







1. Knowledge Distillation(知识蒸馏,KD)
蒸馏希望将一个比较大的teacher网络中的知识给转移到比较小的student网络中,从而实现网络的压缩。
2.Knowledge Distillation for LLMs(大语言模型的蒸馏)
自从2015年Hinton提出KD这个概念,CV和NLP领域的知识蒸馏相关的工作就层出不穷。到了预训练模型的时代呢,在Bert上做的多种智能方案也取得了不错的效果。我们可以发现以往的正常工作,它主要都是在分类任务上面,比如图像分类还是文本分类。随着生成式大语言模型的兴起,很多工作也尝试从chatgpt的API中获取数据,然后来蒸馏生成式的小模型,这种蒸馏方法实际上就是所谓的Sequence KD。也是为数不多的可以在无法获得teacher模型的输出概率的情况下去进行蒸馏的方法。
那如果我们可以获得更多的大模型的信息,比如说模型生成句子的概率,甚至是整个的白盒的模型,我们能否比现在做的更好。这个问题首先是有意义的,因为现在开源的优质大模型越来越多,相比于用GPT4去蒸馏,其实这些大模型也足以作为训练小模型的比较好的teacher模型。并且如果我们直接去部署这些大模型也是比较消耗资源的,其次对于Bert这种分类模型,现有的白盒蒸馏已经能在保证性能的情况下做到相当高的压缩比了,但是生成式的白盒蒸馏其实还少有研究。对于语言模型,一种比较简单的白盒蒸馏方法是说我们在做语言模型的时候,把每一个预测下一个词的这个任务看成一个分类任务,从而去无缝的迁移这个分类模型的蒸馏方法,我们把它叫做standard KD。使用standard KD比不用KD蒸馏的效果提升其实很微弱,距离teacher模型也有一点的距离。
3. Outline
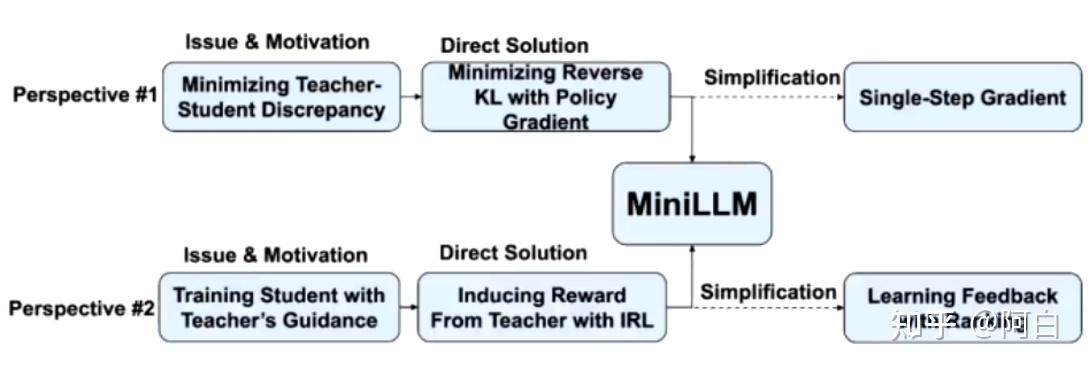
Outline:MiniLLM的两个角度
1. 第一个角度:可以把蒸馏看成一个减小student和teacher之间差异的一个过程,在这个视角下,就是以前绝大多数的正常方法实际上就是去优化student和teacher之间的正向KL散度。
2.第二个角度:可以把它看成用teacher去指导student模型去训练的过程。这个视角的不同点在于我们不再期望student和teacher的输出完全一致,而是希望利用teacher提供一些信号去辅助student的训练。十分类似于有一个智能体,然后在一个环境的信号下去不断地学习。在这种情况下,传统的蒸馏方法其实是对应的强化学习的behaviour cloning。熟悉RLHF的同学可能直接管它叫SFT。也对应着student直接在teacher或者说人类生成的数据上去训练。behaviour cloning的问题在强化学习中有很多讨论了,比如是相比于用一个环境的reward直接去做RL,我们直接用behaviour cloning可能会导致学出来的agent的泛化性比较差。类似的讨论在当初人们讲RLHF为什么有效的时候也经常出现。对于分类模型的话由于模型的输出不存在多步的决策,所以上面说的这个问题就没那么明显了。但是对于生成模型,生成过程可以看成一个多步决策,所以它的一些问题就显现出来了。为了解决这些问题,我们尝试借助强化学习中inverse RL的方法。也就是说我们先从环境(teacher)里induce出一个reward model。然后利用reward model对student进行强化学习。
需要知道的是reward model从形式上看最终就是teacher模型的输出概率然后再取log的形式。这个形式并不是拍脑袋想的,而是通过inverse RL推导出来的,具体的推导过程就不说了。有了这个reward可以搭配max entropy RL(最大熵)进行训练。这样就形成了KD的第二个解决方案。把它叫做learning from model’s feedback。
4.目标之间的等价性
经过数学变换这两种蒸馏方法其实是等价的,他们优化的是同一个目标。为了简单起见,我们把左边的式子,就是反向KL,作为miniLLM最终的优化目标的形式。这样的一个等价性也说明了我们使用这个目标去做蒸馏的合理性。
5.策略梯度优化
对目标求梯度。由于我们需要对采样的分布去求梯度。但是发现直接优化还是会有一些问题。
发现单步的生成策略往往是很重要的,所以对刚刚的梯度公式做了一些变换,将单步的梯度分离出来。Policy gradient最后求出来每一步的reward Rt相当于是从当前位置到最后位置的一个累加,可以把当前步的reward单独拿出来,然后求和变成第一项,再把long range的部分给甩到后面。这样就发现第一项可以直接通过在整个词表上求和来算期望,从而避免了一部分的蒙特卡洛采样。这也会使我们的训练收敛的更快。
其次发现在对student训练的过程中,将学生和教师分布进行混合,也会让训练更加稳定。
最后对reverse RL做长度归一化可以解决它本身长度偏好的问题。
6.最终的优化算法

首先会对student进行SFT的训练,训练数据可以是teacher生成的数据,也可以是人来写的数据。然后进行miniLLM的训练。每一轮从student去采样一些句子,然后去算反向KL,然后计算reward,再根据之前的式子去算梯度,最后回传,更新到student模型,这就是整个
7.模型的整体性能
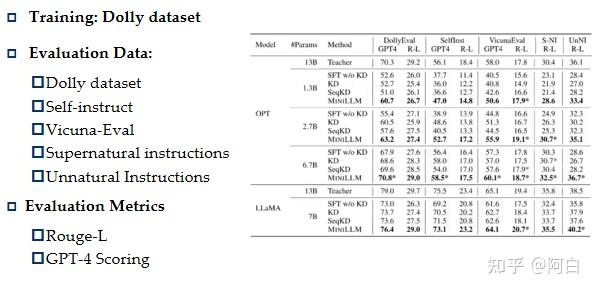
整体性能
在不同的instuction数据上去做测试。使用Rouge-L和GP4打分这两种评价方法。可以看到在不同的评测数据集和不同的评测方法,包括不同的模型种类和模型大小上,miniLLM方法都是有比较明显的优势。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









