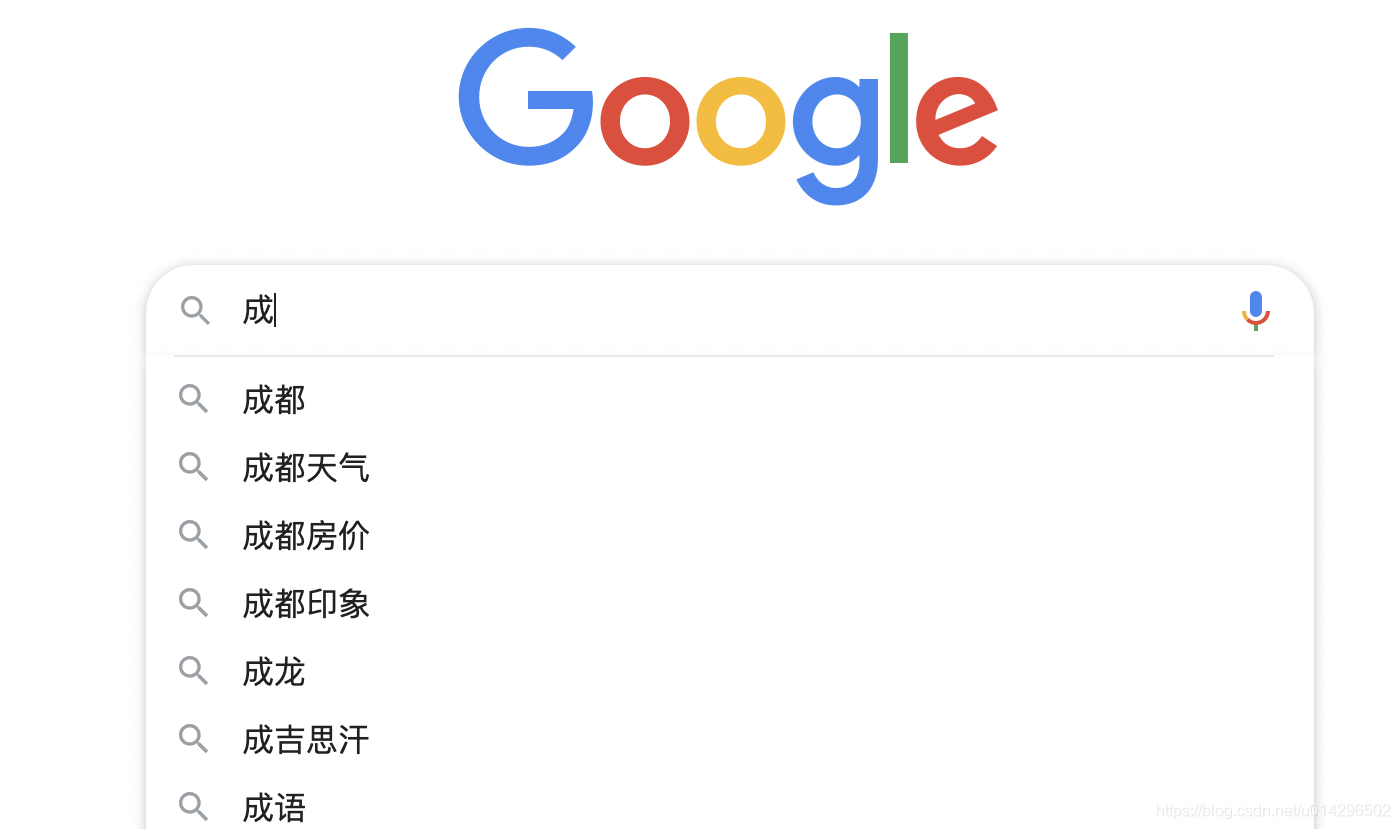
看谷歌的提示,都是2个或者4个词,我觉得这里可以把“成”看成一个词,预测下个词"都"后,再把“成都”看成一个词,从而可以预测出来“天气”,“房价”,就能够实现这个功能。一般情况下,N-Gram的N设置为1,2就够用了,但是如果语料够丰富的话,我觉得适当的增加N大小,可能会引入更多的语义信息。

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









