







 本文介绍了chatbot的分类,重点关注基于seq2seq和attention机制的模型。从基础的seq2seq模型到引入attention的Bahdanau和Luong Attention,深入探讨了它们的工作原理。此外,还提及了构建chatbot的数据集选择、评价指标和模型构建过程。
本文介绍了chatbot的分类,重点关注基于seq2seq和attention机制的模型。从基础的seq2seq模型到引入attention的Bahdanau和Luong Attention,深入探讨了它们的工作原理。此外,还提及了构建chatbot的数据集选择、评价指标和模型构建过程。
1. 生活中的chatbot
现在社会,随着AI的迅猛发展,各种新技术层出不穷,大大改变了我们的生活,其中,有很多技术已经走入了我们的日常生活,比如CV领域的人脸识别 ,NLP 领域的智能助手等。本次,我们就来聊聊智能助手中会涉及到的技术,也就是chatbot。
chatbot,其实是有很多分类的,目前,最常见的是把它分为一下几类:
-
Chit-Chat-oriented Dialogue Systems: 闲聊型对话机器人,产生有意义且丰富的回复。
-
Task-oriented: 任务驱动类,我们日常生活中常用的智能助手就是这类。
这两类其实技术方面是互通的。虽然深度学习以及强化学习等技术发展迅速,不过,在目前的智能助手中,占据主要地位的还是基于规则的,智能助手对话经过预定义的规则(关键词、if-else、机器学习方法等)处理,然后执行相应的操作,产生回复。这种方式虽然生成的对话质量较高,不过,缺点是规则的定义,系统越复杂规则也越多,而且其无法理解人类语言,也无法生成有意义的自然语言对话。处在比较浅层的阶段(最重要的是,这种方式并不好玩!!!),而基于生成式的chatbot,则可以生成更加丰富、有意义、特别的对话响应。但是,该类bot存在许多问题,比如沉闷的回应、agent没有一个固定的风格、多轮对话等等。不过,尽管 有问题,后续还是可以提高的嘛,对于我们AI工程师来说,我们还是希望能运用上我们掌握技术 ,去做一个生成式的chatbot,这样,才有成就感啊。
2. 基于seq2seq的chatbot

图1 seq2seq结构
seq2seq应该是序列到序列模型中最经典的了,基础的seq2seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。
seq2seq的两个基本结构都是一类rnn单元,而rnn天然适合变长序列任务,不过,最初的rnn饱受梯度弥散的困扰,因而,后续发展出的rnn通过状态的引入来减缓了这种现象,目前,最常用的rnn结构便是lstm以及gru。
3. 基于attention-seq2seq的chatbot
近年来,深度学习中的Attention机制的引入,提高了各种模型的成功率,在sota的模型中,Attention仍然是无处不在的组成部分。因此,非常有必要关注Attention机制。不过,在这篇文章中,我们主要关注两种最经典的attention结构,即:
这两种attention虽然年代久远,不过,对于我们理解attention的作用还是很有裨益的。
3.1 attention为何物?
当我们看到 "Attention "这个词时,脑海里想到的意思便是将你的注意力引导到某件事情上,并给予更大的注意。而深度学习中的Attention机制就是基于这种引导你的注意力的概念,它在处理数据时,会对某些因素给予更大的关注。
广义来讲,attention是网络结构的一个部件,它负责管理和量化下面两种相互依赖关系:
- 输入与输出元素之间,即General Attention
- 输入元素之间,即Self-Attention
attention为何有效呢 ?回到图1,我们知道seq2seq的encoder是把整个句子压缩成了一个高维向量,而句子是变化多端的,一个长句子被压缩一个向量,会存在比较大的信息缺失现象,更合理的做法是,针对句子层面以及单词层面同时考量,这样能大大缓解这种信息缺失,提高模型的效果,举个例子来说,在做机器翻译的时候,输入句子为:“chatbot is interesting!”,翻译结果为“聊天机器人很有趣", 那么,在翻译“聊天机器人”这个单词的时候,就会对“chatbot”这个单词给予更大的关注,从而提高了翻译的准确性。
3.2 Bahdanau Attention
这个attention提出于2014年,就今天来说是个相当古老的模型了,不过,也因为它早,所以显出其经典性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lzKIidZY-1632883561244)(https://blog.floydhub.com/content/images/2019/09/Slide38.JPG)]
图2 Bahdanau Attention
这种Attention,通常被称为Additive Attention。该Attention的提出旨在通过将解码器与相关输入句子对齐,并实现Attention,来改进机器翻译中的序列到序列模型。论文中应用Attention的整个步骤如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QEZqvyWA-1632883561246)(https://blog.floydhub.com/content/images/2019/09/Slide50.JPG)]
当时的经典模型,随着时间的流逝,看起来也不在多高大上了,不得不感叹技术的发展啊!
3.3 Luong Attention
该类Attention通常被称为 Multiplicative Attention,是建立在Bahdanau提出的注意机制之上。Luong Attention和Bahdanau Attention的两个主要区别在于:
- 对齐得分的计算方式
- attention机制被引入decoder的位置
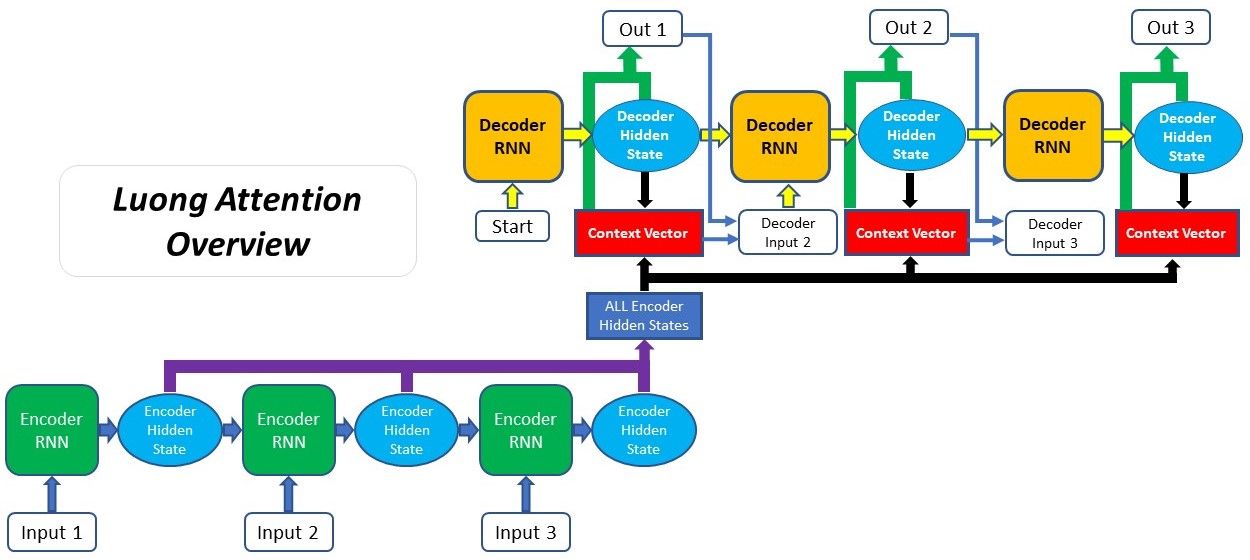
这两种Attention的score的计算方式如下:
Bahdanau Attention:
s c o r e a l i g n m e n t = W c o m b i n e d ⋅ t a n h ( W d e c o d e r ⋅ H d e c o d e r + W e n c o d e r ⋅ H e n c o d e r ) score_{alignment} = W_{combined} \cdot tanh(W_{decoder} \cdot H_{decoder} + W_{encoder} \cdot H_{encoder}) scorealignment=Wcombined⋅tanh(Wdecoder⋅Hdecoder+Wencoder⋅Hencoder)
Luong Attention:
-
dot
s c o r e a l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









