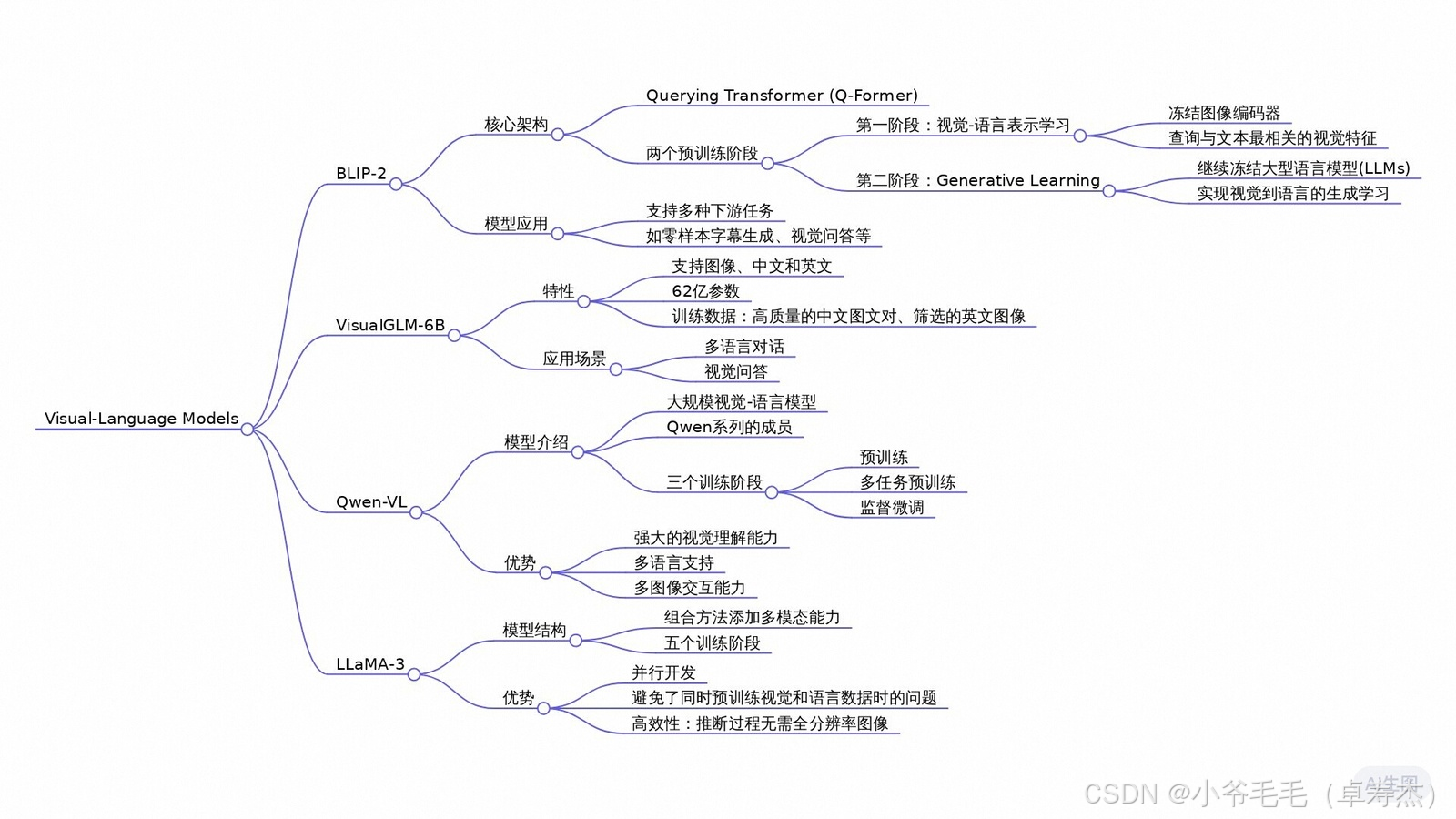
重磅推荐专栏: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展 1. VisualGLM BLIP-2 https://arxiv.org/pdf/2301.12597.pdf BLIP-2是一种用于视觉-语









 超级会员免费看
超级会员免费看


 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








