







 本文介绍了一个基于Apache Flink的应用程序示例——Socket Text Stream WordCount,演示了如何从socket读取文本流并进行词频统计。该示例包括设置执行环境、获取输入数据、扁平映射字符串分割等功能。
本文介绍了一个基于Apache Flink的应用程序示例——Socket Text Stream WordCount,演示了如何从socket读取文本流并进行词频统计。该示例包括设置执行环境、获取输入数据、扁平映射字符串分割等功能。
应用程序示例2:
public class SocketTextStreamWordCount {
public static void main(String[] args) throws Exception {
if (args.length != 2){
System.err.println("USAGE:\nSocketTextStreamWordCount <hostname> <port>");
return;
}
String hostName = args[0];
Integer port = Integer.parseInt(args[1]);
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data
DataStream<String> text = env.socketTextStream(hostName, port).setParallelism(1);
text.flatMap(new LineSplitter()).setParallelism(2) // group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1).setParallelism(2)
.print();
env.execute("Java WordCount from SocketTextStream Example");
}
/**
* Implements the string tokenizer that splits sentences into words as a user-defined
* FlatMapFunction. The function takes a line (String) and splits it into
* multiple pairs in the form of "(word,1)" (Tuple2<String, Integer>).
*/
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}其转化分析如下:
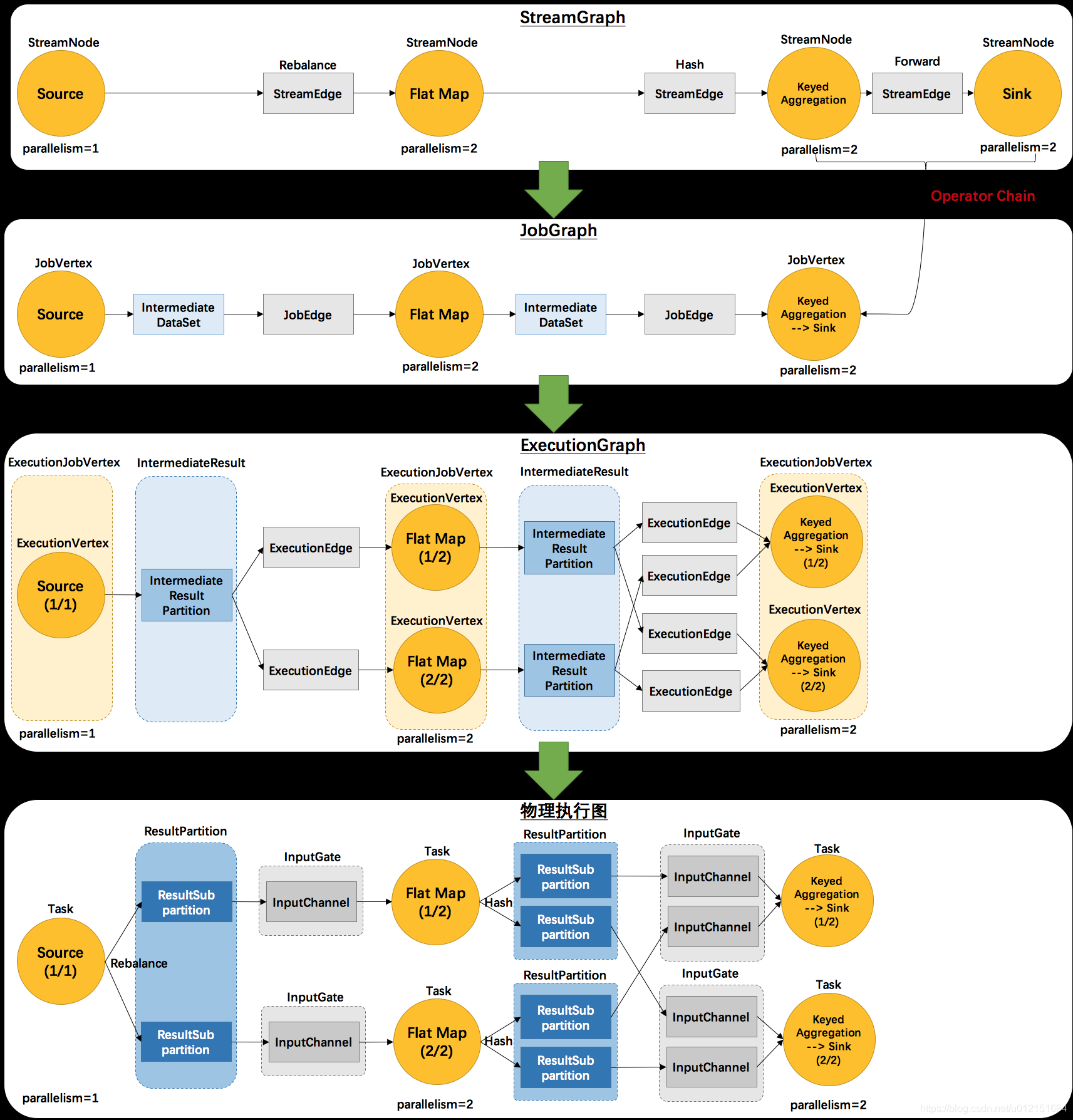
上面这张图清晰的给出了flink各个图的工作原理和转换过程。其中最后一个物理执行图并非flink的数据结构,而是程序开始执行后,各个task分布在不同的节点上,所形成的物理上的关系表示。
- 从JobGraph的图里可以看到,数据从上一个operator流到下一个operator的过程中,上游作为生产者提供了IntermediateDataSet,而下游作为消费者需要JobEdge。事实上,JobEdge是一个通信管道,连接了上游生产的dataset和下游的JobVertex节点。
- 在JobGraph转换到ExecutionGraph的过程中,主要发生了以下转变:
- 加入了并行度的概念,成为真正可调度的图结构
- 生成了与JobVertex对应的ExecutionJobVertex,ExecutionVertex,与IntermediateDataSet对应的IntermediateResult和IntermediateResultPartition等,并行将通过这些类实现
- ExecutionGraph已经可以用于调度任务。可以看到flink根据该图生成了一一对应的Task,每个task对应一个ExecutionGraph的一个Execution。Task用InputGate、InputChannel和ResultPartition对应了上面图中的IntermediateResult和ExecutionEdge。
其中StreamGraph是对用户逻辑的映射。JobGraph在此基础上进行了一些优化,比如把一部分操作串成chain以提高效率。ExecutionGraph是为了调度存在的,加入了并行处理的概念。而在此基础上真正执行的是Task及其相关结构。

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









