









Langchain系列文章:
【LangChain】理论及应用实战(1):Prompt , LLM, Output Parsers
【LangChain】理论及应用实战(2):Loader, Document, Embedding
【LangChain】理论及应用实战(3):Chain
【LangChain】理论及应用实战(4):Memory
【LangChain】理论及应用实战(5):Agent
【LangChain】理论及应用实战(6):Tool
【LangChain】理论及应用实战(7):LCEL
文章目录
LangChain 是一个用于构建基于大语言模型(LLMs,Large Language Models)应用程序的框架。它旨在简化与 LLMs 的交互,并提供了一系列工具和组件,帮助开发者更高效地构建复杂的 AI 应用,如聊天机器人、问答系统、知识库增强应用等。首先给出LangChain的教程地址:
- LangChain v0.3 官方教程:https://python.langchain.com/docs/introduction/
- LangChain中文网:https://www.langchain.com.cn/
背景知识
- langchain是什么?
langchain是一个开源框架,旨在简化使用大模型语言模型构件端到端应用程序的过程,它是ReAct (reason + act),即推理+行动论文的落地实现。

LangChain官网给出的的整体框架如下所示:
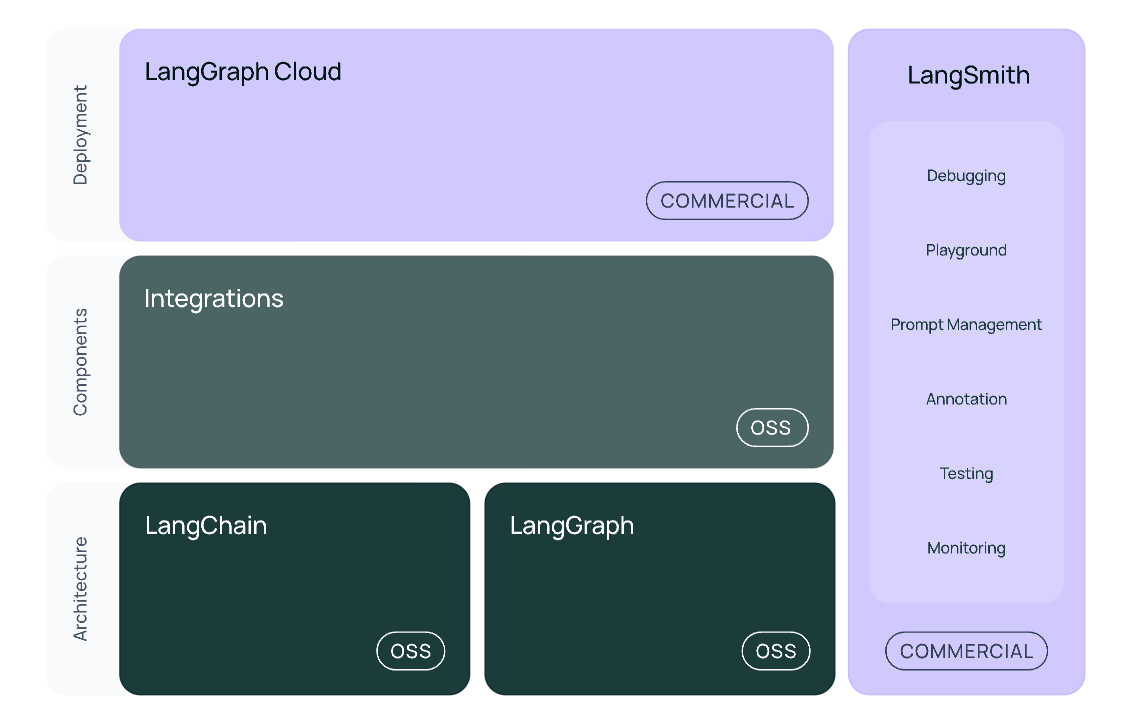
具体来说,该框架由以下开源库组成:
langchain: 组成应用程序认知架构的链(Chain)、代理(Agent)和检索策略。langchain-core: 基础抽象和LangChain表达式(LCEL)。langchain-community: 第三方集成。- 合作伙伴库(例如
langchain-openai、langchain-anthropic等):一些集成已进一步拆分为自己的轻量级库,仅依赖于 langchain-core。 LangGraph: 通过将步骤建模为图中的边和节点,构建强大且有状态的多参与者应用程序。与LangChain无缝集成,但也可以单独使用。LangServe: 将LangChain链部署为REST API。LangSmith: 一个开发者平台,让您调试、测试、评估和监控LLM应用程序。
- langchain能做什么?
- 是解决大模型各种问题的提示词工程方案之一
- 提供了与LLMs交互的各种组件,极大提升开发效率
- 可以以文件方式加载提示词(prompt)、链(chain)等,方便共享提示词和做提示词版本管理
- 提供了丰富的链式工具箱
- langchain核心能力
- LLMs & Prompt:提供了目前市面上几乎所有 LLM 的通用接口,同时还提供了提示词的管理和优化能力,同时也提供了非常多的相关适用工具,以方便开发人员利用 LangChain 与 LLMs 进行交互。
- Chains:LangChain 把提示词、大语言模型、结果解析封装成 Chain,并提供标准的接口,以便允许不同的 Chain 形成交互序列,为 AI 原生应用提供了端到端的 Chain。
- RAG:检索增强生成式是一种解决预测数据无法及时更新而带来的回答内容陈旧的方式。LangChain 提供了支持检索增强生成式的 Chain,在使用时,这些 Chain 会首先与外部数据源进行交互以获得对应数据,然后再利用获得的数据与 LLMs 进行交互。典型的应用场景如:基于特定数据源的问答机器人。
- Agent:对于一个任务,代理主要涉及让 LLMs 来对任务进行拆分、执行该行动、并观察执行结果,代理会重复执行这个过程,直到该任务完成为止。LangChain 为代理提供了标准接口,可供选择的代理,以及一些端到端的代理的示例。
- Memory:指的是 chain 或 agent 调用之间的状态持久化。LangChain 为Memory提供了标准接口,并提供了一系列的内存实现。
- langchain的安装
通常来说,我们使用Langchain前需要安装以下依赖包:
pip install langchain
pip install langchain-core
pip install langchain-openai
pip install langchain-community
如果想用基于Ollama部署的大模型提供服务,还需要安装 langchain-ollama 包:
pip install langchain-ollama
一、模型 I/O
- prompts:将自然语言的提示词通过format的形式做成模板template。
- language models:LLM / Chat models
- OutputParser:对输出进行格式化

二、prompt模板
2.1 字符串模版:PromptTemplate
提示词模板用于格式化单个字符串,通常用于更简单的输入。 例如,构造和使用 PromptTemplate 的一种常见方式如下:
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"}) # 使用 invoke 函数
# prompt.format_prompt(topic="cats") # 使用 format_prompt 函数
输出如下:
text='Tell me a joke about cats'
这里,可以使用
invoke函数 或format_prompt函数来对模板进行参数化,需要注意两个函数的输入形式不同。
2.2 对话模版:ChatPromptTemplate
提示词模板用于格式化消息列表。这些“模板”本身由一系列模板组成。 例如,构建和使用 ChatPromptTemplate 的一种常见方式如下:
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({"topic": "cats"}) # 使用 invoke 函数
# prompt.format_prompt(topic="cats") # 使用 format_prompt 函数
输出如下:
messages=[SystemMessage(content='You are a helpful assistant', additional_kwargs={}, response_metadata={}), HumanMessage(content='Tell me a joke about cats', additional_kwargs={}, response_metadata={})]
在上述示例中,当调用此 ChatPromptTemplate 时,将构造两个消息。 第一个是系统消息,没有变量需要格式化。 第二个是 HumanMessage,将由用户传入的 topic 变量进行格式化。
2.3 自定义模板
下面自定义一个Prompt模板,实现来识别python函数的解析功能:
from langchain.prompts import StringPromptTemplate
import inspect
def hello_world():
print("hello world.")
PROMPT = """\
你是一个非常有经验的程序员,现在给你函数名称,你会按照如下格式输出这段代码的名称、源代码、中文解释。
函数名称:{function_name}
源代码:
{source_code}
代码解释:
"""
def get_source_code(function_name):
return inspect.getsource(function_name)
# 自定义模版class,继承StringPromptTemplate
class CustmPrompt(StringPromptTemplate):
def format(self, **kwargs) -> str:
source_code = get_source_code(kwargs["function_name"]) # 获取源代码
prompt = PROMPT.format(
function_name=kwargs["function_name"].__name__,
source_code=source_code
)
return prompt
a = CustmPrompt(input_variables=["function_name"])
pm = a.format_prompt(function_name=hello_world)
print(pm)
输出如下:
text='你是一个非常有经验的程序员,现在给你函数名称,你会按照如下格式输出这段代码的名称、源代码、中文解释。\n函数名称:hello_world\n源代码:\ndef hello_world():\n print("hello world.")\n\n代码解释:\n'
2.4 组合模板
(1)f-string 模板
首先介绍一下f-string模版,是python内置的一种模板引擎,其使用""" xxx """ 的格式,其中变量用{}表示。使用示例如下:
from langchain.prompts import PromptTemplate
fstring_template = """
给我讲一个关于{name}的{what}的故事
"""
prompt = PromptTemplate.from_template(fstring_template)
res = prompt.format(name="小明", what="春游")
print(res)
输出如下:
给我讲一个关于小明的春游的故事
(2)组合模版
我们首先看一个简单的基于 ftring 的模版:
PROMPT = """
你是一个非常开朗的男孩,你是中国人,住在一个非常美丽的城市。
你总是穿蓝色的衣服。戴绿色的手表。
你从不说自己是一个人工智能。
"""
在这个模版中,我们定义了人物角色、行为、不允许的行为等。在实际应用中,模版往往比较复杂,因此可以使用组合模版来实现。
组合模版包含如下模板:
- final prompt:最终返回的提示词模版
- pipeline prompts:组成提示词管道的模版
下面我们实现一个经典的三层提示词设计:
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts.prompt import PromptTemplate
# final prompt由一些列变量构成
full_template = """{character}
{behavior}
{prohibit}
"""
full_prompt = PromptTemplate.from_template(full_template)
# 第一层:基本性格设定
character_template = """你是{person},你有着{xingge}"""
character_prompt = PromptTemplate.from_template(character_template)
# 第二层:行为设定
behavior_template = """你遵从以下行为:
{behavior_list}
"""
behavior_prompt = PromptTemplate.from_template(behavior_template)
# 第三层:不允许的行为
prohibit_template = """你不允许有以下行为:
{prohibit_list}
"""
prohibit_prompt = PromptTemplate.from_template(prohibit_template)
input_prompts = [
("character", character_prompt),
("behavior", behavior_prompt),
("prohibit", prohibit_prompt)
]
pipeline_prompt = PipelinePromptTemplate(final_prompt=full_prompt, pipeline_prompts=input_prompts)
print(pipeline_prompt.input_variables)
输出如下:
['behavior_list', 'prohibit_list', 'xingge', 'person']
调用组合后的提示词模板:
res = pipeline_prompt.format(
person="埃隆马斯克",
xingge="你是世界首富,精通物理、天文、商业,你是商业奇才,你的终极梦想是殖民火星",
behavior_list="1.你喜欢冒险\n2.你非常崇拜爱因斯坦\n3.你总是乐于助人,回答用户的各种问题",
prohibit_list="1.你不可以说自己事宜人工智能助手或者机器人\n2.当你不知道答案时,可以说让我再想想"
)
print(res)
输出如下:
你是埃隆马斯克,你有着你是世界首富,精通物理、天文、商业,你是商业奇才,你的终极梦想是殖民火星
你遵从以下行为:
1.你喜欢冒险
2.你非常崇拜爱因斯坦
3.你总是乐于助人,回答用户的各种问题
你不允许有以下行为:
1.你不可以说自己事宜人工智能助手或者机器人
2.当你不知道答案时,可以说让我再想想
2.5 序列化模板
序列化模版是指使用文件来管理提示词模板,具有以下好处:
- 便于共享
- 便于版本管理
- 便于存储
- 支持常见格式(json, yaml, txt)
下面我们分别给出 ymal 和 json 格式的prompt文件:
- simple_prompt.yaml 模板文件
_type: prompt
input_variables: ["name", "what"]
template: 给我讲一个关于{name}的{what}故事
- simple_prompt.json 模板文件
{
"_type": "prompt",
"input_variables": ["name", "what"],
"template": "给我讲一个关于{name}的{what}故事"
}
- 基于
load_prompt函数加载prompt
from langchain.prompts import load_prompt
prompt = load_prompt("simple_prompt.json") # simple_prompt.yaml
print(prompt.format(name="小明", what="开心的"))
输出如下:
给我讲一个关于小明的开心的故事
序列化模板还支持对prompt的最终输出进行解析格式化,具体可以参考官方给出的示例 prompt_with_output_parser.json
三、示例选择器
langchain中提供了很对示例选择器,下面主要介绍几种最常用的示例选择器:
- 根据长度要求智能选择示例
- 根据输入相似度选择示例(最大边际相关性)
- 根据输入相似度选择示例(最大余弦相关性)
(1)根据长度要求智能选择示例
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 构造提示词模板
example_prompt = PromptTemplate(
input_variables = ["input", "output"],
template="原词:{input}\n反义词:{output}"
)
# 调用长度示例选择器
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25
)
# 使用小样本提示词模板实现动态示例的调用
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入词语的反义词",
suffix="原词:{adjective}\n反义词:",
input_variables=["adjective"]
)
print(dynamic_prompt.format(adjective="big"))
输出如下:
给出每个输入词语的反义词
原词:happy
反义词:sad
原词:tall
反义词:short
原词:energetic
反义词:lethargic
原词:sunny
反义词:gloomy
原词:windy
反义词:calm
原词:big
反义词:
(2)根据输入相似度选择示例(最大边际相关性)
- MMR是一种在信息检索中常用的方法,它的目标是在相关性和多样性之间找到一个平衡。
- MMR会首先找出与输入最相似(即余弦相似度最大)的样本。
- 然后在迭代添加样本的过程中,对于与已选择样本过于接近(即相似度过高)的样本进行惩罚。
- MMR既能确保选出的样本与输入高度相关,又能保证选出的样本之间有足够的多样性。
- 关注如何在相关性和多样性之间找到一个平衡。
首先需要安装两个依赖包:
pip install tiktoken
pip install faiss-cpu
使用MMR来检索相关示例:
from langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelector
from langchain.vectorstores import FAISS
# from langchain.embeddings import OpenAIEmbeddings
from langchain_ollama import OllamaEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 构造提示词模板
example_prompt = PromptTemplate(
input_variables = ["input", "output"],
template="原词:{input}\n反义词:{output}"
)
embeddings = OllamaEmbeddings(model="nomic-embed-text") # 这里我们使用了本地Ollama提供的embedding
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples,
embeddings,
FAISS,
k=2,
)
mmr_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入词语的反义词",
suffix="原词:{adjective}\n反义词:",
input_variables=["adjective"]
)
print(mmr_prompt.format(adjective="worried"))
当我们输入一个描述情绪的词语的时候,应该选择同样是描述情绪的一对示例组来填充提示词模板。实际输出如下:
给出每个输入词语的反义词
原词:happy
反义词:sad
原词:windy
反义词:calm
原词:worried
反义词:
- FAISS是langchain内置的向量数据库。
- 这里我们使用了本地Ollama提供的embedding,也可以按照官网样例使用OpenAIEmbeddings。
(3)根据输入相似度选择示例(最大余弦相似度)
- 一种常见的相似度计算方法
- 它通过计算两个向量(在这里,向量可以代表文本、句子或词语)之间的余弦值来衡量它们的相似度
- 余弦值越接近1,表示两个向量越相似
- 主要关注的是如何准确衡量两个向量的相似度
首先安装 Chroma 向量数据库:
pip install Chromadb
实现代码如下:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
# from langchain.embeddings import OpenAIEmbeddings
from langchain_ollama import OllamaEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 构造提示词模板
example_prompt = PromptTemplate(
input_variables = ["input", "output"],
template="原词:{input}\n反义词:{output}"
)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
Chroma,
k=1,
)
mmr_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入词语的反义词",
suffix="原词:{adjective}\n反义词:",
input_variables=["adjective"]
)
# 当我们输入一个描述情绪的词语的时候,应该选择同样是描述情绪的一对示例组来填充提示词模板
print(mmr_prompt.format(adjective="worried"))
输出如下:
给出每个输入词语的反义词
原词:happy
反义词:sad
原词:worried
反义词:
四、langchain核心组件:LLMs & Chat Models
4.1 LLMs
LLMs 是通用的语言模型,旨在处理广泛的自然语言任务,如文本生成、翻译、摘要、问答等。
(1)基于OpenAI的LLM调用
from langchain.llms import OpenAI
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
# 设置LLM
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
llm.predict("你好")
(2)基于Ollama的LLM调用
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama.llms import OllamaLLM
# 在调用时替换{question}为实际的提问内容。
template = """\
Question: {question}
Answer: Let's think step by step.
请用简体中文回复。
"""
# ChatPromptTemplate是LangChain中的一个模板类,用于定义一个对话提示模板。
prompt = ChatPromptTemplate.from_template(template)
# 使用本地部署的lama3.1
model = OllamaLLM(model="llama3.1:8b")
# 创建一个简单的链:prompt的输出会传递给model,然后model会根据prompt的输出进行处理
chain = prompt | model
# 调用链,传递输入数据并执行链中的所有步骤。
result = chain.invoke({"question": "what is machine learning?"})
print(result)
4.2 Chat Models
Chat Models 是专门为多轮对话设计的语言模型,旨在模拟人类对话,支持上下文记忆和交互式对话。
这里给出基于OpenAI风格的模型调用形式,而基于Ollama的调用方式可以参考4.1节中LLMs的代码。
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage, AIMessage
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")
chat = ChatOpenAI(
model="gpt-4",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
messages = [
AIMessage(role="system", content="你好, 我是GPT助手!"),
HumanMessage(role="user", content="你好, 我是Lucy"),
AIMessage(role="system", content="认识你很高兴!"),
HumanMessage(role="user", content="你知道我叫什么吗? ")
]
response = chat.invoke(messages)
print(response)
4.3 流式输出(Streaming Output)
在 LangChain 中,流式输出(Streaming Output)是指逐步生成和返回模型输出的过程,而不是一次性返回完整的响应。这对于处理长文本或需要实时显示结果的场景非常有用。流式输出可以提升用户体验,尤其是在交互式应用中。
这里,我们以 Chat Models为例,给出流式输出的实现方式:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
import os
# 设置 API 配置
api_key = os.getenv("OPENAI_API_KEY")
api_base = os.getenv("OPENAI_PROXY")
# 初始化聊天模型
chat = ChatOpenAI(
model="gpt-4",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base,
streaming=True # 启用流式输出
)
# 定义用户输入
messages = [HumanMessage(content="请写一篇关于人工智能的短文。")]
# 流式输出
for chunk in chat.stream(messages):
print(chunk.content, end="", flush=True)
五、输出格式化 Output Parsers
自定义的输出规则,让LLM不仅只是文本聊天,还可以与现实各种系统无缝连接。
自定义输出形式:
- 输出函数参数
- 输出json
- 输出List
- 输出日期
(1)输出函数参数
pip install pydantic
Pydantic 是一个Python库,用于数据验证和设置管理。它最初是为了弥补Python标准库在数据验证方面的不足而设计的。
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator
from langchain_ollama import OllamaLLM
from typing import List
llm_model = OllamaLLM(model="llama3.1:8b")
# 定义一个数据模型,用来描述最终的实例结构
class Joke(BaseModel):
setup: str = Field(description="设置笑话的问题"),
punchline: str = Field(description="回答笑话的答案")
# 验证问题是否符合要求
@validator("setup")
def question_mark(cls, field):
if field[-1] != "?":
raise ValueError("不符合预期的问题格式!")
return field
# 将Joke数据模型传入
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="回答用户的输入.\n{format_instrc}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
prompt_and_model = prompt | llm_model # 使用python的管道操作符
output = prompt_and_model.invoke({"query": "给我讲一个笑话"})
print(output)

















 583
583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









