






苍天不负有心人。
紫罗兰
推迟工作的策略可以追溯到有记录的历史出现之前。它偶尔会被嘲笑为拖延症,甚至纯粹是懒惰。然而,在过去的几十年里,工人们已经认识到这种策略在简化和简化并行算法方面的价值[KL80,Mas92]。信不信由你,并行编程中的“懒惰”往往优于和优于勤奋!这些性能和可伸缩性的好处源于延迟工作可以削弱同步原语,从而减少同步开销。
那些愿意并能够阅读和理解这一章的人将会揭开许多谜团,包括:
2.一个并发引用计数器,它不仅避免了这种陷阱,而且还避免了昂贵的原子读-修改-写访问,此外还避免了对被遍历的数据结构的任何类型的写入。
4.一种同步原语,允许使用完全相同的机器指令序列对并发更新的链接数据结构进行遍历,这些机器指令序列可能用于遍历相同数据结构的顺序实现。
6.如何在各种延迟处理原语中进行选择。
工作延迟的一般方法包括参考计数(第9.2节)、危险指针(第9.3节)、序列锁定(第9.4节)和RCU(第9.5节)。最后,第9.6节描述了如何在本章中涵盖的工作延迟计划中进行选择,第9.7节讨论了更新。但首先,第9.1节将介绍一个示例算法,用于比较和对比这些方法。
一盎司的应用程序值得大量的抽象。
布克T.华盛顿
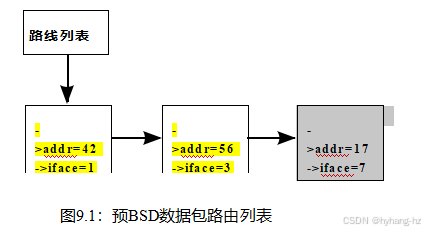
本章将使用一个简化的数据包路由算法来演示这些方法的价值,并允许对它们进行比较。在操作系统内核中使用路由算法,将每个传出的TCP/IP数据包传递到适当的网络接口。这个特殊的算法是在BSD UNIX [Jac88]中使用的20世纪80年代经典的数据包序列优化算法的简化版本,由一个简单的链表组成。现代路由算法使用更复杂的数据结构,然而,一个简单的算法将帮助在一个简单的设置中突出并行性特定的问题。
我们进一步简化了算法,将搜索键从由源和目标IP地址和端口组成的四倍简化到一个简单的整数。查找和返回的值也将是一个简单的整数,因此数据结构如图9.1所示,它将地址为42的数据包定向到接口1,地址为56到接口3,地址为17到接口7。这个列表通常会被频繁地搜索,并且很少被更新。在第三章中,我们了解到,逃避不方便的物理定律,如有限光速和物质的原子性质的最好方法是要么分割数据,要么依赖阅读——主要是共享。本章将读共享技术应用于BSD包路由。
清单9.1(route_seq.c)显示了一个简单的单线程实现,它对应于图9.1。第1-5行定义route_entry结构,第6行定义route_list标题。第8-20行定义路由查找(),它按顺序搜索loste(),返回相应的->iface,如果没有路由条目,则返回ULONG_MAX。第22-33行定义了route_add(),它分配一个routh_entry结构,初始化它,并将其添加到列表中,在内存分配失败时返回-ENOMEM。最后,第35-47行定义了route_del(),如果指定的routh_entry结构存在,则删除并释放它,否则返回-ENOENT。
| 1结构路由_entry{ 2 3 10 11 13 14 15 16 18 21 22introute_add(无符号长addr,无符号长接口)23{ 24 26 27 28 29 30 31 34 35 int route_del(无符号长addr)36 { 37 39 40 41 42 43 45 47 } |
我永远也不会让你走!
未知的
引用计数会跟踪对给定对象的引用数,以防止过早地释放该对象。因此,它有着悠久而光荣的使用历史,至少可以追溯到20世纪60年代早期的魏曾鲍姆的一篇论文[魏63]。魏森鲍姆讨论参考计数,就好像它已经众所周知了,所以它可能可以追溯到20世纪50年代,甚至40年代。也许更进一步,鉴于人们修理大型危险机器长期以来一直使用通过挂锁实现的机械参考计数技术。在进入机器之前,每个工人都将一个挂锁锁在机器的开/关开关上,从而防止工人在机器内部时通电。因此,参考计数是并发实现预bsd路由的一个极好的历史悠久的候选对象。
为此,清单9.2显示了数据结构和route_查找()函数,清单9.3显示了route_add()和route_del()函数(均在route_refcnt.c上)。由于这些算法与清单9.1中所示的顺序算法非常相似,所以我们将只讨论这些差异。
从清单9.2开始,第2行添加实际的引用计数器,第6行添加->re_freed使用后检查字段,第9行添加用于同步并发更新的路由锁,第11-15行添加re_free(),设置->re_freed,使route_>re_freed()检查使用后错误。在route_ lookup()本身中,第29-30行释放先前元素的参考计数,如果计数为零则释放它,行34-42获得新元素的引用,第35和36行执行自由使用后检查。
![]()
在清单9.3中,第11、15、24、32和39行引入了锁定以同步并发更新。第13行初始化->re_freed自由检查后使用字段,最后,如果引用计数的新值为零,则第33-34行调用re_free()。

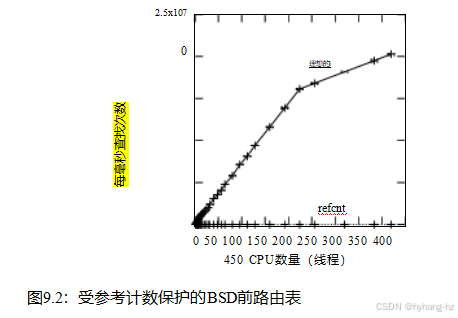
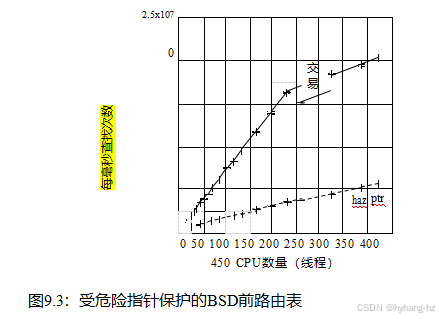
图9.2显示了只读工作负载上的引用计数的性能和可伸缩性,其中10元素列表运行在一个8个28核超线程2.1 GHz x86系统上,共有448个硬件线程(hps .2019。12.02a/lscpu.hps).“理想”跟踪是通过运行清单9.1中所示的顺序代码生成的,其工作原理仅仅是因为这是一个只读工作负载。引用计数的性能非常糟糕,其可伸缩性甚至更糟糕,因为“refcnt”跟踪与x轴难以区分。考虑到第3章,这并不奇怪:参考计数的获取和发布将频繁的共享内存写入添加到其他只读工作负载中,从而招致了严重的惩罚

| 1结构路由_entry{ 2 3 4 6 9 DEFINE_SPINLOCK(线路锁);10 11静态空白re_free(结构route_entry *rep)12 { 13 16 17无符号长route_查找(无符号长addr)18 { 19 20 21 22 23 25重试: 26 27 28 30 32 34 36 37 38 39 40 42 43 45 46 47 48 |
但情况会变得更糟。
运行多个更新线程重复调用route_add()和del(),将会很快遇到清单9.2第36行的中止()语句,该语句表示空闲后使用错误。这反过来又意味着引用计数不仅严重降低了可伸缩性和性能,而且还未能提供所需的保护。
导致无后使用错误的事件序列如下,图9.1所示:
1.线程A查找地址42,到达清单9.2中的route_roockup()的第32行。换句话说,线程A有一个指向第一个元素的指针,但尚未获得对它的引用。
2.线程B调用清单9.3中的route_del()来删除地址42的路由条目。它成功完成,因为这个条目的->re_refcnt字段等于值1,所以它调用re_free()来设置->re_freed字段并释放该条目。
3.线程A继续执行rouch_查找()。它的代表指针是非null的,但是第35行看到它的->re_freed字段是非零的,所以第36行调用中止()。
问题是引用计数位于要保护的对象中,但这意味着在获取引用计数本身的瞬间没有保护!这是Gamsa等人指出的锁定问题的参考计数对应物[GKAS99]。我们可以想象使用全局锁或引用计数来保护每个路由条目的引用计数获取,但这将导致严重的争用问题。尽管存在的算法允许在并发环境中进行安全的引用计数获取[Val95],但它们不仅非常复杂和容易出错[MS95],而且还提供了糟糕的性能和可伸缩性[HMBW07]。
简而言之,并发性绝对降低了参考计数的有效性!当然,与其他同步原语一样,引用计数也有众所周知的易用性缺点。这一方面可能导致内存泄漏,另一方面也可能导致内存过早释放。
这是一个引用计数陷阱,等待着粗心的并发代码开发人员,在第201页提到。

为了成功地解决问题,以完全不同的方式来看待问题是有帮助的。为此,下一节将描述什么可以被认为是一个由内到外的引用计数,它提供了良好的性能和可伸缩性。
如果有疑问,就把它翻过来。
Zara木匠
避免并发引用计数问题的一种方法是由内到外实现引用计数器,也就是说,不是增加存储在数据元素中的整数,而是在每个cpu(或每个线程)列表中存储指向该数据元素的指针。这些列表中的每个元素都称为危险指针[Mic04a]。2然后,通过计算引用该元素的危险指针的数量,可以获得给定数据元素的“虚拟引用计数器”的值。因此,如果该元素无法访问,并且不再有任何引用它的危险指针,则可以安全地释放该元素。
当然,这意味着必须非常小心地进行危险指针获取,以避免并发删除的破坏性竞争。清单9.4显示了一个实现,它显示了第1-16行的hp_try_record(),第18-27行的hp_record(),以及第29-33行的hp_clear()(hazptr.h)。
第16行上的hp_try_record()宏只是ht的一个铸造包装器
通过一个更新,它将返回一个特殊的HAZPTR_POISON令牌。

第6行读取指向要被保护的对象的指针。如果第8行发现此指针是NULL或特殊的HAZPTR_POISON已删除对象标记,它将返回指针的值以通知调用者失败。否则,第9行将指针存储在指定的危险指针中,第10行通过在第1行11中重新加载原始指针强制该存储的完全排序。(有关内存排序的更多信息,请参见第15章。)如果原始指针的值没有改变,那么危险指针保护指向对象,在这种情况下,第12行返回一个指向该对象的指针,这也向调用者指示成功。否则,如果指针在两个READ_ONCE()调用之间发生更改,则第13行表示失败。

hp_record()函数非常简单:它反复调用hp_try_记录(),直到返回值不是HAZPTR_POISON。
hp_clear()函数更简单,smp_mb()强制调用者使用受危险指针保护的对象和设置为NULL之间进行完全排序。
一旦将受危险指针保护的对象从其链接的数据结构中删除,因此未来的危险指针阅读器现在无法访问它,它将被传递给
| 比较(无效,无效) 3 5 8 9 10 11 12 16 20 22 23 25 26 29 37 39 41 47 48 void hazptr_free_later(hazptr_head_t *n)49 { 52 56 } |
| 1结构路由_entry{ 2 3 4 6 8结构route_entry route_list; 9 DEFINE_SPINLOCK(路由器); 10危险_指针__线程*my_hazptr;11 12无符号长route_查找(无符号长addr)13 { 14 15 16 19 20 22 23 25 26 29 30 |
hazptr_free_later(),显示在清单9.5(hazptr_free_later().c)的第48-56行。第50行和第51行将对象排在每个线程列表rlist上,第52行以rcount对对象进行计数。如果第53行看到现在有足够多的对象排队,第54行调用hazptr_scan()试图释放其中一些。
hazptr_scan()函数显示在列表的第6-46行。该函数依赖于固定的最大线程数(NR_THREADS)和固定的最大危险指针数(K),这允许使用固定大小的危险指针数组。因为任何线程都可能需要扫描危险指针,所以每个线程都维护自己的数组,该数组由每个线程的变量gplist引用。如果第14行确定该线程尚未分配其gplist,则第15-18行执行该分配。第20行上的存储屏障确保所有线程在第22-28行扫描所有危险指针之前看到该线程删除的所有对象,将非空指针累积到plist数组并以psize计数它们。第29行上的存储屏障确保在释放任何对象之前发生。第30行,然后对这个数组进行排序,以便在下面使用二进制搜索。
第31行和第32行将从该线程的待释放对象列表中删除所有元素,将它们放在本地tmplist上,第33行将将计数归零。每个对象都通过循环跨越线34-45来处理每个要被释放的对象。第35和36行从tmtist中移除第一个对象,如果第37和38行确定存在保护该对象的危险指针,第39-41行将其放回rlist上。否则,第43行将释放该对象。
Pre-BSD路由示例可以使用清单9.6中所示的数据结构和路由查找(),清单9.7中的危险指针可以使用路由_add()和route_del()(route_hazptr.c)。与参考计数一样,危险指针
实现与第203页上的清单9.1中所示的顺序算法非常相似,所以我们将只讨论差异。
从清单9.6开始,第2行显示了用于使用危险指针队列的->hh字段,第6行显示了用于检测使用后错误的->re_freed字段,第21行调用hp_try_record()试图获取危险指针。如果返回值为NULL,则第23行向调用者返回一个未找到的指示。如果对hp_try_record()的调用与删除赛跑,第25行分支回到第18行的重试,从一开始就重新遍历列表。当找到所需的元素时,do-while循环将失效,但如果该元素已经被释放,则第29行终止程序。否则,元素的->iface字段将返回给调用者。
请注意,第21行调用了hp_try_record(),而不是更容易使用的hp_记录(),即在hp_try_record()失败时重新启动完整的搜索。而这样的重新启动是正确性所绝对必需的。要了解这一点,请考虑一个包含元素A、B和C的受危险、指针保护的链表,它受到以下事件序列的影响:
1.线程0存储指向元素B的危险指针(可能已从元素A遍历到元素B)。
2.线程1从列表中删除元素B,它将从元素B到元素C的指针设置为特殊的HAZPTR_POISON值,以标记删除。因为线程0有一个指向元素B的危险指针,所以还无法释放它。
3.线程1将从列表中删除元素C。因为没有引用元素C的危险指针,所以会立即释放它。
4.线程0试图获取一个指向现在已删除的元素B的后继者的危险指针,但是hp_try_record()返回HAZPTR_POISON值,迫使调用者从列表的开始重新启动其遍历。
这是一件非常好的事情,因为B的后继任者是现在释放的元素C,这意味着线程0的后续访问可能导致任意可怕的内存损坏,特别是如果元素C的内存已经被重新分配到其他目的。因此,危险指针读取器通常必须在面对并发删除时重新启动完整的遍历。通常,重新启动必须返回到某个全局(因此是不朽的)指针,但如果该位置保证仍然活动,有时可以在某些中间位置重新启动,例如,由于当前线程持有一个锁、一个引用计数等。
![]()
因为算法使用危险指针可能在任何步骤的遍历链接数据结构,这样的算法通常必须注意避免做任何更改数据结构,直到他们获得所有危险指针所需的更新问题。

这些危险指针限制给阅读器带来了巨大的好处,这是因为危险指针存储在每个CPU或线程的本地,这反过来允许在没有任何遍历而不写入被遍历的数据结构的情况下执行遍历。参见第112页上的图5.8,危险指针使CPU缓存能够实现
| 清单9.7:BSD前路由表添加/删除 | ||
| 1 | int | route_add(无符号长addr,无符号长接口) |
| 2 | { | |
| 3 | 结构路由entry*rep; | |
| 4 | ||
| 5 | 代表=malloc(代表); | |
| 6 | 如果(!代表) | |
| 7 | 返回-ENOMEM; | |
| 8 | rep->addr = addr; | |
| 9 | ||
| 10 | 代表->re_freed=0; | |
| 11 | spin_lock(&路由器锁); | |
| 12 | rep->re_next=routh_list.re_next; | |
| 13 | route_list .re_next =代表; | |
| 14 | spin_oluch(&路由器锁); | |
| 15 | 返回0; | |
| 16 | } | |
| 17 | ||
| 18 | int | route_del(无符号长addr) |
| 19 | { | |
| 20 | 结构路由entry*rep; | |
| 21 | 结构路径输入repp; | |
| 22 | ||
| 23 | spin_lock(&路由器锁); | |
| 24 | repp = &route_list .re_next; | |
| 25 | 为(;;){ | |
| 26 | rep = *repp; | |
| 27 | 如果(代表== NULL) | |
| 28 | 破碎 | |
| 29 | 如果(rep->addr == addr){ | |
| 30 | *repp =代表->re_next; | |
| 31 | ||
| 32 | ||
| 33 | hazptr_free_later(&rep->hh); | |
| 34 | 返回0; | |
| 35 | } | |
| 36 | 爬行动物= &rep->re_next; | |
| 37 | } | |
| 38 | spin_oluch(&路由器锁); | |
| 39 | 返回-ENOENT; | |
| 40 | } | |
执行资源复制,这反过来又允许削弱并行访问-控制机制,从而提高性能和可伸缩性。
重新启动危险指针遍历的另一个优点是减少最小内存占用:任何当前未被危险指针引用的对象都可以立即释放。相比之下,第9.5节将讨论一种机制,即避免读端重试(并最小化读端开销),但这可能会导致更大的内存占用。
route_add()和route_del()函数如清单9.7所示。第10行初始化->re_freed,第31行毒害新删除的对象的->re_next字段,第33行将该对象传递给hazptr_free_later()函数,一旦安全完成,hazptr_free_later()函数将释放该对象。自旋锁的工作原理与清单9.3中的相同。
与其他机制的实际性能比较可以在第10章和其他出版物中找到[HMBW07,McK13,Mic04a]。

而危险指针是在第201页中提到的并发参考计数器。下一节试图通过使用序列锁来改进危险指针,这就避免了读侧写和每个对象的内存障碍。
这就像重新开始一样。
约翰列侬
已发布的序列锁定记录[Eas71,Lam77]可以追溯到阅读-写入器锁定,但序列锁定仍然是相对模糊的。序列锁在Linux内核中用于读取——主要是读取器必须查看的处于一致状态的数据。然而,与读者-作者锁定不同,读者并不排除作者。相反,与危险指针一样,序列锁迫使读取器如果从并发写入器检测到活动,则重试操作。从图9.4中可以看出,使用序列锁来设计代码是很重要的,这样读者就很少需要重试了。

序列锁定的关键组成部分是序列号,在没有更新的情况下,它是偶数,在有更新的情况下,它是奇数。然后,读者可以在每次访问前后快照该值。如果其中一个快照有
| 1做{ | |
| 2 | seq = read_seqbegin(&test_seqlock); |
| 3 | /*读取端访问。*/ |
| 4}而 | (read_seqretry(&test_seqlock,seq)); |
| 1 write_seqlock (& test_seqlock ); | |
| 2 | /*更新*/ |
| 3 | write_sequnlock (& test_seqlock ); |
一个奇数值,或者如果两个快照不同,则有一个并发更新,读卡器必须丢弃访问的结果,然后重试它。因此,当访问受序列锁保护的数据时,读者会使用清单9.8中所示的read_seqbegin()和read_seqretry()函数。写入器必须在每次更新之前和之后增加该值,并且在给定的时间内只允许增加一个写入器。因此,作者在更新受序列锁保护的数据时,会使用清单9.9中所示的write_seqlock()和write_sequnlock()函数。
因此,受序列锁保护的数据可以有任意大量的并发阅读器,但一次只有一个写入器。序列锁定用于Linux内核中以保护用于计时的校准量。它还用于路径名遍历,以检测并发重命名操作。
在清单9.10(seqlock.h)中显示了一个序列锁的简单实现。seqlock_t数据结构显示在第1-4行,其中包含序列号和一个用于序列化写入器的锁。第6-10行显示了seqlock_init(),顾名思义,它初始化了一个seqlock_t。
第12-19行显示了read_seqbegin(),它开始了一个序列锁读取侧临界部分。第16行获取序列计数器的快照,第17行在调用者的关键部分之前命令此快照操作。最后,第18行返回快照的值(清除最小的位),调用者将其传递给稍后对read_seqretry()的调用。

| 清单9.11:序列锁定的bsd前路由表查找(BUGGY!!!) |
| 1结构路由_entry{ 2 3 5 8 DEFINE_SEQ_LOCK(sl);9 10无符号长route_查找(无符号长addr)11 { 12 13 14 15 19 20 21 24 25 30 33 34 |
第21-29行显示read_seqretry(),如果自对应调用read_seqbegin()以来至少有一个作者,则返回true。第26行在第27行获取序列计数器的新快照之前,命令调用者之前的临界部分。第28行检查序列计数器是否已经发生了变化,换句话说,是否已经至少有一个写入器,如果有,则返回true。

第31-36行显示了write_seqlock(),它只是获得锁,增加序列号,并执行一个内存障碍,以确保该增量在调用者的关键部分之前排序。第38-43行显示了write_sequnlock(),它执行一个内存障碍,以确保呼叫者的临界部分在第41行上的序列号增加之前被排序,然后释放锁。

| 清单9.12:序列锁定的bsd前路由表添加/删除(BUGGY!!!) | ||
| 1 | int | route_add(无符号长addr,无符号长接口) |
| 2 | { | |
| 3 | 结构路由entry*rep; | |
| 4 | ||
| 5 | 代表=malloc(代表); | |
| 6 | 如果(!代表) | |
| 7 | 返回-ENOMEM; | |
| 8 | rep->addr = addr; | |
| 9 | ||
| 10 | ||
| 11 | write_seqlock(&sl); | |
| 12 | rep->re_next=routh_list.re_next; | |
| 13 | ||
| 14 | write_sequnlock(&sl); | |
| 15 | 返回0; | |
| 16 | } | |
| 17 | ||
| 18 | int | route_del(无符号长addr) |
| 19 | { | |
| 20 | 结构路由entry*rep; | |
| 21 | 结构路径输入repp; | |
| 22 | ||
| 23 | ||
| 24 | repp = &route_list .re_next; | |
| 25 | 为(;;){ | |
| 26 | rep = *repp; | |
| 27 | 如果(代表== NULL) | |
| 28 | 破碎 | |
| 29 | 如果(rep->addr == addr){ | |
| 30 | ||
| 31 | write_sequnlock(&sl); | |
| 32 | ||
| 33 | 代表->re_freed=1; | |
| 34 | 免费(代表); | |
| 35 | 返回0; | |
| 36 | } | |
| 37 | 爬行动物= &rep->re_next; | |
| 38 | } | |
| 39 | ||
| 40 | 返回-ENOENT; | |
| 41 | } | |
那么,当序列锁定应用到预bsd的路由表时,会发生什么呢?清单9.11显示了数据结构和route_查找(),而Listing9.12显示了route_add()和route_del()(route_seqlock.c)。这个实现再次类似于前面部分中的对应实现,因此只会突出显示差异。
在清单9.11中,第5行添加了->re_freed,在第29行检查。第8行添加了一个序列锁,rouke()在第18、23和32行使用,第24和33行分支回第17行的重试标签。其效果是重试与更新同时运行的任何查找。
在清单9.12中,第11、14、23、31和39行获取并释放序列锁,而第10和33行handes->re_freed。因此,这个实现非常简单。
它在只读工作负载上也表现得更好,如图9.5所示,尽管它的性能仍然远非理想。更糟糕的是,它遭受了免费使用后使用的失败。问题是,在read_seqretry()有机会警告并发更新之前,读者可能会因为访问已经释放的结构而遇到分段冲突。
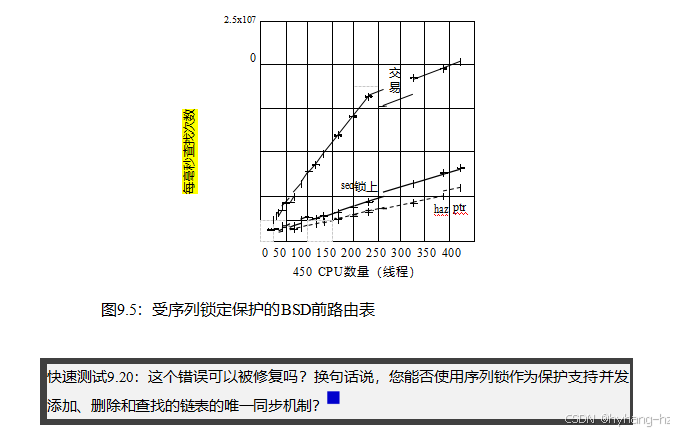
如第201页所暗示的,序列锁的读侧和写侧临界部分都可以被视为事务,因此序列锁定可以被视为事务内存的有限形式,这将在第17.2节中讨论。序列锁定的限制是:(1)序列锁定限制更新,(2)序列锁定不允许遍历指向更新器可能释放的对象的指针。这些限制当然可以通过事务性内存来克服,但也可以通过结合其他同步原语与序列锁定来克服。
序列锁允许作者推迟阅读时间,但反之亦然。这可能会导致不公平,甚至缺乏作者繁重的工作量。3另一方面,在没有作者的情况下,序列锁阅读器相当快,规模线性。只有人类想要两个世界的最好一面:快速阅读而没有阅读端失败的可能性,更不用说饥饿了。此外,用指针来克服序列锁定的限制也会很好。下一节将介绍一个完全具有这些属性的同步机制。
“免费”是一个非常好的价格!
汤姆彼得森
前面几节中讨论的所有机制都使用了许多方法中的一种来推迟特定的行动,直到它们能够安全地执行。第9.2节中讨论的引用计数器使用显式计数器来推迟可能干扰读取器的操作,从而导致读取端争用,从而导致较差的可伸缩性。第9.3节所涵盖的危险指针以每个线程列表的形式使用隐式计数器的指针。这避免了读取端争用,但要求读取器执行存储和条件分支,以及读取端原语中的全内存障碍,或者更新端原语中实时不友好的处理器间中断。4第9.4节中提出的序列锁也避免了读端争用,但不保护指针遍历,并且像危险指针一样,需要读端原语中的全内存障碍,或者需要更新端原语中的处理器间中断。这些计划的缺点提出了这样一个问题:是否有可能做得更好。
本节介绍读取副本更新(RCU),它提供了一个API,允许阅读器与源代码中的区域相关联,而不是对频繁更新的共享数据进行昂贵的更新。本节的其余部分将从许多不同的角度来研究RCU。第9.5.1provides节RCU的经典介绍,第9.5.2covers节基本RCU概念,第9.5.3presents节Linux内核API,第9.5.4introduces节一些常见的RCU用例,最后第9.5.5covers节最近与RCU相关的工作。
虽然RCU以微妙和困难而闻名,但如果使用得当,它是相当简单的。事实上,正如巴特勒·兰普森一样的权威将其归类为容易并发[AH22,第3章]。
前面几节中讨论的方法为预bsdd的路由表提供了良好的可伸缩性,但显然不是理想的性能。因此,在精神“只有那些走得太远知道你能走多远”,5我们将一路,研究算法的并发读者可能执行完全相同的汇编语言指令序列单线程查找,尽管并发更新的存在。当然,这个值得称赞的目标可能会引发严重的可实现性问题,但如果我们不尝试,我们甚至不可能成功!
9.5.1.1最小限度的插入和删除
为了最小化对可实现性的关注,我们关注一个最小的数据结构,它由一个为NULL或引用单个结构的单一全局指针组成。虽然这种数据结构可能很小,但在生产中被大量使用[RH18]。图9.6显示了一种经典的插入方法,它显示了随着时间从上到下推进的四种状态。第一行显示了初始状态,gptr等于NULL。在第二行中,我们分配了一个未初始化的结构,如问号所示。在第三行中,我们已经初始化了该结构。最后,在第四行也是最后一行中,我们更新了gptr,以引用新分配和初始化的元素。
我们可能希望这个对gptr的赋值可以使用一个简单的c语言赋值语句。不幸的是,Section4.3.4.1dashes抱有这些希望。因此,更新程序不能使用简单的c语言赋值,而是必须使用如图所示的smp_store_release(),或者,如我们可以看到的,使用rcu_assign_pointer()。
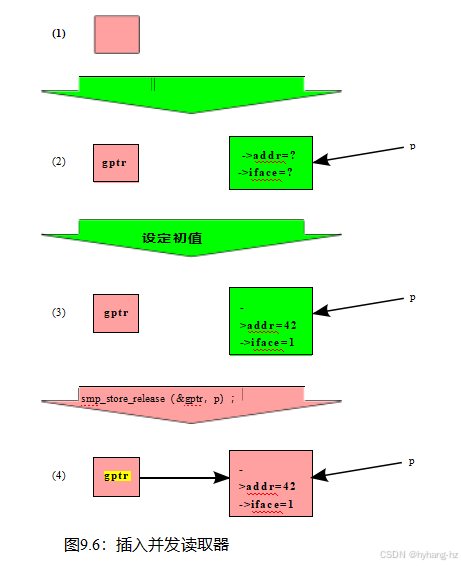
类似地,人们可能希望读者可以使用一个c语言赋值来获取gptr的值,并保证获得NULL的旧值或获取新安装的指针,但无论如何都能看到有效的结果。不幸的是,第4.3.4.1节也粉碎了这些希望。为了获得这个保证,读者必须使用READ_ONCE(),或者,正如我们将看到的,rcu_dereference()。然而,在大多数现代计算机系统上,每个读侧原语都可以用一个加载指令来实现,这正是通常在单线程代码中使用的指令。
从读者的角度回顾图9.6,在前三个状态下,所有读者都会看到gptr的值为NULL。在进入第四个状态时,一些读者可能会看到gptr的值仍然为NULL,而另一些读者可能会看到它引用了新插入的元素,但在一段时间后,所有读者都会看到这个新元素。在任何时候,所有的读者都会看到gptr包含一个有效的指针。因此,确实可以在链接的数据结构中添加新的数据,同时允许并发读取器执行通常在单线程代码中使用的相同的机器指令序列。这种免费的并发读取方法提供了出色的性能和可伸缩性,而且也非常适合实时使用。
插入当然非常有用,但迟早也需要删除数据。从图9.7中可以看出,第一步很简单。再次吸取了第4.3.4.1节的经验教训,smp_store_release()被用来记空指针,从而从图中的第一行移动到第二行。在这一点上,现有的读者看到了->addr为42和->iface为1的旧结构,但新的读者将看到一个
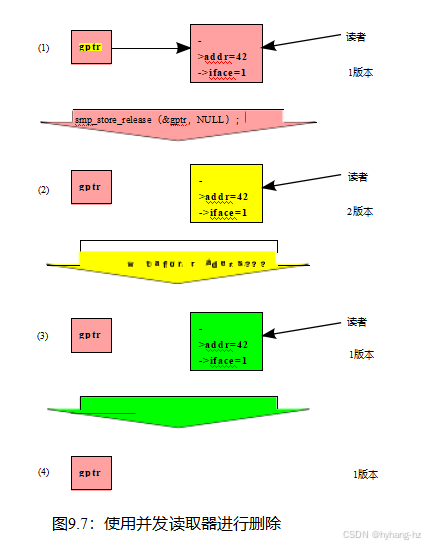
NULL指针,即并发阅读器可能对状态有分歧,如图中的“两个版本”所示。

我们只需等待所有已存在的阅读器完成,就可以回到一个单一的版本,如第3行所示。在这一点上,所有已存在的阅读器都完成了,以后的阅读器没有指向旧数据项的路径,因此不能再有任何阅读器引用它。因此,它可以被安全地释放,如第4行所示。
因此,如果有一种等待已有读取器完成的方法,就可以向链接数据结构和链接数据结构中删除数据,尽管读取器执行适合单线程执行的相同机器指令序列。所以也许一路走并不是太远!
但是我们怎样才能知道所有的读者实际上都完成了呢?这个问题是第9.5.1.3节的主题。但是,首先,下一节定义了RCU的核心API。
9.5.1.2核心RCU API
完整的linux内核API非常广泛,有超过100个API成员。但是,本节将限制为6个核心RCU API成员,这就足够了
表9.1:核心RCU API
| 原始的 | 目的: | |
| 读者 |
|
|
| rcu_read_unlock() | 结束RCU读侧临界部分。 | |
| rcu_dereference() | 安全地加载一个受RCU保护的指针。 | |
| 更新程序 | synchronize_rcu() | 等待所有已存在的RCU读取端关键部分完成。 |
| call_rcu() | 在所有已存在的RCU读取侧临界部分完成后,调用指定的函数。 | |
| rcu_assign_pointer() | 安全地更新一个受RCU保护的指针。 |


接下来的部分将介绍RCU并介绍其基本原理。完整的API内容见第9.5.3节。
读者使用了核心api中的三个成员。rcu_read_lock()和rcu_read_unlock()函数划分了RCU读侧临界部分。这些可能是嵌套的,这样一个rcu_read_lock()-rcu_read_unlock()对就可以被封闭在另一对中。在这种情况下,RCU读侧关键部分的嵌套集作为一个很大的关键部分,覆盖了嵌套集的全部范围。第三个读端API成员rcu_dereference()获取一个受RCU保护的指针。从概念上讲,rcu_dereference()只是从内存加载,但我们将在9.5.2.1节中看到,rcu_dereference()必须阻止编译器和(在一种情况下)CPU使用稍后引用此指针的内存操作重新排序其负载。
![]()
核心api的其他三个成员被更新者使用。syaan_rcu()函数实现了图9.7中的“等待阅读器”操作。call_rcu()函数是synchronize_rcu()的异步对应物,通过在所有已存在的RCU阅读器完成后调用指定的函数。最后,rcu_assign_pointer()宏用于更新一个受RCU保护的指针。从概念上讲,这只是一个赋值语句,但我们将在第9.5.2.1that节中看到,rcu_assign_pointer()必须防止编译器和CPU重新排序这个赋值,以便在用于初始化指向结构的任何先前赋值之前。

表9.1总结了核心RCU API,便于参考。因此,我们准备继续介绍RCU的关键RCU操作,等待读者。
将synchronize_rcu()和call_rcu()的阅读器等待功能建立在由rcu_read_lock()和rcu_read_解锁()更新的引用计数器上是很诱人的,但是Figure5.1in第5章显示,并发引用计数会导致极大的开销。这种极端的开销在具体情况下得到了证实
在第205页上的图9.2中的参考计数器。危险指针极大地降低了开销,但是,正如我们在213页的图9.3中看到的,不是零。然而,许多RCU实现使用具有精心控制的缓存位置的计数器。
第二种方法观察到内存同步是昂贵的,因此使用寄存器,即每个CPU或线程的程序计数器(PC),因此对读取器没有开销,至少在没有并发更新的情况下是这样。更新器轮询每个相关的PC,如果该PC不在读侧代码中,那么相应的CPU或线程处于静止状态,反过来,信号显示有可能访问新删除的数据元素的任何读取器的完成。一旦所有CPU或线程的pc被发现在任何阅读器之外,宽限期就完成了。请注意,这种方法带来了一些严重的挑战,包括内存排序、有时从读者那里调用的函数,以及不断令人兴奋的代码运动优化。然而,这种方法据说被用于生产。
第三种方法是简单地等待一段固定的时间,该时间足以舒适地超过任何合理的读者的寿命[Jac93,Joh95]。这在实时系统中很有效[RLPB18],但在不那么奇特的环境中,墨菲说,即使为不合理的长寿读者做好准备也是至关重要的。要看到这一点,请考虑失败这样做的后果:当不合理的阅读器仍在引用它时,数据项将被释放,该项很可能立即重新分配,甚至可能作为其他类型的数据项。不合理的读者和不知情的重新分配器就会试图将相同的内存用于两个非常不同的目的。随后出现的混乱将非常难以调试。
第四种方法是永远等待,并且知道这样做甚至可以容纳最不合理的读者。这种方法也被称为“内存泄漏”,由于内存泄漏经常需要过早和不方便的重新启动,因此名声不好。然而,当更新速率和正常运行时间都有明显的限制时,这是一个可行的策略。例如,这种方法可以很好地在一个高可用性的集群中工作,其中系统会定期崩溃,以确保集群确实保持高可用性。6在有垃圾收集器的环境中,泄漏内存也是一种可行的策略,在这种情况下,垃圾收集器可以被认为是堵塞了泄漏[KL80]。但是,如果您的环境缺少垃圾收集器,请继续阅读!
第五种方法避免了周期崩溃,而是周期性地“停止世界”,例如传统的停止世界的垃圾收集器。这种方法在无处不在的连接之前的几十年里也被广泛使用,当时在每个工作日结束时关闭电力系统是一种常见的做法。然而,在当今这个始终相连的世界中,停止这个世界会严重降低响应时间,这是开发并发垃圾收集器的动机之一[BCR03]。此外,虽然我们需要所有已有的读者来完成,但我们不需要它们全部同时完成。
这个观察结果导致了第六种方法,即一次停止一个CPU或线程。这种方法的优点是根本不会降低读者的响应时间,更不用说严重降低了。此外,许多应用程序已经有了状态(称为静止状态),只有在所有已存在的阅读器都完成之后才能达到。在事务处理系统中,一对连续事务之间的时间可能会
处于静止状态。在反应性系统中,一对连续事件之间的状态可能是静止状态。在非抢占式操作系统内核中,上下文开关可以是静止状态[MS98a]。无论如何,一旦所有的cpu和/或线程都通过了一个静止状态,系统就被说已经完成了一个宽限期,在这个宽限期时,所有在这个宽限期开始时存在的阅读器都保证已经完成。因此,释放在该宽限期开始之前被删除的任何被删除的数据项也被保证是安全的。
在非先发制人的操作系统内核中,要使上下文切换成为有效的静止状态,读取器在引用通过图9.6和9.7所示的gptr指针获得的给定实例数据结构时,必须禁止阻塞。这种无阻塞约束与在纯自旋锁上的类似约束是一致的,即CPU在持有自旋锁时被禁止阻塞。如果没有这个约束,所有的cpu都可能被旋转线程试图获得被阻塞线程持有的旋锁。旋转线在获得锁之前不会放弃它们的CPU,但是持有锁的线不可能释放它,直到其中一个旋转线放弃了一个CPU。这是一种典型的死锁情况,通过禁止阻塞,同时持有自旋锁来避免这种死锁。
同样,对解引用gptr的读取器线程也施加了同样的约束:这样的线程在使用指向数据项完成之前不允许阻塞。返回到图9.7的第二行,其中更新程序刚刚完成执行smp_store_release(),假设CPU 0执行一个上下文切换。因为读取器不允许在遍历链表时进行阻塞,所以我们保证可能已经在CPU 0上运行的所有之前的读取器都已完成。将这一推理扩展到其他CPU,一旦观察到每个CPU执行上下文切换,我们就保证所有之前的读取器都已经完成,并且不再有任何引用新删除的数据元素的读取器线程。然后,更新器可以安全地释放该数据元素,从而产生图9.7底部所示的状态。
这种方法被称为基于静止状态的回收(QSBR)[HMB06]。QSBR示意图如图9.8所示,随着时间从图的顶部推进到底部。青色的方框描述了RCU读侧临界部分,每个部分以rcu_read_lock()开始,以rcu_read_unlock()结束。CPU 1执行了WRITE_ONCE(),它删除了当前的数据项(大概之前已经读取了指针值并利用了适当的同步),然后等待读取器。这个等待操作会导致一个即时的上下文切换,这是一个静止状态(用粉红色的圆圈表示),这反过来意味着在CPU 1上的所有先前的读取都已经完成。接下来,CPU 2进行上下文切换,这样CPU1和2上的所有读取器都已完成。最后,CPU 3进行了一个上下文切换。此时,已知整个系统中的所有读取器都已完成,因此宽限期结束,允许synchronize_rcu()返回到其调用者那里,进而允许CPU 1释放旧的数据项。

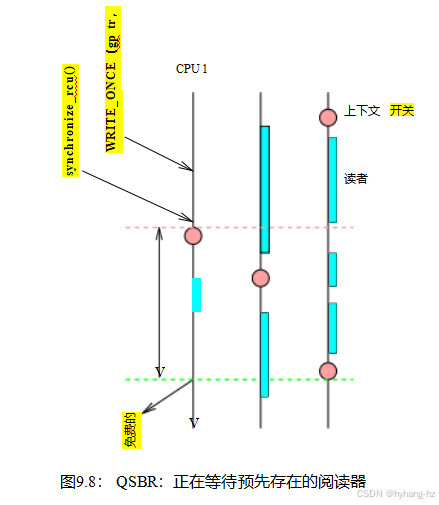
虽然生产质量的QSBR实现可能相当复杂,但一个玩具的非抢占式的linux内核实现却相当简单:
| 空白synchronize_rcu(空白){ int cpu; for_each_online_cpu(cpu) sched_setaffinity(当前->pid,cpumask_of(cpu));} |
for_each_online_cpu()原语遍历所有CPU,sched_()函数导致当前线程在指定的CPU上执行,这迫使目标CPU执行上下文切换。因此,一旦for_each_online_cpu()完成,每个CPU都执行了一个上下文切换,这反过来又保证了所有预先存在的读取器线程都已经完成。
请注意,这种方法不是生产质量的。对许多角情况的正确处理和对一些强大优化的需要意味着生产质量的实现是相当复杂的。此外,针对可抢占环境的RCU实现要求读者实际做一些事情,在非实时linux内核环境中,可以简单地将rcu_read_锁()和rcu_read_unlock()定义为先禁用()和先启用(),

并证明了即使面对并发更新,也以零成本提供读端同步是可能的。实际上,清单9.13显示了如何实现读取(access_route())、图9.6的插入(ins_route())和图9.7的删除(del_route())。(第9.5.4.1节显示的路由表。)
快速测试9.26:清单9.13中的rcu_read_lock()和rcu_read_unlock()的意义是什么?为什么不让静止的状态为自己说话呢?

请参考清单9.13,请注意,route_lock用于在调用ins_route()和del_route()的并发更新器之间进行同步。但是,这个锁不是由调用access_route()的阅读器获取的:阅读器反而受到第9.5.1.3节中描述的QSBR技术的保护。
请注意,ins_route()只是返回gptr的旧值,图9.6假定该值始终为NULL。这意味着调用者有责任确定如何处理非null值,这项任务由于读者可能仍在一段不确定的时间内引用它而变得复杂。呼叫者可以使用以下方法之一:
1.使用synchronize_rcu()来安全地释放这个指向性的结构。尽管从RCU的角度来看,这种方法是正确的,但可以说它存在软件工程泄漏-api问题。
2.如果返回的指针是非空的,则触发一个断言。
3.将返回的指针传递给稍后调用的ins_route(),以恢复之前的值。
相比之下,del_route()使用synchronize_rcu()和免费的()来安全地释放新删除的数据项。

这个示例显示了读取和更新受RCU保护的数据结构的一种通用方法,但是,有相当多的用例,其中一些将在第9.5.4节中介绍。
总之,实际上可以创建并发链接的数据结构,而执行与单线程读取器将执行的相同的机器指令序列的读取器可以遍历这些数据结构。下一节总结了RCU的高级属性。
9.5.1.5 RCU属性
一个关键的RCU属性是,读取不需要等待更新。该属性使RCU实现能够提供低成本甚至无成本的读取器,从而实现低开销和优秀的可伸缩性。这个属性还允许RCU读取器和更新器进行有用的并发向前进程。相比之下,传统的同步原语必须使用昂贵的指令强制执行严格的互斥,从而增加了开销并降低了可伸缩性,但通常也禁止读取器和更新者进行有用的并发向前进程。

如前所述,RCU划定读者与rcu_read_lock()和rcu_read_解锁(),并确保每个读者有一个一致的视图(见图9.7)通过维护多个版本的对象和使用更新端原语如synchronize_rcu()确保对象不释放,直到完成所有读者可能使用它们。RCU使用rcu_assign_pointer()和rcu_dereference()分别为发布和读取对象的新版本提供了高效和可伸缩的机制。这些机制将工作分配在读取路径和更新路径之间,从而使读取路径非常快,以类似于危险指针的方式使用复制和弱化优化,但不需要读取侧重试。在某些情况下,包括CONFIG_PREEMPT=n Linux内核,RCU的读端原语没有任何开销。
但是这些属性在实践中真的有用吗?这个问题将在下一节中进行讨论。
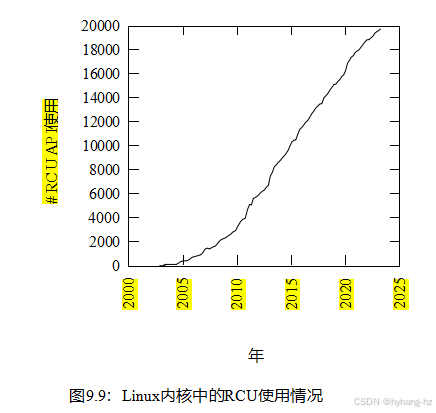
RCU自2002年10月以来就已经在Linux内核中使用了[Tor02]。从那时起,RCU API的使用已经大幅增加,如图9.9所示。RCU在被Linux内核中接受之前和在Linux内核之后都被大量使用,如第9.5.5节所述。总之,RCU具有广泛的实际适用性。
本节中讨论的最小示例是对RCU的一个很好的介绍。然而,RCU的有效使用通常要求您对您的问题有不同的思考。因此,检查RCU的基本原理是很有用的,这是下一节所讨论的任务。
本节重新检查上一节中所涵盖的地面,但独立于任何特定的示例或用例。喜欢生活得非常接近实际代码的人可能希望跳过本节中介绍的基本基本原理。
RCU由三种基本机制组成,第一种用于插入,第二种用于删除,第三种用于允许读取器容忍并发的插入和删除。第9.5.2.1节描述了用于插入的发布-订阅机制,第9.5.2.2describes节如何等待已有的RCU阅读器支持删除,以及第9.5.2.3discusses节如何维护最近更新的对象的多个版本允许并发插入和删除。最后,第9.5.2.4节总结了RCU的基本原理。
9.5.2.1发布-订阅机制
因为RCU阅读器不被RCU更新器排除在外,所以当阅读器访问它时,受RCU保护的数据结构可能会发生改变。可以移动、删除或替换已访问的数据项。因为数据结构对读者来说不会“保持静止”,所以每个读者的访问都可以被认为是订阅了当前版本的
受RCU保护的数据项。对于更新者来说,他们可以被认为是发布新版本。
不幸的是,正如在第4.3.4.1节中所述和在第9.5.1.1节中所重申的那样,对这些发布和订阅操作使用普通访问是不明智的。相反,有必要通知编译器和CPU需要注意,如图9.10所示,它说明了清单9.13中并发执行ins_route()(及其调用者)和access_route()之间的交互。
图9.10中的ins_route()列显示了ins_route()调用者分配一个新的路由结构,然后包含初始化预的垃圾。然后,调用者初始化新分配的结构,然后调用ins_route()来发布一个指向新路由结构的指针。发布不影响结构的内容,因此该结构在发布后仍然有效。
同一图中的access_route()列显示了被订阅和取消引用的指针。此解除引用操作绝对必须看到有效的路由结构,而不是初始化之前的垃圾,因为引用垃圾可能会导致内存损坏、崩溃和挂起。如前所述,避免这种垃圾意味着发布和订阅操作必须同时通知编译器和CPU需要维护所需的顺序。
发布由rcu_assign_pointer()执行,它确保ins_路由()的调用者的初始化在实际发布操作的指针存储之前被排序。此外,rcu_assign_pointer()必须是原子性的,因为并发读取器可以看到指针的旧值或指针的新值,但不能看到这两个值的某些混搭。C11存储发布操作满足了这些要求,事实上,在Linux内核中,rcu_assign_pointer()是根据smp_store_release()来定义的,这类似于C11存储发布。
请注意,如果需要并发更新,则将需要某种同步机制来调解同一指针上的多个并发rcu_assign_pointer()调用。在Linux内核中,锁定是可选择的机制,但是
几乎可以使用任何同步机制。一个特别轻量级的同步机制的例子是第8章的数据所有权:如果每个指针都属于一个特定的线程,那么该线程可以在该指针上执行rcu_assign_pointer(),而不需要额外的同步开销。

订阅由rcu_dereference()执行,它命令在取消引用之前从指针加载订阅操作。类似于rcu_asist_指针(),rcu_dereference()必须是原子的,因为加载的值必须是从单个存储加载的,例如,编译器不能破坏负载。9不幸的是,对rcu_dereference()的编译器的支持最多是一个正在进行中的工作[MWB+ 17,MRP+ 17,BM18]。与此同时,Linux内核依赖于易失性负载、各种CPU架构的细节、编码限制[McK14e],以及在DEC Alpha [Cor02]上的内存障碍指令。然而,在其他架构上,rcu_dereference()通常会发出单个加载指令,就像等效的单线程代码一样。编码限制在第15.3.2节中有更详细的描述,但是,现场选择的常见情况(“->”)工作得相当好。不需要最终读取端性能的软件可以使用C11获取负载,从而提供所需的订购和更多,尽管是有代价的。希望对rcu_dereference()的轻级编译器支持将在适当的时候出现。
简而言之,使用rcu_assign_pointer()来发布指针和使用rcu_取消引用()来订阅它们,成功地避免了图9.10中所示的“不确定”的垃圾负载。因此,这两个原语可以用于向链接结构添加新数据,而不中断并发读取器。

在不中断读取器的情况下将数据添加到链接结构是一件好事,与单线程读取器相比,这可以在不增加读取端成本的情况下实现。但是,在大多数情况下,还需要删除数据,这是下一节的主题。
在其最基本的形式中,RCU是一种等待事情完成的方式。当然,还有很多其他的方式来等待事情完成,包括参考计数、读者-作者锁、事件等等。RCU的最大优点是,它可以等待(例如)20,000个不同事物中的每一个,而不必明确地跟踪每一个,也不必担心性能下降、可伸缩性限制、复杂的死锁场景和内存泄漏危险
使用显式跟踪的方案。
在RCU的例子中,每个等待的东西都被称为RCU读侧关键部分。如表9.1所示,RCU读取侧临界部分以rcu_read_lock()原语开始,并以相应的rcu_read_unlock()原语结束。RCU读侧关键部分可以嵌套,并且可以包含几乎任何代码,只要该代码不包含静止状态。例如,在Linux内核中,在RCU读取侧临界部分中休眠是非法的,因为上下文切换是一种静止状态。10如果您遵守这些约定,您可以使用RCU来等待任何预先存在的RCU读取侧关键部分完成,而synchronize_rcu()则使用间接的方法来完成实际的等待[DMS+ 12,McK13]。
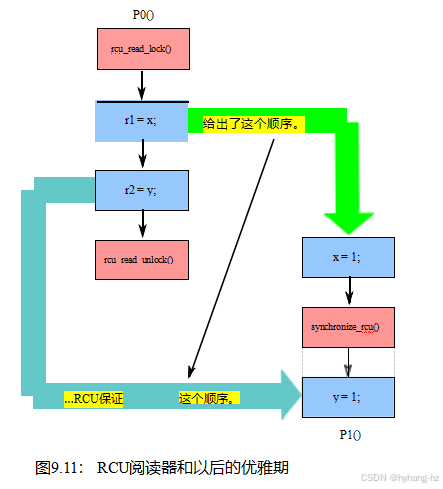
RCU读侧临界段与以后的RCU宽限期之间的关系是一种如果-则关系,如图9.11所示。如果一个给定的临界部分的任何部分先于一个给定的宽限期的开始,那么RCU保证所有的该临界部分都将先于该宽限期的结束。在图中,P0()对x的访问先于P1()对这个相同变量的访问,因此也先于P1()对synchronize_rcu()的调用所产生的宽限期。因此,可以保证P0()对y的访问将先于P1()的访问。在这种情况下,如果r1的最终值为0,则r2的最终值也保证为0。
![]()
RCU读侧临界段与早期RCU宽限期之间的关系也是一种if-then关系,如图9.12所示。如果给定临界部分的任何部分在给定宽限期结束之后,那么RCU保证所有临界部分都在该宽限期的开始之后。在
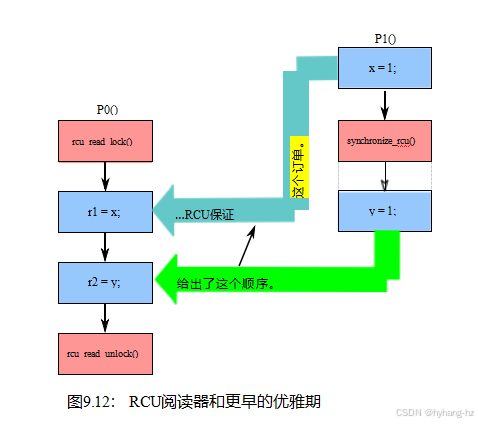
图中,P0()对y的访问遵循P1()对相同变量的访问,因此遵循P1()对synchronize_rcu()的调用产生的宽限期。因此,可以保证P0()对x的访问将遵循P1()的访问。在这种情况下,如果r2的最终值为1,那么r1的最终值也保证为1。

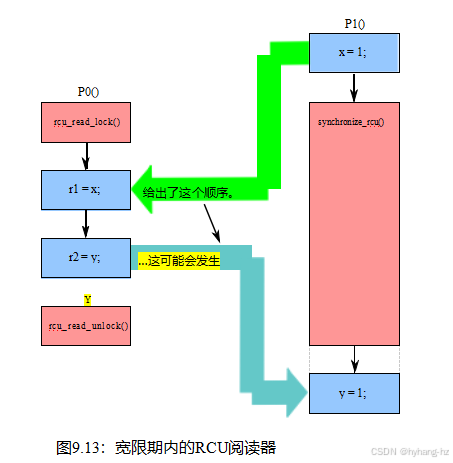
最后,如图9.13所示,RCU读取侧临界部分可以通过RCU宽限期完全重叠。在这种情况下,r1的最终值为1,r2的最终值为0。
但是,r1的最终值不是0,r2的最终值不是1。这将意味着RCU的读取侧临界部分完全重叠了一个宽限期,这是被禁止的(或者至少在RCU中构成了一个错误)。因此,RCU的等待阅读保证有两部分: (1)如果给定RCU阅读侧临界部分的任何部分先于给定宽限期的开始,那么该临界部分先于该宽限期的结束。(2)如果一个给定的RCU读侧临界部分的任何部分会在一个给定的宽限期的结束之后,那么整个临界部分就会在该宽限期的开始之后。这个定义对于几乎所有基于RCU的算法都是足够的,但是对于那些想要更多的算法,简单的RCU可执行形式模型可以作为Linux内核v4.17及更高版本的一部分获得,如第12.3.2节所讨论的。此外,RCU的排序属性在第15.4.3节中更详细的内容进行了更详细的研究。

尽管RCU的等待阅读器功能有时确实用于为如图9.11–9.13所示的变量排序赋值,但它更经常用于安全地释放从链接结构中删除的数据元素,正如在第9.5.1节中所做的那样。一般的过程可以用以下的伪代码来说明:
1.进行更改,例如,从链接列表中删除一个元素。
2.等待所有已存在的RCU读取侧关键部分完全完成(例如,通过使用synchronize_rcu())。
3.例如,例如,释放上面替换的元素。
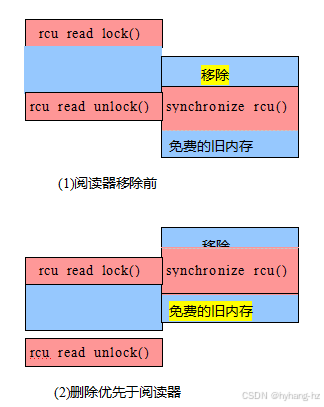
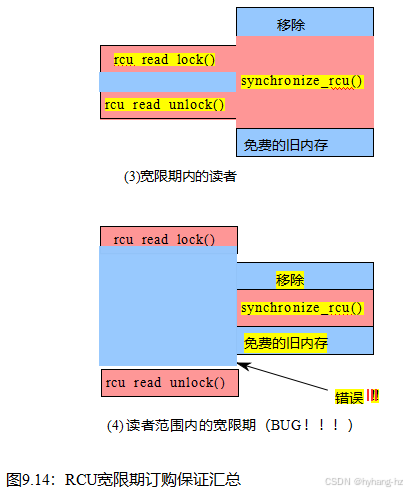
这个更抽象的过程需要一个比Figures9.11–9.13更抽象的图表,这是特定于一个特定的试金石测试。毕竟,无论RCU更新的形式和RCU读侧关键部分的形式如何,RCU实现都必须正确工作。图9.14满足了这一需求,显示了四种可能的场景,在每个场景中,时间从上到下向前推进。在每个场景中,RCU阅读器由左边的方框堆栈表示,RCU更新器由右边的堆栈表示。
在第一个场景中,读卡器在更新器开始删除之前开始执行,因此该读卡器可能对已删除的数据元素有一个引用。因此,在阅读器完成之前,更新器不能释放此元素。在第二种场景中,读卡器在删除完成后才会开始执行。读取器无法获得对已删除的数据元素的引用,因此可以在读取器完成之前释放此元素。第三种场景与第二种场景类似,但说明了即使读者无法获得对一个元素的引用,仍然允许推迟对该元素的释放,直到读者完成之后。在第四个也是最后一个场景中,读取器在更新器开始删除数据元素之前开始执行,但这个元素在读取器完成之前(错误地)被释放。一个正确的RCU实现将不允许这第四种情况发生。这个图表因此说明了RCU的等待读者的功能:给定一个宽限期,每个读者在这个宽限期结束之前结束,在这个宽限期开始之后开始,或者两者都开始,在这种情况下,它完全包含在这个宽限期内。
因为RCU的读者可以在更新过程中取得进展,不同的读者可能对数据结构的状态存在分歧,这是下一节将讨论的主题。
本节讨论RCU如何通过包含多个版本的数据来容纳无同步读取器。因为这些无同步的读取器提供了非常弱的时间同步,所以RCU用户通过空间同步进行补偿。空间同步在第6章中讨论了,并在实践中大量使用以获得良好的性能和可伸缩性。在本节中,空间同步将用于实现一种较弱的(但有用的)形式的正确性,以及优秀的性能和可伸缩性。
第9.5.1.1节中的图9.7显示了空间同步的一个简单变体,在其中,与del_route()同时运行的不同阅读器(参见清单9.13)可能会看到旧的路由结构或空列表,但无论什么方式都会得到有效的结果。当然,仔细看图9.6就会发现,调用ins_route()也会导致并发读取器看到不同的版本:无论是初始的空列表还是新插入的路由结构。请注意,引用计数(第9.2节)和风险指针(第9.3节)也会导致并发读取器看到不同的版本,但RCU的轻量级读取器更有可能发生这种情况。
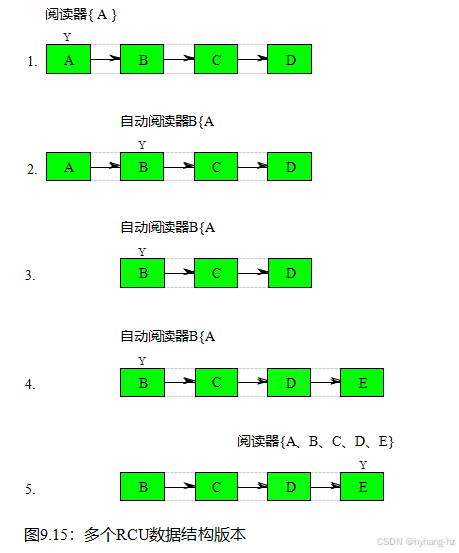
然而,维护多个弱一致的版本可能会带来一些惊喜。例如,考虑图9.15,其中读取器正在遍历同时更新的链表。11在图的第一行,阅读器引用数据项A,在第二行,一直看到B和B。在第三行,更新器删除元素A,在第四行,更新器将元素E添加到列表的末尾。在第五行也是最后一行,读者完成它的遍历,看到元素A到E。
除了没有时间有这样的名单存在。这种情况可能比图9.7中显示的更令人惊讶,图9.7中不同的并发读者看到不同的版本。相比之下,在图9.15中,读者看到了一个从未真正存在过的版本!
解决这种奇怪情况的一种方法是通过较弱的语义学。读取器遍历必须遇到在完整遍历过程中出现的任何数据项(B、C和D)中的任何数据项,并且可能遇到也可能不遇到仅在部分遍历(A和E)中出现的数据项。因此,在这种特殊的情况下,读者遍历遇到所有五个元素是完全合理的。如果这个结果有问题,解决此情况的另一种方法是使用更强的同步机制,如阅读-写入器锁定,或聪明地使用时间戳和版本控制,如第9.5.4.11节所述。当然,更强大的机制将会更昂贵,但工程寿命的关键是选择和权衡。
虽然这种情况看起来很奇怪,但它与现实世界完全一致。正如我们在第3.2节中看到的,有限的光速在计算机系统中不能被忽略,在这个系统之外也不能被忽略。这反过来又意味着,系统内表示系统外现实世界状态的任何数据总是永远过时,因此与现实世界不一致。因此,序列{A、B、C、D、E}很可能发生在现实世界中,但由于光速延迟,从未出现在计算机系统的内存中表示。在这种情况下,读者令人惊讶的遍历将正确地反映现实。
因此,在真实世界的数据上运行的算法必须考虑到不一致的数据,要么通过容忍不一致,要么通过采取步骤来排除或拒绝它们。在许多情况下,这些算法也完全能够处理系统内的不一致性。
第9.1节中介绍的前bsd包路由例子就是一个很好的例子。路由列表的内容是由路由协议设置的,这些协议具有显著的延迟(秒甚至分钟),以避免路由不稳定性。因此,一旦路由更新到达一个给定的系统,它很可能已经以错误的方式发送数据包。在更新运行的几微秒内以错误的方式发送一些数据包显然不是问题,因为处理延迟路由更新的高级协议操作也会处理内部不一致。
互联网路由也不是唯一能容忍不一致的情况。重复,任何算法,在系统内数据跟踪系统外的状态必须容忍不一致性,包括安全策略(通常由委员会的人类),存储配置,和WiFi接入点,更不用说可移动硬件如麦克风、耳机、相机、鼠标、打印机和其他。此外,图9.9所示的大量Linux内核RCU API的使用,以及Linux内核对引用计数的大量使用和危害的增加其他项目中的指针表明,对这种不一致性的容忍比人们想象的更普遍。
这种常见情况的不一致性容忍的一个根本原因是,单项查找在实践中比全数据结构遍历要常见得多。毕竟,全数据结构的遍历比单项查找要昂贵得多,因此开发人员有动机避免这种遍历。并发更新不仅比完整的遍历更不可能影响单项查找,而且孤立的单项查找也无法检测到这种不一致性。因此,在常见的情况下,这种不一致不仅是可以容忍的,它们实际上是看不见的。
在这种情况下,RCU阅读器可以被认为是完全有更新器,尽管这些阅读器可能执行与单线程程序执行的机器指令序列完全相同,正如201页所暗示的那样。例如,参考第226页上的清单9.13,假设每个读取器线程在其生命周期中只调用access_route()一次,并且读取器和更新线程之间没有其他通信。然后,每次调用访问_路由()都可以在ins_route()调用之后进行排序,该ins_route()调用产生了由访问_路由()中列表的第11行访问的路由结构,并在任何后续的ins_route()或del_route()调用之前进行排序。
总之,维护多个版本正是实现RCU阅读器的极低开销的原因,正如前面所述,许多算法都不被多个版本所困扰。然而,也有一些算法绝对不能处理多个版本。有一些技术可以将这种算法应用于RCU [McK04],例如,使用第13.4.2节中描述的序列锁定。
这些示例假设在整个更新操作中保持互斥锁,这意味着在给定时间最多可能有两个版本的列表。
本节描述了基于RCU的算法的三个基本组件:
1.一种发布-订阅机制,用于添加新数据,包括用于更新端发布的rcu_assign_指针()和用于读端订阅的rcu_dereference(),
2.一种等待现有的RCU阅读器完成的方式,一方面是基于由rcu_read_lock()和rcu_read_unlock()分隔的阅读器,另一方面是通过synchronize_rcu()或call_rcu()等待的更新器(正式描述见第15.4.3节),以及
3.一种维护多个版本以允许更改在不伤害或过度延迟的情况下的并发RCU阅读器的原则。

这三个RCU组件允许在面对并发读取器时更新数据,这些并发读取器可能正在执行与单线程实现中的读取器将使用的相同的机器指令序列。这些RCU组件可以以不同的方式组合,以实现令人惊讶的不同类型的基于RCU的算法,其中一些在9.5.4节中介绍。然而,通常在更高的抽象级别上工作会更好。为此,下一节将描述linux内核API,它包括简单的数据结构,如列表。
本节从RCU的linux-内核API的角度来看它。12第9.5.3.2节介绍了RCU的等待完成api,第9.5.3.3presents RCU的发布-订阅和版本维护api,第9.5.3.4presents RCU的列表处理api,第9.5.3.5presents RCU的诊断api,以及第9.5.3.6节描述了RCU在哪个上下文中可以使用的各种api。最后,9.5.3.7presents节总结语。
对内核内部不感兴趣的读者可能希望跳过到第251页的第9.5.4节,但最好是在回顾了下一节关于软件工程的考虑之后。
9.5.3.1 RCU API和软件工程
已经浏览了表9.2、9.3、9.4和9.5的读者可能会注意到,linux内核api的完整列表有超过100个成员。这与表9.1中显示的仅有的6个API成员形成了鲜明的(也许是令人沮丧的)对比。这种情况清楚地提出了这样一个问题:“为什么会有这么多人?”??"
这个问题将在下面的部分中得到更彻底的回答,但同时本节的其余部分总结了动机。
有一句明智的老话,大意是“错是人”。这意味着RCU API的很大一部分的目的是提供诊断,最显著的是表9.5,但在其他地方也是如此。
造成人类错误的重要原因是人类大脑的局限性,例如,短期记忆的有限能力。在这本书中展示的玩具的例子并没有强调这些限制。这是出于必要:许多读者在学习新材料的同时推动他们的认知极限,所以例子需要保持简单。
因此,这些示例将rcu_dereference()调用与封闭的rcu_read_lock()和rcu_read_unlock()调用相同的函数中。相比之下,现实世界的软件必须经常从不同的函数,甚至从不同的翻译单元调用这些API成员。因此,Linux内核RCU API已经扩展以适应锁定程序,这允许rcu_dereference()和朋友在不受rcu_read_lock()保护时抱怨。Linux内核RCU还检查一些双自由错误,RCU读侧临界部分中的无限循环,并尝试在RCU读侧临界部分中调用静止状态。
现实世界的软件适应人类认知极限的另一种方式是通过抽象。因此,linux内核API包含了对其进行操作的成员除了表9.1中的面向指针的核心API之外。Linux内核本身还提供了受RCU保护的哈希表和搜索树。
像Linux这样的操作系统内核在图2.3中所示的软件堆栈的“铁三角形”的底部附近运行,在那里性能至关重要。因此有专门的变异的RCU api用于快速路径,例如,在9.5.3.3节中讨论,RCU_INIT_POINTER()可以代替rcu_assign_pointer()在RCU保护指针被分配给空或当指针尚未被读者访问。使用RCU_INIT_POINTER()允许编译器在选择指令和执行优化方面有更多的回旋余地,从而提高了性能。
另一方面,当使用错误的RCU_INIT_POINTER()会导致静默内存损坏,所以请小心!是的,在某些情况下,内核可以检查给定内核上下文中RCU API成员的不适当使用,但是RCU_INIT_POINTER()使用的约束还无法检查。
最后,在Linux内核中,上述人类认知的限制因在Linux上运行的工作负载的多样性和严重性而加剧。在v5.16中,这产生了不少于五种类型的RCU,每一种都设计为RCU读者和作者提供不同的性能、可伸缩性、响应时间和能源效率权衡。这些RCU口味将是下一节的主题。
对“什么是RCU”最直接的答案是,RCU是一个API。例如,在Linux内核中使用的RCU实现由表9.2总结,其中分别显示了RCU、“可睡眠”RCU(SRCU)、任务RCU和通用API的等待阅读器部分,表9.3显示了API的发布-订阅部分[McK19b].13]
如果您是RCU的新手,您可以考虑只关注表9.2中的一个列,每一个列都总结了Linux内核的RCU API家族中的一个成员。例如,如果您主要对理解在Linux内核中如何使用RCU感兴趣,那么“RCU”将是开始的地方,因为它是最常用的。另一方面,如果您想理解RCU本身,“Tasks RCU”有最简单的API。您以后总是可以回来查看其他列。
![]()
“RCU”列对应于三个linux内核RCU实现的整合[McK19c,McK19a],其中RCU读侧关键部分以rcu_read_lock()、rcu_read_lock_bh()或rcu_read_lock_sched()开始,分别以rcu_read_unlock()、rcu_read_unlock_bh()或rcu_read_unlock_ sched()结束。任何禁用下半部分、中断或抢占的代码区域也充当RCU读侧关键部分。RCU读侧裂缝切片可以嵌套。相应的同步更新端原语synchronize_rcu()和synchronize_rcu_expedited(),以及它们的同步缩写syyan_net(),等待当前执行的RCU读取端的任何类型的关键部分完成。这种等待的长度被称为“宽限期”,而synchronize_rcu_expedited()旨在减少宽限期延迟
表9.2: RCU等待完成的api
| RCU:原始 | SRCU:睡眠读者 | 任务RCU:免费追踪蹦床 | 任务RCU粗鲁:自由的空闲任务跟踪蹦床 | 任务RCU跟踪:保护可睡眠的BPF程序 | |
| 初始化和清理 | define_srcu() DEFINE_STATIC_SRCU() init_srcu_struct() cleanup_srcu_struct() | ||||
| 读取端 临界截面标记 | rcu_read_lock() ! rcu_read_unlock() ! rcu_read_lock_bh() rcu_read_unlock_bh() rcu_read_lock_sched() rcu_read_unlock_sched() (再加上任何贬低的底部 一半,优先购买权,或中断。) | srcu_read_lock() srcu_read_unlock() | 自愿的上下文切换 | 自愿的上下文切换和 代码的优先启用区域 | rcu_read_lock_trace() rcu_read_unlock_trace() |
| 更新端原语(同步) | synchronize_rcu()同步_net() synchronize_rcu_expedited() | synchronize_srcu() synchronize_srcu_expedited() | synchronize_rcu_tasks() | synchronize_rcu_tasks_rude() | synchronize_rcu_tasks_trace() |
| 更新端原语 (异步/回调) | call_rcu() ! | call_srcu() | call_rcu_tasks() | call_rcu_tasks_rude() | call_rcu_tasks_trace() |
| 更新端原语(等待回调) | rcu_barrier() | srcu_barrier() | rcu_barrier_tasks() | rcu_barrier_tasks_rude() | rcu_barrier_tasks_trace() |
| 更新端原语(启动/等待) | get_state_synchronize_rcu() cond_synchronize_rcu() | ||||
| 更新侧原语(空闲内存) | kfree_rcu() | ||||
| 类型安全存储器 | |||||
| 读取侧约束 | 无阻塞(仅限优先购买权) | 没有具有相同srcu结构的synchronize_srcu() | 没有自愿的上下文切换 | 既不阻塞也不优先购买 | 没有RCU任务跟踪的宽限期 |
| 读取侧开销 | 简单的指令,记忆障碍 | 免费的 | CPU本地访问(优先=免费) | CPU本地访问 | |
| 异步 更新端开销 | 亚微秒 | 亚微秒 | 亚微秒 | 亚微秒 | 亚微秒 |
| 恩典期延迟 | 10秒 | 毫秒 | 助手 | 毫秒 | 10秒 |
| 加速的 宽限期 | 10秒微秒 | 微秒 | N/A | N/A | N/A |
增加的CPU开销和ipi的费用。异步更新端原语call_rcu()在后续宽限期之后调用具有指定参数的指定函数。例如,call_rcu(p,f);将导致在随后的宽限期之后调用“RCU回调”f (p)。在某些情况下,例如在卸载使用call_rcu()的linux内核模块时,需要等待所有未完成的RCU回调来完成[McK07e]。rcu_barrier()原语将执行这项工作。

最后,RCU可用于提供类型安全的内存[GC96],如第9.5.4.5节所述。在RCU的上下文中,类型安全内存保证了给定的数据元素在访问它的任何RCU读侧关键部分期间都不会更改类型。要使用基于RCU的类型安全内存,请将SLAB_TYPESAFE_BY_RCU传递给kmem_cache_create()。
Table9.2displays中的“SRCU”列是一个专门的RCU API,允许在由srcu_read_lock()和srcu_read_unlock()分隔的srcuread侧临界部分[McK06]中进行一般睡眠。但是,与RCU不同的是,SRCU的srcu_read_lock()返回一个必须传递到相应srcu_read_unlock()的值。这种差异是由于SRCU用户为每个不同的SRCU使用分配了一个srcu_struct,因此没有方便的地方来存储每个任务的读取器嵌套计数。(请记住,尽管Linux内核提供了动态分配的每个cpu的存储,但目前还没有动态分配的每个任务的存储。)
如果一个给定的srcu_struct结构必须在多个翻译单元中使用,则可以使用DEFINE_ SRCU()定义为一个全局变量,否则也可以定义为DEFINE_ STATIC_SRCU()。例如,DEFINE_SRCU(my_srcu)将创建一个名为my_srcu的全局变量,程序中的任何文件都可以使用该变量。或者,srcu_struct结构可以是堆栈上的变量或动态分配的内存区域。在这两种非全局变量的情况下,内存必须在第一次使用前使用init_srcu_struct()进行初始化,并在最后一次使用后(但在底层存储消失之前)使用cleanup_srcu_struct()进行清理。
然而它们被创建,这些不同的srcu_struct结构阻止SRCU读侧临界部分阻断不相关的synchronize_srcu()和synchronize_srcu_expedited()调用。当然,在SRCU读侧临界部分中使用synchronize_srcu()或synchronize_srcu_expedited()都会导致自死锁,因此应该避免。与RCU一样,SRCU的synchronize_srcu_expedited()与synchronize_srcu()相比减少了宽限期延迟,但以增加CPU开销为代价。

与普通的RCU类似,使用异步调用_srcu()函数可以避免自死锁。但是,在使用call_srcu()时必须特别小心因为单个任务可以很快地注册SRCU回调。鉴于SRCU允许读者阻塞任意的时间段,这可能会消耗任意大量的内存。相反,给定同步synchronize_srcu()接口,给定任务必须完成等待给定宽限期,才能开始等待下一个宽限期。
同样类似于RCU,还有一个srcu_barrier()函数,它等待调用所有之前的call_srcu()回调。
换句话说,SRCU通过允许开发人员限制其范围来弥补其极其薄弱的前进进度保证。
表9.2中的“Tasks RCU”列显示了一个专门的RCU API,它调节了在linux-内核跟踪中使用的蹦床的释放。这些蹦床用于将控制从被跟踪的代码中的一个点转移到进行实际跟踪的代码中。当然,有必要确保在一个给定的蹦床中执行的所有代码在释放该蹦床之前都已经完成。
对被跟踪的代码的更改通常仅限于单个跳转或调用指令,因此不能适应实现rcu_read_lock()和rcu_read_unlock()所需的代码序列。蹦床也不能包含这些对rcu_read_lock()和rcu_read_unlock()的呼叫。要看到这一点,请考虑一个即将开始执行给定蹦床的CPU。因为它还没有执行rcu_read_lock(),这个蹦床可以在任何时候被释放,这对这个CPU来说是一个致命的惊喜。因此,蹦床不能被在跟踪代码或蹦床本身中执行的同步原语所保护。这确实提出了一个关于究竟如何保护蹦床的问题。
回答这个问题的关键是要注意,蹦床代码从来不包含直接或间接执行自愿上下文切换的代码。这段代码可能会被抢占,但它永远不会直接或间接地调用调度()。这表明RCU的一种变体具有自愿的上下文切换和空闲执行作为其唯一的静止状态。这个变体是taskes RCU。
任务RCU没有读侧标记功能,这很好,因为它的主要用例没有地方放置这样的标记。相反,调用调度()直接作为静止状态。更新可以使用synchronize_rcu_tasks()来等待所有已存在的蹦床执行完成,或者它们可以使用它的异步对应项,call_rcu_tasks()。还有一个rcu_barrier_tasks(),等待完成对应于所有call_rcu_任务()调用的回调。没有synchronize_rcu_tasks_expedited(),因为还没有对它的请求,尽管实现一个有用的变体也不会没有挑战。

“任务RCU Rude”列提供了在第9.5.1.4节中介绍的玩具集成功能的一个更有效的变体。这种变体会导致每个CPU执行一个上下文切换,因此任何自愿的上下文切换或代码的任何可抢占区域都可以作为一个静止状态。Tasks RCU Rude变体使用linux内核工作队列工具来强制并发上下文切换,而不是玩具实现所采用的串行cpu-cpu方法。该API反映了Tasks RCU的特性,包括缺乏显式的读侧标记。
表9.3: RCU发布-订阅和版本维护API

因此,对于Tasks RCU家族具有明确的读侧标记是不寻常的!

rcu_pointer_handoff()原语只是返回它的唯一参数,但对于工具检查从RCU读侧关键部分泄漏的指针很有用。rcu_pointer_handoff()的使用表明,对于这些工具,有关结构的保护已经从RCU转移到一些其他一些机制,如锁定或参考计数。
RCU_INIT_POINTER()宏可以用于初始化尚未公开给阅读器的受RCU保护的指针,或者,也可以将受RCU保护的指针设置为NULL。在这些受限的情况下,不需要由rcu_assign_pointer()提供的内存屏障指令。类似地,RCU_POINTER_INITIALIZER()提供了一个gcc风格的结构初始化器,以允许在结构中轻松地初始化受RCU保护的指针。
第二类订阅指向数据项的指针,或者,安全地遍历受RCU保护的指针。同样,简单地使用c语言访问加载这些指针可能会导致在被指向的数据中看到预初始化前的垃圾。类似地,在RCU读侧临界部分之外以任何方式加载这些指针都可能导致随时释放指向对象。但是,如果指针只是要测试而不要取消引用,那么释放指向的对象并不一定是一个问题。在这种情况下,可以使用rcu_access_pointer()。但是,通常情况下,RCU读侧保护是必需的,因此rcu_dereference()原语使用Linux内核的锁锁工具[Cor06a]来验证此rcu_dereference()调用是否受rcu_read_lock()、srcu_read_lock()或其他RCU读侧标记的保护。相比之下,rcu_access_pointer()原语不涉及锁锁,因此当在RCU读侧临界部分之外使用时,不会引发锁锁投诉。
另一种不需要保护的情况是,更新端代码在保持更新端锁的同时访问受RCU保护的指针。针对这种情况,提供了受rcu_dereference_保护的()API成员。它的第一个参数是RCU保护的指针,第二个参数采用一个锁表达式,描述为了访问安全必须持有哪些锁。从读取器和更新器调用的代码都可以使用rcu_dereference_check(),它也采用锁锁表达式,但也可以从不持有锁的读取端代码调用。在某些情况下,锁程序表达式可能非常复杂,例如,在使用细粒度锁定时,可能持有大量锁中的任何一个,而且可能很难找出哪些适用。在这些(希望是罕见的)情况下,rcu_dereference_raw()提供了保护,但不检查是否在读取器中被调用,或是否持有任何特定的锁。rcu_dereference_raw_不跟踪()API成员的行为类似,但无法跟踪,因此可以通过跟踪代码安全地使用。
尽管几乎任何链接结构都可以通过操作指针来访问,但高级结构可以非常有帮助。因此,下一节将介绍Linux内核所使用的各种受RCU保护的链接表。
虽然rcu_assign_pointer()和rcu_dereference()在理论上可以用于构建任何可能的受RCU保护的数据结构,但在实践中,通常最好使用更高级层次的构造。因此,rcu_assign_pointer()和
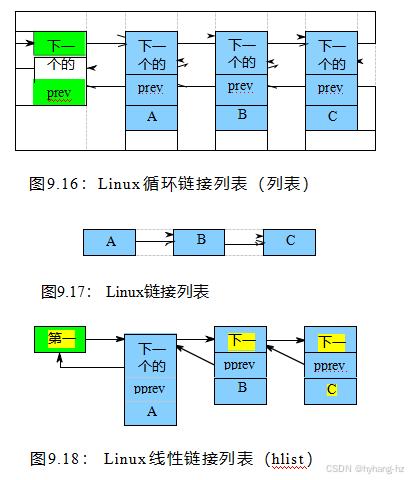
rcu_dereference()原语已经嵌入到Linux的列表操作API的特殊RCU变体中。Linux有四种双链表的变体,环状结构列表_head和线性结构hlist_head/结构hlist_node,结构hlist_nulls_head/结构hlist_nulls_node,和结构hlist_bl_head/结构hlist_bl_node对。前者如图-ure9.16所示,其中绿色(最左边的)框表示列表标题,蓝色(最右边的三个)框表示列表中的元素。这种表示法很麻烦,因此将缩写为如图9.17所示,它只显示非头(蓝色)元素。
Linux的hlist15是一个线性列表,这意味着它只需要一个指针作为标头,而不是循环列表所需的两个指针,如图9.18所示。因此,使用hlist可以使大型哈希表的哈希-桶数组的内存消耗减半。与前面一样,这种表示法很麻烦,因此hlist结构将以与list_head样式列表相同的方式缩写,如Figure9.17中所示。
Linux的hlist的一个变体,名为hlist_nulls,提供了多个不同的NULL指针,但在其他方面使用如图9.18所示的相同布局。在这个变体中,具有零低阶位的->下一个指针被认为是一个指针。但是,如果低阶位设置为1,上层位识别NULL指针的类型。此类型的列表用于允许无锁读取器检测节点何时从一个列表移动到另一个列表。例如,哈希表的每个桶都可能使用其索引来标记它的空指针。如果读取器遇到一个与它开始的桶的索引不匹配的空指针,该读取器知道它正在遍历的元素在遍历期间被移动到其他桶,并随身携带该读取器。读者可以
使用null()函数(如果传递了hlist_nulls NULL指针则返回true)来确定它何时到达列表的结尾,使用get_nulls_value()函数(返回其参数的NULL指针标识符)来获取NULL的类型
建议当get_nulls_value()返回一个意外的值时,阅读器可以采取纠正措施,例如,从一开始就重新启动其遍历。

关于hlist_nulls的更多信息可以在Linux-内核源代码树中找到,并在rculist_nulls.rst文件(旧内核中的rculist_nulls.txt)中提供了有用的示例代码。
Linux的hlist的另一个变体包含了位锁定,名为hlist_bl。这个变体使用如图9.18所示的相同布局,但是保留了头指针的低阶位(图中的“第一”)来锁定列表。这种方法还减少了内存的使用,因为它允许使用指针本身来存储一个单独的自旋锁。
表9.4总结了这些链表变体的API成员。更多信息可在Linux-内核源代码树的文档/RCU目录和Linux每周新闻[McK19b]中获得。
但是,本节的其余部分扩展了list_replace_rcu()的使用,因为这个API成员为RCU提供了它的名称。这个API成员用于执行更复杂的更新一个元素的列表有多个字段原子更新,这样给定的读者看到旧的值或新的值,但不是两组的混合物。例如,链接列表中的每个节点可能都有整数字段->a、->b和->c,并且可能需要将给定节点的字段分别从5、6和7更新到5、2和3。

下面的讨论使用图9.19来说明状态更改。每个元素中的三元组分别表示字段->a、->b和->c的值。红色阴影的元素可能会被阅读器引用,而且由于阅读器不直接与更新器同步,因此阅读器可能会与整个替换过程同时运行。请注意,为了清晰起见,省指针了从尾部到头部的链接。
该列表的初始状态,包括指针p,与删除示例相同,如图的第一行所示。
下面的文本描述了如何将5、2、3替换5、6、7元素,这样任何给定的读者都能看到这两个值中的一个。
第15行分配一个替换元素,导致图9.19第二行所示的状态。此时,读取器无法保存对新分配元素的引用(如绿色阴影所示),并且它未初始化(如问号所示)。
第16行将旧元素复制到新元素,从而得到如图9.19的第三行所示的状态。新分配的元素仍然不能被阅读器引用,但它现在已被初始化。
表9.4:受RCU保护的列表API
| 列表:循环的双链接列表 | 线性双链列表 | hlist_nulls:线性双链表,最多31位标记 | hlist_bl:具有位锁定的线性双链表 | |||||
| 结构列表head | hlist_head | 结构 | hlist_nulls_head | 结构 | hlist_bl_head | |||
| 结构 | hlist_node | 结构 | hlist_nulls_node | 结构 | hlist_bl_node | |||
| 初始化 | ||||||||
| init_list_head_rcu() | ||||||||
| 全遍历 | ||||||||
| list_for_each_entry_rcu() | hlist_for_each_entry_rcu() | hlist_nulls_for_each_entry_rcu() | ||||||
| 列表_for_每个条目_无锁() | hlist_for_each_entry_rcu_bh() hlist_for_each_entry_rcu_notrace() | hlist_nulls_for_each_entry_safe() | ||||||
| 恢复遍历 | ||||||||
| list_for_each_entry_continue_rcu() | hlist_for_each_entry_continue_rcu() | |||||||
| list_for_each_entry_from_rcu() | hlist_for_each_entry_continue_rcu_bh() hlist_for_each_entry_from_rcu() | |||||||
| 逐级遍历 | ||||||||
| list_entry_rcu() list_entry_无锁() list_first_or_null_rcu() list_next_rcu() list_next_or_null_rcu() | hlist_first_rcu() hlist_next_rcu() hlist_pprev_rcu() | hlist_nulls_first_rcu() hlist_nulls_next_rcu() | hlist_bl_first_rcu() | |||||
| 添加 | ||||||||
| list_add_rcu() list_add_tail_rcu() | hlist_add_before_rcu() hlist_add_behind_rcu() hlist_add_head_rcu() hlist_add_tail_rcu() | hlist_nulls_add_head_rcu() | ||||||
| 删除 | ||||||||
| list_del_rcu() | hlist_del_rcu() | hlist_nulls_del_rcu() | hlist_bl_del_rcu() | |||||
| hlist_del_init_rcu() | hlist_nulls_del_init_rcu() | hlist_bl_del_init_rcu() | ||||||
| 更换 | ||||||||
| list_replace_rcu() | ||||||||
| 绞接 | ||||||||
| list_splice_init_rcu() | list_splice_tail_init_rcu() | |||||||
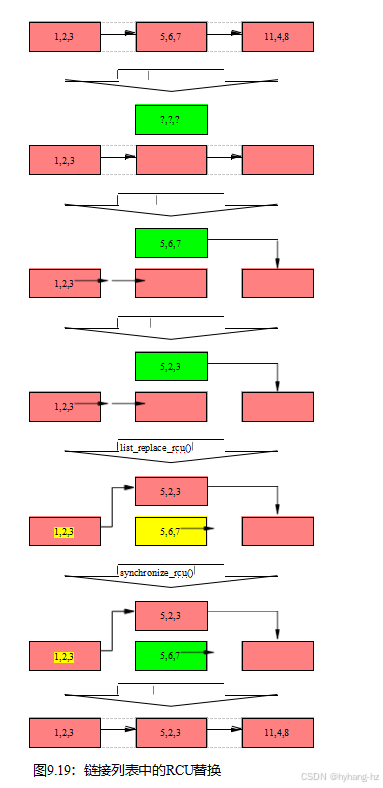
表9.5: RCU诊断api
| 类别 | 原语 |
| 标记RCU指针 | rcu __ |
| 调试对象支持 | init_rcu_head() destroy_rcu_head() init_rcu_head_on_stack() destroy_rcu_head_on_stack() |
| 失速报警控制 | rcu_cpu_stall_reset() |
| 回调检查 | rcu_head_init() rcu_head_after_call_rcu() |
| 锁止装置支架 | rcu_read_lock_held() rcu_read_lock_bh_held() rcu_read_lock_sched_held() srcu_read_lock_held() rcu_is_watching() rcu_lockdep_warn() rcu_nonidle() rcu_sleep_check() |
第17行将q->b更新为值“2”,第18行将q->c更新为值“3”,如图9.19的第四行所示。请注意,读者仍然无法访问新分配的结构。
现在,第19行进行替换,这样新元素最终对读者可以看到,因此被阴影显示为红色,如图9.19的第五行所示。此时,如下图所示,我们有两个版本的列表。已有的读者可能会看到5、6、7元素(因此现在是黄色的),但新的读者将会看到5、2、3元素。但是任何给定的读者都可以保证看到一组值或另一组值,而不是两者的混合。
在第20行上的synchronize_rcu()返回之后,将经过一个宽限期,因此在list_replace_rcu()之前开始的所有读取都将完成。特别是,任何可能持有引用5,6,7元素的读者都保证已经退出他们的RCU阅读侧关键部分,因此被禁止继续持有引用。因此,不再有任何阅读器引用旧元素,如图9.19第六行的绿色阴影所示。就读者而言,我们又回到了列表的单一版本,但是用新元素代替旧元素。
在第21行上的kfree()完成后,该列表将出现在图9.19的最后一行中所示。
尽管RCU是以替换案例命名的,但Linux内核中的绝大多数RCU使用都依赖于简单的独立插入和删除,如第9.5.2.3节中的图9.15所示。
下一节将介绍帮助开发人员调试使用RCU的代码的api。
表9.5显示了RCU的诊断性api。
调试对象支持对于作为从Linux内核的内存分配器获得的结构的一部分的任何rcu_head结构都是自动的,但是那些构建自己的特殊目的内存分配器的rcu_head结构可以在分配和空闲时间分别使用init_rcu_head()和destroy_rcu_ head()。那些使用函数调用堆栈上的rcu_head结构(它会发生!)可以在第一次使用前使用init_rcu_head_on_stack(),在最后一次使用后使用destroy_rcu_head_on_stack(),但在从函数返回之前使用。调试对象支持允许检测涉及将相同的rcu_head结构快速连续传递给call_rcu()和朋友的错误,这是call_rcu()中臭名昭著的双无内存分配错误类的call_rcu()对应物。
停止警告控制由rcu_cpu_stall_reset()提供,它允许调用者在当前宽限期的剩余时间内抑制RCU CPU停止警告。RCU CPU停止警告有助于查明RCU读侧临界部分运行时间过长的情况,这对于内核调试器能够抑制它们很有用,例如,当遇到断点时。
回调检查由rcu_head_init()和rcu_head_after_call_ rcu()提供。前者在传递给调用_rcu()之前在rcu_head结构上调用,然后rcu_head_after_call_rcu()将检查查看是否用指定的函数调用了回调。
对锁锁[Cor06a]的支持包括rcu_read_lock_held()、rcu_read_lock_ bh_held()、rcu_read_lock_sched_held()和srcu_read_lock_held(),如果在相应类型的RCU读端关键部分中调用,它们都返回true。
![]()
因为rcu_read_lock()不能从空闲循环中使用,而且由于能源效率的考虑导致空闲循环变得相当华丽,如果在使用rcu_read_lock()合法的上下文中调用,rcu_is_观察()返回true。请注意,srcu_read_lock()可能从空闲甚至离线cpu中使用,这意味着rcu_is_watching()不适用于SRCU。
如果锁定程序已启用且其参数计算结果为true,RCU_LOCKDEP_WARN()将发出警告。例如,如果在RCU读端临界部分之外调用RCU_LOCKDEP_WARN(!rcu_read_lock_held())将发出警告。
RCU_NONIDLE()可用于强制RCU在执行作为唯一参数传入的语句时进行监视。例如,RCU_NONIDLE(WARN_ON(!rcu_is_watich()))永远不会发出警告。然而,2020-2021年时间框架的变化将RCU扩展到空闲循环,这应该会大大减少甚至消除对RCU_NONIDLE()的需求。
最后,如果在RCU、RCU-bh或RCU-sched读侧关键部分中调用,rcu_sleep_check()将发出警告。
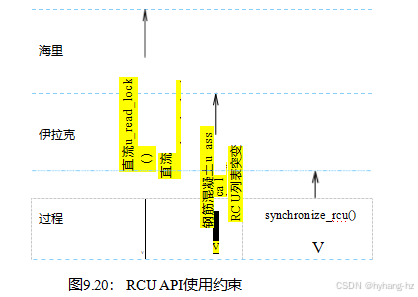
9.5.3.6RCU在哪里可以使用的api?
图9.20显示了在哪个内核环境中可以使用哪些api。RCU读侧原语可以在任何环境中使用,包括NMI,RCU突变和异步宽限期原语可以在NMI以外的任何环境中使用,最后,RCU同步宽限期原语只能在进程上下文中使用。RCU列表遍历原语包括list_ for_each_entry_rcu()、hlist_for_each_entry_rcu()等。类似地,RCU列表突变原语包括list_add_rcu()、hlist_del_rcu()等。
请注意,来自其他RCU家族的原语可以被替换,例如,srcu_read_lock()可以在任何可以使用rcu_read_lock()的上下文中使用。
在其核心上,RCU只不过是一个API,它支持发布和订阅插入,等待所有RCU阅读器完成,并维护多个版本。也就是说,可以在RCU之上构建更高层次的结构,包括Section9.5.4中列出的阅读-写入器锁定、引用计数和存在保证结构。此外,我毫不怀疑Linux社区将继续为RCU找到有趣的新用途,就像它们对整个内核中许多同步原语的作用一样。
当然,一个更完整的RCU视图还将包括您可以使用这些api做的所有事情。
然而,对于许多人来说,一个RCU的完整视图必须包括示例RCU实现。附录Bentury展示了一系列不断增加复杂性和能力的“玩具”RCU实现,尽管其他人可能更喜欢经典的“读取-复制更新的用户级实现”[DMS+ 12]。对于其他人,下一节将给出一些RCU用例的概述。
本节回答了这个问题:“什么是RCU?”从RCU可以使用的角度来看。因为RCU最常用于替换一些现有的机制,所以我们主要从它与这些机制的关系的角度来看待它,比如
表9.6:RCU使用情况
| 机制RCU替换 | 页 |
| 用于BSD前路由的RCU | 252 |
| 等待已存在的事情完成 | 254 |
| 分阶段状态更改 | 257 |
| 仅添加的列表(发布/订阅) | 259 |
| 类型安全存储器 | 259 |
| 存在保证 | 260 |
| 轻质垃圾收集器 | 261 |
| 仅删除列表 | 262 |
| 准读写锁 | 262 |
| 准参考计数 | 272 |
| 准多版本并发性控制(MVCC) | 274 |
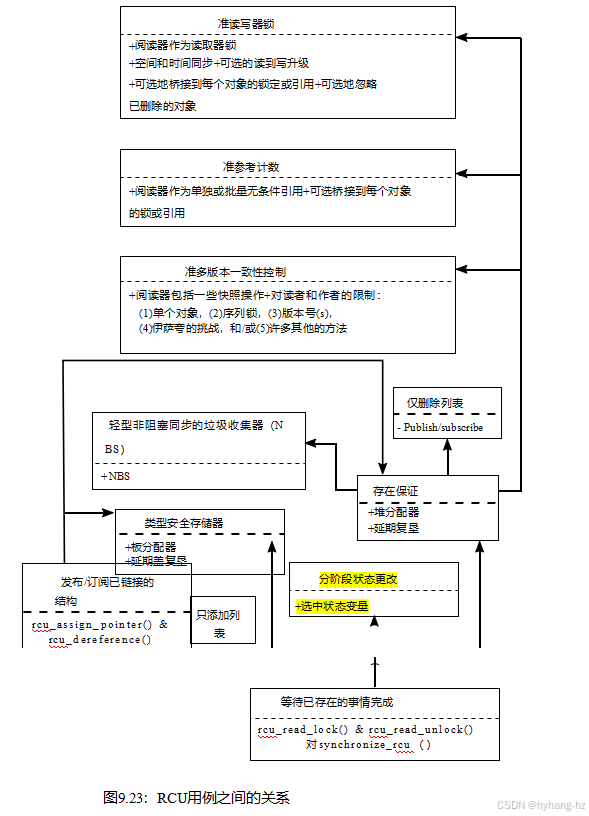
详见表9.6,如图9.23所示。在本表中列出的部分之后,第9.5.4.12provides节是一个摘要。
与后面的部分相比,本节主要关注一个非常特定的用例,以便与其他机制进行比较。
清单9.14和9.15显示了受RCU保护的预BSD路由表(route_rcu.c)的代码。前者显示数据结构和route_lookup(),后者显示route_add()和route_del()。
在清单9.14中,第2行添加了RCU回收使用的->rh字段,第6行添加了->re_freed使用后检查字段,第16行、22行和26行添加了RCU读侧保护,第20行和21行添加了“使用后检查”。在清单9.15中,第11、13、30、34和39行添加了更新侧锁定,第12和33行添加了RCU更新侧保护,第35行导致在宽限期经过之后调用route_cb(),第17-24行定义了route_cb()。这是一个工作并发实现的最小添加代码。
| 1结构路由_entry{ 2 3 4 6 8 CDS_LIST_HEAD(route_list); 9 DEFINE_SPINLOCK(线路锁);10 11无符号长route_查找(无符号长addr)12 { 13 14 17 18 22 23 25 27 |
| 1introute_add(无符号长addr,无符号长接口)2{ 3 5 6 7 8 9 11 13 14 16 17静态空隙route_cb(结构体rcu_head *rhp)18 { 19 21 22 25 26 int route_del(无符号长addr)27 { 28 31 32 35 36 38 40 41 } |
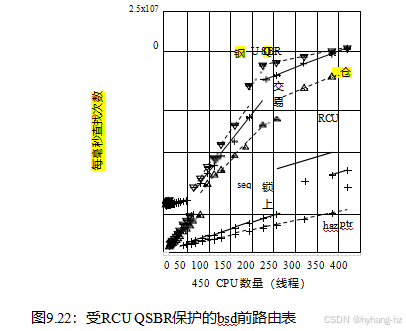
图9.21显示了在只读工作负载上的性能。RCU的规模相当好,并提供了近乎理想的性能。然而,这些数据是使用用户空间RCU的RCU_SIGNAL风格的[Des09b,MDJ13f]生成的,为此rcu_read_锁定()和rcu_read_unlock()生成少量的代码。RCU的QSBR味道会发生什么,它不会为rcu_read_lock()和rcu_read_unlock()生成任何代码?(关于RCU QSBR的讨论见Section9.5.1,特别是图9.8。)
这个问题的答案如图9.22所示,这表明RCU QSBR的运行性能和可伸缩性实际上超过了理想的无同步工作负载。

尽管Pre-BSD路由是一个很好的RCU用例,但值得看看图9.23中所示的更广泛的用例之间的关系。此任务将由以下各部分执行。
在阅读这些部分时,请询问自己其中哪一个用例最能描述bsd前路由。
如第9.5.2节所述,RCU的一个重要组件是等待RCU阅读器完成的一种方式。RCU的一个伟大的力量是,它允许你等待成千上万的不同的事情完成而无需显式跟踪每一个,而不导致性能退化,可伸缩性限制,复杂的死锁场景,和内存泄漏危险固有的方案使用显式跟踪。
在本节中,我们将展示同步_sched()的读端对应项(包括任何禁用抢占的东西,以及硬件操作和禁用中断的原语)如何允许您与不可屏蔽中断(NMI)处理程序交互,而使用锁定是相当困难的。这种方法被称为“纯RCU”[McK04],在Linux内核中的几个地方使用了它。
参数超出了定义范围。否则,第15行将增加由pcvalue参数索引的配置文件缓冲区条目。请注意,使用缓冲区存储大小可以保证范围检查与缓冲区相匹配,即使一个较大的缓冲区突然被一个较小的缓冲区所取代。
第18-27行定义了nmi_stop()函数,其中调用者负责互斥(例如,保持正确的锁)。第20行获取指向轮廓缓冲器的指针,如果没有缓冲器,则第22行和第23行退出该功能。否则,第24行NULL将退出配置文件缓冲区指针(使用rcu_assign_pointer()原语来维护在弱有序机器上的内存排序),第25行等待RCU缓冲宽限期过去,特别是等待代码的所有不可抢占区域,包括NMI处理程序,来完成。一旦在第26行继续执行,我们就可以保证任何获得指向旧缓冲区的指针的nmi_profile()实例都已经返回。因此,可以释放缓冲区,在这种情况下,使用kfree()原语是安全的。

简而言之,RCU可以方便地在配置文件缓冲区之间动态切换(您只需尝试通过原子操作有效地实现这一点,或者完全通过锁定!)。这是罕见的RCU的罕见使用。RCU通常用于更高的抽象级别,如下面的章节所示。
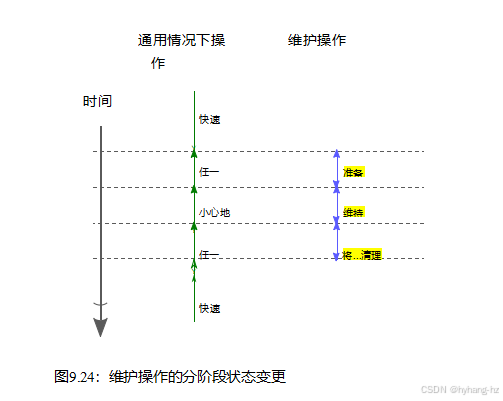
图9.24显示了一个有效处理维护操作的阶段状态更改的时间轴。如果没有正在进行的维护操作,常见情况操作必须快速进行,例如,不获取读写器锁。但是,如果正在进行维护操作,则必须仔细进行常见情况操作,并考虑到由于它们与维护操作同时运行而增加的复杂性。这意味着常见情况下的操作在维护操作期间会产生更高的开销,这也是维护操作通常计划在低负载期间进行的原因之一。
在图中,这些明显冲突的要求通过在维护操作之前有一个准备阶段和之后有一个清理阶段来解决,在此期间,常见情况操作可以快速或谨慎地进行。
此分阶段状态更改的伪代码示例如清单9.17所示。共情况操作由cco()在从第5行到第10行的RCU读侧临界段内执行。这里,第6行检查全局be_wecel标志,调用cco_carefully()或cco_quickly(),如所示。
这允许主()函数在第15行上设置be_ceal标志,并在第16行上等待RCU宽限期。当控制到达第17行时,所有看到be_cerel值的错误(因此可能调用cco_quickly()函数)的cco()函数都将完成它们的操作,因此所有当前执行的cco()函数都将调用cco_carefully()。这意味着要调用do_maint()函数是安全的。然后第18行等待可能与do_maint()并发运行的所有cco()函数完成,最后第19行将be_weel标志设置为false。
| 小心,2 3 void计算机控制中心(void)4 { 6 7 8 11 } 12 空隙管道(无效) 19 |

分阶段状态更改允许频繁操作使用轻量级检查,而不需要昂贵的锁获取或原子读-修改-写操作,并且在Linux内核中以rcu_sync [NZ13]的幌子使用,以实现具有轻量级读取器的读-写入器信号量的变体。分阶段状态更改只向等待完成的用例添加了一个已检查的状态变量(第9.5.4.2节),因此也处于相当低的抽象级别。
仅添加数据结构,以仅添加列表为例,可以用于一组令人惊讶的常见用例,也许最常见的是更改的日志记录。仅添加的数据结构是对RCU的底层发布/订阅机制的纯粹使用。
一个bsd前路由表的仅添加的变体可以从清单9.14和9.15中派生出来。因为没有删除,route_del()和route_cb()函数可以免除,连同->rh和->re_freed rothe_entry结构的字段,rcu_read_lock(),rcu_read_unlock()调用routhe_查找()函数,和所有使用->re_freed在所有剩余功能字段。
当然,如果route_add()函数有许多并发调用,那么在路由锁上就会有严重的争用,如果使用无锁技术,那么在路由列表上就会有严重的内存争用。避免这种争用的通常方法是使用并发友好的数据结构,如哈希表(参见第10章)。或者,每个cpu的数据结构可以定期合并到单个全局数据结构中。
另一方面,如果没有任何删除,具有许多route_add()并发调用的延长时间段最终将消耗所有可用内存。因此,大多数受RCU保护的数据结构也实现了删除。
许多无锁算法并不要求给定的数据元素通过给定的RCU读端关键部分引用它来保持相同的标识——但只有在该数据元素保留相同类型的情况下。换句话说,这些无锁算法可以容忍在给定的数据元素引用它时被释放并重新分配为相同类型的结构,但必须禁止类型上的更改。这种保证在学术文献[GC96]中被称为“类型安全内存”,它比第9.5.4.6节中讨论的存在保证要弱,因此相当难处理。Linux内核中的类型安全内存算法使用板缓存,特别是用SLAB_TYPESAFE_BY_RCU标记这些缓存,以便在返回释放的板到系统内存时使用RCU。RCU的使用保证了在任何已存在的RCU读取侧关键部分期间,该板的任何正在使用的元素都将保留在该板中,从而保留其类型。


需要注意的是,SLAB_TYPESAFE_BY_RCU绝对不会阻止kmem_ cache_alloc()立即重新分配刚刚通过kmem_cache_free()释放的内存!事实上,rcu_dereference()刚刚返回的受SLAB_TYPESAFE_BY_RCU保护的数据结构可能会被释放并进行任意大量的重新分配,即使是在rcu_read_lock()的保护下。相反,SLAB_TYPESAFE_BY_RCU的操作方法是防止kmem_cache_free()将一个完全释放的数据结构板返回给系统,直到一个RCU宽限期过去之后。简而言之,尽管给定的RCU读侧临界部分可能会看到给定的SLAB_TYPESAFE_BY_RCU数据元素被任意地释放和重新分配,但元素的类型保证在该临界部分完成之前不会更改。
因此,这些算法通常使用一个验证步骤,通过检查以确保新引用的数据结构确实是被请求的数据结构[LS86,第2.5节]。这些验证检查要求数据结构的某些部分不受自由重新分配过程的影响。这样的验证检查通常很难正确进行,并且可以隐藏微妙和困难的错误。
因此,尽管基于类型安全的无锁算法在极少数困难的情况下可能非常有用,但您应该在可能的情况下使用存在性保证。毕竟,更简单的事情几乎总是更好的事情!另一方面,基于类型安全的无锁算法可以提供改进的缓存局部性,从而提高性能。这种改进的缓存局部性是由于这样的算法可以立即重新分配一个新释放的内存块。相比之下,基于存在保证的算法必须等待所有已存在的读取器才能重新分配内存,此时内存可能已经从CPU缓存中弹出。
从图9.23中可以看到,RCU的类型-安全内存用例结合了等待完成和发布-订阅组件,但是在Linux内核中还包含了由SLAB_TYPESAFE_BY_RCU标志指定的板分配器的延迟回收。
9.5.4.6存在保证
Gamsa等人[GKAS99]讨论了存在保证,并描述了如何使用类似于RCU的机制来提供这些存在保证(见PDF第7页的第5节),第7.4节讨论了如何通过锁定来保证存在,以及这样做的后续缺点。其效果是,如果在RCU读侧临界段中访问了任何受RCU保护的数据元素,则该数据元素保证在该RCU读侧临界段期间仍然存在。
清单9.18演示了基于RCU的存在保证如何通过一个从哈希表中删除元素的函数来启用每个元素的锁定。第6行计算一个哈希函数,第7行进入一个RCU读侧临界部分。如果第9行发现哈希表的对应桶为空,或者存在的元素不是我们希望删除的元素,那么第10行退出RCU读侧临界部分,第11行表示失败。

否则,第13行获得更新侧自旋锁,然后第14行检查该元素是否仍然是我们想要的元素。如果是这样,第15行离开RCU读侧临界部分,第16行将其从表中移除,第17行释放锁,第18行等待所有预先存在的RCU读侧临界部分完成,第19行释放新移除的元素,第20行表示成功。如果元素不再是我们想要的元素,第22行释放锁,第23行离开RCU读侧临界部分,第24行表示未能删除指定的键。

警报阅读器将认识到这只是对原始等待完成主题(第9.5.4.2节)的轻微变化,添加发布/订阅、链接结构、堆分配器(通常)和延迟回收,如图9.23所示。他们还可能注意到比第7.4节中讨论的基于锁的存在保证具有死锁豁免的优势。
人们第一次了解RCU的感叹是“RCU有点像垃圾收集器!”这个感叹号有很大的真实性,但也可能是误导。
也许考虑RCU和自动垃圾收集器(GC)之间关系的最好方法是RCU类似于GC,因为收集的时间是自动确定的,但是RCU与GC的不同之处在于: (1)程序员
必须手动指示给定的数据结构何时有资格被收集,并且(2)程序员必须手动标记可能保存引用的RCU读侧关键部分。
尽管有这些差异,但相似之处确实很深。事实上,我所知道的第一个类似于RCU的机制使用基于引用计数的垃圾收集器来处理宽限期[KL80],RCU和垃圾收集之间的联系最近被注意到[SWS16]。
轻量级的垃圾收集器用例与保证存在的用例非常相似,只向混合算法中添加所需的非阻塞算法。这个轻量级的垃圾收集器用例也可以与下一节中描述的存在性保证一起使用。
仅删除列表是9.5.4.4节中介绍的仅添加列表,可以认为是存在保证用例,但没有发布/订阅组件,如图9.23所示。当初始化时知道列表中的可能成员,并且可以删除成员时,可以使用仅删除列表。例如,列表中的元素可能表示系统中的硬件元素,但如果不重新启动就无法修复或替换。
一个bsd前路由表的仅删除变体可以从清单9.14和9.15中派生出来。因为没有添加,所以可以取消route_add()函数,或者,它的使用可能被限制为初始化时间。理论上,route_查找()函数可以使用非RCU迭代器,尽管在Linux内核中,这将导致来自调试代码的投诉。此外,一个RCU迭代器的增量成本通常可以忽略不计。
因此,仅进行删除的情况通常使用为添加和删除而设计的算法和数据结构。
也许Linux内核中最常用的RCU是在读密集型情况下替代读写器锁定。然而,从一开始,我并没有立即看到RCU的使用。事实上,早在20世纪90年代早期实现通用RCU实现之前,我就选择了一个轻量级读写器锁[HW92]17。我所设想的轻量级读写器锁的每一个使用都是使用RCU实现的。事实上,轻量级的阅读器-写入器锁在三年多后才首次被使用。天啊,我觉得傻了!
RCU和读写器锁定之间的关键相似之处在于,两者都有可以同时执行的读侧关键部分。事实上,在某些情况下,可以机械地将RCU API成员替换为相应的读写器锁定API成员。但首先,为什么要麻烦呢?
RCU的优点包括性能、死锁豁免权和实时延迟。当然,RCU也有局限性,包括读取器和更新器同时运行,低优先级RCU读取器可以阻止等待宽限期过去的高优先级线程,宽限期延迟可以延长许多毫秒。下面的段落将讨论这些优点和限制。
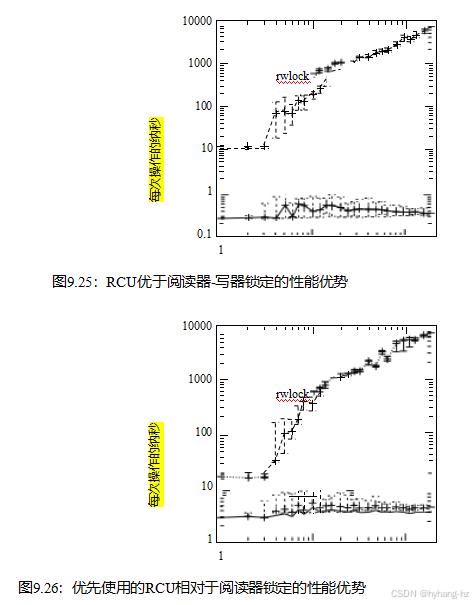
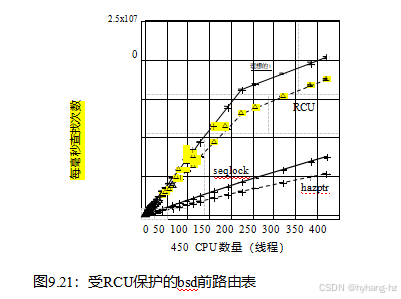
linux内核RCU相对于读写器锁定的读端性能优势如图9.25所示,它是在一个448-CPU 2.10 GHz Intel x86系统上生成的。

请注意,在单个CPU上,读写器锁定比RCU慢一个数量级以上,而在192个CPU上,RCU锁定比RCU慢四个数量级以上。相比之下,RCU的规模相当好。在这两种情况下,误差条覆盖了30次运行的全部测量范围,其中线是中位数。
更温和的视图可以从CONFIG_PREEMPT内核,尽管RCU仍然击败阅读器锁定之间的七倍一个CPU和192个CPU的三个数量级,如图9.26所示,这是生成在相同的448-CPU 2.10 GHz x86系统。请注意,在大量cpu上的读写器锁定的高可变性。误差条跨越了整个数据范围。
![]()
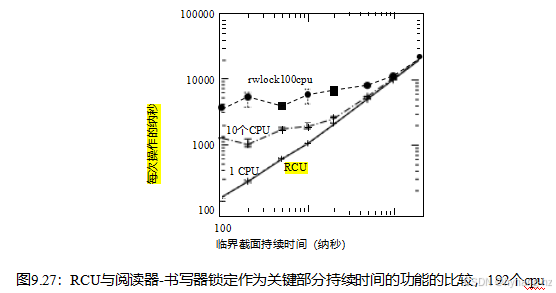
当然,图9.25和9.26中的读取器-写器锁定的低性能被不现实的零长度临界部分夸大了。RCU的性能优势随着临界截面开销的增加而降低,如Figure9.27所示,它在与之前的图相同的系统上运行。这里,y轴表示读取侧原语的开销和临界区开销的和,x轴表示临界区开销,以纳秒为单位。但请注意对数尺度y轴,这意味着轨迹之间的小间隔仍然代表着显著的差异。这个图显示了不可抢占的RCU,但是考虑到可抢占的RCU的读取端开销只有大约3纳秒,它的图将与图9.27几乎相同。
![]()
读写器锁定有三个跟踪,上面的跟踪是100个CPU,下一个跟踪是10个CPU,最低的跟踪是1个CPU。cpu的数量越多,临界段越短,RCU的性能优势就越大。100-CPU系统不再罕见,而且许多系统调用(因此它们包含的任何RCU读取端关键部分)在微秒内完成,这一事实强调了这些性能优势。
此外,正如下一段所讨论的,RCU读侧原语几乎完全没有死锁。
僵局免疫尽管RCU提供了显著的性能优势——主要是工作负载,这是创建RCU的主要原因之一
事实上是它对读侧僵局的免疫力。这种豁免源于这样一个事实,即RCU读侧原语不阻塞、旋转甚至不向后分支,因此它们的执行时间是确定性的。因此,它们不可能参与一个死锁循环。
![]()
RCU的读侧死锁豁免的一个有趣的结果是,可以无条件地将RCU读取器升级到RCU更新器。尝试使用读写器锁定进行这样的升级会导致死锁。下面是执行RCU读到更新升级的示例代码片段:
| rcu_read_lock() ; list_for_each_entry_rcu(p,&head,list_field){使用(p); 如果(需要更新(p)) { spin_lock(我的锁); do_更新(p); spin_解锁(&my_lock); } } rcu_read_unlock() ; |
注意,do_udate()是在锁保护和RCU读侧保护下执行的。
RCU的死锁豁免的另一个有趣的结果是它对大量优先级倒置问题的豁免。例如,低优先级RCU读取器不能阻止高优先级RCU更新程序获取更新侧锁。类似地,低优先级的RCU更新器不能阻止高优先级的RCU阅读器进入RCU读取端关键部分。

实时延迟因为RCU读侧原语既不旋转也不阻塞,所以它们提供了极好的实时延迟。此外,如前所述,这意味着它们不受涉及RCU读取侧原语和锁的优先级反转的影响。
然而,RCU很容易受到更微妙的优先级反转场景的影响,例如,等待RCU宽限期过去的高优先级进程可以被-rt内核中的低优先级RCU读取器阻止。这可以通过使用RCU优先级提升来解决[McK07d,GMTW08]。
然而,使用RCU优先级提升要求rcu_read_unlock()进行降提升,这需要获取调度器锁。因此,在调度器和RCU中需要进行一些注意,以避免死锁,而在v5.15的Linux内核中,RCU需要避免在持有任何RCU的锁时调用调度器。
这反过来又意味着,当启用了RCU优先级提升时,rcu_read_unlock()并不总是无锁的。然而,如果rcu_read_unlock()的关键部分没有得到优先级提升,它仍然是无锁的。此外,关键部分将不会被优先级提升,除非它们被优先化,或者,在-rt内核中,它们获得非原始的自旋锁。这意味着从在任何给定CPU上运行的最高优先级任务的角度来看,rcu_read_unlock()通常将是无锁的。
RCU读取器和更新器同时运行,因为RCU阅读器从不旋转或阻塞,而且因为更新器不受任何形式的回滚或中止语义,RCU阅读器和更新器确实可以同时运行。这意味着RCU读取器可能访问陈旧的数据,甚至可能看到不一致,其中任何一个都可以使从读写器锁定到RCU的转换非常重要。
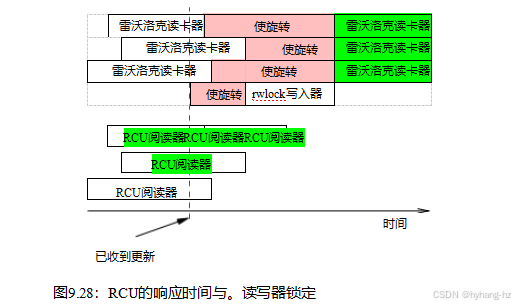
然而,在非常大量的情况下,不一致和陈旧的数据并不是问题。最典型的例子是网络路由表。因为路由更新可能需要相当长的时间才能到达给定的系统(几秒甚至几分钟),所以当更新到达时,系统将以错误的方式发送数据包。继续以错误的方式发送更新并持续几毫秒通常不是问题。此外,由于RCU更新器可以在不等待RCU阅读器完成的情况下进行更改,RCU阅读器可能比批公平阅读-写入锁定阅读器更快地看到变化,如图9.28所示。
![]()
一旦收到更新,rwlock写入器在最后一个读取器完成之前不能继续,后续的读取器在写入器完成之前不能继续。但是,这些后续的读者可以保证看到新的值,如最右边的方框的绿色阴影所示。相比之下,RCU阅读器和更新者不会相互阻止,这使得RCU阅读器可以更快地看到更新后的值。当然,因为它们的执行与RCU更新器重叠,所有的RCU阅读器都很可能看到更新的值,包括在更新前开始的三个阅读器。然而,只有最右边的绿色阴影的RCU阅读器才能保证看到更新后的值。
读写器锁定和RCU只是提供了不同的保证。通过读写锁定,任何在作者开始后开始的读者都保证看到新的值,而任何在作者旋转时试图开始的读者可能会看到也可能不会看到新的值,这取决于rwlock实现的读者/作者偏好。相比之下,使用RCU,任何在更新器完成后开始的读取器都保证会看到新值,而任何在更新器开始后完成的读取器可能会看到也可能不会看到新值,这取决于时间。
这里的关键是,尽管读写器锁定确实保证一致性在计算机系统的范围,在某些情况下,这种一致性的代价增加与外部世界,由有限的光速度和非零大小的原子。换句话说,读-写器锁定以对外部世界的陈旧数据为代价获得内部一致性。
注意,如果在读取读写器锁定时计算一个值,然后在该锁释放后使用该值,那么这个读写器锁定用例使用的是陈旧的数据。毕竟,这个值所基于的数量在该锁被释放后的任何时候都可能发生变化。这种阅读器-写入器锁定的用例通常很容易转换为RCU,如列表9.19,9.20、9.21以及附带的文本所示。
低优先级RCU读取器可以在实时RCU [GMTW08]或SRCU [McK06]中阻止高优先级回收器,抢占读取器将阻止一个宽限期完成,即使一个高优先级任务被阻止等待该宽限期完成。实时RCU可以通过用call_rcu()代替synchronize_rcu()或使用RCU优先级提升[McK07d,GMTW08]来避免这个问题。也许有一天有必要通过提高优先级来增强SRCU和RCU任务跟踪,但在一个明确的现实世界需求被证明之前。

RCU宽限期延长了许多毫秒,除了用户空间RCU [Des09b,MDJ13f],加速宽限期,以及附录B中描述的几个“玩具”RCU实现,RCU宽限期延长了毫秒。尽管有许多技术可以使如此长的延迟无害,包括使用异步接口(call_rcu()和call_rcu_bh())或轮询接口(get_state_synchronize_rcu()、start_poll_synchronize_rcu()和poll_state_synchronize_rcu()),但这种情况是RCU在读取主要情况下使用的主要原因。
如第9.5.3节所述,在Linux内核中,可以通过加速宽限期获得更短的宽限期,例如,通过调用synchronize_rcu_加速()而不是synchronize_rcu()。加快的宽限期可以将延迟减少到几十微秒,尽管以牺牲更高的CPU利用率和IPIs为代价。添加的IPIs在某些实时工作负载中可能特别不受欢迎。
代码:读写器锁定vs。RCU在最好的情况下,从读写器锁定到RCU的转换非常简单,如列表9.19,9.20和9.21所示,所有这些都取自维基百科[MPA+06]。
然而,转换并不总是如此简单。这是因为清单9.21中的spin_lock()和synchronize_rcu()都不排除清单9.20中的读取器。首先,spin_lock()不会以任何方式与rcu_read_锁()和rcu_read_unlock()交互,因此不排除它们。其次,尽管write_lock()和synchronize_rcu()都在等待预先存在的读取器,但只有write_lock()才能阻止后续读取器的开始。18.因此,synchronize_rcu()
| 1 | 结构el { | 1 | 结构el { |
| 2 | 结构列表_headlp; | 2 | 结构列表_headlp; |
| 3 | 长键; | 3 | 长键; |
| 4 | spinlock_t互斥因子; | 4 | spinlock_t互斥因子; |
| 5 | int数据; | 5 | int数据; |
| 6 | /*其他数据字段*/ | 6 | /*其他数据字段*/ |
| 7 | }; | 7 | }; |
| 8 | DEFINE_RWLOCK(李斯特姆); | 8 | DEFINE_SPINLOCK(李斯特姆); |
| 9 | LIST_HEAD(头); | 9 | LIST_HEAD(头); |
| 1 | 输入搜索(长键,输入结果) | 1 | 输入搜索(长键,输入结果) |
| 2 | { | 2 | { |
| 3 | 结构el *p; | 3 | 结构el *p; |
| 4 | 4 | ||
| 5 | read_lock(&listmutex); | 5 | rcu_read_lock() ; |
| 6 | 每个输入列表(页和头,页) | { 6 | list_for_each_entry_rcu(p,和头,lp){ |
| 7 | 如果(p->键==键){ | 7 | 如果(p->键==键){ |
| 8 | *result = p->data; | 8 | *result = p->data; |
| 9 | 读取解锁(&listmutex); | 9 | rcu_read_unlock() ; |
| 10 | 返回1; | 10 | 返回1; |
| 11 | } | 11 | } |
| 12 | } | 12 | } |
| 13 | 读取解锁(&listmutex); | 13 | rcu_read_unlock() ; |
| 14 | 返回0; | 14 | 返回0; |
| 15 | } | 15 | } |
| 1 | int删除(长键) | 1 | int删除(长键) |
| 2 | { | 2 | { |
| 3 | 结构el *p; | 3 | 结构el *p; |
| 4 | 4 | ||
| 5 | 写_lock(&listmutex); | 5 | spin_lock(&listmutex); |
| 6 | 每个条目(p,&head, | lp) { 6 | 每个条目的列表(p,和头部,lp) { |
| 7 | 如果(p->键==键){ | 7 | 如果(p->键==键){ |
| 8 | list_del(&p->lp); | 8 | list_del_rcu(&p->lp); |
| 9 | write_解锁(&listmutex); | 9 10 | spin_uloke(&列表互斥);synchronize_rcu(); |
| 10 | kfree (p); | 11 | kfree (p); |
| 11 | 返回1; | 12 | 返回1; |
| 12 | } | 13 | } |
| 13 | } | 14 | } |
| 14 | write_解锁(&listmutex); | 15 | spin_解锁(&listmutex); |
| 15 | 返回0; | 16 | 返回0; |
| 16 | } | 17 | } |
不能排除读者。然而,许多使用读写器锁定的情况都可以转换为RCU。
用RCU替换阅读器-写入器锁定的更详细的案例可以在其他地方找到[Bro15a,Bro15b]。
语义学:读者作者锁定vs。RCU在上一节的扩展中,读取器-写器锁定语义可以粗略和非正式地总结为以下三个时间约束:
1.写端获取将等待任何读取持有者释放锁定。
2.写入器端获取等待任何写入保持器释放锁。
3.读端获取等待任何写保持器释放锁定。
RCU完全免除了约束#3,并削弱了其他两个如下:
1.编写者会先等待任何预先存在的读取持有器,然后再进入其更新的破坏性阶段(通常是释放内存)。
2.作者可以根据需要相互同步。
当然,正是这种削弱允许RCU实现获得优秀的性能和可伸缩性。它还允许RCU实现上述无条件的读到写升级,这在读写器锁定中非常吸引人,也非常容易出现死锁。使用RCU的代码可以以惊人的大量方式来弥补这种削弱,但最常见的是通过施加空间约束:
1.新的数据被放置在新分配的内存中。
2.旧数据将被释放,但仅需在:
(a)该数据已经被取消链接,以便以后的读者无法访问,而(b) A随后的RCU宽限期已经过去。
当然,对于一些读写锁定的用例,RCU削弱的语义是不合适的,但是Linux内核的经验表明,超过80%的读写锁实际上可以被RCU取代。例如,一个通用的读取器-写入器锁定用例在保持锁时计算一些值,然后在释放该锁后使用该值。这个用例会导致陈旧的数据,因此经常会适应RCU较弱的语义。
如图9.6和9.7所示的RCU单例数据结构说明了这种时间和空间约束的相互作用。该结构在清单9.22的第1-4行中定义,并包含两个整数字段,->a和->b(单例例.c)。该结构的当前实例由在第4行中定义的曲线配置指针引用。
当前结构的字段通过cur_a和cur_b参数传递回在第6-20行上定义的get_config()函数。这两个字段可能有点过时,但它们绝对必须相互一致。get_config()函数在RCU从第10行开始到第18行结束的临界部分中提供了这种一致性,这提供了所需的时间同步。第11行获取指向当前我的配置结构的指针。这个结构将被使用,无论任何并发的更改由于
| 1结构myconfig { 2 5 6intget_配置(int *cur_a,int *cur_b)7 { 8 12 |
| 1空白2{ 3 4 5 6 7 8 9 10 11 12 13 14 } | set_config(int cur_a,int cur_b) 结构我的配置*mcp; mcp=malloc(规模(*mcp));BUG_ON(!mcp); mcp->a = cur_a;mcp->b = cur_b; 如果(mcp){ } |
调用set_config()函数,从而提供所需的空间同步。如果第12行确定曲线配置指针为NULL,则第14行返回失败。否则,第16行和第17行复制出->a和->b字段,第19行返回成功。这些->a和->b字段来自相同的肌配置结构,而RCU读侧临界部分阻止了该结构被释放,从而保证了这两个字段彼此一致。
该结构由清单9.23中所示的set_config()函数进行了更新。第5-8行分配并初始化一个新的肌配置结构。第9行原子交换指针这个新结构的指针旧结构,同时也提供完整的内存顺序xchg()操作前后,从而提供所需的更新/阅读器空间同步和所需的更新/更新器同步。如果第10行确定指向旧结构的指针实际上是非NULL,则第11行等待宽限期(从而提供所需的阅读器/更新器时间同步),第12行释放旧结构,知道不再有仍然引用它的阅读器是安全的。
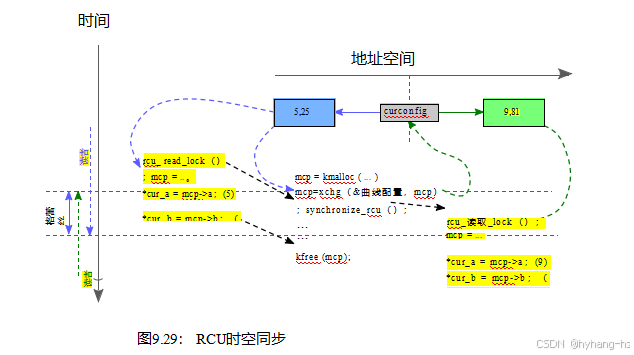
包含“5,25”),每个绿色虚线箭头表示与新结构的交互作用(在右边,包含“9,81”)。
黑色虚线箭头表示左右两侧的RCU阅读器之间的时间关系,中间是RCU宽限期,每个箭头指向从旧事件到新事件。对synchronize_rcu()的调用遵循最左边的rcu_read_lock(),因此该synchronize_rcu()调用必须在相应的rcu_read_unlock()之后才能返回。相反,对synchronize_rcu()的调用出现在最右边的rcu_read_lock()之前,这允许来自同一synchronize_rcu()的返回忽略相应的rcu_read_解锁()。这些时间关系阻止了我配置结构在RCU阅读器仍然访问它们时被释放。
这两条水平的灰色虚线表示不同的读者得到不同结果的时间段,然而,每个读者只会看到这两个对象中的一个。在第一条水平线之前结束的所有读取器都将看到最左边的我的配置结构,而在第二条水平线之后开始的所有读取器都将看到最右边的结构。在这两行之间,也就是说,在宽限期期间,不同的读者可能会看到不同的对象,但只要每个阅读器只加载曲线配置指针一次,每个阅读器将看到它的我的配置结构的一致视图。

简而言之,当在合适的链接数据结构上操作时,RCU结合时间和空间同步,以近似读-写器锁定,RCU读侧关键部分作为读-写器锁定读取器,如图9.23和9.29所示。RCU的时间同步由读取侧标记提供,例如rcu_read_lock()和rcu_read_unlock(),以及更新侧宽限期原语,例如synchronize_rcu()或call_ rcu()。空间同步由读端rcu_dereference()族提供,每个族都订阅rcu_assign_发布的版本
pointer().19 RCU的时间和空间同步组合与第6.3.2,6.3.3节和第7.1.4节中提出的方案形成了对比,其中时间和空间同步分别通过锁定和静态数据结构布局分别提供。

因为在RCU读侧关键部分正在进行时,不允许完成宽限期,所以RCU读侧原语可以用作一种受限制的引用计数机制。例如,请考虑以下代码片段:

rcu_read_lock()和rcu_dereference()原语的组合可以被认为是获得了对p的引用,因为在rcu_dereference()分配给p之后开始的宽限期不可能在我们达到匹配的rcu_read_unlock()之后结束。这种参考计数方案受到了限制
禁止在RCU读侧临界部分内等待RCU宽限期,也禁止将RCU读侧临界部分的引用从一个任务传递到另一个任务。
不管这些限制如何,以下代码都可以安全地删除p:
| spin_lock(&mylock);p=头; rcu_assign_pointer(头,空);spin_olook(&mylock); /*等待释放所有引用。*/ synchronize_rcu() ; kfree (p); |
对head的分配防止未来对p的任何引用被获取,synchronize_rcu()等待以前获得的任何引用被释放。

当然,RCU也可以与传统的参考计数结合起来,如第13.2节所述。
但为什么要费心呢?同样,部分答案是性能,如图9.30和9.31所示,再次显示了448-CPU 2.1 GHz Intel x86系统中不可抢占和可抢占的linux内核RCU的数据。与参考计数相比,不可抢占的RCU的优势范围从一个CPU的超过一个数量级到192个CPU的大约四个数量级。可抢占的RCU的优势范围从一个CPU的3倍到192个CPU的3个数量级。
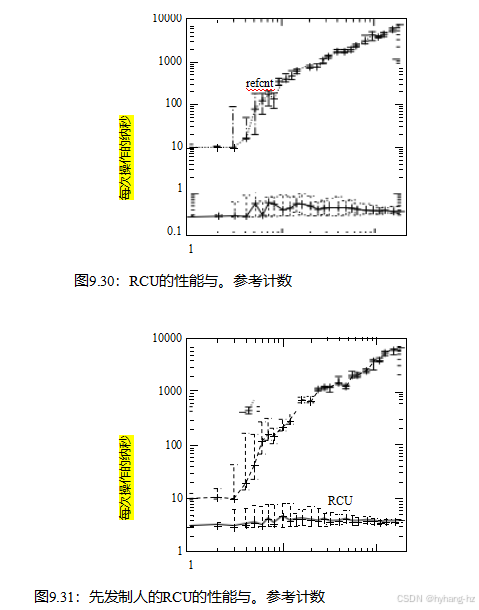

然而,与读写器锁定一样,RCU的性能优势在短时间临界部分和大量cpu中最为显著,如图9.32所示。此外,与读写器锁定一样,许多系统调用(因此它们包含的任何RCU读侧关键部分)都在几微秒内完成。
虽然传统的引用计数器通常与特定的数据结构或特定的数据结构组相关联,但这种方法确实有一些缺点。例如,为各种数据结构维护单个全局引用计数器通常会导致弹跳包含引用计数的缓存行。正如我们在图9.30–9.32中看到的,这种缓存线跳跃会严重降低性能。
相比之下,RCU的轻量级rcu_read_lock()、rcu_dereference()和rcu_read_ulockey()读侧原语允许非常频繁的读侧使用,而性能下降可以忽略不计。除了对rcu_dereference()的调用并没有做任何特定的操作来获取对指向对象的引用。繁重的工作是由rcu_read_lock()和rcu_read_unlock()原语以及它们与RCU宽限期的交互来完成的。
忽略这些对rcu_dereference()的调用允许RCU被认为是一种“批量引用计数”机制,其中每个对rcu_read_lock()的调用都获得对每个受RCU保护的对象的引用,并且很少或没有开销。然而,RCU附带的限制可能会相当繁重。例如,在许多情况下,linux内核禁止在RCU读侧关键部分中睡觉将会破坏整个目的。第9.3节中描述的危险指针机制可以更好地满足这种情况。在代码很少休眠的情况下,通过使用RCU在普通非休眠情况下作为引用计数,并在需要休眠时桥接到显式引用计数器来处理。
或者,如果引用必须由一个代码部分的单个任务持有,则可能包含睡眠RCU(SRCU)[McK06]。这并不能涵盖引用从一个任务“传递”到另一个任务的罕见情况,例如,当启动I/O时获取引用并在相应的完成中断处理程序中释放时。同样,通过显式引用计数器或危险指针可以更好地处理这种情况。
当然,SRCU本身也带来了一些限制,即将srcu_read_lock()的返回值传递到相应的srcu_read_unlock()中,并且不会从硬件中断处理程序或不可屏蔽中断(NMI)处理程序中调用SRCU原语。关于这一限制提出了多少问题,以及如何最好地
处理它,目前尚没有定论。
然而,在引用保存在单个CPU或任务范围内的常见情况下,RCU可以用作高性能和高度可伸缩的引用计数机制。
如图9.23所示,准引用计数将RCU读取器作为单独或批量引用计数添加,也可能在角落情况下连接到引用计数器。
RCU也可以被认为是一种具有弱一致性标准的简化的多版本并发控制(MVCC)机制。第9.5.2.3节涉及了多版本的方面。但是,在其本机形式中,RCU只在给定的受RCU保护的数据元素中提供版本一致性。
然而,在某些情况下,跨多个数据元素需要一致性和新的数据。幸运的是,有许多方法可以避免不一致和陈旧的数据,包括以下内容:
1.将RCU读取器封闭在序列锁定读取器中,如果发生更新,将强制重试RCU读取器,如Section13.4.2and Section13.4.3中所述。
2.将必须一致的数据放到链接数据结构的单个元素中,并避免在RCU阅读器可见的任何元素中更新这些字段。RCU的读者获得对任何此类元素的参考,然后保证看到一致的值。其他详细信息见第13.5.4节。
3.使用每个元素锁来保护“删除”标志,允许RCU阅读器拒绝过时的数据[McK04,ACMS03]。
4.提供一个存在标志,所有数据元素引用的更新[McK14d、McK14a、McK15b、McK16b、McK16a]。
5.使用多种基于计数器的方法之一[McK08a、McK10、MW11、McK14b、MSFM15、KMK+19]。在这些方法中,更新者维护一个版本号,并维护到给定数据片段的旧版本的链接。读者可以获取当前版本号的快照,并在必要时遍历这些链接以找到与该快照一致的版本。
简而言之,当使用RCU来近似多版本并发控制时,您只为实际需要的一致性级别付费。
如Figure9.23所示,准多版本并发控制是基于存在保证,添加读侧快照操作和对读取器和写器的约束,约束的确切形式由一致性要求决定,如上所述。
在其核心,RCU只不过是一个API:
1.一种用于添加新数据的发布-订阅机制,
2.一种等待已存在的RCU阅读器完成的方式,以及
3.一种维护多个版本以允许更改在不伤害或过度延迟的情况下的并发RCU阅读器的原则。
也就是说,可以在RCU之上构建更高层次的结构,包括前面几节中描述的各种用例。此外,我毫不怀疑,对于RCU以及任何其他一些同步原例,还将继续找到新的用例。因此,RCU的用例在概念上比RCU本身更为复杂,正如在第201页中所暗示的那样。
同时,图9.33显示了RCU最有用的一些粗略的经验法则。
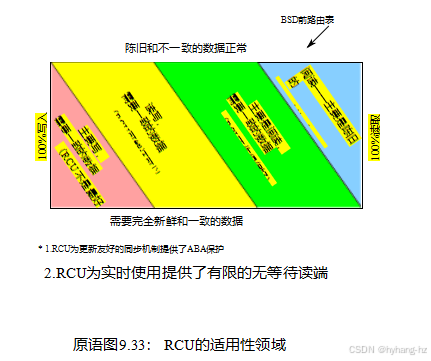
如图右上角的蓝色框所示,如果您读取了数据,RCU的工作效果最好——主要是允许陈旧和不一致的数据的数据(但关于陈旧和不一致数据的更多信息)。Linux内核中的典型示例是路由表。因为路由更新可能需要好几秒钟甚至几分钟才能在互联网上传播,所以系统一直在以错误的方式发送数据包。在几毫秒内继续以错误的方式发送其中一些信息的小可能性几乎从来都不是问题。
如果您有一个需要一致数据的工作负载,RCU工作良好,如绿色的“读主要需要一致数据”框所示。本例中的一个例子是Linux内核从用户级System-V信号量id到相应的内核内数据结构的映射。信号量的使用频率远远超过它们被创建和销毁的频率,所以这个映射主要是读取的。但是,对已经被删除的信号量执行信号量操作将是错误的。这种对一致性的需求是通过使用内核内信号量数据结构中的锁,以及在删除信号量时设置的“已删除”标志来处理的。如果用户ID映射到带有“删除”标记集的内核数据结构,则数据结构被忽略,因此用户ID被标记为无效。
虽然这要求读取器为代表信号量本身的数据结构获得一个锁,但它允许他们免除对映射数据结构的锁定。因此,阅读器锁定地遍历用于从ID映射到数据结构的树,这反过来大大提高了性能、可伸缩性和实时响应。
正如黄色的“读写”框所示,RCU对于需要一致数据的读写工作负载也很有用,尽管通常与许多其他同步原语一起使用。例如,最近的Linux内核中的目录项缓存将RCU与序列锁、每个cpu锁和每个数据结构锁一起使用,以在常见情况下允许无锁遍历路径名。尽管RCU在这种读写情况下非常有益,但相应的代码通常比读取的代码在大多数情况下更复杂。
最后,如图左下角的红色方框所示,更新——主要是需要一致数据的工作负载很少是使用RCU的好地方,尽管也有一些例外[DMS+ 12]。例如,如第9.5.4.5节所述,在内部
在Linux内核中,SLAB_TYPESAFE_BY_RCU板分配器标志为RCU阅读器提供了类型安全的内存,这可以大大简化非阻塞同步和其他无锁算法。此外,如果罕见的读取器在实时系统上的关键代码路径上,为这些读取器使用RCU可能会提供实时响应的好处,超过弥补增加的更新端开销,如14.3.6.5节中讨论的。
简而言之,RCU是一个API,它包括一个用于添加新数据的发布-订阅机制,一种等待现有的RCU阅读器完成的方式,以及一个维护多个版本的原则,以允许更新以避免伤害或过度延迟并发的RCU阅读器。这个RCU API最适合读取-大多数情况,特别是当应用程序可以容忍陈旧和不一致的数据时。
已知的第一次提到类似RCU的东西是来自唐纳德·克努斯[Knu73,基本算法的第413页]的错误报告,反对约瑟夫·魏森鲍姆的滑移列表处理设施[魏63]。Knuth报告这个漏洞是正当的,因为SLIP没有任何形式的宽限期保证。
第一个已知的关于任何类似RCU的非漏洞报告出现在Kung和雷曼的里程碑式论文[KL80]中。在学术界有一些额外的应用[ML82,ML84,Lis88,Pug90和91,PAB+95,CAK+96,RSB+97,GKAS99],但该领域的大部分工作是由从业者[RTY+ 87,HOS89,Jac93,Joh95,SM95,SM97,SM98,MS98a]。

到2000年,该倡议已经传递给开源项目,最著名的是Linux内核社区[Rus00a,Rus00b,MS01,MAK+01,MSA+02,ACMS03].20 RCU在2002年底被接受到Linux内核中,随后有许多在可伸缩性、健壮性、实时响应、能源效率和专门用例方面的改进。截至2023年,linux内核RCU仍在积极开发中。
![]()
然而,在2010年代中期,许多社区和机构的RCU研发出现了一个可喜的热潮[Kaa15]。第9.5.5.1节描述了RCU的使用,第9.5.5.2describes节的RCU实现(以及创建和使用实现的工作),最后,第9.5.5.3节描述了RCU及其使用的验证和验证。
9.5.5.1 RCU使用
波特兰州立大学(PSU)的菲尔·霍华德和乔恩·沃波尔已经将RCU应用于红黑树[How12,HW11],并结合使用软件事务内存同步的更新。乔什·特里普利特和乔恩·沃波尔(同样是PSU的成员)将RCU应用于可调整大小的哈希表[Tri12、TMW11、Cor14c、Cor14d]。其他受RCU保护的可调整大小的散列表是由赫伯特·徐[徐10]和马修·德斯诺埃尔斯[MDJ13c]创建的。
麻省理工学院的奥斯汀·克莱门茨、弗兰斯·卡肖克和尼科莱·泽尔多维奇创建了一个RCU优化的平衡二叉树(盆景)[CKZ12],并将此树应用到Linux内核的虚拟机子系统中,以减少Linux内核的mmap_sem上的读端争用。这项工作导致了数量级的加速和可扩展性,至少可以达到80个cpu。这与PeterZijlstra[之前的14]开发的补丁类似,但两者都受到了限制,因为当时,文件系统数据结构对RCU阅读器并不安全。Clents等人通过优化匿名页面的页面故障路径,避免了这一限制。最近,文件系统数据结构已经安全RCU读者(Cor10,Cor11],所以也许这个工作可以实现所有页面类型,不只是匿名页面——彼得·齐吉尔斯特拉,事实上,最近原型,和劳伦特米福尔莱斯皮纳斯继续沿着这些线工作。马修·威尔科克斯和利亚姆·豪莱特正在努力使用RCU,以实现对其他内存管理数据结构的细粒度锁定和无锁访问。
麻省理工学院的延东·毛和罗伯特·莫里斯以及哈佛大学的埃迪·科勒创造了另一种RCU保护树马斯特特里[MKM12],它结合了B+树和尝试的想法。尽管这个树比受RCU保护的哈希表慢约2.5倍,但与哈希表不同,它支持对键范围的操作。此外,Masstree支持具有长共享密钥前缀的对象的高效存储,此外,通过日志记录到大量存储提供持久性。
该论文指出,马斯特里的性能与缓存相当,即使马斯特里持续存储更新,而缓存却没有。本文还将Masstree的性能与持久数据存储MongoDB、VoltDB和Redis进行了比较,报告了Masstree具有显著的性能优势,在某些情况下超过两个数量级。另一篇论文[TZK+ 13],由屠史蒂芬、郑文汀、芭芭拉·利斯科夫、麻省理工学院和科勒的塞缪尔·马登撰写,将马斯特里应用于一个名为Silo的内存数据库,在一个著名的交易处理基准上,实现了每秒700K笔交易(每分钟4200万笔交易)。有趣的是,筒仓保证了线性化性,而不会在保持锁时产生宽限期的开销。
玛雅·阿贝尔和哈吉特·阿蒂亚采取了更严格的方法[AA14]到RCU保护的搜索树,像马斯特里一样,允许并发更新。本文包括了一个正确的证明,包括证明这棵树上的所有操作都是线性化的。不幸的是,该实现通过在保持锁时引起宽限期等待的全部延迟来实现线性化性,这降低了仅进行更新的工作负载的可伸缩性。解决这个问题的一种方法是放弃线性化[HKLP12,McK14d],然而,Arbel和Attiya创建了一个RCU变体,以减少低端宽限期延迟。当然,没有什么是免费的,而且这个RCU变体似乎达到了大约32个cpu的可伸缩性限制。尽管对于降低线性化性,从而获得性能和可伸缩性还有许多可扩展性要说,但看到学者们试验替代RCU实现是非常好的。
蒂莫西·哈里斯创建了一个基于时间的用户空间RCU [Har01],它对雅各布森[Jac93]和Joh95]之前创建的RCU进行了改进。之前的两种基于时间的方法都假设读者持续时间有一个明显的上限,这可以在硬实时系统中正确工作。在非实时系统中,这种类型的方法
当读者被中断、抢占或以其他延迟时,容易失败。然而,这种容易失败的实现将被独立发明两次,这一事实表明了对类似RCU的机制的需求的深度。Timothy Harris对之前的两个努力进行了改进,要求每个读者在开始读侧遍历之前对全局时间基进行快照。然后推迟释放读取器可见对象,直到所有进程的读取器快照表明删除该对象之后的时间。然而,全局时间基础在某些系统上可能是昂贵且不准确的。
Keir Fraser创建了一个名为EBR的用户空间RCU,用于
非阻塞同步计时和软件事务性内存[Fra03,Fra04,FH07]。这项工作改进了蒂莫西·哈里斯的工作,用一个软件计数器取代了全球时钟,从而消除了大部分的费用和与当时的商品系统全球时钟相关的所有不准确性。有趣的是,这项工作一方面引用了Linux内核RCU,但同时也启发了最初的不可优先考虑的Linux内核RCU实现的QSBR这个名称。
马修·德斯诺耶斯创建了一个用户空间RCU,用于跟踪[Des09b、Des09a、DMS+ 12、MDJ13f、MDJ13c、MDJ13b、MDJ13d、MDJ13e、MDJ13h、MDJT13b、MDJ13g、MDJ13a、MDJT13a],已在许多项目中使用[BD13]。
布拉格查尔斯大学的研究人员也一直在致力于RCU的实现,包括安德烈·波齐米克[Pod10]和亚当·哈拉斯卡[Hra13]的论文。
刘玉洁(利哈伊大学)、维克多卢昌科(甲骨文实验室)和迈克尔斯皮尔(也叫利哈伊)按下可扩展非零指标(SNZI)[ELLLM07]作为宽限期机制。预期的用途是实现软件事务性内存(见第17.2节),它施加了线性化的要求,这反过来似乎限制了可伸缩性。
类似于RCU的机制也在寻找进入Java的方法。[SZJ12]使用类似RCU的机制来消除与Java的垃圾收集器交互时需要的读取障碍,从而导致显著的性能改进。
上海交通大学的刘润、张恒和陈海波研究了一种特殊的RCU,他们用于优化的“被动阅读-作者锁”[LZC14],类似于高萨姆·谢诺伊[她06]和斯里瓦萨·巴特[Bha14]创建的RCU。Liu等人的论文从一些专家方面都很有趣[McK14g]。
Mike Ash发布了一篇对苹果目标c运行时中类似RCU的原语的描述。这种方法通过指定的代码范围来识别读侧关键部分,从而成为实现零读侧开销的另一种方法,尽管这种方法给跨多个函数的大型读侧关键部分带来了一些有趣的实际挑战。
佩德罗·拉马尔赫特和安德烈亚·科雷亚[RC15]制作了《穷人的RCU》,尽管使用了一对读者-作者锁,但它设法为读者提供了无锁的前进保证[MP15a]。
玛雅·Ar贝尔和亚当·莫里森[AM15]制作了“谓词RCU”,它努力减少宽限期时间,以有效地支持在宽限期保持更新侧锁的算法。这导致减少了更新到宽限期的批处理,并减少了可伸缩性,但确实成功地提供了较短的宽限期。
![]()
亚历山大·马特维耶夫(麻省理工学院)、尼尔·沙维特(麻省理工学院和特拉维夫大学)、帕斯卡·费尔伯(纳沙泰尔大学)和帕特里克·马里耶(也是纳沙泰尔大学)[MSFM15]产生了一种类似RCU的机制,可以被认为是明确标记只读事务的软件事务内存。它们的用例需要在不同的宽限期内保持锁,这限制了可伸缩性[MP15a,MP15b]。这似乎是第一个充分利用RCU酷刑测试套件的与RCU相关的学术工作,也是第一个向linux内核RCU提交性能改进的工作,它被v4.4所接受。
亚历山大·马特维耶夫的RLU随后由Jaeho Kim等人的MV-RLU跟进[KMK+ 19]。这项工作通过允许多个并发更新,避免跨宽限期保持锁,以及使用渐同步宽限期,例如call_rcu()而不是synchronize_rcu(),提高了RLU的可扩展性。本文还做出了一些有趣的性能评估选择,并在第594页的第17.2.3.3节中进一步讨论。
Adam Belay等人创建了一个RCU实现,该实现保护其IX操作系统中TCP/IP的地址解析协议(ARP)使用的数据结构[BPP+ 16]。
迪米特里奥斯西亚等应用HTM和RCU搜索树[SNGK17,SBN+ 20],克里斯蒂娜等使用HTM和RCU颜色图[GGK18],和在公园等使用HTM和RCU优化NUMA系统上的高竞争锁定。
Alex Kogan等人将RCU应用于可伸缩地址空间的范围锁定[KDI20]。
9.5.5.3 RCU验证
在2017年初,人们普遍认为几乎任何bug都是一个潜在的安全漏洞,因此验证和验证是首要的问题。
石溪大学的研究人员已经生产了一个具有RCU感知功能的数据竞赛探测器[Dug10,Sey12,SRK+ 11]。IMDEA的阿列克谢·戈特斯曼、特拉维夫大学的诺姆·里内茨基和牛津大学的杨宏修克发表了一篇论文[GRY12],用分离逻辑表达了RCU的形式语义,并继续使用并发性的其他方面。
约瑟夫·塔萨罗蒂(卡内基-梅隆大学)、德里克·德雷尔(马克斯·普朗克软件系统研究所)和维克多·瓦菲亚迪斯(也叫MPI-SWS)[TDV15]制作了一个手动正式证明用户空间RCU的静止状态回收(QSBR)变体的正确性[Des09b,DMS+ 12]。梁(牛津大学)、保罗·麦肯尼(IBM)、丹尼尔·克罗宁和汤姆·梅勒姆(都包括牛津)[LMKM16]使用C有界模型检查器(CBMC)[CKL04]生成了Linux核树RCU相当一部分的正确性的机械证明。Lance Roy [Roy17]使用CBMC为大量linux内核可睡眠RCU(SRCU)提供了类似的正确性证明[McK06]。最后,米卡利斯和康斯坦丁诺斯·萨格纳斯(雅典国立技术大学)[KS17a,KS19]使用Nighugg工具[LSLK14]对Linux核树RCU的正确性进行了机械证明。
除了注入到RCU中专门用于测试验证工具的bug之外,这些工作都没有找到任何bug。相比之下,亚历克斯·格罗斯(俄勒冈州立大学)、伊夫特哈尔·艾哈迈德、卡洛斯·延森(两人都是俄亥俄州立大学)和保罗·e·麦肯尼(IBM)[GAJM15]
| 财产 | 参考计数 | 危险指针 | 序列锁定 | RCU |
|
|
|
|
|
|
| 内存开销 | 每个对象的计数器 | 每个指针 每个对象的读取器 | 无保护 | 没有一个 |
| 保护持续时间 | 可以是长 | 可以是长 | 无保护 | 用户必须绑定持续时间 |
| 需要遍历重试 | 如果对象已删除 | 如果对象已删除 | 如果有任何更新 | 从不 |
| 自动突变linux内核RCU的源代码,以测试rcu酷刑测试套件的覆盖范围。这项工作在这个套件的覆盖范围中发现了几个漏洞,其中一个是在Tiny RCU中隐藏了一个真正的漏洞(已经修复)。 如果幸运的话,所有这些验证工作最终将产生更多更好的并发代码验证工具。 总是选择看起来最好的方式,不管它多么粗糙;习惯很快就会使它变得容易和愉快。 | ||||





毕达哥拉斯
第9.6.1provides节是高级概述,第9.6.2provides节是本章中介绍的延迟处理技术之间的差异。本讨论假设一个链接的数据结构足够大,因此读者不会保存从一个遍历到另一个遍历的引用,并且可以在任何位置和任何时间添加和从结构中删除元素。第9.6.3节然后指出了一些危险指针、序列锁定和RCU的生产用途。这个讨论应该可以帮助您在这些技术之间做出明智的选择。
表9.7显示了一些区分延迟回收技术的高级属性。
“阅读器”行总结了图9.22中所示的结果,它显示了除了引用计数外,所有的结果都享有相当快速和可伸缩的阅读器。
“内存开销”行评估每种技术对存储阅读器保护的外部存储的需求。RCU依赖于静止状态,因此不需要存储来表示阅读器,无论是在对象的内部还是外部。引用计数可以在结构中的每个对象中使用一个整数,并且不需要额外的存储空间。危险指针需要提供外部到对象的指针,并且每个CPU或线程都有足够的指针来跟踪在任何给定时间被引用的所有对象。考虑到大多数基于危险指针的遍历只需要少数的危险指针,这在实践中通常不是一个问题。当然,

“保护持续时间”描述了用户可以保护给定对象的一段时间内的约束(如果有的话)。引用计数和危险指针都可以保护对象延长时间,不会产生副作用,但是保持对一个对象的RCU引用可以防止所有其他RCU被释放。因此,RCU读取器必须相对较短,以避免系统的内存不足,SRCU、Tasks RCU和Trace RCU等特殊目的实现是此规则的例外。同样,序列锁不提供指针遍历保护,这就是为什么它通常用于静态数据。
“需要遍历重试”行告诉对给定对象的新引用是否会无条件获得,就像使用RCU一样,或者引用获取是否会失败,导致重试操作,这是引用计数、危险指针和序列锁的情况。在引用计数和危险指针的情况下,只有在删除给定对象时试图获取对该对象的引用时,才需要重试,下一节将详细介绍这个主题。当然,如果它与任何更新同时运行,序列锁定必须重试其关键部分。

当然,不同的行在不同的情况下会有不同的重要性级别。例如,如果您当前的代码存在危险指针的读侧可伸缩性问题,那么危险指针可能需要重试引用获取并不重要,因为您当前的代码已经处理了这个问题。类似地,如果响应时间考虑已经限制了读取器遍历的持续时间,就像在内核和底层应用程序中经常发生的那样,那么RCU有持续时间限制要求并不重要,因为您的代码已经满足了它们。同样地,如果读者必须已经写入了他们正在遍历的对象,那么引用计数器的读取侧开销可能就不那么重要了。当然,如果要保护的数据是在静态分配的变量中,那么序列锁定无法保护指针就无关紧要了。
最后,基于延迟动态采样在危险指针和RCU之间的动态切换工作[BGHZ16]。这将将危险指针和RCU之间的选择推迟到运行时,并将决策的责任委托给软件。
然而,当在这些技术之间进行选择时,这个表应该有很大的帮助。但是那些希望有更多细节的人应该继续讲到下一节。
表9.8提供了更详细的经验法则,可以帮助您在本章中介绍的四种延迟处理技术中进行选择。
如“存在保证”行所示,如果需要对链接数据元素的存在保证,则必须使用引用计数、风险指针或RCU。序列锁不提供存在保证,而是提供更新检测,重试任何遇到更新的读侧关键部分。
| 财产 | 参考计数 | 危险指针 | 序列锁定 | RCU |
|
|
|
|
|
|
| 更新和阅读器同时取得进展 | 是 | 是 | 不 | 是 |
| 读者之间的争论 | 高 | 没有一个 | 没有一个 | 没有一个 |
| 每个关键部分的读者们的开销 | N/A | N/A | 二 smp_mb() | 范围从无到两个smp_mb() |
| 每个对象的读取器遍历开销 | 读修改-写原子操作、内存障碍指令和缓存 小姐 | smp_mb()* | 没有,但不安全 | 无(易失性访问) |
| 读者前进进度保证 | 无锁 | 无锁 | 阻塞 | 无限制等待 |
| 阅读器参考获取 | 可能失败(条件) | 可能失败 有前提的 | 不安全 | 不能失败 无条件的 |
| 内存足迹 | 有界的 | 有界的 | 有界的 | 无界的 |
| 复垦前进进度 | 无锁 | 无锁 | N/A | 阻塞 |
| 自动回收 | 是 | 用例 | N/A | 用例 |
| 代码行 | 94 | 79 | 79 | 73 |





*这个smp_mb()可以通过使用linux内核成员屏障()系统调用将其降级为编译器屏障()。
当然,正如“更新和读取器并发进展”行所示,这种更新检测意味着序列锁定不允许更新器和读取器同时进行向前进展。毕竟,阻止这种前进的进程是首先使用序列锁定的全部要点!这种情况指出了将序列锁定与参考计数、危险指针或RCU结合使用的方法,以提供存在性保证和更新检测。实际上,Linux内核在路径名查找期间以这种方式结合了RCU和序列锁定。
“读者之间的争论”、“读者每评论部分开销”和“读者每对象遍历开销”行粗略了这些技术的阅读侧开销。引用计数的开销可能相当大,阅读器之间存在争议,并且对所遍历的每个对象都需要一个完全有序的读-修改-写原子操作。危险指针会为遍历的每个数据元素和序列锁产生内存障碍的开销

“阅读器前进保证”行显示,只有RCU有一个有限的无等待前进保证,这意味着它可以通过执行有限数量的指令来执行有限的遍历。
“阅读器参考获取”行表示只有RCU能够无条件地获取参考。序列锁的条目是“不安全的”,因为,同样,序列锁检测更新,而不是获取引用。如果给定的获取失败,引用计数和危险指针都要求从一开始就重新启动遍历。要查看这一点,请考虑一个按该顺序包含对象a、B、C和D的链表,以及以下一系列事件:
1.阅读器获得对对象B的引用。
2.更新器删除对象B,但避免释放它,因为阅读器持有一个引用。该列表现在包含对象A、C和D,并且对象B的->的下一个指针被设置为HAZPTR_POISON。
3.更新程序删除对象C,以便列表现在包含对象A和d。因为没有对对象C的引用,所以它立即被释放。
4.读取器试图在现在已被删除的对象B之后前进到对象的后继者,但是中毒的>下一个指针阻止了这一点。这是一件好事,因为对象B的->下一个指针会指向自由职业者。
5.因此,读者必须从列表的头部重新启动其遍历。
因此,当无法获取引用时,危险指针或引用计数器遍历必须从一开始就重新启动该遍历。在嵌套的链接数据结构的情况下,例如,一个包含链接列表的树,必须从最外层的数据结构重新启动遍历。这种情况使RCU具有显著的易用性优势。
然而,RCU的易用性优势并不是免费提供的,这可以在“内存足迹”行中看到。RCU对无条件引用获取的支持意味着它必须避免释放给定的RCU阅读器可访问的任何对象,直到该读取器完成。因此,RCU具有无限制的内存占用,至少除非更新被限制。相反,引用计数和风险指针只需要保留并发读取器实际引用的那些数据元素。
内存占用和获取失败之间的这种紧张关系有时在Linux内核中通过结合使用RCU和引用计数器来解决。RCU用于短命引用,这意味着RCU读侧临界部分可以很短。这些较短的RCU读取侧临界部分反过来意味着相应的RCU宽限期也可以很短,这限制了内存占用。对于需要更长寿命引用的少数数据元素,将使用引用计数。这意味着参考获取失败的复杂性只需要处理这些少数数据元素:大部分参考获取是无条件的,由RCU提供。有关将引用计数与其他同步机制相结合的更多信息,请参见第13.2节。
“回收前进进度”行显示,危险指针可以提供非阻塞的更新[Mic04a,HLM02]。引用计数可能会,也可能不会,这取决于实现。然而,序列锁定不能提供非阻塞的更新,因为它的更新侧锁。RCU更新者必须等待阅读器,这也排除了完全非阻塞的更新。然而,也有一些情况下
唯一的阻塞操作是等待释放内存,这导致的情况,在许多目的上,与非阻塞一样好[DMS+ 12]。
如“自动回收”行所示,只有引用计数才能自动释放内存,即使只有非循环数据结构。危险指针和RCU的某些用例可以使用链接计数提供自动回收,这可以被认为是参考计数,但仅适用于来自数据结构的其他部分的传入链接[Mic18]。
最后,“代码行”行显示了在bsd之前的路由表实现的大小,给出了一个相对易用性的粗略概念。也就是说,需要注意的是要注意,引用计数和序列锁定实现是有问题的,而且正确的引用计数实现要复杂得多[Val95,MS95]。就其本身而言,一个正确的序列锁定实现需要添加一些其他的同步机制,例如,危险指针或RCU,以便序列锁定检测并发更新,而其他机制提供了安全的引用获取。
随着使用这些技术获得更多的经验,无论是单独的还是在组合中,本节中提出的经验规则将需要细化。然而,这节确实反映了当前的技术水平。
本节指出了一些对危险指针、序列锁定和RCU的公开可见的生产用途。参考文献计数被省略了,不是因为它不重要,而是因为它不仅被广泛使用,而且在半个世纪前的教科书中有大量的文献记载。列出这些其他技术的生产用途的人们希望得到的好处之一是提供例子来研究,或者发现错误,视情况而定。21
9.6.3.1生产使用危险指针
2010年,基思·博斯蒂克增加了一个危险指针。2015年发布的MongoDB 3.0包含了“连线老虎”,因此也包含了危险指针。
2011年,Samy Al Bahra向并发工具包库添加了危险指针[Bah11b]。
2014年,马克西姆·基津斯基增加了危险指针。
2015年,David Gwynne向OpenBSD [Gwy15]引入了共享参考指针,一种危险指针的形式。
2017-2018年,铁锈语言弧交换[Van18]和conc[切割17]箱推出了自己的危险指针实现。
2018年,法师迈克尔向脸书的愚蠢图书馆[Mic18]添加了危险指针,在那里它被大量使用。
9.6.3.2生产中使用的序列锁定
Linux内核在2003年为v2.5.60添加了序列锁定[Cor03],这是通过x86实现每日()系统调用中使用的一种特殊技术来实现的。
2011年,Samy Al Bahra在并发工具包库中增加了序列锁定[Bah11c]。
保罗·邦齐尼在2013年在QEMU模拟器中添加了一个简单的序列锁定[Bon13]。
Alexis Menard在2016年在铬中抽象了一个序列锁实现[Men16]。
2018年,在宝石()中添加了一个简单的序列锁定实现[Gol18a]。特征库还有一个特殊目的的队列,由类似于序列锁定的机制管理。
9.6.3.3生产使用的RCU
IBM的VM/XA采用了被动序列化机制,这类似于20世纪80年代的RCU[HOS89]。
DYNIX/ptx于1993年采用了RCU[MS98a,SM95]。
Linux内核采用了迪潘卡尔Sarma的RCUin 2002的实现[Tor02]。用户空间RCU项目始于2009年[Des09b]。
Knot DNS项目从2010年开始使用用户空间RCU库[Slo10]。同年,OSv内核增加了一个RCU实现[Kiv13],后来又添加了一个受RCU保护的链接列表[Kiv14b]和一个受RCU保护的哈希表[Kiv14a]。
2011年,Samy Al Bahra在并发工具包库[Bah11a]中添加了epochs(RCU的一种形式[Fra04,FH07])。
NetBSD在2012年开始使用上述的v6.0的被动序列化[The12a]。除此之外,在NetBSD数据包过滤器(NPF)中使用了被动序列化[Ras14]。
2015年,Paolo Bonzini在2015年通过用户空间RCU库的友好分叉为QEMU模拟器添加了RCU支持[BD13,Bon15]。
2015年,马克西姆·基津斯基将RCU加入利比亚银行[Khi15]。
我们在2016年实现了libqsbr,即基于QSBRand时代的回收(EBR)[Ras16],这两种方法都是RCU的实现类型。
Sheth等人[SWS16]演示了利用Go的垃圾收集器提供类似RCU的功能的价值,并且Go编程语言提供了可以提供此功能的值类型。22
马特·克莱因描述了一种用于特使代理的RCU类机制[Kle17]。
2018年,本田在数据平面开发工具包(DPDK)中增加了一个RCU库[Nag18]。
Stjepan Glavina将基于时代的RCU实现合并到锈语言[Gla18]的并发支持“板条箱”中。
杰森·多南菲尔德制作了一个RCU实现,作为他的连线端口到窗口NT内核的一部分[Don21]。
最后,任何被垃圾收集的并发语言(而不仅仅是Go!)以零增量成本获得RCU实现的更新部分。
也许当序列锁定、危险指针和RCU都像引用计数器一样被广泛使用和众所周知的时候就会到来。在此之前,这些机制的生产使用应该有助于指导机制的选择
以及展示如何最好地应用它们中的每一个。这样,我们就揭开了在第201页提出的最后一个谜团。
下一节将讨论更新,这是本章中描述的许多阅读机制的一个棘手的问题。
生活中唯一的东西就是改变。
弗朗索瓦·德拉罗切福科德
本章中提到的延迟处理技术最直接适用于阅读——主要是一些情况,这就引出了这样一个问题:“但是更新怎么办呢?”毕竟,提高读者的性能和可伸缩性是很好的,但很自然地也想要良好的性能和可伸缩性。
我们已经看到了一种具有高性能和可伸缩性的情况,即第五章中调查的计数算法。这些算法以部分分区的数据结构为特色,因此更新可以在本地操作,而更昂贵的读取必须跨越整个数据结构。塞拉斯·博伊德-维克希泽已经将这个概念推广到生成OpLog,他已经将其应用于linux内核路径名查找、VM反向映射和stat()系统调用[BW14]。
另一种方法被称为“干扰者”,是为处理大容量输入数据流的应用程序设计的。该方法是依赖于单生产者-单消费者的FIFO队列,从而最大限度地减少对同步的需要[Sut13]。对于Java应用程序,破坏器还具有最小化对垃圾收集器的使用的优点。
当然,在可行的情况下,完全分区或“共享”系统提供了优秀的性能和可伸缩性,如第6章所述。
下一章将介绍几种类型的数据结构的上下文中的更新。


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









