




注:本文为 “虚拟地址转换” 相关合辑。
英文引文,机翻未校。
中文引文,略作重排。
未整理去重,如有内容异常,请看原文。
How the CPU Translates Virtual Addresses to Physical Addresses
CPU 如何将虚拟地址转换为物理地址
How does the CPU knows which physical address is mapped to which virtual address?
CPU 如何知晓虚拟地址与物理地址的映射关系?
Mohit
Feb 15, 2025
Introduction
引言
In modern operating systems, processes operate in an isolated virtual memory space, unaware of the underlying physical memory. This abstraction, managed by the CPU’s Memory Management Unit (MMU), allows for efficient and secure memory allocation. But how does the CPU know which physical address corresponds to a given virtual address? This article explores the mechanics behind virtual-to-physical address translation, page tables, context switching, and more, complete with code examples and diagrams.
在现代操作系统中,进程运行于相互隔离的虚拟内存空间,无需感知底层物理内存的具体布局。这种内存抽象由 CPU 的内存管理单元(Memory Management Unit, MMU)实现,能够支持高效且安全的内存分配机制。但CPU 究竟如何确定某个虚拟地址对应的物理地址?本文将深入解析虚拟地址到物理地址的转换机制、页表结构、上下文切换等技术细节,并辅以代码示例与示意图。
1. Virtual Memory Overview
1. 虚拟内存概述
Virtual memory allows each process to believe it has exclusive access to the system’s memory. The MMU translates virtual addresses (used by software) into physical addresses (used by hardware). Key benefits include:
虚拟内存技术让每个进程都认为自己独占整个系统的内存空间。MMU 负责将软件使用的虚拟地址转换为硬件识别的物理地址。该技术的优势如下:
-
Isolation: Processes cannot access each other’s memory.
隔离性:进程无法访问彼此的内存空间。 -
Efficiency: Physical memory is dynamically allocated as needed.
高效性:物理内存可根据需求动态分配。 -
Security: Memory permissions (read/write/execute) are enforced.
安全性:可强制实施内存权限控制(读/写/执行)。
2. Role of the MMU and Page Tables
2. MMU 与页表的作用
The MMU uses page tables—hierarchical data structures maintained by the OS—to map virtual addresses to physical addresses. Each process has its page table, updated during context switches.
MMU 通过页表(由操作系统维护的层级化数据结构)实现虚拟地址到物理地址的映射。每个进程都拥有独立的页表,且页表会在上下文切换时更新。
Page Table Basics
页表基础
-
Page: A fixed-size block of memory (typically 4 KB).
页:固定大小的内存块(通常为 4 KB)。 -
Page Table Entry (PTE): Contains the physical address of a page and flags (e.g., present, writable).
页表项(Page Table Entry, PTE):存储对应页的物理地址及属性标志(如存在标志、可写标志)。
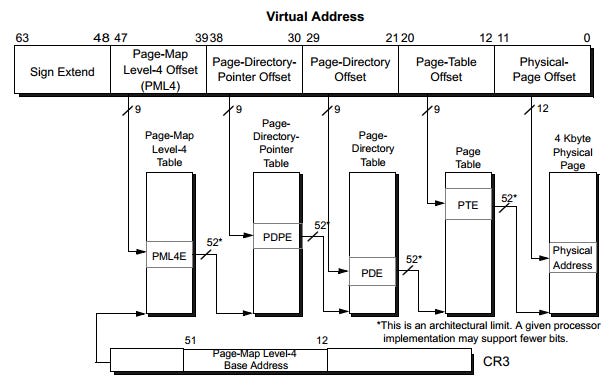
x86-64 分页架构
3. Multi-Level Page Tables
3. 多级页表
Modern CPUs use multi-level page tables to reduce memory overhead. For example, x86-64 uses a 4-level structure:
现代 CPU 采用多级页表结构以降低内存开销。例如,x86-64 架构使用 4 级页表结构:
Translation Process:
地址转换流程:
-
The CR3 register holds the physical address of the PML4 table.
CR3 寄存器存储页映射级别 4 表(PML4 表)的物理地址。 -
Bits 39–47 of the virtual address index into the PML4 table.
虚拟地址的第 39–47 位用于索引 PML4 表,获取对应的表项。 -
Each entry points to a PDP table, indexed by bits 30–38.
PML4 表项指向页目录指针表(PDP 表),虚拟地址的第 30–38 位用于索引 PDP 表。 -
This repeats until the PT entry provides the physical page address.
重复上述索引过程,直至页表(PT 表)项提供目标物理页的地址。 -
The remaining 12 bits are the offset within the page.
虚拟地址剩余的 12 位作为页内偏移量,与物理页地址拼接得到最终物理地址。
4. Context Switching and the CR3 Register
4. 上下文切换与 CR3 寄存器
When the OS switches processes, it updates the CR3 register to point to the new process’s PML4 table. This ensures the MMU uses the correct page table for translations.
当操作系统执行进程上下文切换时,会更新 CR3 寄存器,使其指向新进程的 PML4 表。这一操作确保 MMU 使用正确的页表进行地址转换。
Process Control Block (PCB)
进程控制块(Process Control Block, PCB)
The OS stores process-specific data (including CR3) in the PCB. During a context switch:
操作系统将进程专属数据(包括 CR3 寄存器的值)存储在 PCB 中。上下文切换的执行步骤如下:
-
Save the current process’s state (registers, CR3).
保存当前进程的运行状态(寄存器值、CR3 寄存器值)。 -
Load the new process’s CR3 into the MMU.
将新进程的 CR3 寄存器值加载至 MMU。 -
Invalidate the TLB (unless using Process Context Identifiers).
使 TLB 中的缓存项失效(若未使用进程上下文标识符则执行此操作)。
5. Translation Lookaside Buffer (TLB)
5. 转换后备缓冲区(Translation Lookaside Buffer, TLB)
The TLB caches recent translations to avoid costly page table walks. On a context switch, the OS invalidates TLB entries unless they’re tagged with a Process Context Identifier (PCID).
TLB 用于缓存近期的地址转换结果,以避免耗时的页表遍历操作。在上下文切换时,操作系统会使 TLB 中的缓存项失效——除非这些缓存项带有进程上下文标识符(Process Context Identifier, PCID) 标签。
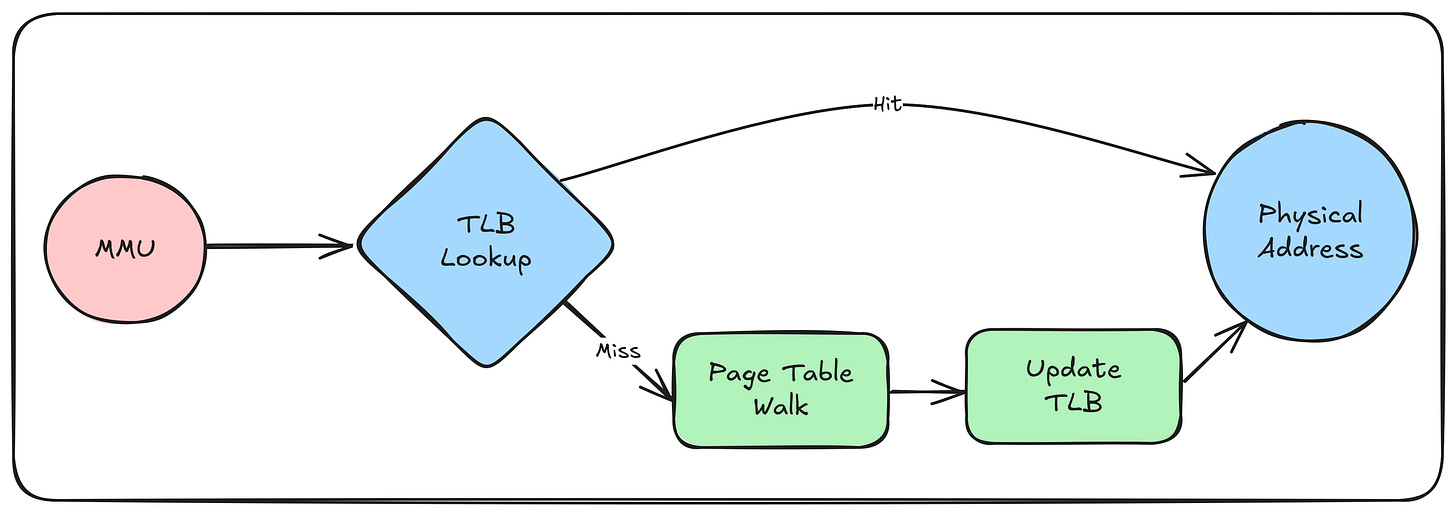
TLB 工作流程
6. Code Examples
6. 代码示例
Example 1: Virtual Addresses in Parent and Child Processes
示例 1:父子进程中的虚拟地址
Code (virtual_address.c):
代码(virtual_address.c):
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int var = 42;
printf("Parent PID: %d\n", getpid());
printf("Parent var address: %p\n", &var);
pid_t pid = fork();
if (pid == 0) {
printf("Child PID: %d\n", getpid());
printf("Child var address: %p\n", &var);
var = 84;
printf("Child var value: %d\n", var);
_exit(0);
} else {
wait(NULL);
printf("Parent var value: %d\n", var);
}
return 0;
}
Compile and Run:
编译与运行:
gcc virtual_address.c -o virtual_address
./virtual_address
Expected Output:
预期输出:
Parent PID: 9079
Parent var address: 0x7ffe197e5700
Child PID: 9080
Child var address: 0x7ffe197e5700
Child var value: 84
Parent var value: 42
Explanation:
解释:
-
Parent and child share the same virtual address for
var.父子进程中变量
var的虚拟地址完全相同。 -
Due to copy-on-write, they point to different physical addresses.
基于写时复制(copy-on-write) 机制,二者的虚拟地址映射到不同的物理地址。
Example 2: Translating Virtual to Physical Addresses
示例 2:虚拟地址到物理地址的转换
Using /proc/[pid]/pagemap:
The Linux kernel exposes physical page mappings via /proc/[pid]/pagemap.
使用 /proc/[pid]/pagemap 文件:
Linux 内核通过 /proc/[pid]/pagemap 文件对外暴露进程的物理页映射关系。
Code (pagemap.c):
代码(pagemap.c):
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define PAGE_SHIFT 12
#define PAGE_SIZE (1 << PAGE_SHIFT)
#define PFN_MASK (((1ULL << 55) - 1) & ~((1ULL << PAGE_SHIFT) - 1))
int main() {
int var;
int fd;
uint64_t entry, pfn;
off_t offset;
printf("Virtual address of var: %p\n", &var);
fd = open("/proc/self/pagemap", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
offset = (uintptr_t)&var / PAGE_SIZE * sizeof(entry);
if (lseek(fd, offset, SEEK_SET) == (off_t)-1) {
perror("lseek");
close(fd);
return 1;
}
if (read(fd, &entry, sizeof(entry)) != sizeof(entry)) {
perror("read");
close(fd);
return 1;
}
close(fd);
if ((entry & (1ULL << 63)) == 0) {
printf("Page not present\n");
return 1;
}
pfn = entry & PFN_MASK;
printf("Physical address: 0x%lx\n", (pfn << PAGE_SHIFT) | ((uintptr_t)&var & (PAGE_SIZE - 1)));
return 0;
}
Compile and Run (as root):
编译与运行(需 root 权限):
gcc pagemap.c -o pagemap
sudo ./pagemap
Expected Output:
预期输出:
Virtual address of var: 0x7ffe25e5e3e8
Physical address: 0x1220003e8
Explanation:
解释:
-
The program reads its own pagemap to resolve the physical address of
var.该程序读取自身的页映射文件,解析变量
var对应的物理地址。 -
Requires root privileges due to security restrictions.
由于安全限制,此操作需要 root 权限才能执行。
Example 3: Inspecting Process Memory Maps
示例 3:查看进程内存映射
Use pmap to view a process’s memory regions:
使用 pmap 命令查看进程的内存区域分布:
pmap [pid]
Output:
输出示例:
1234: ./virtual_address
00007f8d4a2e9000 4K r---- libc.so.6
00007f8d4a2ea000 2048K r-x-- libc.so.6
...
Explanation:
解释:
- Shows virtual memory regions mapped to physical pages or files.
输出内容展示进程的虚拟内存区域如何映射到物理页或文件。
7. Conclusion
7. 结论
The CPU translates virtual addresses to physical addresses using page tables managed by the OS. Each process has its table, and the MMU’s CR3 register is updated during context switches.
CPU 通过操作系统维护的页表完成虚拟地址到物理地址的转换。每个进程拥有独立的页表,且 MMU 的 CR3 寄存器会在上下文切换时更新。
The TLB caches translations for speed, while the OS ensures isolation and correctness through careful management of page tables and process states. By understanding these mechanisms, developers can write more efficient and secure systems software.
TLB 通过缓存地址转换结果提升转换速度,而操作系统则通过对页表和进程状态的精细管理,保障进程间的内存隔离性与地址转换的正确性。开发者理解这些底层机制后,能够编写出更高效、更安全的系统级软件。
彻底搞懂虚拟地址翻译为物理地址的过程
原创 2021-04-26 19:45·一轮世间
本文详细解析虚拟地址通过内存管理单元(MMU)、翻译后备缓冲器(TLB)与一级高速缓冲(L1)转换为物理地址的完整过程,并结合实例对该流程展开验证,内容涵盖虚拟页号、页表项、TLB 映射、高速缓冲映射等相关要素。
现代操作系统加载可执行文件后创建进程,进程内所有指令与数据均被分配对应的虚拟地址。中央处理器(CPU)获取虚拟地址后,必须将其翻译为内存的物理地址,才能对指令与数据执行访问操作。本文围绕虚拟地址到物理地址的翻译流程与实践展开阐述,整体分为 2 个部分:
- 虚拟地址翻译为物理地址的流程
- 虚拟地址翻译流程的实例验证
1 虚拟地址翻译为物理地址的流程
当 CPU 首次访问某一虚拟地址时,该虚拟地址对应的虚拟页未加载至内存,且对应的页表项(PTE)未缓存至 TLB,因此需要执行的操作步骤相对完整,流程如下图所示。
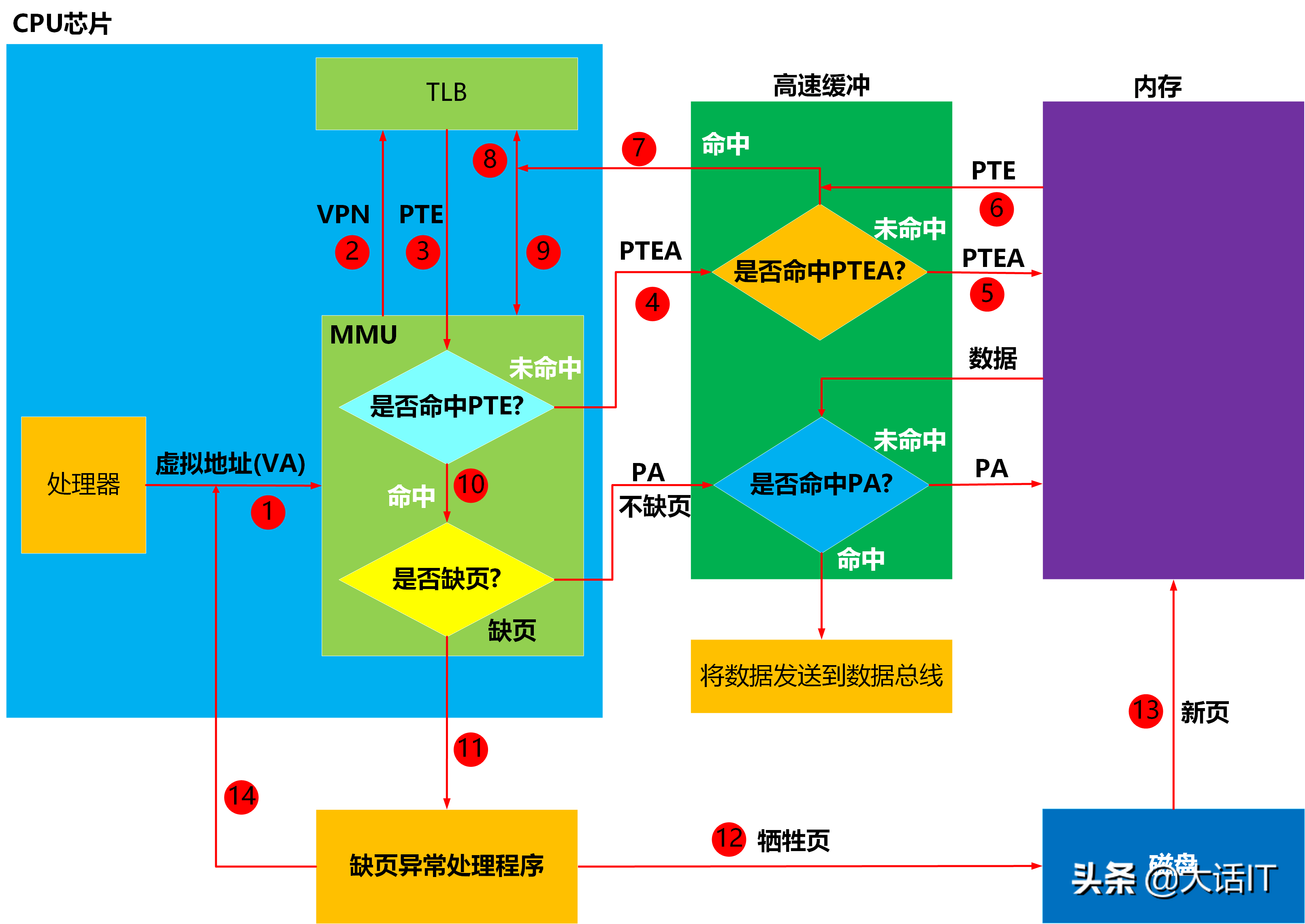
1.1 首次访问虚拟地址的执行步骤
步骤 1:处理器将虚拟地址(VA) 发送至内存管理单元(MMU)。
虚拟地址的格式如下图所示。

如上图所示,虚拟地址的总长度为 n n n 位,其中虚拟页偏移量的长度为 p p p 位。
步骤 2:MMU 从虚拟地址中提取虚拟页号(VPN),并将虚拟页号发送至翻译后备缓冲器(TLB);TLB 根据接收到的虚拟页号,在自身的TLB 映射表中查询对应的页表项(PTE,Page Table Entry)。
页表项的结构如下图所示。

步骤 3:TLB 将查询结果返回至 MMU。
步骤 4:MMU 对 TLB 返回的查询结果进行分析,判定当前无可用 PTE,即发生 TLB 未命中。此时,MMU 根据页表基址寄存器(PTBR) 存储的页表起始地址,与虚拟页号(VPN)执行地址运算,得到该虚拟页对应页表项的物理地址 PTEA(Page Table Entry Address),并将该物理地址发送至一级高速缓冲(L1)。
步骤 5:L1 根据接收到的 PTEA 查询内部缓冲映射表,判定当前无 PTEA 对应的映射关系,即发生 L1 未命中;随后 L1 向内存发起请求,获取 PTEA 对应的存储内容。
步骤 6:内存将 PTEA 对应的页表项(PTE) 传输至 L1;L1 建立 PTEA 与 PTE 之间的映射关系,完成缓存写入。
步骤 7:L1 再次根据 PTEA 查询内部缓冲映射表,此时查询命中,随即将 PTE 传输至 TLB。
步骤 8~9:TLB 接收 PTE 后,建立虚拟页号(VPN) 与 PTE 之间的映射关系(步骤 8),并将 PTE 传输至 MMU(步骤 9)。
步骤 10:MMU 接收 PTE 后,检查 PTE 中的有效位,以此判定该虚拟页是否已加载至物理内存。
步骤 11:MMU 经检查判定虚拟页未加载至物理内存,随即向 CPU 发送缺页中断;CPU 响应中断并执行缺页中断处理程序。
步骤 12:缺页中断处理程序依据预设的页面置换算法,从物理内存中选定一个已缓存的虚拟页作为牺牲页;若该牺牲页的内容自加载后发生过修改,则将其写回磁盘;随后将该牺牲页对应 PTE 的有效位设置为 0 0 0,标记该页已不在物理内存中。
步骤 13:缺页中断处理程序将缺失的虚拟页从磁盘换入物理内存的空闲区域,同时更新该虚拟页对应 PTE 的有效位为 1 1 1,并写入对应的物理页号。
步骤 14:缺页中断处理程序执行完毕,程序计数器跳转至触发缺页中断的指令处;CPU 重新执行该指令,再次将虚拟地址发送至 MMU,重新启动虚拟地址翻译流程。
1.2 非首次访问同一虚拟地址的执行步骤
当 CPU 非首次访问同一虚拟地址时,该虚拟地址对应的虚拟页已加载至物理内存,且对应的 PTE 已缓存至 TLB,因此执行步骤得到简化,流程如下图所示。
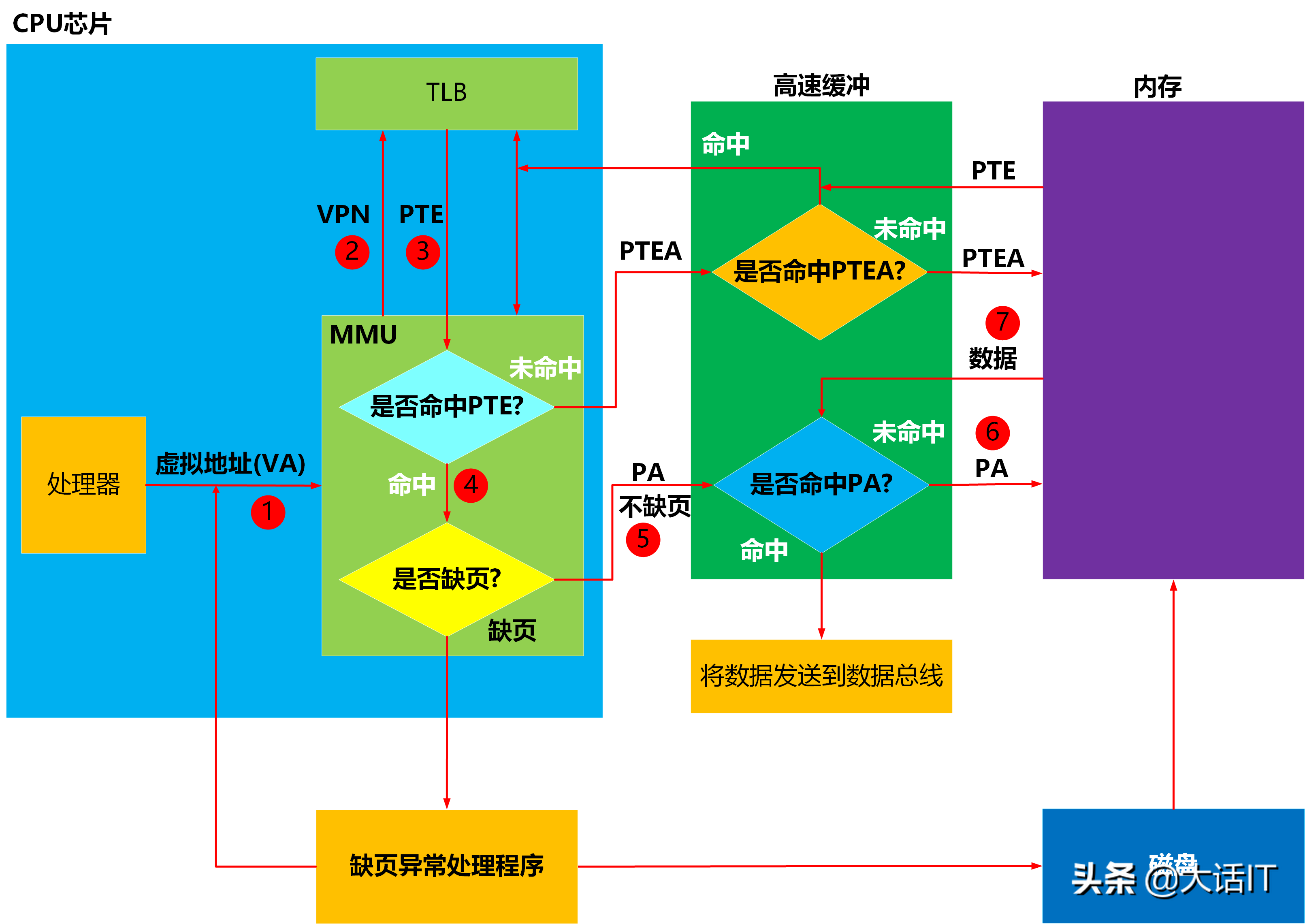
步骤 1:处理器将虚拟地址(VA) 发送至内存管理单元(MMU)。
步骤 2:MMU 从虚拟地址中提取虚拟页号(VPN),并将虚拟页号发送至 TLB;TLB 根据虚拟页号查询映射表,获取对应的 PTE。
步骤 3:TLB 将查询到的 PTE 返回至 MMU。
步骤 4:MMU 判定查询结果存在有效 PTE,即发生 TLB 命中;随后检查 PTE 的有效位,确认该虚拟页已加载至物理内存;MMU 提取 PTE 中的物理页号(PPN),与虚拟地址中的虚拟页偏移量(VPO)执行拼接运算,得到最终的物理地址(PA),并将 PA 发送至 L1。
步骤 5:L1 根据接收到的 PA 查询内部缓冲映射表,判定当前无 PA 对应的映射关系,即发生 L1 未命中;随后 L1 向内存发起请求,获取 PA 对应的指令或数据。
步骤 6:内存将 PA 对应的指令或数据传输至 L1;L1 建立 PA 与对应内容的映射关系,完成缓存写入。
步骤 7:L1 再次根据 PA 查询内部缓冲映射表,此时查询命中,随即将对应的指令或数据传输至数据总线;CPU 从数据总线接收数据,完成本次访问操作。
1.3 多次访问同一虚拟地址的优化逻辑
当 CPU 第三次及后续访问同一虚拟地址时,与第二次访问的差异在于:该虚拟地址对应的物理地址及其数据已缓存至 L1,因此无需向内存发起查询请求,直接从 L1 中读取数据,访问效率进一步提升。
至此,虚拟地址翻译为物理地址的完整过程阐述完毕,下文结合具体实例对该流程展开验证。
2 虚拟地址翻译流程的实例验证
本节基于前文阐述的虚拟地址翻译流程,结合 TLB 与高速缓冲的映射原理,通过具体参数与地址实例完成流程验证。在实例验证前,首先对 TLB 与高速缓冲的相关概念进行梳理。
2.1 相关概念梳理
2.1.1 翻译后备缓冲器(TLB)
TLB 的全称为翻译后备缓冲器,本质是一种高速缓存映射表,其功能是建立虚拟页号(VPN) 与页表项(PTE) 之间的映射关系。
CPU 访问虚拟地址时,需查询该地址对应的 PTE。若每次均从内存中查询 PTE,需耗费数十甚至上百个时钟周期;即便 PTE 已缓存至 L1,查询仍需耗费 1 ∼ 2 1\sim2 1∼2 个时钟周期;而若 PTE 缓存至 TLB,查询操作几乎无需额外时钟周期,其访问速度与 CPU 寄存器接近,可显著提升地址翻译效率。
TLB 的映射结构如下图所示。
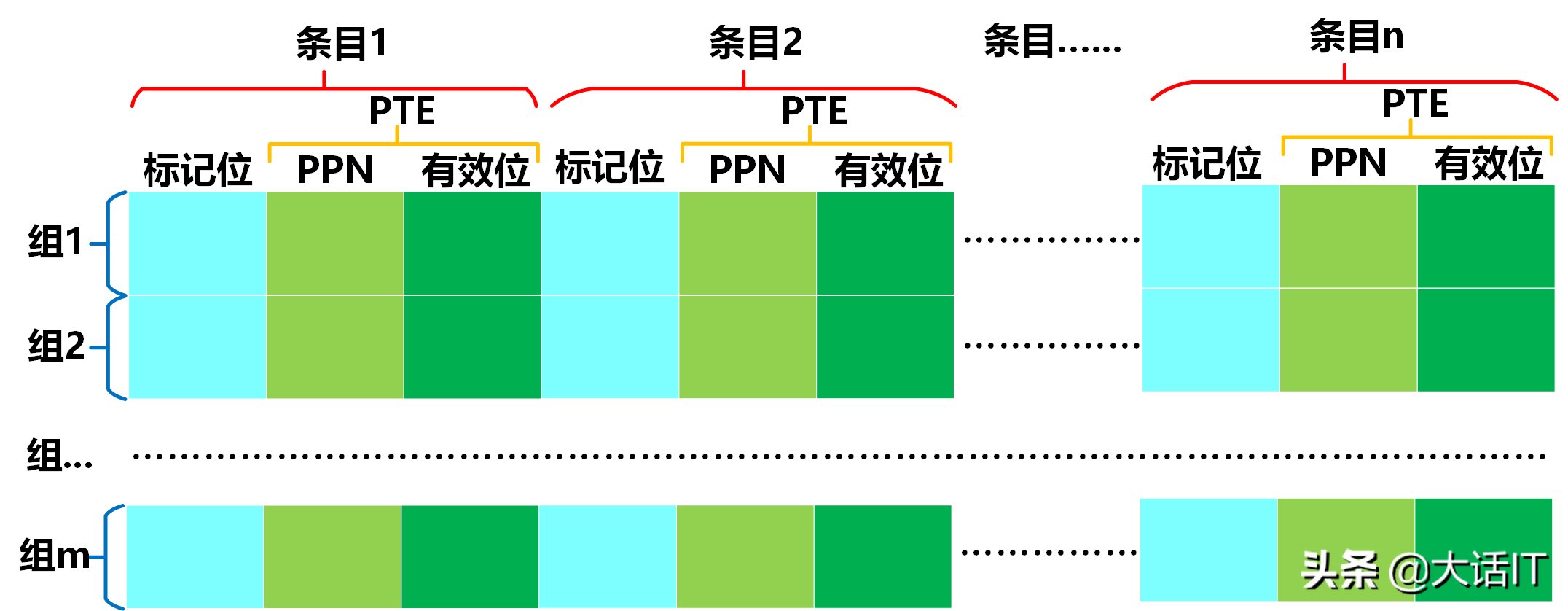
如上图所示,一个 TLB 由 m m m 个 TLB 组构成,每个 TLB 组包含 n n n 个TLB 条目;每个 TLB 条目由 PTE 与标记位(Tag) 两部分组成。
TLB 组内的标记位具有唯一性,因此可通过标记位在 TLB 组内定位唯一的条目;每个 TLB 组对应一个唯一的组号(Index)。
从数据结构角度分析,TLB 可视为一个二维数组,通过组号与标记位两个参数可定位唯一的 PTE。
虚拟地址中的虚拟页号(VPN)可拆分为 TLB 标记位(TLBT) 与 TLB 组号(TLBI) 两部分,其结构如下图所示。
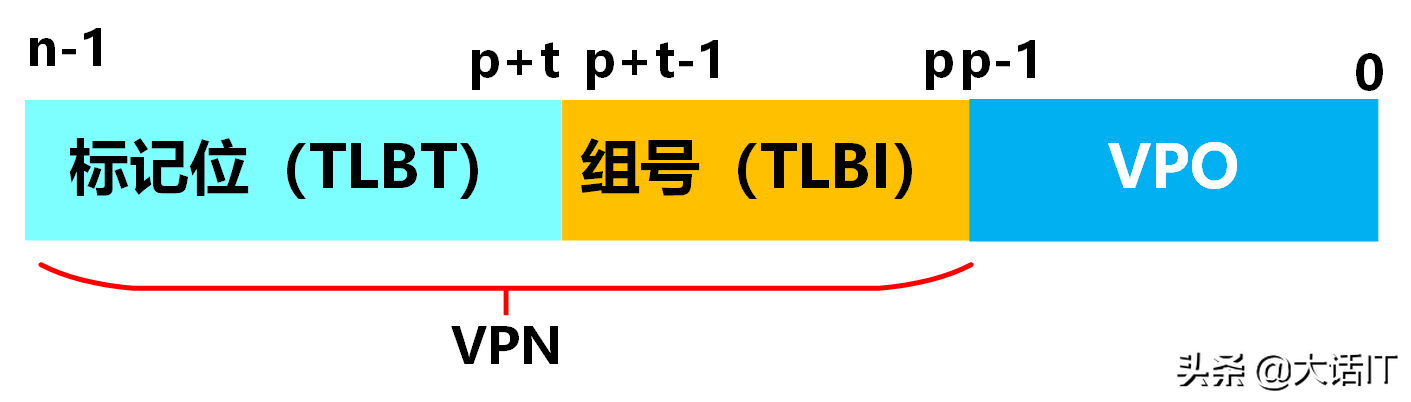
如上图所示,VPN 的高位部分为 TLBT,低位部分为 TLBI;其中 TLBI 的位数由 TLB 组的数量决定,TLBT 的位数为 VPN 总位数减去 TLBI 的位数。
示例:若某 TLB 包含 4 4 4 个组,总条目数为 64 64 64,则每个组包含 16 16 16 个条目。此时 TLBI 的位数为 2 2 2 位( 2 2 = 4 2^2=4 22=4),TLBT 的位数为 4 4 4 位( 2 4 = 16 2^4=16 24=16)。
2.1.2 高速缓冲(L1)
高速缓冲通常采用静态随机访问存储器(SRAM) 作为存储介质,其访问速度比内存采用的动态随机访问存储器(DRAM) 快数十倍甚至上百倍。为提升 CPU 数据访问效率,系统会将近期频繁访问的数据缓存至高速缓冲中。
高速缓冲内部维护一张映射表,用于建立物理地址(PA) 与对应存储内容之间的映射关系,其结构如下图所示。
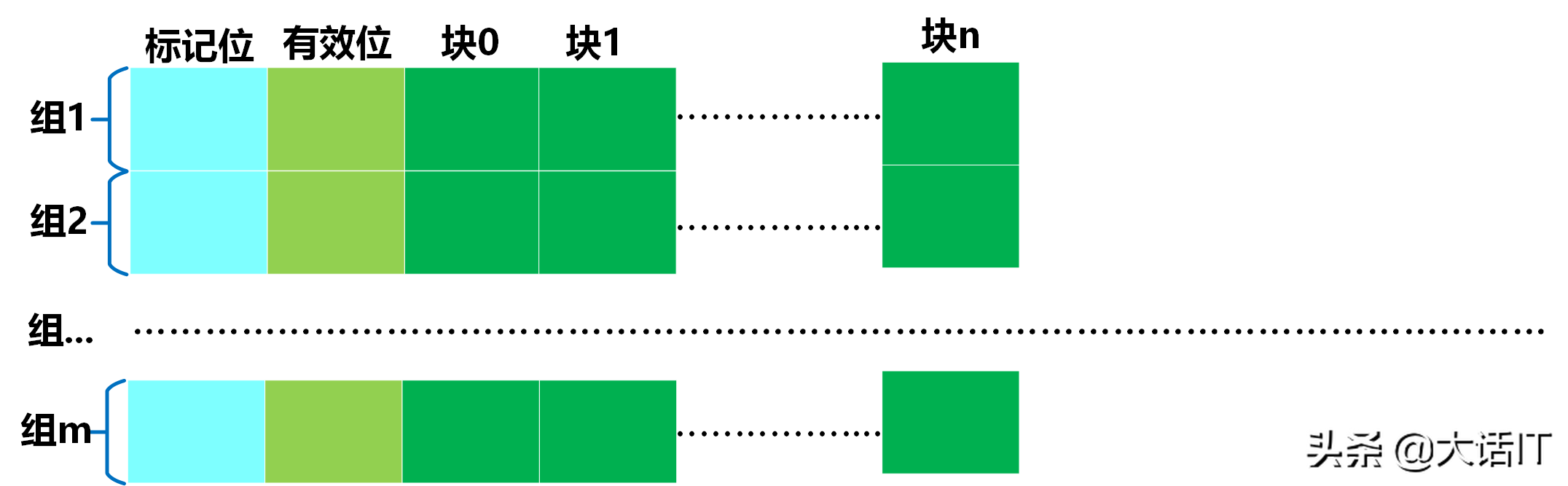
如上图所示,高速缓冲映射表由 m m m 个高速缓冲组构成;每个高速缓冲组包含标记位(Tag)、有效位(Valid Bit) 与 n n n 个高速缓冲块(Cache Block)。
有效位的取值用于标记缓冲块的有效性:有效位为 1 1 1 时,表示对应缓冲块的内容有效;有效位为 0 0 0 时,表示对应缓冲块的内容已过期失效。
物理地址(PA)可拆分为 高速缓冲标记位(CT)、高速缓冲组号(CI) 与 块偏移量(CO) 三部分,其结构如下图所示。
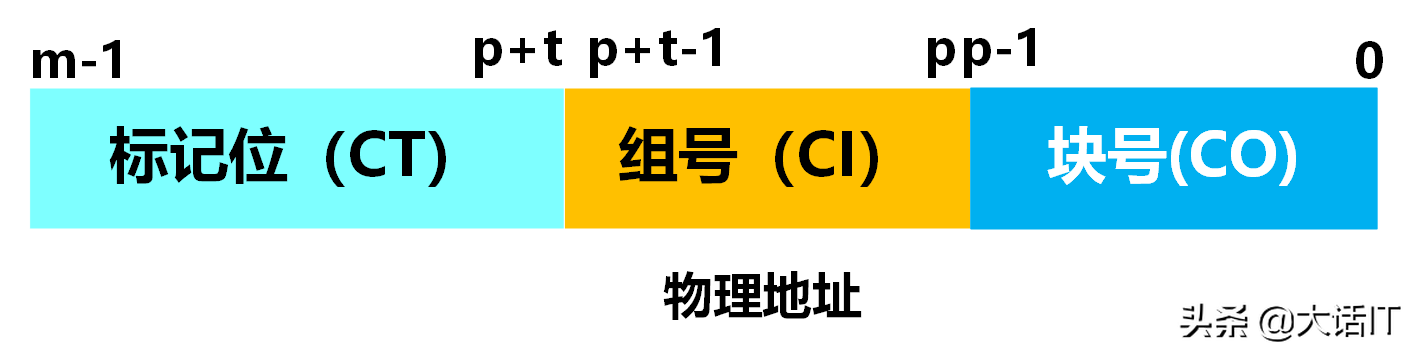
如上图所示,物理地址的总长度为 m m m 位,其中块偏移量 CO 占用 p p p 位,高速缓冲组号 CI 占用 t t t 位,剩余位数为高速缓冲标记位 CT 的长度。
高速缓冲的查询逻辑如下:
- 根据物理地址中的 CI 定位对应的高速缓冲组;
- 检查该组的有效位:若有效位为 0 0 0,判定为高速缓冲未命中;若有效位为 1 1 1,执行下一步;
- 对比该组的 CT 与物理地址中的 CT:若两者不相等,判定为高速缓冲未命中;若两者相等,执行下一步;
- 根据物理地址中的 CO,在该组对应的缓冲块中提取数据,判定为高速缓冲命中。
示例:若某高速缓冲包含 16 16 16 个组,每个组包含 4 4 4 个缓冲块,则 CI 的位数为 4 4 4 位( 2 4 = 16 2^4=16 24=16),CO 的位数为 2 2 2 位( 2 2 = 4 2^2=4 22=4),剩余位数为 CT 的长度。
2.2 实例参数设定
为验证虚拟地址翻译流程,设定如下实验参数:
- 内存采用字节寻址方式,每个字长为 1 1 1 字节(32 位系统中字长通常为 4 4 4 字节,此处为简化计算做特殊设定);
- 虚拟地址长度为 14 14 14 位;页表包含 256 256 256 个页表项,因此虚拟页号(VPN)的长度为 8 8 8 位( 2 8 = 256 2^8=256 28=256),虚拟页偏移量(VPO)的长度为 6 6 6 位( 14 − 8 = 6 14-8=6 14−8=6);
- 物理地址长度为 12 12 12 位;
- 页面大小为 64 64 64 字节( 2 6 = 64 2^6=64 26=64,与 VPO 位数一致);
- TLB 包含 4 4 4 个组,每个组包含 4 4 4 个条目,总条目数为 16 16 16;
- 一级高速缓冲(L1)包含 16 16 16 个组,每个组包含 4 4 4 个缓冲块;
- 采用一级页表结构(多级页表的翻译逻辑与一级页表一致,仅增加地址拆分与查询步骤)。
2.3 地址格式分析
2.3.1 虚拟地址格式
基于上述参数,虚拟地址的格式如下图所示。
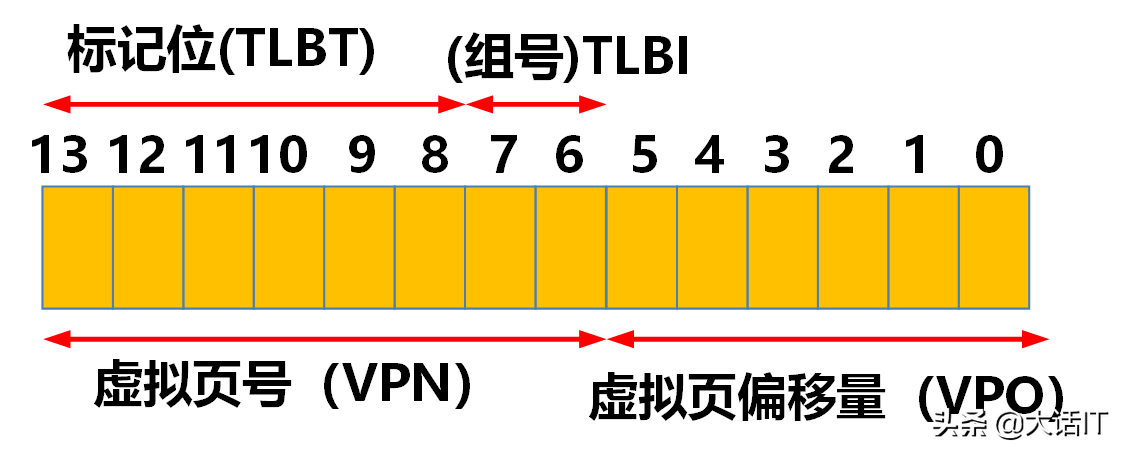
如上图所示,虚拟地址的 VPN 部分拆分为 TLBT 与 TLBI:TLB 包含 4 4 4 个组,因此 TLBI 的长度为 2 2 2 位;VPN 总长度为 8 8 8 位,因此 TLBT 的长度为 6 6 6 位( 8 − 2 = 6 8-2=6 8−2=6)。
2.3.2 物理地址格式
基于上述参数,物理地址的格式如下图所示。
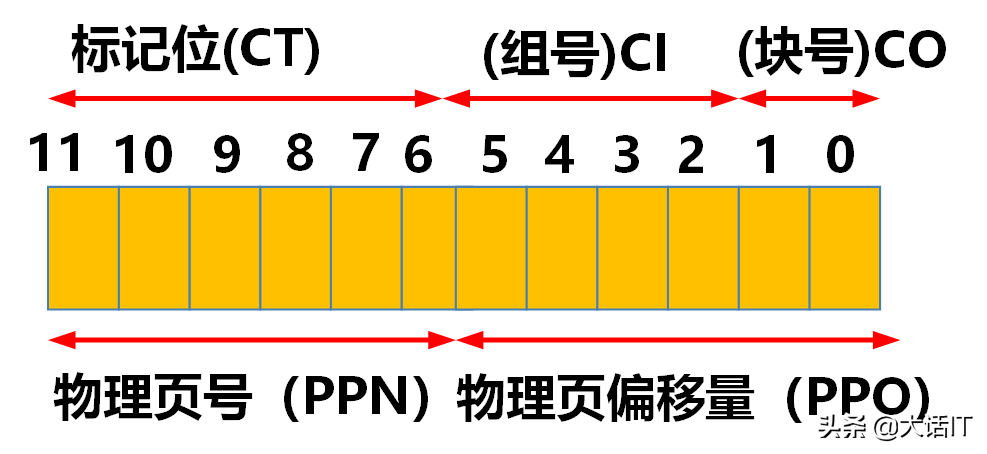
如上图所示,物理地址的长度为 12 12 12 位,拆分为 CT、CI 与 CO 三部分:
- 高速缓冲包含 16 16 16 个组,因此 CI 的长度为 4 4 4 位( 2 4 = 16 2^4=16 24=16);
- 每个组包含 4 4 4 个缓冲块,因此 CO 的长度为 2 2 2 位( 2 2 = 4 2^2=4 22=4);
- CT 的长度为 6 6 6 位( 12 − 4 − 2 = 6 12-4-2=6 12−4−2=6)。
2.4 映射表与页表数据
本实例采用的 TLB 映射表、高速缓冲映射表与页表数据如下:
-
TLB 映射表
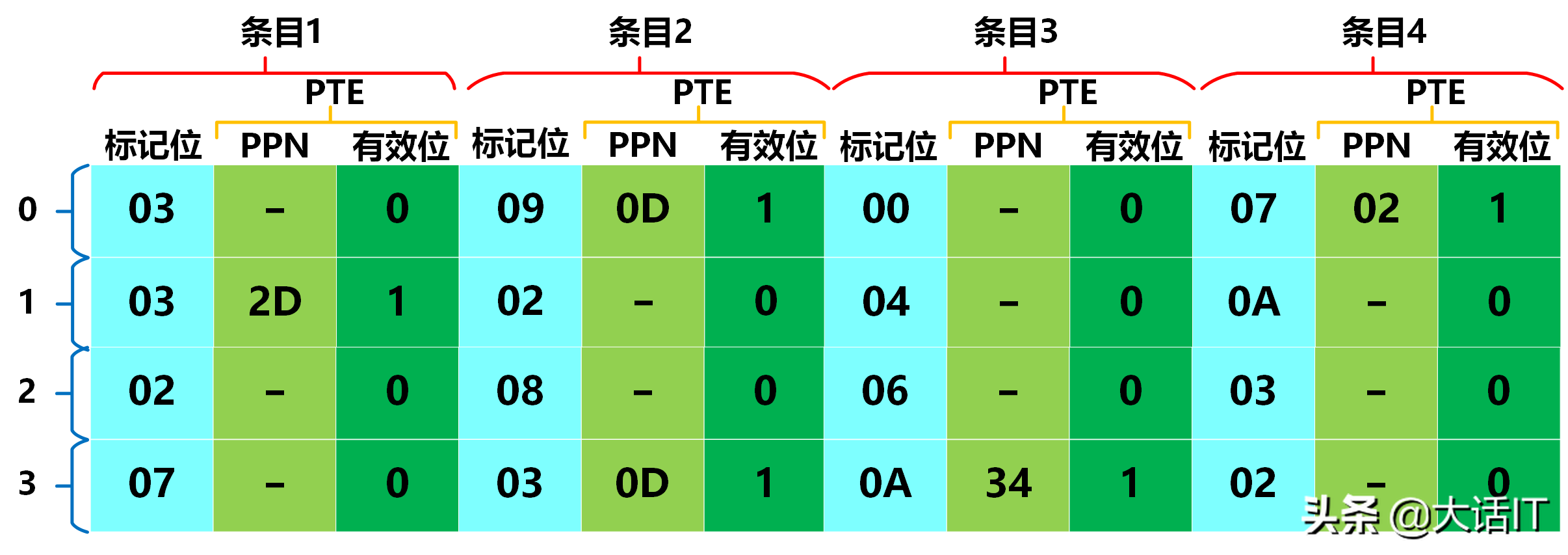
-
高速缓冲映射表
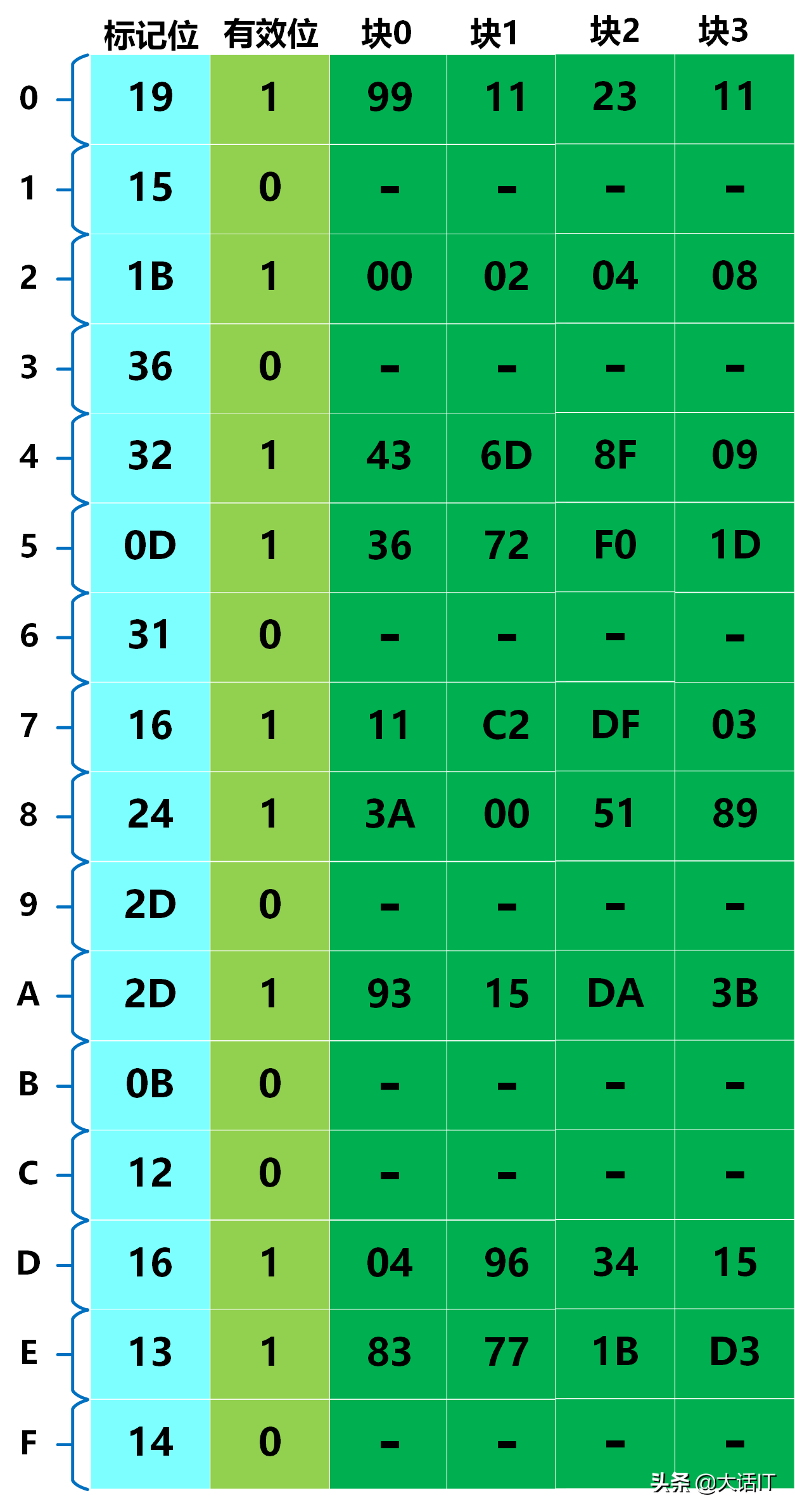
-
页表数据
页表总共有 256 256 256 项,本实例列出前 16 16 16 项的数据,如下图所示。
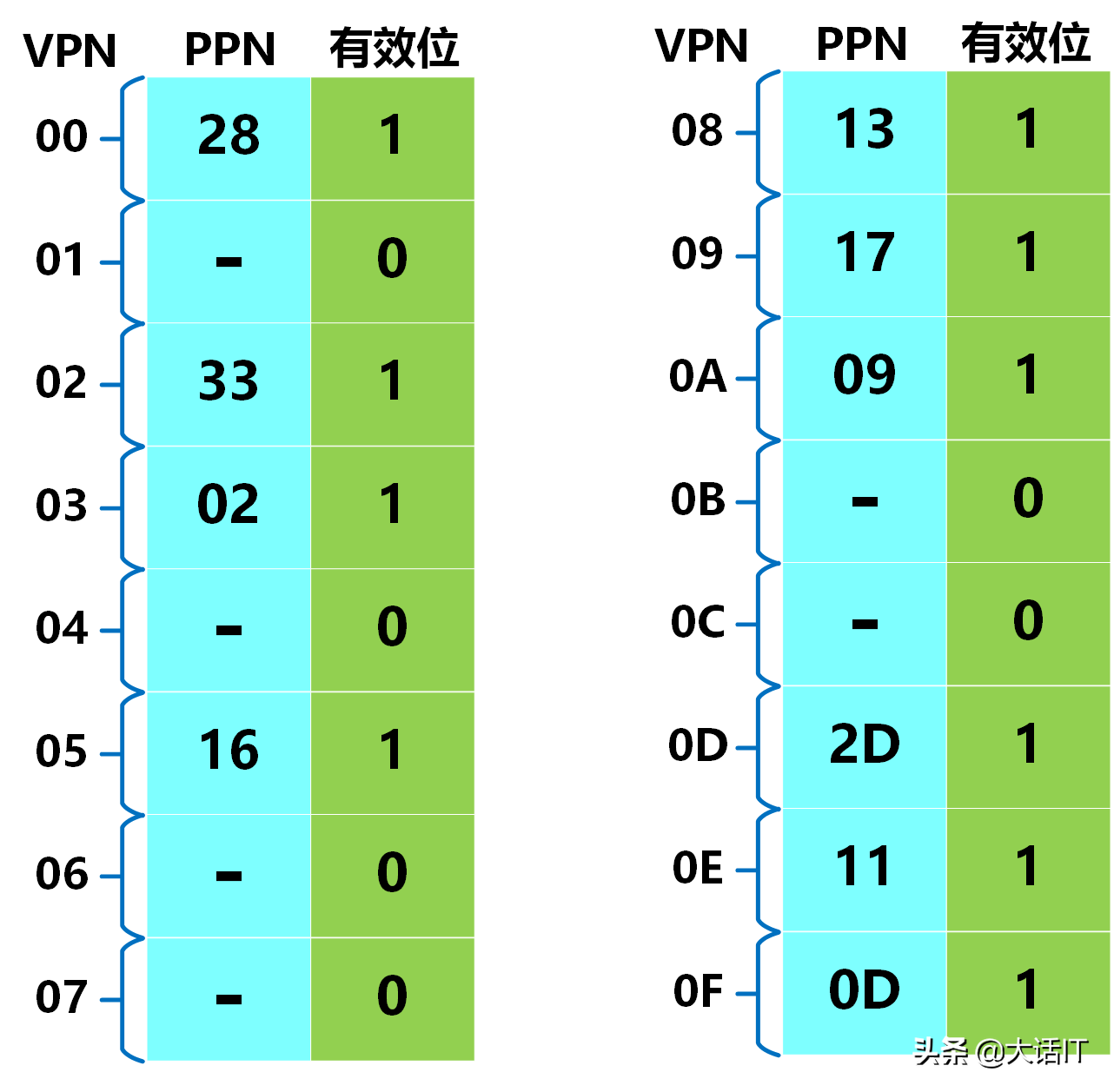
2.5 地址翻译过程验证
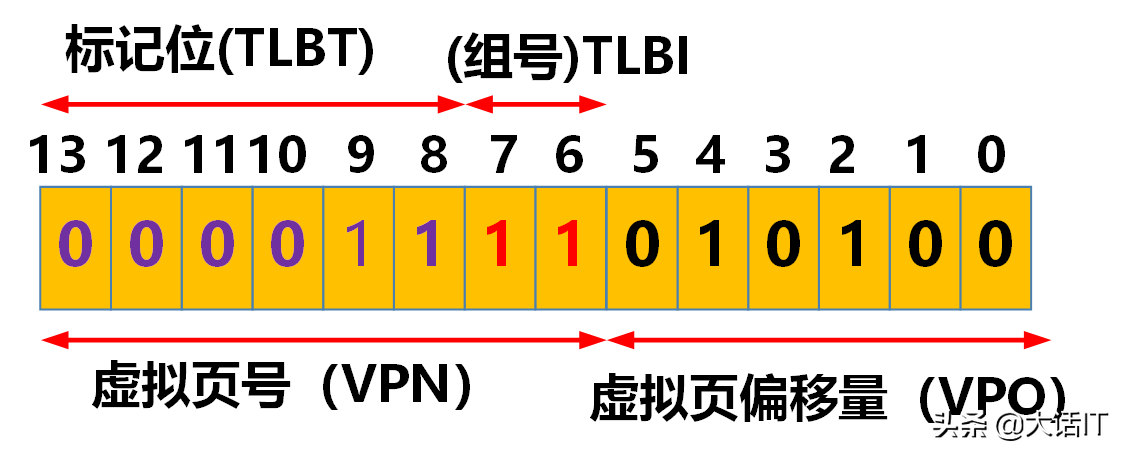
假设 CPU 需访问的虚拟地址为 0 x 03 d 4 0x03d4 0x03d4,该地址的 16 位二进制表示为 0000001111010100 \boldsymbol{0000001111010100} 0000001111010100。由于虚拟地址的长度为 14 14 14 位,因此需舍弃高 2 2 2 位,得到 14 位虚拟地址的二进制表示为 00001111010100 \boldsymbol{00001111010100} 00001111010100,其格式拆分如下图所示。
步骤 1:TLB 查询与命中判定
从上图中可提取:
- TLB 组号(TLBI):二进制为 11 \boldsymbol{11} 11,对应十六进制为 0 x 03 \boldsymbol{0x03} 0x03;
- TLB 标记位(TLBT):二进制为 000011 \boldsymbol{000011} 000011,对应十六进制为 0 x 03 \boldsymbol{0x03} 0x03。
根据 TLBI 与 TLBT 查询 TLB 映射表,查询结果如下图所示。
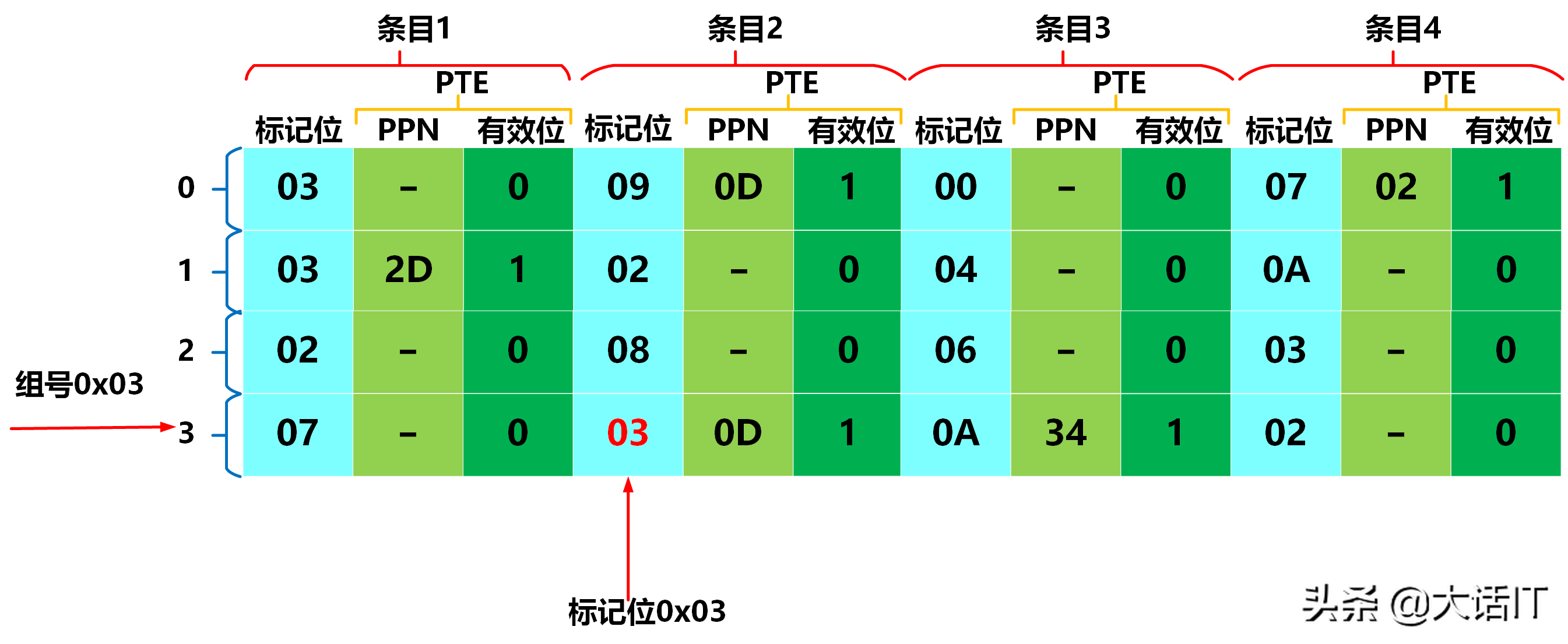
由上图可知,TLB 查询命中,对应的页表项(PTE)中包含:
- 物理页号(PPN): 0 x 0 D \boldsymbol{0x0D} 0x0D;
- 有效位: 1 \boldsymbol{1} 1(表示该虚拟页已加载至物理内存)。
步骤 2:物理地址计算
虚拟页偏移量(VPO)与物理页偏移量(PPO)的数值相等,从虚拟地址格式拆分图中可提取:
- VPO 的二进制表示: 010100 \boldsymbol{010100} 010100;
- VPO 的十六进制表示: 0 x 14 \boldsymbol{0x14} 0x14。
物理地址(PA)由物理页号(PPN)与物理页偏移量(PPO)拼接得到:
- PPN 的二进制表示: 001101 \boldsymbol{001101} 001101;
- PPO 的二进制表示: 010100 \boldsymbol{010100} 010100;
- 拼接后的物理地址二进制表示: 001101010100 \boldsymbol{001101010100} 001101010100;
- 转换为十六进制后,物理地址为 0 x 354 \boldsymbol{0x354} 0x354。
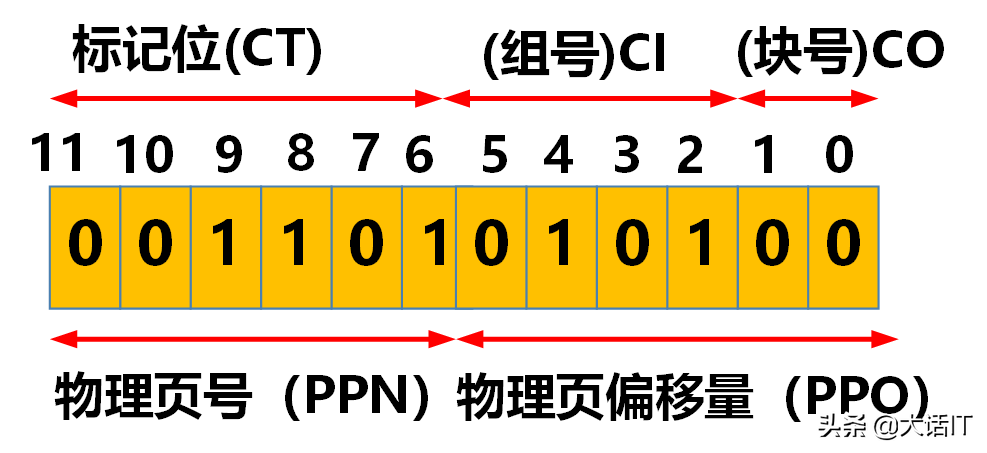
物理地址的格式拆分如下图所示。
步骤 3:高速缓冲查询与数据读取
从上图中可提取物理地址的拆分信息:
- 高速缓冲组号(CI):二进制为 0101 \boldsymbol{0101} 0101,对应十六进制为 0 x 05 \boldsymbol{0x05} 0x05;
- 高速缓冲标记位(CT):二进制为 001101 \boldsymbol{001101} 001101,对应十六进制为 0 x 0 D \boldsymbol{0x0D} 0x0D;
- 块偏移量(CO):二进制为 00 \boldsymbol{00} 00,对应十六进制为 0 x 00 \boldsymbol{0x00} 0x00。
根据 CI、CT 与 CO 查询高速缓冲映射表,查询结果如下图所示。
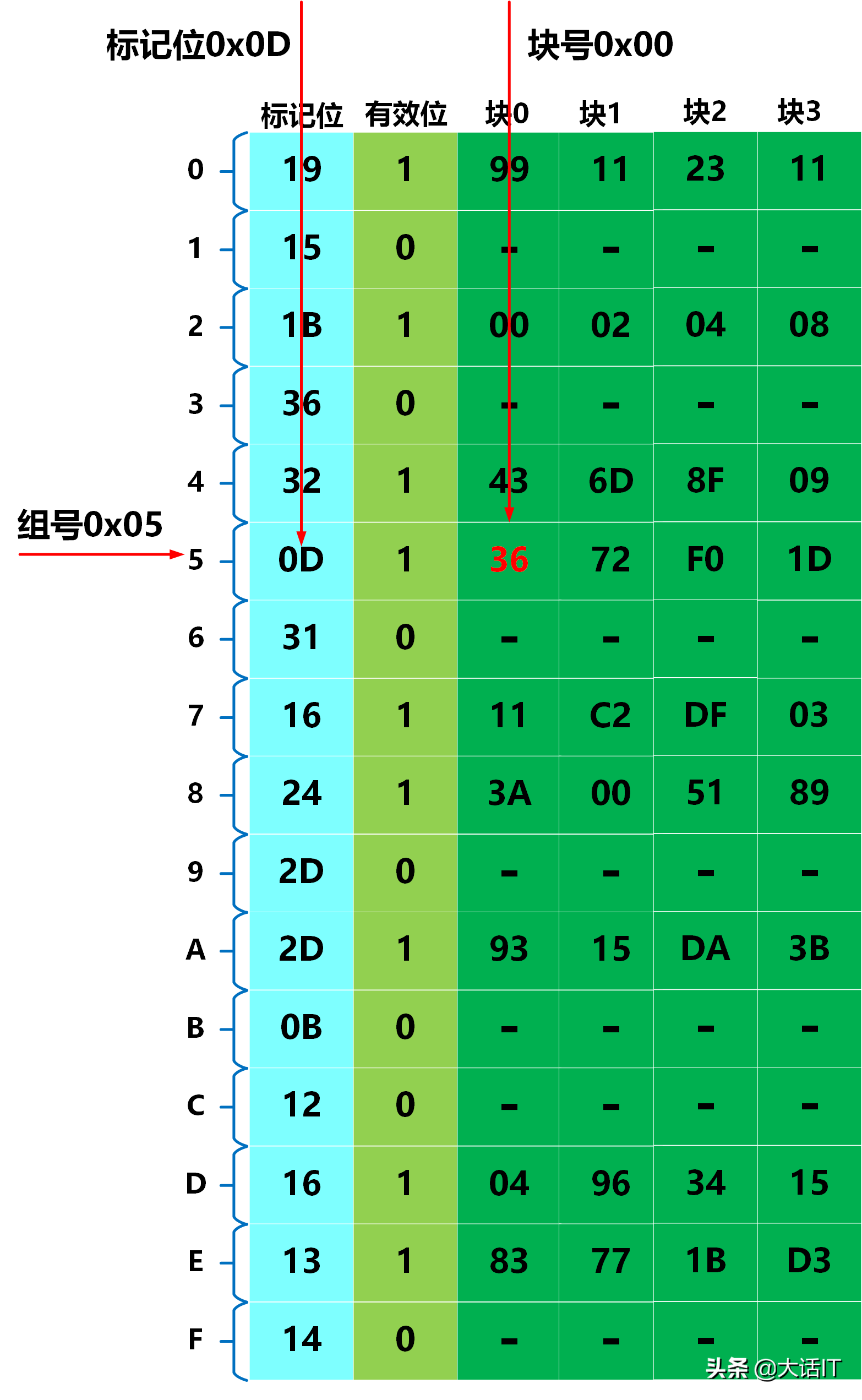
由上图可知,高速缓冲查询命中,对应的存储数据为 0 x 36 \boldsymbol{0x36} 0x36。该数据将被传输至 CPU,完成本次虚拟地址的访问操作。
说明
本实例为 TLB 与高速缓冲均命中的理想场景。在实际系统中,还可能出现 TLB 未命中、高速缓冲未命中、缺页中断等场景,其处理流程可参照本文第 1 章的内容展开推导。
计算机内存管理:虚拟地址与多级页表
TLB 未命中、缺页中断、多级页表及 x86-64 大页模式
前言
本文系统讲解计算机虚拟地址到物理地址的翻译机制,聚焦 TLB 未命中、缺页中断两类典型异常场景的处理流程,深入剖析多级页表的设计思想与实现逻辑,并以 x86-64 架构为例,详细阐述四级页表、大页模式的地址翻译及异常处理机制,同时提供 Linux 系统下大页的配置与验证实操指南。内容兼顾理论原理与工程实践,适用于计算机体系结构、操作系统课程学习及相关工程开发参考。
术语约定与符号说明
术语定义
| 缩写 | 全称 | 译名 | 规范释义 |
|---|---|---|---|
| CR3 | Control Register 3 | 控制寄存器3 | x86/x86-64 架构中存储当前进程页全局目录(PGD)物理基址的寄存器,是多级页表翻译的起始点 |
| L1 Cache | Level 1 Cache | 一级高速缓存 | CPU 核心最紧邻的高速缓存,用于缓存数据与页表项(PTE),降低内存访问延迟 |
| MMU | Memory Management Unit | 内存管理单元 | 硬件模块,负责虚拟地址(VA)到物理地址(PA)的翻译,执行 TLB 查找、页表查询等操作 |
| Offset | Page Offset | 页内偏移量 | 虚拟/物理地址中用于定位页内具体字节的部分,位数由页面大小决定(如 4KB 页对应 12 位),虚拟页内偏移量(VPO)与物理页内偏移量(PPO)完全一致 |
| PGD | Page Global Directory | 页全局目录 | x86-64 四级页表的一级页表,存储页上级目录(PUD)的物理基址与属性信息 |
| PMD | Page Middle Directory | 页中间目录 | x86-64 四级页表的三级页表,存储页表(PT)的物理基址与属性信息 |
| PPN | Physical Page Number | 物理页号 | 物理页框的唯一编号,与页内偏移量拼接可生成完整物理地址 |
| PTE | Page Table Entry | 页表项 | 页表中的基本条目,存储物理页号、有效位、脏位、访问权限位等地址映射与属性信息 |
| PTEA | Page Table Entry Address | 页表项物理地址 | 页表项在物理内存中的地址,由页表基址与虚拟页号(VPN)计算得出 |
| PT | Page Table | 页表 | 多级页表的末级页表,直接存储物理页框号与对应虚拟页的属性信息 |
| PTBR | Page Table Base Register | 页表基址寄存器 | 存储单级页表起始物理地址的寄存器,用于单级页表的地址翻译 |
| PUD | Page Upper Directory | 页上级目录 | x86-64 四级页表的二级页表,存储页中间目录(PMD)的物理基址与属性信息 |
| PS | Page Size Flag | 页面大小标志位 | 页表项中的标志位,置 1 表示当前为大页模式(2MB/1GB),置 0 表示标准页模式(4KB) |
| Swap Space | Swap Partition | 交换分区 | 磁盘上的预留空间,用于存储被换出的物理内存页面,缺页时可重新加载至物理内存 |
| TLB | Translation Lookaside Buffer | 快表 | 高速缓存,存储虚拟页号与物理页号的映射关系,用于加速地址翻译,降低页表查询延迟 |
| VA | Virtual Address | 虚拟地址 | CPU 发起的地址请求,需经 MMU 翻译为物理地址后才能访问实际内存 |
| VPN | Virtual Page Number | 虚拟页号 | 虚拟地址中用于索引页表的部分,对应虚拟页的唯一编号 |
| hugetlbfs | Huge Page File System | 大页文件系统 | Linux 系统中用于管理大页内存的特殊文件系统,进程通过挂载该文件系统申请使用大页 |
符号与格式约定
-
VA [ a : b ] \text{VA}[a:b] VA[a:b]:表示虚拟地址从第 a 位到第 b 位的字段(高位在前,低位在后)
-
∥ \parallel ∥:表示位拼接操作
-
≪ \ll ≪:表示左移操作
-
sizeof ( X ) \text{sizeof}(X) sizeof(X):表示数据类型 X 的字节长度
-
#PF:缺页中断的中断向量标识
一、虚拟地址翻译基础与异常场景
1.1 虚拟地址翻译概念
虚拟地址翻译是 MMU 将 CPU 发起的虚拟地址(VA)转换为物理地址(PA)的过程,是现代操作系统实现内存隔离、地址空间扩展的关键机制。在翻译过程中,TLB 作为页表项(PTE)的高速缓存,可大幅减少页表查询的内存访问次数,降低地址翻译延迟;而 TLB 未命中与缺页中断是翻译过程中两类最典型的异常场景,其触发条件与处理逻辑直接决定内存访问效率。
1.2 TLB 未命中(TLB Miss)
1.2.1 触发条件
当 CPU 发起虚拟地址访问请求时,MMU 提取虚拟地址中的虚拟页号(VPN)查询 TLB:若 TLB 中不存在与该 VPN 匹配的有效条目,则判定为 TLB 未命中。其特征为:目标虚拟页已加载至物理内存(对应 PTE 的有效位为 1),仅 PTE 未被缓存至 TLB,异常仅与 TLB 的缓存状态相关,与虚拟页是否在物理内存中无关。
1.2.2 处理流程(硬件自动完成)
TLB 未命中无需触发 CPU 中断,由 MMU 与 L1 高速缓存协同完成处理,具体步骤如下:
-
计算页表项物理地址(PTEA):MMU 读取页表基址寄存器(单级页表场景为 PTBR,多级页表场景为 CR3 指向的各级页表基址)中的页表起始物理地址,结合 VPN 计算目标 PTE 的物理地址: PTEA = 页表基址 + VPN × sizeof(PTE) \text{PTEA} = \text{页表基址} + \text{VPN} \times \text{sizeof(PTE)} PTEA=页表基址+VPN×sizeof(PTE)。其中 sizeof(PTE) \text{sizeof(PTE)} sizeof(PTE) 由硬件架构固定(如 x86 架构为 4 字节,x86-64 架构为 8 字节)。
-
从 L1 缓存/物理内存获取 PTE:MMU 依据计算得到的 PTEA 访问 L1 缓存:若 L1 缓存命中,则直接将缓存中的 PTE 传输至 MMU;若 L1 缓存未命中,则由 L1 缓存控制器向物理内存发起读取请求,将 PTE 加载至 L1 缓存后,再传输至 MMU。
-
更新 TLB 缓存:MMU 接收 PTE 后,将 VPN 与 PTE 中的物理页号(PPN)及属性信息的映射关系写入 TLB 的空闲条目;若 TLB 无空闲条目,则按 LRU(最近最少使用)或 FIFO(先进先出)等替换算法淘汰 TLB 中旧的无效或低优先级条目,再写入新的映射关系。
-
完成物理地址翻译:MMU 提取 PTE 中的物理页号(PPN),与虚拟地址中的页内偏移量(VPO)拼接生成物理地址(PA): PA = ( PPN × 页面大小 ) + VPO \text{PA} = (\text{PPN} \times \text{页面大小}) + \text{VPO} PA=(PPN×页面大小)+VPO。
-
访问目标物理地址:MMU 将生成的 PA 发送至 L1 缓存,查询对应数据后传输至 CPU,完成本次内存访问。
1.2.3 关键特性
-
无中断开销:全程由硬件自动处理,无需操作系统介入,处理延迟仅为数十个时钟周期(远低于缺页中断)。
-
缓存一致性要求:当操作系统修改物理内存中的 PTE(如更新权限、修改映射关系)时,必须同步刷新 TLB 中对应的条目,避免旧的 PTE 映射残留导致地址翻译错误(即 TLB 污染)。常见刷新方式包括单条目刷新(如 x86-64 架构的 INVLPG 指令)与全量刷新(如重加载 CR3 寄存器)。
1.3 缺页中断(Page Fault,#PF)
1.3.1 触发条件
缺页中断的触发需同时满足两个条件:① MMU 通过 TLB 查找或内存页表查询,获取到目标虚拟页对应的 PTE;② 该 PTE 的有效位(Present Bit)为 0,表示目标虚拟页未加载至物理内存(其内容可能存储在磁盘交换分区、可执行文件或其他外部存储介质中)。其特征为:目标虚拟页不在物理内存中,必须通过磁盘 I/O 或其他外部加载方式将页面载入物理内存后,才能完成地址翻译。
若 MMU 未找到目标虚拟页对应的 PTE(如访问非法虚拟地址),则不属于缺页中断,而是内存访问错误,操作系统会直接终止进程并抛出异常(如 Linux 系统的 SIGSEGV 信号)。
1.3.2 处理流程(操作系统中断处理)
缺页中断属于软中断,需 CPU 暂停当前进程执行,切换至内核态执行操作系统的缺页中断处理程序,具体步骤如下:
-
触发并响应中断:MMU 检测到 PTE 有效位为 0 后,向 CPU 发送中断信号;CPU 收到信号后,暂停当前指令执行,保存当前进程的上下文(如通用寄存器、程序计数器、状态寄存器等),并依据中断向量表跳转至缺页中断处理程序入口。
-
判定缺页类型:中断处理程序首先解析触发中断的虚拟地址,校验该地址是否属于当前进程的合法虚拟地址空间:① 有效缺页:虚拟地址合法,仅页面未加载至物理内存;② 无效缺页:虚拟地址非法(如野指针访问、越界访问),此时操作系统直接终止当前进程,并返回内存访问错误信息。
-
分配物理内存页框:对于有效缺页,操作系统从物理内存的空闲页框链表中,分配一个符合要求的物理页框,用于存储即将加载的虚拟页内容。
-
加载页面内容:根据虚拟页的类型,从对应存储介质中读取页面内容至分配的物理页框:① 文件映射页(如可执行文件代码段、数据段):从磁盘文件的对应偏移量读取内容;② 交换页(此前被换出至交换分区的页面):从磁盘交换分区读取之前保存的内容;③ 匿名页(如堆、栈空间):将页面初始化为 0(避免残留旧数据导致安全问题)。
-
更新页表项(PTE):操作系统更新目标虚拟页对应的 PTE 信息:① 将有效位(Present Bit)置为 1;② 写入分配的物理页框对应的物理页号(PPN);③ 设置页面访问权限位(如读/写权限、用户态/内核态访问控制)、脏位(初始为 0)、访问位(初始为 1)等属性。
-
刷新 TLB 缓存:若 TLB 中存在该虚拟页对应的无效条目,操作系统需执行 TLB 刷新操作清除该条目,避免旧的无效映射干扰后续地址翻译。
-
恢复上下文并重试:操作系统恢复之前保存的进程上下文,将程序计数器重置为触发缺页中断的指令地址;CPU 重新执行该访问指令,此时虚拟页已加载至物理内存,PTE 有效,地址翻译流程可正常完成。
1.3.3 关键特性
-
高延迟特性:处理过程涉及磁盘 I/O(若需加载外部存储内容),延迟通常为毫秒级,远高于 TLB 未命中的数十个时钟周期(微秒级以下)。
-
页面置换机制:若物理内存无空闲页框,操作系统需按页面置换算法(如 LRU、Clock、NRU 等)选择一个“牺牲页”换出至磁盘交换分区:若牺牲页的脏位为 1(表示页面内容被修改过),则需先将页面内容写回磁盘;若脏位为 0(内容未修改),则可直接丢弃,无需写回操作。
1.4 TLB 未命中与缺页中断的差异
| 对比 | TLB 未命中 | 缺页中断 |
|---|---|---|
| 触发本质 | PTE 未缓存至 TLB,虚拟页已在物理内存 | 虚拟页未加载至物理内存,PTE 有效位为 0 |
| PTE 有效位状态 | 有效位 = 1 | 有效位 = 0 |
| 处理主体 | MMU + L1 高速缓存(纯硬件) | CPU + 操作系统(硬件触发 + 软件处理) |
| 是否触发中断 | 否,无中断上下文切换开销 | 是,属于软中断,需切换至内核态 |
| 处理延迟 | 低(数十个时钟周期,微秒级以下) | 高(毫秒级,含磁盘 I/O 开销) |
| 主要操作 | 读取 PTE 并更新 TLB 缓存 | 分配页框、加载页面、更新 PTE、刷新 TLB |
二、多级页表的地址翻译机制
2.1 多级页表的设计背景
2.1.1 单级页表的固有缺陷
单级页表要求为进程的整个虚拟地址空间分配连续的物理内存用于存储页表项,即使大部分虚拟地址未被实际使用,也需预留完整的页表空间。例如,x86 32 位架构下,虚拟地址空间为 4GB,若采用 4KB 标准页,需 2 20 2^{20} 220 个 PTE(每个 4 字节),对应 4MB 连续物理内存;对于 64 位架构的超大虚拟地址空间,单级页表所需的连续物理内存将达到天文数字,远超实际硬件承载能力,造成严重的内存资源浪费。
2.1.2 多级页表的设计思想
多级页表通过“分层索引、按需分配”的设计,解决单级页表的内存浪费问题,思想包括三点:① 页表分层:将虚拟地址划分为多个页表索引字段,每个字段对应一级页表的索引,末级页表项直接指向物理页框,非末级页表项指向其下一级页表的物理基址;② 按需分配:各级页表均为独立的物理页面,仅当存在有效虚拟地址映射时,才为对应层级的页表分配物理内存,无有效映射的层级无需分配页表;③ 基址链式关联:通过页表基址寄存器(如 CR3)与各级页表项的指针,构建从顶级页表到末级页表的链式索引关系,实现地址翻译的层级遍历。
2.2 虚拟地址划分规则(以 x86-32 二级页表为例)
x86-32 架构采用二级页表设计,页面大小为 4KB( 2 12 2^{12} 212 字节),32 位虚拟地址被划分为三个字段,具体划分规则如下:
| 字段名称 | 位数 | 作用 |
|---|---|---|
| 页目录号(PDI) | 10 | 用于索引一级页表(页目录表,PDT)中的页目录项(PDE) |
| 页表号(PTI) | 10 | 用于索引二级页表(PT)中的页表项(PTE) |
| 页内偏移量(Offset) | 12 | 用于定位物理页框内的具体字节,与物理页内偏移量完全一致 |
虚拟地址结构可表示为:
Virtual Address = [ PDI ( 10 bit ) ] ⏟ 页内偏移量 页目录号(一级页表索引) ∥ [ PTI ( 10 bit ) ] ⏟ 页内偏移量 页表号(二级页表索引) ∥ [ Offset ( 12 bit ) ] ⏟ 页内偏移量(定位页内字节) ∣ ∣ \text{Virtual Address} = \underbrace{[\text{PDI}(10\,\text{bit})]}_{\vphantom{\text{页内偏移量}}\text{页目录号(一级页表索引)}} \parallel \underbrace{[\text{PTI}(10\,\text{bit})]}_{\vphantom{\text{页内偏移量}}\text{页表号(二级页表索引)}} \parallel \underbrace{[\text{Offset}(12\,\text{bit})]}_{\text{页内偏移量(定位页内字节)}}|| Virtual Address=页内偏移量页目录号(一级页表索引) [PDI(10bit)]∥页内偏移量页表号(二级页表索引) [PTI(10bit)]∥页内偏移量(定位页内字节) [Offset(12bit)]∣∣
2.3 二级页表的地址翻译流程(硬件自动完成)
x86-32 二级页表的地址翻译由 MMU 硬件自动完成,依赖 CR3 寄存器存储页目录表(PDT)的物理基址,具体流程如下:
-
读取一级页表基址:MMU 从 CR3 寄存器中读取页目录表(PDT)的物理起始地址。
-
查找页目录项(PDE):结合虚拟地址中的页目录号(PDI),计算目标页目录项的物理地址: PDE Address = PDT Base + PDI × 4 \text{PDE Address} = \text{PDT Base} + \text{PDI} \times 4 PDE Address=PDT Base+PDI×4(x86 架构 PTE 为 4 字节);读取该页目录项,若其有效位为 0,则触发缺页中断;若有效,则提取其中存储的二级页表(PT)物理基址。
-
查找页表项(PTE):结合虚拟地址中的页表号(PTI),计算目标页表项的物理地址: PTE Address = PT Base + PTI × 4 \text{PTE Address} = \text{PT Base} + \text{PTI} \times 4 PTE Address=PT Base+PTI×4;读取该页表项,若其有效位为 0,则触发缺页中断;若有效,则提取其中存储的物理页号(PPN)。
-
拼接物理地址:将提取的物理页号(PPN)与虚拟地址中的页内偏移量(Offset)拼接,生成完整物理地址: Physical Address = ( PPN × 4096 ) + Offset \text{Physical Address} = (\text{PPN} \times 4096) + \text{Offset} Physical Address=(PPN×4096)+Offset(4096 为 4KB 页面大小)。
-
访问物理地址:MMU 将生成的物理地址发送至 L1 高速缓存,查询对应数据后传输至 CPU,完成本次内存访问。
2.4 多级页表与 TLB 的协同机制
多级页表的分层索引会增加内存访问次数(如二级页表需 2 次内存访问查询页表项,三级页表需 3 次),导致地址翻译延迟上升。TLB 作为高速缓存,可有效弥补这一缺陷,二者的协同机制如下:
-
TLB 缓存内容:TLB 条目存储“虚拟地址的多级索引组合(如 PDI+PTI)”与“物理页号(PPN)”的映射关系,同时包含页面权限、有效位等关键属性,无需区分页表层级。
-
TLB 命中场景:MMU 查询 TLB 时,若找到匹配的有效条目,直接提取 PPN 拼接物理地址,跳过多级页表的层级遍历过程,将翻译延迟降低至 1-2 个时钟周期。
-
TLB 未命中场景:MMU 执行完整的多级页表翻译流程,遍历各级页表获取 PPN 后,将“多级索引组合+PPN”的映射关系写入 TLB,供后续相同虚拟地址访问时复用。
2.5 多级页表的优势与适用场景
2.5.1 优势
| 类型 | 说明 |
|---|---|
| 节省物理内存 | 仅为存在有效映射的虚拟地址分配各级页表空间,无映射的虚拟地址对应的页表层级无需分配,大幅降低页表占用的物理内存。例如,x86-32 架构下,若进程仅使用 1MB 虚拟内存,二级页表仅需 1 个页目录表(4KB)+ 1 个页表(4KB),共 8KB 物理内存,远低于单级页表的 4MB。 |
| 支持超大虚拟地址空间 | 通过分层索引,可适配 64 位架构的超大虚拟地址空间(如 x86-64 架构的 48 位有效虚拟地址),而单级页表无法应对如此庞大的索引规模。 |
| 动态适配地址空间变化 | 各级页表可按需创建或销毁,能够灵活适配进程虚拟地址空间的动态变化(如堆/栈空间的增长与收缩、内存映射的动态建立与释放)。 |
2.5.2 适用场景
多级页表是现代计算机系统的主流页表方案,适用于虚拟地址空间较大的系统(32 位及以上操作系统),包括个人计算机、服务器、嵌入式系统等各类采用分页机制的计算设备。
2.6 多级页表的扩展逻辑(三级/四级页表)
多级页表的扩展遵循“增加索引字段、延长页表链”的逻辑,通过新增页表层级适配更大的虚拟地址空间:
-
三级页表:在二级页表基础上增加“页上级目录表”,虚拟地址划分为“页上级目录号 + 页目录号(PDI) + 页表号(PTI) + 页内偏移量”四个字段。翻译流程为:页上级目录基址 → 页上级目录项 → 页目录表(PDT)基址 → 页目录项(PDE) → 页表(PT)基址 → 页表项(PTE) → 物理页号(PPN) → 物理地址。
-
四级页表:在三级页表基础上再增加“页全局目录表”,虚拟地址新增“页全局目录号”字段,页表基址查询链进一步延长。x86-64 架构采用的正是四级页表设计,以适配 48 位有效虚拟地址空间。
三、x86-64 架构四级页表及异常处理
3.1 x86-64 四级页表的结构与地址划分
3.1.1 四级页表的组成(从顶级到末级)
x86-64 架构采用四级页表设计,各级页表均为 4KB 物理页面,每个页表项占 8 字节,因此每页可存储 512 个页表项(4KB / 8 字节 = 512)。四级页表的组成从顶级到末级依次为:
-
页全局目录(PGD):一级页表,每个页表项(PGD 项)存储二级页表(PUD)的物理基址与属性信息。
-
页上级目录(PUD):二级页表,每个页表项(PUD 项)存储三级页表(PMD)的物理基址与属性信息。
-
页中间目录(PMD):三级页表,每个页表项(PMD 项)存储四级页表(PT)的物理基址与属性信息(标准页模式)或大页物理基址(大页模式)。
-
页表(PT):四级页表(末级页表),每个页表项(PT 项)存储目标虚拟页对应的物理页号(PPN)与属性信息。
3.1.2 虚拟地址划分(48 位有效位)
x86-64 架构定义的有效虚拟地址宽度为 48 位(VA[47:0]),超出 48 位的地址部分按符号扩展处理。结合四级页表结构,48 位虚拟地址被划分为 5 个字段,具体划分规则如下:
| 字段名称 | 位数 | 作用 |
|---|---|---|
| PGD 索引 | 9 | 索引页全局目录(PGD),定位对应 PUD 页表的物理基址 |
| PUD 索引 | 9 | 索引页上级目录(PUD),定位对应 PMD 页表的物理基址 |
| PMD 索引 | 9 | 索引页中间目录(PMD),定位对应 PT 页表的物理基址(标准页模式)或大页物理基址(大页模式) |
| PT 索引 | 9 | 索引页表(PT,末级),定位对应虚拟页的物理页号(PPN) |
| 页内偏移量 | 12 | 定位物理页框内的具体字节,对应 4KB 页面大小( 2 12 2^{12} 212 字节) |
虚拟地址结构可表示为:
Virtual Address = [ PGD Index ( 9 bit ) ] ⏟ 一级页表索引 ∥ [ PUD Index ( 9 bit ) ] ⏟ 二级页表索引 ∥ [ PMD Index ( 9 bit ) ] ⏟ 三级页表索引 ∥ [ PT Index ( 9 bit ) ] ⏟ 四级页表索引 ∥ [ Offset ( 12 bit ) ] ⏟ 页内偏移 ∣ ∣ \text{Virtual Address} = \underbrace{[\text{PGD Index}(9\,\text{bit})]}_{\text{一级页表索引}} \parallel \underbrace{[\text{PUD Index}(9\,\text{bit})]}_{\text{二级页表索引}} \parallel \underbrace{[\text{PMD Index}(9\,\text{bit})]}_{\text{三级页表索引}} \parallel \underbrace{[\text{PT Index}(9\,\text{bit})]}_{\text{四级页表索引}} \parallel \underbrace{[\text{Offset}(12\,\text{bit})]}_{\text{页内偏移}}|| Virtual Address=一级页表索引 [PGD Index(9bit)]∥二级页表索引 [PUD Index(9bit)]∥三级页表索引 [PMD Index(9bit)]∥四级页表索引 [PT Index(9bit)]∥页内偏移 [Offset(12bit)]∣∣
3.2 四级页表的正常翻译流程
x86-64 四级页表的地址翻译由 MMU 硬件自动完成,依赖 CR3 寄存器(存储当前进程 PGD 页表的物理基址),具体流程如下:
-
计算 PGD 项地址: PGD Entry Address = CR3 Value + PGD Index × 8 \text{PGD Entry Address} = \text{CR3 Value} + \text{PGD Index} \times 8 PGD Entry Address=CR3 Value+PGD Index×8(8 字节为 PTE 长度);读取该 PGD 项,提取其中存储的 PUD 页表物理基址(若 PGD 项有效位为 0,触发缺页中断)。
-
计算 PUD 项地址: PUD Entry Address = PUD Base + PUD Index × 8 \text{PUD Entry Address} = \text{PUD Base} + \text{PUD Index} \times 8 PUD Entry Address=PUD Base+PUD Index×8;读取该 PUD 项,提取其中存储的 PMD 页表物理基址(若 PUD 项有效位为 0,触发缺页中断)。
-
计算 PMD 项地址: PMD Entry Address = PMD Base + PMD Index × 8 \text{PMD Entry Address} = \text{PMD Base} + \text{PMD Index} \times 8 PMD Entry Address=PMD Base+PMD Index×8;读取该 PMD 项,提取其中存储的 PT 页表物理基址(标准页模式,若 PMD 项有效位为 0,触发缺页中断)。
-
计算 PT 项地址: PT Entry Address = PT Base + PT Index × 8 \text{PT Entry Address} = \text{PT Base} + \text{PT Index} \times 8 PT Entry Address=PT Base+PT Index×8;读取该 PT 项,提取其中存储的物理页号(PPN,若 PT 项有效位为 0,触发缺页中断)。
-
拼接物理地址:将 PPN 与页内偏移量拼接,生成完整物理地址: Physical Address = ( PPN × 4096 ) + Offset \text{Physical Address} = (\text{PPN} \times 4096) + \text{Offset} Physical Address=(PPN×4096)+Offset(4096 为 4KB 页面大小)。
3.3 四级页表中的页表项缺失处理机制
x86-64 四级页表的页表项缺失分为“高层页表项缺失(PGD/PUD/PMD 项缺失)”与“底层页表项缺失(PT 项缺失)”两类,均通过操作系统的缺页中断处理程序完成修复,差异在于缺失项对应的层级及需分配的资源类型。
3.3.1 触发条件
在四级页表的层级遍历过程中,若任意层级的页表项有效位为 0,且触发中断的虚拟地址属于当前进程的合法虚拟地址空间(经地址合法性校验通过),则触发缺页中断;若虚拟地址非法,则直接终止进程并抛出内存访问错误。
3.3.2 高层页表项缺失处理(以 PUD 项缺失为例)
高层页表项(PGD/PUD/PMD)缺失的含义是“其下一级页表未分配物理内存”,而非虚拟页未加载,处理流程如下:
-
触发缺页中断,CPU 暂停当前进程执行,保存进程上下文并跳转至缺页中断处理程序。
-
操作系统解析触发中断的虚拟地址,通过地址字段拆分,确认缺失页表项所属的层级(此处为 PUD 项)及对应的下一级页表类型(此处为 PMD 页表)。
-
从物理内存空闲页框链表中分配一个 4KB 物理页框,用于存储下一级页表(此处为 PMD 页表)。
-
初始化新分配的页表:将页表内所有页表项的有效位置为 0,确保初始状态下无无效映射。
-
更新缺失的高层页表项(此处为 PUD 项):写入新分配的下一级页表(PMD)物理基址,将有效位置为 1,并设置对应的访问权限位(如内核态可读写、用户态不可访问等)。
-
刷新 TLB:清除 TLB 中可能存在的该虚拟地址对应的无效条目,避免旧映射干扰。
-
恢复进程上下文,CPU 重新执行触发缺页的指令,此时缺失的高层页表项已修复,翻译流程可继续向下遍历。
PGD 项、PMD 项缺失的处理流程与上述逻辑完全一致,仅需适配对应的页表层级与下一级页表类型。
3.3.3 底层页表项缺失处理(PT 项缺失)
PT 项(末级页表项)缺失的含义是“目标虚拟页未加载至物理内存”,处理流程与通用缺页中断处理逻辑一致,具体步骤如下:
-
触发缺页中断,CPU 保存进程上下文并跳转至中断处理程序;程序首先校验触发中断的虚拟地址合法性,确认属于有效缺页。
-
从物理内存空闲页框链表中分配一个 4KB 物理页框,用于存储目标虚拟页内容。
-
根据虚拟页类型,填充页面内容:① 匿名页(如堆、栈空间):将页面初始化为 0;② 文件映射页(如可执行文件代码段、数据段):从磁盘文件的对应偏移量读取内容至物理页框;③ 交换页(此前被换出至交换分区):从磁盘交换分区读取之前保存的内容至物理页框。
-
更新 PT 项:写入分配的物理页号(PPN),将有效位置为 1,并设置页面访问权限位、脏位(初始为 0)、访问位(初始为 1)等属性。
-
刷新 TLB,清除该虚拟地址对应的无效条目。
-
恢复进程上下文,CPU 重新执行访问指令,此时虚拟页已加载,翻译流程正常完成。
3.3.4 页面置换适配逻辑
若物理内存无空闲页框可供分配(无论是高层页表还是虚拟页),操作系统将执行页面置换流程:① 按页面置换算法(如 LRU、Clock 算法)从当前进程或系统全局的物理页框中选择一个“牺牲页”;② 检查牺牲页的脏位:若脏位为 1,需先将页面内容写回磁盘交换分区;若脏位为 0,可直接丢弃页面内容;③ 更新牺牲页对应的 PTE:将有效位置为 0,记录其在交换分区中的存储位置(若为交换页);④ 释放牺牲页对应的物理页框,用于分配给缺失的页表或虚拟页,后续流程按正常缺失处理逻辑执行。
四、x86-64 架构大页模式(2MB/1GB)
4.1 大页模式的原理与分类
4.1.1 设计目标
在 4KB 标准页模式下,x86-64 四级页表的翻译需 4 次内存访问(TLB 未命中场景),对于大内存应用(如数据库、虚拟化、大数据分析),会产生大量页表项,导致 TLB 命中率下降、地址翻译延迟上升。大页模式通过“合并连续页框、简化页表层级、扩大单个 TLB 条目映射范围”的设计,优化内存访问效率:① 合并连续页框:将多个连续的 4KB 标准页合并为一个大页(2MB/1GB),减少页表项数量;② 简化页表层级:大页对应的页表项在非末级页表(PMD/PGD)中直接指向大页物理基址,跳过后续层级的页表查询;③ 提升 TLB 命中率:单个 TLB 条目可映射 2MB/1GB 地址空间,大幅减少 TLB 条目占用,降低 TLB 未命中概率。
4.1.2 大页分类与规格
x86-64 架构支持两种大页规格,分别为 2MB 大页与 1GB 大页,具体参数如下:
| 大页规格 | 等效标准页数量 | 页表层级简化 | 虚拟地址字段划分 | 适用场景 |
|---|---|---|---|---|
| 2MB 大页 | 512 个 4KB 页(512×4KB=2MB) | 跳过末级 PT 层,仅需 PGD→PUD→PMD 三级遍历 | PGD(9) + PUD(9) + PMD(9) + 偏移(21)(21 位偏移对应 2 21 = 2 M B 2^{21}=2MB 221=2MB) | Web 服务器、数据库服务、中间件等需要连续内存访问的应用 |
| 1GB 大页 | 262144 个 4KB 页(262144×4KB=1GB) | 跳过 PUD、PMD、PT 三层,仅需 PGD 一级遍历 | PGD(9) + 偏移(39)(39 位偏移对应 2 39 = 1 G B 2^{39}=1GB 239=1GB) | KVM 虚拟化(虚拟机内存分配)、大数据分析(海量数据缓存)、高性能计算等超大内存需求场景 |
注:大页的页内偏移位数由页面大小决定,计算公式为 偏移位数 = log 2 ( 大页大小 ) \text{偏移位数} = \log_2(\text{大页大小}) 偏移位数=log2(大页大小),如 2MB 大页的偏移位数为 log 2 ( 2 × 1024 × 1024 ) = 21 \log_2(2×1024×1024)=21 log2(2×1024×1024)=21 位。
4.2 大页模式的地址翻译流程
4.2.1 2MB 大页翻译流程
2MB 大页模式通过 PMD 项直接指向大页物理基址,跳过后续 PT 层遍历,具体流程如下:
-
虚拟地址划分:按“PGD(9 位) + PUD(9 位) + PMD(9 位) + 偏移(21 位)”拆分虚拟地址。
-
层级遍历至 PMD 层:MMU 从 CR3 读取 PGD 基址,结合 PGD 索引查询 PGD 项,获取 PUD 基址;再结合 PUD 索引查询 PUD 项,获取 PMD 基址。
-
查询 PMD 项:结合 PMD 索引计算 PMD 项地址,读取该 PMD 项;检查 PMD 项的 PS 标志位(页面大小标志位),若 PS=1,确认当前为 2MB 大页模式,提取 PMD 项中存储的 2MB 大页物理基址(该基址按 2MB 对齐,低 21 位为 0)。
-
拼接物理地址:将 2MB 大页物理基址与虚拟地址中的 21 位偏移量拼接,生成
4.2.1 2MB 大页翻译流程(续)
- 拼接物理地址:将 2MB 大页物理基址与虚拟地址中的 21 位偏移量拼接,生成完整物理地址:
Physical Address = ( Large Page Base ≪ 21 ) + Offset \text{Physical Address} = (\text{Large Page Base} \ll 21) + \text{Offset} Physical Address=(Large Page Base≪21)+Offset
其中 $ \text{Large Page Base} $ 为 PMD 项中存储的大页基址(高位有效,低 21 位为 0),$ \text{Offset} $ 为虚拟地址的低 21 位偏移量。 - 访问物理地址:MMU 将生成的物理地址发送至 L1 缓存,查询数据后传输至 CPU,完成内存访问。
4.2.2 1GB 大页翻译流程
1GB 大页模式通过 PGD 项直接指向大页物理基址,跳过 PUD、PMD、PT 三层遍历,具体流程如下:
- 虚拟地址划分:按 PGD(9 位) + 偏移(39 位) 拆分虚拟地址,39 位偏移量对应 2 39 = 1 GB 2^{39}=1\,\text{GB} 239=1GB 地址空间。
- 查询 PGD 项:MMU 从 CR3 寄存器读取 PGD 页表物理基址,结合 PGD 索引计算 PGD 项地址;读取该 PGD 项,检查 PS 标志位,若 $ \text{PS}=1 $,确认当前为 1GB 大页模式,提取 PGD 项中存储的 1GB 大页物理基址(该基址按 1GB 对齐,低 39 位为 0)。
- 拼接物理地址:将 1GB 大页物理基址与虚拟地址中的 39 位偏移量拼接,生成完整物理地址:
Physical Address = ( Large Page Base ≪ 39 ) + Offset \text{Physical Address} = (\text{Large Page Base} \ll 39) + \text{Offset} Physical Address=(Large Page Base≪39)+Offset - 访问物理地址:MMU 将物理地址发送至缓存/内存,读取数据返回 CPU,完成访问。
4.3 大页模式的异常处理机制
4.3.1 触发条件
大页模式下的缺页中断触发条件与标准页模式一致:翻译过程中对应层级页表项(2MB 大页为 PMD 项,1GB 大页为 PGD 项)的有效位为 0,且虚拟地址属于进程合法地址空间。
4.3.2 2MB 大页 PMD 项缺失处理
- 触发缺页中断,CPU 保存当前进程上下文,跳转至内核态缺页中断处理程序。
- 解析虚拟地址:拆分地址字段,检测 PMD 项的 PS 标志位配置,确认当前为 2MB 大页模式。
- 分配连续物理页框:从物理内存中分配 512 个连续的 4KB 页框,且起始地址需按 2MB 对齐;若内存碎片化严重无足够连续页框,则执行页面置换流程释放连续内存。
- 填充大页内容:根据虚拟页类型加载数据:
- 匿名页(堆/栈):将 2MB 连续内存初始化为 0;
- 文件映射页:从磁盘文件对应偏移量读取 2MB 数据至物理内存;
- 交换页:从磁盘交换分区读取之前换出的 2MB 数据。
- 更新 PMD 项:写入 2MB 大页的物理基址,将有效位设为 1,PS 标志位设为 1,同时配置访问权限位(读/写/执行)、脏位、访问位等属性。
- 刷新 TLB:执行 TLB 刷新操作,清除该虚拟地址对应的无效条目,避免旧映射干扰。
- 恢复上下文并重试:加载进程上下文,重置程序计数器至触发缺页的指令,CPU 重新执行访问操作,此时大页映射已建立,翻译流程正常完成。
4.3.3 1GB 大页 PGD 项缺失处理
处理逻辑与 2MB 大页一致,差异仅在于内存分配与页表项更新:
- 分配 262144 个连续的 4KB 页框,起始地址按 1GB 对齐;
- 更新 PGD 项:写入 1GB 大页物理基址,有效位设为 1,PS 标志位设为 1,配置对应权限属性。
4.3.4 大页页面置换适配逻辑
大页模式对内存连续性要求极高,无足够连续页框时,操作系统执行以下适配流程:
- 遍历空闲页框链表,优先查找满足对齐要求的连续内存块;
- 若无可用连续块,则按 LRU 算法选择部分标准页或小规格大页执行置换,释放连续内存空间;
- 部分服务器操作系统支持 大页内存预留机制,在系统启动时预先分配指定大小的连续内存池,专供大页分配使用,避免运行时内存碎片化导致的分配失败。
4.4 大页模式的优势与限制
4.4.1 优势
- 降低地址翻译延迟:2MB 大页减少 1 次内存访问,1GB 大页减少 3 次内存访问,TLB 未命中时的翻译效率提升显著;
- 减少页表内存占用:映射 1GB 内存时,4KB 标准页需 262144 个 PT 项(占用 2MB 内存),而 1GB 大页仅需 1 个 PGD 项(占用 8 字节);
- 提升 TLB 命中率:单个 TLB 条目可映射更大地址空间,相同 TLB 容量下,大页模式可缓存更多虚拟地址映射,大幅降低 TLB 未命中概率;
- 优化连续内存访问性能:大内存应用(如数据库、虚拟化)的连续数据访问可减少缓存行切换与地址翻译次数,提升整体吞吐量。
4.4.2 限制
- 内存连续性要求严苛:内存碎片化严重时,无法分配足够大的连续页框,导致大页分配失败;
- 内存灵活性降低:大页分配后无法动态拆分,适用于批量连续内存访问场景,不适合小内存、离散访问场景;
- 操作系统配置依赖:需手动启用大页功能(如 Linux 的 hugetlbfs 文件系统),部分应用需修改代码适配大页内存分配接口;
- 内存浪费风险:若应用实际内存需求小于大页尺寸,未使用的大页空间会被闲置,造成内存资源浪费。
5 Linux 系统大页配置与验证(实操)
5.1 前置条件
- CPU 支持:2MB 大页需 CPU 开启 PSE(Page Size Extension) 特性,1GB 大页需开启 PDPE1GB 特性;
- 权限要求:所有配置操作需使用
root用户或通过sudo提升权限; - 系统兼容性:主流 Linux 发行版(CentOS/RHEL、Ubuntu、Debian)均支持大页配置,配置文件路径略有差异。
5.2 检查 CPU 大页支持性
通过读取 /proc/cpuinfo 文件,检查 CPU 是否支持对应的大页特性:
# 检查 2MB 大页支持(PSE 特性)
grep pse /proc/cpuinfo
# 检查 1GB 大页支持(PDPE1GB 特性)
grep pdpe1gb /proc/cpuinfo
若输出结果包含对应字段(如 flags : ... pse ...),则表示 CPU 支持该规格大页;无输出则不支持。
5.3 临时配置(重启失效)
临时配置无需修改系统文件,配置效果在系统重启后丢失,适用于测试场景。
5.3.1 配置 2MB 大页
# 分配 1024 个 2MB 大页(总计 2GB)
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
5.3.2 配置 1GB 大页
# 分配 4 个 1GB 大页(总计 4GB)
echo 4 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
5.4 永久配置(重启生效)
5.4.1 sysctl 配置(推荐,适用于 2MB 大页)
- 编辑
/etc/sysctl.conf配置文件,添加大页配置参数:
vi /etc/sysctl.conf
- 追加以下内容:
# 分配 1024 个 2MB 大页
vm.nr_hugepages = 1024
# 配置大页预留数量(可选)
vm.nr_overcommit_hugepages = 512
- 执行以下命令使配置生效:
sysctl -p
5.4.2 GRUB 配置(适用于 1GB 大页)
1GB 大页需通过内核启动参数配置,步骤如下:
- 编辑
/etc/default/grub文件:
vi /etc/default/grub
- 修改
GRUB_CMDLINE_LINUX参数,添加大页配置:
GRUB_CMDLINE_LINUX="default_hugepagesz=1G hugepagesz=1G hugepages=4 hugepagesz=2M hugepages=1024"
参数说明:
default_hugepagesz=1G:设置默认大页尺寸为 1GB;hugepagesz=1G hugepages=4:分配 4 个 1GB 大页;hugepagesz=2M hugepages=1024:分配 1024 个 2MB 大页。
- 生成新的 GRUB 配置文件:
- CentOS/RHEL 7+ 系统:
grub2-mkconfig -o /boot/grub2/grub.cfg
- Ubuntu/Debian 系统:
update-grub
- 重启系统使配置生效:
reboot
5.5 挂载 hugetlbfs 文件系统
进程需通过 hugetlbfs 文件系统使用大页内存,配置步骤如下:
5.5.1 临时挂载
mount -t hugetlbfs hugetlbfs /dev/hugepages
5.5.2 永久挂载
- 编辑
/etc/fstab文件,添加挂载项:
vi /etc/fstab
- 追加以下内容:
hugetlbfs /dev/hugepages hugetlbfs defaults 0 0
- 执行以下命令使挂载生效:
mount -a
5.6 验证大页配置
5.6.1 查看大页整体信息
cat /proc/meminfo | grep -i huge
预期输出示例:
AnonHugePages: 204800 kB
ShmemHugePages: 0 kB
HugePages_Total: 1024
HugePages_Free: 1024
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 2097152 kB
字段说明:
HugePages_Total:总大页数量;HugePages_Free:空闲大页数量;Hugepagesize:大页尺寸。
5.6.2 查看指定规格大页详情
# 查看 2MB 大页详情
cat /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
# 查看 1GB 大页详情
cat /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
5.6.3 查看进程大页使用情况
# 查看挂载点下的大页使用进程
lsof /dev/hugepages
# 查看指定进程(PID)的大页映射
cat /proc/[PID]/maps | grep huge
5.7 常见问题排查
- 大页分配失败:检查内存是否足够、是否存在连续内存块,可通过
numastat -m查看 NUMA 节点内存分布; - 进程无法使用大页:确认进程具有
/dev/hugepages访问权限,或应用代码未正确调用大页分配接口; - 内核日志排查:查看大页相关内核日志,定位配置错误:
dmesg | grep -i huge
- hugetlbfs 挂载失败:检查
/etc/fstab配置是否正确,或/dev/hugepages目录是否存在。
6 虚拟地址至物理地址翻译机制总结(x86/x86-64 架构)
6.1 翻译机制逻辑
虚拟地址到物理地址的翻译是硬件(MMU/TLB)与软件(操作系统页表管理)协同工作的过程,逻辑可归纳为:
- TLB 优先查询:MMU 首先查询 TLB,若命中则直接拼接物理地址,实现低延迟翻译;
- 多级页表遍历:TLB 未命中时,MMU 依据 CR3 寄存器指向的顶级页表,逐层遍历多级页表,获取物理页号;
- 异常处理兜底:遍历过程中若页表项缺失或无效,触发缺页中断,由操作系统完成页表项创建、页面加载或内存分配,修复映射后重试翻译。
6.2 不同机制的权衡与适用场景
| 翻译机制 | 优势 | 主要限制 | 典型适用场景 |
|---|---|---|---|
| 单级页表 | 结构简单,翻译步骤少 | 内存占用高,不支持大地址空间 | 早期 32 位嵌入式系统 |
| 多级页表 | 按需分配页表,节省内存 | 翻译需多次内存访问 | 主流 32/64 位通用操作系统 |
| 多级页表+TLB | 兼顾内存效率与翻译速度 | TLB 容量有限,存在未命中开销 | 所有现代计算机系统 |
| 大页模式 | 降低翻译延迟,提升 TLB 命中率 | 内存连续性要求高,灵活性低 | 数据库、虚拟化、高性能计算 |
6.3 优化方向
- TLB 优化:增大 TLB 容量、支持多级页表条目缓存、引入 PCID(进程上下文标识符)减少上下文切换时的 TLB 刷新开销;
- 页表优化:采用多级页表按需分配、支持大页模式、引入透明大页(THP)自动优化页表映射;
- 内存管理优化:优化页面置换算法、预留连续内存池、支持 NUMA 架构下的本地大页分配。
via:
-
How the CPU Translates Virtual Addresses to Physical Addresses
https://chessman7.substack.com/p/how-the-cpu-translates-virtual-addresses -
彻底搞懂虚拟地址翻译为物理地址的过程 - 今日头条
https://www.toutiao.com/article/6955273381021319712/ -
内核内存管理-虚拟地址到物理地址转换实验 — seamaner’s blog
https://seamaner.github.io/2025/01/21/kernel-mm/ -
一个虚拟地址到物理地址的过程 - 知乎
https://zhuanlan.zhihu.com/p/484183354 -
……

















 1943
1943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









