







P5741 【深基7.例10】旗鼓相当的对手 - 加强版
题目描述

运行代码
使用数组与结构体
#include<bits/stdc++.h>
using namespace std;
#define N 1005
struct node{
char ch[10];
int chinese, math, english, s;
}a[N];
int main(){
int n;
cin >> n;
for(int i=1; i<=n; ++i){
cin >> a[i].ch >> a[i].chinese >> a[i].math >> a[i].english;
a[i].s = a[i].chinese + a[i].math + a[i].english;
}
for(int i=1; i<=n; ++i){
for(int j=i+1; j<=n; ++j){
if(abs(a[i].chinese - a[j].chinese) <= 5 && abs(a[i].math - a[j].math) <= 5 && abs(a[i].english - a[j].english) <= 5 && abs(a[i].s - a[j].s) <= 10){
if(strcmp(a[i].ch , a[j].ch) > 0)
cout << a[j].ch << " " << a[i].ch << endl;
else
cout << a[i].ch << " " << a[j].ch << endl;
}
}
}
return 0;
}
使用向量以及字符串
- 使用
string类型来存储学生姓名,相比字符数组更方便操作,不需要担心数组越界等问题。 - 使用
vector来动态管理学生信息数组,避免了像原代码中预先定义固定大小数组可能导致的空间浪费或不够用的情况。
#include<bits/stdc++.h>
using namespace std;
#define N 1005
// 定义结构体表示学生信息
struct Student {
string name;
int chinese, math, english, totalScore;
};
int main() {
int n;
cin >> n;
// 创建学生信息数组
vector<Student> students(n);
// 输入学生信息并计算总分
for (int i = 0; i < n; ++i) {
cin >> students[i].name >> students[i].chinese >> students[i].math >> students[i].english;
students[i].totalScore = students[i].chinese + students[i].math + students[i].english;
}
// 两层循环遍历学生数组,比较符合条件的学生并输出
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (abs(students[i].chinese - students[j].chinese) <= 5 &&
abs(students[i].math - students[j].math) <= 5 &&
abs(students[i].english - students[j].english) <= 5 &&
abs(students[i].totalScore - students[j].totalScore) <= 10) {
if (students[i].name > students[j].name)
cout << students[j].name << " " << students[i].name << endl;
else
cout << students[i].name << " " << students[j].name << endl;
}
}
}
return 0;
}代码思路
- 输入学生信息:
- 首先通过
cin读取学生的数量n。 - 然后使用循环遍历,依次读取每个学生的姓名、语文成绩、数学成绩和英语成绩,并计算出每个学生三门成绩的总分。
- 首先通过
- 比较学生信息:
- 通过两层嵌套的循环来遍历所有学生的组合。外层循环控制第一个学生的索引
i,内层循环控制第二个学生的索引j,且j从i + 1开始,这样可以避免重复比较(比如已经比较过i = 1和j = 2的情况,就不需要再比较i = 2和j = 1了)。 - 对于每一对学生
i和j,判断他们的语文成绩、数学成绩、英语成绩的差值绝对值是否都小于等于5,并且总分的差值绝对值是否小于等于10。如果满足这些条件,说明这两个学生的成绩较为接近。 - 当满足成绩接近的条件后,再比较这两个学生的姓名。如果学生
i的姓名字典序大于学生j的姓名字典序(通过>运算符比较string类型),就先输出学生j的姓名,再输出学生i的姓名;否则先输出学生i的姓名,再输出学生j的姓名。
- 通过两层嵌套的循环来遍历所有学生的组合。外层循环控制第一个学生的索引
总体来说,这段代码的目的是根据输入的学生成绩信息,找出成绩较为接近的学生对,并按照姓名字典序的顺序输出这些学生对的姓名。
P1048 [NOIP2005 普及组] 采药
题目描述
[NOIP2005 普及组] 采药 - 洛谷

运行代码
#include<iostream>
#include<algorithm>
using namespace std;
const int MAXN = 1009;
int dp[MAXN][MAXN];
int main() {
int t, m;
int time[MAXN], worth[MAXN];
cin >> t >> m;
for (int i = 1; i <= m; ++i) {
cin >> time[i] >> worth[i];
}
// 初始化dp数组第一行
for (int j = 0; j <= t; ++j) {
if (j >= time[1]) {
dp[1][j] = worth[1];
}
}
// 动态规划计算dp数组其他行
for (int i = 2; i <= m; ++i) {
for (int j = 0; j <= t; ++j) {
if (j < time[i]) {
dp[i][j] = dp[i - 1][j];
} else {
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - time[i]] + worth[i]);
}
}
}
cout << dp[m][t];
return 0;
}代码思路
这段代码解决的是一个背包问题,具体来说是一个 0/1 背包问题的变体。给定一个总时间 t 和 m 个物品,每个物品有对应的花费时间 time[i] 和价值 worth[i],要求在总时间限制内选择物品,使得所选物品的总价值最大。
-
数据读取与初始化:
- 首先通过
cin读取总时间t和物品的数量m。 - 然后使用循环依次读取每个物品的花费时间
time[i]和价值worth[i],并将这些数据存储到相应的数组中。 - 对于
dp数组,它是用于记录中间状态的二维数组。其中dp[i][j]表示在前i个物品中,在总时间限制为j的情况下能获得的最大价值。在初始化阶段,我们先单独处理了dp数组的第一行(即只考虑第一个物品时的情况),如果总时间j大于等于第一个物品的花费时间time[1],那么dp[1][j]就等于第一个物品的价值worth[1],否则为0(因为时间不够选这个物品,价值就是0)。
- 首先通过
-
动态规划计算过程:
- 接下来通过两层嵌套的循环来填充
dp数组的其他部分。外层循环变量i从2开始,表示考虑第i个物品(因为第一行已经单独初始化了),一直到m(所有物品都考虑完)。内层循环变量j从0开始,表示总时间限制,一直到t(给定的总时间)。 - 在每次循环中,对于
dp[i][j]的计算,需要判断当前总时间j是否小于第i个物品的花费时间time[i]:- 如果
j < time[i],这意味着在总时间限制为j的情况下,无法选择第i个物品,所以dp[i][j]的值就等于不考虑第i个物品时(即前i - 1个物品)在总时间限制为j的情况下能获得的最大价值,也就是dp[i - 1][j]。 - 如果
j >= time[i],此时有两种选择:一是不选择第i个物品,那么最大价值就是前i - 1个物品在总时间限制为j的情况下能获得的最大价值,即dp[i - 1][j];二是选择第i个物品,那么此时总时间就剩下j - time[i],所以要加上第i个物品的价值worth[i],即dp[i - 1][j - time[i]] + worth[i]。我们需要取这两种情况中的最大值作为dp[i][j]的值,所以通过max函数来实现,即dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - time[i]] + worth[i])。
- 如果
- 接下来通过两层嵌套的循环来填充
-
结果输出:最后,当
dp数组全部填充完成后,dp[m][t]就表示在考虑了所有m个物品,总时间限制为t的情况下能获得的最大价值,将其输出即可。
综上所述,通过动态规划的方法,逐步填充 dp 数组,记录下不同物品选择情况下的最大价值,最终得到在给定条件下的最优解(即最大总价值)。
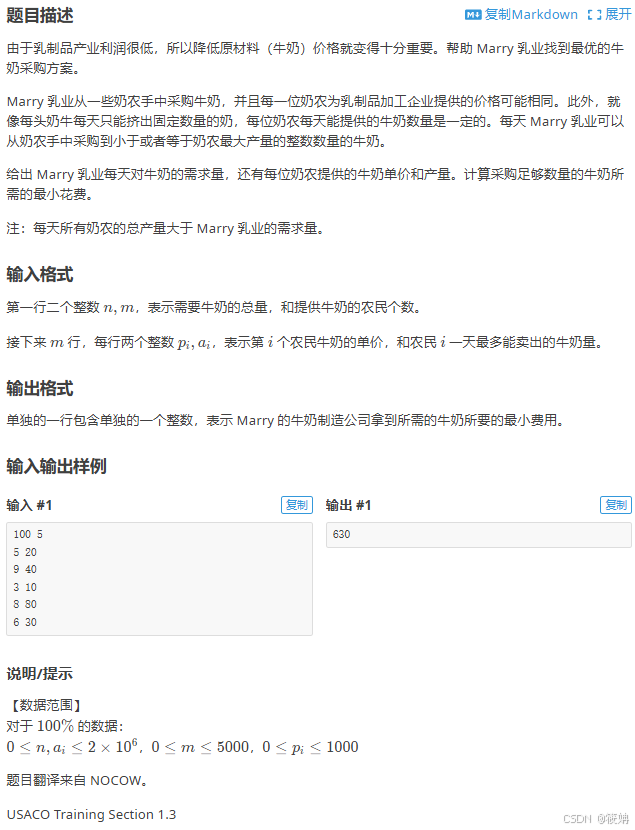
P1208 [USACO1.3] 混合牛奶 Mixing Milk
题目描述
[USACO1.3] 混合牛奶 Mixing Milk - 洛谷
运行代码
使用结构体
#include <bits/stdc++.h>
using namespace std;
const int maxn = 2e5 + 10;
struct milk {
int p, s;
} a[maxn];
int cmp(milk x1, milk x2) {
if (x1.p != x2.p)
return x1.p < x2.p;
else {
return x1.s > x2.s;
}
}
int main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= m; i++) {
cin >> a[i].p >> a[i].s;
}
sort(a + 1, a + 1 + m, cmp);
int sum = 0;
for (int i = 1; i <= m; i++) {
if (n - a[i].s >= 0) {
n -= a[i].s;
sum += a[i].p * a[i].s;
} else {
sum += a[i].p * n;
break;
}
}
cout << sum << endl;
return 0;
}
使用数组
- 使用
vector来存储牛奶的信息,相比于数组更加灵活,不需要预先指定固定的最大长度,避免了可能出现的数组越界问题以及内存浪费(如果实际数据量小于预设的maxn)。 - 将结构体成员变量名改为更具可读性的
price(价格)和supply(供应量)。 - 比较函数
compare的参数改为按值传递,这在大多数情况下是更合适的做法,并且函数体内部逻辑更加清晰,直接返回比较结果。
#include<bits/stdc++.h>
using namespace std;
const int maxn = 2e5 + 10;
// 定义结构体表示牛奶信息
struct Milk {
int price;
int supply;
};
// 比较函数,用于排序
bool compare(Milk x1, Milk x2) {
if (x1.price!= x2.price)
return x1.price < x2.price;
return x1.supply > x2.supply;
}
int main() {
int n, m;
cin >> n >> m;
vector<Milk> milks(m);
// 输入牛奶的价格和供应量信息
for (int i = 0; i < m; ++i) {
cin >> milks[i].price >> milks[i].supply;
}
// 对牛奶信息按照价格和供应量进行排序
sort(milks.begin(), milks.end(), compare);
int sum = 0;
for (int i = 0; i < m; ++i) {
if (n - milks[i].supply >= 0) {
n -= milks[i].supply;
sum += milks[i].price * milks[i].supply;
} else {
sum += milks[i].price * n;
break;
}
}
cout << sum << endl;
return 0;
}代码思路
这段代码主要解决的是一个根据给定的牛奶购买预算和不同牛奶的价格、供应量信息,来计算在预算范围内购买牛奶所能获得的最大花费的问题。
-
数据输入与初始化:
- 首先通过
cin读取两个整数n和m,其中n表示购买牛奶的预算,m表示可供选择的牛奶种类数量。 - 然后使用循环遍历输入每一种牛奶的价格
price和供应量supply,并将这些信息存储到vector中的Milk结构体对象里。
- 首先通过
-
数据排序:
- 定义了一个比较函数
compare,用于对vector中的牛奶信息进行排序。在比较函数中,首先比较牛奶的价格,如果价格不同,就按照价格从小到大排序;如果价格相同,再比较供应量,按照供应量从大到小排序。这样排序的目的是为了在后续购买牛奶时,优先选择价格低且供应量相对较大的牛奶,以便在预算范围内获得更大的花费。 - 通过
sort函数结合compare函数对vector中的牛奶信息进行排序。
- 定义了一个比较函数
-
购买牛奶并计算花费:
- 初始化一个变量
sum用于记录购买牛奶的总花费。 - 通过循环遍历已经排序好的牛奶信息。在每次循环中,判断当前预算
n是否足够购买当前种类牛奶的全部供应量:- 如果
n - milks[i].supply >= 0,说明预算足够购买该种牛奶的全部供应量,那么就从预算中减去购买该种牛奶所花费的量(即该种牛奶的供应量),并将购买该种牛奶的花费(价格乘以供应量)累加到sum中。 - 如果
n - milks[i].supply < 0,说明预算不够购买该种牛奶的全部供应量,此时只能用剩余的预算按当前牛奶的价格购买部分牛奶,将购买部分牛奶的花费(价格乘以剩余预算)累加到sum中,并通过break语句跳出循环,因为预算已经用完,无法再购买其他牛奶了。
- 如果
- 初始化一个变量
-
结果输出:最后,将计算得到的购买牛奶的总花费
sum通过cout输出。
综上所述,该代码通过对牛奶信息进行排序,然后按照排序后的顺序在预算范围内合理购买牛奶,最终计算出在给定预算下购买牛奶所能获得的最大花费。


















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











