







目录
产品概述
产品简介
什么是DataWorks
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
产品架构
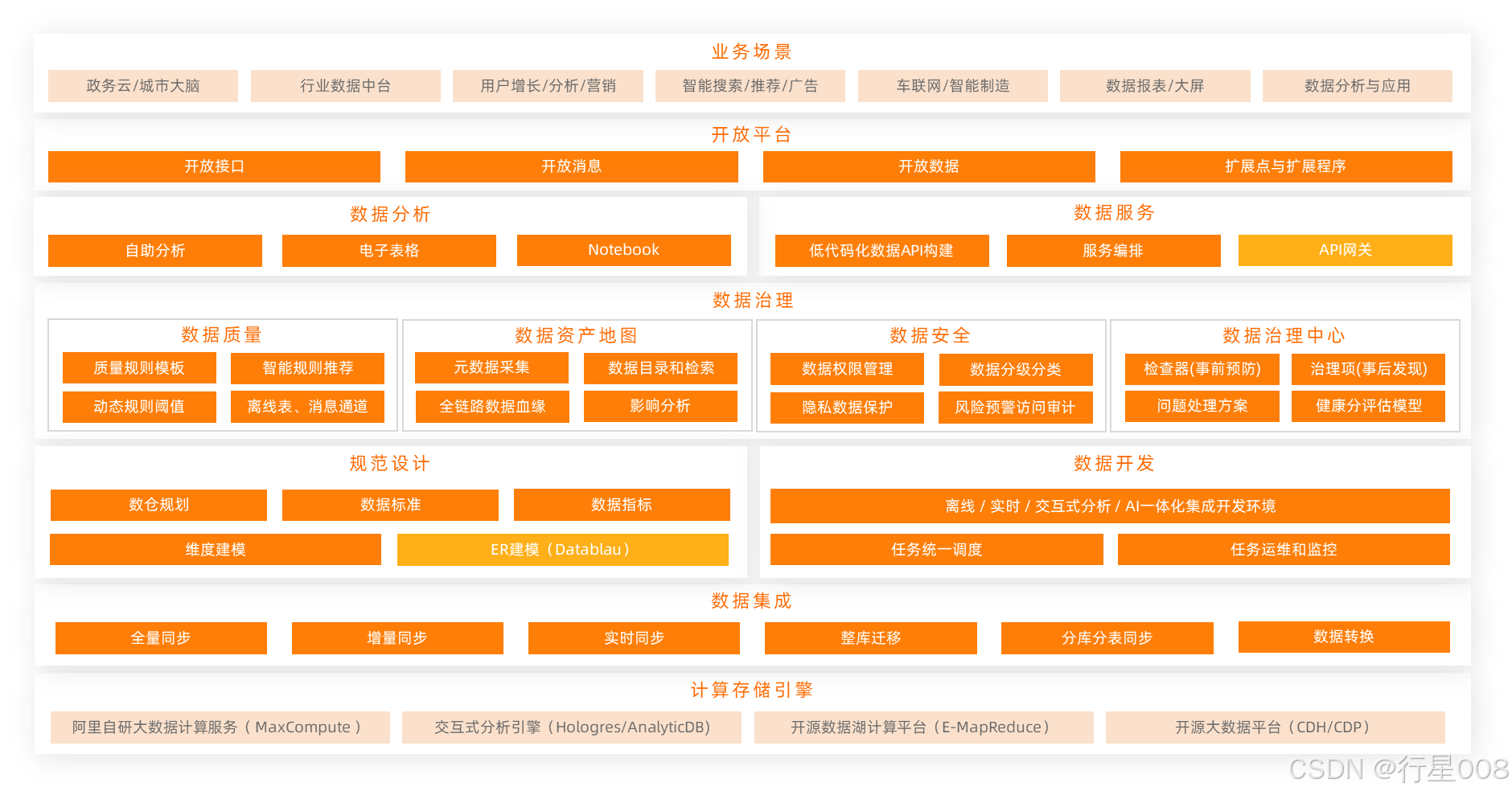
功能特性
- 数据集成:全领域数据汇聚
- 数据开发与运维中心:数据加工
- 数据建模:智能数据建模
- 数据分析:即时快速分析
- 数据质量:全流程的质量监控
- 数据地图:统一管理,跟踪血缘
- 数据服务:低成本快速发布API
- 开放平台:能力全面开放
- 迁移助手与迁云服务
应用场景
核心能力
- 数据集成:复杂网络环境、丰富数据源之间的数据传输与上云。
- 数据开发:在线批处理、流处理和机器学习等多引擎任务开发,构建复杂的调度依赖,提供开发、生产环境隔离的研发模式。
- 实时分析(仅公共云):提供基于电子表格的快速、灵活的即时查询。
- 数据服务:零代码快速生成Serverless化的API。
- 数据质量:通过表级别、字段级别监控规则定义,第一时间感知脏数据。
- 智能监控:一键实现复杂工作流的全链路监控报警配置。
- 数据地图(公共云)/数据管理(专有云):提供强大的数据搜索、数据类目、数据血缘等能力。
- 数据资产管理(仅专有云):统一管理整个平台的数据表、API等各类数据资产。
- 数据安全:数据脱敏、权限控制等能力。
- 应用开发(仅公共云):基于Web端的组件拖拉拽轻松构建数据应用。
- 工作空间管理(公共云)/平台管理(专有云):从系统层面,为管理者提供对使用DataWorks的用户(成员)权限、DataWorks底层计算引擎配置的管理能力。
总之,使用DataWorks,您不仅可以进行海量数据的离线加工分析,还能完成数据的汇聚集成、开发、生产调度与运维、离线与实时分析、数据质量治理与资产管理、安全审计、数据共享与服务、机器学习、应用搭建等覆盖大数据全生命周期的最佳实践。让数据从采集到展现、从分析到驱动应用得以一站式解决,真正实现数据业务化、业务数据化。
构建数据仓库
DataWorks具有通过可视化方式实现数据开发、治理全流程相关的核心能力,在此介绍DataWorks在构建云上大数据仓库和构建智能实时数据仓库两个典型应用场景下的应用示例。
构建云上大数据仓库
本场景推荐的架构如下。

-
适用行业:全行业适用。
-
方案优势:阿里巴巴大数据最佳实践,高性能、低成本、Serverless服务,免运维、全托管模式,让企业的大数据研发人员更聚焦在业务数据的开发、生产、治理。
-
产品组合:MaxCompute + Flink + DataWorks。
-
场景说明
-
用户数据来源丰富,包括来自云端的数据、外部数据源,数据统一沉淀,完成数据清洗、建模。
-
用户的应用场景复杂,对非结构化的语音、自然语言文本进行语音识别、语义分析、情感分析等,同时融合结构化数据搭建企业级的数据管理平台,并且计算和存储成本最低。
-
平台支撑多种形式的应用,包括使用机器学习算法进行复杂数据分析、使用BI报表进行图表展现、使用可视化产品进行大屏展示、使用其他自定义的方式消费数据。
-
构建智能实时数据仓库
本场景推荐的架构如下。

-
适用行业:适用于电商、游戏、社交等互联网行业大规模数据实时查询场景。
-
方案优势:
-
阿里云实时数仓全套链路与离线数仓无缝打通。
-
满足一套存储,两种计算(实时计算和离线计算)的高性价比组合。
-
-
产品组合:DataHub+实时计算Flink+交互式分析+MaxCompute+DataWorks+Quick BI / DataV
-
场景说明:
-
数据采集:通过DataWorks(批量)、DataHub(实时)进行统一数据采集接入。
-
数据开发:基于DataWorks进行数据全链路研发,包括数据集成、数据开发和ETL 、转换及计算等开发,以及数据作业的调度、监控、告警等。DataWorks提供数据开发链路的安全管控的能力,以及基于DataWorks数据服务模块提供统一数据服务API能力。
-
实时数据:按实际业务需求使用Flink进行实时ETL(可选)、结果入库,使用交互式分析产品构建实时数据仓库、应用集市,并提供海量数据的实时交互查询和分析。
-
交互式分析:提供实时离线联邦查询。历史离线数据存放于MaxCompute,实时分析数据存放于交互式分析。基于阿里云Quick BI或第三方数据分析工具(如Tableau)执行数据可视化,以及构建各业务板块数据服务门户应用。
-
通用数据开发
通常数据开发的总体流程包括数据产生、数据收集与存储、数据分析与处理、数据提取和数据展现与分享。
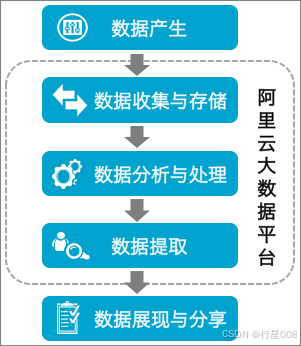
说明
上图中,虚线框内的开发流程均可基于阿里云大数据平台完成。
数据开发的流程如下所示:
- 数据产生:业务系统每天会产生大量结构化的数据,存储在业务系统所对应的数据库中,包括MySQL、Oracle和RDS等类型。
- 数据收集与存储:您需要同步不同业务系统的数据至MaxCompute中,方可通过MaxCompute的海量数据存储与处理能力分析已有的数据。
DataWorks提供数据集成服务,可以支持多种数据源类型,根据预设的调度周期同步业务系统的数据至MaxCompute。
- 数据分析与处理:完成数据的同步后,可以对MaxCompute中的数据进行加工(MaxCompute SQL、MaxCompute MR)、分析与挖掘(数据分析、数据挖掘)等处理,从而发现其价值。
- 数据提取:分析与处理后的结果数据,需要同步导出至业务系统,以供业务人员使用其分析的价值。
- 数据展现与分享:数据提取成功后,可以通过报表、地理信息系统等多种展现方式,展示与分享大数据分析、处理后的成果。
相关云产品
DataWorks作为阿里云一站式大数据开发与治理平台,通常会与计算引擎产品联合使用,此外使用DataWorks进行数据集成时通常联合进行数据传输的数据源产品一起使用。
计算引擎类云产品
DataWorks支持将计算引擎或开源集群创建为DataWorks工作空间的数据源,在数据开发中绑定这些数据源后,您即可在DataWorks上创建对应数据源的计算任务,并进行周期调度。当前支持创建的数据源类型如下:
-
MaxCompute
-
E-MapReduce
-
Hologres
-
ADB for PostgreSQL
-
ADB for MySQL
-
CDH
-
ClickHouse
创建数据源并在数据开发绑定数据源的操作可参见创建并管理数据源、开发前准备:绑定数据源或集群。
数据源类云产品
使用DataWorks进行数据集成时,支持将数据从不同数据源间进行离线或实时同步,各类阿里云或自建关系型数据库、非结构化存储、大数据存储、消息队列等产品均支持添加为DataWorks的数据源,添加完成后即可使用DataWorks进行数据集成。
注意:
具体支持哪些数据源集成需要查看具体的详情清单。
-
离线同步支持的数据源情况请参见支持的数据源与读写插件。
-
实时同步支持的数据源情况请参见实时同步支持的数据源。
这篇博客到这里就接近尾声了,希望我的分享能给您带来一些启发和帮助,别忘了点赞、收藏。您的每一次互动、鼓励是我持续创作的动力!期待与您再次相遇,共同探索更广阔的世界!

















 2515
2515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









