






 本文详细介绍了Hadoop的安装配置,包括创建hadoop用户、安装VIM、ssh、java环境及hadoop。接着展示了如何在伪分布式模式下运行Hadoop,配置core-site.xml和hdfs-site.xml,并执行相关命令。此外,还提供了MapReduce的编程实例,实现了文件合并、去重、排序等功能,展示了如何编写MapReduce程序并执行。
本文详细介绍了Hadoop的安装配置,包括创建hadoop用户、安装VIM、ssh、java环境及hadoop。接着展示了如何在伪分布式模式下运行Hadoop,配置core-site.xml和hdfs-site.xml,并执行相关命令。此外,还提供了MapReduce的编程实例,实现了文件合并、去重、排序等功能,展示了如何编写MapReduce程序并执行。
hadoop大数据
实验一–安装基本的环境以及简单的编程
创建hadoop用户,方便管理
#创建用户
sudo useradd -m hadoop -s /bin/bash
#设置用户名
sudo passwd hadoop
#设置管理员权限
sudo adduser hadoop sudo
#更新apt
sudo apt-get update
安装VIM编辑器
sudo apt-get install vim
安装ssh
sudo apt-get install openssh-server
#成功后登录本机
ssh localhost
#配置免密码秘钥
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh ocalhost
ssh-keygen -t rsa # 会有提示,都按回车即可
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
安装java环境
cd /usr/lib
sudo mkdir jvm #创建/jvm目录用来存放JDK文件
#进入你的jdk包目录下,下面执行解压
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
配置环境变量
vim ~/.bashrc
在文件的开头放入以下文字
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc#该语句使得上面的立即生效
安装hadoop
#解压hadoop
sudo tar -zxf ~/hadoop.tar.gz -C /usr/local
#修改文件夹访问权限
sudo chown -R hadoop ./hadoop
#进入hadoop解压目录后执行是否安装成功
./bin/hadoop version
伪分布式模式
core-site.xml文件的修改
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置文件配置好后,格式化
./bin/hdfs namenode -format
启动hadoop程序
./sbin/start-dfs.sh
进入web查看:
localhost:9000
停止hadoop程序
./sbin/stop-dfs.sh
可以将hadoop配置到环境变量~/.bashrc
export PATH=$PATH:/usr/local/hadoop/sbin
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
source ~/.bashrc#变量生效
直接使用start-dfs.sh启动hadoop
hadoop常用命令
| 指令 | 详解 |
|---|---|
| ./bin/hdfs dfs | 查看所有命令 |
| ./bin/hdfs dfs –help put | 查看put的解释 |
| dfs –mkdir –p /user/hadoop | 在HDFS中为hadoop用户创建一个用户目录(需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。) |
| dfs –ls . | 显示HDFS中与当前用户hadoop对应的用户目录下的内容 |
| dfs –ls /user/hadoop | 上一条等价 |
| dfs –ls | 列出HDFS上的所有目录 |
| dfs –mkdir filename | 创建目录 |
| dfs –rm –r /input | 删除目录 |
| dfs -put File.txt input | 将File.txt传到input文件夹中 |
| dfs –cat input/File.txt | 查看文件内容 |
| dfs -get input/File.txt /下载 | 下载到本地目录 |
| dfs -cp | 复制命令 |
实验要求:
首先,利用Hadoop提供的Shell命令完成:
(1) 向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
(2) 从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
(3) 将HDFS中指定文件的内容输出到终端中;
(4) 显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
(5) 给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
(6) 提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
(7) 提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
(8) 向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
(9) 删除HDFS中指定的文件;
(10) 删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录;
(11) 在HDFS中,将文件从源路径移动到目的路径。
package sy1;
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/***
* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
*/
public class MergeFile {
Path inputPath = null; // 待合并的文件所在的目录的路径
Path outputPath = null; // 输出文件的路径
String hadoopUrl="192.168.242.129";
String hadoopPort="9000";
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://"+hadoopUrl+"/:"+hadoopPort+"");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
// 下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath, new MyPathFilter(".*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
// 下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
// 下面打印后缀不为.abc的文件的路径、文件大小
System.out.print(
"路径:" + sta.getPath() + " 文件大小:" + sta.getLen() + " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile("hdfs://192.168.242.129:9000/user/hadoop/input",
"hdfs://192.168.242.129:9000/user/hadoop/input/merge.txt");
merge.doMerge();
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIEUVFpJ-1637591473580)(hadoop大数据.assets\image-20211029010516212.png)]
实验二-mapreduce
MapReduce编程实践1
1 作业题目
编程实现一个词频统计程序
2 作业目的
1. 理解Hadoop中MapReduce模块的处理逻辑
2. 熟悉MapReduce编程
3 实验平台
操作系统:Linux
工具:Eclipse或者Intellij Idea等Java IDE
4 实验内容和要求
1. 统计/user/hadoop/input文件夹下所有文件中每个单词出现的次数。
2. 假设:在Linux本地文件系统/usr/local/hadoop文件夹中有2个文本文件:wordfile1.txt, wordfile2.txt。这个txt文件的内容可以任意,也可以类似如下内容:
文件wordfile1.txt的内容如下:
Hello Hadoop
I love Hadoop
文件 wordfile2.txt的内容如下:
Hello Mapreduce lab
Mapreduce is good
3. 启动hadoop伪分布式,将Linux本地的两个文件wordfile1.txt和wordfile2.txt上传到/user/hadoop/input目录下。
4. 编写mapreduce程序,实现单词出现次数统计。统计结果保存到/user/hadoop/output文件夹。
5. 获取统计结果(给出截图或相关结果数据)
步骤
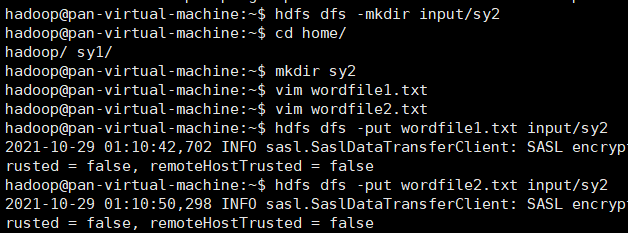
#创建input/sy2:
hdfs dfs -mkdir input/sy2
#创建本地文件
vim wordfile1.txt
vim wordfile2.txt
文件wordfile1.txt的内容如下:
Hello Hadoop
I love Hadoop
文件 wordfile2.txt的内容如下:
Hello Mapreduce lab
Mapreduce is good
#上传
hdfs dfs -put wordfile1.txt input/sy2
hdfs dfs -put wordfile2.txt input/sy2
直接执行程序
#配置环境
export CLASSPATH="/usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:$CLASSPATH"
#编译
javac WordCount.java
#连接
jar -cvf WordCount.jar *.class
#执行
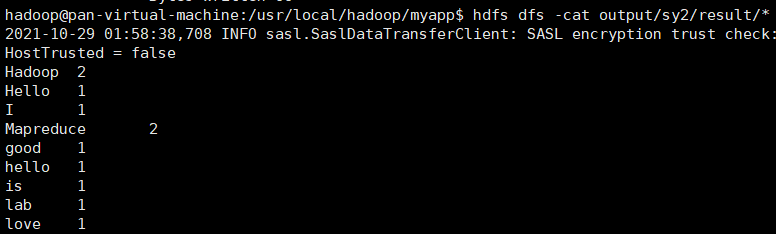
hadoop jar WordCount.jar WordCount input/sy2 output/sy2
#输出
hdfs dfs -cat output/sy2/*
输出结果
MapReduce编程实践2
1 作业题目
编程实现多个输入文件的合并和排序等操作。
2 作业目的
1.掌握基本的MapReduce编程方法;
2.掌握用MapReduce解决一些常见的数据处理问题,包括数据合并、去重、排序等。
3 实验平台
(1)操作系统:Linux(建议 Ubuntu18.04 或 Ubuntu20.04)
(2)Hadoop 版本:3.1.3。
4 实验内容和要求
1.编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
输入文件A的样例如下:
20210101 x
20210102 y
20210103 x
20210104 y
20210105 z
20210106 x
输入文件B的样例如下:
20210101 y
20210102 y
20210103 x
20210104 z
20210105 y
根据输入文件A和B合并得到的输出文件C的样例如下:
20210101 x
20210101 y
20210102 y
20210103 x
20210104 y
20210104 z
20210105 y
20210105 z
20210106 x
2. 编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
输入文件1的样例如下:
33
37
12
40
输入文件2的样例如下:
4
16
39
5
输入文件3的样例如下:
1
45
25
根据输入文件1、2和3得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
访问参数的配置
package sy1;
/**
* @author 潘彬
* @version 创建时间:2021年10月29日 上午1:25:41
* 类说明
*/
public class HADOOP {
public static String hadoopUrl="hdfs://192.168.242.129:9000";
public static String[] sy2Args1={"hdfs://192.168.242.129:9000/user/hadoop/input/sy2/1",
"hdfs://192.168.242.129:9000/user/hadoop/output/sy2/1/C.txt"};
public static String[] sy2Args2={"hdfs://192.168.242.129:9000/user/hadoop/input/sy2/2",
"hdfs://192.168.242.129:9000/user/hadoop/output/sy2/2/"};
}
程序1
vim A
vim B
程序上传后:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZwyaFxoJ-1637591473585)(hadoop大数据.assets\image-20211029123236150.png)]
//编程实现文件合并和去重操作
package sy2;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import sy1.HADOOP;
public class Merge {
/**
* @param args
* 对 A,B 两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件 C
*/
//重载 map 函数,直接将输入中的 value 复制到输出数据的 key 上
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text text = new Text();
public void map(Object key, Text value, Context context) throws
IOException,InterruptedException{
text = value;
context.write(text, new Text(""));
} }
//重载 reduce 函数,直接将输入中的 key 复制到输出数据的 key 上
public static class Reduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context )
throws IOException,InterruptedException{
context.write(key, new Text(""));
} }
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.default.name",HADOOP.hadoopUrl);
String[] otherArgs = HADOOP.sy2Args1; /* 直接设置输入参数
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge and duplicate removal");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行程序后的结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6BY79kEs-1637591473587)(hadoop大数据.assets\image-20211029121809753.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HZnsZnWP-1637591473588)(hadoop大数据.assets\image-20211029121819169.png)]
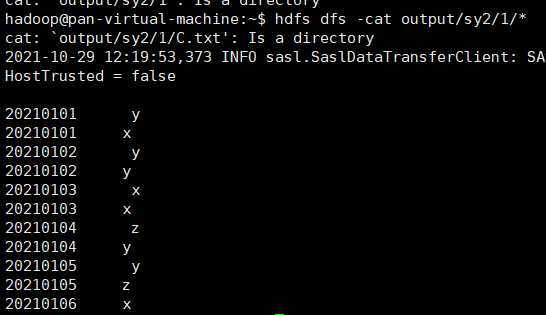
hdfs dfs -cat output/sy2/1/*
输出:
程序2
创建文件并上传

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bRxk7HGu-1637591473591)(hadoop大数据.assets\image-20211029123051977.png)]
//输入文件的排序代码
package sy2;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import sy1.HADOOP;
public class MergeSort {
/**
* @param args
* 输入多个文件,每个文件中的每行内容均为一个整数
* 输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整
数的排序位次,第二个整数为原待排列的整数
*/
//map 函数读取输入中的 value,将其转化成 IntWritable 类型,最后作为输出 key
public static class Map extends Mapper<Object, Text, IntWritable, IntWritable>{
private static IntWritable data = new IntWritable();
public void map(Object key, Text value, Context context) throws
IOException,InterruptedException{
String text = value.toString();
data.set(Integer.parseInt(text));
context.write(data, new IntWritable(1));
}
}
//reduce 函数将 map 输入的 key 复制到输出的 value 上,然后根据输入的 value-list中元素的个数决定 key 的输出次数,定义一个全局变量 line_num 来代表 key 的位次
public static class Reduce extends Reducer<IntWritable, IntWritable,
IntWritable, IntWritable>{
private static IntWritable line_num = new IntWritable(1);
public void reduce(IntWritable key, Iterable<IntWritable> values, Context
context) throws IOException,InterruptedException{
for(IntWritable val : values){
context.write(line_num, key);
line_num = new IntWritable(line_num.get() + 1);
}
}
}
//自定义 Partition 函数,此函数根据输入数据的最大值和 MapReduce 框架中Partition 的数量获取将输入数据按照大小分块的边界,然后根据输入数值和边界的关系返回对应的 Partiton ID
public static class Partition extends Partitioner<IntWritable, IntWritable>{
public int getPartition(IntWritable key, IntWritable value, int num_Partition){
int Maxnumber = 65223;//int 型的最大数值
int bound = Maxnumber/num_Partition+1;
int keynumber = key.get();
for (int i = 0; i<num_Partition; i++){
if(keynumber<bound * (i+1) && keynumber>=bound * i){
return i;
}
}
return -1;
}
}
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.default.name",HADOOP.hadoopUrl);
String[] otherArgs = HADOOP.sy2Args2; /* 直接设置输入参数
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge and sort");
job.setJarByClass(MergeSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setPartitionerClass(Partition.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
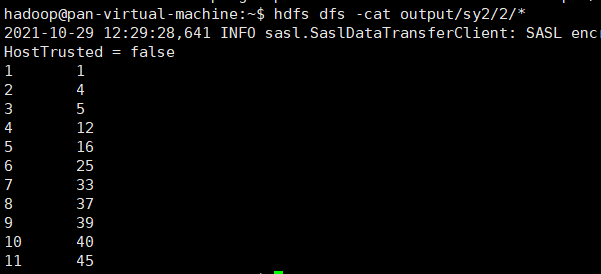
程序执行完成


输出命令:hdfs dfs -cat output/sy2/2/*



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











