






并行计算实验2
2021.11.24
创建结点
docker run --rm --name=node1 --network=mpi-net -v /root/program:/root/program -itd mpi-centos

查看结点

进入结点
docker exec -it e21c327ef219 /bin/bash
由于我们的共享地址是 :/root/program,所以将server文件创建在这里,编译后的文件也放在这里
创建servers文件
#当前目录是/root/program
vi servcers
node1:3
node2:3
node3:3
编译cpi文件到此
mpicc /root/mpich-3.2/examples/cpi.c -o /root/program/cpi
当前的文件:ls

执行编译
mpirun -n 9 -f ./servers ./cpi
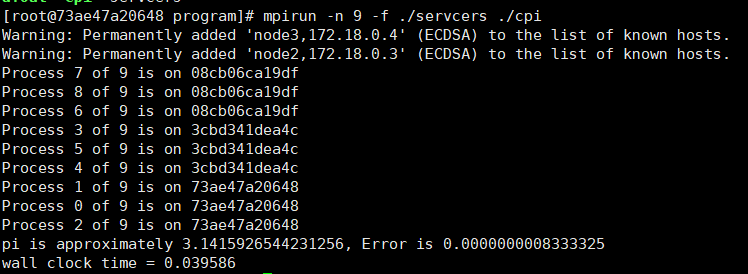
三.MPI程序演示
新建pi.c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <mpi.h>
void read_num(long long int *num_point,int my_rank,MPI_Comm comm);
void compute_pi(long long int num_point,long long int* num_in_cycle,
long long int* local_num_point,int comm_sz,long long int *total_num_in_cycle,MPI_Comm comm,int my_rank);
int main(int argc,char** argv){
long long int num_in_cycle,num_point,total_num_in_cycle,
local_num_point;
int my_rank,comm_sz;
double begin,end;
MPI_Comm comm; MPI_Init(NULL,NULL);//初始化
comm=MPI_COMM_WORLD;
MPI_Comm_size(comm,&comm_sz);//得到进程总数 MPI_Comm_rank(comm,&my_rank);//得到进程编号
read_num(&num_point,my_rank,comm);//读取输入数据begin=MPI_Wtime();
compute_pi(num_point,&num_in_cycle,&local_num_point,comm_sz,&total_num_in_cycle,comm,my_rank);
end=MPI_Wtime();
if(my_rank==0){ printf("Elapsing time: %fs\n",end-begin); }
MPI_Finalize();
return 0;
}
void read_num(long long int* num_point,int my_rank,MPI_Comm comm){
if(my_rank==0){
printf("please input num in sqaure \n"); scanf("%lld",num_point); }
MPI_Bcast(num_point,1,MPI_LONG_LONG,0,comm);
}
void compute_pi(long long int num_point,long long int* num_in_cycle,long long int* local_num_point,int comm_sz,long long int *total_num_in_cycle,MPI_Comm comm,int my_rank){
*num_in_cycle=0;
*local_num_point=num_point/comm_sz;
double x,y,distance_squared;
srand(time(NULL));
for(long long int i=0;i< *local_num_point;i++){
x=(double)rand()/(double)RAND_MAX;
x=x*2-1;
y=(double)rand()/(double)RAND_MAX;
y=y*2-1;
distance_squared=x*x+y*y;
if(distance_squared<=1)
*num_in_cycle=*num_in_cycle+1;
} MPI_Reduce(num_in_cycle,total_num_in_cycle,1,MPI_LONG_LONG,MPI_SUM,0,comm);
if(my_rank==0){
double pi=(double)*total_num_in_cycle/(double)num_point*4; printf("the estimate value of pi is %lf\n",pi);
}
}
编译
mpicc pi.c -std=c99 -o pi #不写后面会报错
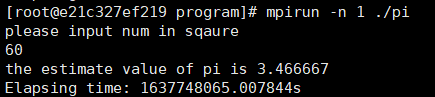
运行
mpirun -n 1 ./pi



















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











