






简单如1、2、3!
未知的
计数或许是计算机最简单、最自然的功能。然而,在大型共享内存多处理器上高效且可扩展地进行计数却颇具挑战。此外,计数这一概念的简洁性使我们能够探索并发的基本问题,而无需受复杂数据结构或同步原语的干扰。因此,计数为并行编程提供了一个极好的入门。
本章介绍了一些具有简单、快速和可扩展计数算法的特殊案例。但是首先,让我们了解您对并发计数已经了解了多少。

5.1为什么并发计数不是简单的?
追求简单,但不要轻信。
怀德海
让我们从一些简单的事情开始,例如,清单5.1中所示的算术运算的直接使用 (count_ nonatomic .c)。这里,我们在第1行有一个计数器, 我们在第5行增加它, 我们在第10行读出了它的价值。 还有什么比这更简单呢?

这种方法还有一个额外的优点,如果你做了大量的阅读,几乎没有增量,它是快速的,而且在小型系统上,性能非常好。
只有一个大问题:这种方法可能会丢失计数。在我的六核x86笔记本电脑上,运行了invokedinc_count()285,824,000次,但最终计数器的值只有35,385,525。尽管近似计算在计算中确实有其重要性,但87 %的计数丢失还是有些过分了。

准确计数的直接方法是使用原子操作,如清单5.2所示(count_ atomic .c)。第1行 定义原子变量,第5行 原子级递增它,以及第10行 读出来。因为这是原子,所以它能保持完美的计数。
| 清单5.2:原子级计数! |
| 1atomic_t计数器=ATOMIC_INIT(0);2 3静态__inline__void inc_count(void)4{ 7 8静态__inline__ longread_coun t(void)9{ |
然而,它的速度较慢:在我的六核x86笔记本电脑上,它比非原子增量慢二十多倍,即使只有一个线程在增加。
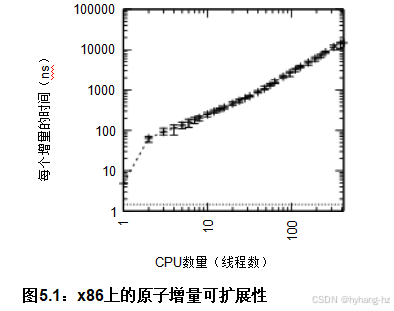
考虑到第3章中的讨论,这种糟糕的性能不应该令人惊讶,同样,随着CPU和线程数量的增加,原子增量的性能变慢也不应该令人惊讶,如图5.1所示。 在这个图中,位于x轴上的水平虚线代表了一个完全可扩展算法的理想性能:使用这样的算法,给定的增量将产生与单线程程序相同的开销。显然,对单个全局变量进行原子增量操作远非理想,而且随着额外CPU的增加,这种开销会成倍增长。

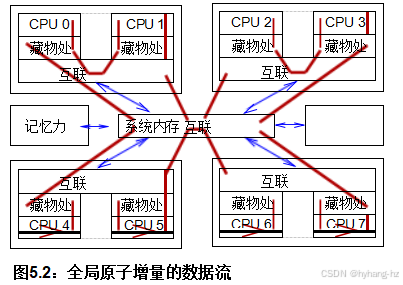
关于全球原子增量的另一个观点,可参考图5.2。 为了使每个CPU都有机会增加给定的全局变量,包含该变量的缓存行必须在所有CPU之间循环,如红色箭头所示。这种循环需要相当长的时间,导致图5.1中看到的性能较差。,可以认为如图5.3所示。 以下各节讨论了高性能计数,它避免了这种循环中固有的延迟。

马克·吐温
本节介绍统计计数器的常见特殊情况,即计数更新频率极高而读取值的频率极低。这些计数器将用于解决快速问答5.2中提出的网络包计数问题。
统计计数通常通过为每个线程(或在内核中运行时为每个CPU)提供一个计数器来处理,这样每个线程都会更新自己的计数器,这一点在第73页的4.3.6节中有所提及。通过简单地将所有线程的计数器相加,可以读取这些计数器的总值,这依赖于加法的交换性和结合性。这是将在第135页的6.3.4节中介绍的数据所有权模式的一个例子。

提供每个线程变量的一种方法是为每个线程指定一个元素的数组(假定缓存对齐并填充以避免错误共享)。
![]()
这样的数组可以被包装成每个线程的原始数据,如清单5.3所示(count_ stat .c)第1行 定义一个包含一组名为counter的、类型为unsigned long的线程计数器的数组。
第3行 – 8 展示一个函数,用于递增计数器,使用get_thread_ var()原语定位当前运行线程的计数器数组元素。由于该元素仅由相应线程修改,因此非原子递增就足够了。然而,这段代码usesWRITE_ONCE()防止破坏性
编译器优化。举个例子,编译器有权将要存储的位置用作临时存储,因此在实际存储之前,会将实际上相当于垃圾的数据写入该位置。这当然会让试图读取计数的人感到困惑。使用ofWRITE_ONCE()可以防止这种优化以及其他类似的优化。
第10行 – 18 展示一个函数,该函数使用for_ each_ thread()原语遍历当前运行的线程列表,并使用per_ thread()原语获取指定线程的计数器。此代码还使用READ_ONCE()以确保编译器不会将这些加载操作优化得毫无意义。例如,在两个连续调用read_ count()的情况下,可能会被内联,而一个谨慎的优化器可能会注意到相同的位置正在被累加,从而错误地认为只需一次累加并使用结果值两次就足够了。这种优化对于期望后续read_ count()调用考虑其他线程活动的人来说可能会相当令人沮丧。使用READ_ONCE()可以防止这种优化以及其他类型的优化。

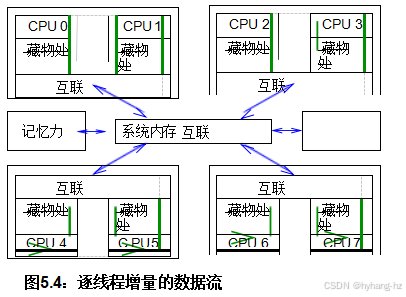
这种方法随着更新线程数量的增加而线性扩展invokinginc_count()。如图5.4中每个CPU上的绿色箭头所示,这样做的原因是,每个CPU都可以快速地增加其线程的变量,而无需进行昂贵的跨系统通信。因此,本节解决了本章开头提出的网络包计数问题。

但是,许多实现提供了更便宜的机制来处理线程数据,而且不受任意数组大小限制。这是下一节的主题。
Theinc_count()更新器使用的函数非常简单,如第6行所示 – 9 .
读取器使用的read_count()函数更为复杂。第16行 获取锁以排除退出的线程,以及第21行 释放它。第17行 将sum初始化为那些已经退出的线程累积的计数,并行18 – 20 汇总当前正在运行的线程累积的计数。最后,行22 返回总和。

第25行 – 32 显示count_ register_ thread()函数,每个线程在首次使用此计数器之前都必须调用此函数。此函数只是将该线程的counterp[]数组元素设置为指向其线程计数器变量。

第34行– 42 显示thecount_unregister_thread()函数,每个先前调用count_register_thread()的线程必须在退出前调用该函数。第38行 获取锁,并行41 释放它,从而排除任何调用toread_count()以及对count_unregister_ thread()的其他调用。第39行 将此线程的计数器添加到全局最终计数,然后行40 NULL会删除其counterp[]数组条目。随后调用read_count()将看到全局finalcount中退出线程的计数,并在遍历counterp[]数组时跳过退出线程,从而获得正确的总数。
这种方法几乎与非原子加法具有相同的性能,并且线性扩展。另一方面,并发读取争夺单一全局锁,因此性能低下,扩展极差。然而,对于统计计数器而言,这并不是问题,因为增量操作频繁而读取操作几乎不存在。当然,这种方法比基于数组的方案复杂得多,因为给定线程的每线程变量在该线程退出时会消失。

基于数组和基于Thread_local的方法都提供了出色的更新侧性能和可伸缩性。然而,这些优点导致大量线程的读取侧开销较大。下一节将介绍一种方法,在保留更新侧可伸缩性的同时减少读取侧开销。
一种在大幅提高读取性能的同时保持更新侧可扩展性的方法是降低一致性要求。前一节中的计数算法保证返回一个值,该值介于理想计数器在执行read_count()开始时可能达到的值和结束时可能达到的值之间。
read_ count()的执行。最终一致性[ Vog09]提供了更弱的保证:在没有调用inc_ count()的情况下,调用read_ count()最终会返回一个准确的计数。
我们通过维护一个全局计数器来实现最终一致性。然而,更新器仅操作其每个线程的计数器。提供了一个单独的线程来将每个线程的计数器中的计数值传递给全局计数器。读取者只需访问全局计数器的值。如果更新器处于活跃状态,读取者使用的值将会过时,但一旦更新停止,全局计数器最终会收敛到真实值——因此这种方法可以称为最终一致。
实现如清单5.5所示 (count_ stat_ eventual .c)。第1行 – 2 显示跟踪计数器值的每个线程变量和全局变量,以及第3行 显示停止标志,用于协调终止(在以下情况下
我们希望用一个精确的计数器值来终止程序)。Theinc_count()函数显示在第5行 – 10 与清单5.3中的对应项类似。 第12行所示的read_ count()函数 – 15仅返回global_ count变量的值。
然而,count_ init()函数在第34行 – 44创建最终的()线程,如第17行所示 – 32,它会遍历所有线程,将每个线程的局部计数器相加,并将总和存储到global_count变量中。最终的()线程会在两次遍历之间等待任意选择的一毫秒。
第46行的count_cleanup()函数 – 51坐标终止。这里的调用tosmp_load_acquire()和eventual()中的调用smp_store_release()确保了所有对global_ count的更新都对call count_cleanup()之后的代码可见。
这种方法在支持线性计数器更新能力的同时,提供了极快的计数器读出速度。然而,这种出色的读侧性能和更新侧可扩展性是以额外运行最终()的线程为代价的。

快速测试5.26:鉴于清单5.5中所示的最终一致算法读取和更新操作的开销极低,且具有极高的可扩展性,为什么还要考虑第5.2.2节中描述的实现方式呢 考虑到其昂贵的读取端代码?

这三种实现表明,尽管运行在并行机器上,统计计数器仍有可能获得接近单程过程的性能。

根据本节介绍的内容,您现在应该能够回答本章开头关于网络统计计数器的快速测验了。
对正确问题的近似答案比对一个精确答案更有价值
近似问题。
约翰·图基
计数的另一个特殊情况是限位检查。例如,正如快速测试5.3中提到的近似结构分配限位问题 假设你需要维护一个计数,记录分配的结构数量,一旦使用中的结构数量超过某个限制,在这种情况下是10,000个。进一步假设这些结构是短暂的,这个限制很少被超出,而且这个限制是近似的,即有时超出这个限制是一个有限度,而有时未能达到这个限制也是一个有限度。参见第5.4节 如果你需要精确的限制。
一种可能的限制造计设计是将10,000的限制除以线程数量,然后给每个线程分配一个固定的结构池。例如,如果有100个线程,每个线程将管理自己的100个结构池。这种方法简单,在某些情况下效果很好,但无法处理常见的场景,即某个结构由一个线程分配而另一个线程释放[MS93]。一方面,如果某个线程负责释放任何结构,则执行大部分分配操作的线程会耗尽结构,而执行大部分释放操作的线程则会有大量无法使用的信用。另一方面,如果释放的结构被归功于分配它们的CPU,则需要CPU之间互相操作计数器,这将需要昂贵的原子指令或其他线程间通信的方式。
简而言之,对于许多重要的工作负载,我们无法完全划分计数器。鉴于分区计数器是第5.2节讨论的三种方案中带来优秀更新侧性能的原因 ,这可能是悲观的理由。然而,第5.2.4节中提出的最终一致算法 提供了一个有趣的提示。回想一下,该算法维护了两组书,一个用于更新器的每线程计数变量和一个用于读取器的全局计数变量,最终由一个()线程定期更新全局计数,以最终与每个线程的计数值保持一致。每个线程的计数完美地划分了计数值,而全局计数则保留了完整的值。
对于限幅计数器,我们可以使用这个主题的一个变体,其中我们部分地对计数器进行分区。例如,考虑四个线程,每个线程不仅有一个线程计数器,而且还有一个线程最大值(称为count ermax)。
但是,如果某个线程需要增加其计数器,但计数器等于最大值怎么办?这里的关键是将该线程计数值的一半移动到全局计数器,然后增加计数器。例如,如果某个线程的计数器和最大值变量都等于10,我们这样做:
3.为了平衡增加的分数,从这个线程的计数器中减去5。
4.释放全局锁。
5.增加此线程的计数器,结果为6。
尽管此过程仍需全局锁定,但每次五次增量操作只需获取一次锁,大大减少了该锁的竞争度。我们可以通过增加countermax的值来将这种竞争度降低到最低。然而,增加countermax值的相应代价是全局计数的准确性降低。要了解这一点,请注意,在四核系统中,如果countermax等于十,全局计数最多会出错40次。相比之下,如果countermax增加到100,全局计数可能会出错多达400次。
这引发了我们对全局计数与计数器总值偏差的关注,其中总值是全局计数和每个线程计数变量之和。这个问题的答案取决于总值与计数器上限(称为全局计数最大值)之间的差距。这两个值之间的差异越大,计数器最大值可以设置得越高而不超过全局计数最大值。这意味着可以根据这一差异来设置给定线程的计数器最大值。当远未达到上限时,线程的计数器最大值被设置为较大值以优化性能和可扩展性;而当接近上限时,这些变量则被设置为较小值,以减少对全局计数最大值检查时的误差。
此设计是并行快速路径的一个示例,这是一种重要的设计模式,在这种模式中,常见情况无需执行昂贵指令且线程之间没有交互,但偶尔也会使用一种更为保守设计(且开销更高)的全局算法。该设计模式在第6.4节中有更详细的介绍。
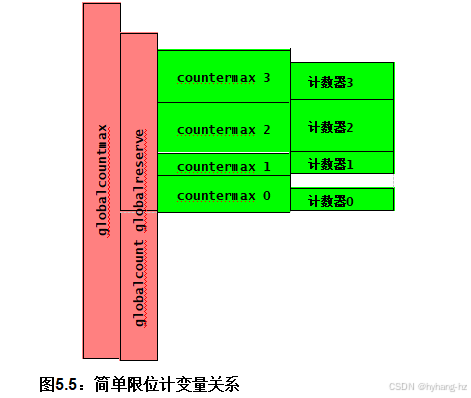
清单5.6 显示了此实现所使用的每个线程变量和全局变量。per-thread反计数器和countermax变量分别是相应线程的局部计数器及其上限。第3行中的全局countermax变量 包含聚合计数器的上限以及第4行上的全局计数变量 是全局计数器。全局计数器与每个线程的计数器之和给出了整体计数器的总值。第5行中的全局保留变量 至少是所有线程计数器变量的最大值之和。这些变量之间的关系如图5.5所示:
1.globalcount和globalreserve的总和必须小于或等于globalcountmax。
2.所有线程的countermax值之和必须小于或等于全局保留量。
3.每个线程的counter必须小于或等于该线程的countermax。
| 清单5.6:简单限位计变量 | |
| 1个未签名的长线程计数器=0; | |
| 3 | |
| 4 | |
| 5 | 未签名的长期全球储备=0; |
| 6 | 未签名的长* counterp[ NR_ THREADS] = { NULL }; |
| 7 | |
counter[]数组的每个元素都引用了相应线程的计数变量,最后,gblcnt_互斥锁spinlock保护所有全局变量,换句话说,除非线程已经获得了gblcnt_ mutex,否则任何线程都不允许访问或修改任何全局变量。
清单5.7 显示了add_ count()、sub_ count()和read_ count()函数(count_lim.c)。

第1行 – 18显示add_count(),它将指定的值delta添加到计数器中。行3 检查这个线程的计数器是否有空间给delta,如果有,就执行第4行 添加并行5 返回成功。这是add_ counter()fastpath,它不执行原子操作,仅引用每个线程变量,并且不应该发生任何缓存未命中。

如果第3行有测试失败时,我们必须访问全局变量,因此必须在第7行acquiregblcnt_mutex, 我们在第11行发布 在故障情况下或在线16 在成功案例中,第8行 调用全局变量globalize_ count(),如清单5.9所示,它清除了线程局部变量,并根据需要调整全局变量,从而简化了全局处理。(但不要只听我的,自己试着写一下吧!)
| 3 | 如果 | (counter+ delta<= countermax){ | |||
| 4 | 一次写入(计数器, | 柜台 | + | 希腊语字母表第四字母δ | |
| 5 | return1; | ||||
| 6 | } | ||||
第9行 和10 检查是否可以容纳delta的添加,表达式小于号前的意义如图5.5所示 为两个红色(最左边)条形的高度差。如果不能容纳delta的增加,则行11 (如上所述)发布gblcnt_mutex和第12行 返回值表示失败。
否则,我们走慢路。第14行 将delta加到globalcount中,然后行15 调用balance_ count()(如清单5.9所示 )用于更新全局变量和每个线程的变量。调用balance_count()通常会将thisthread的countermax设置为重新启用快速路径。第16行 然后释放gblcnt_mutex(如前所述),最后,第17行 返回表明成功。

第20行 – 36 显示sub_ count(),它从计数器中减去指定的delta。第22行 检查per-thread count er是否可以容纳这个减法,如果是,则行23 做减法和第24行 返回成功。这些行构成sub_count()的快速路径,和add_count()一样,此快速路径不执行任何代价操作。
如果快速路径不能容纳delta的减法,执行程序将在第26行进入慢路径 – 35 . 因为慢路径必须访问全局状态,行26acquiresgblcnt_mutex,由第29行释放 (如发生故障)或通过线路34 (如成功)。第27行 调用全局变量globalize_ count(),如清单5.9所示, 这再次清除了线程局部变量,根据需要调整全局变量。第28行 检查计数器是否可以容纳减去的delta,如果不是,则行29 发布gblcnt_mutex(如前面所述)和第30行返回失败。
另一方面,如果第28行 发现计数器可以容纳减法delta,我们完成了慢路径。第32行 减去33,然后划线 invokesbalance_count()(见清单5.9 )更新全局变量和每个线程的变量(希望重新启用快速路径)。然后第34行 发布gblcnt_mutex,第35行 返回成功。

第38行– 51showread_count(),返回计数器的总值。它acquiresgblcnt_mutex在第43行 并在第49行释放它 ,不包括add_ count()和sub_ count()中的全局操作,以及,正如我们将看到的,也不包括线程创建和退出。第44行 将局部变量sum初始化为globalcount的值,然后循环跨越第45行 – 48汇总每个线程的计数器变量。第50行 然后返回总和。
清单5.9 显示了add_ count()、sub_ count()和read_ count()这些在清单5.7中显示的primitives所使用的许多实用函数。
第1行 – 7 显示全局变量globalize_ count(),该函数将当前线程的每线程计数器清零,并适当调整全局变量。需要注意的是,此函数不会改变计数器的总值,而是改变计数器当前值的表示方式。第3行将线程的计数变量添加到全局计数器中,第4行 零位计数器。同样,第5行 从全局保留中减去每线程计数器max,行6 计数器最大值为零。参考图5.5很有帮助 在读取此函数和下一个的balance_ count()时。
第9行 – 19 显示balance_ count(),大致来说是globalize_count()的逆数。此函数的作用是将当前线程的countermax变量设置为最大值,以避免计数器超过全局最大限制。当然,更改当前线程的countermax变量需要相应调整counter、globalcount和globalreserve,这可以通过参考图5.5来了解。 通过这样做,balance_ count()最大化使用ofadd_count()的低优先级快速路径和sub_count()。由于withglobalize_count(),balance_ count()不被允许更改计数器的聚合值。
第11行 – 13 计算此线程对未被全局计数或全局保留覆盖的全局计数最大值部分的份额,并将计算出的数量分配给此线程的计数最大值。第14行 对全局储备进行相应的调整。第15行 将此线程的计数器设置为中间
从零到countermax的范围。第16行 检查全局计数器是否确实可以容纳这个计数器值,如果不是,则执行第17行 相应地减少计数器。最后,在任何情况下,行18 对全局计数进行相应的调整。

查看图5.6所示的示意图有助于了解counter之间的关系如何随着first globalize_ count()和then balance_ count()的执行而变化。 时间从左向右推进,最左边的配置大致如图5.5所示。 中心配置展示了线程0执行globalize_count()后这些相同计数器之间的关系。从图中可以看出,线程0的计数器(图中的“c 0”)被加到全局计数上,而全局保留量则相应减少。线程0的计数器及其最大值(图中的“cm 0”)都被减少到零。其他三个线程的计数器保持不变。请注意,这一变化并未影响计数器的整体值,这由连接最左侧和中心配置的最下方虚线表示。换句话说,在两种配置中,全局计数与四个线程计数变量之和是相同的。同样,这一变化也未影响全局计数与全局保留量之和,这由上方的虚线表示。
最右侧的配置展示了在线程0执行balance_ count()后,这些计数器之间的关系。剩余计数的四分之一,由从所有三个配置向上延伸的垂直线表示,被加到线程0的countermax中,再将其中的一半加到线程0的counter中。加到线程0的
为了防止改变计数器的总体值(它仍然是全局计数器和三个线程的总和,因此也会从全局计数器中减去计数器
| 清单5.10:近似限位计变量 |
| 1个未签名的长线程计数器=0; |
| 2个未签名的长线程计数器max=0; |
| 3个未签名的长全局计数器max=10000; |
| 4个未签名的长全局计数=0; |
| 5个未签名的长全局保留=0; |
| 6个未签名的长* counterp[ NR_线程]={NULL}; |
| 7DEFINE_SPINLOCK(gblcnt_mutex); |
| 8#defineMAX_COUNTERMAX 100 |
计数变量),再次由连接中心和最右侧配置的两条虚线中的下一条表示。全局保留变量也进行了调整,使其等于四个线程的计数最大值之和。由于线程0的计数小于其计数最大值,线程0可以再次局部增加计数。
 第21行 – 28 显示count_ register_ thread(),它为新创建的线程设置状态。此函数只是将指向新创建线程计数器变量的指针安装到counterp[]数组中相应条目的ofgblcnt_mutex保护下。
第21行 – 28 显示count_ register_ thread(),它为新创建的线程设置状态。此函数只是将指向新创建线程计数器变量的指针安装到counterp[]数组中相应条目的ofgblcnt_mutex保护下。
最后,第30行 – 38 显示count_ unregister_ thread(),它会为即将退出的线程删除状态。第34行 收购gblcnt_mutex和37号线 释放它。第35行 调用globalize_ count()清除此线程的计数状态,以及第36行 清除计数器counterp[]中此线程的条目。
这种计数器在聚合值接近零时非常快,但由于加法计数器和减法计数器的快速路径中存在比较和分支操作,会产生一些开销。然而,使用每个线程的计数器最大预留量意味着即使聚合值远未达到全局最大值,加法计数器也可能失败。同样地,即使聚合值远未接近零,减法计数器也可能失败。
在许多情况下,这是不可接受的。即使全局计数最大值旨在作为近似限制,通常也有一个具体的近似程度上限。一种限制近似程度的方法是为每个线程的计数最大值实例设置上限。这项任务将在下一节中进行。
因为这个实现(count_lim_app.c)与上一节的实现(清单5.6非常相似, 5.7 ,和5.9 ),这里只显示了更改。列表5.10 与清单5.6相同, 加上ofMAX_COUNTERMAX,它设置每个线程计数器变量max的最大允许值。
同样,列表5.11 与清单5.9中的balance_ count()函数相同, 加上第6行 和7, 这些变量对每个线程的计数器变量执行theMAX_COUNT ERMAX限制。
未知的
为了解决在快速测试5.4中提到的确切结构-分配限制问题, 我们需要一个能够准确判断其限制是否被超过的限制计数器。实现这种限制计数器的一种方法是让那些预留了计数的线程释放这些计数。一种实现方式是使用原子指令。当然,原子指令会减慢快速路径的速度,但另一方面,不尝试一下也是愚蠢的。
不幸的是,如果一个线程要安全地从另一个线程中移除计数,两个线程都需要原子操作对方线程的计数和最大计数变量。通常的做法是将这两个变量合并为一个变量,例如,给定一个32位变量,使用高16位表示计数,低16位表示最大计数。

简单原子限制计数器的变量和访问函数如清单5.12所示 (count_lim_at omic.c)。早期算法中的counter和countermax变量被合并到单个变量counterandmax中,如第1行所示, upper半部分为counter,lower半部分为countermax。此变量的类型为atomic_t,其底层表示为int。
第2行 – 6 显示globalcountmax、globalcount、globalreserve、counterp、andgblcnt_mu tex的定义,它们都扮演着rolemi-
与Li sting 5.10中的对应项比较。 第7行 definesCM_BITS,它给出了计数器和max的每个半部分的位数,以及第8行 定义MAX_COUNTERMA X,它给出计数器和max的任一半中可能持有的最大值。
![]()
第10行 – 15显示split_ counterandmax_ int()函数,当给定来自theatomic_t counter和max变量的基本int时,它将其拆分为counter (c)和countermax(cm)组件。第13行 隔离该int中最重要的半部分,将结果置于参数c指定的位置,并在第14行 隔离该整数的最不显著半部分,并将结果置于由参数cm指定的位置。
第17行 – 24 显示split_counter和max()函数,它们从第20行指定的变量中提取底层的int ,按照第22行的旧参数指定的方式存储它, 然后invokessplit_counterandmax_in t()在第23行将其拆分。

第26行 – 32 显示merge_counter和max()函数,可以将其视为逆ofsplit_counterandmax()。第30行 将通过c和cm分别传递的计数器和countermax值合并,并返回结果。

清单5.13 显示add_ count()和sub_ count()函数。
| 列表5.14:原子Limi t计数器读数 |
| 1未签名的long read_count(void)2{ 3 intc; 4 intcm; 5 intold; 6 intt; 7个未签名的长字节;8 11for_each_thread(t){ 12if(counter[t]!=NULL){ 13split_counterandmax(反[t,&old,&c,&cm); 16} 18返回总和;19} |
第1行 – 32显示add_count(),其快速路径跨越第8行– 15 ,其余的函数是慢路径。第8行 – 14快速路径形成比较和交换(CAS)循环,在第13行使用了atomic_ cmpxchg()原语 – 14 执行实际的CAS。第9行 将当前线程的counter和max变量拆分为它的counter
(在c)和countermax(在cm)组件中,同时将底层插入旧的。第10行 检查是否可以本地容纳量delta(注意避免整数溢出),如果不是,行11 转至slowpa th。否则,第12行 将更新后的计数器值与原始计数器最大值结合成新的值。atomic_cmpxchg()原语在第13行 – 14然后原子地将此线程的计数器和最大变量与old进行比较,如果比较成功,则将其值更新为new。如果比较成功,第15行 返回成功,否则,执行继续在第8行的循环中。

第16行 – 31见清单5.13 显示add_count()的慢路径,该路径由gblcnt_mutex保护,在线17获取 并在第24行发布 和30。 第18行 调用globalize_ count(),将此线程的状态移动到全局计数器中。第19行 – 20 检查delta值是否可以被当前的全局状态所容纳,如果不能,则行21 调用flush_ local_ count()将所有线程的本地状态刷新到全局计数器,然后行22 – 23重新检查是否可以容纳delta。如果在所有这些之后,仍然不能容纳delta的添加,则行24 发布gblcnt_mutex(如前面所述),然后行25返回s失败。
否则,第28行 将delta添加到全局计数器中,第29行 如果合适,sp读取计数到本地状态,第30行 释放gblcnt_互斥锁(如前面所述),最后,第31行 返回成功。
第34行 – 63 见清单5.13 显示子计数(),其结构与add_count()类似,在第41行有一个快速路径 – 48 在第49行加一个慢音 – 62 .对这个函数的逐行分析留给读者作为练习。
清单5.14 显示read_ count()。第9行 获取gblcnt_互斥锁和第17行 释放它。第10行 将局部变量sum初始化为globalcount的值,并且
跨越线路11的环 – 16 将每个线程计数器添加到此总和中,使用split_ counterandmax在第13行隔离每个线程计数器。 最后,第18行 返回总和。
清单5.15 和5.16 显示实用程序functionsglobalize_count(),flush_local_count(),balance_count(),count_register_thread(),andcount_unregister_thread()。globalize_count()的代码显示在第1行 – 12 见清单5.15 ,与之前的算法类似,增加了第7行, 现在需要将counter和countermax从counterandmax中分离出来。
flush_ local_ count()代码将所有线程的本地计数器状态移动到全局计数器,代码显示在第14行 – 32 .第22行 检查s,以查看globalreserve的值是否允许任何线程计数,如果不是,则请参阅第23行 返回。否则,第24行 将局部变量ze ro初始化为组合零计数器和countermax。循环跨越行25 – 31 通过每个线程的序列。第26行 检查ks,以查看当前线程是否具有计数状态,如果是,则行27 – 30将该状态移动到全局计数器。第27行 原子地获取当前线程的状态,同时将其替换为零。第28行 将此状态分为其计数器(在局部变量c中)和计数器最大值(在局部变量cm中)组件。第29行 将此线程的计数器添加到全局计数器,而行30 从globalreserve中减去此线程的countermax。
第1行 – 22 见清单5.16 显示balance_ count()的代码,该函数会重新填充调用线程的本地计数器和最大变量。此函数与前面的算法非常相似,但需要对合并后的计数器和最大变量进行处理。代码的详细分析留作读者练习,正如从第24行开始的count_register_thread()函数一样。 并且count_unregister_thread()函数从第33行开始。

下一节对这一设计进行了定性评价。
这是首次实现让计数器运行至任一极限的情况,但这样做是以在快速路径中添加原子操作为代价的,这在某些系统上会显著减慢快速路径的速度。尽管某些工作负载可能能够容忍这种减速,但寻找写侧性能更好的算法仍然是值得的。其中一种算法使用信号处理程序来窃取计数。
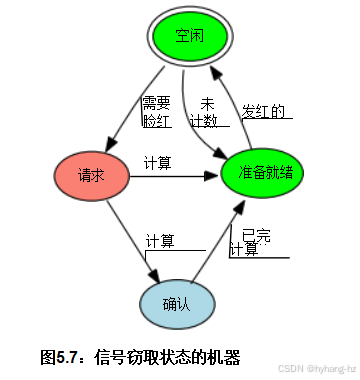

尽管现在每个线程的状态只由相应的线程来操纵,但仍需要与信号处理程序进行同步。这种同步是由图5.7所示的状态机提供的。
状态机初始处于空闲状态,whenadd_count()orsub_ count()发现本地线程的计数与全局计数的组合无法满足请求,相应的慢路径会将每个线程的偷盗状态设置为REQ(除非该线程没有计数,在这种情况下,它会直接进入就绪)。只有持有gblcnt_互斥锁的慢路径才被允许从空闲状态转换,这由绿色表示。4 慢路径随后向每个线程发送信号,相应的信号处理程序检查相应线程的偷窃和计数变量。如果偷窃状态不是REQ,则信号处理程序不允许改变状态,因此直接返回。否则,如果计数变量被设置,表明当前线程的快路径正在进行,信号处理程序将偷窃状态设置为AC K,否则设置为就绪。
如果偷窃状态为ACK,只有快速路径才被允许改变偷窃状态,如蓝色颜色所示。当快速路径完成时,它将偷窃状态设置为READY。
1#定义THEFT_ IDLE 0 2 #defineTHEFT_REQ 1 3#定义THEFT_ACK 2 4 #defineTHEFT_READY 3 5
8个未签名的长__线程计数器=0;
9个未签名的长__threadcountermax = 0;
10个未签名的长全局计数器max=10000;
11个未签名的长全局计数=0;
12个未签名的长全局保留字=0;
13个未签名的长* counterp[ NR_ THREADS] = { NULL};
14个未签名的长* countermaxp[ NR_ THREADS] = { NULL};
15 int * theftp[ NR_ THREADS] = { NULL };16 DEFINE_ SPINLOCK(gblcnt_ mutex);
17#defineMAX_COUNTERMAX 100

清单5.17 (count_ lim_ sig .c)显示了基于信号窃听的计数器实现所使用的数据结构。第1行 – 7定义前一节中描述的每个线程窃取状态机的状态和值。第8行 – 17 与早期实现类似,增加了行s 14 和15 允许远程访问线程的countermax和theft变量。
清单5.18 显示负责在每个线程变量和全局变量之间迁移计数的函数。第1行 – 7 显示globalize_ count(),与早期实现相同。第9行 – 16 show flush_local_count_sig(),这是在盗窃过程中使用的信号处理程序。行11 和12 检查是否为“REQ”状态,如果不是,则返回,不作任何更改。第13行 将盗窃状态设置为ACK,如果第14行 看到此线程的快速路径未运行,第15行 usessmp_store_release()将盗窃状态设置为“就绪”,进一步确保快速路径中的任何计数器更改都发生在此“盗窃”状态变为“就绪”之前。

第18行 – 47 显示flush_ local_ count(),该函数从slowpath调用以清空所有线程的本地计数。循环跨越第2和3行 – 32 为每个具有本地计数的线程推进偷窃状态,并向该线程发送信号。第24行 跳过任何不存在的线程。否则,第25行 检查当前线程是否持有任何本地计数,如果没有,则行26 将线程的偷盗状态设置为READY,行27 跳到下一个线程。否则,第29行 将线程的偷窃状态设置为REQ和行30 向线程发送信号。

1 intadd_count(未签名的长delta) 2{
3 int fastpath=0; 4
6barrier();
7如果( smp_ load_ acquire(& theft)<= THEFT_ REQ &&
8 countermax- counter>= delta){
14barrier();
15如果(READ_ ONCE(theft)== THEFT_ ACK)
16smp_store_release(和盗窃,THEFT_READY);
19spin_lock(&gblcnt_mutex);
20globalize_count();
21if (globalcountmax - globalc ount-
22 globalreserve< delta){
23flush_local_count();
24如果(globalcountmax -globalcount -
25 globalreserve< delta){
26spin_unlock(&gblcnt_mutex);
27 return0; 28}
29}
30 globalcount+=delta;
31balance_count();
33返回1;
34}

跨越线路33的环 – 46等待每个线程达到就绪状态,然后窃取该线程的计数。第34行 – 35 跳过任何不存在的线程,以及跨越第36行的循环 – 40 等待当前线程的偷窃状态准备好。第37行 为避免优先级反转问题,将阻塞1毫秒,如果第38行 确定线程的信号尚未到达,第39行 重新设置信号。执行到达第41行 当线程的偷窃状态变为就绪时,所以行4 1 – 44行窃。第45行 然后将线程的偷窃状态重新设置为IDLE。
![]()
第49行 – 61 显示balance_count(),它与前面示例中的类似。
清单5.19 显示了add_count()函数。快速路径跨越第5行 – 18 ,以及慢速路径线路19 – 33 .第5行 将每个线程计数变量设置为1,这样任何后续中断此线程的信号处理程序都将把偷窃状态设置为ACK而不是READY,从而允许此快速路径正确完成。第6行 防止编译器重新排序任何快速路径体,使其在计数设置之前出现。第7行 和8 检查每个线程的数据是否可以容纳add_count(),如果没有正在进行的盗窃行为,则行9 快速路径添加和行10 注意到已经采取了快速途径。
| 清单5.20:信号窃取限制计数器减法函数 | |
| 1 int 2{ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32} | sub_count(无符号长delta) int fastpath=0; WRITE_ONCE(计数,1);barrier(); 如果(smp_ load_ acquire(& theft)<= THEFT_ REQ && counter>= delta){ WRITE_ONCE(计数器,计数器-差值); fastpath= 1;} 屏障 WRITE_ONCE(计数器,0);barrier(); 如果(READ_ ONCE(theft)== THEFT_ ACK) smp_store_release(和盗窃,THEFT_READY);如果(快速路径) return1; spin_lock(&gblcnt_mutex);globalize_count(); 如果(globalcount< delta){flush_local_count(); 如果(globalcount< delta){ spin_unlock(&gblcnt_mutex);返回0; }} globalcount-=delta;balance_count(); spin_unlock(&gblcnt_mutex);返回1; |
| 1未签名的长读取计数(void)2{ 3 intt; 4个无符号长整型;5 6spin_lock(&gblcnt_mutex); 7 sum=globalcount; 8for_each_thread(t){ 9if(counter[t]!=NULL) 10 sum += READ_ ONCE(* counterp[t]);11} 12spin_unlock(&gblcnt_mutex); 13返回总和;14} |
在任何情况下,第12行 防止编译器重新排序快速路径主体以遵循第13行 ,允许后续的信号处理程序进行窃取。第14行 再次禁用编译器重排序,然后是第15行 检查信号处理程序是否将偷窃状态更改为“就绪”,如果是,则行16 使用smp_ store_ release()将偷盗状态设置为READY,进一步确保任何看到READY状态的CPU也看到第9行的效果。 如果在第9行进行快速路径添加 执行,然后第18行 返回成功。
否则,我们将进入从第19行开始的慢路径。 慢路径的结构与前面的例子类似,因此分析这部分内容留给读者练习。同样,子计数()在清单5.20中的结构 与add_count()相同,因此对sub_count()的分析也留给读者作为练习,对read_count()的分析也如清单5.21所示。
| 1空2{ 3 4 5 6 7 8 9 10 11 14空15{ 16 17 18 19 20 21 22 23} 24 25空26{ 27 28 29 30 31 32 33 34 35} | count_init(空) 结构信号a; sa.sa_handler=flush_local_count_sig;sigemptyset(&sa.sa_mask); sa.sa_flags=0; 如果(sigaction(SIGUSR1,&sa,NULL)!=0){perror(“sigaction”); 退出(EXIT_FAILURE); } count_register_thread(void)int idx=smp_thread_id(); spin_lock(&gblcnt_mutex); counterp[idx]=&counter; countermaxp[idx]=&countermax; theftp[idx]=&theft; spin_unlock(&gblcnt_mutex); count_unregister_thread(int nthreadsexpected)int idx=smp_thread_id(); spin_lock(&gblcnt_mutex);globalize_count(); counterp[idx]=NULL; countermaxp[idx]=NULL;theftp[idx]=NULL; spin_unlock(&gblcnt_mutex); |
第1行– 12 见清单5.22 showcount_init()将upflush_local_count_sig()设为SIGUSR 1的信号处理程序,从而允许pthread_kill()调用inflush_local_count()到invokeflush_local_count_sig()。线程注册和注销的代码与前面的例子类似,因此其分析留作读者练习。
信号窃取实现的速度比我六核x86笔记本电脑上的原子实现快八倍以上。它总是更可取吗?
信号窃取实现方式在奔腾4系统上更为理想,因为它们的原子指令较慢,但基于旧80386的顺序对称系统由于原子实现的较短路径长度表现更好。然而,这种更新侧性能的提升是以更高的读侧开销为代价的:这些POSIX信号并非免费。如果最终性能至关重要,你需要在应用程序将要部署的系统上同时测量两者。

这是高质量API如此重要的一个原因:它们允许根据不断变化的硬件性能特性进行更改。

尽管本节中提出的精确计数器实现非常有用,但如果计数器的值始终接近零,这并不会有多大帮助,例如在计算对I/O设备的未完成访问次数时。这种接近零的计数方式带来的高开销尤其令人头疼,因为我们通常并不关心有多少次引用。正如快速测验5.5提出的可移动I/O设备访问计数问题所指出的那样。 ,访问次数是无关紧要的,除非有人真的想删除设备。
解决这个问题的一个简单方法是在计数器中添加一个较大的“偏置”(例如十亿),以确保数值远离零,从而使计数器能够高效运行。当有人想要移除设备时,这个偏置会被从计数值中减去。最后几次访问的计数会相当低效,但关键在于之前的多次访问已经以全速被记录下来了。
尽管带有偏置的计数器可能非常有用,但它只是第77页所提到的可移除I/O设备访问计数问题的部分解决方案。 在尝试移除设备时,我们不仅需要知道当前I/O访问的确切次数,还需要防止任何未来的访问开始。一种实现方法是在更新计数器时读取并获取一个读写锁,在检查计数器时写入并获取同一个读写锁。执行I/O操作的代码可能如下:
| read_unlock(&mylock);cancel_io(); } else{ |
第1行 读取-获取锁,然后执行第3行 或7 释放它。行2 检查设备是否正在被移除,如果是,则行3 释放锁和行4 取消I/O,或者采取适当的措施,以确保设备被移除。否则,第6行 增加访问计数,第7行 释放锁,第8行 执行I/O,以及第9行 减少访问计数。

| removing=1; 子计数(mybias); |
第1行 write-获取锁和行4 释放它。行2 指出设备正在被移除,循环跨越行5 – 6等待任何I/O操作完成。最后,行7 是否需要额外处理以准备器械取出。
![]()
这种认为具体事物具有普遍性的观点具有深远的意义。
道格拉斯·R·霍夫施塔特
本章介绍了传统计数原语的可靠性、性能和可扩展性问题。C语言++操作符在多线程代码中无法保证可靠运行,而对单个变量的原子操作既不高效也不适合大规模处理。因此,本章提出了一系列在特定情况下表现和扩展性极佳的计数算法。
对这些计数算法的教训进行回顾是很有价值的。为此,第5.5.1节 概述要求进行现场确认,第5.5.2节 总结性能和可扩展性,第5.5.3节 讨论了专业化的需求,最后,第5.5.4节 列举了所学到的教训,并提醒读者注意后面章节将对这些教训进行扩展。
本节中的许多算法相当简单,以至于人们很容易认为它们是构造正确或通过检查就能确定正确的。不幸的是,执行构造或检查的人很容易变得过于自信、疲惫、困惑,或者干脆粗心大意,所有这些都可能导致错误。事实上,早期实现的限幅计数器确实存在错误,在某些情况下
由于在32位系统中维护64位计数的复杂性,因此即使对于本章介绍的简单算法,验证也不是可选的。
统计计数器被测试是否像计数器一样工作(counttorture.h),即计数器中的总和会随着各个更新侧线程添加的量之和而变化。
还对限位计数器进行了测试,以确定其是否具有计数器的功能(“limtorture.h”),并检查了它们是否能够满足指定的限值。
这两个测试套件均生成性能数据,这些数据将在第5.5.2节中使用。
尽管这种验证水平对于这些教科书级别的实现已经足够好,但在将类似的算法投入生产之前,进行额外的验证是明智之举。第十一章描述了其他测试方法,鉴于大多数计数算法的简单性,第十二章中介绍的许多技术也非常有帮助。
表5.1的上半部分 展示了四种并行统计计数算法的性能。所有四种算法在更新时都提供了接近完美的近似可扩展性。线程变量实现(count_end.c)在更新时比基于数组的实现(count_stat.c)快得多,但在大量核心读取时较慢,并且当有许多并行读取者时会遭受严重的锁竞争。这种竞争可以通过第9章介绍的延迟处理技术来解决,如表5.1的count_end_rcu .c ro w所示。 Deferred processing还对count_stat_eventual .c行进行了优化,这得益于最终一致性。

表5.1下半部分 展示了并行限制计数算法的性能。严格执行这些限制会导致显著的更新侧性能损失,尽管在这种x86系统中,通过用信号替代原子操作可以减少这种损失。所有这些实现都面临着并发读取时的读侧锁竞争问题。

简而言之,本章展示了一系列计数算法,在多种特殊情况下表现和扩展都非常出色。但我们的并行计数是否必须局限于这些特殊情况?难道不是应该有一个通用算法,在所有情况下都能高效运行吗?下一节将探讨这些问题。
这些算法只在各自特殊情况下才能很好地工作,这可能被认为是并行编程的一个主要问题。毕竟,C语言中的++运算符在单线程代码中也能很好地工作,而且不仅限于特殊情况,而是普遍适用,对吧?
这种观点确实包含了一丝真理,但本质上是错误的。问题不在于并行性本身,而在于可扩展性。要理解这一点,首先考虑C语言中的++运算符。事实上,它通常并不适用,仅限于特定范围内的数字。如果你需要处理1000位的十进制数,C语言中的++运算符将无法满足你的需求。

这个问题不仅限于算术。假设你需要存储和查询数据。你应该使用ASCII文件吗?XML?关系数据库?链表?密集数组?AB树?基数树?还是其他众多允许数据存储和查询的数据结构和环境之一?这取决于你需要做什么,需要多快完成,以及你的数据集有多大——即使是在顺序系统上也是如此。
同样,如果需要计数,你的解决方案将取决于需要处理的数字大小,需要同时操作给定数字的cpu数量,数字将如何使用,以及你需要的性能和可扩展性水平。
这个问题并不仅限于软件。一座供人们步行过小溪的桥设计可能简单到只有一块木板。但你大概不会用一块木板来跨越哥伦比亚河宽达数千米的河口,这样的设计也不适合承载混凝土卡车的桥梁。简而言之,正如桥梁设计必须随着跨度和负载的增加而变化一样,软件设计也必须随着CPU数量的增加而改变。话虽如此,最好能自动化这一过程,使软件能够适应硬件配置和工作负载的变化。事实上,已经有一些研究探讨了这种自动化[AHS+03,SAH+03],Linux内核在启动时会进行一些重新配置,包括有限的二进制重写。随着主流系统中CPU数量的不断增加,这种适应性将变得越来越重要。
简而言之,正如第三章所述,物理定律对并行软件的限制与对桥梁等机械制品的限制一样严格。这些限制迫使软件实现专业化,尽管在软件领域,可能可以自动化选择适合特定硬件和工作负载的专业化方案。
当然,即使是概括性的计数也是相当专业的。我们需要用计算机做许多其他的事情。下一节将把我们从计数器中学到的知识与本书后面讨论的主题联系起来。
本章的开头段落承诺,我们对计数的研究将为并行编程提供一个极好的介绍。本节明确地建立了本章的教训与后续章节中所介绍的内容之间的联系。
中的例子表明,分区是可扩展性和性能的一个重要工具。计数器可以完全分区,如第5.2节中讨论的统计计数器 ,或者部分分区,如第5.3节中讨论的限位计数器 和5.4。 分区将在第6章中进行更深入的讨论,部分并行化则在第6.4节中进行讨论,其中称为并行快速路径。

部分分区计数算法使用锁定来保护全局数据,而锁定是第七章的主题。相比之下,分区数据通常完全受相应线程的控制,因此无需任何同步操作。这种数据所有权将在第六章第三节中介绍,并在第八章中详细讨论。
由于整数加法和减法相比典型的同步操作成本极低,要实现合理的可扩展性就需要谨慎使用同步操作。一种方法是批量处理加法和减法操作,使得大量这些低成本的操作由一次同步操作来完成。表5.1中列出的每种计数算法都采用了某种形式的批量优化。
最后,讨论了第5.2.4节中提到的最终一致统计计数器 展示了如何通过延迟活动(在这种情况下,更新全局计数器)来提供显著的性能和可扩展性优势。这种方法使得常见代码能够使用比其他方式更便宜的同步操作。第9章将探讨延迟可以如何进一步提高性能、可扩展性和实时响应。
总结摘要:
1.分区可提高性能和可扩展性。
2.部分分区,即只应用于公共代码路径的分区,几乎同样有效。
3.部分分区可以应用于代码(如第5.2节所述 的统计计数器的分区更新和非分区读取),但也可以跨时间(如第5.3节所述和第5.4节 当远离极限时,其极限计数器运行速度较快,而接近极限时运行速度较慢)。
4.跨时间分区通常会将更新本地批处理,以减少昂贵的全局操作数量,从而减少同步过载,进而提高性能和可扩展性。表5.1中列出的所有算法均如此。大量使用分批。
5.只读代码路径应保持只读:如表5.1的count_end .c行所示,对共享内存进行虚假同步写入会破坏性能和可扩展性。
6.谨慎使用延迟可提高性能和可扩展性,如第5.2.4节所示。
7.并行性能和可扩展性通常是一种平衡:超过某个点后,优化某些代码路径会降低其他路径的性能。表5.1中的count_stat .c和count_ end_ rcu. c行说明这一点。
8.不同级别的性能和可扩展性将影响算法和数据结构设计,还有许多其他因素。图5.1 说明这一点:原子增量对于一个两CPU系统可能是完全可接受的,但对于一个八CPU系统来说却完全不够用。
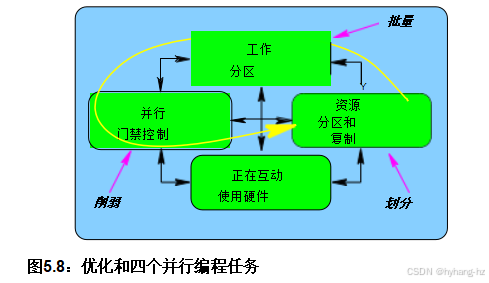
进一步总结,我们有三种提高性能和可扩展性的“大三”方法,即(1)在CPU或线程上进行分区,(2)批量处理以使每次昂贵的同步操作能够完成更多工作,以及(3)在可行的情况下弱化同步操作。作为一个大致的经验法则,你应该按此顺序应用这些方法,正如前面讨论图2.6时所指出的那样。分区优化适用于“资源分区和复制”气泡,批量处理优化适用于“工作分区”气泡,而弱化优化则适用于“并行访问控制”气泡,如所示。见图5.8。 当然,如果你使用的是专用硬件,如数字信号处理器(DSP)、现场可编程门阵列(FPGA)或通用图形处理单元(GPU),你可能需要在整个设计过程中密切关注“与硬件交互”这一环节。例如,GPGPU的硬件线程结构和内存连接可能会极大地受益于非常细致的分区和批量设计决策。
简而言之,正如本章开头所述,计数的简单性使我们能够探索许多基本的并发问题,而无需被复杂的同步原语或复杂的数据结构所干扰。这些同步原语和数据结构将在后续章节中介绍。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









