







 Transformer模型解决了RNN在序列建模中的局限性,通过Self-Attention和Multi-Head Attention实现并行计算,提升了性能。本文详细介绍了Transformer的架构,包括Self-Attention、Multi-Head Attention、Positional Encoding以及它们在Encoder和Decoder中的应用,展示了其在自然语言处理领域的创新和影响。
Transformer模型解决了RNN在序列建模中的局限性,通过Self-Attention和Multi-Head Attention实现并行计算,提升了性能。本文详细介绍了Transformer的架构,包括Self-Attention、Multi-Head Attention、Positional Encoding以及它们在Encoder和Decoder中的应用,展示了其在自然语言处理领域的创新和影响。
1. Introduction
在transformer模型问世以前,序列建模任务最常用的模型就是sequence-to-sequence了,尤其是随着各种attention机制的加入,attention-based seq2seq模型获得了更好的性能从而得到了更广泛的应用。
不过RNN也有自己的问题:
-
无法并行,导致训练偏慢
-
句间依赖
序列问题其实包括了三种依赖:源句子内部依赖 ,目标句子内部依赖,源句子与目标句子之间的依赖。这三种依赖关系对于从源句子到目标句子的转换都十分重要,而seq2seq则无法建模这三种依赖,哪怕加上了attention,也只是捕捉到了源句子与目标句子间的依赖,另外两种依赖仍旧无法建模。
-
对长序列建模能力不足
由于RNN结构的串行特征,越往后面,它内部的信息对于最初的信息的记忆就会越少,导致在处理长序列的时候,句子开头的信息保留的就会非常少,从而对于句子的建模信息完整性缺失。
由于seq2seq的这些缺陷,促进了学者们针对新的架构提出了更多的关注,Facebook有人提出了一种基于CNN的seq2seq模型,这类模型拥有CNN的特性,可以很好的实现并行,不过其性能提升并不大。终于,在2017年,一篇新作《Attention Is All You Need》被提出,transformer横空出世,它有着CNN那样的并行效率,同时又有着高于seq2seq的性能,从而拉开了自己精彩的一生。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L9bW9wfY-1632813272829)(https://miro.medium.com/max/1400/1*yEIgjqxpf-RfX4UL4ztBgg.png)]
2. 架构总览
先看一下transformer的整体架构,有个总体印象:
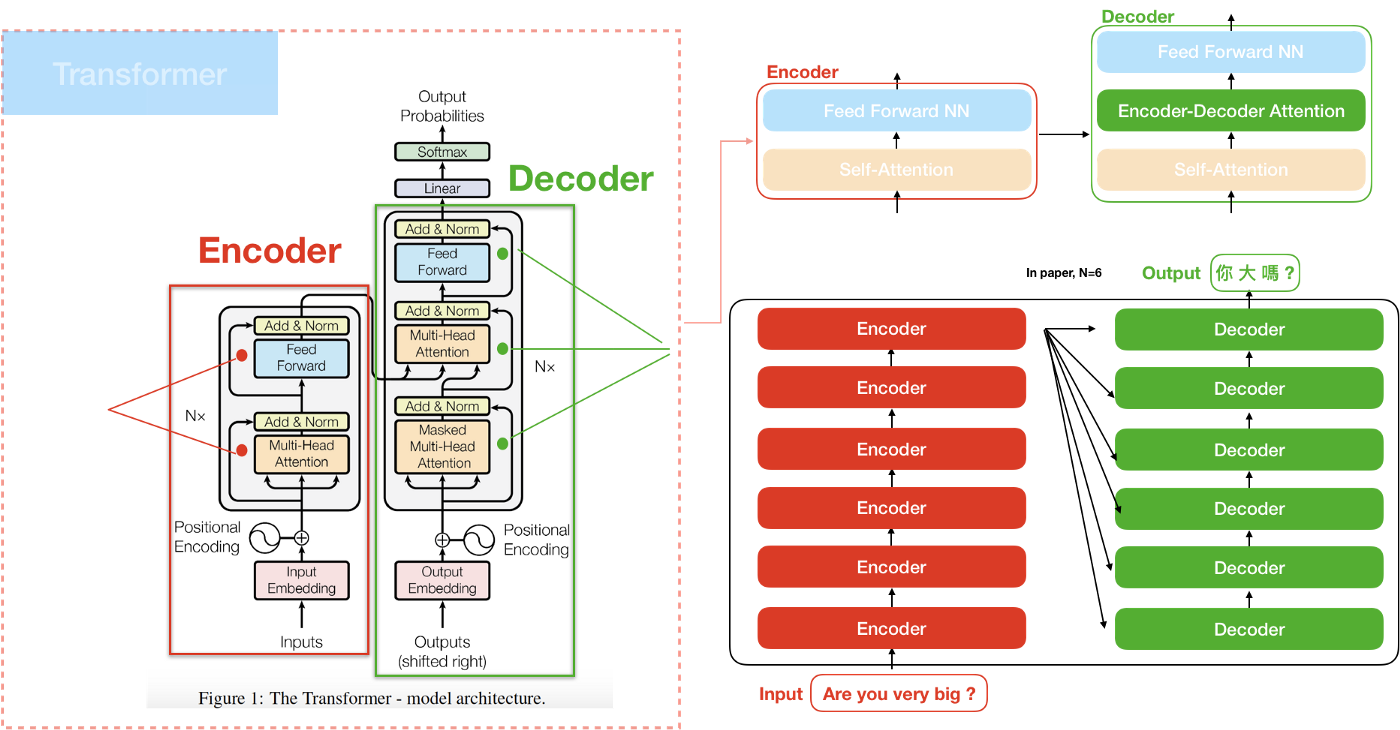
从模型上来看,transformer本身并不复杂,理解了它的几个组件,便可以理解其实现原理:
- Self-Attention
- Multi-Head Attention
- Positional Encoding
- Masked multi-head attention&Encoder-Decoder Attention
3. 组件
3.1 Self-Attention
transformer的attention不同于seq2seq中的attention,它使用的是一种称为self-attention的机制。在介绍self-attention以前,首先需要明确几个概念,即Query/Key/Value.
query/key/value的概念来自于信息检索领域,例如,当你在Youtube上输入一个query来搜索某个视频时,搜索引擎会将你的query与数据库中与候选视频相关联的一组key(视频标题、描述等)进行映射,然后向你展示最佳匹配的视频(value),所以key代表的是其实就是query的属性,value则是与query匹配的程度。一个简单粗暴的比喻是在档案柜中找文件。query向量就像一张便利贴,上面写着你正在研究的课题。key向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是value向量。只不过我们最后找的并不是单一的value向量,而是很多文件夹value向量的混合。回到attention方面,attention本质上也是从一个集合中发现与本token最匹配的元素,所以也可以认为是一个检索过程。
从比较早的attention开始,attention score的计算方式为:
c = ∑ j α j h j ∑ α j = 1 c=\sum_{j}\alpha_{j}h_{j} \quad \sum \alpha_{j}=1 c=j∑αjhj∑αj=1
如果 α \alpha α是个one-hot向量,那么这时候显然就是从 h h h中检索出一条向量,如果 α \alpha α是softmax向量,那么就是以概率向量 α \alpha α进行比例检索。不过这类型的attention有个问题。
到了transformer中,由于是self-attention,所以attention的计算是在源句子或者目的句子上进行的,所以这里的query/key/value有一些变化,基本上来讲:
- Query:代表token的representation vector
- Key: 表征token属性的向量
- Value: memory,Query包含的信息,这里就类似于RNN中的hidden state
这三种vector可以通过矩阵乘法很容易进行实现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gJ11JJNB-1632813272833)(https://miro.medium.com/max/1400/1*qSpa4BLAwa3pOgZ3lyxgBg.png)]
这里的一般看法是输入句中的每个文字是由一系列成对的<地址Key, 元素Value>所构成,而目标中的每个文字是Query,那么就可以用Key, Value, Query去重新解释如何计算context vector ,透过计算Query和各个Key的相似性,得到每个Key对应Value的权重系数,权重系数代表讯息的重要性,亦即attention score;Value则是对应的讯息,再对Value进行加权求和,得到最终的Attention/context vector。
不过,个人感觉应该借鉴了Facebook提出的memory network思想,Query,Key,Value分别对应I(input feature map),G(generalization),O(output feature map)模块,通过将输入x变换到Query实现I的操作,然后用Query与Key计算匹配程度,实现G操作,最终通过权重向量与Value实现O操作。
self-attention接收n个输入,同时产生n个输出。它内部通过在输入之间进行交互(self),来让每个输入找到它最应该关注的另外一个输入(attention)。self-attention的运算其实非常简单,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RMi6o0kK-1632813272834)(https://miro.medium.com/max/2000/1*_92bnsMJy8Bl539G4v93yg.gif)]
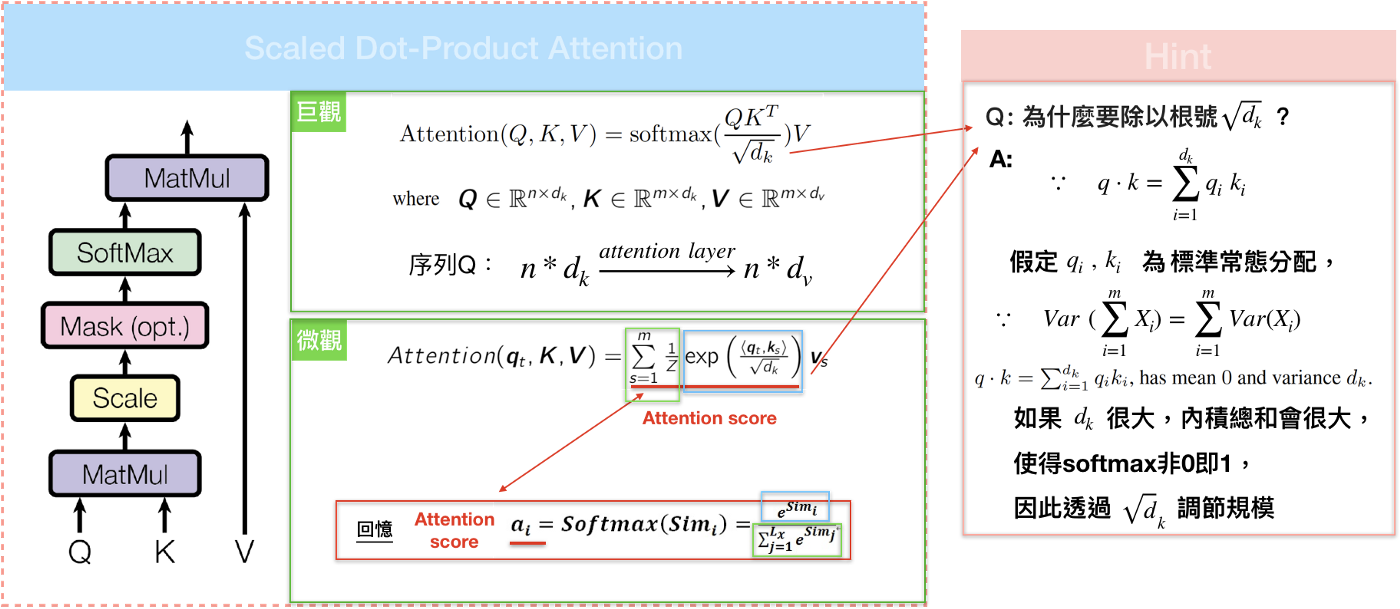
这里还有个要注意的地方,那就是从总览图可以看出,decoder与encoder的attention是存在一些区别的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6zBT98Sa-1632813272839)(https://miro.medium.com/max/1400/1*6gWbzqnAQjpg1n35rrExZQ.png)]
3.2 Multi-Head Attention
Multi-head Attention其实就是多个S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









