







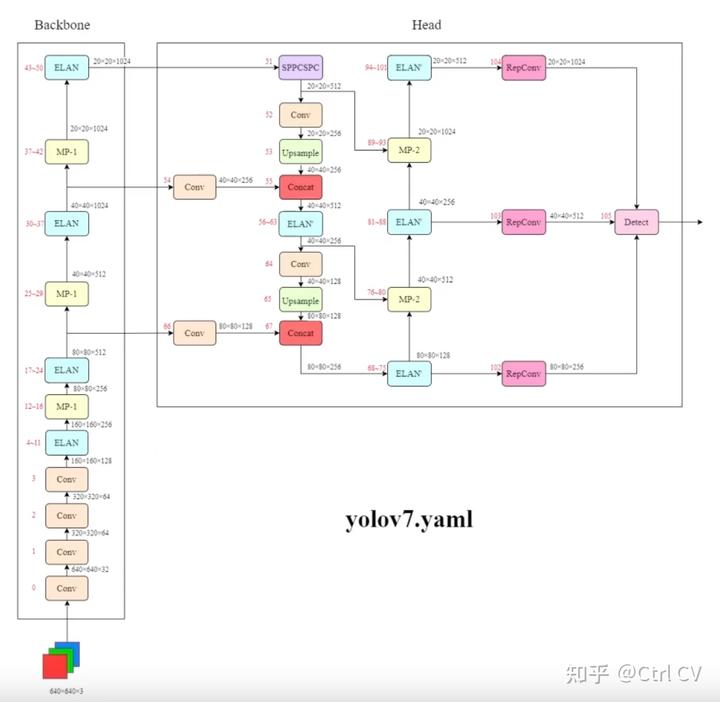
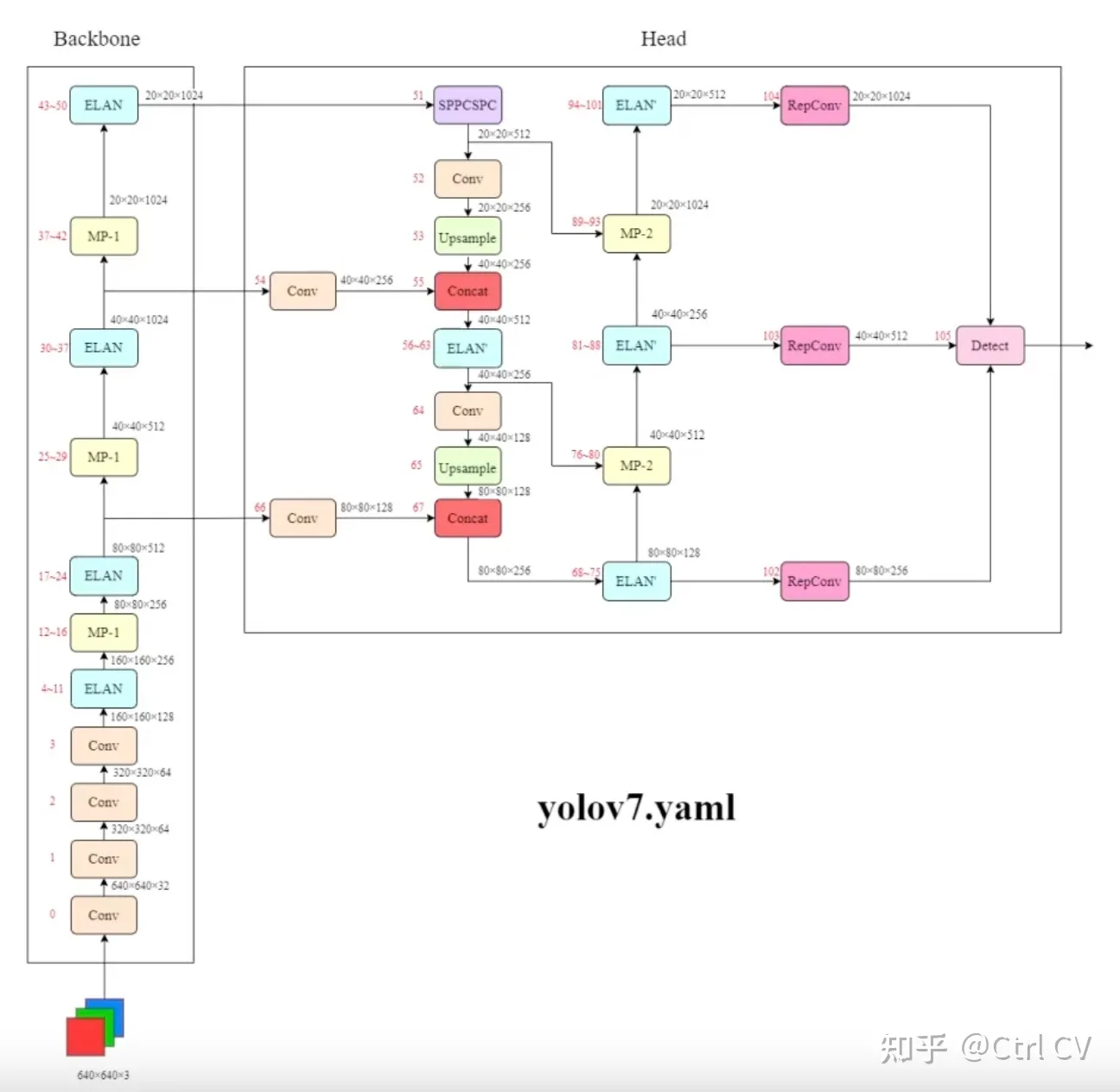
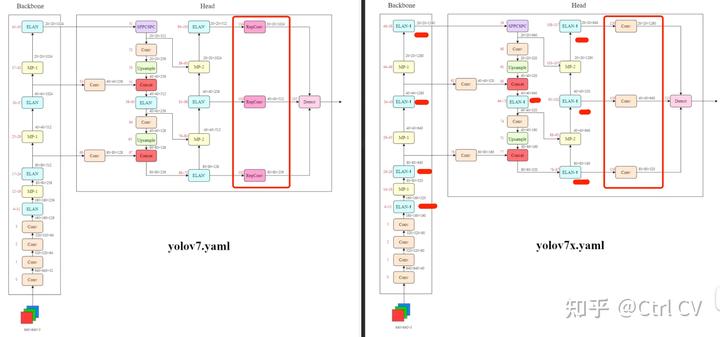
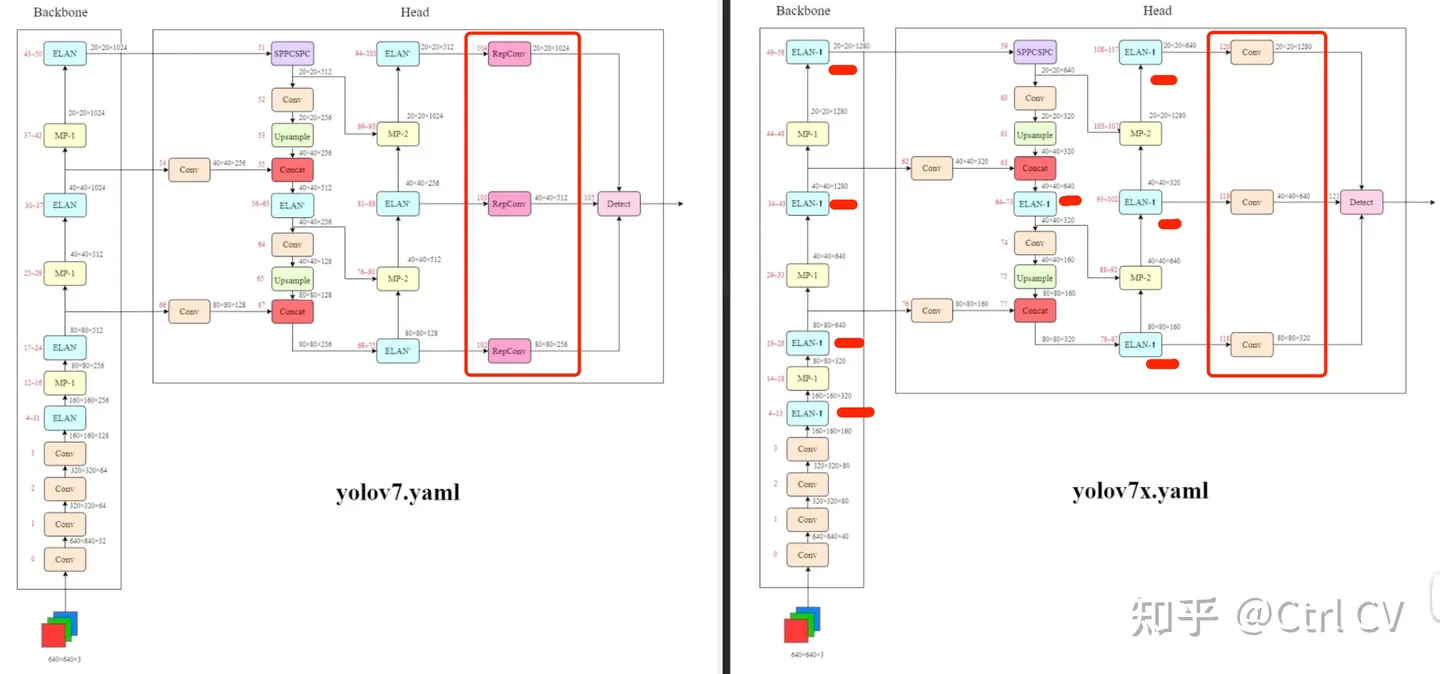
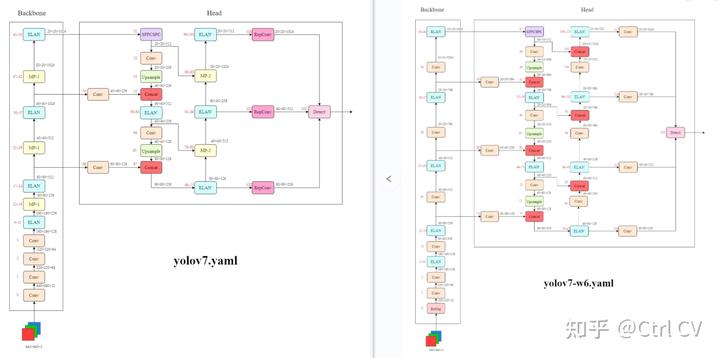
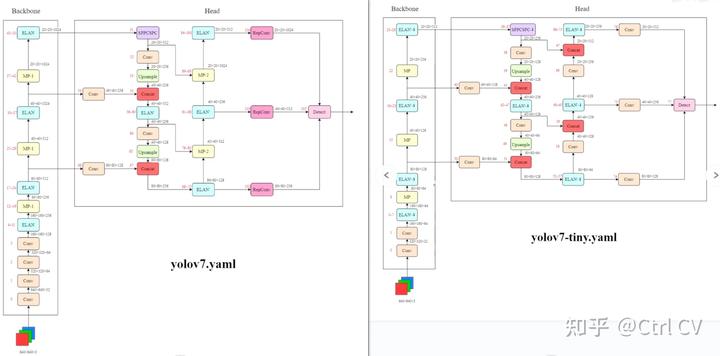
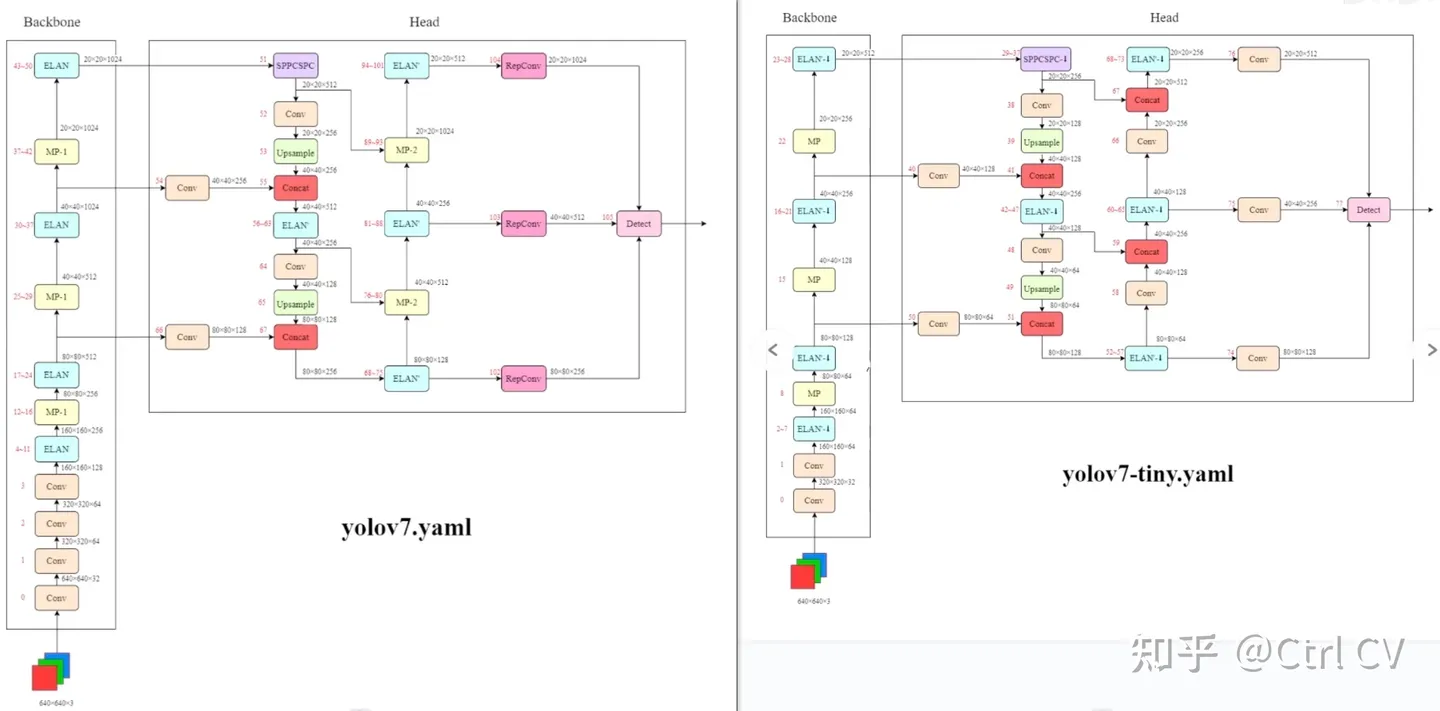
一、yolov7网络架构图
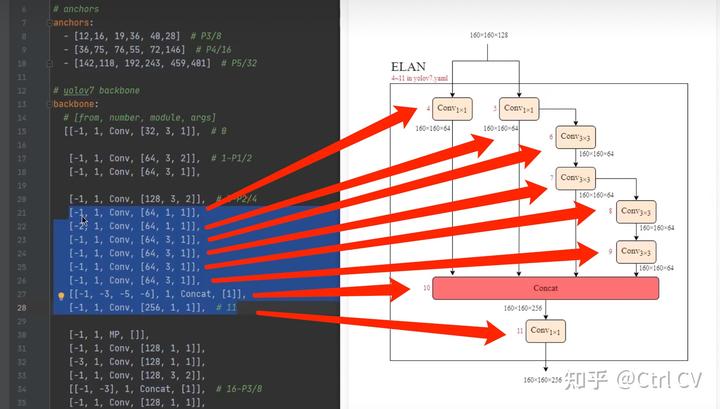
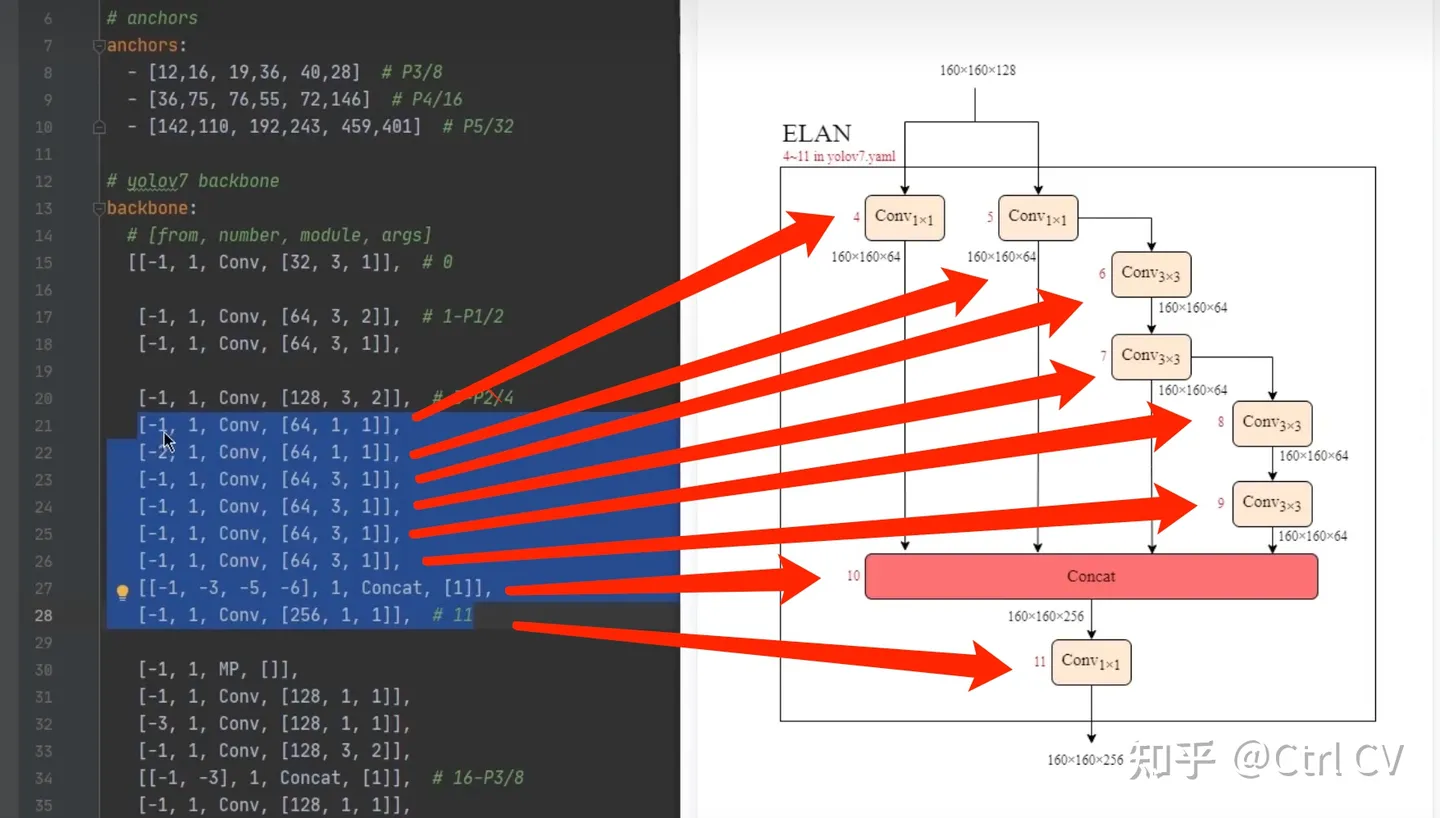
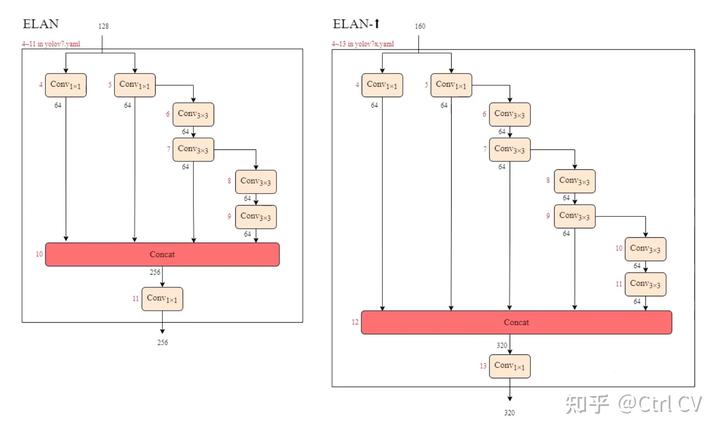
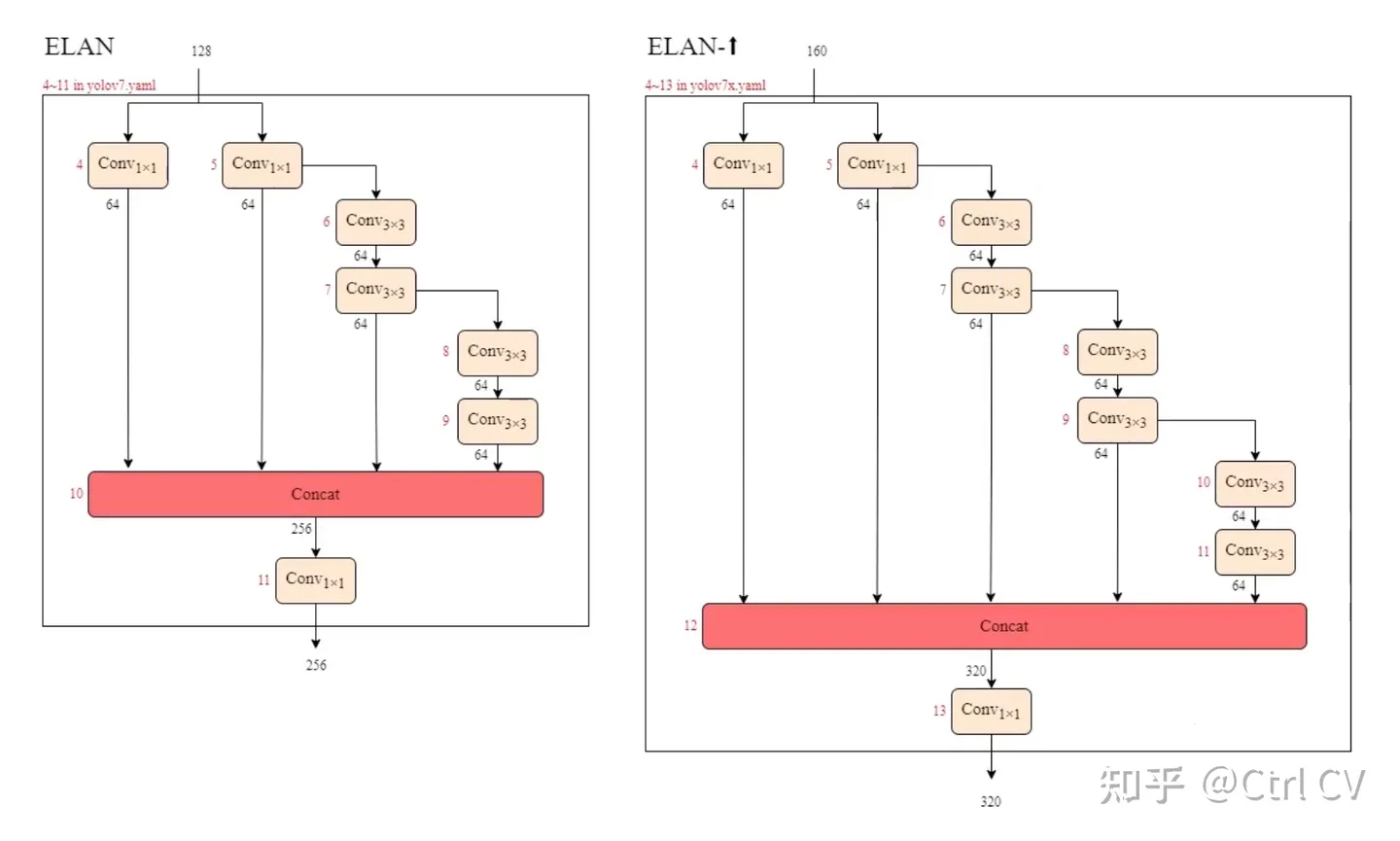
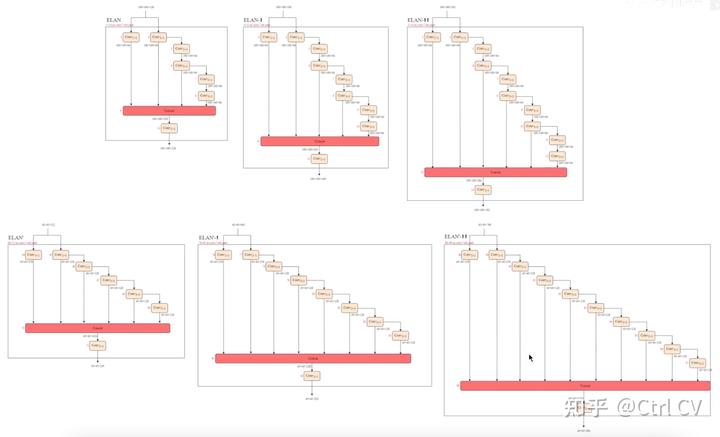
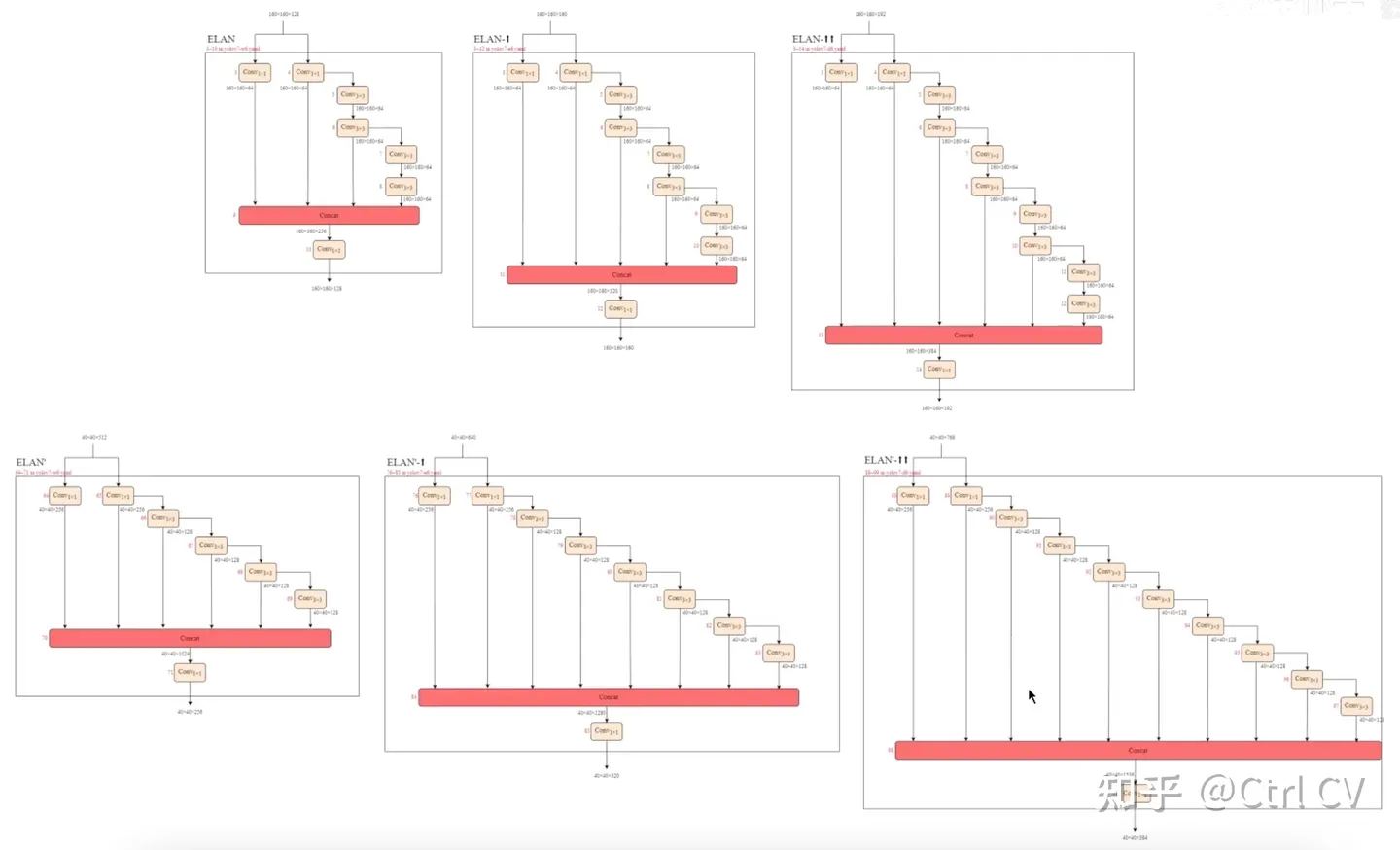
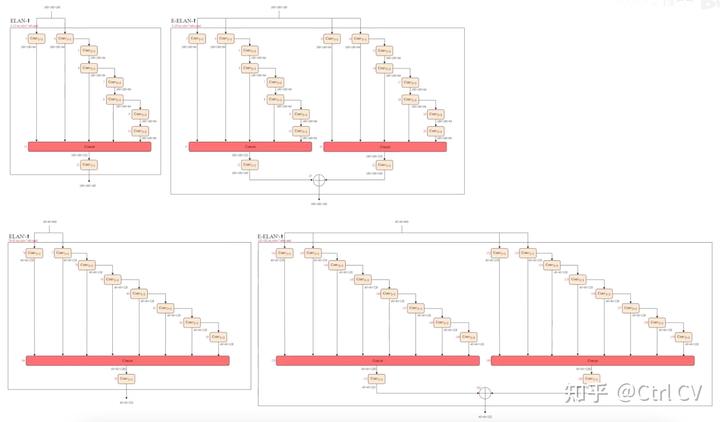
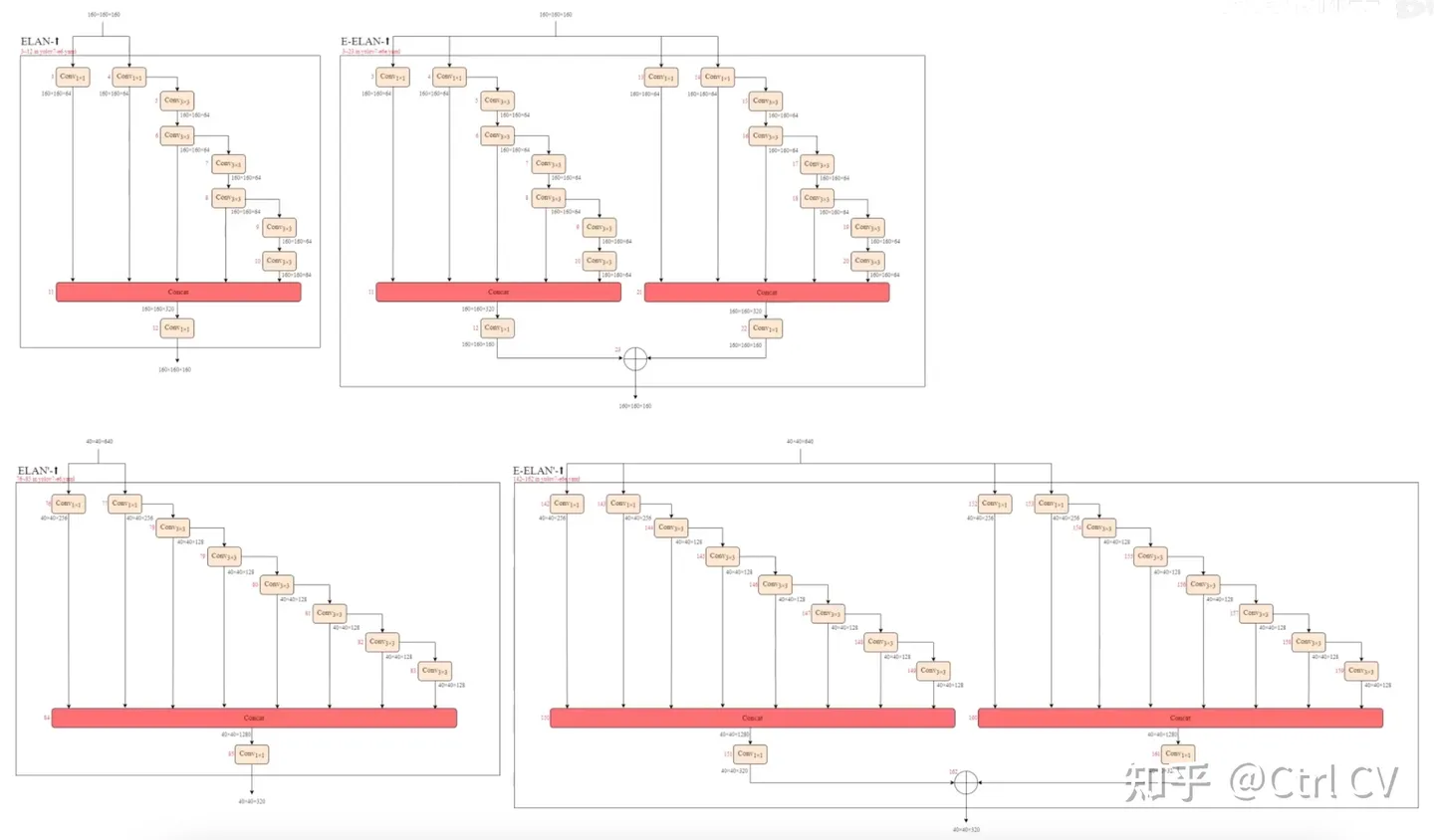
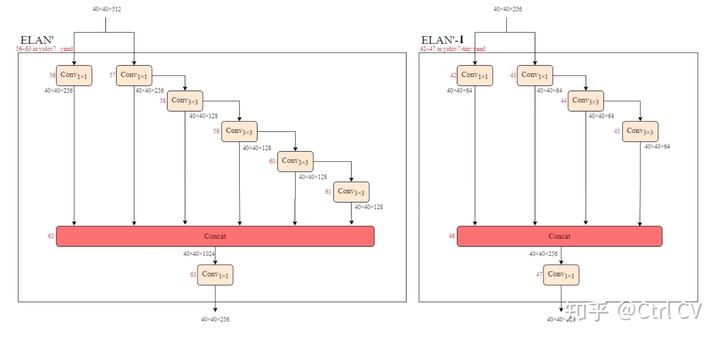
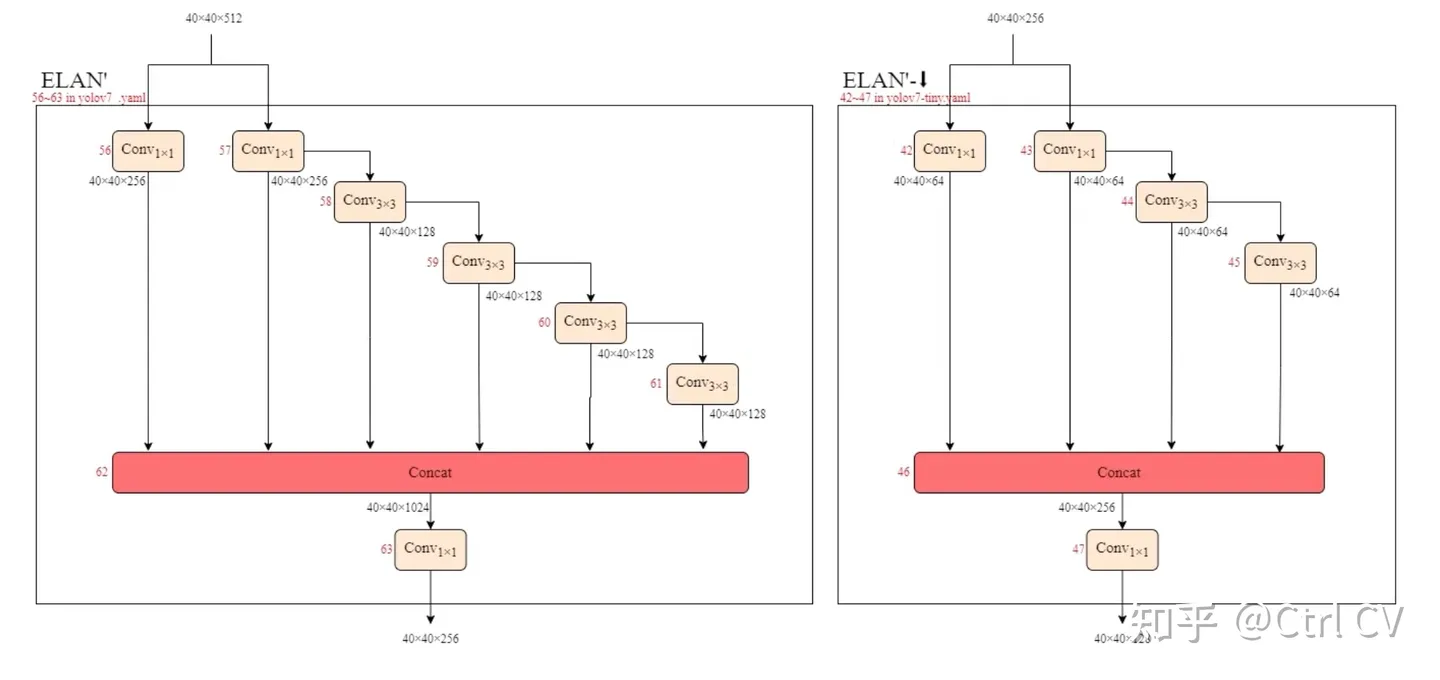
二、yolov7 ymal, ELAN结构分析
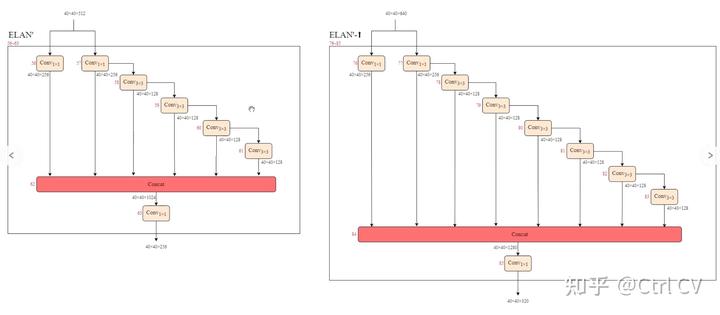
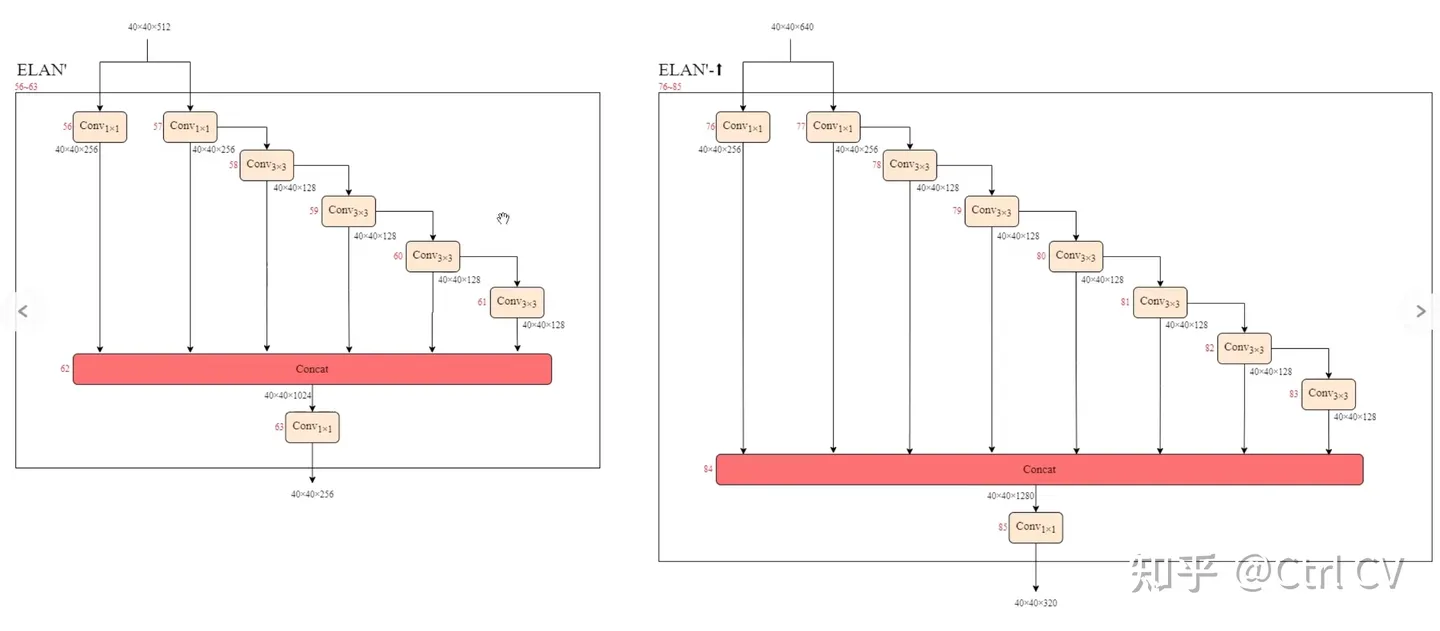
对照论文中的ELAN结构
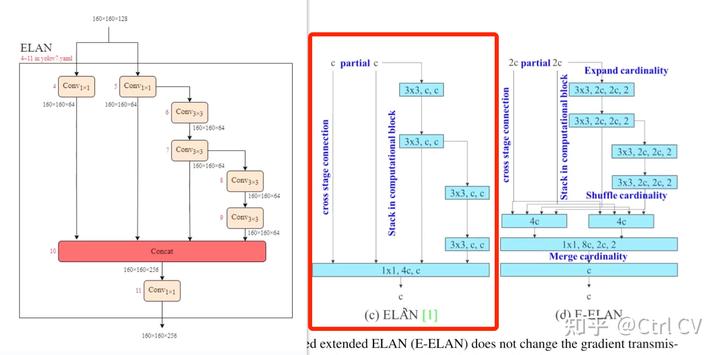
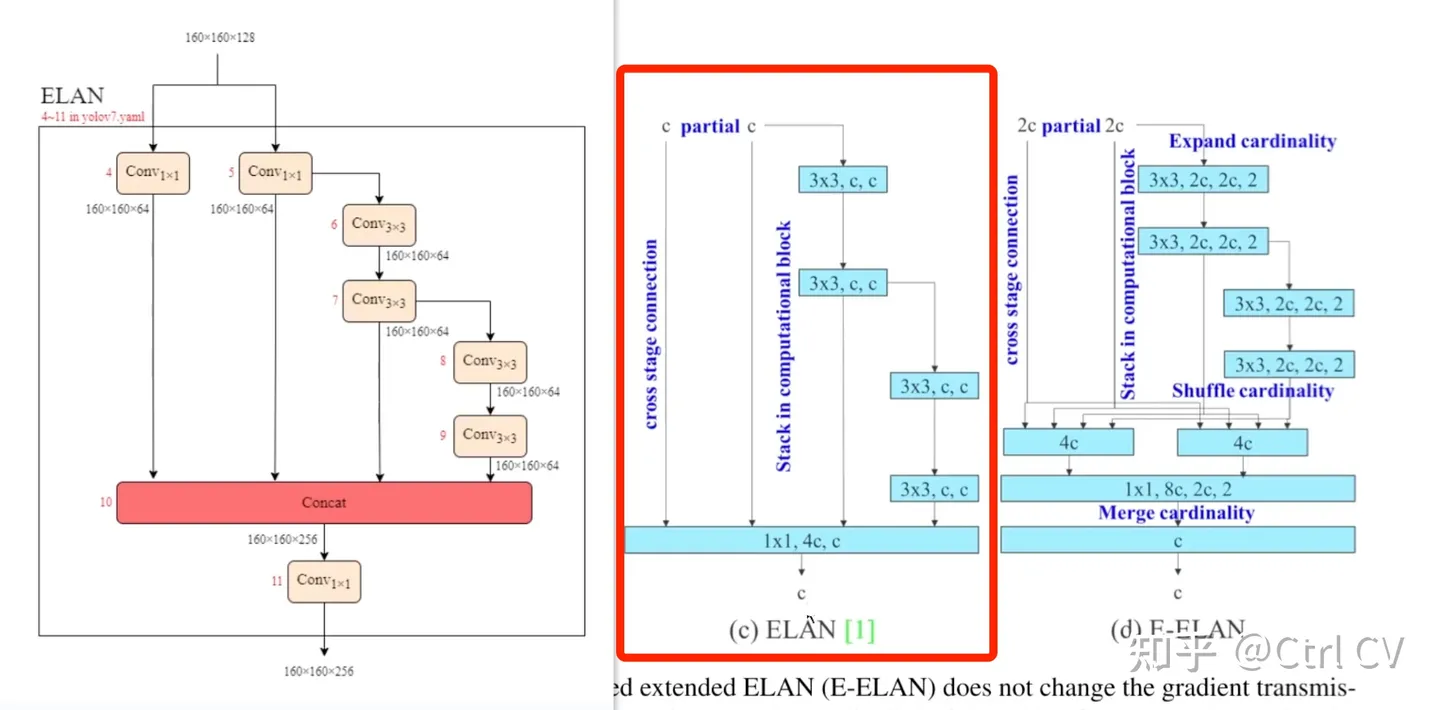
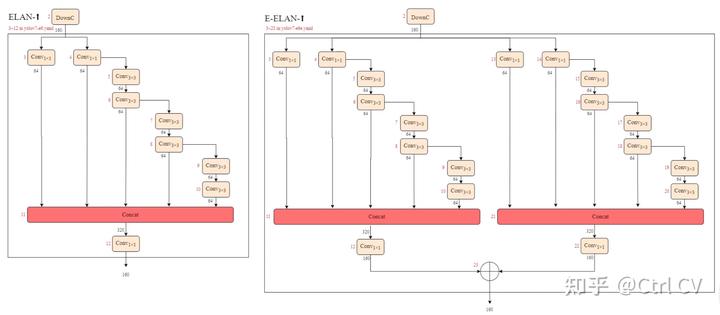
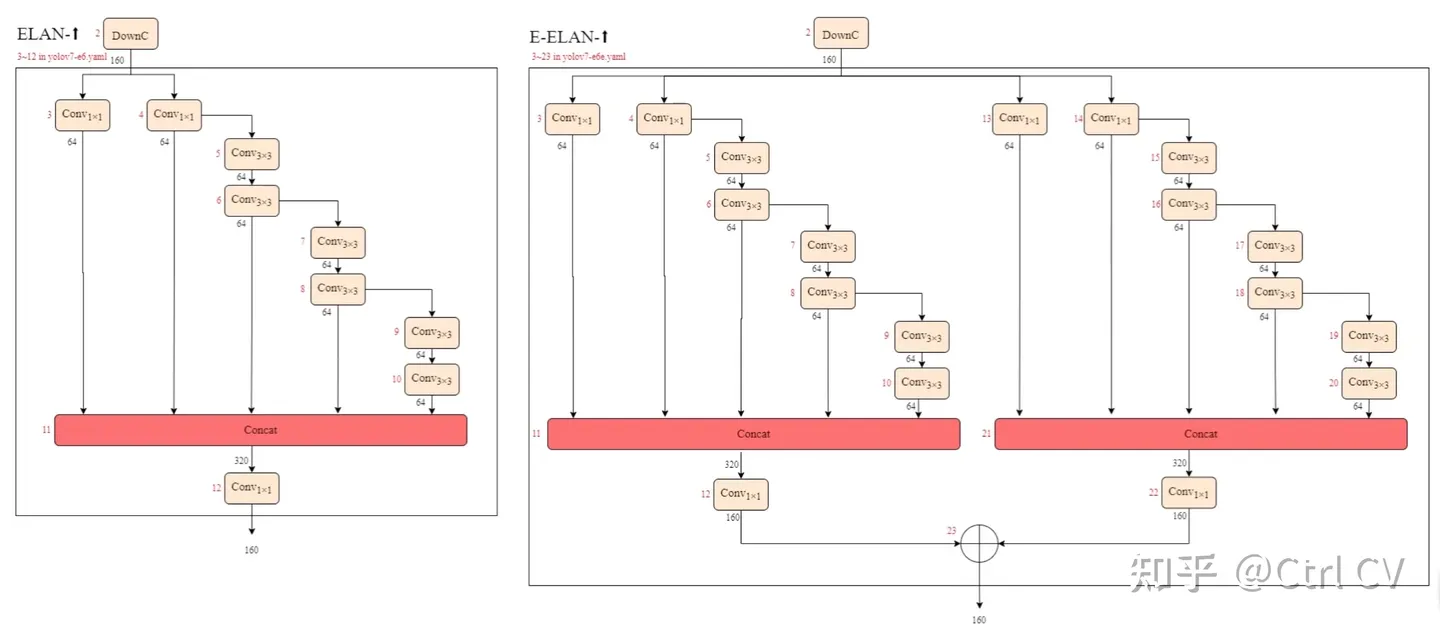
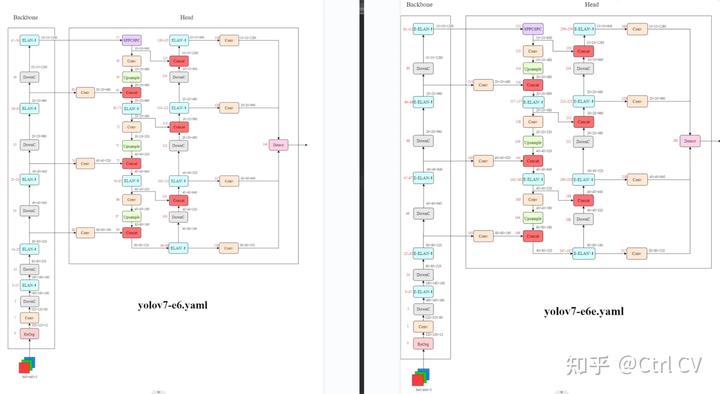
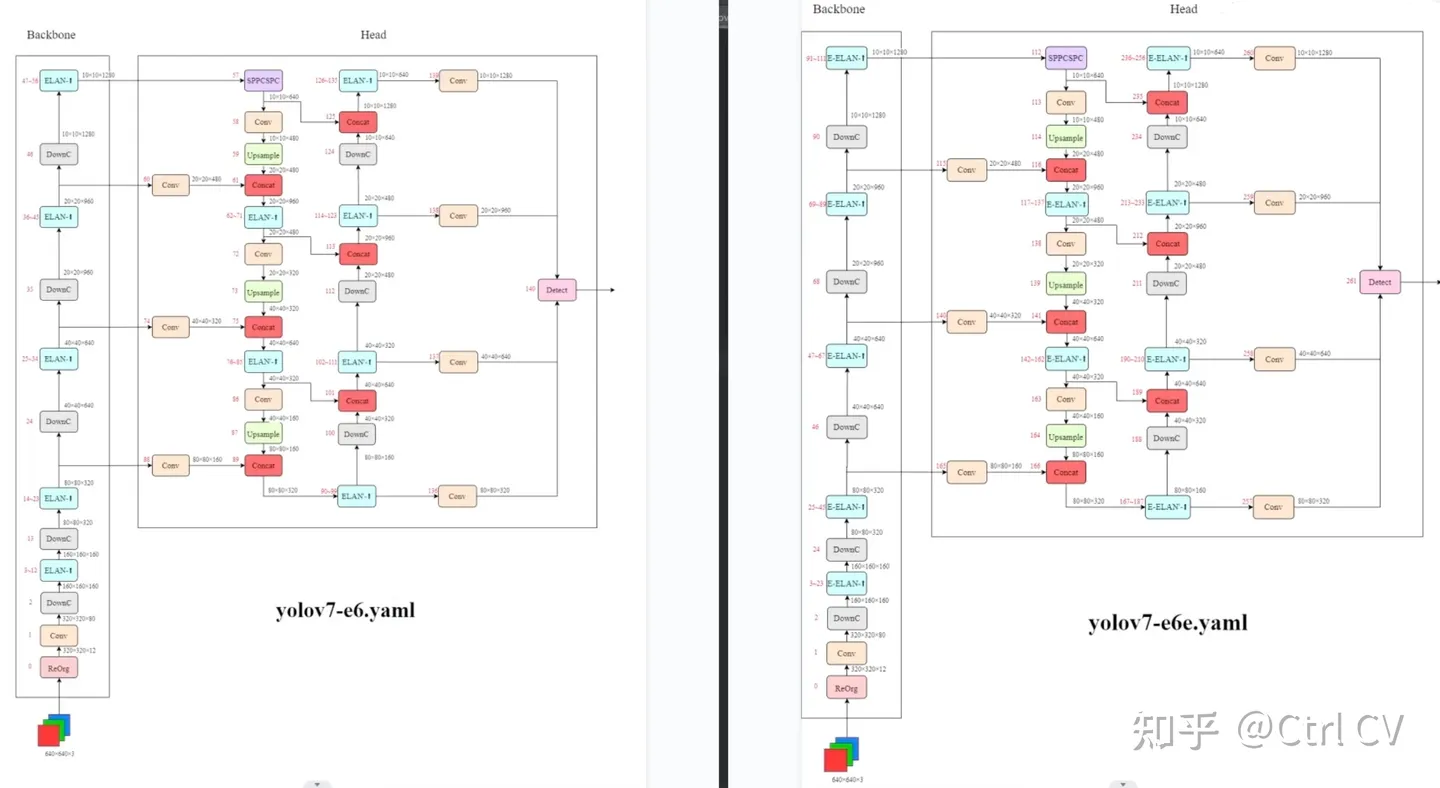
三、E-ELAN结构
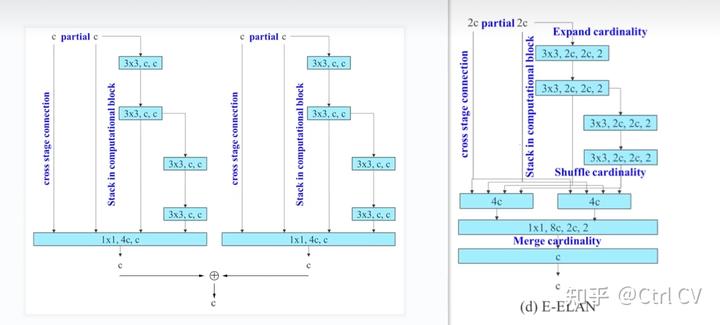
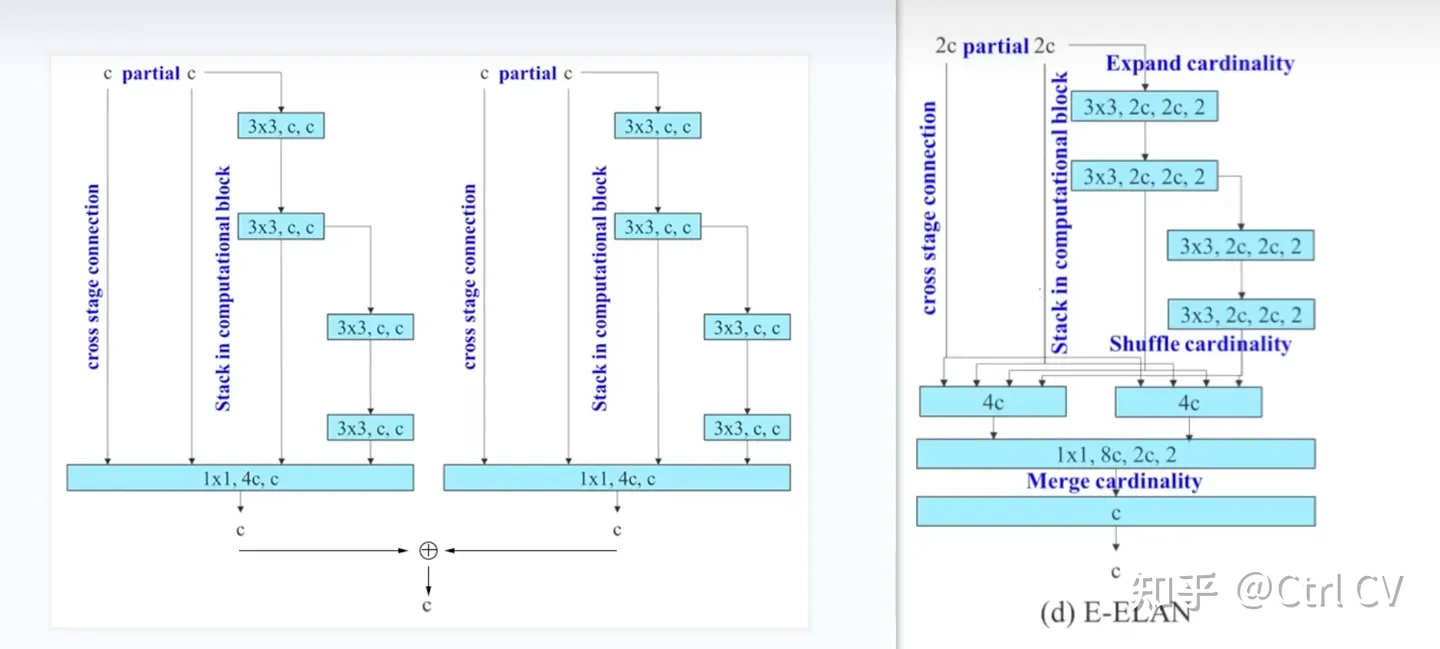
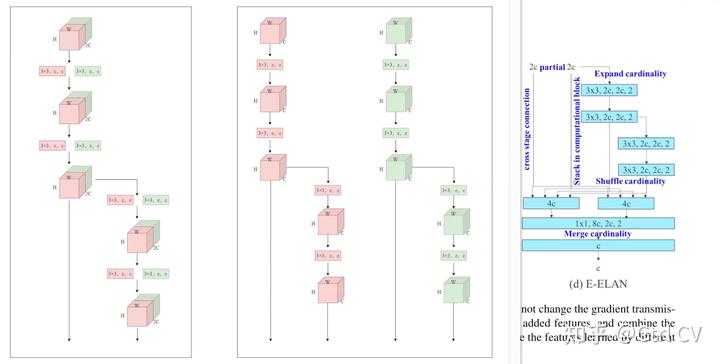
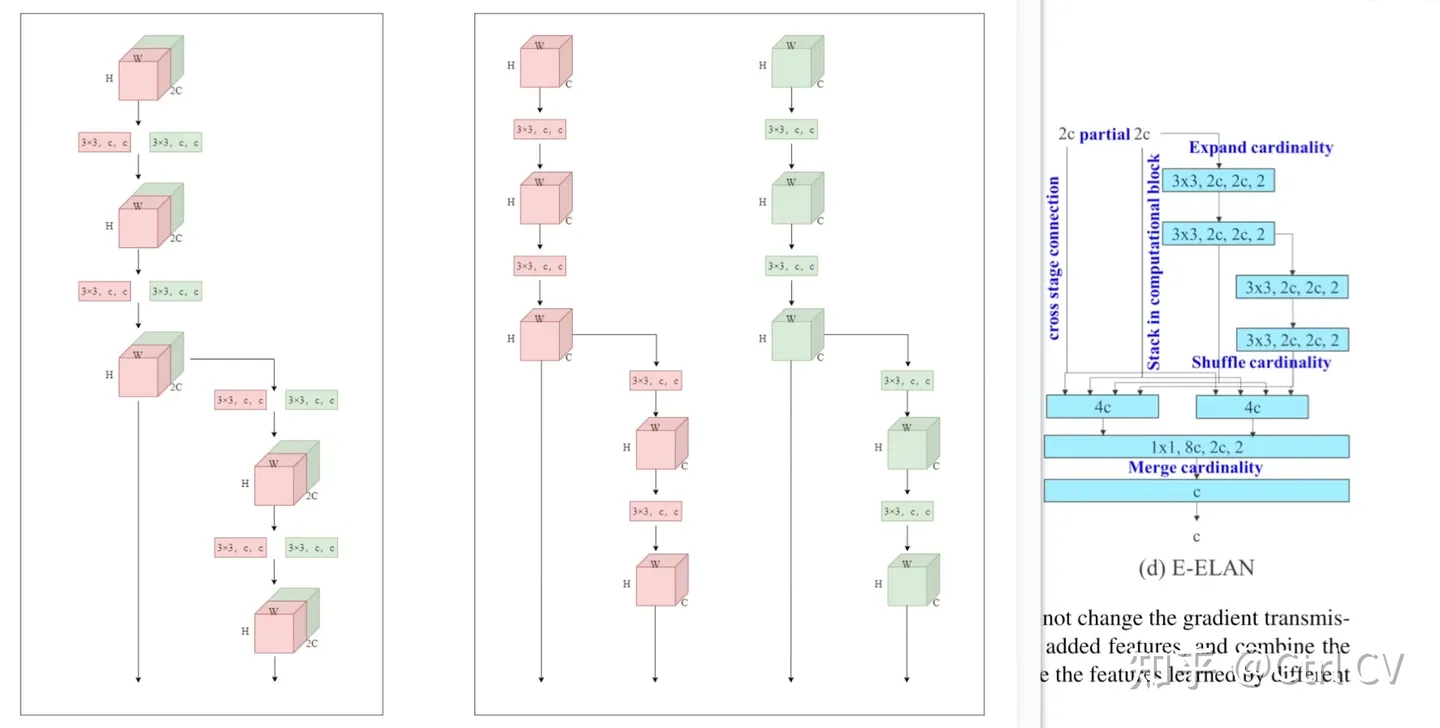
对比yolov7 e6 yaml 与 yolov7 e6e yaml
yolov7 模型缩放


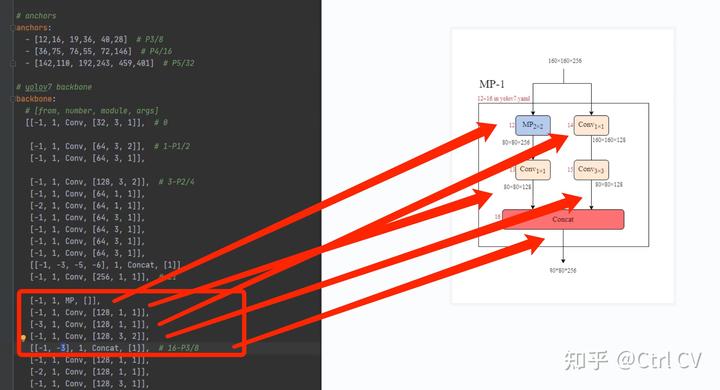
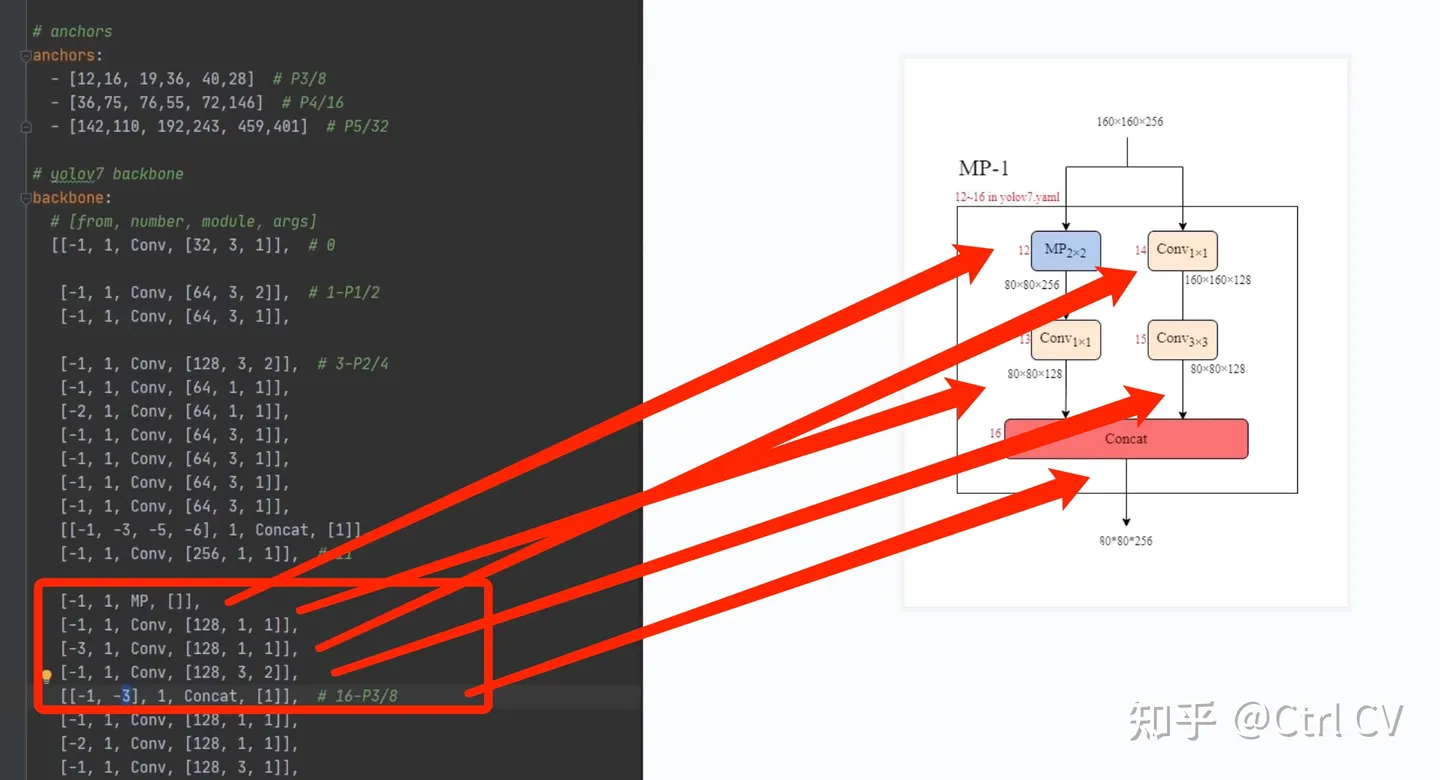
MP1
Conv块 又称为 CBS
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
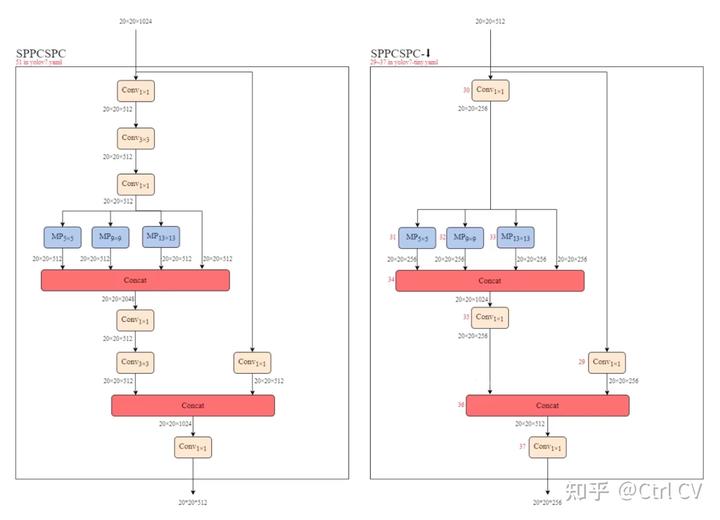
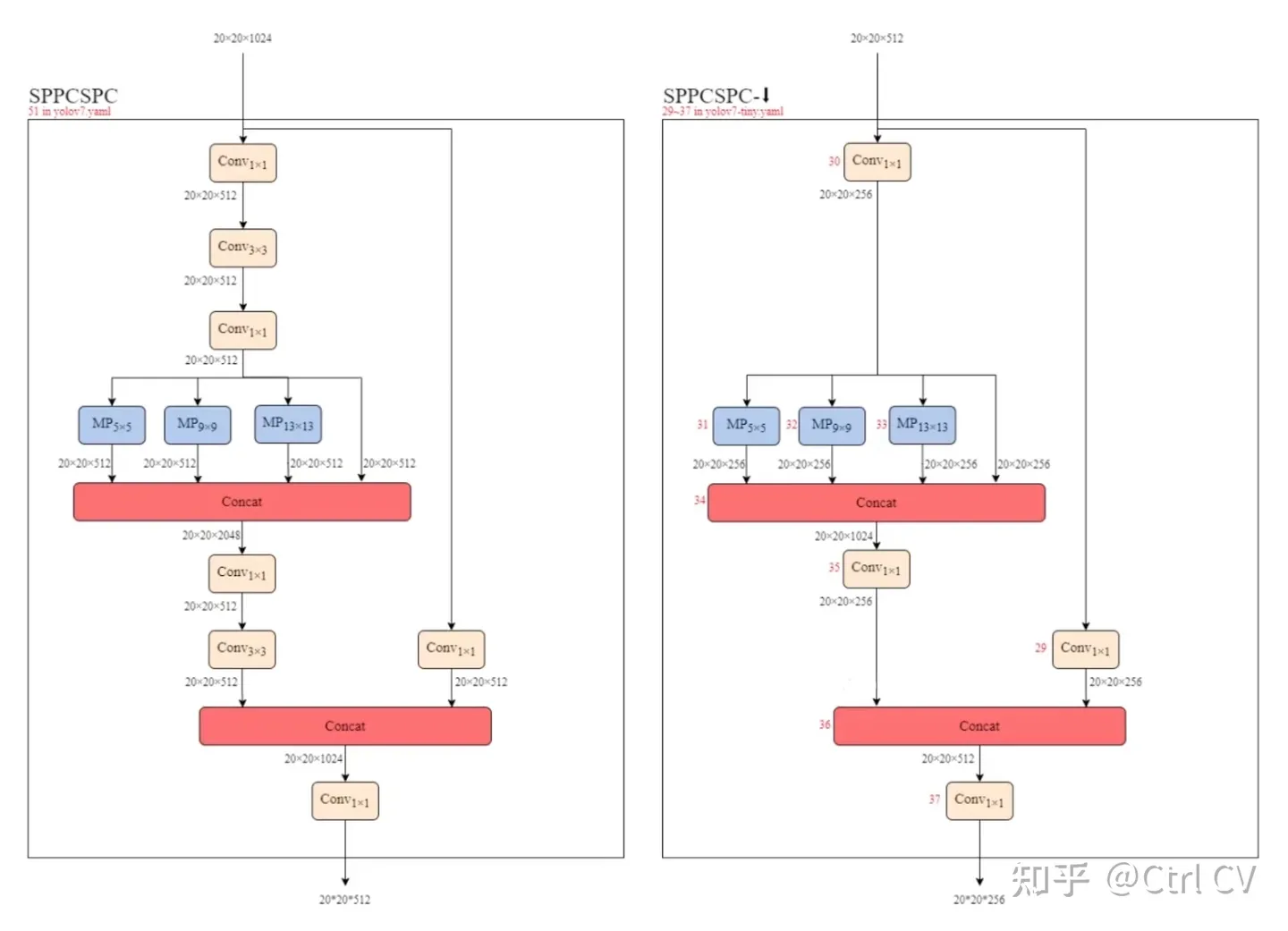
</code></pre></div><p class="ztext-empty-paragraph"><br></p><p data-pid="EnzX62aN">sppcspc结构</p><figure data-size="normal"><noscript><img src="https://pic1.zhimg.com/v2-5fc005fc207fc6b7c419437045b81774_b.jpg" data-caption="" data-size="normal" data-rawwidth="2174" data-rawheight="1196" class="origin_image zh-lightbox-thumb" width="2174" data-original="https://pic1.zhimg.com/v2-5fc005fc207fc6b7c419437045b81774_r.jpg"/></noscript><div><img src="https://pic1.zhimg.com/80/v2-5fc005fc207fc6b7c419437045b81774_1440w.webp" data-caption="" data-size="normal" data-rawwidth="2174" data-rawheight="1196" class="origin_image zh-lightbox-thumb lazy" width="2174" data-original="https://pic1.zhimg.com/v2-5fc005fc207fc6b7c419437045b81774_r.jpg" data-actualsrc="https://pic1.zhimg.com/v2-5fc005fc207fc6b7c419437045b81774_b.jpg" data-original-token="v2-21a5d69f0847febff325c6443c8eda95" height="1196" data-lazy-status="ok" style=""></div></figure><div class="highlight"><pre><code class="language-text">##### cspnet #####
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def init(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).init()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))</code></pre></div><p data-pid="71_j5DnC">比较之前的ELAN模块这里有所不同:</p><figure data-size="normal"><noscript><img src="https://pic2.zhimg.com/v2-655133b74bdcc93a3900049e46ba9099_b.jpg" data-caption="" data-size="normal" data-rawwidth="2184" data-rawheight="1232" class="origin_image zh-lightbox-thumb" width="2184" data-original="https://pic2.zhimg.com/v2-655133b74bdcc93a3900049e46ba9099_r.jpg"/></noscript><div><img src="https://pic2.zhimg.com/80/v2-655133b74bdcc93a3900049e46ba9099_1440w.webp" data-caption="" data-size="normal" data-rawwidth="2184" data-rawheight="1232" class="origin_image zh-lightbox-thumb lazy" width="2184" data-original="https://pic2.zhimg.com/v2-655133b74bdcc93a3900049e46ba9099_r.jpg" data-actualsrc="https://pic2.zhimg.com/v2-655133b74bdcc93a3900049e46ba9099_b.jpg" data-original-token="v2-0d281003e9e4eedb43c6eb0a3a97e283" height="1232" data-lazy-status="ok" style=""></div></figure><figure data-size="normal"><noscript><img src="https://pic2.zhimg.com/v2-5c0d0730892cd5b92c3d36023e16b99d_b.jpg" data-caption="" data-size="normal" data-rawwidth="2254" data-rawheight="922" class="origin_image zh-lightbox-thumb" width="2254" data-original="https://pic2.zhimg.com/v2-5c0d0730892cd5b92c3d36023e16b99d_r.jpg"/></noscript><div><img src="https://pic2.zhimg.com/80/v2-5c0d0730892cd5b92c3d36023e16b99d_1440w.webp" data-caption="" data-size="normal" data-rawwidth="2254" data-rawheight="922" class="origin_image zh-lightbox-thumb lazy" width="2254" data-original="https://pic2.zhimg.com/v2-5c0d0730892cd5b92c3d36023e16b99d_r.jpg" data-actualsrc="https://pic2.zhimg.com/v2-5c0d0730892cd5b92c3d36023e16b99d_b.jpg" data-original-token="v2-34d09e564a779cfbfdf2c350f84d40cd" height="922" data-lazy-status="ok" style=""></div></figure><p data-pid="6ZU1zHOU">MP2</p><figure data-size="normal"><noscript><img src="https://pic4.zhimg.com/v2-8c544179619f143db15fee02cfb2ddff_b.jpg" data-caption="" data-size="normal" data-rawwidth="1994" data-rawheight="1140" class="origin_image zh-lightbox-thumb" width="1994" data-original="https://pic4.zhimg.com/v2-8c544179619f143db15fee02cfb2ddff_r.jpg"/></noscript><div><img src="https://pic4.zhimg.com/80/v2-8c544179619f143db15fee02cfb2ddff_1440w.webp" data-caption="" data-size="normal" data-rawwidth="1994" data-rawheight="1140" class="origin_image zh-lightbox-thumb lazy" width="1994" data-original="https://pic4.zhimg.com/v2-8c544179619f143db15fee02cfb2ddff_r.jpg" data-actualsrc="https://pic4.zhimg.com/v2-8c544179619f143db15fee02cfb2ddff_b.jpg" data-original-token="v2-69aaab5f7505458b1741617cb7242003" height="1140" data-lazy-status="ok" style=""></div></figure><p data-pid="CjInuHPu">比较MP1 MP2</p><figure data-size="normal"><noscript><img src="https://pic2.zhimg.com/v2-2a01daa475923528d2d9fd823abc8a39_b.jpg" data-caption="" data-size="normal" data-rawwidth="1966" data-rawheight="752" class="origin_image zh-lightbox-thumb" width="1966" data-original="https://pic2.zhimg.com/v2-2a01daa475923528d2d9fd823abc8a39_r.jpg"/></noscript><div><img src="https://pic2.zhimg.com/80/v2-2a01daa475923528d2d9fd823abc8a39_1440w.webp" data-caption="" data-size="normal" data-rawwidth="1966" data-rawheight="752" class="origin_image zh-lightbox-thumb lazy" width="1966" data-original="https://pic2.zhimg.com/v2-2a01daa475923528d2d9fd823abc8a39_r.jpg" data-actualsrc="https://pic2.zhimg.com/v2-2a01daa475923528d2d9fd823abc8a39_b.jpg" data-original-token="v2-74e23704aba0fa33820c2783be2aad2a" height="752" data-lazy-status="ok" style=""></div></figure><p data-pid="4JSmLSxl">RepConv结构</p><div class="highlight"><pre><code class="language-text">##### repvgg #####
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return (
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
bias3x3 + bias1x1 + biasid,
)
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros(
(self.in_channels, input_dim, 3, 3), dtype=np.float32
)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return (
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),
)
def fuse_conv_bn(self, conv, bn):
std = (bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t = (bn.weight / std).reshape(-1, 1, 1, 1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels = conv.in_channels,
out_channels = conv.out_channels,
kernel_size = conv.kernel_size,
stride=conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups,
bias = True,
padding_mode = conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)
return conv
def fuse_repvgg_block(self):
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
# Fuse self.rbr_identity
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity, nn.modules.batchnorm.SyncBatchNorm)):
# print(f"fuse: rbr_identity == BatchNorm2d or SyncBatchNorm")
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
# print(f"fuse: rbr_identity != BatchNorm2d, rbr_identity = {self.rbr_identity}")
bias_identity_expanded = torch.nn.Parameter( torch.zeros_like(rbr_1x1_bias) )
weight_identity_expanded = torch.nn.Parameter( torch.zeros_like(weight_1x1_expanded) )
#print(f"self.rbr_1x1.weight = {self.rbr_1x1.weight.shape}, ")
#print(f"weight_1x1_expanded = {weight_1x1_expanded.shape}, ")
#print(f"self.rbr_dense.weight = {self.rbr_dense.weight.shape}, ")
self.rbr_dense.weight = torch.nn.Parameter(self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None
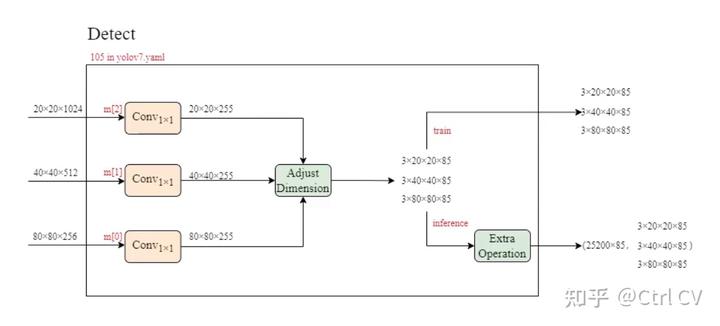
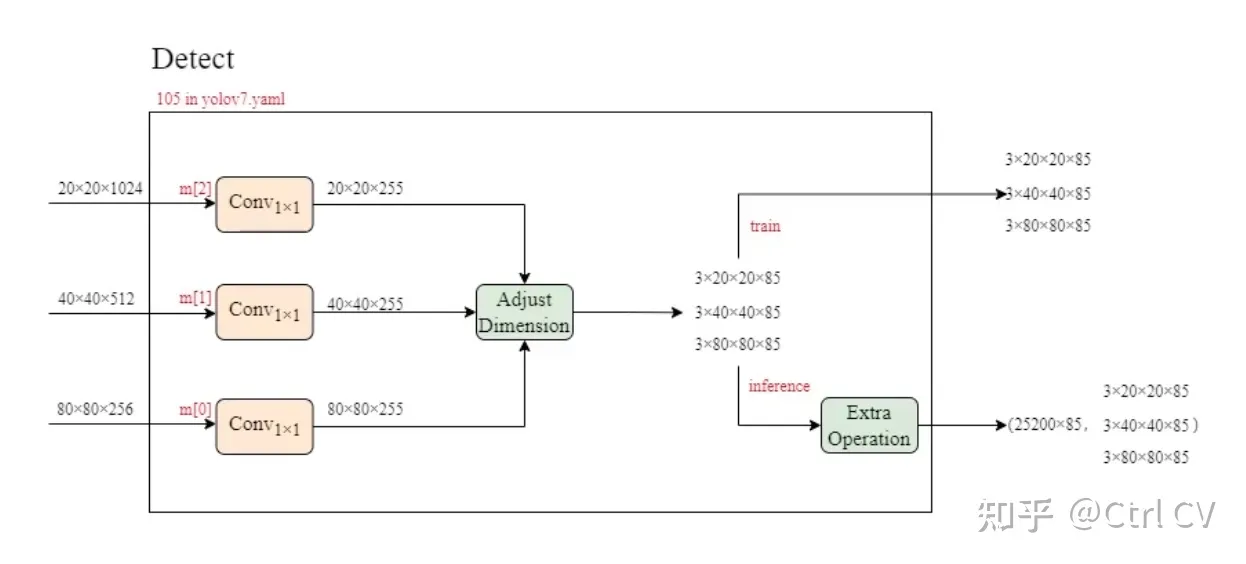
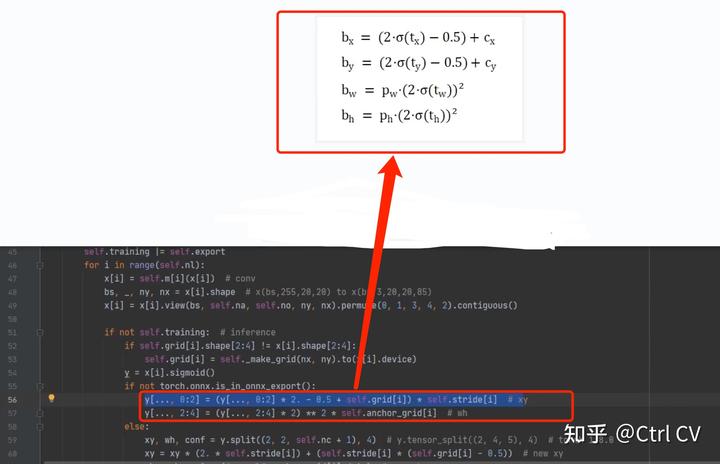
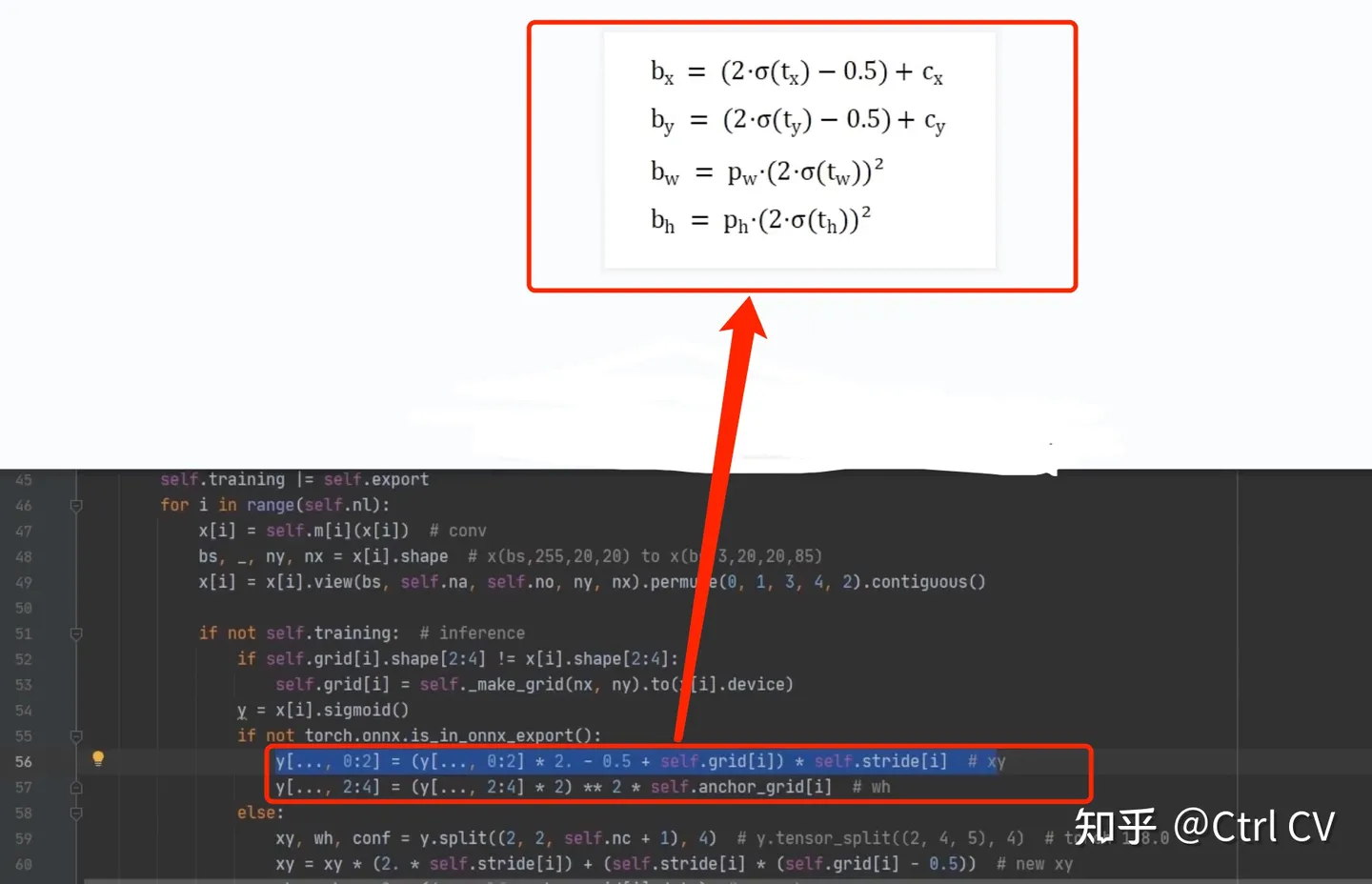
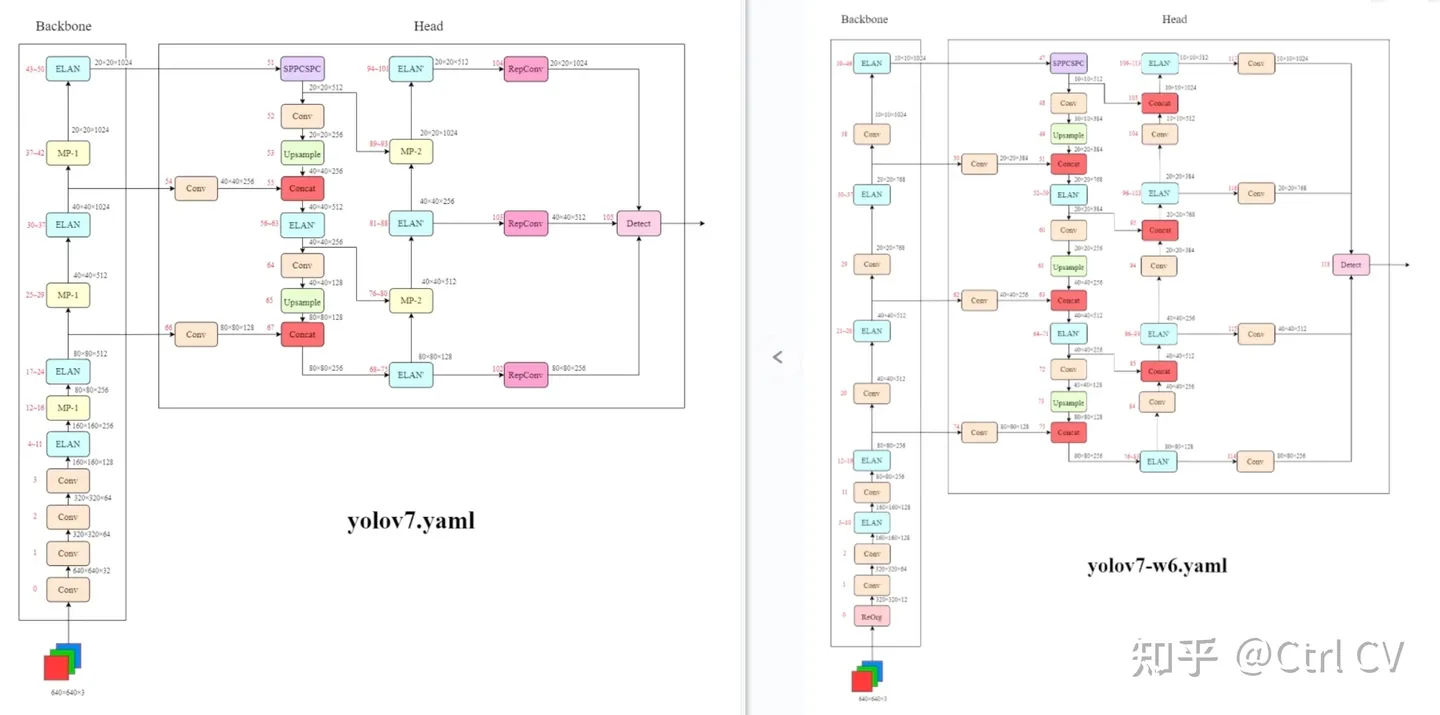
yolov7-w6
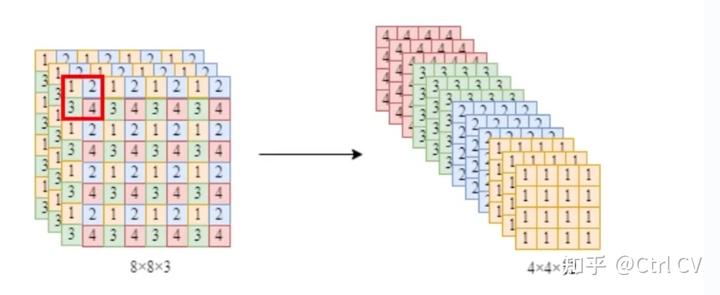
ReOrg模块
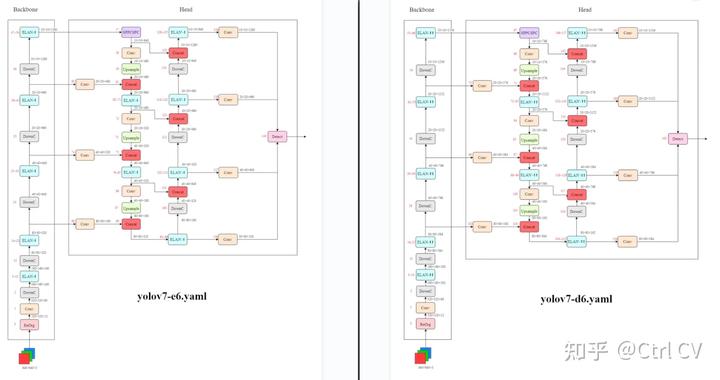
yolov7-e6
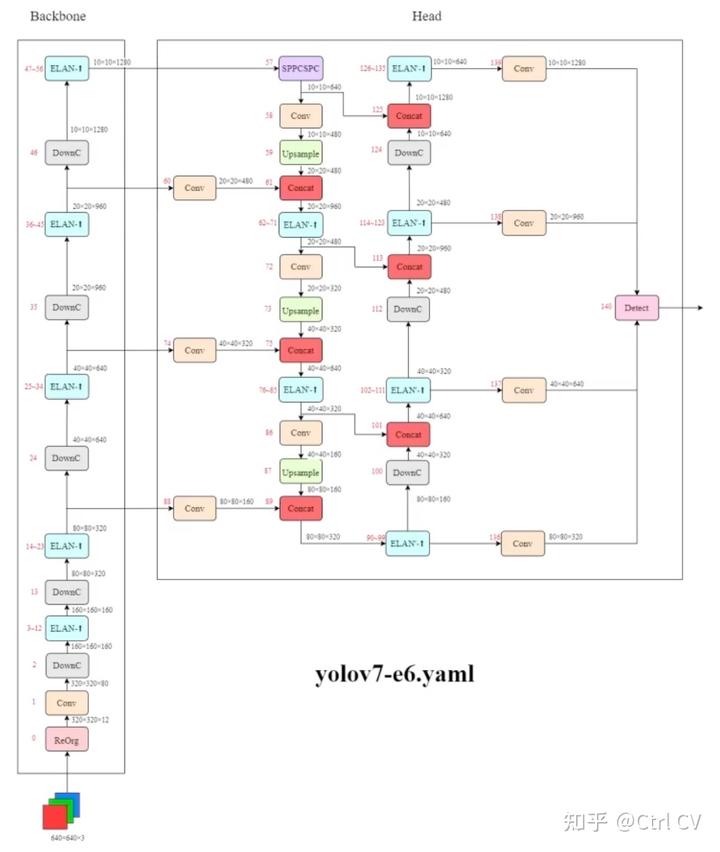
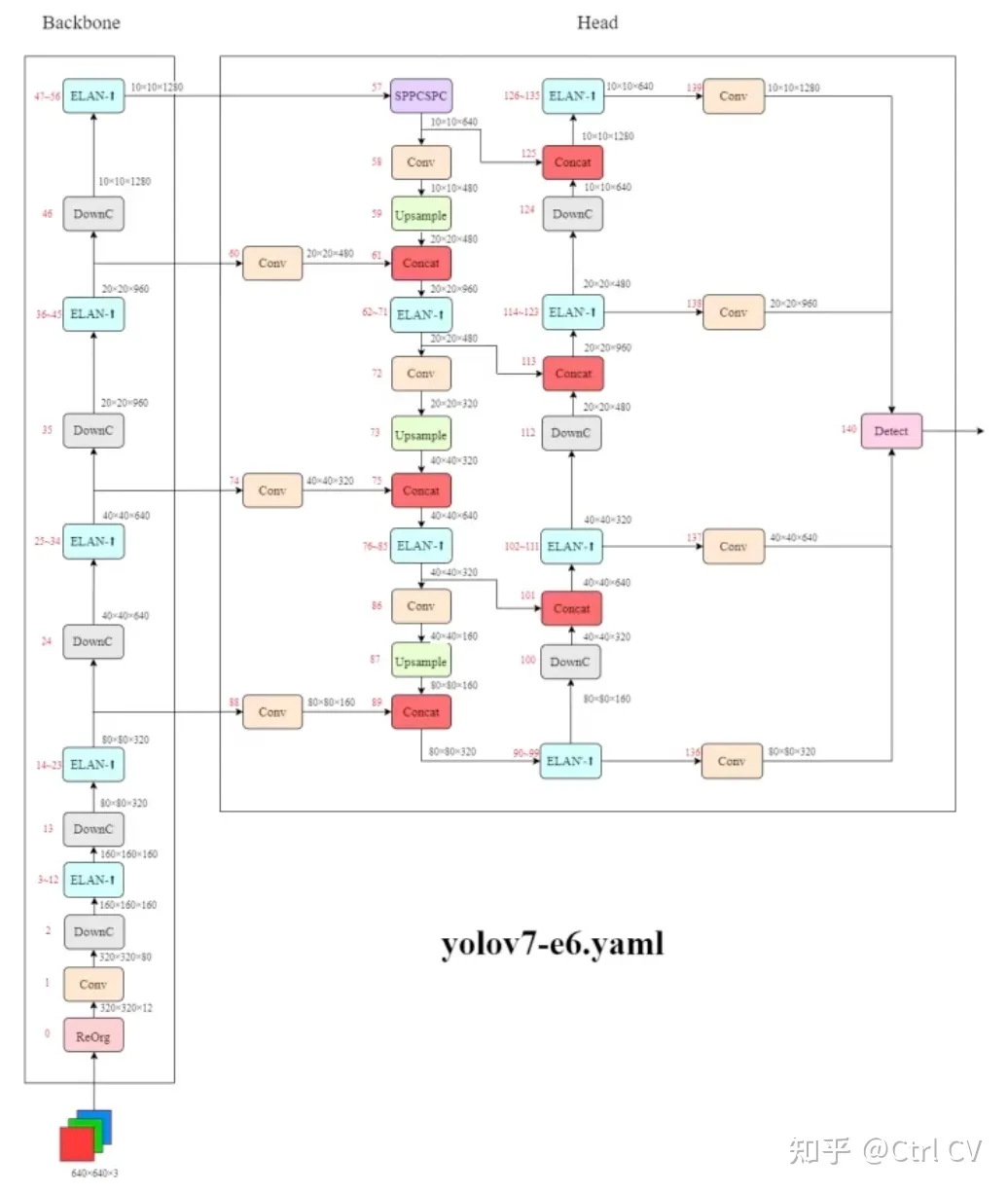
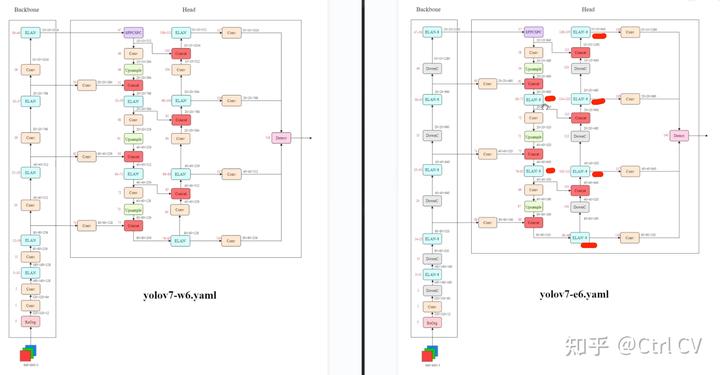
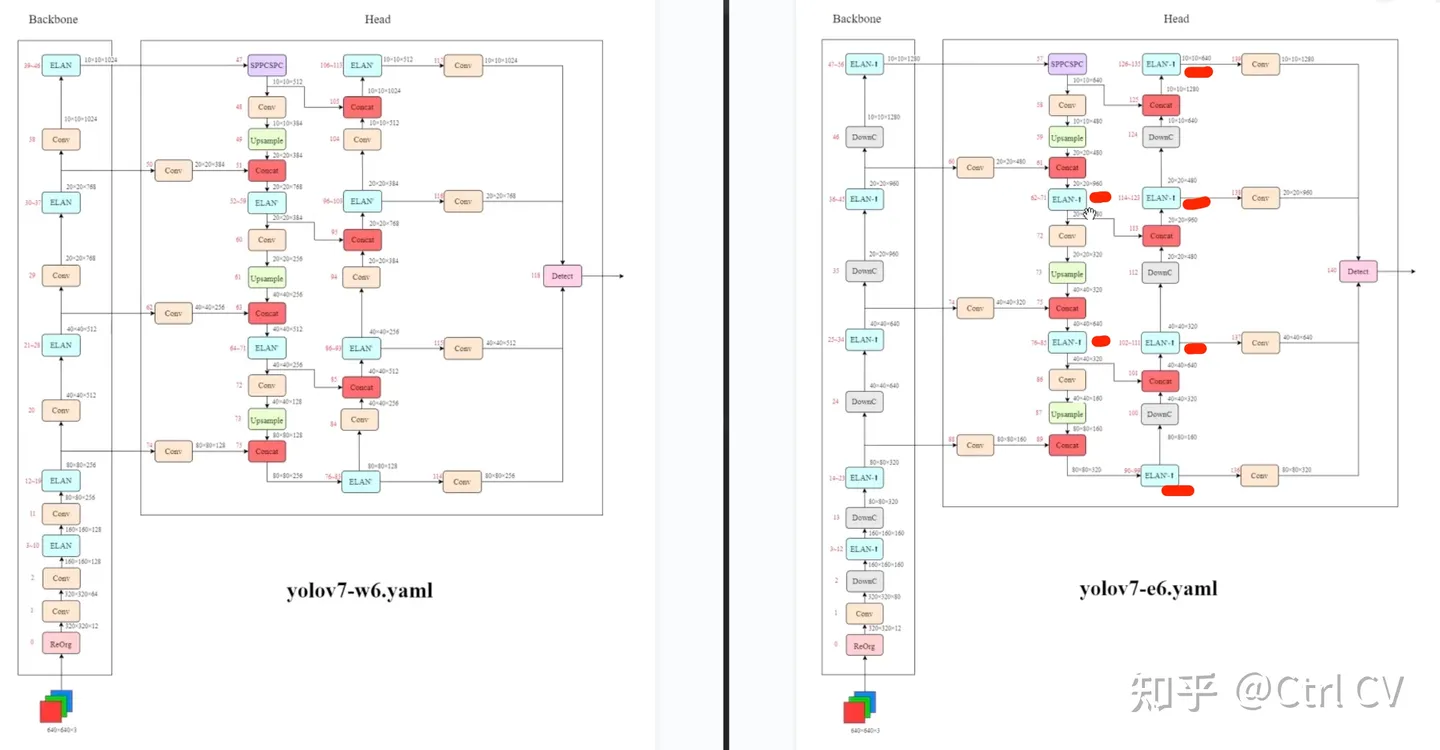
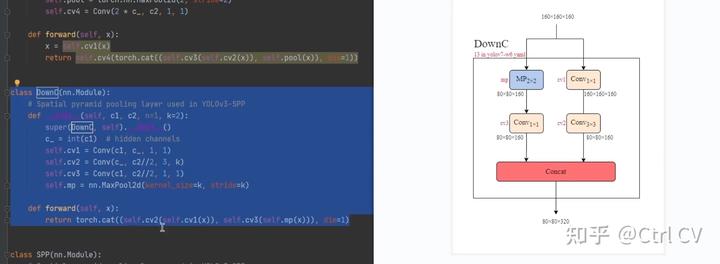
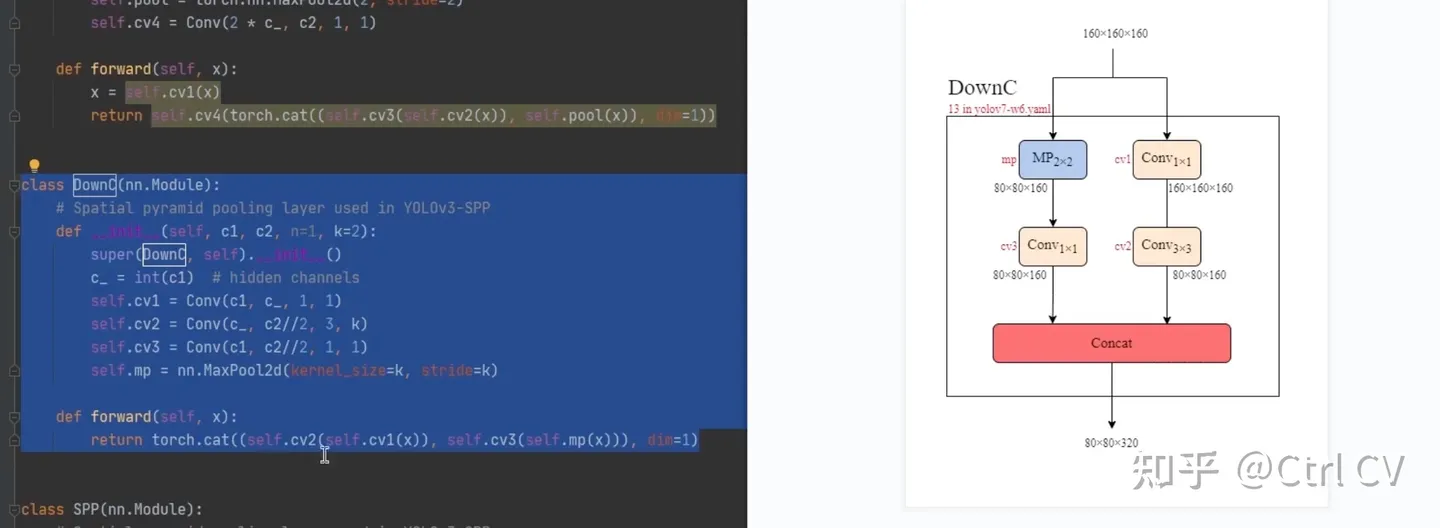
DowmC结构
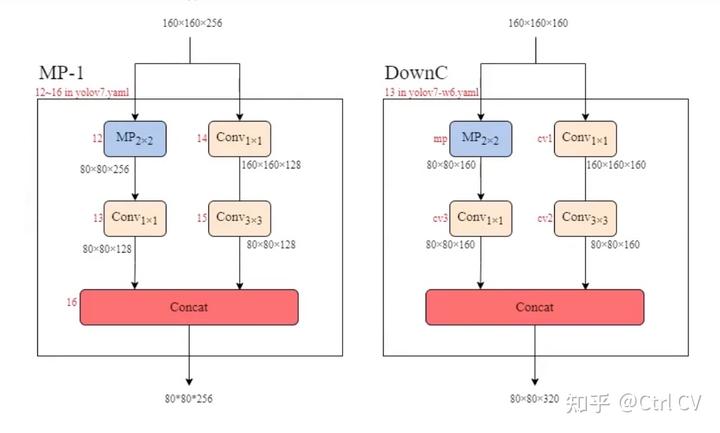
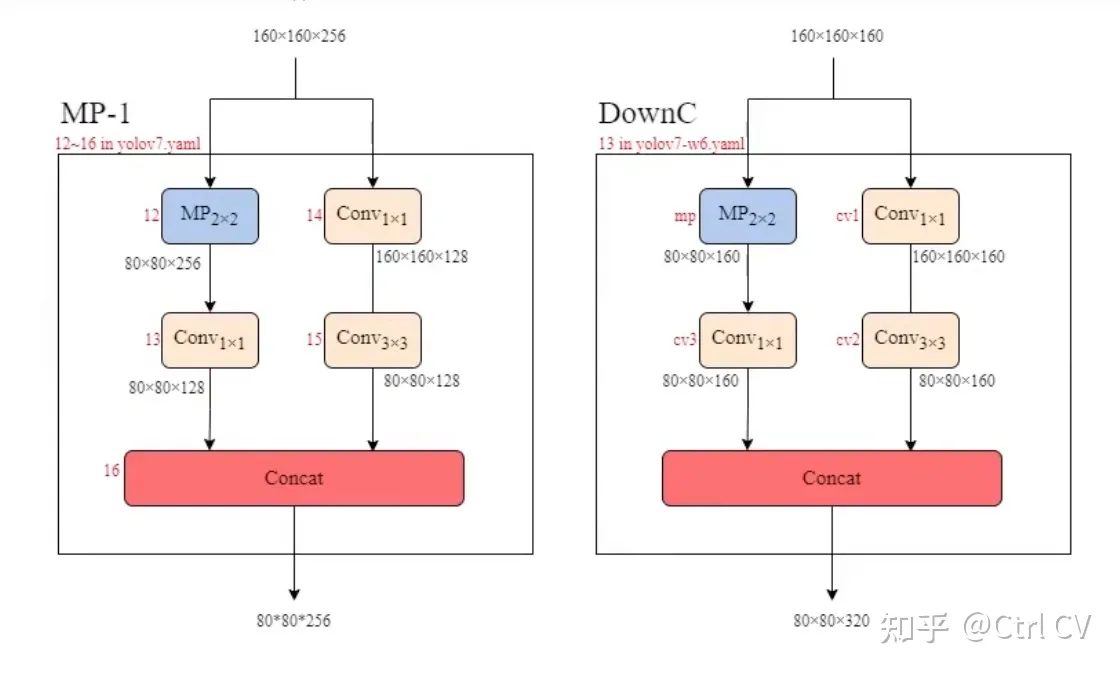
yolov7-d6
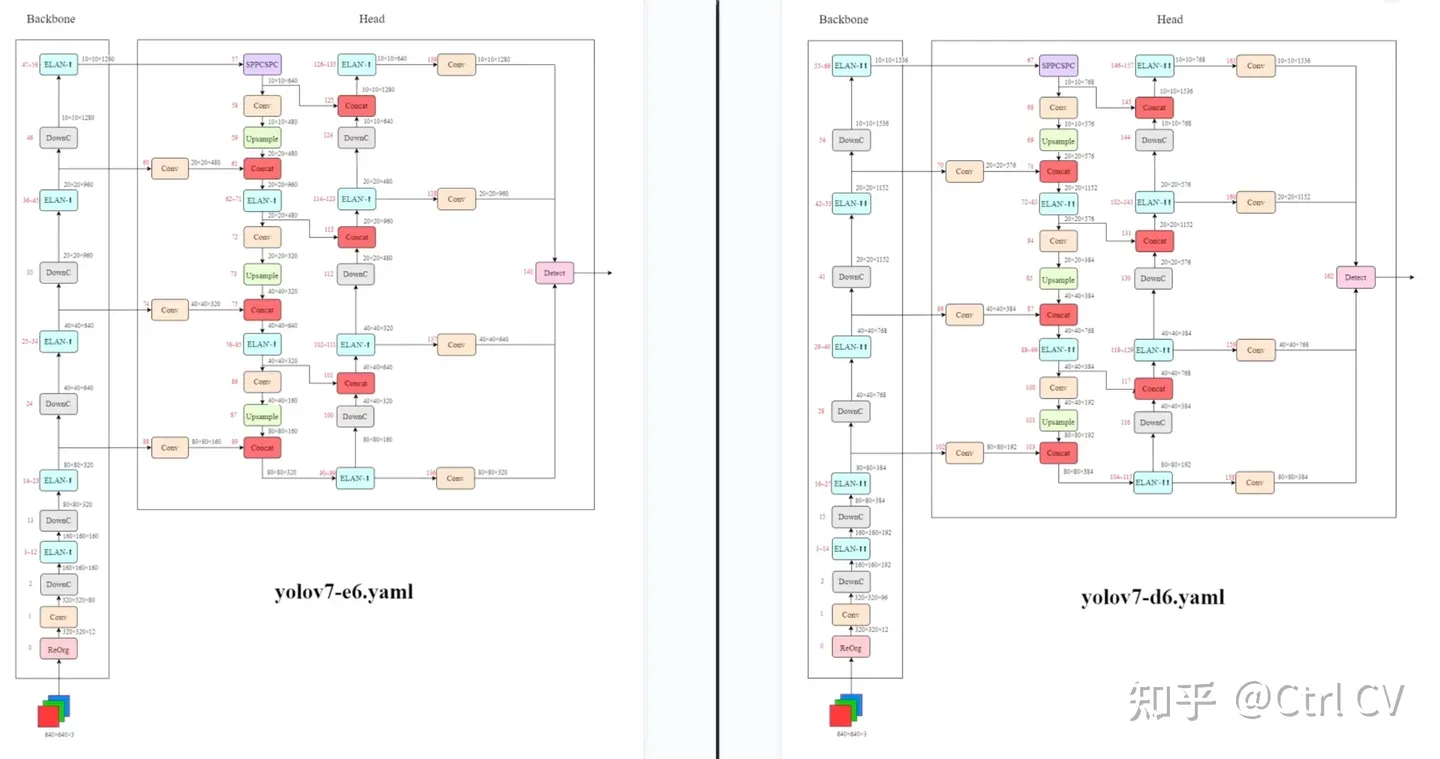
yolov7e6e
yolov7-tiny
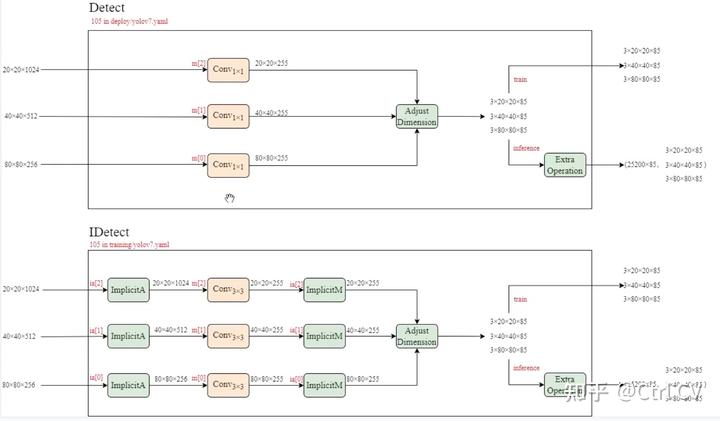
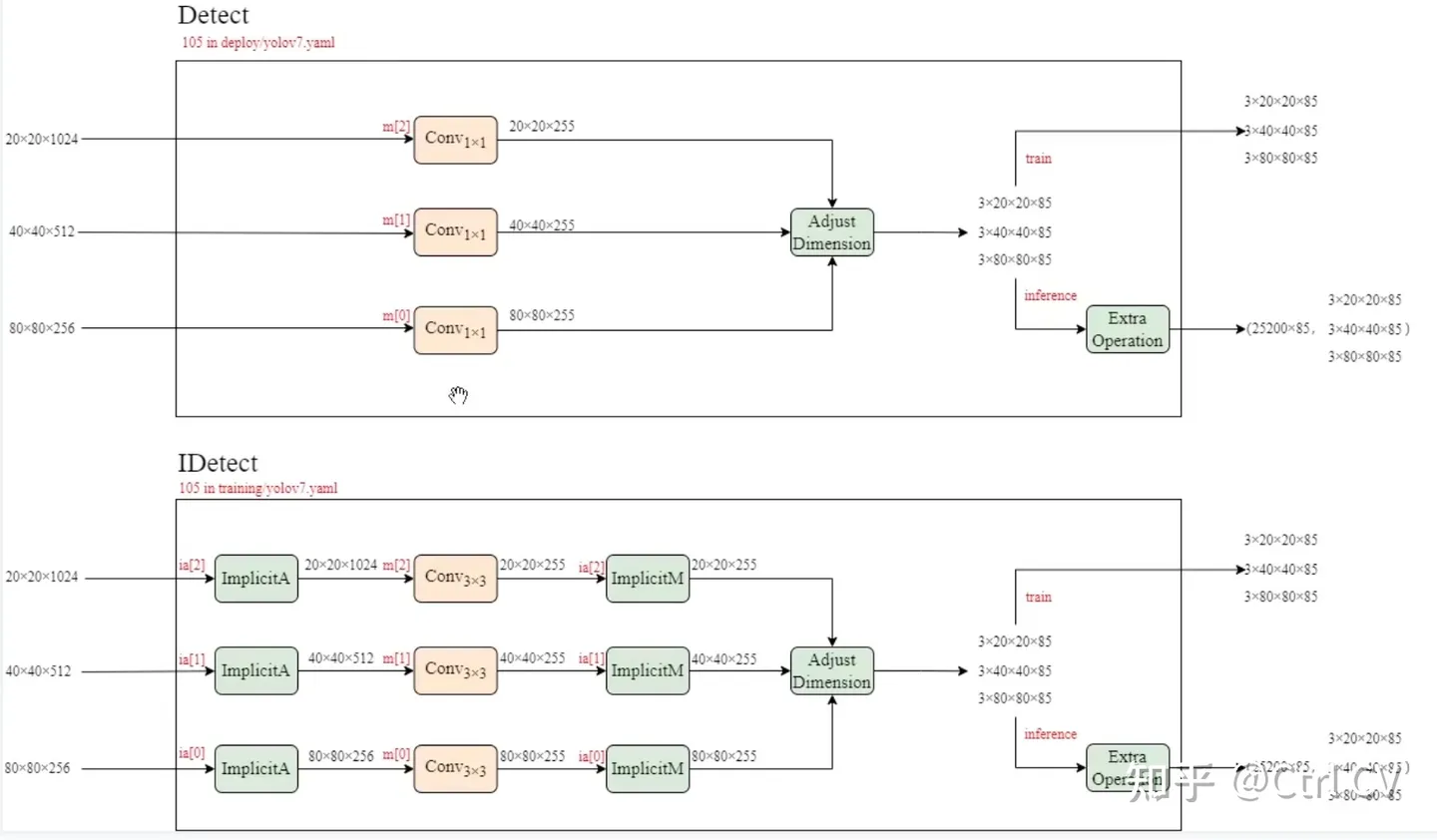
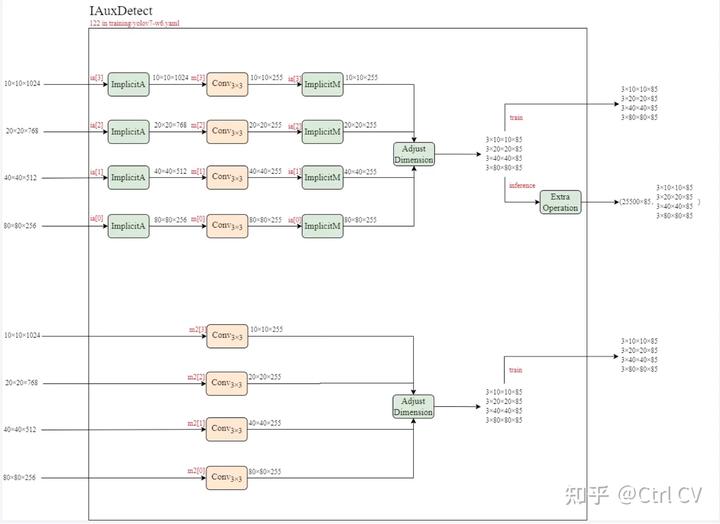
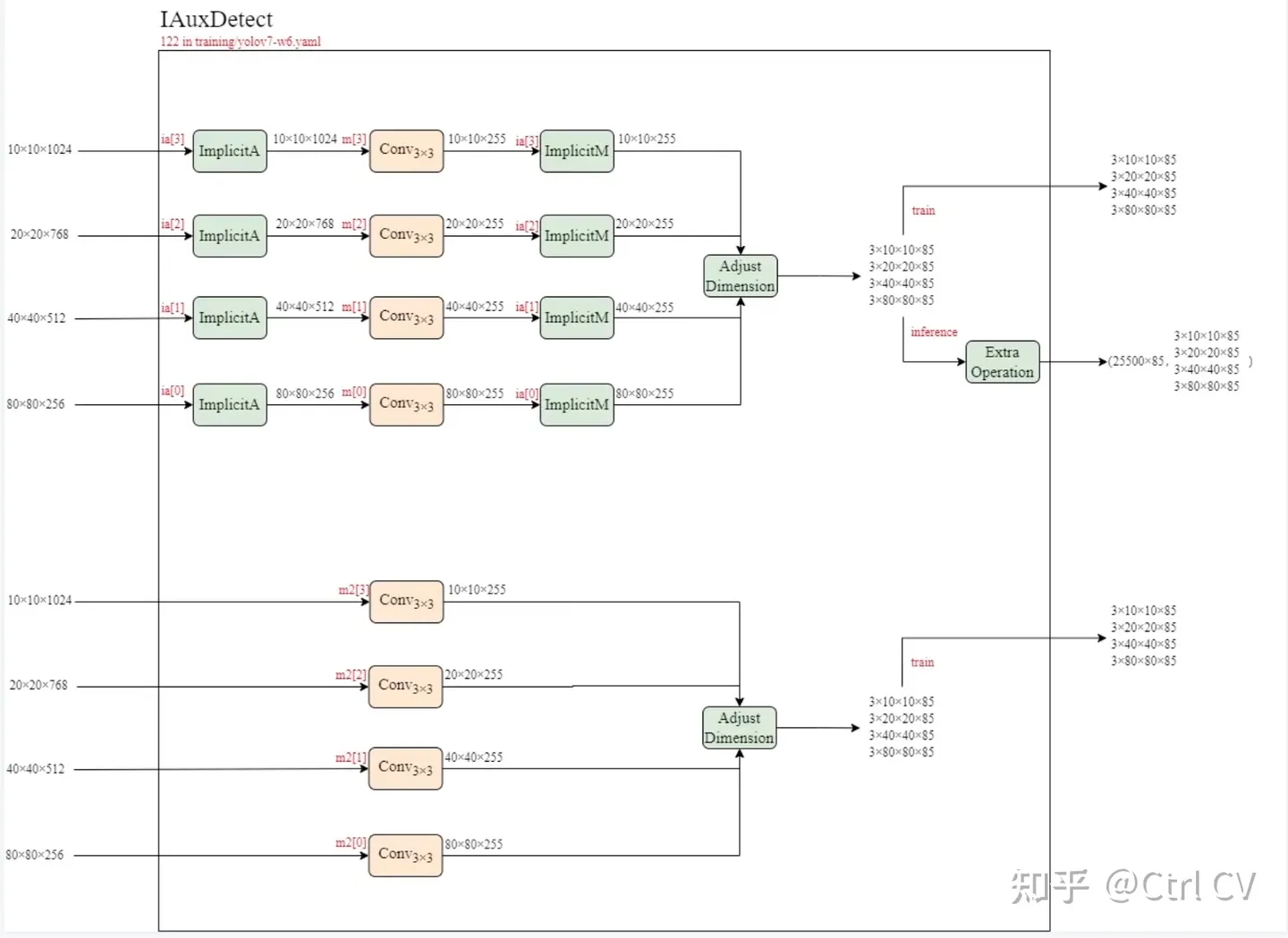
yolov7训练自己的数据集与yolov5类似,参考之前的文章。

















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









