







 本文聚焦于无监督学习中的聚类算法,先提及KMeans等“硬”聚类算法,引出模糊聚类中的FCM算法。详细介绍了FCM算法的大致原理、通过示例展示其聚类效果及API使用,阐述了算法过程,还指出该算法存在易陷入局部最优、受初始化隶属度矩阵影响的缺点。
本文聚焦于无监督学习中的聚类算法,先提及KMeans等“硬”聚类算法,引出模糊聚类中的FCM算法。详细介绍了FCM算法的大致原理、通过示例展示其聚类效果及API使用,阐述了算法过程,还指出该算法存在易陷入局部最优、受初始化隶属度矩阵影响的缺点。
(起笔于20200109 16点15分)
0. 引言
聚类方法在无监督学习中具有非常重要的意义,由于没有标签的存在,而我们又有将数据分成不同组的需要,所以就引出了聚类算法,例如KMeans,DBSCAN等。其中KMeans作为一种非常有效的方法,被广泛使用,该种方法通过在样本空间中,以缩小各个样本与类别(类别数目需要事先指定)中心的距离作为优化目标,最后实现聚类的效果。平时的使用过程中,我们也会将聚类算法作为一种数据前期探究过程的一种方法,通过这种方法查看数据的大致分布等等内容。
但前文提到的KMeans算法,属于一种“硬”聚类,每个样本有且仅有一个类别归属;但实际上,有时候我们可能需要一个度量值,来判断这个点不同类别的“归属感”,听起来有点像混合高斯分布一样的感觉,个人认为这样理解没有错误。
那么本篇文章就具体来介绍一下模糊聚类中的FCM(Fuzzy c-means Cluster)算法。
文章的内容组织如下,首先大致介绍FCM的原理,然后实际作图来说明FCM的效果(他人博客的代码),最后记录一下具体的算法。
(本人属于初步学习阶段,对于这部分内容依然还有很多理解上的不足,仅仅是作为本人的记录)
1. FCM
1.1 大致原理初识
FCM算法跟KMeans算法的流程框架大体上是很相似的,这里不展开将具体的原理,后面小节会具体展开。需要知道的是,FCM能够给每个点赋予隶属度,而这个隶属度就是他属于每个聚类中心的可能性。当然概率要满足一定的数值关系。而KMeans中的距离,也能起到这样的作用,只不过需要一定的换算关系,说不定这个数值就是我说的这种方法得来的,当然需要考证。
那么,也就是说,通过这样的聚类方法之后,每个点都有了一个隶属度关系,有这样的认识之后,那么我们首先来看看代码如何使用。
1.2 FCM的示例
这部分的代码来源于[1]-Fuzz Clustering,感兴趣的读者可以直接去查看原文。
1.2.1 导入库
import skfuzzy as fuzz
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
其中skfuzz通过命令pip install scikit-fuzzy安装。
1.2.2 生成数据
colors = ['b', 'orange', 'g', 'r', 'c', 'm', 'y', 'k', 'Brown', 'ForestGreen']
# Define three cluster centers
centers = [[1, 3],
[2, 2],
[3, 8]]
# Define three cluster sigmas in x and y, respectively
sigmas = [[0.3, 0.5],
[0.5, 0.3],
[0.5, 0.3]]
# Generate test data
np.random.seed(42) # Set seed for reproducibility
xpts = np.zeros(1)
ypts = np.zeros(1)
labels = np.zeros(1)
for i, ((xmu, ymu), (xsigma, ysigma)) in enumerate(zip(centers, sigmas)):
xpts = np.hstack((xpts, np.random.standard_normal(200) * xsigma + xmu))
ypts = np.hstack((ypts, np.random.standard_normal(200) * ysigma + ymu))
labels = np.hstack((labels, np.ones(200) * i))
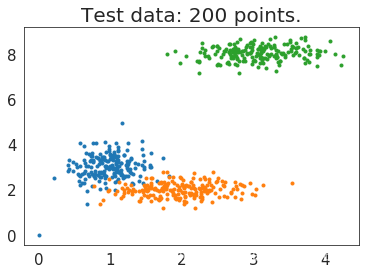
# Visualize the test data
fig0, ax0 = plt.subplots()
for label in range(3):
ax0.plot(xpts[labels == label], ypts[labels == label], '.')
ax0.set_title('Test data: 200 points.')
plt.show()
生成图片如下:
1.2.3 聚类效果
# Set up the loop and plot
fig1, axes1 = plt.subplots(3, 3, figsize=(10, 10))
alldata = np.vstack((xpts, ypts))
fpcs = []
for ncenters, ax in enumerate(axes1.reshape(-1), 2):
cntr, u, u0, d, jm, p, fpc = fuzz.cluster.cmeans(
alldata, ncenters, 2, error=0.005, maxiter=1000, init=None)
# Store fpc values for later
fpcs.append(fpc)
# Plot assigned clusters, for each data point in training set
cluster_membership = np.argmax(u, axis=0)
for j in range(ncenters):
ax.plot(xpts[cluster_membership == j],
ypts[cluster_membership == j], '.', color=colors[j])
# Mark the center of each fuzzy cluster
for pt in cntr:
ax.plot(pt[0], pt[1], 'rs')
ax.set_title('Centers = {0}; FPC = {1:.2f}'.format(ncenters, fpc), size=12)
ax.axis('off')
fig1.tight_layout()
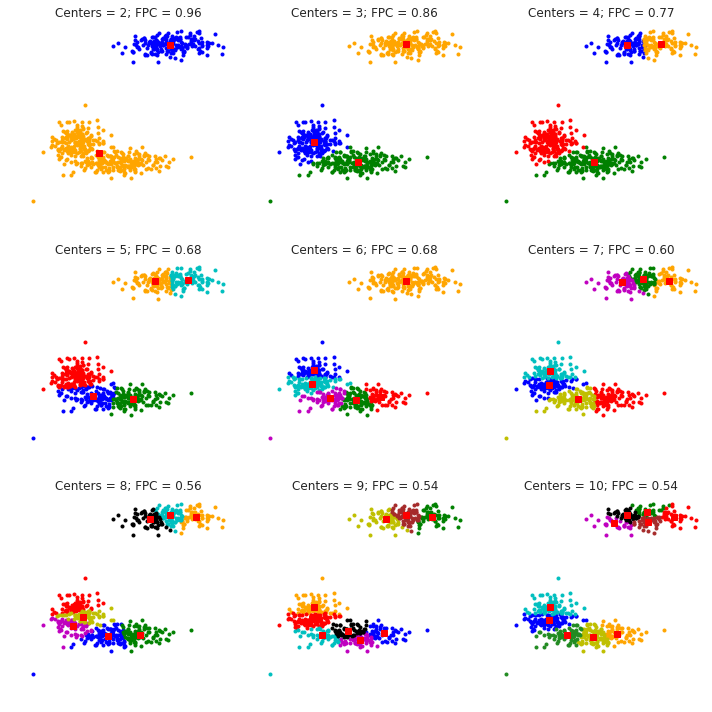
该部分代码已经上传至Github。
1.3.4 API使用
在FCM的函数使用过程中,需要注意的是,他输入的数据的形状跟平时使用机器学习的算法不同,他的形状正好是那些算法的输入的转置->(特征个数,样本数量),这里需要注意,具体可以参考文章[2],或者直接参考库的文档。
1.3 FCM的算法过程
在手册[3]中,具体介绍了FCM的算法流程。在我看来,其中比较重要的点,就是他的一些公式,因为大致上的流程跟KMeans本质上是一样的。算法大致流程如下,具体请参考文章[3]。
- 初始化隶属度矩阵 U = [ u i j ] U=[u_{ij}] U=[uij]
- 利用隶属度矩阵计算中心向量 C = [ c j ] C=[c_j] C=[cj]
- 更新隶属度矩阵
- 重复2-3步骤,直到满足一定条件,一般是隶属度矩阵两次更新之间的误差小于某个 ε \varepsilon ε
1.4 FCM的缺点
与KMeans算法一样,该算法同样存在容易陷入局部最优的缺点,而且受到初始化里隶属度矩阵的影响。
参考
[1]Fuzzy Clustering
[2]skfuzzy.cmeans与sklearn.KMeans聚类效果对比以及使用方法
[3]Fuzzy C-Means Clustering


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









