




注:本文为 “Linux 进程与线程创建” 相关合辑。
英文引文,机翻未校。
中文引文,略作重排。
如有内容异常,请看原文。
Linux Process and Thread Creation: System Call Architecture
Linux 进程与线程创建:系统调用架构
Understanding the Unified Task Model in Modern Linux Kernels
理解现代 Linux 内核中的统一任务模型
Mohit
Jul 09, 2025
Linux handles process and thread creation through a unified approach that might surprise developers coming from other operating systems. In fact, for the Linux kernel itself there’s absolutely no difference between what userspace sees as processes (the result of fork) and as threads (the result of pthread_create). Both are represented by the same data structures and scheduled similarly.
Linux 采用统一的方式处理进程与线程的创建,这一点可能会让来自其他操作系统的开发者感到意外。实际上,对于 Linux 内核而言,用户空间中所看到的进程(由 fork 系统调用创建)和线程(由 pthread_create 函数创建)之间不存在任何本质区别。二者均由相同的数据结构表示,且调度方式完全一致。
The kernel treats everything as tasks, represented by the task_struct data structure. In Linux, threads are just tasks that share some resources, most notably their memory space; processes, on the other hand, are tasks that don’t share resources.
内核将所有执行实体均视为任务,并通过 task_struct 数据结构对其进行描述。在 Linux 系统中,线程本质上是一类共享部分资源(最显著的是内存空间)的任务;而进程则是一类不共享资源的任务。
The Clone System Call: Foundation of Process and Thread Creation
克隆(Clone)系统调用:进程与线程创建的基础
At the heart of Linux’s process and thread creation lies the clone() system call. Both fork and clone map to the same underlying kernel mechanism, and both of these are in turn implemented using the clone system call.
Linux 进程与线程创建机制的核心是 clone() 系统调用。fork 与 vfork 系统调用均基于相同的内核底层机制实现,而这两个系统调用本身又通过 clone() 系统调用完成具体功能。
System Call Hierarchy
系统调用层级结构
The system call hierarchy represents the layered architecture of Linux process and thread creation mechanisms. At the userspace level, applications invoke familiar functions like fork(), pthread_create(), and vfork(), but these are merely high-level interfaces that eventually converge on a single kernel mechanism.
系统调用层级结构体现了 Linux 进程与线程创建机制的分层架构。在用户空间层面,应用程序会调用诸如 fork()、pthread_create() 和 vfork() 等常用函数,但这些函数都只是高层接口,最终会统一调用同一个内核底层机制。
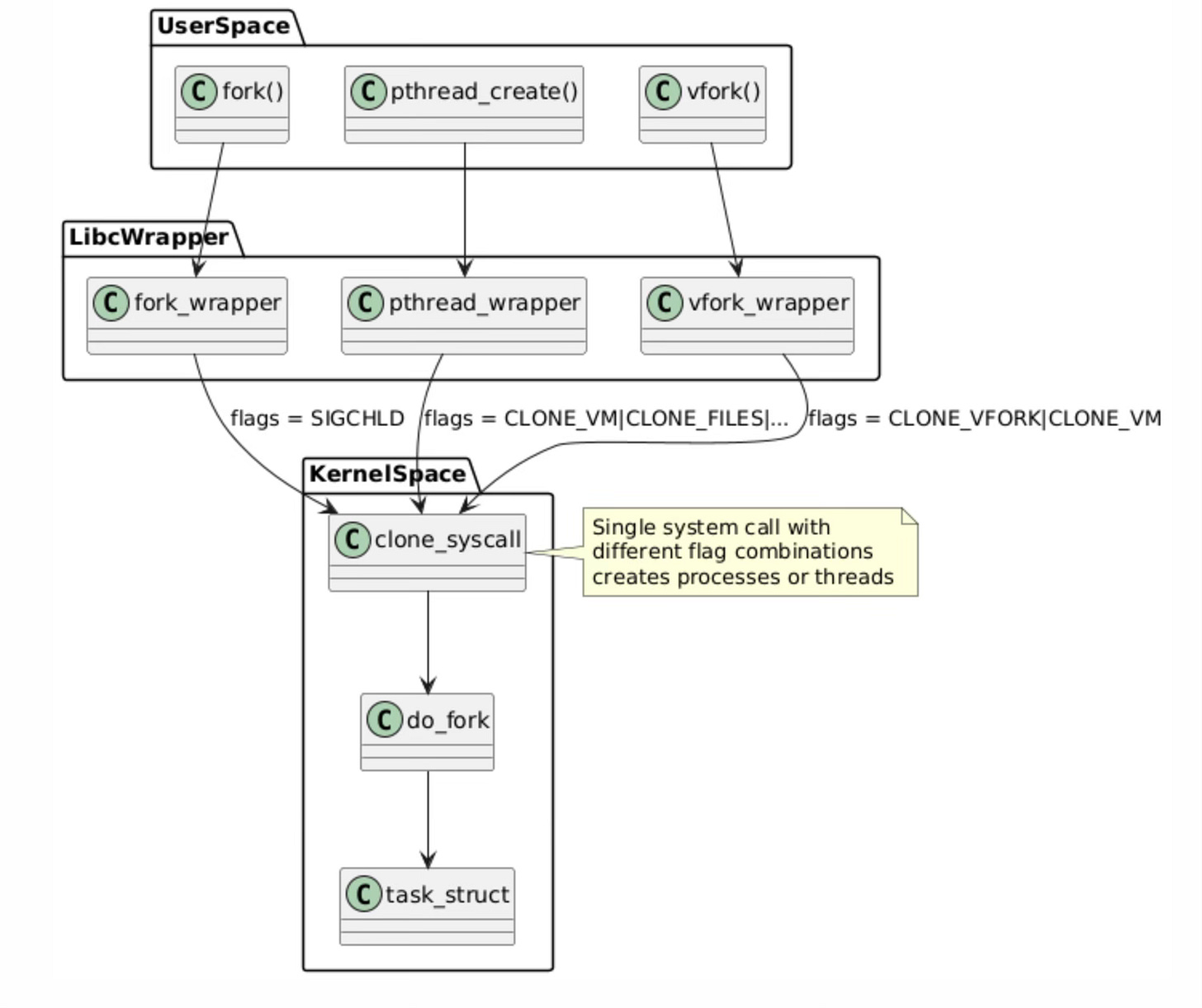
System Call Hierarchy
系统调用层级结构
The libc wrapper layer serves as an abstraction that translates these different API calls into appropriate clone() system call invocations with specific flag combinations.
C 标准库(libc)的封装层起到抽象作用,可将上述不同的 API 调用转换为带有特定标志组合的 clone() 系统调用。
This unified approach demonstrates the elegance of the Linux kernel design. Rather than implementing separate kernel pathways for process and thread creation, the kernel provides a single, flexible clone() system call that can create tasks with varying degrees of resource sharing.
这种统一的设计思路体现了 Linux 内核架构的简洁性。内核并未为进程和线程的创建分别实现独立的内核处理流程,而是提供了一个统一且灵活的 clone() 系统调用,通过该调用可创建具备不同资源共享程度的任务。
The do_fork() kernel function handles the actual task creation logic, allocating and initializing the fundamental task_struct data structure that represents every schedulable entity in the system. This design reduces code duplication in the kernel while providing maximum flexibility for different use cases.
内核函数 do_fork() 负责处理实际的任务创建逻辑,该函数会分配并初始化 task_struct 这一核心数据结构,系统中的每一个可调度实体均由该结构表示。这种设计减少了内核中的代码冗余,同时为不同的应用场景提供了高度的灵活性。
Clone Flags and Their Effects
克隆标志及其作用
The clone() system call accepts various flags that determine what resources the parent and child will share. Here are the key flags:
clone() 系统调用支持多种标志参数,这些参数决定了父子任务之间需要共享的资源类型。以下为核心标志的详细说明:
CLONE_VM: When set, the child shares the parent’s virtual memory space. This flag is fundamental to thread creation because it enables multiple execution contexts to operate within the same address space. Without CLONE_VM, each task receives its own copy of the parent’s memory mappings through the copy-on-write mechanism.
CLONE_VM:当设置该标志时,子任务会共享父任务的虚拟内存空间。该标志是线程创建的基础,它允许多个执行上下文在同一个地址空间内运行。若未设置该标志,每个任务会通过写时复制(Copy-on-Write)机制获得父任务内存映射的独立副本。
The virtual memory descriptor (struct mm_struct) is shared between parent and child when this flag is present, meaning modifications to memory mappings, heap allocations, and stack operations are immediately visible to both tasks.
当设置该标志后,父子任务会共享虚拟内存描述符(struct mm_struct),这意味着对内存映射、堆内存分配以及栈操作的修改会立即对两个任务生效。
The implementation of CLONE_VM involves incrementing the reference count on the parent’s memory management structure rather than duplicating it. This sharing extends beyond just the data pages to include the entire virtual memory layout, including code segments, data segments, heap, and memory-mapped files.
CLONE_VM 标志的实现逻辑为:增加父任务内存管理结构的引用计数,而非直接复制该结构。这种共享机制不仅覆盖数据页,还包括整个虚拟内存布局,具体涵盖代码段、数据段、堆区以及内存映射文件。
However, each task still maintains its own stack space and register context, allowing for independent execution paths while sharing the same memory environment.
需要注意的是,每个任务仍会保留独立的栈空间和寄存器上下文,这使得它们能够在共享内存环境的同时,拥有各自独立的执行流程。
CLONE_FILES: If CLONE_FILES is set, the calling process and the child processes share the same file descriptor table. File descriptors always refer to the same files in the calling process and in the child process.
CLONE_FILES:当设置该标志时,调用进程与子进程会共享同一个文件描述符表。此时,调用进程和子进程中的文件描述符会指向相同的文件。
This means that when one task opens, closes, or modifies a file descriptor, the change is immediately visible to all other tasks sharing the same file table. The kernel accomplishes this by sharing the files_struct structure, which contains the file descriptor array and associated metadata.
这意味着,当某一任务执行文件描述符的打开、关闭或修改操作时,所有共享该文件描述符表的任务都能立即感知到这一变化。内核通过让这些任务共享 files_struct 结构实现此功能,该结构包含文件描述符数组及相关元数据。
This sharing mechanism has important implications for file operations. When multiple threads share file descriptors, they share not only the file handles but also the file position pointers. This means that if one thread reads from a file descriptor, it advances the file position for all other threads sharing that descriptor. Applications must coordinate access to shared file descriptors through synchronization mechanisms to prevent race conditions and ensure predictable behavior.
该共享机制对文件操作存在重要影响。当多个线程共享文件描述符时,它们不仅共享文件句柄,还会共享文件位置指针。这意味着,若某一线程通过某个文件描述符读取文件,所有共享该描述符的线程对应的文件位置指针都会随之移动。因此,应用程序必须通过同步机制协调对共享文件描述符的访问,以避免竞态条件并保证程序行为的可预测性。
CLONE_SIGHAND: If CLONE_SIGHAND is not set, the child process inherits a copy of the signal handlers of the calling process at the time clone() is called. Calls to sigaction(2) performed later by one of the processes have no effect on the other process. Since Linux 2.6.0-test6, flags must also include CLONE_VM.
CLONE_SIGHAND:若未设置该标志,子进程会在 clone() 调用时继承调用进程的信号处理函数副本。此后,任一进程通过 sigaction(2) 系统调用修改信号处理函数,均不会对另一进程产生影响。从 Linux 2.6.0-test6 版本开始,设置该标志时必须同时设置 CLONE_VM 标志。
This flag enables sharing of signal disposition tables between tasks, which is essential for proper thread behavior where signal handlers should be process-wide rather than per-thread.
该标志允许任务之间共享信号处置表,这是实现线程正确行为的关键——在多线程场景下,信号处理函数应作用于整个进程,而非单个线程。
The signal handling architecture in Linux becomes complex when CLONE_SIGHAND is combined with other flags. While signal handlers are shared, each task maintains its own signal mask and pending signal set. This design allows for per-thread signal masking while maintaining consistent signal handler behavior across all threads in a process.
当 CLONE_SIGHAND 标志与其他标志组合使用时,Linux 的信号处理架构会变得较为复杂。尽管信号处理函数是共享的,但每个任务都会维护独立的信号掩码和未决信号集。这种设计支持线程级别的信号屏蔽,同时保证进程内所有线程的信号处理函数行为保持一致。
The kernel enforces the requirement that CLONE_SIGHAND must be accompanied by CLONE_VM because signal handlers often access shared memory, and having different memory spaces would create undefined behavior.
内核强制要求设置 CLONE_SIGHAND 标志时必须同时设置 CLONE_VM 标志,原因在于信号处理函数通常会访问共享内存,若父子任务的内存空间相互独立,将导致未定义行为。
CLONE_THREAD: Creates a thread in the same thread group as the parent. This flag is crucial for implementing POSIX threads semantics, where multiple threads belong to the same process and share a process ID from the perspective of external observers. When CLONE_THREAD is set, the new task joins the thread group of the parent, sharing the same thread group ID (TGID) and appearing as a single process to userspace tools.
CLONE_THREAD:创建一个与父任务同属一个线程组的线程。该标志是实现 POSIX 线程语义的关键——在 POSIX 线程标准中,多个线程隶属于同一个进程,从外部观察者的视角来看,这些线程共享同一个进程 ID。当设置该标志时,新创建的任务会加入父任务的线程组,共享相同的线程组 ID(TGID),且在用户空间工具中会被识别为同一个进程。
The thread group mechanism affects various aspects of process management, including signal delivery, process accounting, and resource limits. Signals sent to the process ID are delivered to the entire thread group, and resource limits are applied at the thread group level rather than per-thread.
线程组机制会影响进程管理的多个方面,包括信号传递、进程记账以及资源限制。发送至进程 ID 的信号会被传递至整个线程组,而资源限制也是作用于线程组级别,而非单个线程。
This creates the illusion of a single process with multiple execution contexts, which aligns with the POSIX threading model expected by most applications.
这种设计营造出“单个进程包含多个执行上下文”的效果,与大多数应用程序所遵循的 POSIX 线程模型完全一致。
Process Creation with Fork
基于 Fork 的进程创建
The fork() system call creates a new process by duplicating the calling process, implementing the classic Unix process creation model. When fork() is invoked, it internally calls clone() with the SIGCHLD flag, which specifies that the parent should receive a SIGCHLD signal when the child terminates.
fork() 系统调用通过复制调用进程的方式创建新进程,该调用实现了经典的 Unix 进程创建模型。当调用 fork() 时,其内部会以 SIGCHLD 标志调用 clone() 系统调用,该标志的作用是:当子进程终止时,父进程会收到 SIGCHLD 信号。
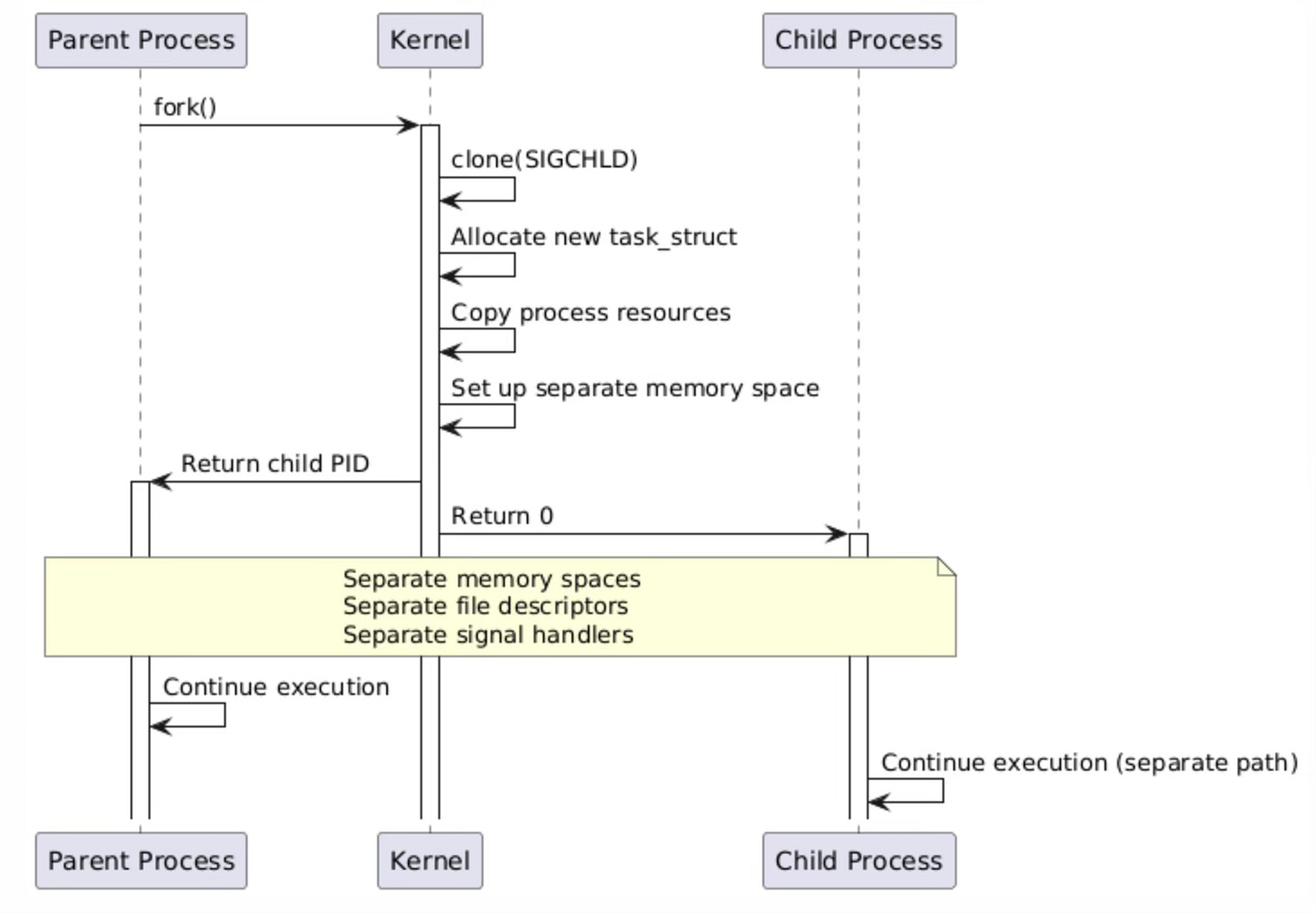
This mechanism provides the foundation for process hierarchies and enables parent processes to monitor and manage their children through wait() family system calls.
该机制为进程层级结构的构建提供了基础,同时允许父进程通过 wait() 系列系统调用监控并管理其子进程。
The kernel’s implementation of fork() involves several critical steps that ensure proper process isolation. First, a new task_struct is allocated and initialized with a copy of the parent’s process information. The kernel then duplicates the parent’s virtual memory space using copy-on-write semantics, meaning that initially both processes share the same physical memory pages marked as read-only. When either process attempts to write to a shared page, the kernel generates a page fault, creates a private copy of the page, and allows the write to proceed. This lazy copying approach optimizes memory usage and reduces the overhead of process creation.
内核对 fork() 的实现包含多个关键步骤,以确保进程之间的完全隔离。首先,内核会分配一个新的 task_struct 结构,并使用父进程的信息对其进行初始化。随后,内核通过写时复制语义复制父进程的虚拟内存空间——初始状态下,父子进程共享相同的物理内存页,且这些内存页被标记为只读。当任一进程尝试向共享内存页写入数据时,内核会触发页错误中断,为该进程创建该内存页的私有副本,之后再允许写操作执行。这种延迟复制的方式优化了内存使用率,并降低了进程创建的开销。
The separation of resources in fork() extends beyond memory to include file descriptors, signal handlers, and process credentials. Each forked process receives its own copy of the parent’s file descriptor table, allowing independent file operations without affecting the parent. Signal handlers are also duplicated, enabling each process to customize its signal handling behavior independently. This complete resource isolation ensures that processes cannot accidentally interfere with each other’s operation, providing the security and stability guarantees expected from the Unix process model.
fork() 实现的资源隔离不仅限于内存,还涵盖文件描述符、信号处理函数以及进程凭证。每个通过 fork() 创建的子进程都会获得父进程文件描述符表的独立副本,从而可以独立执行文件操作而不影响父进程。信号处理函数同样会被复制,使得每个进程都能独立定制自身的信号处理行为。这种完全的资源隔离机制确保进程之间不会发生意外的相互干扰,从而满足 Unix 进程模型对安全性和稳定性的要求。
Thread Creation with pthread_create
基于 pthread_create 的线程创建
The pthread_create() function represents the POSIX threads implementation for creating new threads within a process. Unlike fork(), pthread_create() operates through the pthread library, which serves as a userspace wrapper around the kernel’s clone() system call.
pthread_create() 函数是 POSIX 线程标准中用于在进程内创建新线程的实现。与 fork() 不同,pthread_create() 函数基于 pthread 库实现,而 pthread 库本质上是内核 clone() 系统调用的用户空间封装。
The pthread library carefully orchestrates the thread creation process, managing thread-specific resources like stack allocation, thread-local storage setup, and cleanup handler registration before invoking the kernel to create the actual task.
在调用内核创建实际任务之前,pthread 库会精心协调线程的创建流程,完成线程专属资源的管理工作,包括栈空间分配、线程本地存储(TLS)初始化以及清理处理函数注册等。
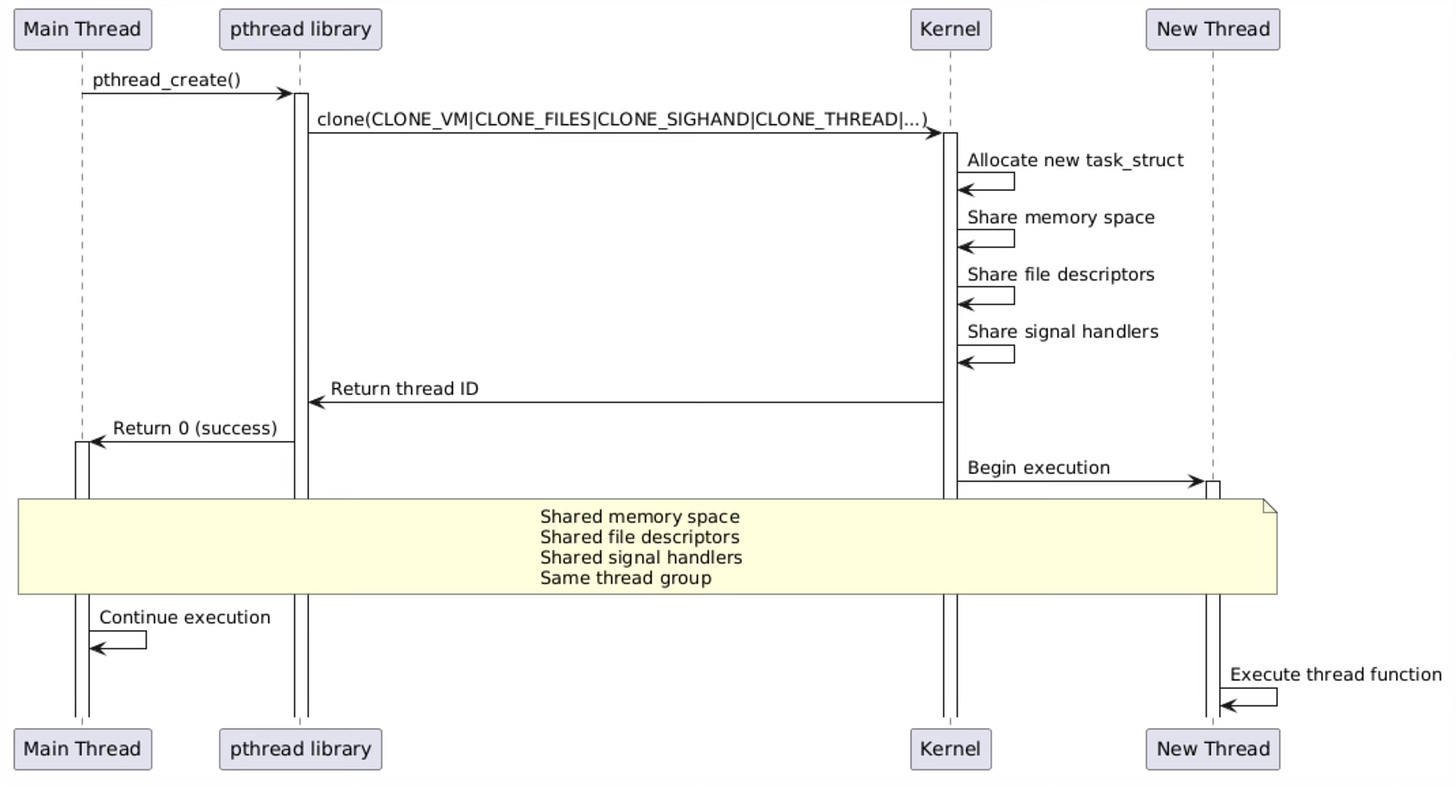
When pthread_create() calls clone(), it passes a specific combination of flags that enable comprehensive resource sharing between the parent and child threads. The CLONE_VM flag ensures that both threads operate within the same virtual address space, allowing them to share global variables, heap allocations, and memory-mapped files.
当 pthread_create() 调用 clone() 时,会传入一组特定的标志组合,以实现父子线程之间的全面资源共享。其中,CLONE_VM 标志确保两个线程在同一个虚拟地址空间内运行,使其可以共享全局变量、堆内存分配以及内存映射文件。
CLONE_FILES enables sharing of file descriptors, so file operations performed by one thread are immediately visible to all other threads in the process. CLONE_SIGHAND ensures that signal handlers are shared, maintaining consistent signal behavior across the entire thread group.
CLONE_FILES 标志允许线程共享文件描述符,因此某一线程执行的文件操作会立即对进程内的所有其他线程可见。CLONE_SIGHAND 标志则保证信号处理函数的共享,从而维持整个线程组的信号处理行为一致性。
The pthread library handles several critical aspects of thread management that the kernel clone() system call does not directly address. This includes allocating and managing thread stacks, typically using mmap() to create stack segments with guard pages to detect stack overflow conditions.
pthread 库还负责处理内核 clone() 系统调用未直接涉及的多项线程管理关键工作。其中包括线程栈的分配与管理——通常通过 mmap() 系统调用创建带有保护页的栈段,以此检测栈溢出情况。
The library also manages thread-local storage (TLS) blocks, which provide per-thread storage for variables marked with __thread specifiers. Additionally, pthread_create() sets up the thread’s cleanup handler chain and synchronization primitives, ensuring that resources can be properly released when the thread terminates either normally or through cancellation.
该库还负责管理线程本地存储(TLS)块,为使用 __thread 关键字修饰的变量提供线程专属的存储空间。此外,pthread_create() 函数会初始化线程的清理处理函数链和同步原语,确保线程无论是正常终止还是被取消,其占用的资源都能被正确释放。
Resource Sharing Matrix
资源共享矩阵
The following table shows what resources are shared between different creation methods:
下表展示了不同创建方式下任务之间共享的资源类型:
Linux Task Creation Resource-Sharing Quick Reference
| Creation Method 创建方式 | Virtual Memory 虚拟内存 | File Descriptor Table 文件描述符表 | Signal Handler Table 信号处理表 | Thread Group Affiliation 线程组归属 | Process/Thread PID 进程/线程 PID | Mount Namespace 挂载命名空间 | Network Namespace 网络命名空间 | PID Namespace PID 命名空间 |
|---|---|---|---|---|---|---|---|---|
fork() | Independent 独立 | Independent 独立 | Independent 独立 | New Process 新进程 | New PID 新 PID | Shared 共享 | Shared 共享 | Shared 共享 |
pthread_create() | Shared 共享 | Shared 共享 | Shared 共享 | Same Thread Group 同一线程组 | Same TGID 同 TGID | Shared 共享 | Shared 共享 | Shared 共享 |
clone(CLONE_VM) | Shared 共享 | Independent 独立 | Independent 独立 | New Process 新进程 | New PID 新 PID | Shared 共享 | Shared 共享 | Shared 共享 |
clone(CLONE_VM|CLONE_FILES) | Shared 共享 | Shared 共享 | Independent 独立 | New Process 新进程 | New PID 新 PID | Shared 共享 | Shared 共享 | Shared 共享 |
clone(CLONE_VM|CLONE_FILES|CLONE_SIGHAND) | Shared 共享 | Shared 共享 | Shared 共享 | New Process 新进程 | New PID 新 PID | Shared 共享 | Shared 共享 | Shared 共享 |
clone(CLONE_VM|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD) | Shared 共享 | Shared 共享 | Shared 共享 | Same Thread Group 同一线程组 | Same TGID 同 TGID | Shared 共享 | Shared 共享 | Shared 共享 |
clone(CLONE_NEWNS) | Independent 独立 | Independent 独立 | Independent 独立 | New Process 新进程 | New PID 新 PID | New Mount Namespace 新挂载空间 | Shared 共享 | Shared 共享 |
clone(CLONE_NEWNET) | Independent 独立 | Independent 独立 | Independent 独立 | New Process 新进程 | New PID 新 PID | Shared 共享 | New Network Stack 新网络栈 | Shared 共享 |
clone(CLONE_NEWPID) | Independent 独立 | Independent 独立 | Independent 独立 | New Process 新进程 | New PID (1 in child namespace) 新 PID(在子空间为 1) | Shared 共享 | Shared 共享 | New PID Namespace 新 PID 空间 |
clone(CLONE_VM|CLONE_NEWNS|CLONE_NEWNET|CLONE_NEWPID) | Shared 共享 | Independent 独立 | Independent 独立 | New Process 新进程 | New PID (1 in child namespace) 新 PID(在子空间为 1) | New Mount Namespace 新挂载空间 | New Network Stack 新网络栈 | New PID Namespace 新 PID 空间 |
Key Details and Common Pitfalls
关键细节与常见坑
-
Meaning of “Shared/Independent”
“共享/独立”含义
Shared = Parent and child tasks operate on the same kernel object; Independent = Each has its own copy with no mutual influence.
共享 = 父子任务操作同一份内核对象;独立 = 各持一份副本,互不影响。 -
Thread Group Rules
线程组规则
Only tasks created withCLONE_THREADjoin the parent’s thread group (same TGID); otherwise, regardless of resource sharing, the kernel treats them as independent processes.
只有带CLONE_THREAD才加入父任务线程组,TGID 相同;否则无论共享多少资源,内核都视为独立进程。 -
Flag Dependencies
flag 依赖CLONE_SIGHANDmust be used withCLONE_VM, otherwise returns-EINVAL.CLONE_SIGHAND必须搭配CLONE_VM,否则返回-EINVAL。CLONE_THREADimpliesCLONE_VM | CLONE_FILES | CLONE_SIGHAND; missing any will return-EINVAL.CLONE_THREAD隐含CLONE_VM | CLONE_FILES | CLONE_SIGHAND,若缺一则返回-EINVAL。
-
PID Namespace Specificity
PID 命名空间特殊性
A new task withCLONE_NEWPIDhas a unique PID in the parent namespace, but sees init PID as 1 in its own namespace; the “Process/Thread PID” column in the table only shows behavior in the parent namespace.
带CLONE_NEWPID的新任务在父空间仍有一个唯一 PID,但在自己空间看到的 init PID 是 1;上表“进程/线程 PID”列仅列出父空间表现。 -
Container Combinations
容器组合
Actual container runtimes (runc, crun, etc.) addCLONE_NEWNS | CLONE_NEWNET | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | CLONE_NEWUSERat once, then supplementCLONE_VM | CLONE_FILESas needed to share kernel-state cache; the table only demonstrates the minimum usable subset.
实际容器运行时(runc、crun 等)会一次性加入CLONE_NEWNS | CLONE_NEWNET | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | CLONE_NEWUSER,再按需补CLONE_VM | CLONE_FILES做共用内核态缓存,上表仅示范最小可用子集。 -
Hidden Restrictions of pthread
pthread 的隐藏限制
glibc’spthread_create()internally fixes flags toCLONE_VM | CLONE_FILES | CLONE_SIGHAND | CLONE_THREAD | CLONE_SYSVSEM, which cannot be adjusted individually by users; direct calls toclone()are required for more flexible sharing.
glibc 的pthread_create()内部已固定CLONE_VM | CLONE_FILES | CLONE_SIGHAND | CLONE_THREAD | CLONE_SYSVSEM,用户无法单独调整;如需更灵活共享,只能直接调用clone()。
Low-Level Implementation Details
底层实现细节
Task Structure Creation
任务结构的创建
The clone() system call implementation in the Linux kernel follows a carefully orchestrated sequence of operations that transforms a single execution context into two independent but potentially resource-sharing tasks. The process begins with rigorous flag validation, where the kernel verifies that the requested flag combinations are logically consistent and supported.
Linux 内核中 clone() 系统调用的实现遵循一套严谨有序的操作流程,通过该流程可将单个执行上下文转换为两个独立但可能共享资源的任务。整个流程始于严格的标志验证阶段——内核会检查传入的标志组合在逻辑上是否一致且受内核支持。
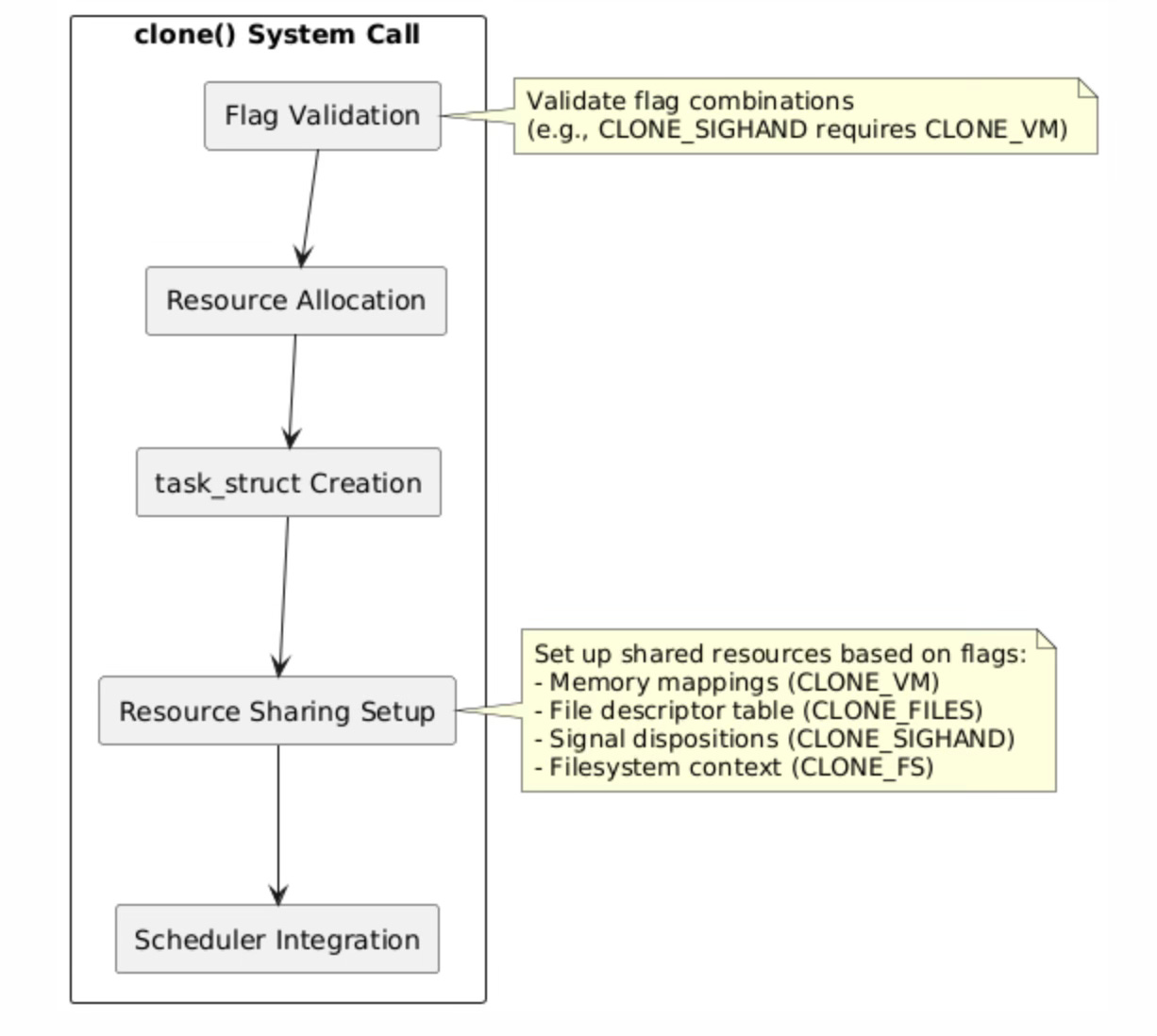
For instance, certain flags like CLONE_SIGHAND require CLONE_VM because signal handlers often access shared memory regions, and having different memory spaces would create undefined behavior when signal handlers execute.
例如,CLONE_SIGHAND 等标志必须与 CLONE_VM 标志同时使用,原因在于信号处理函数通常会访问共享内存区域,若父子任务的内存空间不同,信号处理函数执行时将产生未定义行为。
Resource allocation represents the most complex phase of task creation, involving the allocation and initialization of the new task_struct, which serves as the kernel’s representation of every schedulable entity. The task_struct contains hundreds of fields representing everything from process credentials and memory management information to scheduling parameters and signal handling state.
资源分配是任务创建过程中最复杂的阶段,该阶段需要完成新 task_struct 结构的分配与初始化——内核通过该结构描述每一个可调度实体。task_struct 结构包含数百个字段,涵盖进程凭证、内存管理信息、调度参数以及信号处理状态等所有与任务相关的属性。
The kernel must carefully initialize these fields based on the requested sharing semantics, either copying values from the parent or establishing shared references to parent resources.
内核需要根据请求的资源共享语义,谨慎地初始化这些字段——要么从父任务复制字段值,要么建立对父任务资源的共享引用。
The resource sharing setup phase configures the specific sharing relationships requested through the clone flags. When CLONE_VM is specified, the kernel increments the reference count on the parent’s memory management structure (mm_struct) rather than creating a copy, establishing shared virtual memory semantics.
资源共享配置阶段会根据 clone() 标志的要求,设置具体的资源共享关系。当指定 CLONE_VM 标志时,内核会增加父任务内存管理结构(mm_struct)的引用计数,而非创建该结构的副本,以此实现虚拟内存的共享语义。
Similarly, CLONE_FILES causes the new task to share the parent’s file descriptor table by incrementing the reference count on the files_struct. This reference counting mechanism ensures that shared resources remain valid as long as any task references them, and are automatically freed when the last reference is released.
同理,CLONE_FILES 标志会通过增加 files_struct 结构的引用计数,让新任务共享父任务的文件描述符表。这种引用计数机制确保:只要有任务引用共享资源,该资源就会保持有效;当最后一个引用被释放时,资源会被自动回收。
Integration with the scheduler represents the final phase where the new task becomes eligible for execution. The kernel adds the task to the appropriate runqueue based on its scheduling policy and priority, initializes its scheduling statistics, and sets up any necessary load balancing data structures.
调度器集成是任务创建的最后一个阶段,完成该阶段后新任务将具备执行资格。内核会根据任务的调度策略和优先级,将其添加至对应的运行队列,并初始化任务的调度统计信息,同时设置所需的负载均衡数据结构。
The scheduler integration must account for the task’s resource sharing relationships, as tasks sharing memory or other resources may benefit from being scheduled on the same CPU or CPU complex to improve cache locality and reduce synchronization overhead.
调度器集成过程需要考虑任务的资源共享关系——共享内存或其他资源的任务若被调度到同一个 CPU 或 CPU 集群上执行,将有助于提升缓存局部性并降低同步开销。
Memory Management Differences
内存管理的差异
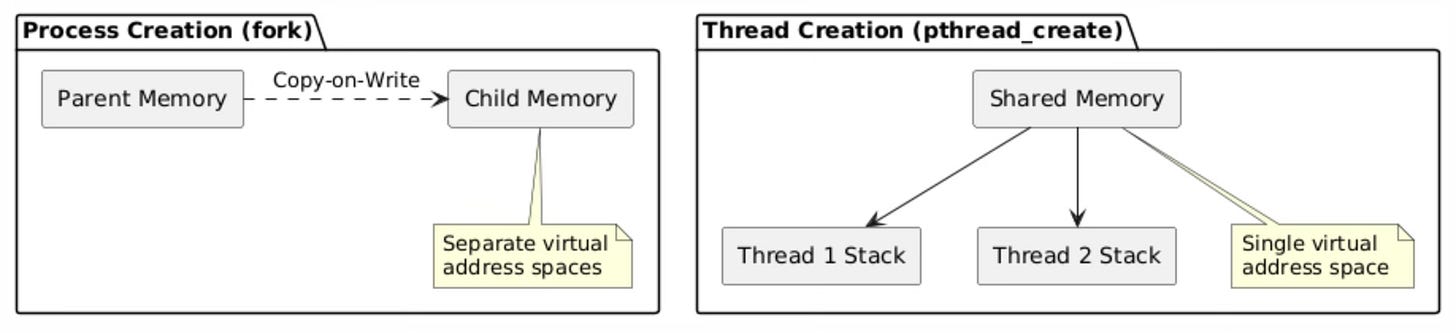
The memory management models for processes and threads represent fundamentally different approaches to resource isolation and sharing. In the process creation model, each new process receives its own complete virtual address space, initially populated through copy-on-write semantics that defer actual memory copying until write operations occur.
进程与线程的内存管理模型体现了资源隔离与共享的两种截然不同的设计思路。在进程创建模型中,每个新进程都会获得独立且完整的虚拟地址空间,该地址空间初始时通过写时复制语义构建——实际的内存复制操作会延迟至写操作发生时执行。
This approach provides strong isolation guarantees, ensuring that processes cannot accidentally corrupt each other’s memory, but requires significant memory management overhead for large processes with extensive memory mappings.
这种方式能够提供强大的隔离保障,确保进程之间不会意外地破坏彼此的内存数据,但对于拥有大量内存映射的大型进程而言,会产生较高的内存管理开销。
The copy-on-write mechanism operates at the page level, where initially both parent and child processes share the same physical memory pages marked as read-only in their respective page tables. When either process attempts to write to a shared page, the hardware generates a page fault that the kernel handles by allocating a new physical page, copying the original page’s contents, and updating the page table entry to point to the new private copy.
写时复制机制基于内存页级别实现,初始状态下,父子进程的页表中均将相同的物理内存页标记为只读。当任一进程尝试向共享内存页写入数据时,硬件会触发页错误中断,内核会处理该中断:分配新的物理内存页,复制原内存页的内容,并更新页表项,使其指向这个新的私有内存页副本。
This lazy copying approach optimizes memory usage by avoiding unnecessary copying of pages that are never modified, but introduces latency spikes when copy-on-write faults occur during execution.
这种延迟复制的方式通过避免复制从未被修改的内存页,优化了内存使用率,但在程序执行过程中触发写时复制页错误时,会产生瞬时的延迟峰值。
In contrast, the thread creation model establishes a single shared virtual address space accessible to all threads within the process. This sharing extends to all memory regions including the heap, global variables, and memory-mapped files, but each thread maintains its own private stack space to enable independent function call chains and local variable storage.
与之相反,线程创建模型会为进程内的所有线程建立一个统一的共享虚拟地址空间。该地址空间的共享范围覆盖所有内存区域,包括堆区、全局变量以及内存映射文件,但每个线程会保留独立的私有栈空间,以支持各自独立的函数调用链和局部变量存储。
The kernel allocates stack space for each thread using mmap() system calls, typically creating stack segments with guard pages at the boundaries to detect stack overflow conditions. Thread stacks are usually allocated from the process’s virtual address space in a downward-growing pattern, with each stack separated by unmapped guard regions that trigger segmentation faults if accessed.
内核通过 mmap() 系统调用为每个线程分配栈空间,通常会在栈段的边界处设置保护页,用于检测栈溢出情况。线程栈通常从进程的虚拟地址空间中分配,采用向下增长的布局方式,且每个栈之间会设置未映射的保护区域——若该区域被访问,会触发段错误中断。
Performance Characteristics
性能特征
Creation Time Comparison
创建时间对比
Thread creation is significantly faster than process creation because:
线程创建的速度远快于进程创建,原因如下:
- No memory space duplication: Threads share the same virtual address space
无需复制内存空间:线程共享同一个虚拟地址空间 - No file descriptor table copying: Threads share the same file descriptor table
无需复制文件描述符表:线程共享同一个文件描述符表 - Minimal resource allocation: Only stack space and thread-specific data need allocation
资源分配量极少:仅需分配栈空间和线程专属数据
The performance differential between thread and process creation stems from the fundamental differences in resource management overhead. Process creation through fork() requires the kernel to duplicate numerous data structures including the virtual memory area (VMA) structures that describe all memory mappings, the file descriptor table containing references to all open files, and various process-specific metadata.
线程与进程创建的性能差异源于二者资源管理开销的本质区别。通过 fork() 创建进程时,内核需要复制大量数据结构,包括描述所有内存映射的虚拟内存区域(VMA)结构、存储所有打开文件引用的文件描述符表,以及各类进程专属的元数据。
Even with copy-on-write optimizations, the kernel must still traverse and duplicate complex data structures, create new page table entries, and establish separate resource accounting structures.
即便使用写时复制优化技术,内核仍需遍历并复制复杂的数据结构、创建新的页表项,同时建立独立的资源记账结构。
Thread creation optimization focuses on minimizing the overhead of creating new execution contexts within existing resource frameworks. The pthread library pre-allocates thread stacks using efficient memory mapping techniques, often maintaining pools of available stacks to avoid repeated system calls.
线程创建的优化思路是:在已有的资源框架内,最大限度地降低新执行上下文的创建开销。pthread 库通过高效的内存映射技术预分配线程栈,通常会维护一个可用栈池,以避免频繁的系统调用。
The kernel’s clone() implementation for threads primarily involves allocating and initializing a new task_struct while establishing shared references to existing resource structures, resulting in significantly reduced computational overhead compared to full process duplication.
针对线程创建的内核 clone() 实现,主要工作是分配并初始化新的 task_struct 结构,同时建立对已有资源结构的共享引用,相比完整的进程复制,该过程的计算开销大幅降低。
Context Switching Performance
上下文切换性能
Context switching performance represents one of the most significant advantages of thread-based architectures over process-based designs. When the scheduler switches between processes, it must perform a complete memory management context switch, including loading new page table roots, flushing translation lookaside buffers (TLBs), and potentially invalidating various CPU cache levels.
上下文切换性能是线程架构相比进程架构的核心优势之一。当调度器在不同进程之间切换时,必须执行完整的内存管理上下文切换,包括加载新的页表根目录、刷新转换后备缓冲区(TLB),以及可能需要使各级 CPU 缓存失效。
This memory management overhead can consume hundreds of CPU cycles and create substantial latency spikes, particularly on systems with large working sets that stress the TLB and cache hierarchies.
这种内存管理开销会消耗数百个 CPU 时钟周期,并导致显著的延迟峰值,在工作集较大、对 TLB 和缓存层级压力较高的系统中,该现象尤为明显。
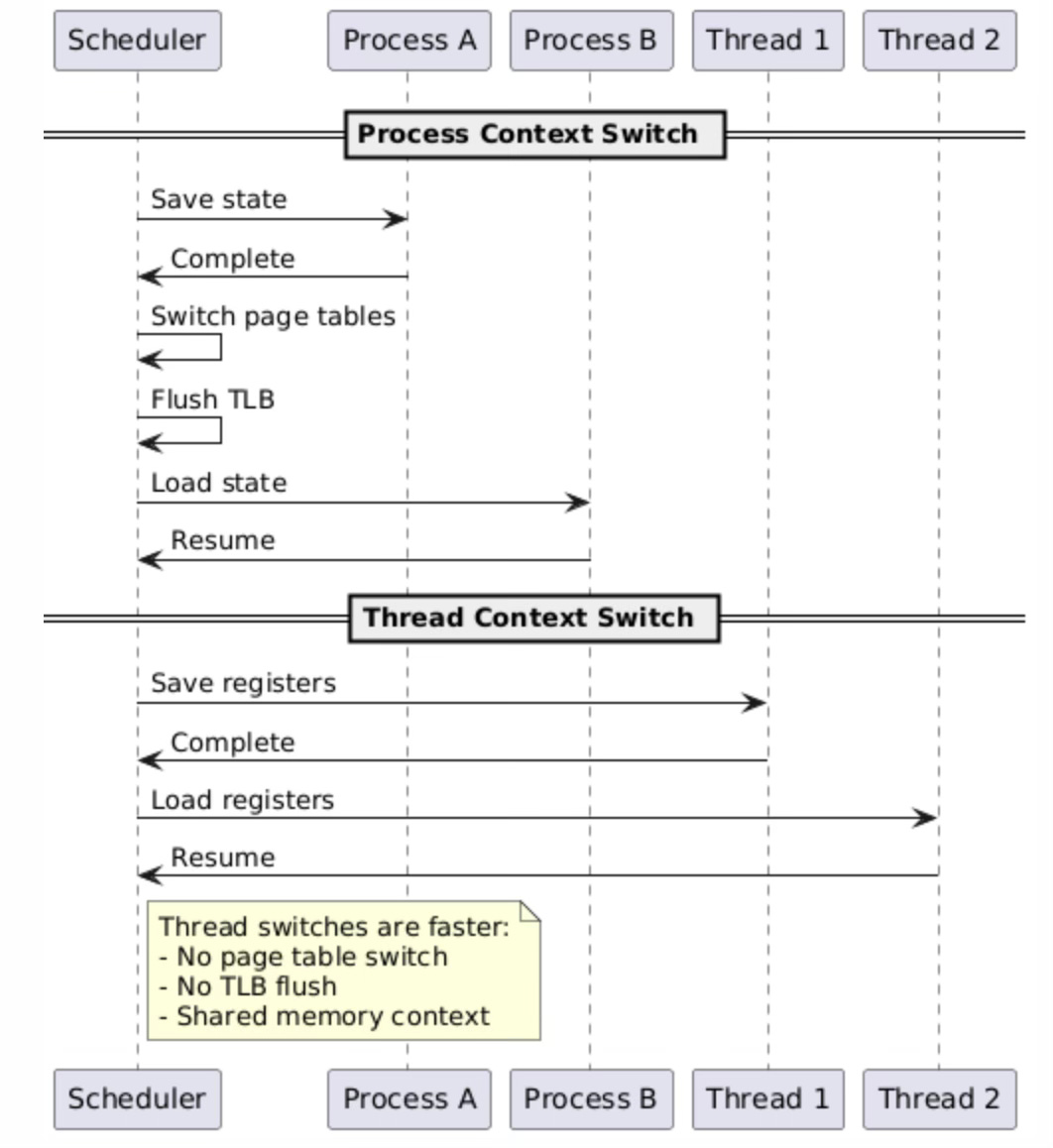
Thread context switches within the same process avoid most memory management overhead because threads share the same virtual address space and therefore the same page table structures. The scheduler only needs to save and restore CPU registers, stack pointers, and thread-specific state, while leaving the memory management unit configuration unchanged.
同一进程内的线程上下文切换可避免大部分内存管理开销,原因在于这些线程共享同一个虚拟地址空间,进而共享相同的页表结构。调度器仅需保存和恢复 CPU 寄存器、栈指针以及线程专属状态,而无需修改内存管理单元(MMU)的配置。
This streamlined switching process reduces context switch latency by an order of magnitude compared to process switches, enabling higher thread switching frequencies and more responsive multithreaded applications.
与进程切换相比,这种精简的切换流程可将上下文切换延迟降低一个数量级,从而支持更高的线程切换频率,并提升多线程应用程序的响应速度。
The shared memory context also improves cache locality, as threads accessing the same data structures benefit from cache lines already loaded by other threads in the same process.
共享的内存上下文还能提升缓存局部性——当多个线程访问相同的数据结构时,可直接使用同一进程内其他线程已加载至缓存中的数据行。
Advanced Clone Flags and Use Cases
高级克隆标志及应用场景
Creating Lightweight Processes
轻量级进程的创建
One flag in particular stands out which is CLONE_THREAD. Different flag combinations enable various lightweight process models:
CLONE_THREAD 是其中尤为重要的一个标志。通过不同的标志组合,可实现多种轻量级进程模型:
Container-like isolation:
类容器隔离:
clone(child_func, stack_ptr,
CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWNET,
NULL);
Shared memory processes:
共享内存进程:
clone(child_func, stack_ptr,
CLONE_VM | CLONE_FILES,
NULL);
Full thread creation:
完整线程创建:
clone(child_func, stack_ptr,
CLONE_VM | CLONE_FILES | CLONE_SIGHAND |
CLONE_THREAD | CLONE_SYSVSEM,
NULL);
The flexibility of the clone() system call enables the creation of lightweight processes that fall between traditional processes and threads in terms of resource sharing and isolation. These hybrid execution models prove particularly valuable for specialized applications such as container runtimes, user-space network stacks, and high-performance computing frameworks that require fine-grained control over resource sharing policies.
clone() 系统调用的灵活性使其能够创建轻量级进程——这类进程在资源共享与隔离程度上介于传统进程和线程之间。这种混合执行模型对于容器运行时、用户空间网络栈以及高性能计算框架等特殊应用极具价值,这些应用需要对资源共享策略进行精细化控制。
The namespace-related flags (CLONE_NEWPID, CLONE_NEWNS, CLONE_NEWNET) enable the creation of isolated execution environments that form the foundation of modern containerization technologies.
与命名空间相关的标志(CLONE_NEWPID、CLONE_NEWNS、CLONE_NEWNET)可用于创建隔离的执行环境,这正是现代容器化技术的核心基础。
Container-like isolation demonstrates how clone() flags can create processes that appear completely isolated from the host system perspective while still sharing certain resources for efficiency. The CLONE_NEWPID flag creates a new process ID namespace where the child process becomes PID 1 within its own namespace, enabling process tree isolation without requiring full virtualization.
类容器隔离的实现,体现了如何通过 clone() 标志创建出“从宿主系统视角看完全隔离,但仍可共享部分资源以提升效率”的进程。CLONE_NEWPID 标志会创建一个新的进程 ID 命名空间,子进程在该命名空间内会成为 PID 为 1 的进程,从而无需完整虚拟化即可实现进程树的隔离。
CLONE_NEWNS creates a separate mount namespace, allowing the child to have its own filesystem view, while CLONE_NEWNET provides network namespace isolation with separate network interfaces and routing tables.
CLONE_NEWNS 标志会创建独立的挂载命名空间,使子进程拥有专属的文件系统视图;CLONE_NEWNET 标志则提供网络命名空间隔离,使子进程具备独立的网络接口和路由表。
Shared memory processes represent an intermediate model where processes share memory space but maintain separate file descriptor tables and signal handlers. This configuration proves useful for applications that need shared memory performance but require isolation for file operations or signal handling.
共享内存进程代表一种中间模型——进程之间共享内存空间,但各自维护独立的文件描述符表和信号处理函数。这种配置适用于需要共享内存带来的高性能,但同时要求文件操作或信号处理相互隔离的应用程序。
The selective sharing enables custom process architectures where different aspects of process state can be shared or isolated based on application requirements, providing more flexibility than the binary choice between full process isolation and complete thread sharing.
这种选择性共享机制支持定制化的进程架构,可根据应用需求决定进程状态的不同部分是共享还是隔离,相比“完全进程隔离”和“完全线程共享”的二元选择,该机制具备更高的灵活性。
Security and Isolation Considerations
安全性与隔离性考量
Namespace Isolation
命名空间隔离
Linux namespaces provide a powerful mechanism for creating isolated execution environments without the overhead of full virtualization. When clone() is invoked with namespace creation flags, the kernel establishes separate instances of global system resources, creating the illusion of independent system environments while sharing the underlying kernel infrastructure.
Linux 命名空间提供了一种强大的机制,能够在无需完整虚拟化开销的前提下,创建隔离的执行环境。当调用 clone() 并传入命名空间创建标志时,内核会为全局系统资源创建独立的实例,从而营造出独立系统环境的效果,同时共享底层的内核基础设施。
This approach enables container technologies to provide strong isolation guarantees while maintaining near-native performance characteristics.
这种方式使容器技术能够在提供强隔离保障的同时,保持接近原生的性能水平。
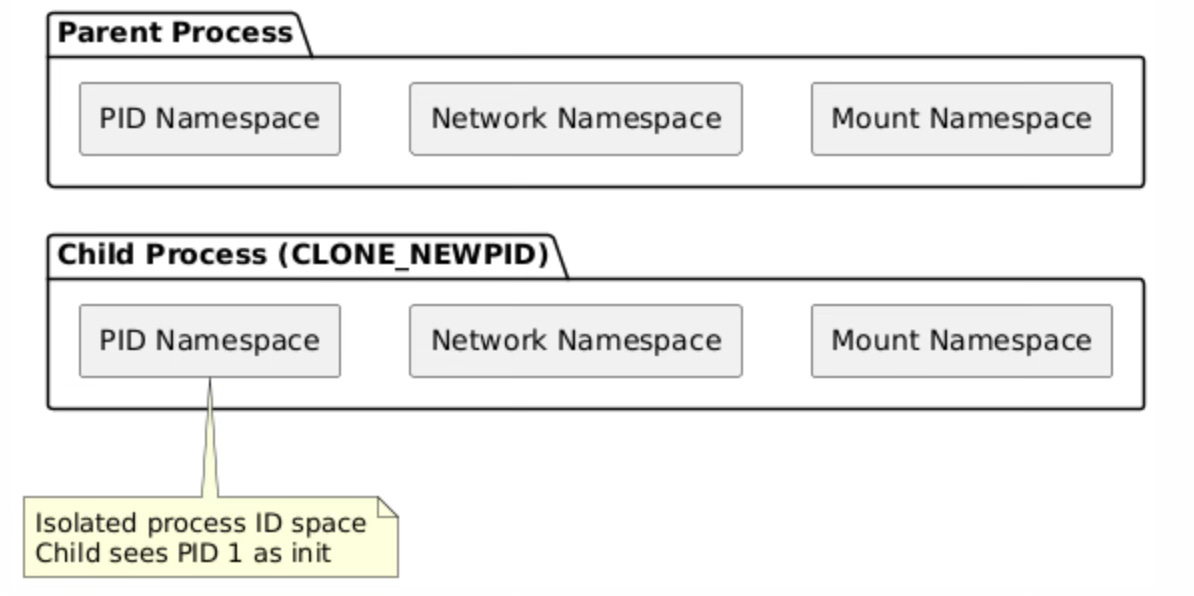
The PID namespace isolation creates separate process ID spaces where each namespace maintains its own PID allocation and process hierarchy. Within a new PID namespace, the first process becomes PID 1 and assumes the role of init, responsible for reaping orphaned processes and handling system-level process management tasks.
PID 命名空间隔离会创建独立的进程 ID 空间,每个命名空间都维护自身的 PID 分配规则和进程层级结构。在新的 PID 命名空间中,第一个创建的进程会成为 PID 为 1 的进程,并承担 init 进程的角色,负责回收孤儿进程并处理系统级别的进程管理任务。
This isolation prevents processes in different namespaces from directly signaling or examining each other, providing security boundaries that contain potential attacks or resource exhaustion scenarios.
这种隔离机制阻止不同命名空间的进程之间直接发送信号或相互探查,从而构建安全边界,防范潜在的攻击或资源耗尽风险。
Network namespace isolation extends this model to network resources, providing each namespace with its own network interfaces, routing tables, firewall rules, and socket port spaces. This enables multiple processes to bind to the same port numbers without conflicts, and allows for complex network configurations where different namespaces can have completely different network topologies.
网络命名空间隔离将这种隔离模型扩展至网络资源,为每个命名空间分配独立的网络接口、路由表、防火墙规则以及套接字端口空间。这使得多个进程可以绑定相同的端口号而不产生冲突,同时支持复杂的网络配置——不同命名空间可拥有完全不同的网络拓扑结构。
The combination of multiple namespace types enables sophisticated isolation scenarios where containers can have their own filesystem view, network configuration, and process space while still sharing the host kernel efficiently.
多种命名空间类型的组合使用,可实现复杂的隔离场景——容器能够拥有专属的文件系统视图、网络配置和进程空间,同时高效地共享宿主内核。
Signal Handling in Threads vs Processes
线程与进程的信号处理对比
However, the calling process and child processes still have distinct signal masks and sets of pending signals. This creates important differences in signal handling:
但需要注意的是,调用进程与子进程仍会拥有独立的信号掩码和未决信号集。这导致二者的信号处理存在如下关键差异:
Process model: Each process has independent signal handling
进程模型:每个进程拥有独立的信号处理机制
Thread model: Signal handlers are shared, but signal masks are per-thread
线程模型:信号处理函数是共享的,但信号掩码为线程私有
The signal handling architecture in Linux becomes particularly complex when dealing with threads due to the hybrid nature of signal delivery and handling. While threads within a process share signal handlers through the CLONE_SIGHAND flag, each thread maintains its own signal mask, allowing for selective signal blocking on a per-thread basis.
在处理线程相关的信号时,Linux 的信号处理架构会变得尤为复杂,这源于信号传递与处理的混合特性。尽管进程内的线程通过 CLONE_SIGHAND 标志共享信号处理函数,但每个线程都维护独立的信号掩码,支持以线程为单位选择性地屏蔽信号。
This design enables sophisticated signal handling strategies where certain threads can be designated as signal handlers while others block signals to avoid interruption during critical sections.
这种设计支持灵活的信号处理策略——可以指定特定线程作为信号处理线程,而其他线程则屏蔽信号,以避免在临界区执行时被中断。
Signal delivery to multithreaded processes follows specific rules defined by the POSIX standard, where signals directed to the process are delivered to any thread that has not blocked the signal. This non-deterministic delivery model requires careful coordination between threads to ensure proper signal handling.
向多线程进程传递信号时,需遵循 POSIX 标准定义的特定规则:发送至进程的信号会被传递给任意未屏蔽该信号的线程。这种非确定性的信号传递模型,要求线程之间进行精细的协调,以确保信号被正确处理。
The kernel’s signal delivery mechanism searches the thread group for eligible targets, potentially waking sleeping threads if necessary to deliver urgent signals. This complexity necessitates careful signal mask management and often leads to designs where a single thread handles all signals while others block them entirely.
内核的信号传递机制会在线程组内搜索符合条件的信号接收线程,若需要传递紧急信号,甚至可能唤醒处于休眠状态的线程。这种复杂性要求开发者谨慎管理信号掩码,在实际设计中,通常会采用“单个线程处理所有信号,其他线程完全屏蔽信号”的方案。
Debugging and Observability
调试与可观测性
Identifying Task Relationships
任务关系的识别
Tools like ps, top, and /proc filesystem show the relationship between tasks:
可通过 ps、top 等工具以及 /proc 文件系统查看任务之间的关系:
# Show thread relationships 查看线程关系
ps -eLf
# Show process tree 查看进程树
pstree -p
# Examine task details 查看任务详细信息
cat /proc/PID/task/*/stat
Common Pitfalls and Best Practices
常见陷阱与最佳实践
Race Conditions in Shared Resources
共享资源的竞态条件
When using clone() with shared resources, developers must handle synchronization:
当使用 clone() 创建共享资源的任务时,开发者必须处理同步问题:
// Proper synchronization for shared file descriptors
pthread_mutex_t fd_mutex = PTHREAD_MUTEX_INITIALIZER;
void safe_file_operation() {
pthread_mutex_lock(&fd_mutex);
// File operations here
pthread_mutex_unlock(&fd_mutex);
}
Memory Leak Prevention
内存泄漏的预防
A new thread will be created and the syscall will return in each of the two threads at the same instruction, exactly like fork(). This similarity can lead to memory management issues if not handled carefully.
新线程创建完成后,该系统调用会在父子两个线程的同一条指令处返回,这与 fork() 的行为完全一致。若处理不当,这种行为相似性可能引发内存管理问题。
Conclusion
结论
Linux’s unified task model through the clone() system call provides a flexible foundation for both process and thread creation. Understanding the flag combinations and their effects on resource sharing is crucial for systems programming and performance optimization.
Linux 通过 clone() 系统调用实现的统一任务模型,为进程和线程的创建提供了灵活的基础。理解标志组合及其对资源共享的影响,对于系统编程和性能优化至关重要。
The choice between processes and threads ultimately depends on the specific requirements for isolation, performance, and resource sharing in your application.
进程与线程的选择,最终取决于应用程序在隔离性、性能和资源共享方面的具体需求。
The kernel’s approach of treating everything as tasks with varying degrees of resource sharing provides both simplicity in implementation and flexibility in use cases, from lightweight threads to fully isolated processes and everything in between.
内核将所有执行实体视为具备不同资源共享程度的任务,这种设计思路既简化了内核实现,又为各类应用场景提供了灵活性——无论是轻量级线程、完全隔离的进程,还是介于二者之间的执行实体,均可基于该模型实现。
一文搞定 Linux 进程和线程(详细图解)
思绪缥缈 转载于 2020-09-18 17:38:18 发布
本文深入探讨 Linux 内核中的进程和线程概念,详细介绍 Linux 进程和线程的创建、管理和调度机制,以及进程间通信的各类方式。
Linux 进程和线程
本文将基于 Linux 内核的设计逻辑,解析进程与线程的底层实现原理。系统调用作为操作系统对外提供的接口,在进程与线程创建、内存分配、文件共享及 I/O 操作等环节中发挥关键作用。
本文将从不同 Linux 内核版本的共性特征切入展开讨论。
基本概念
进程是 Linux 系统中的抽象概念之一,其设计模型与现代操作系统的通用进程模型具有高度一致性。每个进程对应一段独立运行的程序,且在初始化阶段会分配一个独立的控制线程。换言之,每个进程均拥有专属的程序计数器,该计数器用于记录下一条待执行的指令地址。Linux 支持进程在运行期间动态创建额外的线程。
Linux 属于多道程序设计系统,系统内可同时存在多个相互独立的进程并发执行。此外,单个用户通常会同时运行多个活动进程。在大型服务器系统中,并发运行的进程数量可达数百甚至上千个。
在用户空间中,部分进程在用户退出登录后仍会持续运行,这类进程被称为 守护进程(daemon)。
Linux 系统中存在一类特殊的守护进程——计划守护进程(Cron daemon)。该进程每分钟唤醒一次,检查是否存在待执行任务,任务执行完毕后再次进入睡眠状态,等待下一次唤醒周期。
Cron 是一款功能通用的守护进程,可用于执行周期性系统维护、数据备份等任务。其他操作系统中也存在类似功能的程序,例如 Mac OS X 中的
launchd守护进程,以及 Windows 系统中的 计划任务(Task Scheduler)。
Linux 系统中进程的创建方式简洁高效,fork 系统调用可创建一个与源进程完全相同的拷贝(副本)。发起 fork 调用的进程被称为 父进程(parent process),通过 fork 创建的新进程被称为 子进程(child process)。父进程与子进程各自拥有独立的内存映像,若父进程在子进程创建后修改自身内存空间中的变量等数据,子进程的对应数据不会发生同步变化,即 fork 操作完成后,父子进程的运行状态相互独立。
尽管父子进程的内存空间相互隔离,但二者可共享已打开的文件资源。若父进程在调用 fork 前已打开某个文件,子进程在创建后将自动继承该文件的访问权限,且对共享文件的修改会对父子进程同时可见。
父子进程的区分依据是 fork 函数的返回值:父进程调用 fork 后,将获得子进程的进程标识符(Process Identifier, PID),该返回值为非零整数;子进程对应的返回值则为 0。上述逻辑可通过如下代码实现:
pid_t pid = fork(); // 调用 fork 函数创建进程
if (pid < 0) {
error(); // pid < 0 表示进程创建失败
} else if (pid > 0) {
parent_handle(); // 父进程执行逻辑
} else {
child_handle(); // 子进程执行逻辑
}
父进程通过 fork 的返回值获取子进程的 PID,该 PID 是系统内标识子进程的唯一数值。子进程若需获取自身 PID,可调用 getpid 函数。当子进程终止运行时,父进程会收到子进程的 PID 以进行后续资源清理。由于一个进程可创建多个子进程,且子进程亦可继续派生新进程,因此 PID 是进程管理的关键标识。首次调用 fork 生成的进程被称为原始进程,单个原始进程可衍生出一棵进程继承树。
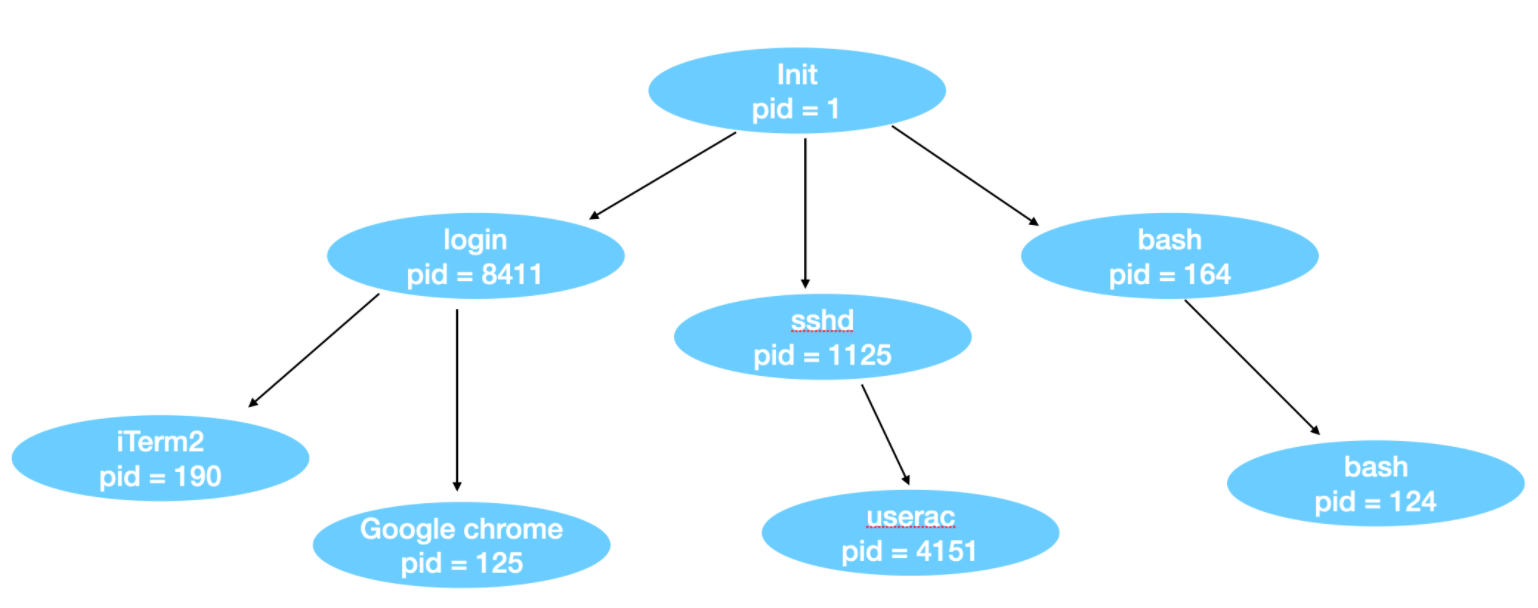
Linux 进程间通信
Linux 系统中进程间的通信机制被统称为 进程间通信(Inter-Process Communication, IPC)。Linux 支持的 IPC 机制主要分为 6 类。
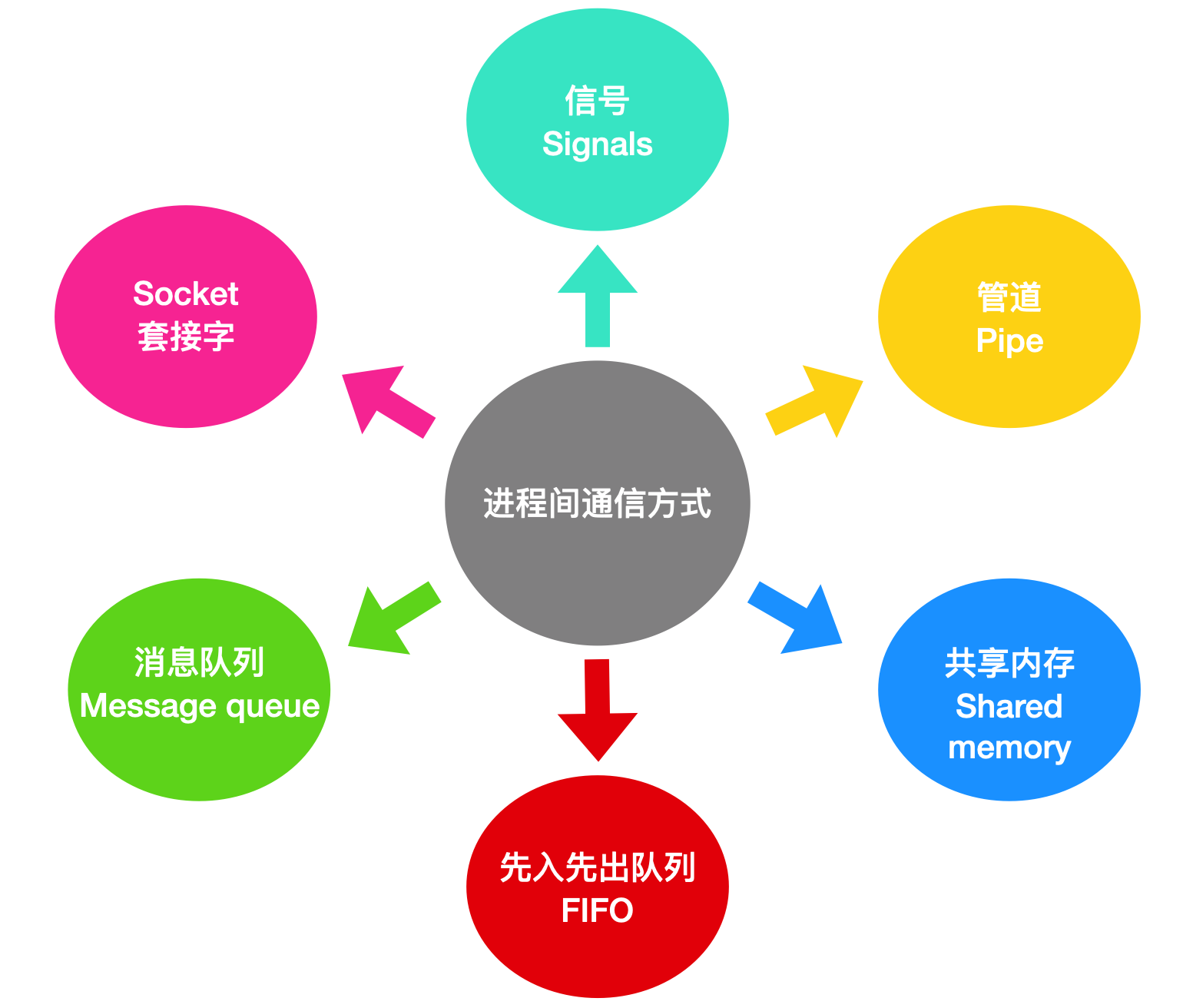
下文将对各类 IPC 机制分别进行概述。
信号(Signal)
信号是 UNIX 系统最早引入的进程间通信机制,Linux 作为 UNIX 类操作系统,完全兼容该机制。信号通过向一个或多个进程发送异步事件信号实现通信,其触发场景包括用户键盘输入、进程访问非法内存地址等;在 Shell 环境中,信号也可用于向子进程传递任务控制指令。
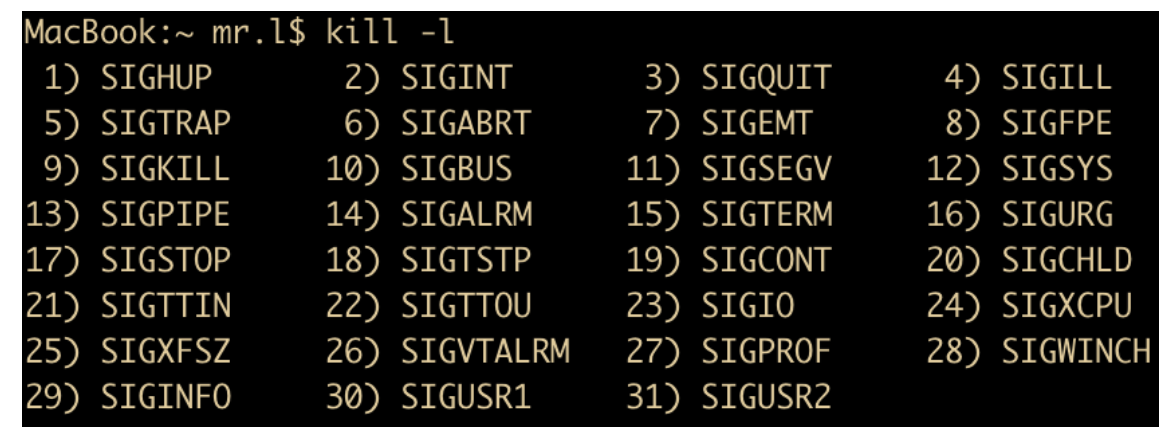
在 Linux 终端中执行 kill -l 命令,可列出当前系统支持的所有信号类型。
进程可选择忽略部分信号,但存在两个无法忽略的信号:SIGSTOP 与 SIGKILL。SIGSTOP 信号用于暂停目标进程的执行,SIGKILL 信号用于强制终止目标进程。除此之外,进程可配置对特定信号的处理策略:若未阻塞信号,进程可选择自定义处理逻辑,或交由内核执行默认处理流程。
操作系统通过中断目标进程的执行流程来递送信号,中断可发生在任意非原子指令执行阶段。若进程已注册信号处理函数,则执行自定义逻辑;否则执行内核预设的默认操作。
例如,进程接收到 SIGFPE(浮点运算异常)信号时,内核默认处理方式为**转储(dump)**并终止进程运行。信号不具备优先级属性,若多个信号同时送达某一进程,内核可按任意顺序进行处理。
常见信号的功能定义如下:
SIGABRT与SIGIOT:用于通知进程终止运行,通常由进程调用 C 标准库的abort()函数主动触发。SIGALRM、SIGVTALRM、SIGPROF:均为定时器信号。SIGALRM对应实际时间超时;SIGVTALRM对应进程占用的用户态 CPU 时间超时;SIGPROF对应进程占用的用户态与内核态总 CPU 时间超时。SIGBUS:进程触发总线错误(如访问未对齐内存)时触发。SIGCHLD:子进程终止、暂停或恢复运行时,向父进程发送该信号,常用于父进程清理子进程资源。SIGCONT:用于恢复先前被SIGSTOP或SIGTSTP暂停的进程,是 Unix Shell 作业控制的信号。SIGFPE:进程执行非法算术运算(如除以零、浮点溢出)时触发。
SIGHUP:进程对应的控制终端关闭时触发。多数守护进程收到该信号后,会重新加载配置文件并重建日志文件连接,而非直接退出。SIGILL:进程尝试执行非法、格式错误或特权指令时触发。SIGINT:用户通过键盘输入Ctrl + C时,操作系统向前台进程发送该信号以请求中断。SIGKILL:强制终止进程的信号,无法被捕获、忽略或阻塞。进程接收到该信号后,无法执行任何清理操作。存在两种特殊情况:僵尸进程无法被SIGKILL杀死,因其已终止运行,仅等待父进程回收资源;处于阻塞状态的进程需被唤醒后才能响应该信号;init进程(PID = 1)会忽略所有SIGKILL信号。该信号通常作为终止进程的最后手段,在SIGTERM信号无效时使用。SIGPIPE:进程向已断开的管道写入数据时触发。SIGPOLL:进程监视的文件描述符上发生指定事件时触发。SIGRTMIN至SIGRTMAX:实时信号,支持按优先级排队处理。SIGQUIT:用户输入Ctrl + \时触发,用于请求进程退出并生成转储文件。SIGSEGV:进程发生段错误(如访问无效虚拟内存地址)时触发。SIGSTOP:强制暂停进程执行的信号,无法被捕获、忽略或阻塞。SIGSYS:进程调用系统调用时传入无效参数触发。SIGTERM:用于请求进程正常终止的信号,可被捕获或忽略。进程接收到该信号后,可执行资源释放、状态保存等清理操作,其功能与SIGINT类似。SIGTSTP:用户通过键盘输入Ctrl + Z时,向前台进程发送该信号以请求暂停。SIGTTIN与SIGTTOU:后台进程尝试从控制终端读取数据时触发SIGTTIN;后台进程尝试向控制终端写入数据时触发SIGTTOU。SIGTRAP:进程触发调试断点或陷阱指令时触发,主要用于调试器实现。SIGURG:套接字上存在紧急或带外数据可读时触发。SIGUSR1与SIGUSR2:用户自定义信号,可用于进程间传递自定义消息。SIGXCPU:进程占用的 CPU 时间超过资源限制时触发。SIGXFSZ:进程尝试创建的文件大小超过系统限制时触发。SIGWINCH:进程对应的控制终端窗口大小发生变化时触发。
管道(Pipe)
Linux 进程可通过创建管道(Pipe)实现单向通信。
管道是连接两个进程的字节流通道,一端进程向管道写入数据,另一端进程从管道读取数据。管道具有同步特性:若进程尝试从空管道读取数据,该进程将被阻塞,直至管道内有数据写入。Shell 中的**管线(pipelines)**功能正是基于管道实现,例如执行如下命令时:
sort < f | head
Shell 会创建两个进程分别执行 sort 与 head 程序,并在两个进程间建立管道,将 sort 进程的标准输出重定向为 head 进程的标准输入。sort 进程的输出数据无需写入磁盘文件,直接通过管道传输至 head 进程;若管道缓冲区被写满,sort 进程将被阻塞,直至 head 进程读取数据释放缓冲区空间。
管道在 Shell 中的语法表示为 |,参与通信的两个进程无需感知管道的存在,所有数据传输均由 Shell 负责管理与控制。
共享内存(Shared Memory)
多个进程可通过共享内存机制访问同一块物理内存空间,实现高效数据交换。一个进程对共享内存的修改可被其他进程实时感知,其通信效率与线程间通信接近。
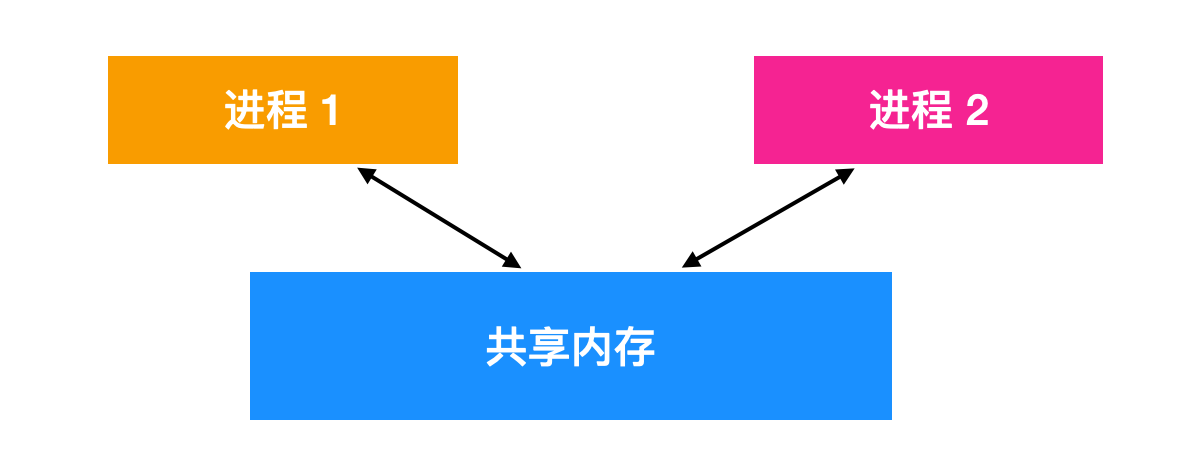
使用共享内存的标准流程如下:
- 调用
shmget()函数创建新的共享内存段,或获取已存在的共享内存段标识符。 - 调用
shmat()函数将共享内存段映射到当前进程的虚拟地址空间。 - 进程完成数据交互后,调用
shmdt()函数将共享内存段从自身虚拟地址空间中分离。 - 调用
shmctl()函数对共享内存段执行控制操作(如删除、修改权限)。
先入先出队列(FIFO)
先入先出队列(FIFO)又被称为命名管道(Named Pipes),其工作原理与匿名管道类似,但存在以下关键区别:匿名管道仅存在于内存中,无对应的文件系统节点,进程退出后管道即被销毁;命名管道则在文件系统中以特殊设备文件的形式存在,拥有独立的路径与权限属性,即使所有通信进程退出,命名管道仍可保留在文件系统中,供后续进程使用。
命名管道严格遵循**先入先出(First-In-First-Out)**原则,写入管道的第一个字节会被最先读取,数据的读写顺序完全一致。

消息队列(Message Queue)
消息队列是内核空间中维护的一个内部链表结构,进程可向队列中发送消息,也可从队列中接收消息。每个消息队列由唯一的 IPC 标识符标识。
消息队列支持两种读取模式:
- 严格模式:遵循 FIFO 原则,消息按发送顺序依次读取,与命名管道的行为一致。
- 非严格模式:允许进程按消息类型读取指定消息,无需遵循发送顺序。
套接字(Socket)
套接字(Socket)是一种支持双向通信的 IPC 机制,可用于同一主机内的进程通信,也可用于跨网络的进程通信。与管道类似,套接字也分为匿名套接字与命名套接字,其中网络套接字是实现网络通信的组件,需依赖 传输控制协议(TCP) 或 用户数据报协议(UDP) 等底层网络协议提供支持。
套接字的主要分类如下:
- 顺序包套接字(Sequential Packet Socket):提供可靠的面向连接通信,传输的数据报长度固定,且保持顺序性。
- 数据报套接字(Datagram Socket):基于 UDP 协议实现,支持双向数据传输,不保证消息的到达顺序与可靠性。
- 流式套接字(Stream Socket):基于 TCP 协议实现,提供可靠的、面向连接的字节流传输服务,类似于电话通信的交互模式。
- 原始套接字(Raw Socket):允许进程直接访问底层网络协议(如 IP 协议),可用于开发自定义网络协议或网络监控工具。
Linux 中进程管理系统调用
本节将介绍 Linux 系统中与进程管理相关的系统调用。在具体讲解前,需明确系统调用的基本概念。
操作系统的功能是为用户层程序提供硬件抽象接口,屏蔽底层硬件与内核实现的复杂性,使用户仅需关注图形界面(GUI)的交互逻辑。操作系统的运行模式分为两类:
- 内核态:操作系统内核的运行模式,拥有最高的系统权限,可直接访问硬件资源与内核数据结构。
- 用户态:用户应用程序的运行模式,权限受限,无法直接访问硬件资源,需通过系统调用请求内核提供服务。
上下文切换指的是处理器在用户态与内核态之间的切换过程,而系统调用是触发上下文切换的主要方式。系统调用是用户层程序向操作系统内核请求服务的接口,通常在后台静默执行。
与进程管理相关的系统调用如下:
fork
fork 调用用于创建一个与父进程完全相同的子进程。子进程创建后,将继承父进程的程序计数器、CPU 寄存器状态、打开的文件描述符等所有资源。
exec
exec 系统调用用于在当前进程的内存空间中执行一个新的可执行文件。调用 exec 后,新的可执行文件会覆盖当前进程的代码段、数据段与堆栈段,原进程的执行逻辑被替换。需要注意的是,exec 调用不会创建新进程,因此进程的 PID 保持不变;但进程的内存映像、代码与数据会被完全替换。若当前进程包含多个线程,所有线程会被终止,新的进程映像将被加载并执行。
进程映像(Process Image)
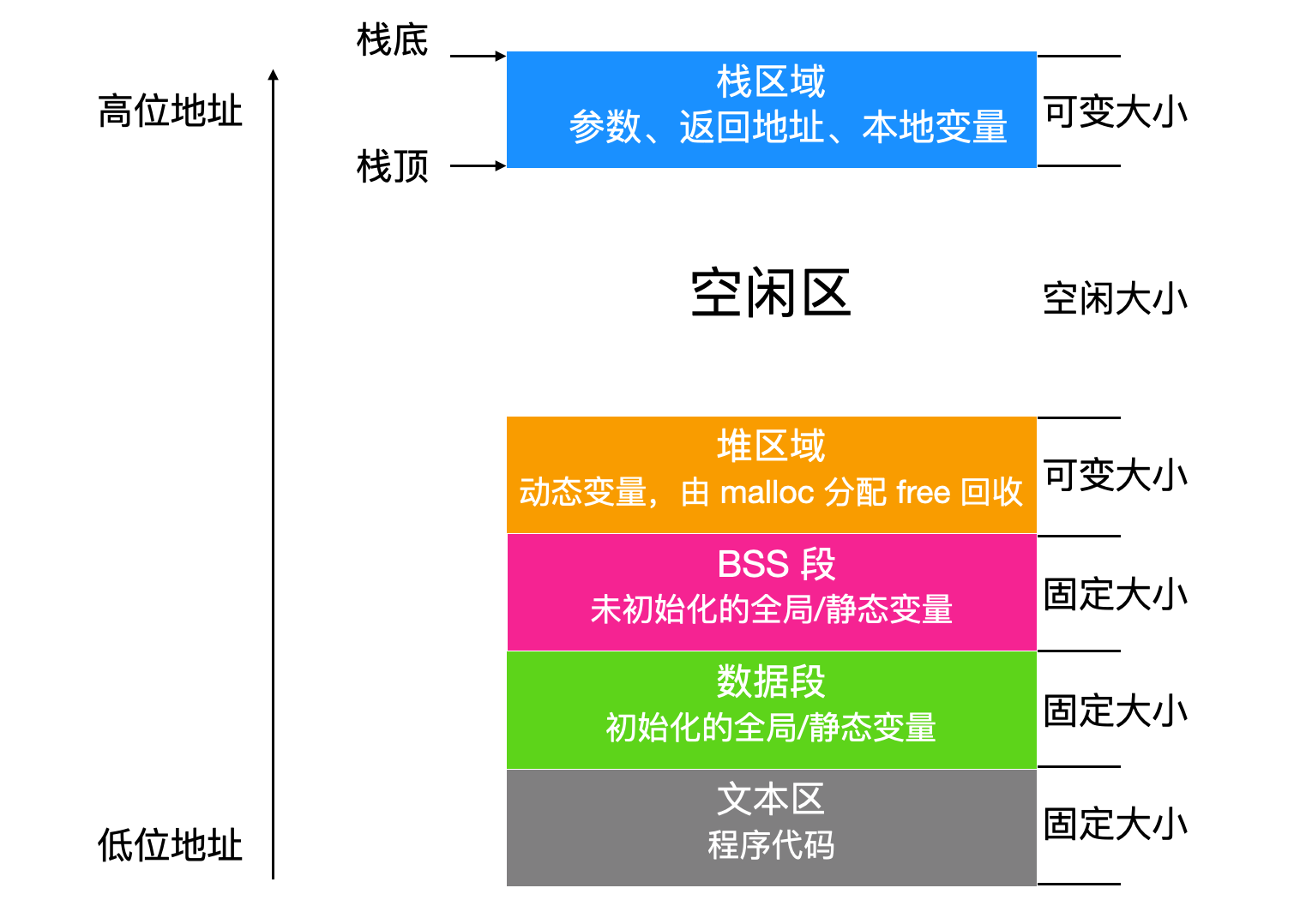
进程映像是指程序运行时所需的内存布局结构,通常包含以下几个部分:
-
代码段(Code Segment / Text Segment)
- 用于存放程序的执行指令,是只读的内存区域。
- 大小在程序编译完成后即确定,运行期间不可修改。
- 部分架构支持代码段可写,代码段中也可能包含只读常量(如字符串常量)。
-
数据段(Data Segment)
- 可读可写的内存区域,用于存放已初始化的全局变量与已初始化的
static变量。 - 生命周期与进程一致,进程创建时分配内存,进程终止时释放内存。
- 可读可写的内存区域,用于存放已初始化的全局变量与已初始化的
-
BSS 段(BSS Segment)
- 可读可写的内存区域,用于存放未初始化的全局变量与未初始化的
static变量。 - 该段内的变量默认初始化为 0。
- 可读可写的内存区域,用于存放未初始化的全局变量与未初始化的
-
栈(Stack)
- 可读可写的内存区域,采用**后进先出(LIFO)**原则管理数据。
- 用于存放函数的局部变量(非
static变量)、函数参数与返回地址。 - 生命周期与函数调用周期一致,函数调用时分配栈帧,函数返回时释放栈帧。
-
堆(Heap)
- 可读可写的内存区域,用于存放程序运行期间动态分配的内存(如通过
malloc()、realloc()函数分配的内存)。 - 生命周期由程序员手动管理,需通过
free()函数释放已分配的内存,否则会造成内存泄漏。
- 可读可写的内存区域,用于存放程序运行期间动态分配的内存(如通过
进程映像的内存布局如下图所示:
exec 并非单一函数,而是一组函数的统称,包含以下 6 个变体:
execlexecleexeclpexecvexecveexecvp
exec 函数的工作流程如下:
- 当前进程的内存映像被新的可执行文件覆盖。
- 新的进程映像由传入
exec函数的参数指定。 - 当前进程的原有执行逻辑终止。
- 新进程继承原进程的 PID、环境变量与部分文件描述符。
- CPU 状态与虚拟内存映射被更新,原进程的虚拟内存空间被新进程的虚拟内存空间替换。
waitpid
waitpid 系统调用用于让父进程等待指定子进程终止或暂停,并获取子进程的退出状态。该调用可实现父进程与子进程的同步。
exit
exit 系统调用用于终止当前进程的执行。调用时传入的参数为进程的退出状态码:0 表示进程正常终止,非零值表示进程异常终止。
其他常见的进程管理相关系统调用如下表所示:
| 系统调用指令 | 描述 |
|---|---|
pause | 挂起进程,直至收到任意信号 |
nice | 修改分时进程的静态优先级 |
ptrace | 实现进程跟踪功能,用于调试器开发 |
kill | 向指定进程或进程组发送信号 |
pipe | 创建匿名管道 |
mkfifo | 创建命名管道(FIFO 文件) |
sigaction | 设置进程对指定信号的处理方式 |
msgctl | 对消息队列执行控制操作 |
semctl | 对信号量执行控制操作 |
Linux 进程和线程的实现
Linux 进程
Linux 进程的底层实现机制较为复杂,其表面行为仅为内核管理逻辑的外在体现。

在 Linux 内核中,进程被抽象为任务(Task),通过 task_struct 结构体进行描述。与其他操作系统不同,Linux 内核并未区分进程、轻量级进程与线程的概念,而是统一使用 task_struct 结构体表示所有执行上下文。因此,对于单线程进程,内核用一个 task_struct 结构体描述;对于多线程进程,内核为每个用户级线程分配一个独立的 task_struct 结构体。Linux 内核本身是多线程的,内核级线程不与任何用户级线程关联。
每个进程在内核中都对应一个 task_struct 进程描述符,该结构体包含了内核管理进程所需的所有信息,例如调度参数、打开的文件描述符、内存映射表等。进程描述符存储在进程的内核堆栈中,从进程创建时开始存在,直至进程终止时被销毁。
与 Unix 系统一致,Linux 通过 PID 区分不同进程。内核将所有进程的 task_struct 结构体组织成一个双向链表,通过 PID 可直接映射到对应的 task_struct 结构体地址,无需遍历链表即可快速访问,提升了进程管理的效率。
进程驻留内存(Process In Memory, PIM) 是冯·诺依曼体系结构的概念,指加载到内存中并正在执行的程序实例。简单来说,进程就是正在运行的程序。
进程描述符包含的信息可分为以下几类:
- 调度参数(Scheduling Parameters):包括进程优先级、最近 CPU 占用时间、最近睡眠时间等,这些参数共同决定了进程的调度顺序。
- 内存映像(Memory Image):即前文所述的进程内存布局,包含代码段、数据段、栈、堆等区域的映射信息。
- 信号(Signals):记录进程对各类信号的处理方式,例如捕获、忽略或执行默认操作。
- 寄存器状态:用于保存进程切换时的 CPU 寄存器值,以便进程恢复执行时能够还原上下文。
- 系统调用状态:记录当前进程正在执行的系统调用信息,包括系统调用号、参数与返回值。
- 文件描述符表:存储进程打开的所有文件描述符,每个文件描述符对应一个内核文件对象的指针。
- 统计数据(Accounting):记录进程的资源使用情况,例如 CPU 占用时间、内存占用量、磁盘 I/O 次数等。
- 内核堆栈(Kernel Stack):进程在内核态运行时使用的固定大小堆栈空间。
- 其他信息:包括进程当前状态、等待事件、定时器信息、父进程 PID、用户标识符(UID)与组标识符(GID)等。
基于上述数据结构,Linux 进程的创建过程可概括为:为子进程分配新的用户空间与进程描述符,从父进程复制大部分属性,分配唯一 PID,设置内存映射,继承文件访问权限,最后将子进程加入调度队列并启动执行。
当进程调用 fork 系统调用时,会触发以下内核操作:
- 进程从用户态切换至内核态。
- 内核为子进程创建
task_struct结构体、内核堆栈与thread_info结构体。关于
thread_info结构体的详细定义,可参考内核源码:https://docs.huihoo.com/doxygen/linux/kernel/3.7/arch_2avr32_2include_2asm_2thread__info_8h_source.html thread_info结构体中包含指向task_struct结构体的指针,且该指针位于结构体的固定偏移位置,使得内核可通过thread_info快速定位到task_struct,降低了上下文切换的开销。- 内核基于父进程的
task_struct结构体填充子进程的task_struct字段。 - 内核从 PID 池中分配一个未被使用的 PID 给子进程,并更新进程链表与哈希表,避免 PID 冲突。
从理论上讲,fork 调用需要为子进程分配独立的内存空间,并复制父进程的代码段、数据段与堆栈段。但直接复制会产生巨大的内存开销与时间开销。为解决该问题,Linux 内核采用了**写入时复制(Copy on Write, COW)**机制,其逻辑如下:
fork调用执行时,内核不为子进程分配新的物理内存,而是让子进程的页表指向父进程的物理内存页面。- 将这些共享页面的属性设置为只读。
- 当父进程或子进程尝试修改共享页面的数据时,会触发写保护异常。
- 内核捕获该异常后,为触发写操作的进程分配一块新的物理内存页面,将原页面的数据复制到新页面中,并更新该进程的页表,使其指向新页面。
- 后续对该页面的修改将仅作用于新页面,父进程与子进程的内存空间自此分离。
写入时复制机制避免了不必要的内存复制,显著降低了 fork 调用的开销,节省了系统内存资源。
子进程创建完成后,若需执行新的程序,会调用 exec 系统调用,此时内核会执行以下操作:
- 验证传入的可执行文件路径是否合法,检查文件的权限与格式。
- 将命令行参数与环境变量从用户态复制到内核态。
- 释放当前进程的旧内存空间(代码段、数据段、栈、堆等)。
- 创建新的虚拟内存映射表,若系统支持内存映射文件(如 Unix 系统的
mmap机制),则将可执行文件的内容映射到进程的虚拟内存空间,而非一次性加载全部内容。 - 进程首次访问新内存空间时,会触发缺页异常(Page Fault),内核会按需将对应的代码或数据页面从磁盘加载到物理内存中。
- 将命令行参数与环境变量复制到新的用户栈中。
- 重置进程的信号处理方式,将 CPU 寄存器清零,并设置程序计数器指向可执行文件的入口地址。
- 新程序开始执行。
以 Shell 执行 ls 命令为例,其底层流程如下:
- Shell 进程调用
fork创建子进程。 - 子进程调用
exec函数,将自身的内存映像替换为ls程序的内存映像。 ls程序执行完毕后调用exit终止,父进程通过waitpid获取子进程的退出状态并回收资源。
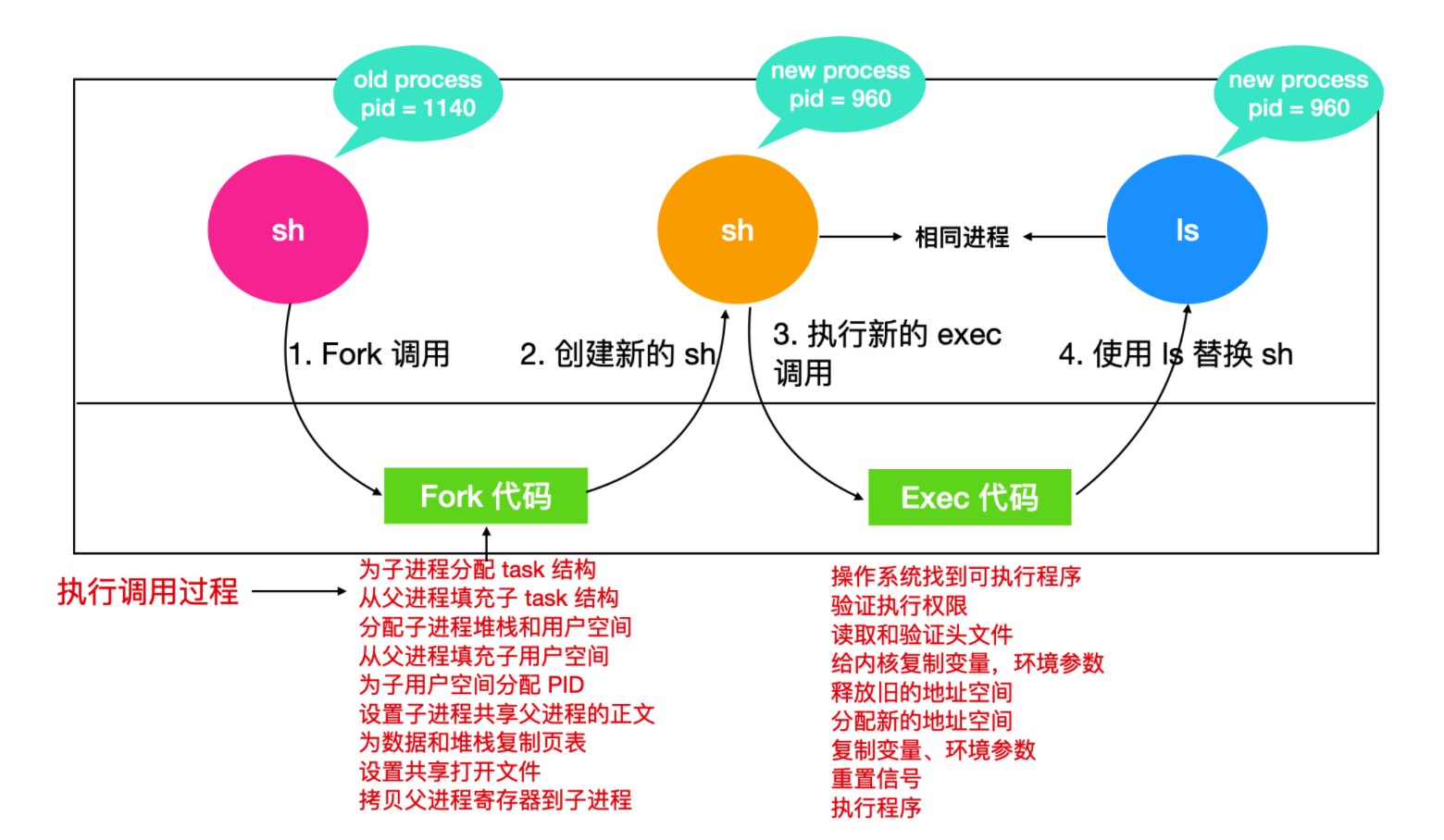
Linux 线程
线程是轻量级的执行单元,其优势在于上下文切换的开销远低于进程,且线程间的通信效率更高。进程切换需要切换内存空间、页表、文件描述符表等大量数据结构,而线程切换仅需切换寄存器状态与内核堆栈。Linux 系统中的线程分为两类:用户级线程与内核级线程。
用户级线程
用户级线程的管理逻辑完全在用户态实现,无需内核参与。线程的创建、销毁与调度均由用户层的线程库(如 POSIX Threads 库)完成。
用户级线程的切换流程如下:
- 线程主动调用切换函数,或通过发送信号、计时器中断等方式放弃 CPU 使用权。
- 线程库保存当前线程的上下文(寄存器状态、栈指针等)。
- 线程库选择就绪队列中的下一个线程,并恢复其上下文。
- 新线程开始执行。
用户级线程的切换速度极快,无需陷入内核态。但该实现方式存在以下缺陷:
- 阻塞问题:若某个用户级线程执行阻塞式系统调用(如
read、write),会导致整个进程被阻塞,进程内的所有用户级线程均无法执行。 - CPU 抢占问题:用户级线程的调度由线程库控制,若某个线程长时间占用 CPU,可能导致其他线程饥饿(Starvation),无法获得执行机会。
为解决上述问题,部分线程库采用了以下优化策略:
- 使用定时器中断强制线程切换,避免单个线程独占 CPU。
- 对阻塞式系统调用进行封装,采用非阻塞 I/O 模型(如
select、poll、epoll),避免进程整体阻塞。

内核级线程
内核级线程的管理逻辑由操作系统内核实现,内核为每个线程分配一个独立的 task_struct 结构体。内核直接参与线程的创建、销毁与调度,线程的调度与进程调度使用相同的调度算法。
内核级线程的优势如下:
- 阻塞处理:若某个内核级线程执行阻塞式系统调用,内核会将该线程阻塞,并调度同一进程内的其他就绪线程执行,不会导致整个进程阻塞。
- 公平调度:内核根据线程的优先级与时间片分配 CPU 资源,避免线程饥饿问题。
内核级线程的主要缺点是上下文切换开销较高,每次线程切换都需要在用户态与内核态之间进行上下文切换。

混合实现
混合实现模式结合了用户级线程与内核级线程的优点,其思想是将多个用户级线程多路复用到少量内核级线程上。
在该模式下,用户程序可创建大量用户级线程,这些线程由用户态的线程库管理;内核仅管理少量内核级线程,用户级线程通过绑定到内核级线程上执行。该模式的优势如下:
- 灵活性高:程序员可根据应用需求调整用户级线程与内核级线程的数量比例。
- 开销均衡:用户级线程的切换开销低,内核级线程的调度由内核负责,可充分利用多核 CPU 的并行处理能力。
- 阻塞优化:当某个用户级线程阻塞时,线程库可将其与内核级线程解绑,并将其他就绪的用户级线程绑定到该内核级线程上执行,避免进程阻塞。

Linux 调度
Linux 采用基于线程的调度模型,内核的调度对象是线程(task_struct 结构体),而非进程。进程仅作为线程的容器存在。
为满足不同应用场景的需求,Linux 将线程分为以下三类调度策略:
- 实时先入先出调度(SCHED_FIFO)
- 适用于实时任务,具有最高的调度优先级。
- 采用 FIFO 调度算法,高优先级的线程一旦就绪,会立即抢占低优先级线程的 CPU 使用权。
- 线程执行完毕或主动放弃 CPU 前,会一直占用 CPU。
- 实时轮询调度(SCHED_RR)
- 适用于实时任务,优先级低于
SCHED_FIFO。 - 采用时间片轮转调度算法,每个线程分配固定的时间片。
- 线程的时间片耗尽后,会被放入就绪队列尾部,等待下一次调度。
- 适用于实时任务,优先级低于
- 分时调度(SCHED_OTHER)
- 适用于普通非实时任务,是默认的调度策略。
- 采用动态优先级调度算法,根据线程的 CPU 占用情况调整优先级。
注:Linux 中的实时性是软实时,无法保证任务的绝对执行时限,仅能保证高优先级任务优先执行。
Linux 为每个线程分配一个 nice 值,用于表示线程的静态优先级。nice 值的取值范围为 -20 至 +19,默认值为 0。nice 值越小,线程的静态优先级越高:root 用户可设置 nice 值为 -20 ~ +19,普通用户仅能设置 nice 值为 0 ~ +19。
Linux 内核的调度算法经历了多次迭代,以下介绍两种经典的调度算法:
O(1) 调度器
O(1) 调度器是 Linux 2.6 内核版本引入的调度算法,其名称源于该算法可在常数时间内完成线程的调度决策,与系统中的线程数量无关。
O(1) 调度器的设计如下:
- 双数组结构:内核维护两个数组,分别为活动数组(active array)与过期数组(expired array)。每个数组包含 140 个链表头,对应 140 个优先级级别。
- 线程分类:处于运行状态或就绪状态的线程被放入活动数组的对应优先级链表中;时间片耗尽的线程被移至过期数组的对应优先级链表中。
- 调度流程
- 调度器从活动数组中选择优先级最高的线程执行。
- 线程的时间片耗尽后,被移至过期数组。
- 若线程在时间片耗尽前因 I/O 等操作阻塞,等待事件完成后会被重新加入活动数组,并保留剩余的时间片。
- 当活动数组为空时,内核交换活动数组与过期数组的指针,过期数组变为新的活动数组,原活动数组变为新的过期数组。
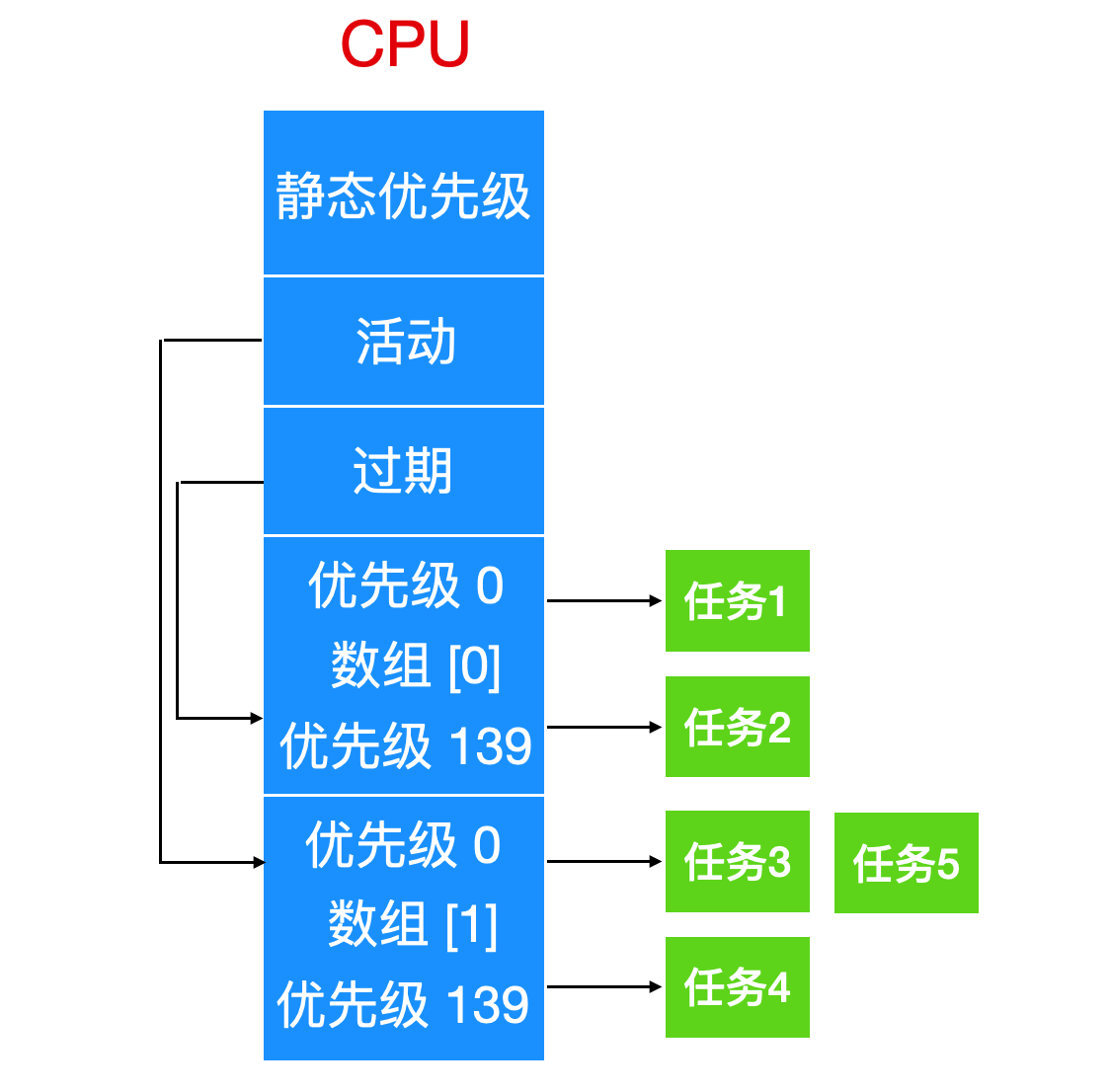
O(1) 调度器为不同优先级的线程分配不同长度的时间片:高优先级线程的时间片较长,低优先级线程的时间片较短。为提升交互式应用的响应速度,调度器会为交互式线程(如桌面应用、Shell 进程)赋予更高的动态优先级。
O(1) 调度器通过奖励与惩罚机制调整线程的动态优先级:
- 内核为每个线程维护一个
sleep_avg变量,用于记录线程的睡眠时间。 - 线程从睡眠状态被唤醒时,
sleep_avg变量值增加,动态优先级提升(奖励交互式线程)。 - 线程的时间片耗尽时,
sleep_avg变量值减少,动态优先级降低(惩罚 CPU 密集型线程)。
O(1) 调度器的动态优先级调整范围为 -5 ~ +5,即静态优先级最高可提升 5 级,最低可降低 5 级。
尽管 O(1) 调度器的调度效率极高,但该算法采用的启发式优先级调整策略存在缺陷:动态优先级的计算逻辑复杂且不够精准,在某些场景下会导致交互式线程的响应速度下降。
完全公平调度器(Completely Fair Scheduler, CFS)
为解决 O(1) 调度器的缺陷,Linux 2.6.23 内核引入了 完全公平调度器(CFS),并成为默认的调度算法。CFS 的设计目标是保证所有线程获得公平的 CPU 资源占用时间。
CFS 的设计如下:
- 红黑树数据结构:CFS 采用红黑树作为就绪线程的存储结构,红黑树的节点按线程的**虚拟运行时间(vruntime)**排序。虚拟运行时间是线程实际运行时间的加权值,与线程的优先级成反比。
- 公平调度原则:CFS 始终选择红黑树中虚拟运行时间最小的线程执行(即红黑树最左侧的节点),确保每个线程的 CPU 占用时间尽可能均衡。
- 调度流程
- 线程创建时,计算其虚拟运行时间,并插入红黑树的对应位置。
- 调度器选择红黑树最左侧的线程执行。
- 线程执行过程中,虚拟运行时间不断增加;当虚拟运行时间超过阈值时,线程被重新插入红黑树,并触发调度。
- 线程因 I/O 等操作阻塞时,其虚拟运行时间停止增加,再次就绪时会被优先调度。
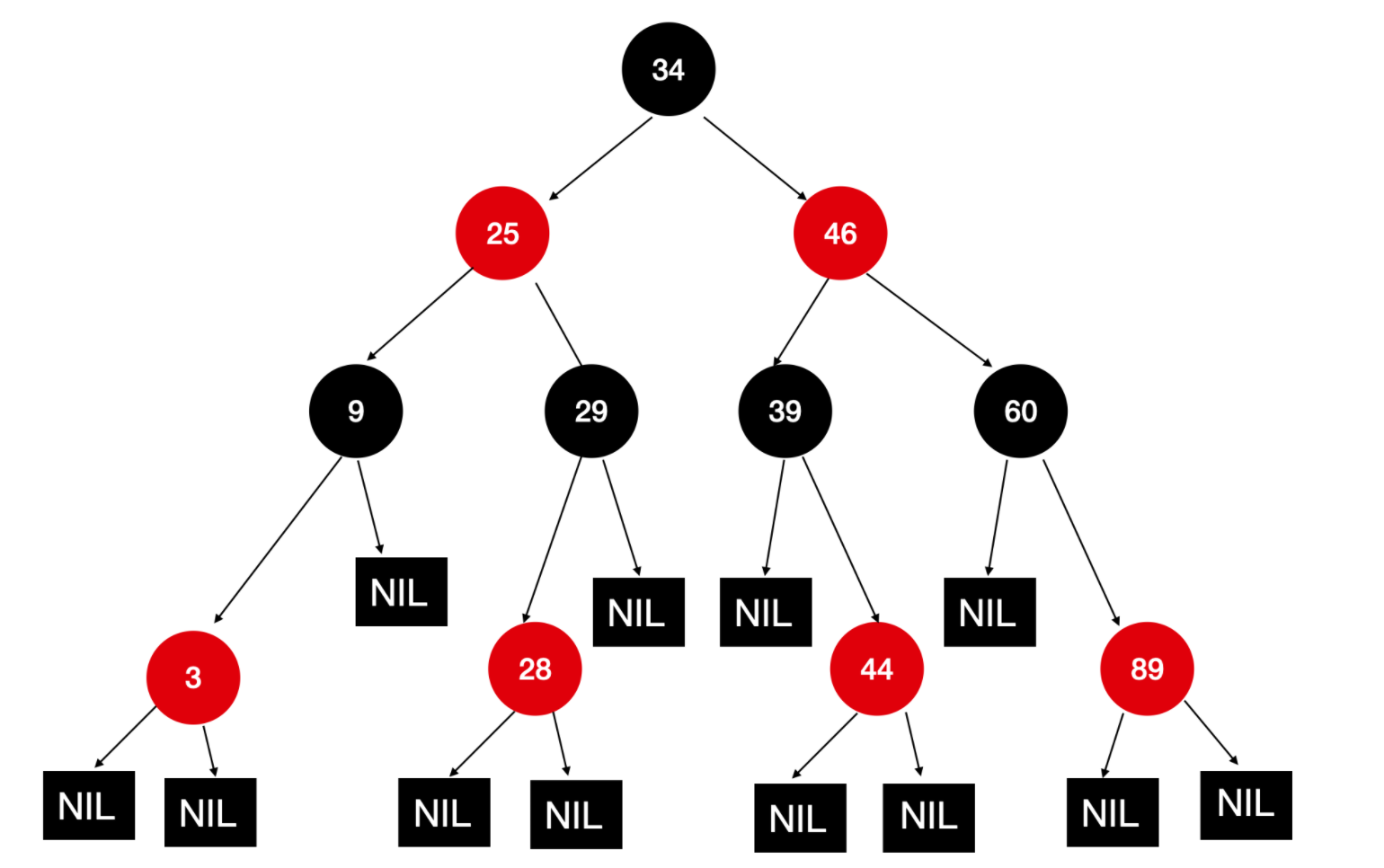
CFS 的调度决策时间复杂度为 O ( log N ) O(\log N) O(logN)( N N N 为就绪线程数量),虽然高于 O(1) 调度器,但在实际系统负载下,该开销完全可接受。CFS 凭借其优秀的公平性与简洁的设计,成为 Linux 内核的主流调度算法。
调度队列与等待队列
CFS 仅负责管理就绪状态的线程,这些线程被组织在与 CPU 核心对应的**运行队列(runqueue)中。处于阻塞状态的线程(如等待 I/O 完成、等待信号量)则被放入等待队列(waitqueue)**中。
等待队列的结构如下:
- 等待队列头(wait_queue_head_t):包含一个指向线程链表的指针与一个自旋锁(spinlock)。
- 等待队列项(wait_queue_t):表示等待队列中的一个线程节点,包含指向
task_struct结构体的指针与等待函数。
自旋锁用于保护等待队列的并发访问,确保在多核心系统中,对等待队列的操作是原子性的。
Linux 系统中的同步机制
Linux 内核与用户层程序均需要同步机制来协调多线程对共享资源的访问,避免出现数据竞争问题。Linux 提供了多种同步原语,其底层依赖硬件提供的原子指令实现。
原子操作
原子操作是不可中断的操作,执行过程中不会被其他线程抢占。Linux 内核提供了 atomic_t 类型与一系列原子操作函数(如 atomic_set、atomic_read、atomic_add),用于实现对共享变量的原子性读写。
内存屏障
由于 CPU 可能对指令进行重排序优化,导致多线程环境下的内存访问顺序不符合预期。Linux 提供了内存屏障指令(如 smp_mb、smp_rmb、smp_wmb),用于强制 CPU 按照程序顺序执行内存访问指令,保证内存操作的可见性与有序性。
自旋锁
自旋锁是一种忙等待锁,适用于临界区执行时间较短的场景。当线程尝试获取已被占用的自旋锁时,会循环检测锁的状态,直至锁被释放,期间不会放弃 CPU 使用权。
自旋锁的特点如下:
- 上下文切换开销低,适用于多核 CPU 系统。
- 临界区执行时间过长会导致 CPU 资源浪费。
- 不支持递归加锁,可能导致死锁。
互斥锁与信号量
互斥锁(Mutex)与信号量(Semaphore)是阻塞式同步原语,适用于临界区执行时间较长的场景。当线程尝试获取已被占用的锁时,会被阻塞并放入等待队列,直至锁被释放。
- 互斥锁:用于实现独占式访问,同一时刻仅允许一个线程持有锁。
- 信号量:支持多个线程同时持有锁,可用于实现资源计数功能。
Linux 还提供了 mutex_trylock、sem_trywait 等非阻塞式调用接口,允许线程在获取锁失败时立即返回,而非阻塞等待。
中断屏蔽
在中断处理程序中,为避免与内核线程竞争共享资源,可通过屏蔽本地中断的方式实现同步。中断屏蔽会禁止当前 CPU 核心响应中断,确保临界区代码的原子性执行。
Linux 系统启动流程
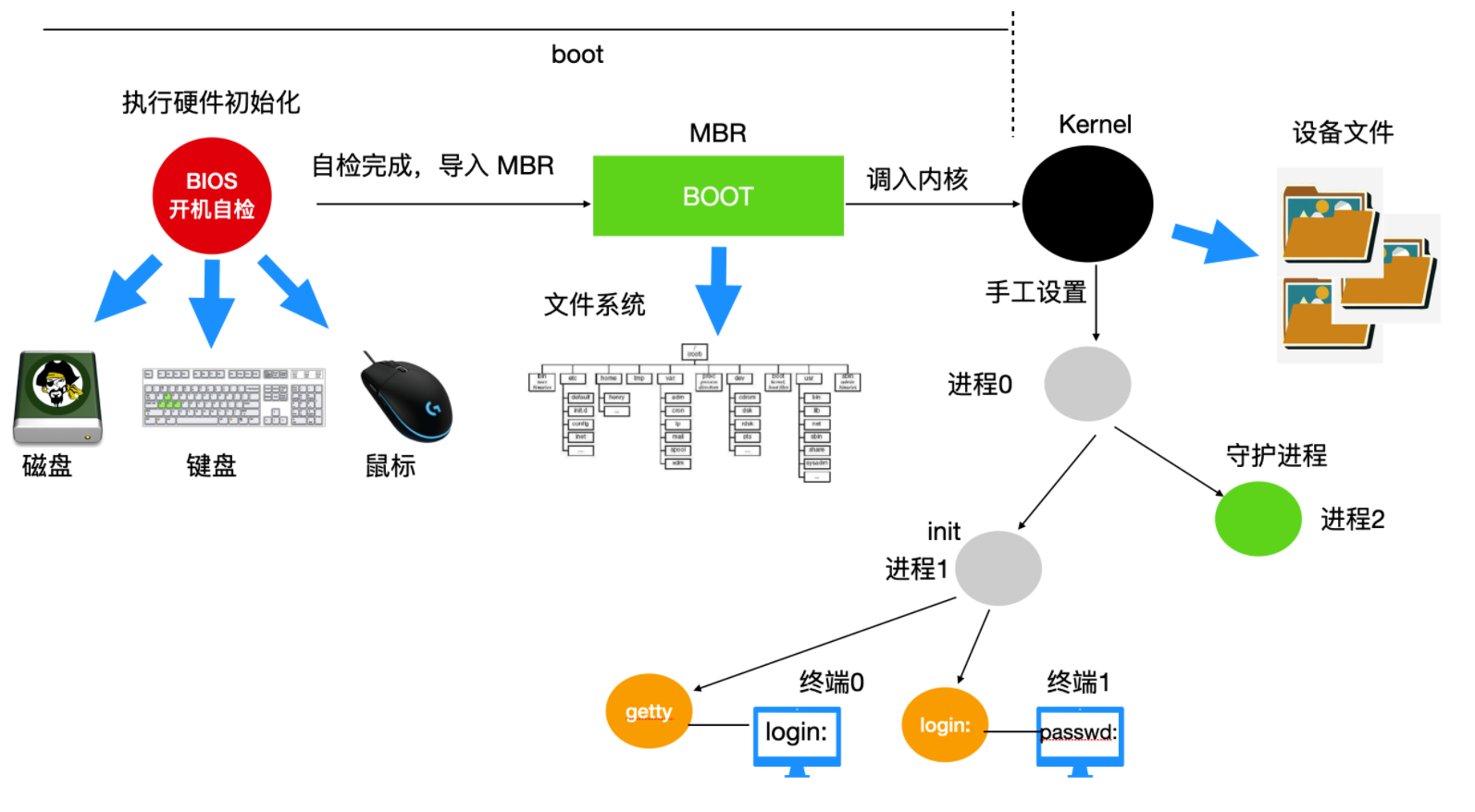
Linux 系统的启动过程是一个从硬件初始化到用户环境加载的复杂流程,主要分为以下几个阶段:
-
BIOS 开机自检(Power-On-Self-Test, POST)
- 计算机通电后,首先执行 BIOS 固件中的初始化代码。
- BIOS 对硬件设备进行检测与初始化,包括 CPU、内存、磁盘、显卡、键盘等。
- 检测通过后,BIOS 会在启动设备的**主引导记录(Master Boot Record, MBR)**中查找引导程序。MBR 是磁盘的第一个扇区,大小为 512 字节。
-
MBR 引导程序执行
- MBR 中的引导程序被加载到内存的固定地址并执行。
- 引导程序的功能是从磁盘中加载 Boot Loader(如 GRUB、LILO)到内存中。
- Boot Loader 加载完成后,会将自身复制到内存的高位地址空间,为后续加载内核释放低位内存空间。
-
Boot Loader 加载内核
- Boot Loader 读取启动设备的根目录,解析文件系统结构。
- 用户通过 Boot Loader 的交互界面选择要启动的内核版本。
- Boot Loader 将选中的内核镜像(
vmlinuz)与初始化内存盘(initrd/initramfs)加载到内存中。 - Boot Loader 设置内核的启动参数,然后将系统控制权移交给内核。
-
内核初始化
- 内核启动代码以汇编语言编写,执行以下初始化操作:
- 创建内核堆栈。
- 识别 CPU 类型与架构。
- 检测内存大小并初始化内存管理单元(MMU)。
- 禁用中断。
- 汇编代码执行完毕后,调用 C 语言编写的
start_kernel()函数,进入内核的主初始化流程。 start_kernel()函数执行以下操作:- 初始化内核的数据结构(如进程描述符、内存映射表)。
- 初始化中断处理机制与定时器。
- 挂载根文件系统(依赖
initrd/initramfs提供的临时文件系统)。 - 创建 0 号进程(idle 进程),该进程是系统中所有进程的祖先。
- 内核启动代码以汇编语言编写,执行以下初始化操作:
-
初始化进程启动
- 0 号进程通过
fork系统调用创建 1 号进程(init 进程),init进程是用户态的第一个进程,负责启动系统的各项服务。 - 0 号进程还会创建 2 号进程(kthreadd 进程),该进程负责管理内核线程的创建与销毁。
init进程根据启动级别(如 runlevel 3 为多用户命令行模式,runlevel 5 为图形界面模式)执行初始化脚本(/etc/rc.d目录下的脚本)。- 初始化脚本完成以下工作:
- 检测并挂载其他文件系统。
- 启动系统守护进程(如
cron、sshd、syslogd)。 - 配置网络接口。
- 0 号进程通过
-
用户登录环境初始化
init进程读取/etc/ttys文件,该文件列出了系统中的所有终端设备。- 对于每个启用的终端设备,
init进程调用fork创建子进程,并执行getty程序。 getty程序在终端上输出login:提示符,等待用户输入用户名。- 用户输入用户名后,
getty程序执行exec调用,将自身替换为login程序。 login程序提示用户输入密码,并与/etc/passwd、/etc/shadow文件中的密码哈希值进行比对。- 密码验证通过后,
login程序执行exec调用,启动用户的登录 Shell(如bash、zsh)。 - Shell 执行用户的个性化配置脚本(如
~/.bashrc),然后等待用户输入命令,至此系统启动完成。
Linux 系统的完整启动流程如下图所示:
Linux 查看进程、线程常用命令
一、 进程信息查看命令
1. ps:进程状态查询
ps 是最基础的进程查看命令,可列出当前系统中运行的进程快照,支持多种参数组合以筛选和格式化输出内容。
| 参数组合 | 功能描述 |
|---|---|
ps aux | 显示系统中所有进程的详细信息,包括无终端关联的进程(如守护进程),输出字段包含 USER(进程所属用户)、PID(进程标识符)、%CPU(CPU 占用率)、%MEM(内存占用率)、COMMAND(启动命令)等 |
ps ef | 以全格式列出所有进程,输出字段包含 UID(用户 ID)、PID、PPID(父进程 ID)、C(CPU 使用率)、STIME(启动时间)、CMD(命令),并可通过 --forest 参数展示进程树结构 |
ps -l | 以长格式显示当前终端关联的进程,输出字段包含 F(进程标志)、S(进程状态)、PRI(优先级)、NI(nice 值)等调度相关信息 |
ps -p <pid> | 查看指定 PID 进程的信息,例如 ps -p 1 查看 init 进程详情 |
进程状态字段说明:
R:运行态,进程正在 CPU 上执行或处于就绪队列S:睡眠态,进程等待事件完成(可被信号唤醒)D:不可中断睡眠态,进程等待 I/O 操作完成(如磁盘读写),无法被信号打断Z:僵尸态,进程已终止但父进程未回收其资源T:停止态,进程被SIGSTOP等信号暂停执行
2. top:交互式进程监控
top 提供动态、实时的进程监控界面,默认按 CPU 占用率排序,支持交互式操作调整显示内容。
| 交互式操作 | 功能描述 |
|---|---|
P | 按 CPU 占用率从高到低排序 |
M | 按内存占用率从高到低排序 |
T | 按进程运行时间从长到短排序 |
p | 输入 PID 筛选指定进程 |
h | 显示帮助信息 |
q | 退出 top 界面 |
关键输出字段:
PID:进程标识符USER:进程所属用户PR:进程调度优先级NI:进程nice值VIRT:进程占用的虚拟内存总量RES:进程占用的物理内存大小SHR:进程共享的内存大小S:进程状态%CPU:实时 CPU 占用率%MEM:实时内存占用率TIME+:进程累计占用的 CPU 时间
3. pgrep:进程 ID 查找
pgrep 可根据进程名称、用户等条件快速查询匹配进程的 PID,避免手动过滤 ps 输出。
| 常用参数 | 功能描述 |
|---|---|
pgrep <进程名> | 查找指定名称进程的 PID,例如 pgrep sshd 查找 SSH 守护进程的 PID |
pgrep -u <用户名> | 查找指定用户运行的所有进程的 PID,例如 pgrep -u root |
pgrep -f <命令行> | 根据完整命令行匹配进程,例如 pgrep -f "python app.py" |
4. pstree:进程树展示
pstree 以树形结构展示进程间的父子关系,直观呈现进程的派生层级。
| 常用参数 | 功能描述 |
|---|---|
pstree | 显示所有进程的树形结构,默认合并同名进程 |
pstree -p | 显示进程树并标注每个进程的 PID |
pstree <pid> | 显示指定 PID 进程的子进程树,例如 pstree 1 查看 init 进程的子进程 |
二、 线程信息查看
Linux 中线程被视为轻量级进程,内核通过 task_struct 统一管理进程与线程,因此部分进程查看命令可直接用于线程查询。
1. ps:线程信息查询
通过添加 -L 参数,ps 可显示进程内的所有线程信息。
| 参数组合 | 功能描述 |
|---|---|
ps -L <pid> | 查看指定 PID 进程内的所有线程,输出字段新增 LWP(线程 ID)、NLWP(进程内线程总数) |
ps auxL | 显示系统中所有进程及其包含的线程信息 |
2. top:线程级监控
在 top 界面中按下 H 键,可切换至线程级监控模式,显示进程内每个线程的资源占用情况。
| 操作步骤 | 功能描述 |
|---|---|
1. 执行 top -p <pid> | 聚焦指定进程 |
2. 按下 H 键 | 切换为线程视图,界面显示该进程内所有线程的 LWP、%CPU、%MEM 等信息 |
3. 按下 k 键 | 可输入线程 LWP 终止指定线程 |
3. htop:增强型交互式监控
htop 是 top 的升级版,默认支持线程视图,界面更友好,操作更便捷(需手动安装)。
| 常用操作 | 功能描述 |
|---|---|
启动 htop | 直接执行 htop 命令,默认显示进程列表 |
按下 F2 | 进入设置界面,可配置显示字段与排序方式 |
按下 F3 | 搜索指定进程或线程名称 |
按下 H | 切换线程视图,显示进程内的所有线程 |
4. /proc 文件系统:进程与线程的底层信息查询
Linux 内核通过 /proc 虚拟文件系统暴露进程和线程的底层运行信息,每个进程对应 /proc/<pid> 目录,线程信息存储在该目录下的子文件中。
| 文件路径 | 功能描述 |
|---|---|
/proc/<pid>/task | 该目录下包含进程内所有线程的子目录,每个子目录以线程 LWP 命名 |
/proc/<pid>/task/<lwp>/status | 查看指定线程的状态信息,包括线程 ID、状态、CPU 时间、内存占用等 |
/proc/<pid>/status | 查看进程的整体状态,其中 Threads 字段表示进程内的线程总数 |
示例:查看 PID 为 1234 的进程内线程总数
cat /proc/1234/status | grep Threads
示例:查看 PID 为 1234 的进程内 LWP 为 1235 的线程状态
cat /proc/1234/task/1235/status
三、 进程资源占用分析
1. pmap:进程内存映射查看
pmap 可显示指定进程的内存映射详情,包括各内存段的地址、大小、权限、映射文件路径等,用于分析进程的内存使用情况。
| 常用参数 | 功能描述 |
|---|---|
pmap <pid> | 查看指定进程的内存映射信息 |
pmap -x <pid> | 以扩展格式显示内存映射,输出字段包含 Address(内存地址)、Kbytes(大小)、RSS(常驻内存)、Dirty(脏页大小)、Mode(权限)、Mapping(映射文件) |
2. strace:进程系统调用跟踪
strace 可跟踪进程执行过程中发起的所有系统调用,包括调用名称、参数、返回值,用于调试进程的异常行为。
| 常用参数 | 功能描述 |
|---|---|
strace <命令> | 跟踪指定命令执行过程中的系统调用,例如 strace ls |
strace -p <pid> | 附加到指定 PID 的进程,实时跟踪其系统调用 |
strace -c | 统计系统调用的调用次数、耗时、错误次数等信息 |
3. lsof:进程打开文件查看
lsof 可列出进程打开的所有文件描述符,包括普通文件、管道、套接字、设备文件等,用于分析进程的文件与网络资源占用。
| 常用参数 | 功能描述 |
|---|---|
lsof -p <pid> | 查看指定 PID 进程打开的所有文件 |
lsof -u <用户名> | 查看指定用户进程打开的所有文件 |
lsof -i | 查看所有网络套接字相关的文件描述符 |
四、 命令使用场景
| 需求场景 | 推荐命令 |
|---|---|
| 快速查看系统中所有进程的基本信息 | ps aux |
| 实时监控进程的 CPU 与内存占用 | top / htop |
| 查看进程的父子关系与派生层级 | pstree -p |
| 查看进程内的线程数量与线程状态 | ps -L <pid> / top -p <pid> + H |
| 分析进程的内存映射与资源占用 | pmap -x <pid> / lsof -p <pid> |
| 调试进程的系统调用与异常行为 | strace -p <pid> |
via:
- Linux Process and Thread Creation: System Call Architecture
https://chessman7.substack.com/p/linux-process-and-thread-creation - 一文搞定Linux进程和线程(详细图解)_linux 启动独立线程-优快云博客
https://blog.youkuaiyun.com/wzl1217333452/article/details/108670054 - linux进程和线程 - 《Linux 学习笔记》
https://www.bookstack.cn/read/KeKe-Li-linux-notes/src-chapter14-01.0.md


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









