







 本文介绍了多模态预训练模型,包括ViLBERT的双流结构和预训练任务,LXMERT的跨模态表示学习,以及IMAGEBERT的数据收集过程。这些模型通过结合视觉和语言信息,实现了更深入的交互和理解。
本文介绍了多模态预训练模型,包括ViLBERT的双流结构和预训练任务,LXMERT的跨模态表示学习,以及IMAGEBERT的数据收集过程。这些模型通过结合视觉和语言信息,实现了更深入的交互和理解。
-
ViLBert
paper: ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
基于双流的 ViLBERT,在一开始并未直接对语言信息和图片信息进行融合,而是先各自经过 Transformer 的编码器进行编码。分流设计是基于这样一个假设,语言的理解本身比图像复杂,而且图像的输入本身就是经过 Faster-RCNN 提取的较高层次的特征,因此两者所需要的编码深度应该是不一样的。
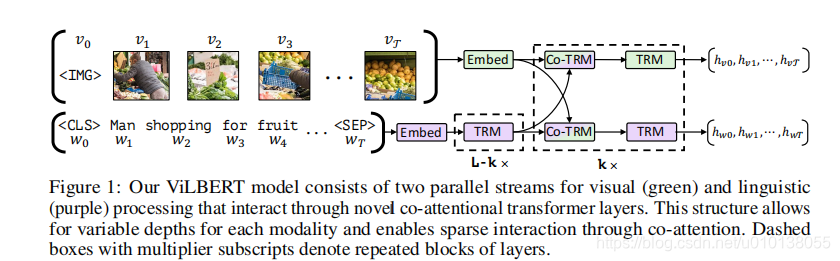
双流的 ViLBERT包括两个平行的视觉(绿色)和语言(紫色)处理流,它们通过新的共同注意转换层相互作用。这种结构允许每个模态的不同深度,并通过共同注意实现稀疏交互。带乘数下标的虚线框表示重复的层块。
输入:Image 和text :
输出:Attention 过的 Image 和text 的表示
模型
1.预训练步骤
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









