







ChatGLM3-6b部署中的坑
本地部署
本地部署采用的是支持CPU模式的ChatGLM3-6b的方式,即通过xinference+chatglm3-cpp的方式。我的笔记本配置为:i7-U8565U+16G内存+128MB的核显
一. 创建环境
- 使用virtualvenv建立python虚拟环境
python -m venv venv
- 安装torch
注意:现在执行的python为创建的虚拟环境下的python.exe所在的位置的程序
.\.venv\Scripts\python.exe -m pip install torch==2.0.0+cpu torchvision torchaudio -f https://mirror.sjtu.edu.cn/pytorch-wheels/torch_stable.html
- 安装xinference
.\.venv\Scripts\python.exe -m pip install xinference[ggml]>=0.4.3
或者
.\.venv\Scripts\python.exe -m pip install xinference[ggml]>=0.4.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
- 安装chatglm-cpp
安装chatglm-cpp有两种方式:
i. 直接下载安装:
.venv\Scripts\python.exe -m pip install -U chatglm-cpp -i https://pypi.tuna.tsinghua.edu.cn/simple/
如果安装失败,如下提示,则试第二种,因为我也没解决(尴尬)
ERROR: Could not build wheels for chatglm-cpp, which is required to install pyproject.toml-based projects
ii. 通过安装whl的方式:
去官网下载对应的whl文件:传送门
根据你的python版本和你的操作系统选择对应的文件版本,cp310表示你的python是3.10版本的。
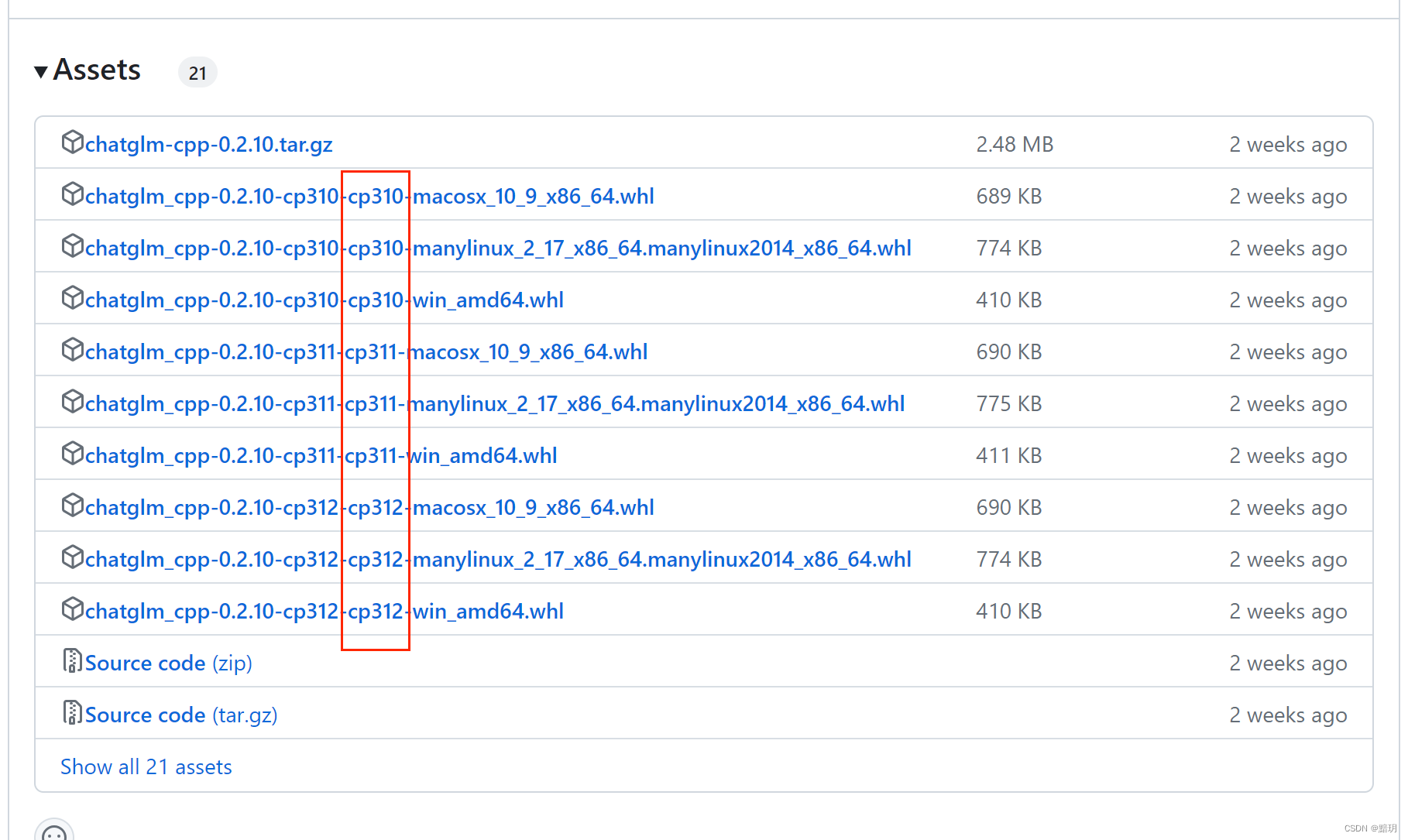
执行安装指令
.venv\Scripts\python.exe -m pip install chatglm_cpp-0.2.10-cp310-cp310-win_amd64.whl
二. 运行chatglm3-6b
- 启动xinference
在安装过程中成功安装了xinference后,会在对应虚拟环境的python所在的目录下生成一个xinference.exe程序,直接在对应的目录下运行即可
运行成功后如下图所示:
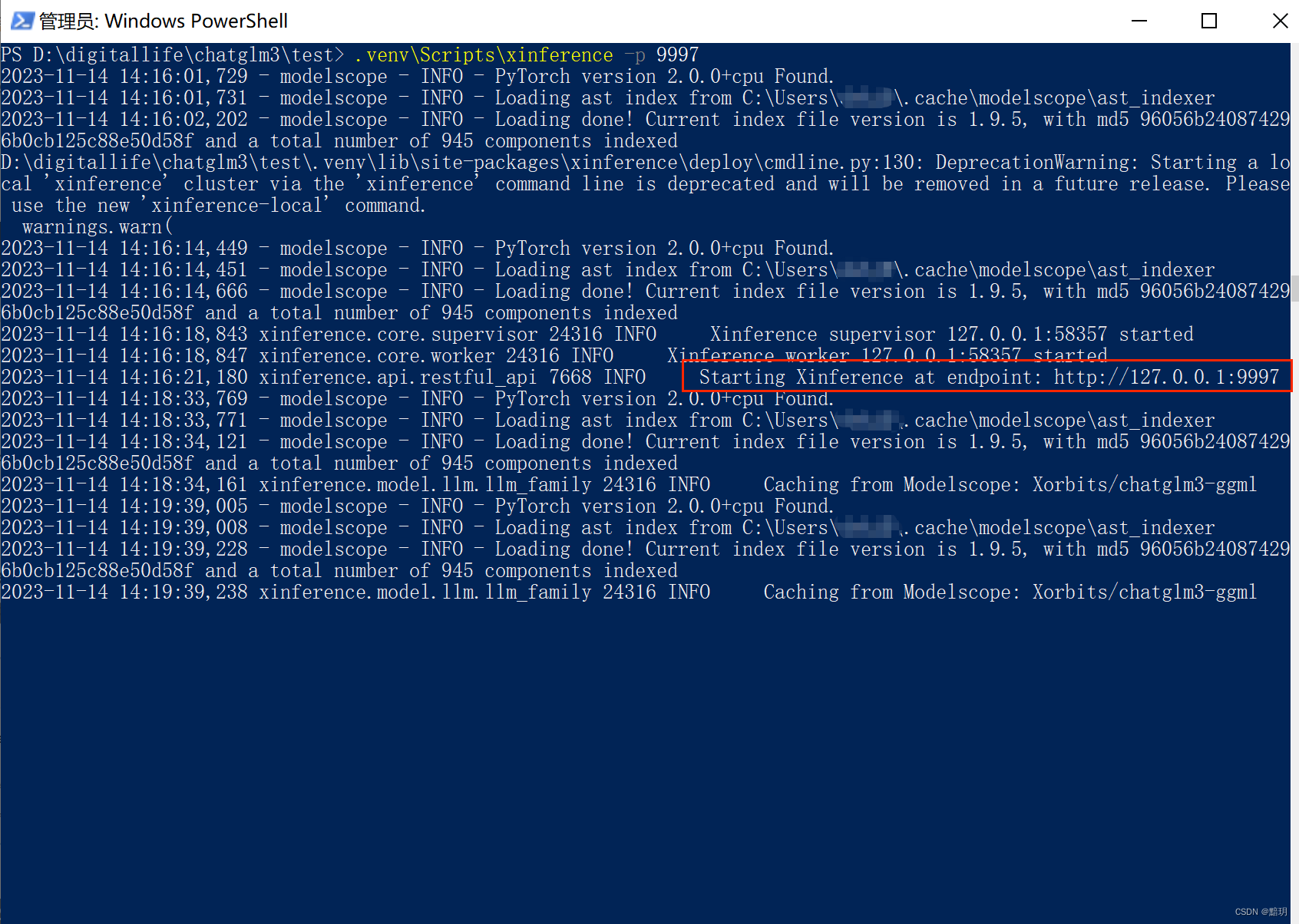
-
打开web界面
用浏览器打开对应xinference界面,界面地址为:http://127.0.0.1:9997/,界面如下图所示
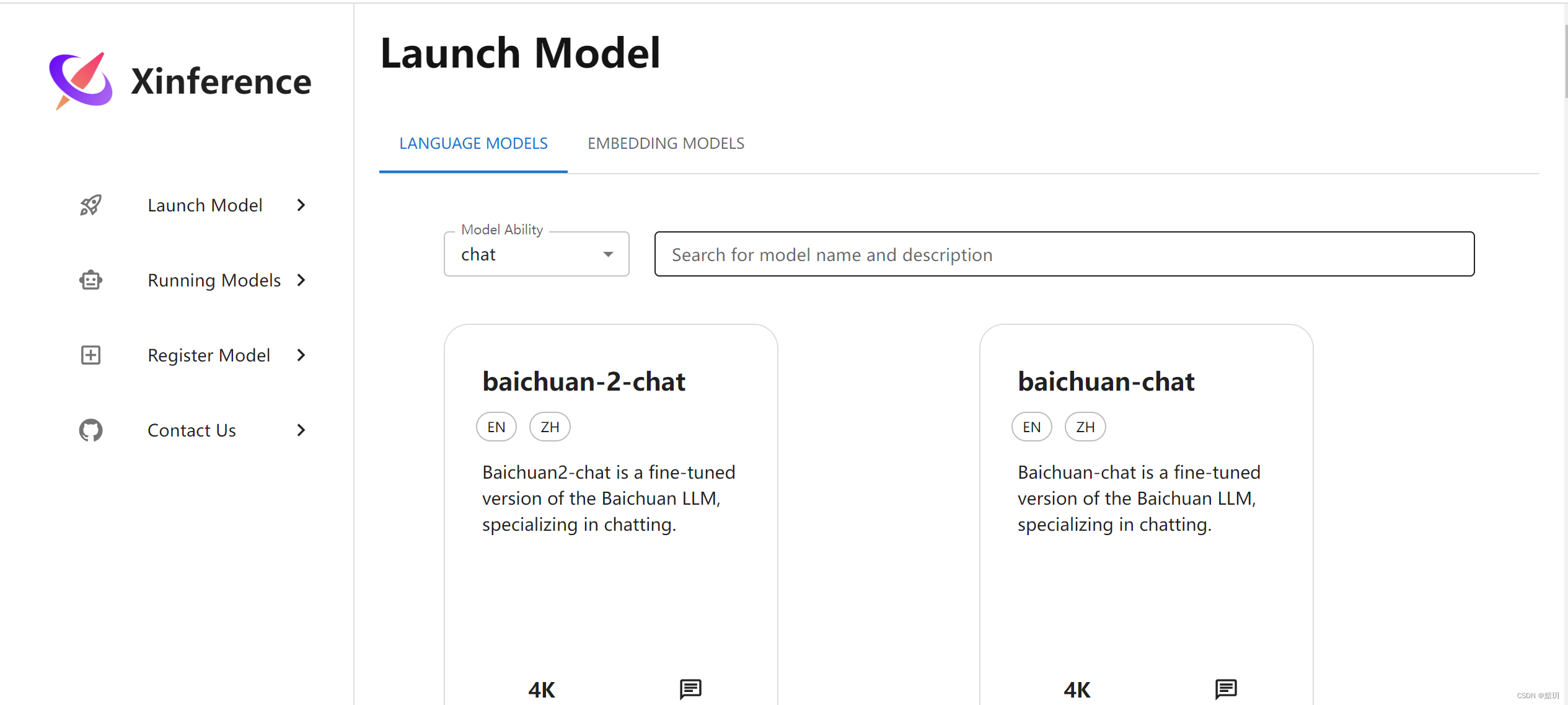
-
按照下图中的步骤选择对应的模型,xinference就会去下载对应的模型并进行部署运行,下载的模型默认存放在:C:\Users\用户名\.cache\modelscope\hub\Xorbits\chatglm3-ggml
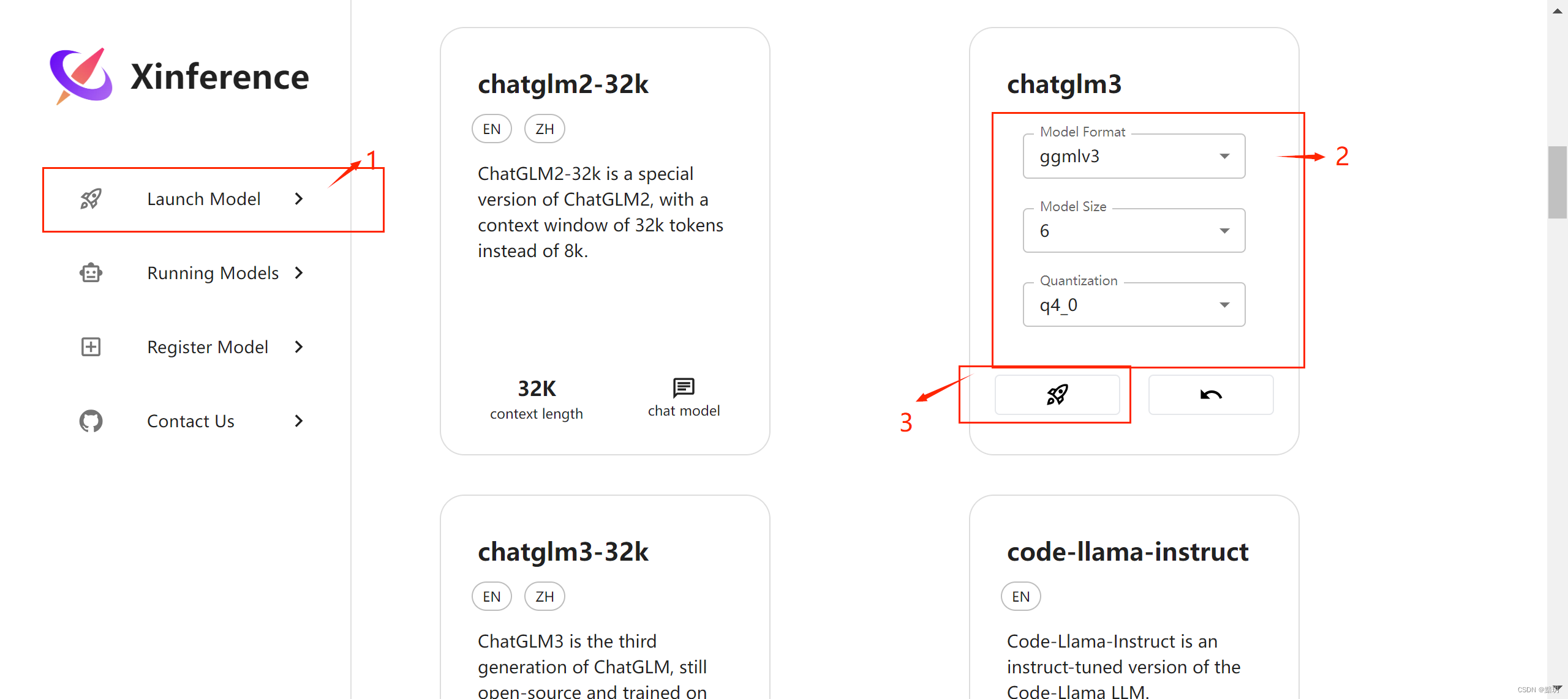 4. 部署成功后会在Running Models界面显示对应运行的模型实例的信息
4. 部署成功后会在Running Models界面显示对应运行的模型实例的信息

-
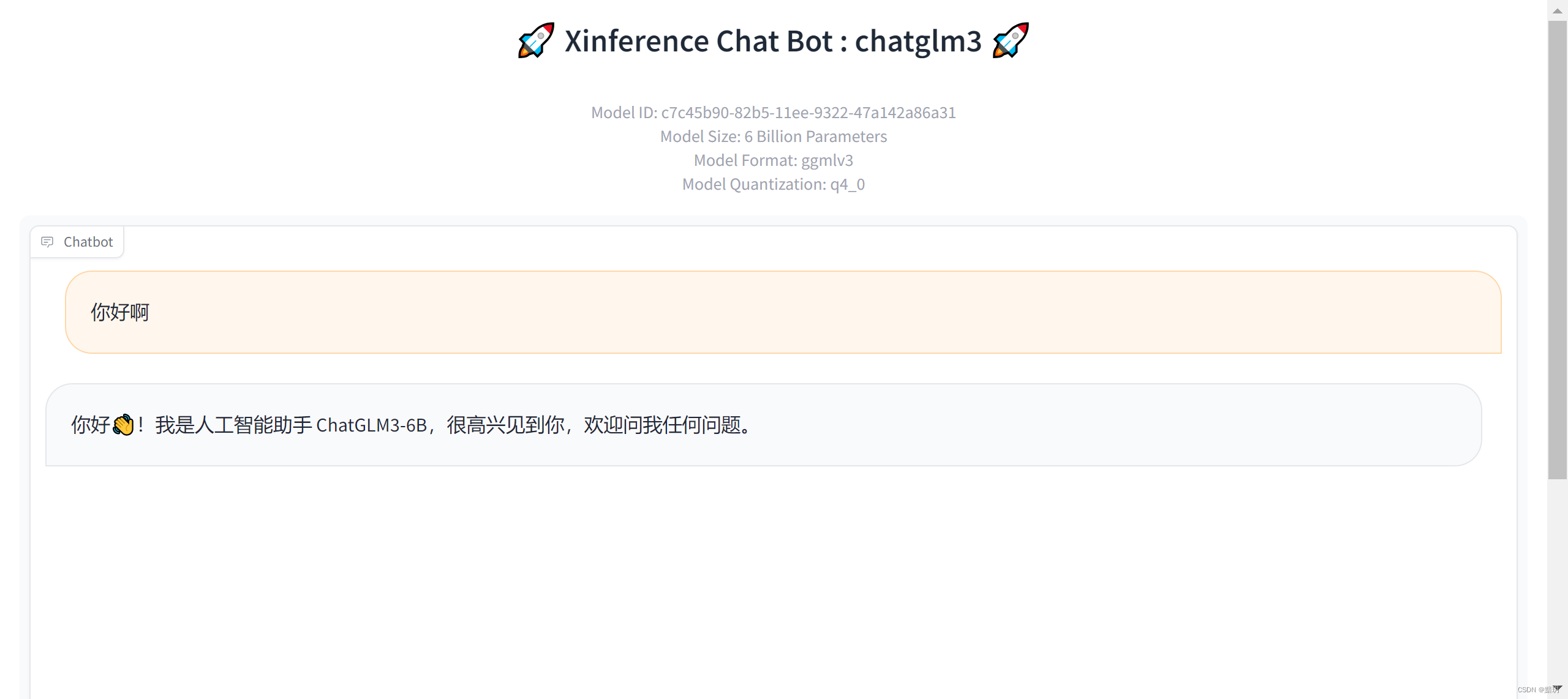
如下图点击对应的按钮即可进入ChatGLM3对应的web交互界面


















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









