









文章目录
本文主要内容参考资料:
LangChain 拥有大量第三方工具。工具是设计用于被模型调用的实用程序:它们的输入旨在由模型生成,输出旨在返回给模型。 每当您希望模型控制代码的某些部分或调用外部API时,都需要工具。
一个工具由以下部分组成:
-
工具的 名称。
-
工具的 描述。
-
定义工具输入的 JSON schema。
-
一个 函数(可选地,还有该函数的异步变体)。
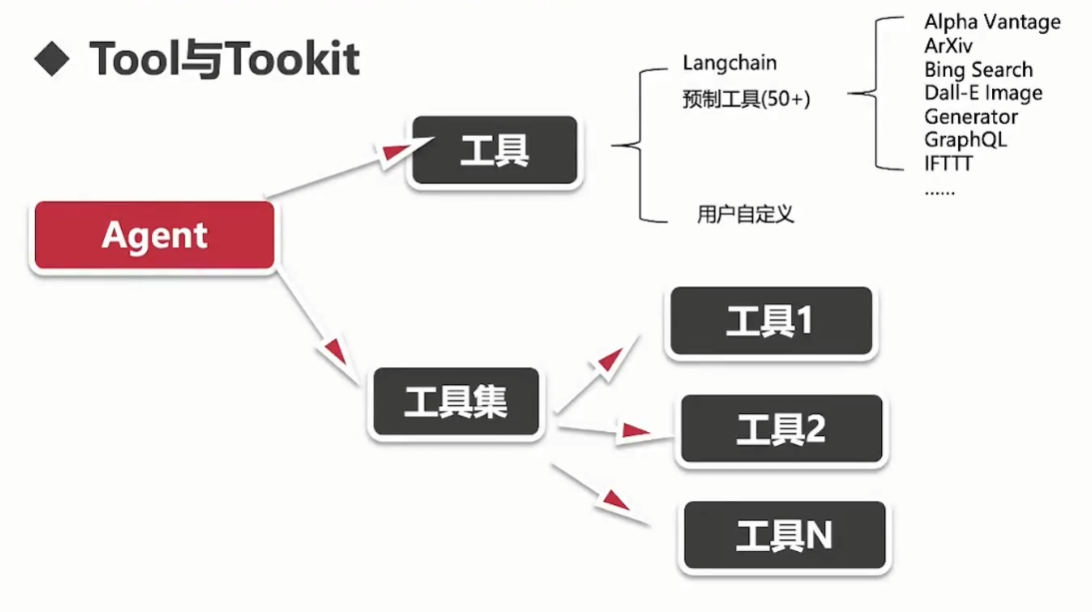
-
Tool:单个工具
-
Tookit:工具集
一、Tool
1.1 Tool的使用
使用内置工具和工具包:https://www.langchain.com.cn/docs/how_to/tools_builtin/
- 使用工具:
load_tools
添加预制工具的方法
from langchain.agents import load_tools
tool_names = [...]
tools = load_tools(tool_names) # 使用load方法
注意:有些tool需要单独设置llm
from langchain.agents import load_tools
tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm) # 在load的时候指定llm
- 查看有哪些内置的tools:
get_all_tool_names
from langchain_community.agent_toolkits.load_tools import get_all_tool_names
tool_names = get_all_tool_names()
print(tool_names)
输出如下:
['sleep', 'wolfram-alpha', 'google-search', 'google-search-results-json', 'searx-search-results-json', 'bing-search', 'metaphor-search', 'ddg-search', 'google-books', 'google-lens', 'google-serper', 'google-scholar', 'google-finance', 'google-trends', 'google-jobs', 'google-serper-results-json', 'searchapi', 'searchapi-results-json', 'serpapi', 'dalle-image-generator', 'twilio', 'searx-search', 'merriam-webster', 'wikipedia', 'arxiv', 'golden-query', 'pubmed', 'human', 'awslambda', 'stackexchange', 'sceneXplain', 'graphql', 'openweathermap-api', 'dataforseo-api-search', 'dataforseo-api-search-json', 'eleven_labs_text2speech', 'google_cloud_texttospeech', 'read_file', 'reddit_search', 'news-api', 'tmdb-api', 'podcast-api', 'memorize', 'llm-math', 'open-meteo-api', 'requests', 'requests_get', 'requests_post', 'requests_patch', 'requests_put', 'requests_delete', 'terminal']
1.2 常见的Tool
(1)SerpAPI:最常见的聚合搜索引擎
from langchain.utilities import SerpAPIWrapper
import os
os.environ["SERP_API_KEY"] = "xxxxxxxxxx"
search = SerpAPIWrapper()
search.run("Obama's first name?")
支持自定义参数,比如将搜索引擎切换到Bing,设置搜索语言等:
params = {
"engine": "bing",
"gl": "us",
"hl": "en",
}
search = SerpAPIWrapper(params=params)
(2)Dall-E
Dall-E是OpenAI出品的文到图AI大模型。
pip install opencv-python scikit-image
示例代码如下:
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, load_tools
# Dall-E 需要配合大模型一起使用
llm = ChatOpenAI(
temperature=0,
model="gpt-4"
)
tools = load_tools([["dalle-image-generator"]])
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
verbose=True
)
output = agent.run("Create an image of the halloween night")
(3)Eleven Labs Text2Speech
Eleven Labs是非常优秀的text到语言转换API,官网地址:https://elevenlabs.io/
pip intsall elevenlabs
pip install pydantic
from langchain.tools import ElevenLabsText2SpeechTool
text_to_speak = "Hello! 你好! Hola! 呷呷! Bonjour! こんにちは! 山のつきれい ! どしもがく!!"
tts = ElevenLabsText2SpeechTool(
voice="Bella",
text_to_speak=text_to_speak,
verbose=True
)
# 生成语音文件后再播放
speech_file = tts.run(text_to_speak)
tts.play(speech_file )
# 边生成语言文件边播放
tts.stream_speech(text_to_speak) # 流式输出
(4)GraphQL
一种API查询语言,类似SQL。
pip install httpx gql > /dev/null
pip install gql
pip install requests_toolbelt
代码示例:
from langchain.chat_models import ChatOpenAI
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain.utils import GraphQLAPIWrapper
llm = ChatOpenAI(
temperature=0,
model="gpt-4",
)
tools = load_tools(
["graphql"],
graphql_endpoint="https://swapi-graphql.netlify.app/.netlify/functions/it"
)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
graphqlfields = """allFilms {
films {
title
director
releaseDate
speciesConnection {
species {
name
classification
homeworld {
name
}
}
}
}
}
"""
suffix = "Search for the titles of all the star wars films stored in the graph"
agent.run(suffix + graphql_fields)
二、Toolkit
Toolkit 是 LangChain 已经封装好的一系列工具,一个工具包是一组工具来组合完成特定的任务。
所有工具包都暴露一个 get_tools 方法,该方法返回工具列表。
2.1 Azure 认知服务
Azure 认知服务官网:https://portal.azure.com/#allservices
- AzureCogsFormRecognizerTool:从文档里提取文本
- AzureCogsSpeech2TextTool:语音到文本
- AzureCogsText2SpeechTool:文本到语音
首先安装依赖包:
pip install --upgrade azure-ai-formrecognizer > /dev/null
pip install --upgrade azure-cognitiveservices-speech > /dev/null
pip install azure-ai-textanalytics
示例代码:
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.agents.agent_toolkits import AzureCognitiveServicesToolkit
import os
os.environ["AZURE_COGS_KEY"] = "9ea5fcee55fd4278821a38eaca652ac7"
os.environ["AZURE_COGS_ENDPOINT"] = "https://westus2.api.cognitive.microsoft"
os.environ["AZURE_COGS_REGION"] = "westus2"
# 创建 toolkit
toolkit = AzureCognitiveServicesToolkit()
# agent使用
llm = ChatOpenAI(temperature=0, model="gpt-4-1106-preview")
agent = initialize_agent(
tools=toolkit.get_tools(),
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
audio_file = agent.run("Tell me a joke and read it out for me.")
查看工具集中包含哪些工具:
toolkit = AzureCognitiveServicesToolkit()
[tool.name for tool in toolkit.get_tools()]
输出如下:
[‘azure_cognitive_services_form_recognizer’,
‘azure_cognitive_services_speech2text’,
‘azure_cognitive_services_text2speech’,
‘azure_cognitive_services_text_analytics_health’]
2.2 Python 代码机器人
一个Python代码机器人,将自然语言转换为Python代码。
安装依赖包:
pip install langchain_experimental
示例代码:
agent_executor = create_python_agent(
llm=ChatOpenAI(temperature=0, model="gpt-4-1106-preview"),
tool=PythonREPLTool(),
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
agent_executor_kwargs={"handle_parsing_errors": True},
)
agent_executor.run("What is the 10th fibonacci number?")
2.3 SQLDataBase 数据库查询
使用 SQLDatabaseChain构建Agent,用来根据数据库来回答一般的问题。
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.lms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0))
agent_executor = create_sql_agent(
llm=ChatOpenAI(temperature=0, model="gpt-4-1106-preview"),
toolkit=toolkit,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS
)
agent_executor.run("Describe the PlayList table")
也可以用自然语言运行SQL查询:
agent_executor.run("List the total sales per country, which country's customers spent the most?")
三、自定义Tool
如何创建工具:https://www.langchain.com.cn/docs/how_to/custom_tools/
在构建 Agent 时,需要提供一个它可以使用的 Tool 列表。除了被调用的实际函数外,Tool 由几个组件组成:
LangChain 支持从以下内容创建工具:
- 函数;
- LangChain 运行接口;
- 通过从 BaseTool 子类化 – 这是最灵活的方法,它提供了最大的控制程度,但需要更多的努力和代码。
从函数创建工具可能足以满足大多数用例,可以通过简单的 @tool 装饰器 来完成。如果需要更多配置,例如同时指定同步和异步实现,也可以使用 StructuredTool.from_function 类方法。
3.1 从函数创建工具
(1)@tool 装饰器:基于 @tool 装饰器是定义自定义工具的最简单方法。默认情况下,装饰器使用函数名称作为工具名称,但可以通过将字符串作为第一个参数传递来覆盖。此外,装饰器将使用函数的文档字符串作为工具的描述 - 因此必须提供文档字符串。
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# Let's inspect some of the attributes associated with the tool.
print(multiply.name)
print(multiply.description)
print(multiply.args)
输出如下:
multiply
Multiply two numbers.
{'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
(2)结构化工具
StructuredTool.from_function 类方法提供比 @tool 装饰器更多的可配置性,而无需太多额外代码。
from langchain_core.tools import StructuredTool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
async def amultiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
calculator = StructuredTool.from_function(func=multiply, coroutine=amultiply)
print(calculator.invoke({"a": 2, "b": 3}))
print(await calculator.ainvoke({"a": 2, "b": 5}))
输出如下:
6
10
3.2 从可运行对象创建工具
接受字符串或 dict 输入的 LangChain Runnables 可以使用 as_tool 方法转换为工具,该方法允许为参数指定名称、描述和其他模式信息。
示例用法:
from langchain_core.language_models import GenericFakeChatModel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[("human", "Hello. Please respond in the style of {answer_style}.")]
)
# Placeholder LLM
llm = GenericFakeChatModel(messages=iter(["hello matey"]))
chain = prompt | llm | StrOutputParser()
as_tool = chain.as_tool(
name="Style responder", description="Description of when to use tool."
)
as_tool.args
3.3 子类化 BaseTool
可以通过从 BaseTool 子类化来定义自定义工具。这提供了对工具定义的最大控制,但需要编写更多代码。
from typing import Optional, Type
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
from pydantic import BaseModel
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
# Note: It's important that every field has type hints. BaseTool is a
# Pydantic class and not having type hints can lead to unexpected behavior.
class CustomCalculatorTool(BaseTool):
name: str = "Calculator"
description: str = "useful for when you need to answer questions about math"
args_schema: Type[BaseModel] = CalculatorInput
return_direct: bool = True
def _run(
self, a: int, b: int, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""Use the tool."""
return a * b
async def _arun(
self,
a: int,
b: int,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""Use the tool asynchronously."""
# If the calculation is cheap, you can just delegate to the sync implementation
# as shown below.
# If the sync calculation is expensive, you should delete the entire _arun method.
# LangChain will automatically provide a better implementation that will
# kick off the task in a thread to make sure it doesn't block other async code.
return self._run(a, b, run_manager=run_manager.get_sync())
multiply = CustomCalculatorTool()
print(multiply.name)
print(multiply.description)
print(multiply.args)
print(multiply.return_direct)
print(multiply.invoke({"a": 2, "b": 3}))
print(await multiply.ainvoke({"a": 2, "b": 3}))
输出如下:
Calculator
useful for when you need to answer questions about math
{'a': {'description': 'first number', 'title': 'A', 'type': 'integer'}, 'b': {'description': 'second number', 'title': 'B', 'type': 'integer'}}
True
6
6

















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









