




注:本文为 “英伟达 CUDA Tile ” 两篇公众号相关合辑。
略作重排,未整理去重。如有内容异常,请看原文。
英伟达革新 CUDA 编程门槛!15 行 Python 实现 GPU 内核,性能比肩 200 行 C++
关注前沿科技 量子位 2025 年 12 月 8 日 12:00 北京
梦晨 发自 凹非寺 量子位 | 公众号 QbitAI
GPU 编程领域迎来重大变革。
英伟达发布最新版本 CUDA 13.1,官方明确表述:这是自 2006 年诞生以来最为显著的技术进步。
关键更新在于推出全新的 CUDA Tile 编程模型,使开发者能够 通过 Python 编写 GPU 内核,仅需 15 行代码即可达到 200 行 CUDA C++ 代码的性能水平。

该消息发布后,芯片界传奇人物 Jim Keller 即刻提出疑问:
英伟达是否正在亲手终结 CUDA 的 “护城河” ?若英伟达全面转向 Tile 模型,AI 内核将更易于移植至其他硬件平台。

Jim Keller 曾参与 AMD Zen 架构、苹果 A 系列芯片、特斯拉自动驾驶芯片的设计工作,被誉为 “硅仙人”,其行业判断具有重要参考价值。
问题随之而来:CUDA 此次更新的具体内容是什么?为何被认为是 “自毁长城” ?
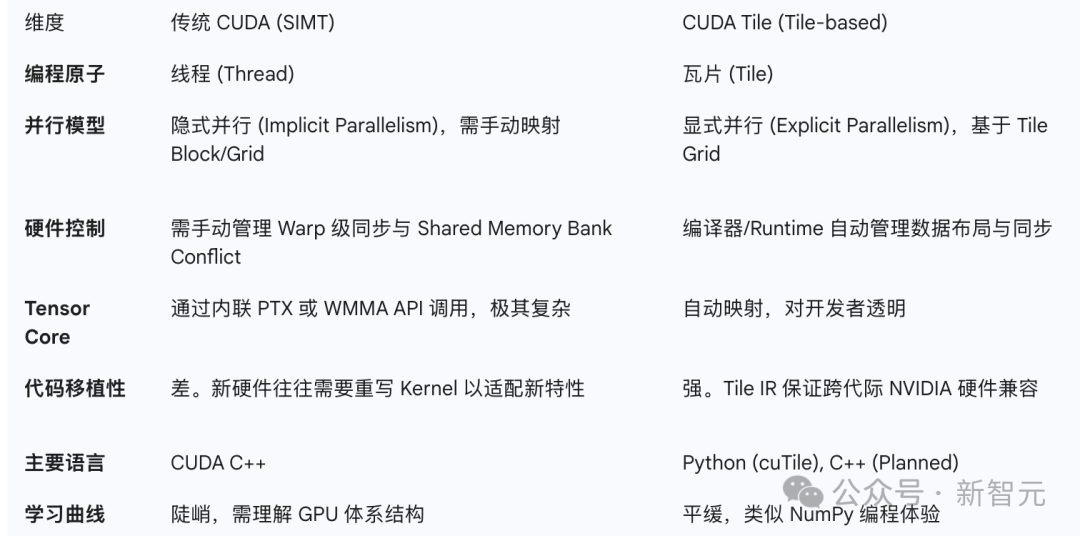
一、GPU 编程范式:从 “线程” 到 “瓦片” 的跨越
要理解此次更新的技术意义,需首先回顾传统 CUDA 编程的复杂性。
在过去 20 年间,CUDA 始终采用 SIMT(单指令多线程)模型,开发者编写代码时需手动管理线程索引、线程块、共享内存布局及线程同步等细节,每一项操作均需自主实现。
若要充分发挥 GPU 性能,尤其是调用 Tensor Core 等专用模块,更需要长期积累的技术经验作为支撑。
(一)CUDA Tile 的技术革新
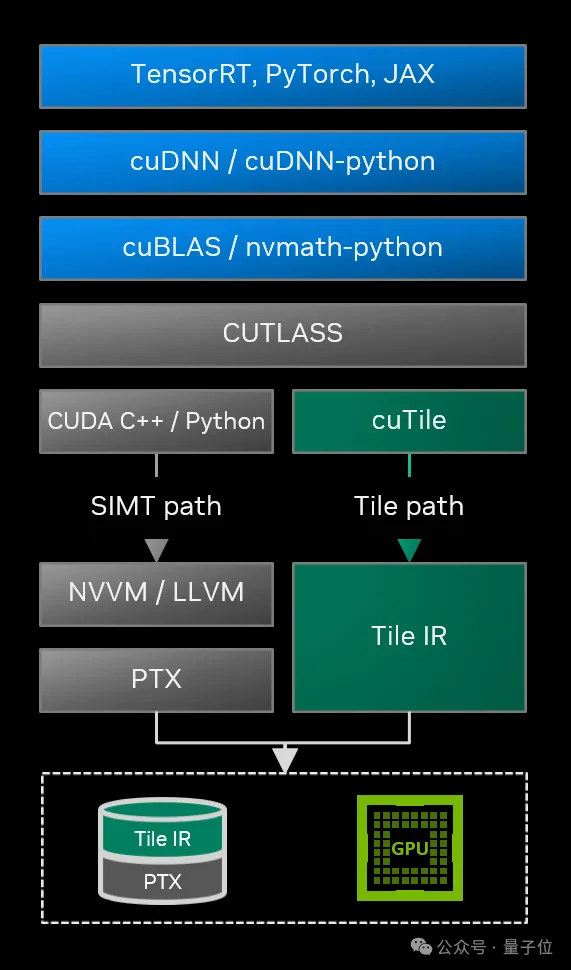
CUDA Tile 彻底重构了传统编程逻辑:
开发者无需逐线程设计执行路径,而是将数据组织为 Tile(瓦片)结构,随后定义 Tile 上的运算规则。至于如何将这些运算映射至 GPU 的线程、Warp 及 Tensor Core,均由编译器与运行时自动完成。
这一逻辑与 NumPy 在 Python 中的应用模式具有相似性。

英伟达为该模型构建了两大关键组件:
- CUDA Tile IR:一套全新的虚拟指令集,在高级语言与硬件之间构建抽象层,确保基于 Tile 编写的代码可兼容不同代际 GPU,从当前的 Blackwell 架构到未来的新型架构均能适配。
- cuTile Python:面向开发者的编程接口,支持直接通过 Python 编写 GPU 内核,使编程门槛从 “HPC 专家” 层级降低至 “具备 Python 基础的数据科学家” 可掌握的范围。
(二)Blackwell 架构针对性优化
此次更新同步推出一系列面向 Blackwell 架构的性能优化特性:
- cuBLAS 引入 FP64 与 FP32 精度在 Tensor Core 上的仿真功能;
- 新增的 Grouped GEMM API 在 MoE(混合专家模型)场景下可实现最高 4 倍加速;
- cuSOLVER 的批处理特征分解在 Blackwell RTX PRO 6000 上,相比 L40S 实现约 2 倍性能提升;
- 开发者工具 Nsight Compute 新增对 CUDA Tile 内核的性能分析支持,可将性能指标直接映射至 cuTile Python 源代码。
目前,CUDA Tile 仅支持 Blackwell 架构(计算能力 10.x 与 12.x),开发重心集中于 AI 算法领域。英伟达表示,未来将扩展至更多架构,并推出 C++ 实现版本。
二、硅仙人的质疑:降低门槛的双重影响
Jim Keller 为何认为英伟达可能 “终结自身护城河” ?
原因在于 Tile 编程模型并非英伟达专属技术。AMD、Intel 及其他 AI 芯片厂商的硬件,在底层架构上同样支持基于 Tile 的编程抽象。
传统 CUDA 难以移植,症结在于 SIMT 模型与英伟达硬件深度绑定,开发者需针对特定 GPU 架构手动编写优化代码,这类代码在其他厂商硬件上要么无法运行,要么性能大幅衰减。
而 Tile 模型具备天然的高抽象层级,当开发者习惯 “仅定义 Tile 运算,硬件细节交由编译器处理” 的编程逻辑后,理论上同一套算法可更便捷地适配至其他支持 Tile 编程的硬件平台。
正如 Jim Keller 所言:“AI 内核将更容易移植。”
但英伟达也预留了技术应对方案:CUDA Tile IR 提供的跨代兼容性,是建立在 CUDA 平台基础之上的。
开发者编写的代码虽更易移植,但移植目标仅限于英伟达自家不同代际的 GPU,而非竞争对手的硬件。
从这一角度看,CUDA 代码可从 Blackwell 架构无缝迁移至下一代英伟达 GPU,但要移植至 AMD 或 Intel 平台,仍需重新编写。
无论 “护城河” 是被加固还是削弱,有一点已成共识:GPU 编程门槛正在大幅降低。
过去,熟练掌握 CUDA 编程的开发者属于稀缺资源。虽然 Python 使用者群体庞大,但能够将代码优化至充分利用 Tensor Core 性能的专家极为稀少。
CUDA Tile 与 cuTile Python 的组合突破了这一瓶颈。英伟达在开发者博客中提及,15 行 Python 内核代码的性能可媲美 200 行手动优化的 CUDA C++ 代码。
这意味着大量数据科学家与 AI 研究者可直接上手编写高性能 GPU 代码,无需依赖 HPC 专家进行优化支持。
参考链接
[1] https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware
[2] https://x.com/jimkxa/status/1997732089480024498
英伟达是否终结 CUDA「护城河」?传奇芯片架构师引发行业争议
新智元 2025 年 12 月 8 日 16:50 北京

新智元报道
编辑:定慧
【新智元导读】深度解析 CUDA Tile 背后的技术布局与行业影响。
英伟达 CUDA 平台刚刚宣布了自诞生以来 20 年间最重大的一次更新!

其中,最具颠覆性的更新为 CUDA Tile 技术——允许开发者通过 Python 替代 C++ 编写内核代码。
在 CUDA 13.1 版本中,该技术通过抽象化底层硬件(如 Tensor Cores)细节,显著降低开发门槛。这一转变可类比为:从手动调试乐团中的每件乐器,转变为仅负责整体音乐指挥。

这一重磅更新迅速引发芯片界传奇人物、Tenstorrent CEO Jim Keller 的关注与质疑:
Jim Keller 提出观点:此次更新是否终结了 CUDA 的「护城河」?

他的论据是:当英伟达 GPU 转向 Tile 瓦片结构,且其他硬件厂商同步采用瓦片架构时,AI 内核的跨平台移植将变得更为便捷。

但事实果真如此吗?
要厘清这一问题,需从两个维度展开分析:
- Jim Keller 的行业地位:为何其观点具有重要影响力?
- CUDA Tile 的技术本质:CUDA「护城河」的本质是什么?
一、Jim Keller:芯片行业的传奇架构师
Jim Keller 是当代芯片界 最具代表性的 CPU/SoC 架构师之一,业内常被誉为「传奇架构师」「芯片圈 GOAT 之一」。
简而言之,他是真正改写过 CPU 发展路线图的关键人物。
近二十多年来,x86 架构、移动 SoC、AI 芯片领域的多次关键技术突破,背后均有 Jim Keller 的参与。

具体技术贡献包括:
(一)x86-64 时代的奠基人之一
作为 x86-64 指令集与 HyperTransport 技术的联合创作者,其技术成果直接影响了当前几乎所有桌面端与服务器端 CPU 的 ISA(指令集架构)及互连方式。
(二)多次主导企业级技术翻身战
- AMD Athlon/K8 时代:首次实现 AMD 在 x86 性能领域对 Intel 的正面抗衡;
- Zen 架构时代:助力 AMD 从市场劣势地位崛起,形成与 Intel 分庭抗礼的竞争格局;
- 苹果时期:主导 A4/A5 芯片设计,开启 iPhone 自研 SoC 路线,为后续 M 系列芯片奠定基础。
(三)跨领域的全栈架构师
极少有架构师能够在 通用 CPU、移动 SoC、车载 SoC、AI 加速器 四大领域均具备一线设计与架构决策经验。近年来,他频繁在 TSMC、三星等行业论坛分享未来工艺与架构趋势,被业界称为「半导体设计传奇」。
因此,Jim Keller 关于 CUDA Tile 的观点具有重要行业参考价值。
二、CUDA 的技术演进与「护城河」本质
英伟达此次更新究竟是拆除了 CUDA 的「护城河」,还是以新形式加固了这一优势?
去年,Jim Keller 曾直言「CUDA 是沼泽而非护城河」,暗指其复杂性使开发者难以脱离该生态系统。

(一)CUDA 的技术发展史
2006 年,英伟达发布 G80 架构与 CUDA 平台,将 GPU 的并行计算单元抽象为通用线程(Threads),正式开启通用 GPU 计算(GPGPU)的黄金时代。
此后二十年,基于「单指令多线程」(SIMT,Single Instruction, Multiple Threads)的编程模型成为 GPU 计算的主流范式。
开发者习惯从单个线程视角出发,设计如何将海量线程映射至数据处理流程。
(二)SIMT 模型的局限性
在人工智能技术爆发的当下,计算的单元已从单一标量数值转变为张量(Tensor)与矩阵。传统 SIMT 模型在处理这类块状数据时,逐渐显现出效率低下、编程复杂的问题。
1. 硬件与编程模型的不匹配
现代 AI 计算的核心是矩阵乘法,而英伟达为加速该运算引入的 Tensor Core 硬件模块,其设计逻辑是单次处理 16 × 16 16 \times 16 16×16 或更大尺寸的矩阵块。
但在 SIMT 模型中,开发者仍需以单个线程为控制单元。要调用 Tensor Core,需手动协调 32 个线程(一个 Warp)协同工作,完成数据从全局内存到共享内存再到寄存器的搬运,并通过复杂的 wmma(Warp-level Matrix Multiply Accumulate)指令实现同步。
2. 开发复杂度高
开发者需精细管理线程间同步与内存屏障,任何疏漏都可能导致死锁或数据竞争。同时,不同代际 GPU 的 Warp 调度机制与 Tensor Core 指令集存在差异,针对 Hopper 架构优化的高性能代码往往无法直接在 Blackwell 架构上运行,需重新进行适配调优。
这正是 Jim Keller 所指的「沼泽」——代码中充斥着针对不同硬件特性的适配补丁,既缺乏可读性,也难以维护。
本质而言,SIMT 模型的矛盾在于:试图用管理独立个体的逻辑(SIMT),去调度需要高度协同的集体操作(Tensor Core)。
三、CUDA Tile:瓦片化计算的技术重构
CUDA 13.1 引入的 CUDA Tile 彻底摒弃了「线程」这一基本编程单元,转而以「瓦片」(Tile)作为编程载体,实现了编程范式的根本性转变。
(一)概念:Tile 的技术定义
在 CUDA Tile 模型中,Tile 被定义为多维数组的一个数据分块(Subset of arrays)。开发者无需关注“第 X X X 号线程执行何种操作”,而是聚焦于“如何将大矩阵切分为若干 Tile,以及对这些 Tile 执行何种数学运算(如加法、乘法)”。
瓦片模型(左侧)将数据分割为块结构,由编译器完成块到线程的映射;而 SIMT 模型(右侧)需同时将数据映射至块与线程层面。

这一范式转变可类比为从汇编语言向高级语言的跨越:
- SIMT 模型:需手动管理寄存器分配、线程掩码、内存合并等底层细节;
- Tile 模型:仅需声明数据块的布局(Layout)与运算算子(Operator),其余操作均由编译器自动完成。
该编程范式在 Python 等高级语言中已较为常见,以 NumPy 库为例,开发者可直接定义矩阵等数据类型,并通过简洁代码实现批量运算逻辑。

在底层实现层面,对应的硬件操作会自动执行,整个计算流程对开发者完全透明。
(二)架构支撑:CUDA Tile IR 的技术价值
此次更新并非单纯的语法优化,英伟达同步引入了一套全新的中间表示——CUDA Tile IR(Intermediate Representation)。
CUDA Tile IR 构建了一套虚拟指令集,使开发者能够以瓦片操作的形式对硬件进行原生编程。
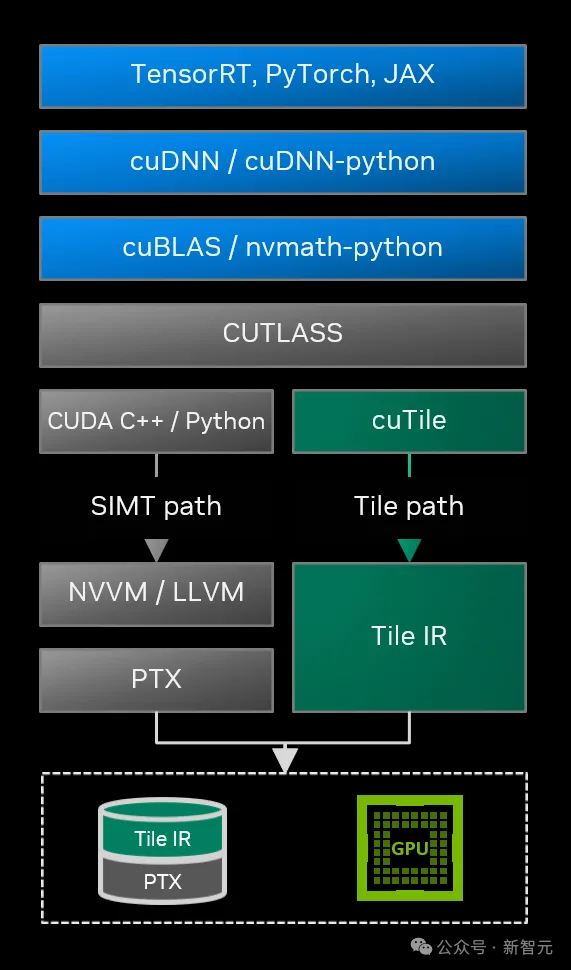
基于该指令集,开发者编写的高层级代码仅需少量修改,即可在多代际 GPU 上高效运行。从技术逻辑来看,CUDA Tile 本质上是英伟达对 AI 编程范式的“降维优化”——将复杂的硬件细节封装于编译器内部,仅向开发者暴露算法逻辑层。
在过往的 CUDA 版本中,C++ 始终是主要开发语言。而在 CUDA 13.1 中,英伟达首次优先推出 cuTile Python 接口,C++ 版本的支持则被延后规划。这一策略调整深刻反映了 AI 开发生态的现状:Python 已成为 AI 领域的通用开发语言。
在此之前,AI 研究员若需优化算子性能,需脱离 Python 开发环境,学习复杂的 C++ 与 CUDA 底层编程逻辑。cuTile 的推出使开发者无需切换环境,即可在 Python 中编写高性能 GPU 内核。
根据英伟达技术博客的案例展示,可通过向量加法的实现对比,直观体现 cuTile 的技术变革:
传统 SIMT 实现方式(伪代码):

cuTile Python 实现方式:

在该示例中,开发者无需了解 GPU 核心数量、Warp 的技术定义等底层硬件信息。ct.load 与 ct.store 等接口在底层可能调用 Blackwell 架构最新的异步内存复制引擎,但这一过程对开发者完全透明。
(三)CUDA Tile 的行业对标:与 OpenAI Triton 的技术博弈
要回答“CUDA Tile 是否终结了英伟达的护城河”这一问题,需引入关键参照变量:OpenAI Triton。
Triton 是 OpenAI 为摆脱对英伟达闭源库(如 cuDNN)的依赖而开发的开源编程语言,其理念与 CUDA Tile 高度一致:基于块(Block-based)的编程模型。

这一技术趋同特征,或成为英伟达推出 CUDA Tile 的行业动因。

综合行业分析与技术特征,关于“CUDA Tile 是否终结护城河”“瓦片架构是否提升 AI 内核跨厂商移植性”的结论如下:

- 英伟达代际间的移植性:这是 CUDA Tile 解决的问题。基于 Tile IR 编写的代码,可从 Hopper 架构无缝移植至 Blackwell 架构,甚至未来的 Rubin 架构,且能实现自动性能优化。在此维度下,代码的移植性得到极大提升。
- 跨厂商的移植性:这是行业期望解决的诉求(如从英伟达移植至 AMD MI300)。但在该维度下,CUDA Tile 几乎未提供实质性支持,甚至进一步提升了跨厂商移植的技术门槛。

Jim Keller 始终对 CUDA 持批判态度,其“CUDA 是沼泽” 的评价,指向 CUDA 的复杂性使开发者形成技术依赖。
综上分析,英伟达并未拆除 CUDA 的“护城河”,而是对其进行了重构:降低了进入生态的技术门槛(更易攀爬的“城墙”),同时在生态内部构建了更具粘性的技术体系(Tile IR 生态),进一步强化开发者的路径依赖。
瓦片架构的普及,使 AI 内核在英伟达不同代际硬件间的移植极为便捷,但在跨厂商硬件间的移植难度反而增加。
Jim Keller 关于“CUDA 曾是沼泽”的判断或许成立,但英伟达通过 CUDA Tile IR 在这片“沼泽”上搭建了专属的“高速公路”——而这条道路,目前仅通向英伟达的技术生态体系。
参考资料:
- https://x.com/jimkxa/status/1997732089480024498
- https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware/
- https://developer.nvidia.com/blog/nvidia-cuda-13-1-powers-next-gen-gpu-programming-with-nvidia-cuda-tile-and-performance-gains
- https://developer.nvidia.com/blog/simplify-gpu-programming-with-nvidia-cuda-tile-in-python
- https://www.tomshardware.com/tech-industry/artificial-intelligence/jim-keller-criticizes-nvidias-cuda-and-x86-cudas-a-swamp-not-a-moat-x86-was-a-swamp-too
via:
- 英伟达自毁 CUDA 门槛!15 行 Python 写 GPU 内核,性能匹敌 200 行 C++
https://mp.weixin.qq.com/s/LI04mIxaEOG5nY5DQF68Og - 英伟达亲手终结 CUDA「护城河」?传奇芯片架构师引发争议
https://mp.weixin.qq.com/s/13Yxbqsydg4va-LLLTOEEQ

















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









