







文章目录
什么是 Normalization(归一化)
Normalization在统计学中一般翻译为归一化,现在已经成了神经网络中不可缺少的一个重要模块了。还有类似的是Standardization,一般翻译成标准化。这两个概念有什么区别呢?
- 归一化是将数据缩放到0-1之间
- 标准化是将数据缩放到均值为0,方差为1的正态分布。

有时候Normalization和Standardization会混淆,注意看清楚即可,不纠结细节。
注意:我们下面讲到的 Normalization归一化 严格讲应该称为 Standardization 标准化。
下面讲到的Normalization归一化的本质都是减去均值除以方差,进行线性映射后,使得数据满足某个稳定分布。其描述了一种把样本调整到均值为 0,方差为 1 的缩放平移操作。使用这种方法可以消除输入数据的量纲,有利于随机初始化的网络训练。
1. Batch Norm(批归一化)
BatchNorm(Batch Normalization),批归一化,旨在提高神经网络的训练速度、稳定性和性能。它由 Sergey Ioffe 和 Christian Szegedy 于 2015 年提出。BatchNorm 主要解决的问题是在训练深度神经网络时出现的内部协变量偏移(Internal Covariate Shift),即网络中各层输入数据分布的变化。
内部协变量偏移是指,随着网络层次的加深,每一层的输入数据(即前一层的输出)的分布可能会发生变化,这可能会导致训练过程中的梯度问题,比如梯度消失或梯度爆炸,从而影响网络的收敛速度和稳定性。

工作原理
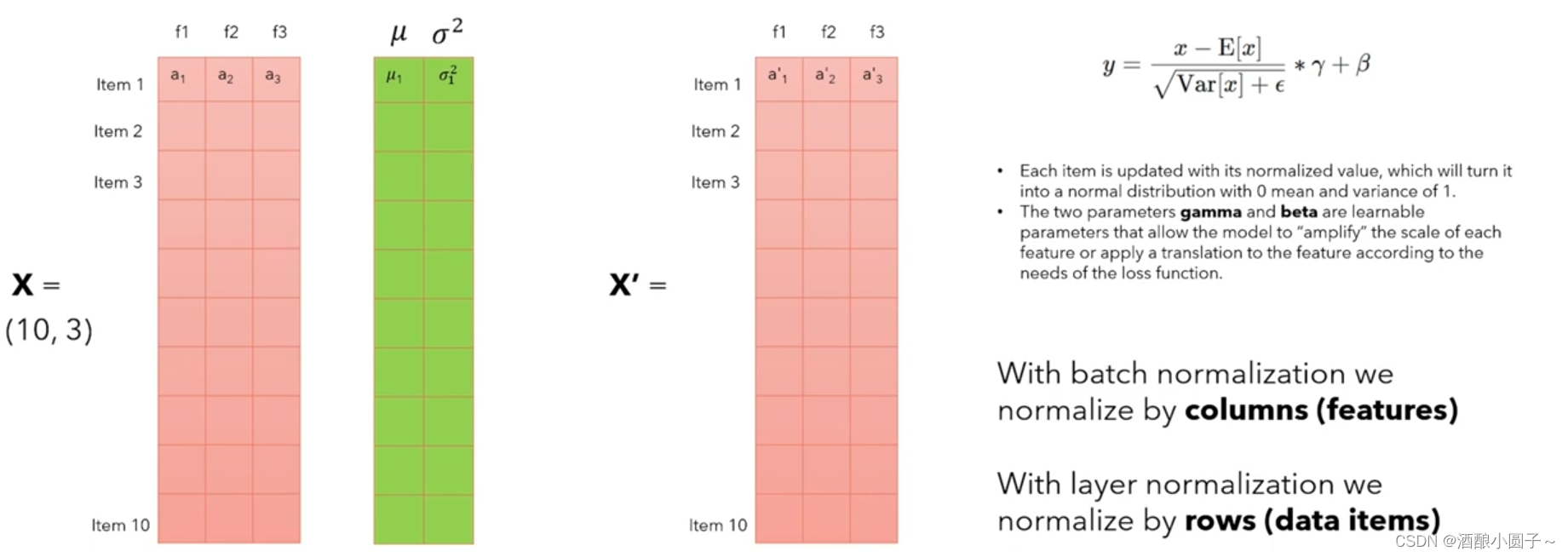
BatchNorm关注的是批次中每一列的数据,这些数据代表了 不同样本的同一个特征。 BatchNorm 的工作原理如下图所示:
-
归一化:在训练过程中,BatchNorm 对每个小批量(mini-batch)的数据进行归一化处理,即计算该批量数据的均值和方差,并使用这些统计量将数据标准化,使得数据的均值为 0,方差为 1。
-
缩放和偏移:归一化后的数据会经过两个可学习的参数(上图公式中的 γ \gamma γ和 β \beta β),即 缩放因子(gamma)和偏移因子(beta),这两个参数允许网络在训练过程中学习到最佳的归一化方式。
-
应用:BatchNorm 通常在神经网络的层之间应用,特别是在卷积层或全连接层之后,激活函数之前。
代码实现
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2: # 全连接层
shape = (1, num_features)
else: # 卷积层
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def batch_norm(self, X, gamma, beta, moving_mean, moving_var, eps, momentum):
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0) # (num_features,)
var = ((X - mean) ** 2).mean(dim=0) # (num_features,)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
mean = X.mean(dim=(0, 2, 3), keepdim=True) # (1,num_features,1,1) 保持X的形状,以便后面可以做广播运算
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True) # (1,num_features,1,1)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var,复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = self.batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9
)
return Y
2. Layer Norm(层归一化)
LayerNorm(Layer Normalization),层归一化是一种在深度学习中用于稳定神经网络训练和提高性能的技术。它是由 Jimmy Lei Ba、Jamie Ryan Kiros、Geoffrey E. Hinton 在 2016 年提出的。LayerNorm 与 Batch Normalization 类似,都旨在减少内部协变量偏移,但它们在归一化的具体实现上有所不同。
工作原理
LayerNorm的解决方案是对 每个样本的所有特征 进行单独归一化,而不是基于整个批次。
具体来说,LayerNorm 会计算单个样本在其所在层的所有激活值的均值和方差,并使用这些统计量来归一化该样本的激活值。这种方法不依赖于小批量统计量,因此可以减少 BatchNorm 中的噪声问题,并允许网络使用更小的小批量大小进行训练。
LayerNorm针对一个样本的 所有特征 计算均值和方差,然后使用这些来对样本进行归一化:
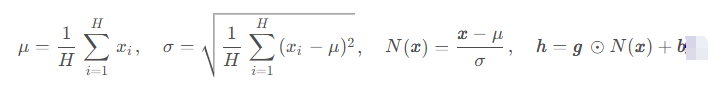
这里 x = ( x 1 , x 2 , ⋯ , x H ) x = ( x_1 , x_2 , ⋯ , x_H ) x=(x1,x2,⋯ ,xH) 表示某个时间步LN层的输入向量表示,向量维度为 H H H; h h h 是LN层的输出; g g g , b b b 是两个可学习的参数,分别代表缩放因子(gamma)和偏移因子(beta)。
LayerNorm 的工作原理如下:
-
归一化:对于网络中的每一层,LayerNorm 会计算该层所有激活值的均值和方差。然后,使用这些统计量将激活值归一化,使得每个样本的激活值的均值为 0,方差为 1。
-
缩放和偏移:与 BatchNorm 类似,归一化后的数据会经过两个可学习的参数(公式中的 g g g 和 b b b),即缩放因子(gamma)和偏移因子(beta),这两个参数允许网络在训练过程中学习到最佳的归一化方式。
-
应用:LayerNorm 可以应用于神经网络的任何层,包括卷积层和循环层,通常放在激活函数之前。
为什么层归一化有用?一些解释如下:
- 减少内部协变量偏移(Internal Covariate Shift): 内部协变量偏移是指在深度神经网络的训练过程中,每一层输入的分布会发生变化,导致网络的训练变得困难。层归一化通过对每一层的输入进行归一化处理,可以减少内部协变量偏移,使得每一层的输入分布更加稳定。
- 稳定化梯度: 层归一化有助于保持每一层输出的均值和方差稳定,从而使得梯度的传播更加稳定。这有助于减少梯度消失或梯度爆炸的问题,提高梯度在网络中的流动性,加快训练速度。
- 更好的参数初始化和学习率调整: 通过层归一化,每一层的输入分布被归一化到均值为0、方差为1的标准正态分布,这有助于更好地初始化网络参数和调整学习率。参数初始化与学习率调整的稳定性对模型的训练效果至关重要。
- 增强模型的泛化能力: 层归一化可以减少网络对训练数据分布的依赖,降低了过拟合的风险,从而提高模型的泛化能力。稳定的输入分布有助于模型更好地适应不同数据集和任务。
Batch Norm与Layer Norm的比较
Normalization技术旨在应对内部协变量偏移问题,它的核心在于将数据调整到一个统一的标准,以便进行有效的比较和处理。为了实现这一目标,我们需要确保参与归一化的数据点在本质上是可比的。
- Batch Normalization(BatchNorm):这是一种对整个批次数据进行归一化的方法。具体来说,BatchNorm关注的是批次中每一列的数据,这些数据代表了不同样本的同一个特征。 因为这些特征在统计上是相关的,所以它们可以被合理地放在一起进行归一化处理。这就像是在同一个班级里,比较不同学生的同一科目成绩,因为这些成绩都在相同的评分标准下,所以可以直接比较。
BatchNorm常用于CV领域,其对整个 batch 样本内的每个特征做归一化,这消除了不同特征之间的大小关系。假设输入图像的尺寸为 b × c × h × w b\times c\times h\times w b×c×h×w (批量大小 * 通道 * 长 * 宽),图像的每个通道 c c c 看作一个特征,BN 可以把各通道特征图的数量级调整到差不多,同时保持不同图片相同通道特征图间的相对大小关系。
- Layer Normalization(LayerNorm):与BatchNorm不同,LayerNorm适用于那些在不同样本之间难以直接比较的情况,如Transformer中的自注意力机制。在这些模型中,每个位置上的数据代表了不同的特征,因此直接归一化可能会失去意义。LayerNorm的解决方案是对每个样本的所有特征进行单独归一化,而不是基于整个批次。 这就像是评估每个学生在所有科目中的表现,而不是仅仅关注单一科目,这样可以更全面地理解每个学生的整体表现。
LayerNorm常用于NLP领域(适用于 Transformer 类模型),其对每个样本的所有特征做归一化,这消除了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系。
3. RMS Norm(均方根层归一化)
RMS Norm(Root MeanSquare Layer Norm),均方根层归一化 是 LayerNorm 的一个简单变体,来自 2019 年的论文 Root Mean Square Layer Normalization,被当前主流的大模型( LLama,Qwen, DeepSeek等 )所使用。
均方根层归一化认为,虽然LayerNorm很好,但是它每次需要计算均值和方差。实际上,Layer Norm成功的原因是re-scaling,因为方差Var计算的过程中使用了均值Mean。因此,RMS Norm不再使用均值Mean,而是构造了一个特殊的 统计量RMS 代替方差Var。
RMSNorm和LayerNorm的主要区别在于:RMSNorm不需要同时计算均值和方差两个统计量,而只需要计算均方根 Root Mean Square (RMS) 均方根 这一个统计量,公式如下:

这里, g i gi gi 为可学习的缩放因子,偏移参数 b i bi bi 移除掉了。
单看上式的话,相当于仅使用 x x x 的均方根来对输入进行归一化,它简化了层归一化的计算,使得计算量更小,同时还有可能带来性能上的提升。(实验表明:RMSNorm 性能和 LayerNorm 相当,但是可以节省7%到64%的运算量。)
LayerNorm与RMSNorm的比较
- 计算复杂度:RMSNorm不计算均值,仅计算均方根(RMS),其归一化操作不减去均值,直接除以均方根,降低了整体计算量。
- 数值稳定性:RMSNorm避免了方差接近零的情况,提升了数值稳定性。
- 表现性能:在某些任务中,RMSNorm可以达到或超过LayerNorm的性能。
总结而言,RMSNorm通过简化归一化过程,降低计算复杂度,提供了一种有效的归一化方法。它在保持模型性能的同时,提高了计算效率,是LayerNorm的有力替代方案。对于需要高效归一化操作的深度学习模型,RMSNorm是一个值得考虑的选择。
代码实现
RMSNorm 在HuggingFace Transformer 库中代码实现如下所示:
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
LlamaRMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps # eps 防止取倒数之后分母为0
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
# weight 是末尾乘的可训练参数, 即g_i
return (self.weight * hidden_states).to(input_dtype)

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









