







自动化机器学习(AutoML)最近变得越来越火,是机器学习下个发展方向之一。其中的神经网络结构搜索(NAS)是其中重要的技术之一。人工设计网络需要丰富的经验和专业知识,神经网络有众多的超参数,导致其搜索空间巨大。NAS即是在此巨大的搜索空间里自动地找到最优的网络结构,实现深度学习的自动化。自2017年谷歌与MIT各自在ICLR上各自发表基于强化学习的NAS以来,已产出200多篇论文,仅2019年上半年就有100多篇论文。此系列文章将解读AutoDL领域的经典论文与方法,笔者也是刚接触这个领域,有理解错误的地方还请批评指正!
此系列的文章:
本文解读两篇基于强化学习的开创性论文:谷歌的《Neural Architecture Search with Reinforcement Learning》和MIT的《Designing Neural Network Architectures Using Reinforcement Learning》。用到的强化学习方法分别为策略梯度(Policy Gradient)和Q-learning。
一、强化学习相关背景知识
强化学习任务包括量大主体:智能体(Agent)和环境(Environment),智能体通过与环境交互获得奖励,来学习相应的策略。强化学习有三种基本方法:动图规划、蒙特卡洛方法和时序差分方法,如下框图所示:
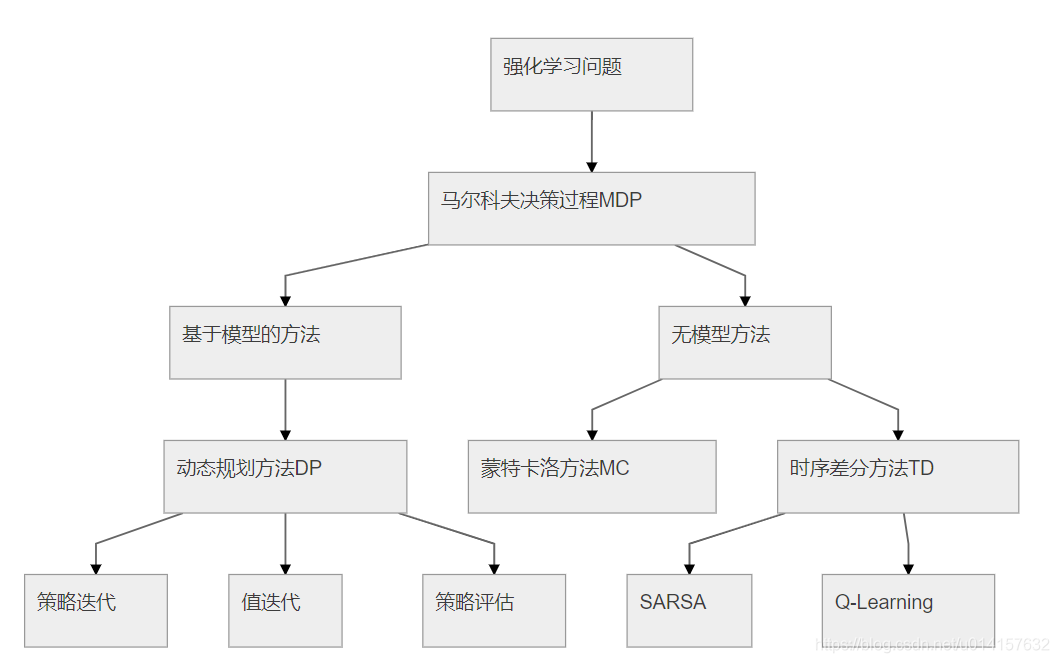
第一篇论文用到的方法是基于策略的策略梯度法,第二篇用到的方法是Q-learning。关于强化学习笔者会在另一篇文章中详细介绍。
二、Neural Architecture Search with Reinforcement Learning
1、总览
这篇论文的大体框架和思路如下图所示。在这篇论文中作者使用一个RNN作为智能体。作者考虑到神经网络的结构和连接可以用一个可变长度的字符串表示,这样可以用RNN生成这样的字符串。RNN采样生成了这样的字符串,一个网络,即子网络(child network)就被确定了。训练这个子网络,得到验证集在这个网络上的准确率,作为奖励信号。然后根据奖励计算策略梯度,更新RNN。在下一轮迭代,RNN会给出可能在验证集上准确率高的一个网络结构。也就是说,RNN会随着时间提升它的搜索质量。
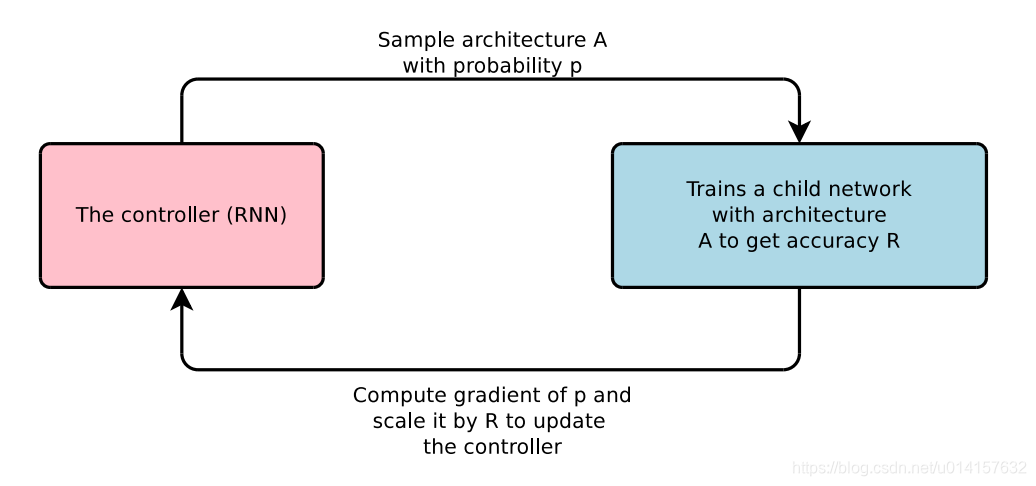
2、控制器RNN的实现
首先作者假设要生成一个前向的只包含卷积的网络(没有跨连接)。使用RNN可以生成卷积层的超参数,超参数表示为一个标记序列:

RNN会预测每一层的滤波器的高度、宽度,步长的高度、宽度,和滤波器个数,一个5个参数。每一个预测是通过softmax分类器实现的,这个时间步的预测会作为下个时间步的输入。当层数达到一个特定的值,这个生成的过程就会停止。这个值会随着训练过程增加。一旦RNN生成了一个结构,即子网络,这个子网络就会被训练,验证集的准确率被记录下来被作为奖励。然后控制器RNN的参数
θ
c
\theta _{c}
θc被更新以生成期望验证集准确率最大的结构。
3、策略梯度
RNN生成一个子网络后,其生成的标记序列可以被看作一系列动作
a
1
:
T
a_{1:T}
a1:T。验证集在其上取得的准确率作为奖励
R
R
R,然后训练RNN。为了找到最优的结构,我们网RNN取最大化期望奖励
J
(
θ
c
)
J(\theta _{c})
J(θc):
J
(
θ
c
)
=
E
P
(
a
1
:
T
;
θ
c
)
[
R
]
J(\theta _{c})=E_{P(a_{1:T};\theta_{c})}[R]
J(θc)=EP(a1:T;θc)[R]
但奖励信号是不可微分的,我们使用策略梯度算法去迭代地更新
J
(
θ
c
)
J(\theta _{c})
J(θc):
∇ θ c J ( θ c ) = ∑ t = 1 T E P ( a 1 : T ; θ c ) [ ∇ θ c log P ( a t ∣ a ( t − 1 ) : 1 ; θ c ) R ] \nabla _{\theta_{c}} J\left(\theta_{c}\right)=\sum_{t=1}^{T} E_{P\left(a_{1 : T} ; \theta_{c}\right)}\left[\nabla \theta_{c} \log P\left(a_{t} | a_{(t-1) : 1} ; \theta_{c}\right) R\right] ∇θcJ(θc)=t=1∑TEP(a1:T;θc)[∇θclogP(at∣a(t−1):1;θc)R]
上式的经验估计如下:
1 m ∑ k = 1 m ∑ t = 1 T ∇ θ c log P ( a t ∣ a ( t − 1 ) : 1 ; θ c ) R k \frac{1}{m} \sum_{k=1}^{m} \sum_{t=1}^{T} \nabla_{\theta_{c}} \log P\left(a_{t} | a_{(t-1) : 1} ; \theta_{c}\right) R_{k} m1k=1∑mt=1∑T∇θclogP(at∣a(t−1):1;θc)Rk
这里 m m m是控制器在训练过程中一个batch生成的子网络数量, T T T是生成的每个子网络的超参数数量, R k R_{k} Rk是第k个子网络在验证集上的准确率。上述的估计是无偏的,还会有很高的方差,为了降低方差,作者使用了baseline function:
1 m ∑ k = 1 m ∑ t = 1 T ∇ θ c log P ( a t ∣ a ( t − 1 ) : 1 ; θ c ) ( R k − b ) \frac{1}{m} \sum_{k=1}^{m} \sum_{t=1}^{T} \nabla_{\theta_{c}} \log P\left(a_{t} | a_{(t-1) : 1 ; \theta_{c}}\right)\left(R_{k}-b\right) m1k=1∑mt=1∑T∇θclogP(at∣a(t−1):1;θc)(Rk−b)
这里 b b b是之前子网络准确率的指数移动平均值。
4、增加网络复杂度:跨连接和其他类型的层
现代网基本都会有跨连接层,比如残差网络和谷歌网络。为了能生成类似这样的网络结构,作者用了基于注意力机制的set-selection。
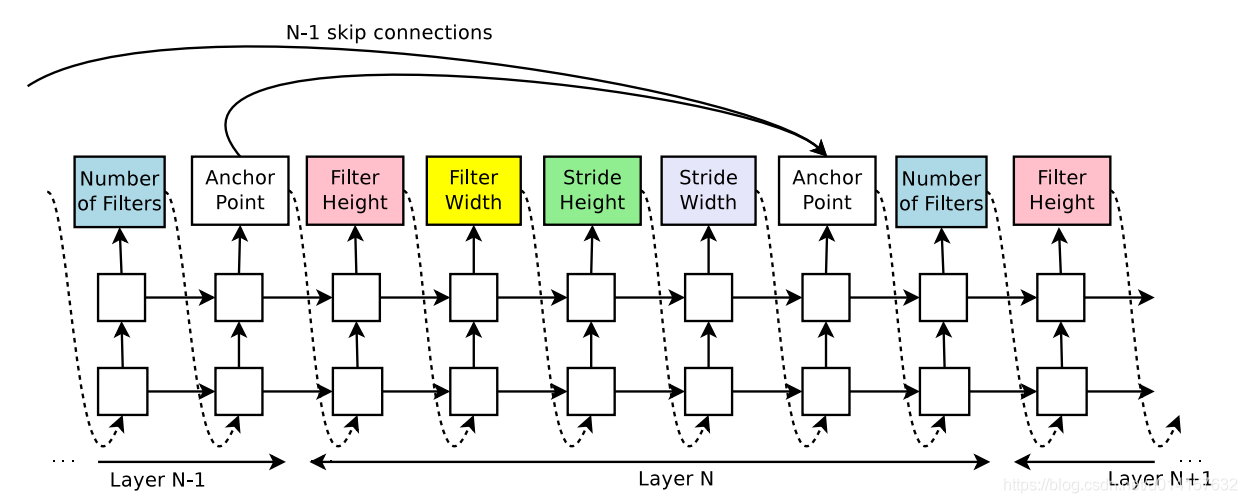
主要做法就是,在RNN的预测上多加一个锚点(anchor point)。比如,在第N层的预测中,锚点会指示连接前N-1层中的哪几个。相当于有N-1个sigmoid函数,每个sigmoid是当前RNN隐藏状态和前N-1个锚点隐藏状态的函数:
P ( Layer j is an input to layer i ) = sigmoid ( v T tanh ( W prev ∗ h j + W curr ∗ h i ) ) \mathrm{P}(\text { Layer } \mathrm{j} \text { is an input to layer i })=\operatorname{sigmoid}\left(v^{\mathrm{T}} \tanh \left(W_{\text {prev}} * h_{j}+W_{\text {curr}} * h_{i}\right)\right) P( Layer j is an input to layer i )=sigmoid(vTtanh(Wprev∗hj+Wcurr∗hi))
h j h_{j} hj是RNN在第 j j j层锚点的隐藏状态, j j j从0到N-1。然后从这些sigmoid中参与决定当前层和前几层中的哪些连接。矩阵 W p r e v , W c u r r , v W_{prev}, W_{curr}, v Wprev,Wcurr,v是可训练的参数。
上面的做法可能会导致“compilation failures”。第一,如果一个层有很多个输入,那么这些输入会在特征图的深度这个维度上被连接,这可能导致各个输入特征图的尺寸不兼容。第二,有些层可能没有输入或输出。作者使用了三个技巧:(1)如果一个层没有输入,那么最一开始的图片作为输入;(2)在最后一层,我们将所有没有被连接的输出都连接起来,然后送入分类器;(3)如果输入特征图的尺寸不一致,,那就填充他们使其有相同的尺寸。
5、生成循环神经网络的cell
作者在这部分给出了生成训练神经网络的方法。对的,NAS不仅可以生成CNN,还可以生成RNN。在每个时间步t,控制器需要找到
h
t
h_{t}
ht关于
h
t
−
1
,
x
t
h_{t-1}, x_{t}
ht−1,xt的函数类型。列入最基本的RNN的cell是
h
t
=
t
a
n
h
(
W
1
∗
x
t
+
W
2
∗
h
t
−
1
)
h_{t}=tanh(W_{1}*x_{t}+W_{2}*h_{t-1})
ht=tanh(W1∗xt+W2∗ht−1)。
RNN和LSTM的cell可以看做以
h
t
−
1
,
x
t
h_{t-1}, x_{t}
ht−1,xt为输入去生成
h
t
h_{t}
ht的一系列步骤的树状结构。控制器需要标记树种每个节点的连接方式(加、对应元素相乘等)和激活函数(tanh,sigmoid等),然后融合两个输入作为输出。然后两个输出再作为下个节点的输入。
对于LSTM,还需要处理记忆状态
c
t
c_{t}
ct和
c
t
−
1
c_{t-1}
ct−1,我们需要控制器预测树中的哪两个节点和这两个记忆状态相连。
以两个节点的树为例,下图展示了其搜索过程:
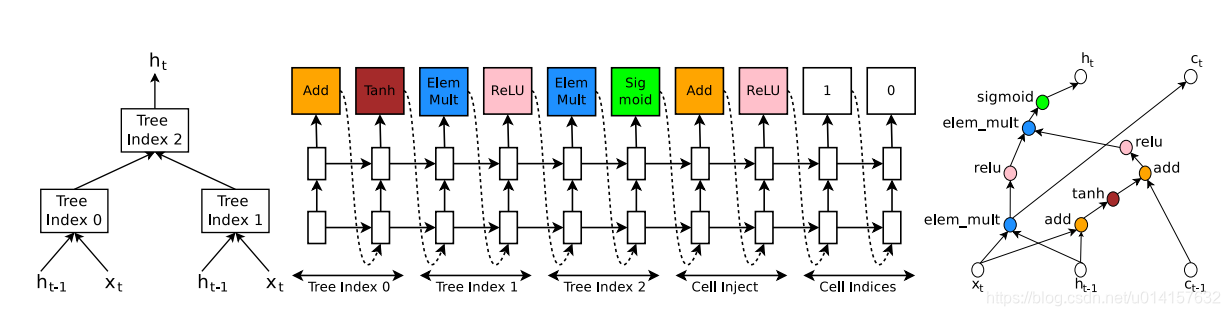
左节点标号为0,右节点标号为1,内节点标号为2。控制器的前三个block预测了每个节点的连接方式和激活函数,后两个block预测了
c
t
c_{t}
ct和
c
t
−
1
c_{t-1}
ct−1如何和树中节点相连。整个计算步骤如下:
- 对于节点0,控制器预测了 A d d Add Add和 t a n h tanh tanh,即: a 0 = t a n h ( W 1 ∗ x t + W 2 ∗ h t − 1 ) a_{0}=tanh(W_{1}*x_{t}+W_{2}*h_{t-1}) a0=tanh(W1∗xt+W2∗ht−1)
- 对于节点1,控制器预测了 E l e m M u l t ElemMult ElemMult和 R e L u ReLu ReLu,即: a 1 = R e L u ( ( W 3 ∗ x t ) ⨀ ( W 4 ∗ h t − 1 ) ) a_{1}=ReLu((W_{3}*x_{t})\bigodot (W_{4}*h_{t-1})) a1=ReLu((W3∗xt)⨀(W4∗ht−1))
- 在cell index这个block里,第二个元素预测了0,表示 c t − 1 c_{t-1} ct−1会连接节点0;cell inject这个block里,预测了 A d d Add Add和 R e L u ReLu ReLu,即节点0的输出会和 c t − 1 c_{t-1} ct−1重新连接: a 0 n e w = R e L u ( a 0 + c t − 1 ) a_{0}^{new}=ReLu(a_{0}+c_{t-1}) a0new=ReLu(a0+ct−1)
- 对于节点2,控制器预测了 E l e m M u l t ElemMult ElemMult和 s i g m o i d sigmoid sigmoid,即 h t = a 2 = s i g m o i d ( a 0 n e w ⨀ a 1 ) h_{t}=a{2}=sigmoid(a_{0}^{new}\bigodot a_{1}) ht=a2=sigmoid(a0new⨀a1)
- 在cell index这个block里,第一个元素预测了1,表示将节点1未经激活函数的输出作为
c
t
c_{t}
ct,即:
c
t
=
(
W
3
∗
x
t
)
⨀
(
W
4
∗
h
t
−
1
)
c_{t}=(W_{3}*x_{t})\bigodot (W_{4}*h_{t-1})
ct=(W3∗xt)⨀(W4∗ht−1)。
上述例子中,树有两个叶子节点,作者在实际的实验中,使用了8个叶子节点。
以上就是此篇论文最核心的方法,有关更多的实验细节和结果可以参看原文。此方法使用强化学习去搜索网络结构,由于每生成一种结构都要训练一遍并评估,而且强化学习需要采样很多很多次,整个搜索会非常耗时。在CIRAR-10数据及上搜索网络,作者用了800块GPU同时训练,可见其有多耗时耗力。NAS的方法如果都这么耗时的话是非常不划算的,如何快速有效地搜索是AutoDL努力的方向之一。
三、Designing Neural Network Architectures Using Reinforcement Learning
在传统的强化学习设置中,过度的探索(exploration)可能会导致收敛变慢,而过度的利用(exploitation)会导致收敛到局部最优。最这篇论文中,作者组合了两种解决方法:带 ϵ \epsilon ϵ贪婪决策和经验回收(experience replay)的Q-learning。
1、Q-learning相关
假定在一个有限状态的环境里,我们教智能体以马尔科夫决策过程(Markov Decision Process, MDP)寻找最优路径。环境是有限状态的这样保证智能体可以在有限步里确切地终止搜索。我们同时限制环境的状态空间 S \mathcal S S和动作空间 U \mathcal U U是离散的和有限的。对于任一状态 s i ∈ S s_{i} \in \mathcal S si∈S,都有有限的动作集合 U ( s i ) ⊆ U \mathcal U(s_{i}) \subseteq \mathcal U U(si)⊆U可以选择。智能体以 p s ′ ∣ s , u ( s j ∣ s i , u ) p_{s^{\prime}|s,u}(s_{j}|s_{i},u) ps′∣s,u(sj∣si,u)的概率,从状态 s i s_{i} si采取某一动作 u ∈ U ( s i ) u \in \mathcal U(s_{i}) u∈U(si)转移到状态 s j s_{j} sj。在每一个时间步t,智能体将得到奖励 r t r_{t} rt。智能体的目标是在所有可能的轨迹上最大化总体期望奖励: m a x T i ∈ T R T i {\rm max}_{\mathcal T_{i} \in \mathcal T}R_{\mathcal T_{i}} maxTi∈TRTi。对于一条轨迹它的总体期望奖励为:
R T i = ∑ ( s , u , s ′ ) ∈ T i E r ∣ s , u , s ′ [ r ∣ s , u , s ′ ] (1) R_{\mathcal{T}_{i}}=\sum_{\left(s, u, s^{\prime}\right) \in \mathcal{T}_{i}} \mathbb{E}_{r | s, u, s^{\prime}}\left[r | s, u, s^{\prime}\right] \tag{1} RTi=(s,u,s′)∈Ti∑Er∣s,u,s′[r∣s,u,s′](1)
对于任一状态 s i ∈ S s_{i} \in \mathcal S si∈S和动作 u ∈ U ( s i ) u \in \mathcal U(s_{i}) u∈U(si),我们定义最大化的期望奖励为 Q ∗ ( s i , u ) Q^{*}(s_{i}, u) Q∗(si,u)。 Q ∗ ( ⋅ ) Q^{*}(\cdot) Q∗(⋅)称为动作值函数, Q ∗ ( s i , u ) Q^{*}(s_{i}, u) Q∗(si,u)的值称为Q-值。用贝尔曼方差递归地最大化这个值:
Q ∗ ( s i , u ) = E s j ∣ s i , u [ E r ∣ s i , u , s j [ r ∣ s i , u , s j ] + γ max u ′ ∈ U ( s j ) Q ∗ ( s j , u ′ ) ] (2) Q^{*}\left(s_{i}, u\right)=\mathbb{E}_{s_{j} | s_{i}, u}\left[\mathbb{E}_{r | s_{i}, u, s_{j}}\left[r | s_{i}, u, s_{j}\right]+\gamma \max _{u^{\prime} \in \mathcal{U}\left(s_{j}\right)} Q^{*}\left(s_{j}, u^{\prime}\right)\right] \tag{2} Q∗(si,u)=Esj∣si,u[Er∣si,u,sj[r∣si,u,sj]+γu′∈U(sj)maxQ∗(sj,u′)](2)
在很多情况下,得到这个方差的解析解是不可能的,我们可以迭代地求解:
Q t + 1 ( s i , u ) = ( 1 − α ) Q t ( s i , u ) + α [ r t + γ max u ′ ∈ U ( s j ) Q t ( s j , u ′ ) ] (3) Q_{t+1}\left(s_{i}, u\right)=(1-\alpha) Q_{t}\left(s_{i}, u\right)+\alpha\left[r_{t}+\gamma \max _{u^{\prime} \in \mathcal{U}\left(s_{j}\right)} Q_{t}\left(s_{j}, u^{\prime}\right)\right] \tag{3} Qt+1(si,u)=(1−α)Qt(si,u)+α[rt+γu′∈U(sj)maxQt(sj,u′)](3)
此方差包括两个参数:(1) α \alpha α是Q-learning rate,决定了新信息相对于旧信息的权重;(2) γ \gamma γ是折扣因子(discount factor),决定了短期奖励相对于长期奖励的权重。Q-learning是免模型的算法,即不需要明确地构建环境的估计。此外Q-learning是off policy的,这意味着它可以通过非最优行为分布来探索最优策略。
我们通过 ϵ \epsilon ϵ贪婪策略选择动作,以 ϵ \epsilon ϵ的概率选择随机动作,以 1 − ϵ 1-\epsilon 1−ϵ的概率选择贪婪动作 m a x u ∈ u ( s i ) Q ( s i , u ) {\rm max}_{u \in {\mathcal u(s_{i})}}Q(s_{i}, u) maxu∈u(si)Q(si,u)。我们慢慢地将 ϵ \epsilon ϵ从1降为0,智能体从探索阶段慢慢变为利用阶段。当探索的代价比较大时,可以使用经验回放来加速收敛。在经验回放里,之前被探索过的路径和奖励被存储下来,智能体在探索的过程中可以利用之前的信息更新Q-值。
2、搜索方法总览
下图展示了一个例子:
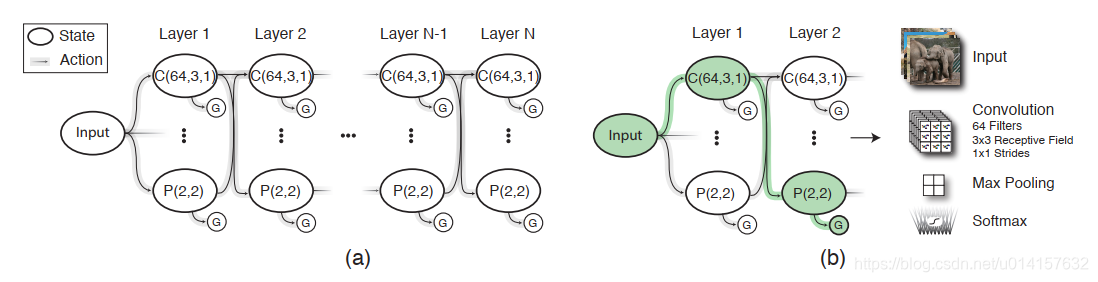
上图中左边显示了可行状态和动作空间,以及agent可能采取的潜在轨迹;右边展示了该轨迹定义的CNN架构。智能体循序地选择神经网络层。选择层的过程是马尔科夫决策过程,假设在一个网络中表现最好的层在另一个网络中应该也是表现最好的。智能体通过
ϵ
\epsilon
ϵ贪婪策略选择层,直到终止条件。训练在此路径下构建的网络,得到验证集上的准确率。验证集准确率和结构描述被存储起来,用于经验回放。智能体遵循着
ϵ
\epsilon
ϵ变化表,从探索阶段过渡到利用阶段。
3、状态空间
每个状态被定义为相关层的所有参数组成的元组,。这里采用五种不同的层:卷积层(C),池化层(P),全连接层(FC),全局平均池化(GAP),和softmax(SM)。下图展示了相关层的参数:
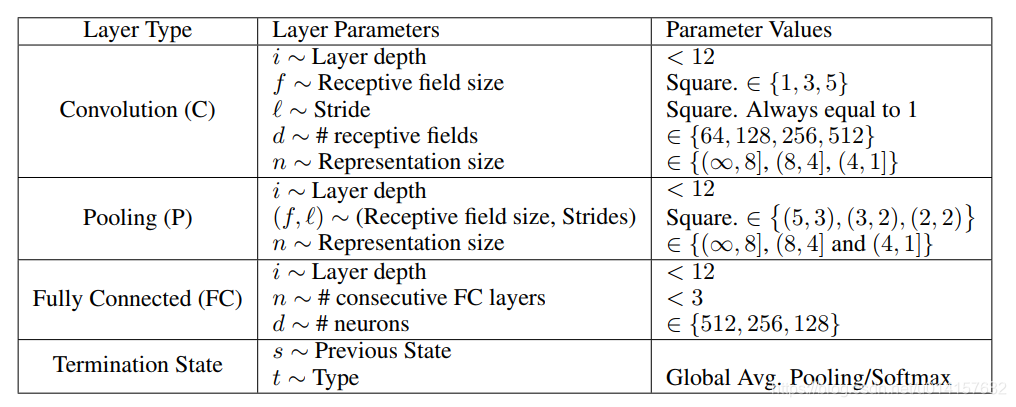
其中每个层有个参数:layer depth层深度。向状态空间添加层深度允许我们压缩操作空间,以便状态操作图是有向无环图(DAG),还允许我们指定智能体在终止之前可以选择的最大层数。每个层还有另一个参数:representations size(R-size)。通过池化和卷积,原始图像被逐渐地压缩尺寸,这可能会导致在采样过程中,特征图被压缩得太小以至于无法继续往下进行。例如五个
2
×
2
2 \times 2
2×2大小步长为2的池化会将
32
×
32
32 \times 32
32×32的图像压缩至
1
×
1
1 \times 1
1×1,使接下来的操作无法进行。使用R-size可以限制一些操作,这些操作使大小为n的特征图变为小于等于n的特征图。在实际构建状态空间时,R-size被分箱成3个桶:
{
(
∞
,
8
]
,
(
8
,
4
]
,
(
4
,
1
]
}
\{(\infty, 8], (8, 4], (4, 1] \}
{(∞,8],(8,4],(4,1]}。这样的分箱操作会增加状态转移的不确定性:根据当前特征图的大小,池化或卷积可能会改变R-size,也可能不会。例如下图:
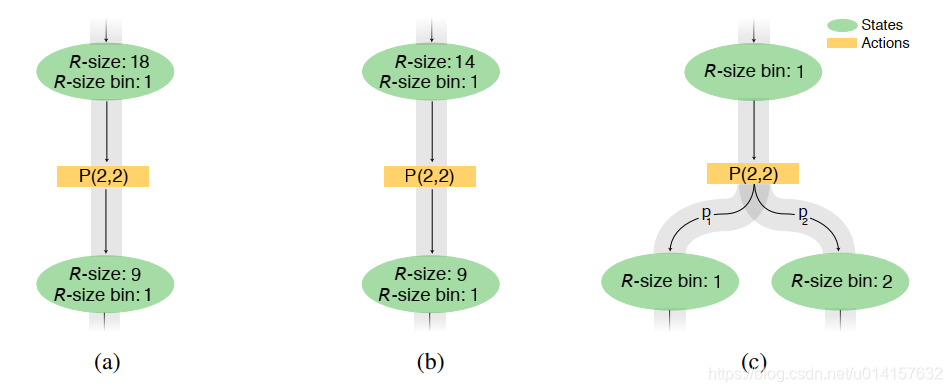
假设有两个R-size bins, R-size Bin1:
[
8
,
∞
)
[8, \infty)
[8,∞)和R-size Bin2:
(
0
,
7
]
(0, 7]
(0,7],图a给出了初始状态为R-size Bin1,真实的表示大小为18的情况。当代理选择使stride为2大小为2×2的池化后,真实的表示大小减小到9,但是R-size bin没有变化。在图b中,stride为2大小为2×2的池层将实际表示大小从14减小到7,但是bin更改为R-size Bin2。因此,在图a和b中,智能体最终处于不同的最终状态,尽管初始状态相同,并且选择了相同的操作。图c显示,在我们的状态-操作空间中,当智能体采取降低表示大小的操作时,它将不确定将转换到哪个状态。
4、动作空间
首先,我们允许智能体在路径上的任一点终止。此外我们只允许从layer depth为
i
i
i的状态转移到layer depth为
i
−
1
i-1
i−1的状态,这样保证是有向无环图。任何达到最大layer depth的层都会转移到终止状态。
接下来,作者将FC层的数量限制为最多两个,因为大量的FC层可能导致太多可学习的参数。当且仅当连续FC状态的数量小于允许的最大值时,位于FC状态的才可以转换到另一个FC类型状态。并且,有
d
d
d个节点的FC只能转移到
d
′
<
d
d^{\prime}<d
d′<d的FC。
然后是一些其他的限制。卷积层可以转移到其他任何类型的层,池化层可以转移到除池化层以外的其他任何层,因为连续的池化相当于一个不在可选状态空间里的大尺寸池化层。只有R-size为(8, 4]和(4, 1]的状态才能转移到FC层,这样保证权重参数不会特别巨大。
5、Q-learning训练过程
在训练部分,作者设置Q-learning rate(
α
\alpha
α)为0.01,折扣因子
γ
\gamma
γ为1。
ϵ
\epsilon
ϵ以一定的步长从1.0逐渐降为0.1,步长由训练的唯一模型的数量决定,如下表所示:

每一条被智能体采样的轨迹,即一个网络结构,被训练,然后得到验证集的准确率,这个网络结构描述和准确率被记录下来。从上表可以看出,在
ϵ
=
1
\epsilon =1
ϵ=1的时候相对于其他值训练了大量的模型,这是为了保证智能体在“利用”之前有充足的机会去“探索”。智能体在
ϵ
=
0.1
\epsilon =0.1
ϵ=0.1的时候终止搜索,以获得随机的最终决策。因为
ϵ
=
0
\epsilon =0
ϵ=0表示确定的决策,而作者希望能获得几个比较好的模型去做集成,所以使
ϵ
=
0.1
\epsilon =0.1
ϵ=0.1以保证最终的决策是随机的。
对于整个训练过程,一个“回放字典”(replay dictionary)被维护,这里存储被采样过的网络及验证集在上面的准确率。如果采样到的模型已经在这个字典里,那这个模型不用背重新训练,其验证集准确率会直接被拿来使用。当每个模型被采样后和训练后,智能体从回放字典里随机采样100个模型,并对每个采样轨迹中的所有转移序列应用到公式3中,转移序列在时间上被倒转,这样做可以加快Q-值的收敛。
6、伪代码

算法1描述了训练的主循环,参数
M
M
M决定了在给定一个
ϵ
\epsilon
ϵ的情况下训练多少个模型,参数
K
K
K表示在每一轮迭代中,从回放字典中采样多少次取更新Q-值。TRAIN 函数表示训练一个确定的模型并返回验证集准确率。

算法2描述了使用
ϵ
\epsilon
ϵ贪婪策略采样新网络的细节。TRANSITION函数在给定一个状态和动作的情况下返回下一步的状态。

算法3描述了公式3的实现细节,折扣因子设为1,对整个状态序列进行时间倒转。
上述所有就是此论文的核心方法,此方法也是非常耗时,对于每个数据集,作者使用10块GPU训练了8-10天。(这篇论文在写作上感觉要比上篇的好,细节清楚)
参考文献
- https://www.automl.org/best-practices-for-scientific-research-on-neural-architecture-search/
- Zoph B , Le Q V . Neural Architecture Search with Reinforcement Learning[J]. 2016.
- Designing Neural Network Architectures using Reinforcement Learning
- https://blog.youkuaiyun.com/u014380165/article/details/78525500
- https://blog.youkuaiyun.com/xjz18298268521/article/details/79078835/
- 《深入理解AutoML和AutoDL》


















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









