







针对前面程序的transformation操作转化分析过程,能够得到StreamGraph、JobGraph的划分、具体生成过程以及链路形式,这两个执行图的转化生成都是在client本地客户端。而最终flink Job运行时调度层核心的执行图-ExecutionGraph是在服务端(JobManager)中生成的。Client向JobManager提交JobGraph后,JobManage就会根据JobGraph来创建对应的ExecutionGraph,并以最终生成的ExecutionGraph来调度任务。ExecutionGraph在实际处理转化上只是改动了JobGraph的每个节点,而没有对整个拓扑结构进行变动;在JobGraph转换到ExecutionGraph的过程中,主要发生了以下转变:
- 加入了并行度的概念,成为真正可调度的图结构
- 生成了与JobVertex对应的ExecutionJobVertex,ExecutionVertex,与IntermediateDataSet对应的IntermediateResult和IntermediateResultPartition等,并行将通过这些类实现
所以针对其代码ExecutionGraphBuilder.buildGraph(JobGraph jobGraph)的具体转化分析如下:
1、创建ExecutionGraph对象并设置基本属性
public class ExecutionGraph implements AccessExecutionGraph {
/** Job specific information like the job id, job name, job configuration, etc. */
private final JobInformation jobInformation; // job任务的基本信息
/** All job vertices that are part of this graph. */
private final ConcurrentHashMap<JobVertexID, ExecutionJobVertex> tasks; // 具体可执行的ExecutionJobVertex任务
/** All vertices, in the order in which they were created. **/
private final List<ExecutionJobVertex> verticesInCreationOrder;
/** All intermediate results that are part of this graph. */
private final ConcurrentHashMap<IntermediateDataSetID, IntermediateResult> intermediateResults; // 数据集
/** The currently executed tasks, for callbacks. */
private final ConcurrentHashMap<ExecutionAttemptID, Execution> currentExecutions;
/** Listeners that receive messages when the entire job switches it status
* (such as from RUNNING to FINISHED). */
private final List<JobStatusListener> jobStatusListeners;
/** Listeners that receive messages whenever a single task execution changes its status. */
private final List<ExecutionStatusListener> executionListeners;
/** The slot provider to use for allocating slots for tasks as they are needed. */
private final SlotProvider slotProvider;
// ------ Fields that are only relevant for archived execution graphs ------------
private String jsonPlan;
......对象创建即是调用其基本构造函数进行变量的初始化,主要设置JobInformation,SlotProvider以及上述比较重要的数据集、ExecutionJobVertex等容器对象的初始化;
其中生成ExecutionGraph最重要的代码如下:
- 生成创建初始化executionGraph对象;
- 将JobVertex在Master上进行初始化;
- 对所有的Jobvertext进行拓扑排序(所谓拓扑排序,即保证如果存在A->B的有向边,那么在排序后的列表中A 节点一定在B节点之前。这里对应着JobGraph从Source出发排序到结束);
- 对排序后的拓扑结构生成ExecutionGraph内部的节点和连接;
public static ExecutionGraph buildGraph(..., JobGraph jobGraph, ...){
......
// 赋值jobId、jobName、JobInformation等
final ExecutionGraph executionGraph;
try {
executionGraph = (prior != null) ? prior :
new ExecutionGraph(..., ..., ...); // 构造ExecutionGraph对象
} catch (IOException e) {
throw new JobException("Could not create the ExecutionGraph.", e);
}
......
// JobVertex在Master上进行初始化, 主要关注vertex.initializeOnMaster(classLoader);对应的不同类型OutputFormatVertex和InputFormatVertex
// 其他类型的vertex在这里没有什么特殊操作. File output format在这一步准备好输出目录, Input splits在这一步创建对应的splits
for (JobVertex vertex : jobGraph.getVertices()) {
......
try {
vertex.initializeOnMaster(classLoader);
}
catch (Throwable t) {
throw new JobExecutionException(jobId,
"Cannot initialize task '" + vertex.getName() + "': " + t.getMessage(), t);
}
}
// 对所有的Jobvertext进行拓扑排序, 从source出发到结束的JobVertex
// topologically sort the job vertices and attach the graph to the existing one
List<JobVertex> sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources();
if (log.isDebugEnabled()) {
log.debug("Adding {} vertices from job graph {} ({}).", sortedTopology.size(), jobName, jobId);
}
executionGraph.attachJobGraph(sortedTopology); // 对排序后的拓扑结构生成ExecutionGraph内部的节点和连接
......
// 后面就是一些针对ckp配置的恢复操作配置
}其中最主要的是:针对排序后的拓扑结构生成ExecutionGraph内部的节点和连接
// 对排序了的拓扑结构进行ExecutionGraph内部的节点和连接
public void attachJobGraph(List<JobVertex> topologiallySorted) throws JobException {
LOG.debug("Attaching {} topologically sorted vertices to existing job graph with {} " +
"vertices and {} intermediate results.",
topologiallySorted.size(), tasks.size(), intermediateResults.size());
final ArrayList<ExecutionJobVertex> newExecJobVertices = new ArrayList<>(topologiallySorted.size());
final long createTimestamp = System.currentTimeMillis();
for (JobVertex jobVertex : topologiallySorted) { // 对已排序的拓扑结构jobVertex, 进行ExecutionJobVertex节点的生成和连接
if (jobVertex.isInputVertex() && !jobVertex.isStoppable()) {
this.isStoppable = false;
}
// create the execution job vertex and attach it to the graph
// 在这里创建生成ExecutionGraph的每个节点
// 首先是进行了一堆赋值,将任务信息交给要生成的图节点,以及设定并行度等
// 然后是创建本节点的IntermediateResult,根据本节点的下游节点的个数确定创建几份
// 最后是根据设定好的并行度创建用于执行task的ExecutionVertex
// 如果job有设定inputsplit的话,这里还要指定inputsplits
ExecutionJobVertex ejv = new ExecutionJobVertex(
this,
jobVertex,
1,
rpcTimeout,
globalModVersion,
createTimestamp);
// 这里要处理所有的JobEdge
// 对每个edge,获取对应的intermediateResult,并记录到本节点的输入上
// 最后,把每个ExecutorVertex和对应的IntermediateResult关联起来
ejv.connectToPredecessors(this.intermediateResults);
ExecutionJobVertex previousTask = this.tasks.putIfAbsent(jobVertex.getID(), ejv);
if (previousTask != null) {
throw new JobException(String.format("Encountered two job vertices with ID %s : previous=[%s] / new=[%s]",
jobVertex.getID(), ejv, previousTask));
}
for (IntermediateResult res : ejv.getProducedDataSets()) {
IntermediateResult previousDataSet = this.intermediateResults.putIfAbsent(res.getId(), res);
if (previousDataSet != null) {
throw new JobException(String.format("Encountered two intermediate data set with ID %s : previous=[%s] / new=[%s]",
res.getId(), res, previousDataSet));
}
}
this.verticesInCreationOrder.add(ejv);
this.numVerticesTotal += ejv.getParallelism();
newExecJobVertices.add(ejv);
}
terminationFuture = new CompletableFuture<>();
failoverStrategy.notifyNewVertices(newExecJobVertices);
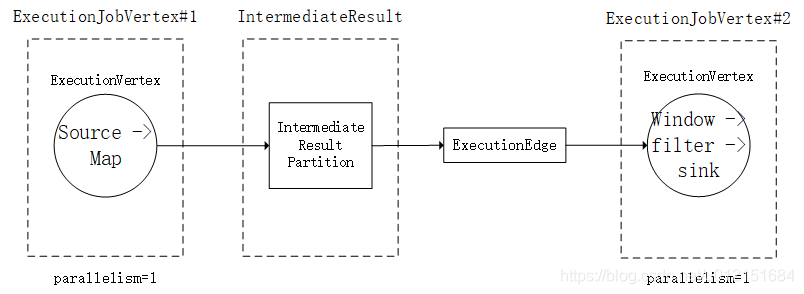
}按照拓扑排序的结果依次遍历为每个JobVertex创建对应的ExecutionJobVertex。在创建ExecutionJobVertex的时候会创建对应的ExecutionVertex,IntermediateResult,ExecutionEdge,IntermediateResultPartition等对象;我们知道,Flink Job是可以指定任务的并行度的,在实际运行时,会有多个并行的任务同时在执行,对应到这里就是ExecutionVertex。ExecutionVertex是并行任务的一个子任务,算子的并行度是多少,那么就会有多少个ExecutionVertex其内部对象具体关联对应情况如下:
- 每一个JobVertex对应一个ExecutionJobVertex;
- 每一个ExecutionJobVertex有parallelism个ExecutionVertex
- 每一个JobVertex可能有n(n>=0)个IntermediateDataSet,在ExecutionJobVertex中,一个IntermediateDataSet对应一个IntermediateResult,,每一个IntermediateResult都有parallelism个生产者produceDataSet,对应parallelism个IntermediateResultPartition;
- 每一个ExecutionJobVertex都会和前向的IntermediateResult连接,实际上是ExecutionVertex和IntermediateResultPartition建立连接,生成多个ExecutionEdge
其构造初始化结果如下:
public class ExecutionJobVertex implements AccessExecutionJobVertex, Archiveable<ArchivedExecutionJobVertex> {
private final ExecutionGraph graph; //
private final JobVertex jobVertex; // 对应的jobVertex
/**
* The IDs of all operators contained in this execution job vertex.
* <p>The ID's are stored depth-first post-order; for the forking chain below the ID's would be stored as [D, E, B, C, A].
* A - B - D
* \ \
* C E
* This is the same order that operators are stored in the {@code StreamTask}.
*/
private final List<OperatorID> operatorIDs;
/**
* The alternative IDs of all operators contained in this execution job vertex.
* <p>The ID's are in the same order as {@link ExecutionJobVertex#operatorIDs}.
*/
private final List<OperatorID> userDefinedOperatorIds;
// ExecutionVertex对应一个并行的子任务
private final ExecutionVertex[] taskVertices;
private final IntermediateResult[] producedDataSets;
private final List<IntermediateResult> inputs;
private final int parallelism;
private final SlotSharingGroup slotSharingGroup;
private final CoLocationGroup coLocationGroup;
private final InputSplit[] inputSplits;
private int maxParallelism;public ExecutionJobVertex(ExecutionGraph graph, JobVertex jobVertex, int defaultParallelism, ...) throws JobException {
......
this.graph = graph;
this.jobVertex = jobVertex;
// 并行度设置
// 获取jobVertex中的并行度 并与默认的并行度(1)进行比较; 后续会按照并行度大小 设置初始化ExecutionVertex
int vertexParallelism = jobVertex.getParallelism();
int numTaskVertices = vertexParallelism > 0 ? vertexParallelism : defaultParallelism;
......
this.parallelism = numTaskVertices;
this.serializedTaskInformation = null;
this.taskVertices = new ExecutionVertex[numTaskVertices]; // parallelism个ExecutionVertex
this.operatorIDs = Collections.unmodifiableList(jobVertex.getOperatorIDs());
this.userDefinedOperatorIds = Collections.unmodifiableList(jobVertex.getUserDefinedOperatorIDs());
this.inputs = new ArrayList<>(jobVertex.getInputs().size());
// take the sharing group
this.slotSharingGroup = jobVertex.getSlotSharingGroup();
this.coLocationGroup = jobVertex.getCoLocationGroup();
// create the intermediate results // 每一个JobVertex可能有n(n>=0)个IntermediateDataSet --> n个IntermediateResult
this.producedDataSets = new IntermediateResult[jobVertex.getNumberOfProducedIntermediateDataSets()];
for (int i = 0; i < jobVertex.getProducedDataSets().size(); i++) {
final IntermediateDataSet result = jobVertex.getProducedDataSets().get(i);
this.producedDataSets[i] = new IntermediateResult( // 构造IntermediateResult中,共有numTaskVertices并行度个IntermediateResultPartition
result.getId(),
this,
numTaskVertices,
result.getResultType());
}
......
// create all task vertices
for (int i = 0; i < numTaskVertices; i++) {
ExecutionVertex vertex = new ExecutionVertex( // 每一个ExecutionJobVertex有parallelism个ExecutionVertex;ExecutionVertex是并行任务的一个子任务
this,
i,
producedDataSets,
timeout,
initialGlobalModVersion,
createTimestamp,
maxPriorAttemptsHistoryLength);
this.taskVertices[i] = vertex;
}
......在JobGraph中用IntermediateDataSet表示JobVertex的对外输出,一个JobGraph可能有n(n >=0)个IntermediateDataSet输出。在ExecutionGraph中,与此对应的就是IntermediateResult。在IntermediateResult中又因为每一个IntermediateResult都有parallelism个生产者produceDataSet,对应parallelism个IntermediateResultPartition;
public class IntermediateResult {
private final IntermediateDataSetID id; // 对应的IntermediateDataSet的ID
private final ExecutionJobVertex producer; // 生产者
private final IntermediateResultPartition[] partitions; // 对应ExecutionJobVertex的并行度
private final IntermediateResultPartition[] partitions = new IntermediateResultPartition[numParallelProducers];
private final ResultPartitionType resultType;
}在每一个ExecutionVertex中都会有其对应的上游ExecutionEdge和下游IntermediateResultPartition
public class ExecutionVertex implements AccessExecutionVertex, Archiveable<ArchivedExecutionVertex> {
// --------------------------------------------------------------------------------------------
private final ExecutionJobVertex jobVertex;
private final Map<IntermediateResultPartitionID, IntermediateResultPartition> resultPartitions;
private final ExecutionEdge[][] inputEdges;
private final int subTaskIndex;
private final EvictingBoundedList<ArchivedExecution> priorExecutions;
private final Time timeout;
/** The name in the format "myTask (2/7)", cached to avoid frequent string concatenations. */
private final String taskNameWithSubtask;
private volatile CoLocationConstraint locationConstraint;
/** The current or latest execution attempt of this vertex's task. */
private volatile Execution currentExecution; // this field must never be null
}Execution是对ExecutionVertex的一次执行,通过ExecutionAttemptId来唯一标识
public class Execution implements AccessExecution, Archiveable<ArchivedExecution>, LogicalSlot.Payload {
/** The executor which is used to execute futures. */
private final Executor executor;
/** The execution vertex whose task this execution executes. */
private final ExecutionVertex vertex;
/** The unique ID marking the specific execution instant of the task. */
private final ExecutionAttemptID attemptId;
}由于ExecutionJobVertex有numParallelProducers个并行的子任务,自然对应的每一个IntermediateResult 就有numParallelProducers个生产者,每个生产者的在相应的IntermediateResult上的输出对应一个IntermediateResultPartition。IntermediateResultPartition表示的是ExecutionVertex的一个输出分区,即:
ExecutionJobVertex ------> IntermediateResult
ExecutionVertex ------> IntermediateResultPartition一个ExecutionJobVertex可能包含多个(n)个IntermediateResult,那实际上每一个并行的子任务ExecutionVertex可能会包含(n)个IntermediateResultPartition。IntermediateResultPartition的生产者是ExecutionVertex,消费者是一个或若干个ExecutionEdge。
ExecutionEdge表示ExecutionVertex的输入,通过ExecutionEdge将ExecutionVertex和IntermediateResultPartition连接起来,进而在不同的ExecutionVertex之间建立联系。
public class ExecutionEdge {
private final IntermediateResultPartition source;
private final ExecutionVertex target;
private final int inputNum;
}最终到目前为止,我们了解了StreamGraph,JobGraph和ExecutionGraph的生成过程,以及他们内部的节点和连接的对应关系。总的来说,streamGraph是最原始的,更贴近用户逻辑的DAG执行图;JobGraph是对StreamGraph的进一步优化,将能够合并的算子合并为一个节点以降低运行时数据传输的开销;ExecutionGraph则是作业运行时用来调度的执行图,可以看作是并行化版本的JobGraph,将DAG拆分到基本的调度单元。
最终可以得到从StreamGraph到JobGraph再到ExecutionGraph的流程转换图;
StreamGraph:

JobGraph:
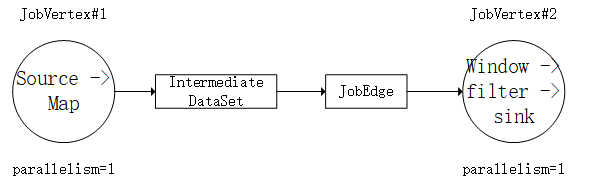
ExecutionGraph:
JsonPlan:
{
"jid": "5ec92c59c91b7b9ac75dd86d16188946",
"name": "word count run",
"nodes": [
{
"id": "90bea66de1c231edf33913ecd54406c1",
"parallelism": 1,
"operator": "",
"operator_strategy": "",
"description": "Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, ReduceFunction$2, PassThroughWindowFunction) -> Filter -> Sink: Print to Std. Out",
"inputs": [
{
"num": 0,
"id": "cbc357ccb763df2852fee8c4fc7d55f2",
"ship_strategy": "HASH",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "cbc357ccb763df2852fee8c4fc7d55f2",
"parallelism": 1,
"operator": "",
"operator_strategy": "",
"description": "Source: Custom Source -> Map",
"optimizer_properties": {}
}
]
}

















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









