







摘要
DocLayout-YOLO是基于YOLO-v10的文档布局分析工具,通过多样化的合成数据和全局到局部的自适应感知增强文档布局分析,提升了处理速度和准确性。它能够对多样性文档进行实时鲁棒的检测。
新闻 🚀🚀🚀
- 2024.10.25 🎉🎉 基于Mesh-candidate Bestfit的数据合成代码开源,可以合成类型多样、真实感强的高质量布局检测数据集。
- 2024.10.23 🎉🎉 DocSynth300K数据集现在已经上线🤗Huggingface,大幅提升下游微调性能。
- 2024.10.21 🎉🎉 在线演示上线🤗Huggingface。
- 2024.10.18 🎉🎉 DocLayout-YOLO接入文档内容提取工具包PDF-Extract-Kit。
- 2024.10.16 🎉🎉 论文上线ArXiv。
快速使用
在线演示
在线演示目前已经上线。对于本地开发部署,参考以下步骤:
环境配置
bash
conda create -n doclayout_yolo python=3.10
conda activate doclayout_yolo
pip install -e .如果只想使用DocLayout-YOLO的推理功能,直接通过pip进行安装:
bash
pip install doclayout-yolo模型推理
脚本推理
通过以下命令运行推理脚本demo.py来进行推理:
bash
python demo.py --model path/to/model --image-path path/to/imageSDK推理
直接通过SDK进行模型推理:
python
import cv2
from doclayout_yolo import YOLOv10
# Load the pre-trained model
model = YOLOv10("path/to/provided/model")
# Perform prediction
det_res = model.predict(
"path/to/image", # Image to predict
imgsz=1024, # Prediction image size
conf=0.2, # Confidence threshold
device="cuda:0" # Device to use (e.g., 'cuda:0' or 'cpu')
)
# Annotate and save the result
annotated_frame = det_res[0].plot(pil=True, line_width=5, font_size=20)
cv2.imwrite("result.jpg", annotated_frame)请使用在DocStructBench上微调的模型来进行推理,适用于实际场景中多种类型文档。模型下载地址在链接,示例图像路径为assets/example。
注意事项
- 对于PDF或者文档内容提取,请参考PDF-Extract-Kit和MinerU。
- 感谢NielsRogge,DocLayout-YOLO现在支持直接从🤗Huggingface进行调用,加载模型示例如下:
python
或者直接通过from_pretrained进行加载:filepath = hf_hub_download(repo_id="juliozhao/DocLayout-YOLO-DocStructBench", filename="doclayout_yolo_docstructbench_imgsz1024.pt") model = YOLOv10(filepath)python
model = YOLOv10.from_pretrained("juliozhao/DocLayout-YOLO-DocStructBench") - 感谢luciaganlulu,DocLayout-YOLO可以进行batch推理。具体来说,在model.predict的demo.py函数中传入图像路径的列表,而不是单张图像。
DocSynth300K数据集
数据下载
使用以下指令下载数据集(约113G):
python
from huggingface_hub import snapshot_download
# Download DocSynth300K
snapshot_download(repo_id="juliozhao/DocSynth300K", local_dir="./docsynth300k-hf", repo_type="dataset")
# If the download was disrupted and the file is not complete, you can resume the download
snapshot_download(repo_id="juliozhao/DocSynth300K", local_dir="./docsynth300k-hf", repo_type="dataset", resume_download=True)数据准备 & 预训练
如果想要进行DocSynth300K预训练,首先使用format_docsynth300k.py将原始数据集的.parquet格式转换成YOLO格式。格式转换后的数据存储在./layout_data/docsynth300k。
python
python format_docsynth300k.py使用此处命令来进行DocSynth300K预训练。默认使用8张GPU进行训练。为了达到最好的性能,可以通过调整预训练超参数例如imgsz以及lr,根据下游微调数据集的分布或者训练设置来调整。
公开文档版面分析(DLA)数据集训练验证
数据准备
指定数据根目录,找到ultralytics配置文件(对于Linux用户配置文件在$HOME/.config/Ultralytics/settings.yaml),将datasets_dir改成项目根目录。
下载整理好的YOLO格式D4LA以及DocLayNet数据,放置在路径./layout_data并且解压缩。
模型训练验证
模型训练使用8张GPU,全局batch size大小为64(8张图片每个GPU)。其他详细的配置、命令、以及模型权重如下:
| 数据集 | 模型 | 是否DocSynth300K预训练? | 图像尺寸 | 学习率 | 训练 | 验证 | AP50 | mAP | 模型权重 |
|---|---|---|---|---|---|---|---|---|---|
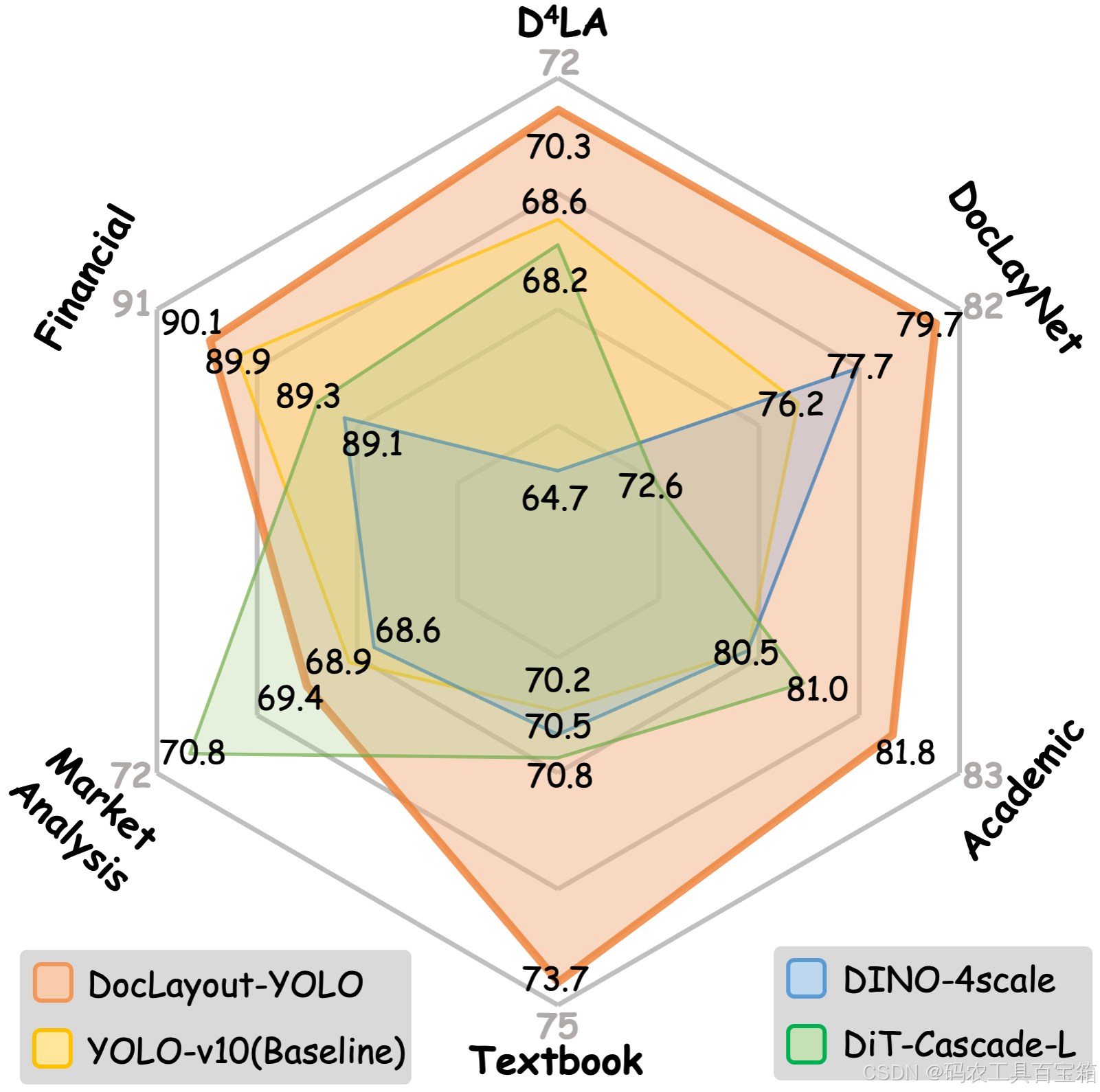
| D4LA | DocLayout-YOLO | ✗ | 1600 | 0.04 | 命令 | 命令 | 81.7 | 69.8 | 权重 |
| D4LA | DocLayout-YOLO | ✓ | 1600 | 0.04 | 命令 | 命令 | 82.4 | 70.3 | 权重 |
| DocLayNet | DocLayout-YOLO | ✗ | 1120 | 0.02 | 命令 | 命令 | 93.0 | 77.7 | 权重 |
| DocLayNet | DocLayout-YOLO | ✓ | 1120 | 0.02 | 命令 | 命令 | 93.4 | 79.7 | 权重 |
使用DocSynth300K预训练过的预训练模型可以从这里进行下载。验证时,将命令中的checkpoint.pt改成需要验证的模型。


















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











