







实验题1:实现希尔排序的算法
题目描述
- 内容:编写一个程序exp10-3.cpp实现希尔排序算法,用相关数据进行测试,并输出各趟的排序结果。
- 算法:exp10-3.cpp程序,采用希尔排序方法在包含函数 ShellList(RecType R[],intn,KeyType k),即采用快速排序方法在R[0,n-1]递增有序中查找关键字为k的记录的位置。
运行代码
Seqlist.cpp
#include <stdio.h>
#include <stdlib.h>
#define MAXL 100
// 定义关键字类型为int
typedef int KeyType;
// 假设其他数据项类型为char,可根据实际需求修改
typedef char InfoType;
// 声明查找顺序表元素类型
typedef struct {
KeyType key;
InfoType data;
} RecType;
// 创建顺序表
void CreateList(RecType R[], KeyType keys[], int n) {
for (int i = 0; i < n; i++) {
R[i].key = keys[i];
}
}
// 输出顺序表
void DispList(RecType R[], int n) {
for (int i = 0; i < n; i++) {
printf("%d ", R[i].key);
}
printf("\n");
}exp10-3.cpp
#include "seqList.cpp"
void ShellSort(RecType R[], int n) {
int i, j, d;
RecType tmp;
d = n / 2;
while (d > 0) {
for (int i = d; i < n; i++) {
tmp = R[i];
j = i - d;
while (j >= 0 && tmp.key < R[j].key) {
R[j + d] = R[j];
j = j - d;
}
R[j + d] = tmp;
}
printf(" d=%d: ", d);
DispList(R, n);
d = d / 2;
}
}
int main() {
int n = 10;
RecType R[MAXL];
KeyType a[] = { 9,8,7,6,5,4,3,2,1,0 };
CreateList(R, a, n);
printf("排序前:");
DispList(R, n);
ShellSort(R, n);
printf("排序后:");
DispList(R, n);
return 1;
}代码思路
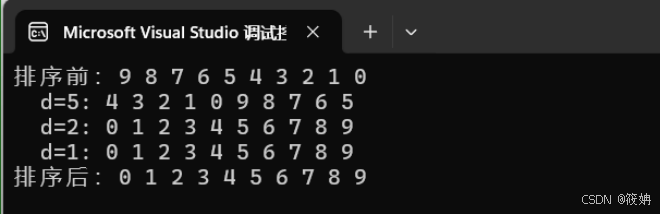
- 实现了一个简单的顺序表数据结构,并在其上应用了希尔排序(Shell Sort)算法对顺序表中的元素进行排序,最后展示排序前后顺序表中元素的情况。
- 数据结构定义部分通过 typedef 定义了 KeyType 为 int 类型,用于表示关键字(通常是用于排序、查找等操作的关键数据部分),InfoType 定义为 char 类型(注释中表明可根据实际需求修改,用于表示其他相关的数据项)。定义了 RecType 结构体,它包含 key(关键字)和 data(其他数据项)两个成员,代表顺序表中的一个元素。
- 希尔排序算法实现(ShellSort 函数):首先初始化了间隔 d 为 n / 2,然后进入外层 while 循环,只要 d 大于 0,就持续进行排序过程。在内层 for 循环中,从间隔位置 d 开始遍历顺序表,对于每个位置 i,先将 R[i] 暂存到 tmp 变量中,然后通过内层 while 循环,按照间隔 d 往前比较和移动元素,如果 tmp.key 小于当前比较位置 j 的元素的 key 值,就将 R[j] 后移 d 个位置(即 R[j + d] = R[j]),并更新 j 的值继续往前比较,直到找到合适的插入位置(即 j 不满足条件时),再将暂存的元素 tmp 插入到该位置(R[j + d] = tmp)。在每次间隔调整前,还输出了当前间隔 d 以及对应的顺序表元素情况,方便观察排序过程中的中间状态。
- 虽然代码中没有显式地进行动态内存分配(如 malloc、free 等操作),但定义的顺序表数组 R 是基于固定大小 MAXL 的静态数组。如果实际应用中需要处理的数据量可能超过这个固定大小,就需要考虑改为动态内存分配的方式来管理顺序表的存储空间,避免出现数组越界等问题。
- 数据完整性问题在 CreateList 函数里只对 key 成员进行了赋值,对于 data 成员未做处理,如果在实际情况中 data 承载了重要信息,需要补充相应的赋值逻辑,保证数据的完整性,否则可能导致后续使用 data 时出现未初始化的错误情况。
- 排序算法的稳定性和效率验证:稳定性:希尔排序本身是一种不稳定的排序算法,但在某些特定应用场景可能需要稳定的排序结果,这时就需要考虑是否要更换排序算法或者对希尔排序进行适当改进(不过通常改进希尔排序实现稳定较为复杂)。效率验证:可以通过改变输入数据的规模(如增大 n 的值)、不同的数据分布情况(有序、逆序、随机等)来测试希尔排序算法的时间复杂度表现,对比理论上的时间复杂度情况,观察代码实际的性能是否符合预期,以便在必要时对算法进行优化。
- 代码的可维护性和扩展性:当前代码功能相对简单,如果后续要添加更多对顺序表的操作(如插入、删除特定元素等)或者支持不同类型的 KeyType 和 InfoType(比如改为 float 等其他类型),代码的结构可能需要进一步调整优化,比如将一些操作封装成更独立、通用的函数,遵循良好的代码设计原则来提高可维护性和扩展性。
实验题2:实现快速排序的算法
题目描述
内容:编写一个程序 exp10-5.cpp,实现快速排序算法,用相关数据进行测试,并输出各次划分的排序结果。
2.算法:exp10-5.cpp程序,其中包含如下函数:
·disppart(RecType R[],ints,int t):显示 R[s..t]划分后的结果。
partition(RecType R[],ints,int t):对 R[s..]元素进行一趟划分(以该区间中第一个元素为基准)。
·QuickSort(RecType R[],int s,intt):对 R[s..]的元素进行递增快速排序。
运行代码
#include "seqlist.cpp"
// 划分函数,用于快速排序中对区间进行划分
int partition(RecType R[], int s, int t) {
int i = s, j = t;
RecType tmp = R[s]; // 这里以区间第一个元素作为基准值,修改为R[s]更合理
while (i < j) {
// 从右往左找第一个小于基准值的元素
while (j > i && R[j].key >= tmp.key) {
j--;
}
if (j > i) {
R[i] = R[j];
i++;
}
// 从左往右找第一个大于基准值的元素
while (i < j && R[i].key <= tmp.key) {
i++;
}
if (i < j) {
R[j] = R[i];
j--;
}
}
R[i] = tmp;
return i;
}
// 用于展示每次划分后的区间情况
void Disppart(RecType R[], int s, int t) {
static int i = 1;
printf("第%d次划分:", i);
for (int j = 0; j < s; j++) {
printf(" "); // 适当增加空格,让输出更美观
}
for (int j = s; j <= t; j++) {
printf(" %3d", R[j].key);
}
printf("\n");
i++;
}
// 快速排序函数主体
void QuickSort(RecType R[], int s, int t) {
if (s < t) {
int i = partition(R, s, t);
Disppart(R, s, t); // 展示本次划分后的区间情况
QuickSort(R, s, i - 1);
QuickSort(R, i + 1, t);
}
}
int main() {
int n = 10;
RecType R[MAXL];
KeyType a[] = { 6, 7, 8, 9, 0, 1, 2, 3, 4, 5 };
CreateList(R, a, n);
printf("排序前:");
DispList(R, n);
QuickSort(R, 0, n - 1); // 快速排序时传入正确的起始和结束下标
printf("排序后:");
DispList(R, n);
return 1;
}代码思路
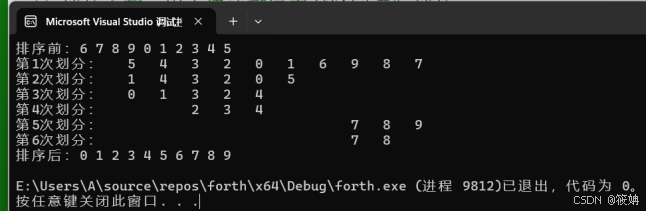
- partition函数:这是快速排序的核心函数之一,用于对给定区间[s, t]进行划分。它选择区间的第一个元素作为基准值,通过双指针法将区间内的元素重新排列,使得左边的元素都小于等于基准值,右边的元素都大于等于基准值,并返回基准值最终的位置。初始化i = s和j = t,并将基准值tmp设为R[s]。通过两个嵌套的while循环实现双指针移动。外层while循环保证i < j,内层第一个while循环从右往左找第一个小于基准值的元素,找到后如果j > i,则将R[j]赋值给R[i]并i++。内层第二个while循环从左往右找第一个大于基准值的元素,找到后如果i < j,则将R[i]赋值给R[j]并j--。最后将基准值tmp放到正确的位置R[i],并返回i 。
- Disppart函数:用于展示每次划分后的区间情况,通过缩进和格式化输出,使每次划分的结果直观地显示出来。使用静态变量i记录划分的次数,每次调用函数时输出 “第i次划分:”。通过循环输出空格来实现缩进,然后输出区间[s, t]内元素的值,并换行。每次调用后i自增。
- QuickSort函数:实现快速排序算法的主体逻辑。它递归地对划分后的子区间进行排序,直到区间长度小于等于 1。首先判断如果s < t,则调用partition函数对区间[s, t]进行划分,得到基准值的位置i。然后调用Disppart函数展示本次划分后的区间情况。接着递归地对左子区间[s, i - 1]和右子区间[i + 1, t]调用QuickSort函数进行排序。
- 排序算法性能问题:快速排序在最坏情况下(例如数据已经有序或逆序)的时间复杂度会退化为 O (n²)。在实验中,可以通过不同的数据分布(有序、逆序、随机等)来测试算法性能,观察是否存在性能退化的情况。如果需要,可以考虑采用随机化选择基准值等优化策略来改善最坏情况性能。
- 静态变量的影响:Disppart函数中的静态变量i用于记录划分次数。在多次调用QuickSort函数进行不同数据排序时,i的值会持续增加。如果希望每次对新数据排序时i都从 1 开始,需要对i进行重置处理,或者考虑将i作为参数传递给Disppart函数,使其不依赖于静态变量。
实验题3:实现堆排序的算法
题目描述
1.内容:编写程序exp10-7.cpp,采用堆排序方法,用相关数据进行测试,并输出各趟的排序结果。
2.算法:exp10-7.cpp程序包含下列函数:。
· DispHeap(RecType R[],int i,int n):以括号表示法输出建立的堆R[1 .. n]
·Sift(RecType R[],int low,int high):对R[low .. high」进行堆筛选的算法。
· HeapSort(RecType R[],int n):对R[1 .. n]元素序列实现堆排序。
运行代码
格式有点问题
#include "seqlist.cpp"
int count = 1;
// 以括号表示法输出建立的堆
void DispHeap(RecType R[], int i, int n) {
if (i <= n) {
printf("%d", R[i].key);
if (2 * i <= n || 2 * i + 1 < n) {
printf("(");
if (2 * i <= n) {
DispHeap(R, 2 * i, n);
}
printf(",");
if (2 * i + 1 <= n) {
DispHeap(R, 2 * i + 1, n);
}
printf(")");
}
}
}
// R[low..high]堆筛选算法
void Sift(RecType R[], int low, int high) {
int i = low, j = 2 * i;
RecType temp = R[i];
while (j <= high) {
// 若右孩子较大,则把j指向右孩子
if (j < high && R[j].key < R[j + 1].key) {
j++;
}
if (temp.key < R[j].key) {
R[i] = R[j];
i = j;
j = 2 * i;
}
else {
break;
}
}
R[i] = temp;
}
// 堆排序函数
void HeapSort(RecType R[], int n) {
int i,j;
// 循环建立初始堆
for (i = n / 2; i >= 1; i--) {
Sift(R, i, n);
}
printf("初始堆 ");
DispHeap(R, 1, n);
printf("\n");
// 进行n - 1次循环,完成堆排序
for (i = n; i >= 2; i--) {
printf("第%d趟排序:", count++);
printf("交换%d与%d,输出%d", R[i].key, R[1].key, R[1].key);
// 将第一个元素和当前区间内的R[1]交换
RecType tmp = R[1];
R[1] = R[i];
R[i] = tmp;
printf("排序结果:");
for (int j = 1; j <= n; j++) {
printf("%2d", R[j].key); // 修正此处,将R[i].key改为R[j].key,正确输出排序结果
}
// 筛选R[1]结点,得到i - 1个结点的堆
Sift(R, 1, i - 1);
printf("筛选调整得到堆:");
DispHeap(R, 1, i - 1);
printf("\n");
}
}
int main() {
int n = 10;
RecType R[MAXL];
KeyType a[] = { 6, 8, 7, 9, 0, 1, 3, 2, 4, 5 };
CreateList(R, a, n);
printf("排序前: ");
DispList(R, n);
HeapSort(R, n);
printf("排序后: ");
DispList(R, n);
return 1;
}正确代码
//顺序表基本运算算法
#include <stdio.h>
#define MAXL 100 //最大长度
typedef int KeyType; //定义关键字类型为int
typedef char InfoType;
typedef struct
{
KeyType key; //关键字项
InfoType data; //其他数据项,类型为InfoType
} RecType; //查找元素的类型
void swap(RecType& x, RecType& y) //x和y交换
{
RecType tmp = x;
x = y; y = tmp;
}
void CreateList(RecType R[], KeyType keys[], int n) //创建顺序表
{
for (int i = 0; i < n; i++) //R[0..n-1]存放排序记录
R[i].key = keys[i];
}
void DispList(RecType R[], int n) //输出顺序表
{
for (int i = 0; i < n; i++)
printf("%d ", R[i].key);
printf("\n");
}
//----以下运算针对堆排序的程序
void CreateList1(RecType R[], KeyType keys[], int n) //创建顺序表
{
for (int i = 1; i <= n; i++) //R[1..n]存放排序记录
R[i].key = keys[i - 1];
}
void DispList1(RecType R[], int n) //输出顺序表
{
for (int i = 1; i <= n; i++)
printf("%d ", R[i].key);
printf("\n");
}#include "seqlist.cpp" //包含排序顺序表的基本运算算法
int count = 1; //全局变量
void DispHeap(RecType R[], int i, int n) //以括号表示法输出建立的堆
{
if (i <= n)
printf("%d", R[i].key); //输出根节点
if (2 * i <= n || 2 * i + 1 < n)
{
printf("(");
if (2 * i <= n)
DispHeap(R, 2 * i, n); //递归调用输出左子树
printf(",");
if (2 * i + 1 <= n)
DispHeap(R, 2 * i + 1, n); //递归调用输出右子树
printf(")");
}
}
void Sift(RecType R[], int low, int high) //R[loww..high}堆筛选算法
{
int i = low, j = 2 * i; //R[j]是R[i]的左孩子
RecType temp = R[i];
while (j <= high)
{
if (j < high && R[j].key < R[j + 1].key) //若右孩子较大,把j指向右孩子
j++; //变为2i+1
if (temp.key < R[j].key)
{
R[i] = R[j]; //将R[j]调整到双亲节点位置上
i = j; //修改i和j值,以便继续向下筛选
j = 2 * i;
}
else break; //筛选结束
}
R[i] = temp; //被筛选节点的值放入最终位置
}
void HeapSort(RecType R[], int n) //对R[1]到R[n]元素实现堆排序
{
int i, j;
for (i = n / 2; i >= 1; i--) //循环建立初始堆
Sift(R, i, n);
printf("初始堆:"); DispHeap(R, 1, n); printf("\n"); //输出初始堆
for (i = n; i >= 2; i--) //进行n-1次循环,完成推排序
{
printf("第%d趟排序:", count++);
printf(" 交换%d与%d,输出%d ", R[i].key, R[1].key, R[1].key);
swap(R[1], R[i]); //将第一个元素同当前区间内R[1]对换
printf(" 排序结果:"); //输出每一趟的排序结果
for (j = 1; j <= n; j++)
printf("%2d", R[j].key);
printf("\n");
Sift(R, 1, i - 1); //筛选R[1]节点,得到i-1个节点的堆
printf("筛选调整得到堆:"); DispHeap(R, 1, i - 1); printf("\n");
}
}
int main()
{
int n = 10;
RecType R[MAXL];
KeyType a[] = { 6,8,7,9,0,1,3,2,4,5 };
CreateList1(R, a, n);
printf("排序前:"); DispList1(R, n);
HeapSort(R, n);
printf("排序后:"); DispList1(R, n);
return 1;
}
12-05 10:34:54
//顺序表基本运算算法
#include <stdio.h>
#define MAXL 100 //最大长度
typedef int KeyType; //定义关键字类型为int
typedef char InfoType;
typedef struct
{
KeyType key; //关键字项
InfoType data; //其他数据项,类型为InfoType
} RecType; //查找元素的类型
void swap(RecType& x, RecType& y) //x和y交换
{
RecType tmp = x;
x = y; y = tmp;
}
void CreateList(RecType R[], KeyType keys[], int n) //创建顺序表
{
for (int i = 0; i < n; i++) //R[0..n-1]存放排序记录
R[i].key = keys[i];
}
void DispList(RecType R[], int n) //输出顺序表
{
for (int i = 0; i < n; i++)
printf("%d ", R[i].key);
printf("\n");
}
//----以下运算针对堆排序的程序
void CreateList1(RecType R[], KeyType keys[], int n) //创建顺序表
{
for (int i = 1; i <= n; i++) //R[1..n]存放排序记录
R[i].key = keys[i - 1];
}
void DispList1(RecType R[], int n) //输出顺序表
{
for (int i = 1; i <= n; i++)
printf("%d ", R[i].key);
printf("\n");
}代码思路
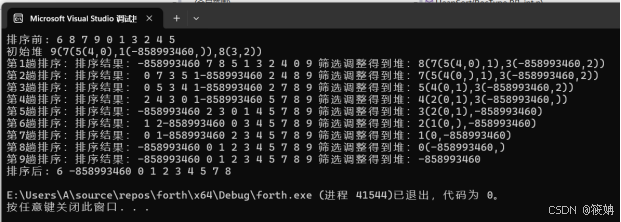
不知道为什么这个代码输出的结果和预期中的结果,发现有一个数据的读取报错然后不对,然后对代码进行进一步改进如下:

- DispHeap函数:以括号表示法递归地输出建立的堆结构。如果当前节点i小于等于堆的大小n,则先输出当前节点的key值,然后判断是否有左右子节点,如果有则输出左括号,递归调用DispHeap输出左子树,输出逗号,递归调用DispHeap输出右子树,最后输出右括号。
- Sift函数:实现堆筛选算法,用于维护堆的性质(大顶堆)。首先记录当前节点i及其左子节点j(j = 2 * i),并将当前节点的值暂存到temp中。然后进入循环,只要j小于等于堆的上界high,就进行以下操作:如果j小于high且右子节点的key值大于左子节点的key值,则将j指向右子节点。如果temp的key值小于R[j]的key值,则将R[i]赋值为R[j],更新i和j的值(i = j,j = 2 * i),继续循环。否则,跳出循环。最后将暂存的值temp赋值给R[i],完成筛选操作。
- 堆排序函数HeapSort:实现堆排序算法。首先通过循环(for (i = n / 2; i >= 1; i--))调用Sift函数来建立初始堆。然后输出初始堆的结构(通过DispHeap函数)。接着进行n - 1次循环,每次循环:交换R[1]和R[i](RecType tmp = R[1]; R[1] = R[i]; R[i] = tmp;),将当前最大元素放到数组末输出当前趟数的排序信息(printf("第%d趟排序:", n - i + 1);)和排序结果(通过DispList函数的逻辑)。调用Sift函数对新的R[1]进行堆调整,保持R[1]到R[i - 1]是一个堆,并输出调整后的堆结构(通过DispHeap函数)。
- 数组下标问题:代码中的数组下标从 1 开始(在HeapSort、Sift和DispHeap等函数中都有体现),与 C 语言中数组下标通常从 0 开始的习惯不同。这种下标方式可能会导致理解和调试代码时容易出现混淆,需要特别注意。
- 数据完整性问题:在CreateList函数中,只对R数组元素的key成员进行了赋值,而data成员未被处理。如果在实际应用中data成员有意义,需要补充相应的赋值逻辑,以保证数据的完整性。
- 内存管理问题:虽然代码中没有显式地进行动态内存分配,但定义的顺序表R是基于固定大小MAXL的静态数组。如果处理的数据量可能超过这个固定大小,需要考虑改为动态内存分配的方式来管理顺序表的存储空间,避免数组越界等问题。
- 排序算法性能验证问题:可以通过改变输入数据的规模(增大n的值)、不同的数据分布情况(有序、逆序、随机等)来测试堆排序算法的时间复杂度表现,对比理论上的时间复杂度情况,观察代码实际的性能是否符合预期,以便在必要时对算法进行优化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











