







 本文深入解析渐进式神经架构搜索(Progressive Neural Architecture Search)技术,介绍其通过逐步增加网络复杂度来优化神经网络结构的方法。文章详细阐述了搜索空间、渐进式搜索策略及代理模型的应用。
本文深入解析渐进式神经架构搜索(Progressive Neural Architecture Search)技术,介绍其通过逐步增加网络复杂度来优化神经网络结构的方法。文章详细阐述了搜索空间、渐进式搜索策略及代理模型的应用。
自动化机器学习(AutoML)最近变得越来越火,是机器学习下个发展方向之一。其中的神经网络结构搜索(NAS)是其中重要的技术之一。人工设计网络需要丰富的经验和专业知识,神经网络有众多的超参数,导致其搜索空间巨大。NAS即是在此巨大的搜索空间里自动地找到最优的网络结构,实现深度学习的自动化。自2017年谷歌与MIT各自在ICLR上各自发表基于强化学习的NAS以来,已产出200多篇论文,仅2019年上半年就有100多篇论文。此系列文章将解读AutoDL领域的经典论文与方法,笔者也是刚接触这个领域,有理解错误的地方还请批评指正!
此系列的文章:
本篇讲述基于代理模型的渐进式搜索《Progressive Neural Architecture Search》。代理模型就是训练并利用一个计算成本较低的模型去模拟原本计算成本较高的那个模型的预测结果,当需要计算的大模型的数量较多时,可以避开很多计算。
一、Progressive Neural Architecture Search
1、总览
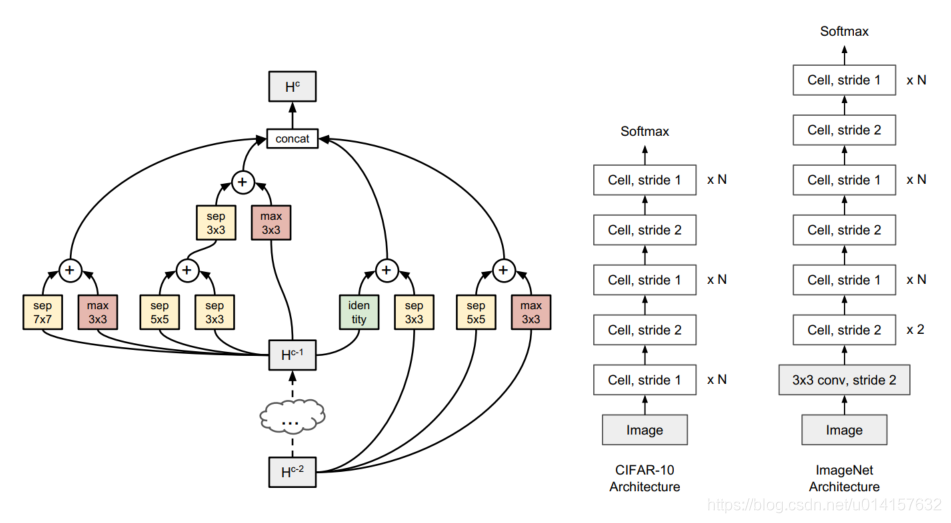
这篇论文也是搜寻卷积cell,每个cell包含B个block,每个block连接两个输入,然后cell堆叠起来组成整个网络,同NASNet(《Learning Transferable Architectures for Scalable Image Recognition》)里的基本一样。不过作者是从简单的浅层的cell开始,逐渐地搜索到复杂的cell,而不是每次预测固定大小的cell。在算法的第b次迭代,有K个候选的cell(每个cell有b个block),这些会被训练和评估。因为这个过程是非常费时的,作者在这里使用代理模型去预测候选cell的效果。将K个包含b个block的候选cell扩展成 K ′ > > K K^{\prime}>>K K′>>K个cell,每个cell有b+1个block。使用代理模型去预测他们的表现,然后选取最高的K个,训练并评估。直到b=B,达到允许的最大block数目。
2、搜索空间
这里作者不再区分normal cell和reduction cell,不过如果步长为2,同样可以实现reduction cell的功能。cell是由B个block组成的,每个block将两个输入组合成一个输出。一个在第
c
c
c个cell里的第
b
b
b个block 可以用一个元组表示
(
I
1
,
I
2
,
O
1
,
O
2
)
(I_{1},I_{2},O_{1},O_{2})
(I1,I2,O1,O2),这里
I
1
,
I
2
∈
I
b
I_{1},I_{2} \in {\mathcal I}_{b}
I1,I2∈Ib表示输入,
O
1
,
O
2
∈
O
b
O_{1},O_{2} \in {\mathcal O}_{b}
O1,O2∈Ob表示作用在输入
I
i
I_{i}
Ii上的操作。对于两个输入的连接方式,NASNet里有相加和沿深度轴连接两种选择,不过作者发现沿深度轴连接在实验中从来没有被选择过,因此这里只将两个输入相加,生成block的输出
H
b
c
H_{b}^{c}
Hbc。可能的输入集合
I
b
\mathcal I_{b}
Ib是这个cell里所有的前驱block的输出
{
H
1
c
,
…
,
H
b
−
1
c
}
\{H_{1}^{c}, \dots, H_{b-1}^{c}\}
{H1c,…,Hb−1c},加上前一个cell的输出
H
B
c
−
1
H_{B}^{c-1}
HBc−1,再加上前前一个cell的输出
H
B
c
−
2
H_{B}^{c-2}
HBc−2。操作空间
O
\mathcal O
O包括以下几种:

令第
b
b
b个block可能的结构空间是
B
b
\mathcal B_{b}
Bb,那么这个空间的大小为
∣
B
b
∣
=
∣
I
b
∣
2
×
∣
O
∣
2
|\mathcal B_{b}|=|\mathcal I_{b}|^{2} \times |\mathcal O|^{2}
∣Bb∣=∣Ib∣2×∣O∣2,
∣
I
b
∣
=
(
2
+
b
−
1
)
|\mathcal I_{b}|=(2+b-1)
∣Ib∣=(2+b−1),
∣
O
∣
=
8
|\mathcal O|=8
∣O∣=8。对于
b
=
1
b=1
b=1,只有
I
1
=
{
H
B
c
−
1
,
H
B
c
−
2
}
\mathcal I_{1}=\{H_{B}^{c-1}, H_{B}^{c-2}\}
I1={HBc−1,HBc−2},所以总共有
∣
B
∣
1
=
4
×
4
×
8
2
=
256
|\mathcal B|_{1}=4 \times 4 \times 8^{2}=256
∣B∣1=4×4×82=256个可能的cell。这里作者令
B
=
5
B=5
B=5,那么一种有
∣
B
1
:
5
∣
=
(
2
2
×
8
2
)
×
(
3
2
×
8
2
)
×
(
4
2
×
8
2
)
×
(
5
2
×
8
2
)
×
(
6
2
×
8
2
)
=
5.6
×
1
0
14
\left|\mathcal{B}_{1: 5}\right|=(2^{2} \times 8^{2}) \times (3^{2} \times 8^{2}) \times (4^{2} \times 8^{2}) \times (5^{2} \times 8^{2} )\times (6^{2} \times 8^{2})=5.6 \times 10^{14}
∣B1:5∣=(22×82)×(32×82)×(42×82)×(52×82)×(62×82)=5.6×1014种可能。但这些可能的cell里有一些对称的结构,例如b=1时只有136个独一无二的cell,那么整个搜索空间大小大概是
1
0
12
10^{12}
1012数量级,比NASNet的
1
0
28
10^{28}
1028小了不少。
下图展示了可能的cell结构和cell的堆叠方式:
3、渐进式搜索
作者从最简单的模型开始,按渐进的方式搜索。首先从只含一个block的cell开始,构造出所有可能的cell空间
B
1
\mathcal B_{1}
B1,将它们放入队列中,并且训练、评估队列中所有的模型。然后扩展其中的每个cell至含有2个block,所有可能的cell空间为
B
2
\mathcal B_{2}
B2,此时所有的候选cell有
∣
B
1
∣
×
∣
B
2
∣
=
256
×
(
(
2
+
1
)
2
×
8
2
)
=
147
,
456
|\mathcal B_{1}| \times |\mathcal B_{2}|=256 \times ((2+1)^{2} \times 8^{2})=147,456
∣B1∣×∣B2∣=256×((2+1)2×82)=147,456种可能。训练和评估这么多种模型是基本不可行的,因此作者使用预测函数(即代理模型)去预测这些模型的表现。之前已经训练评估过一些模型了,那么代理模型就从这些已经评估出来的模型和结果中训练。然后去预测上面147,456种可能的模型,选出K个效果最好的模型,将它们放入队列中,然后重复整个过程,直到cell包含B个block。具体算法如下图所示:

下图展示了一个渐进式搜索的例子:
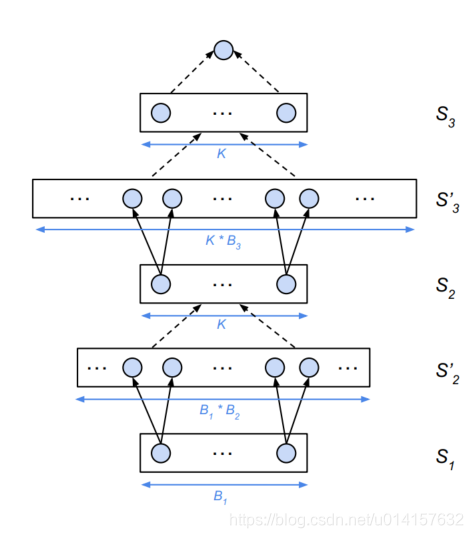
这个例子设cell里最多有B=3个block,
B
b
\mathcal B_{b}
Bb表示有b个block时候选cell的集合。当cell包含一个block时,
S
1
=
B
1
\mathcal S_{1}= \mathcal B_{1}
S1=B1,训练这些并评估这些cell,然后更新代理模型;在第二轮,将
S
1
\mathcal S_{1}
S1里的每个cell扩展到2个block,此时
S
2
′
=
B
1
:
2
\mathcal S_{2}^{\prime}=\mathcal B_{1:2}
S2′=B1:2,预测它们的性能,选择其中最高的
K
K
K个组成
S
2
\mathcal S_{2}
S2,训练并评估它们,然后更新代理模型;在第三轮,将
S
2
\mathcal S_{2}
S2里的每个cell扩展为3个block,得到有3个block的cell的集合的子集
S
3
′
⊆
B
1
:
3
S_{3}^{\prime} \subseteq \mathcal B_{1:3}
S3′⊆B1:3(在第二轮里已经选择了K个最好的cell,已经是子集了,再扩展地话依然是子集),预测它们的性能,选择最好的K个,训练评估它们,最后得到最好的模型。
4、用代理模型预测
我们需要一个代理模型去预测模型的性能,这样的代理模型三友三个特点:(1)能处理可变长度的输入。即使代理模型是在仅包含b个block的cell上训练的,那它也得能预测包含b+1个block的cell的性能;(2)与真实性能呈相关关系。我们并不一定非要获得较低的均方误差,但我们确实希望代理模型预测的性能排序同真实的大致相同;(3)样本效率,我们希望训练和评估尽可能少的cell,这意味着用于代理模型的训练数据将是稀缺的。
作者尝试了两种代理模型:LSTM和MLP。对于LSTM,将长度为 4 b 4b 4b(表示每个block的 I 1 , I 2 , O 1 , O 2 I_{1},I_{2},O_{1},O_{2} I1,I2,O1,O2)的序列作为输入,然后预测验证集准确率,使用L1损失训练模型。作者对 I 1 , I 2 ∈ I I_{1},I_{2} \in \mathcal I I1,I2∈I使用 D D D维的嵌入,对于 O 1 , O 2 ∈ O O_{1},O_{2} \in \mathcal O O1,O2∈O使用另一套嵌入。对于MLP,作者将cell转为固定长度的向量:将每个block的操作嵌入成 D D D维向量,连接block里的操作为 4 D 4D 4D向量,对于cell里所有block的 4 D 4D 4D维向量取平均。对于训练代理模型,因为样本量比较少,作者训练5个模型做集成。
5、实现细节
对MLP代理模型,嵌入向量长度为100,使用两个全连接层,每层有100个神经元。对于LSTM代理模型,隐藏状态长度和嵌入向量长度为100。嵌入向量从[-0.1, 0.1]之间均匀采样初始化。最后全连接层的偏置设为1.8(sigmoid之后为0.68),这是b=1的所有模型的平均准确率。在搜索过程中,每个阶段评估K=256个模型(在第一阶段评估136个),cell最多有B=5个block,第一个卷积cell里有F=24个滤波器,在最终的网络结构里重复N=2次,训练20轮。
参考文献
[1] Liu C , Zoph B , Neumann M , et al. Progressive Neural Architecture Search[J]. 2017.
[2] 《深入理解AutoML和AutoDL》


















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









