




 本文提出使用递归神经网络(RNN)作为控制器,通过强化学习来优化神经网络架构。在CIFAR-10数据集上,这种方法能生成与人类设计相当的网络,而在语言模型任务上,甚至超越了RNN和LSTM。这种方法通过最大化验证集上的精度作为奖励信号,更新控制器策略,从而发现高性能的模型架构。
本文提出使用递归神经网络(RNN)作为控制器,通过强化学习来优化神经网络架构。在CIFAR-10数据集上,这种方法能生成与人类设计相当的网络,而在语言模型任务上,甚至超越了RNN和LSTM。这种方法通过最大化验证集上的精度作为奖励信号,更新控制器策略,从而发现高性能的模型架构。
本文出自论文 NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING,使用一个递归网络来生成神经网络的模型描述。
本文我们使用一个递归网络来生成神经网络的模型描述,并利用强化学习训练RNN,从而最大化在验证集上的生成架构的期望精度。在CIFAR-10数据集上,我们的方法从零开始能够设计一个新的网络架构,使其与人类设计的最好架构在测试集精度上相当。
一、简介
- 本文提出了神经架构搜索,一种基于梯度的方法来寻找好的架构。我们的工作基于对一个神经网络结构和连接性的观察,它可以被一个可变长度的字符串来指定。使用一个递归网络作为控制器来生成如此的字符串具有一定的可能性,在真实数据上训练被字符串指定的网络(子网络)将会导致验证集上的准确性。使用这个准确性作为奖赏信号,我们可以计算策略梯度来更新控制器。最终在下一个迭代过程中,控制器将对接收到高精度的架构更高的概率,随着时间推移控制器将学会改进它的搜索。
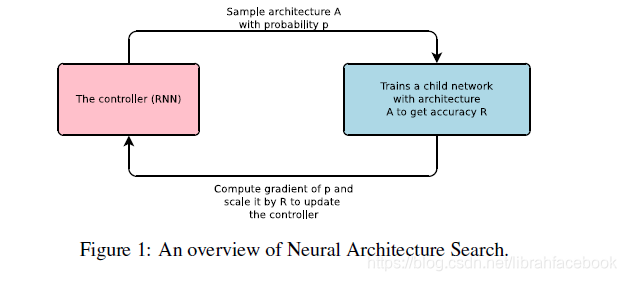
- 我们的实验证明神经架构搜索能够从零开始设计出好的模型,而用其他方法不可能实现出这种效果。在使用CIFAR-10的图像识别任务上,神经架构搜索可以找到一个新的卷积模型,获得良好的效果。在语言模型上,神经架构搜索可以设计出一个新的递归单元,其优于先前的RNN和LSTM架构。
二、相关工作
- 贝叶斯优化方法允许搜索非固定长度的架构,但是这种方法缺乏普遍性和灵活性。现代的神经进化方法对于组成新的模型更加灵活,但是对于大的规模通常缺乏实用性。神经架构搜索的控制器是自回归的,这意味着它一次只能预测一个超参数,且取决于之前的预测。不同于序列到序列的学习,我们的方法优化了一个不可微的度量标准,即子网络的精度,另外我们的方法直接从奖励信号中学习而没有任何监督引导。与该工作相关的想法是使用一个神经网络去学习另一个网络梯度下降更新,和使用强化学习去寻找另一个网络的更新策略的想法。
三、方法
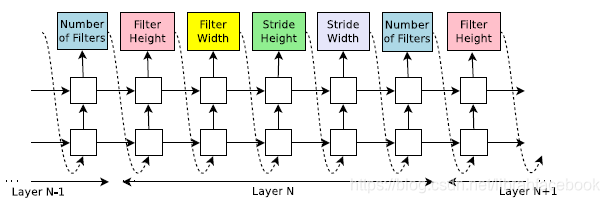
- 使用一个递归神经网络作为控制器来生成模型描述:假设我们想预测只有卷积层的前馈神经网络,我们可以使用控制器来生成它们的超参数来作为令牌序列。一旦控制器RNN结束生成一个架构,一个带着此架构的神经网络被构造好和训练好。在收敛时,在外设的验证集上的网络精度被记录,控制器RNN的参数 θ c \theta_c θc然后被优化,从而最大化所提出架构的期望验证精度。
- 强化训练:控制器预测的令牌列表可以被看作是为一个子网络设计体系架构的动作列表 a 1 : T a_{1:T} a1:T。在收敛阶段,子网络将在数据集上获得一个精度R,我们可以使用R作为奖励信号,然后使用强化学习来训练控制器。为了找到最优的架构,我们要求控制器去最大化它的期待奖励,用公式表达为: J ( θ c ) = E P ( a 1 : T ; θ c ) [ R ] J(\theta_c)=E_{P(a_{1:T};\theta_c)}[R] J(θc)=EP(a1:T;θc)[R]。由于R不可微,我们需要使用一个策略梯度方法去迭代更新参数 θ c \theta_c θ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









