







实验环境
springboot版本:2.2.2.RELEASE
shardingsphere版本:4.0.0-RC3
实验说明:
数据库:demo_ds_master
4张表,表结构一摸一样:user_0,user_1,user_2,user_3
以下为user表的表结构,修改表名,为user_0,user_1,user_2,user_3然后在数据库中执行即可。
CREATE TABLE `user` (
`id` bigint(255) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`uid` varchar(255) DEFAULT NULL,
`school` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
)
第一步:引入shardingsphere依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC3</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>4.0.0-RC3</version>
</dependency>
第二步:application.properties配置
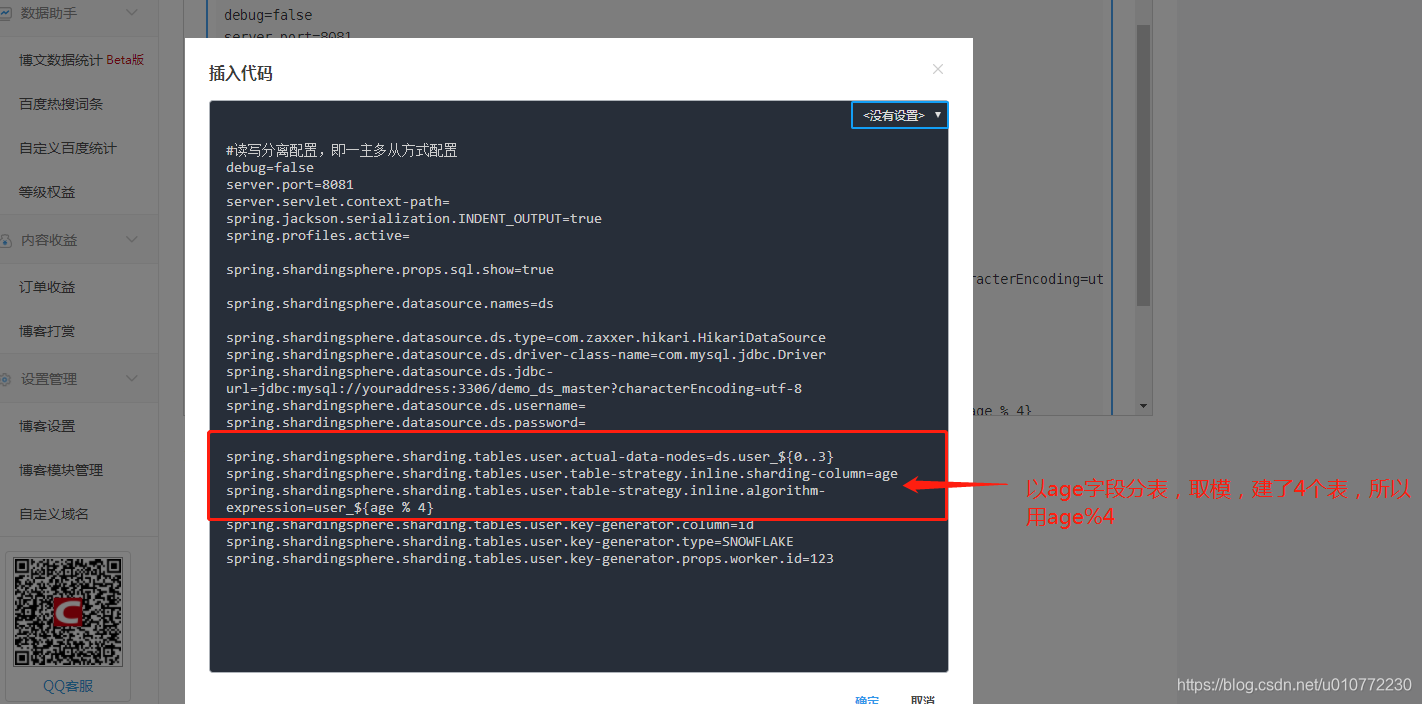
#读写分离配置,即一主多从方式配置
debug=false
server.port=8081
server.servlet.context-path=
spring.jackson.serialization.INDENT_OUTPUT=true
spring.profiles.active=
spring.shardingsphere.props.sql.show=true
spring.shardingsphere.datasource.names=ds
spring.shardingsphere.datasource.ds.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.jdbc-url=jdbc:mysql://youraddress:3306/demo_ds_master?characterEncoding=utf-8
spring.shardingsphere.datasource.ds.username=
spring.shardingsphere.datasource.ds.password=
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds.user_${0..3}
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=age
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_${age % 4}
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.user.key-generator.props.worker.id=123
第三步:验证
1.通过代码,插入一条数据,age=1,发现数据保存在user_1表中
2.通过代码,插入一条数据,age=2,发现数据保存在user_2表中
3.通过代码,插入一条数据,age=3,发现数据保存在user_3表中
4.通过代码,插入一条数据,age=4,发现数据保存在user_0表中
5.通过代码,插入一条数据,age=5,发现数据保存在user_1表中
4通过代码查询,发现查询出5条记录,到此验证完毕。


















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









