




简介
首先使用Llama-3-1-8B作为例子进行解析。如何Llama-3-1-8B想要在本地电脑运行,那么它需要多少GPU才能完美的运行起来了,大约需要19.2G的GPU才能运行。那么我们的机子最好是4090,哎。。。。。。。
这成本太高了,普通人是无法承受的。
因为很多人看到大模型运行成本这么高,所有都在想使用什么方式降低成本,又能达到接近的效果。参数高效微调后的大模型就是此产物,参数高效微调相关知识可以看我之前写的文章。
今天这篇文章目的不是讲解大模型的知识,今天的内容是怎么在自己的电脑上运行Llama-3-1-8B大模型。
例子中的模型是自己通过4bit量化训练的模型,可以在8G的以下的机子上可以运行。
这里插入一个如何计算大模型运行是需要消耗多少资源。
1)估算公式(该公式来自于Sam Stoelinga简化[1])
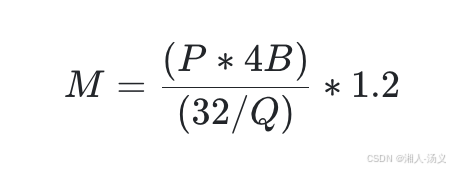
| 符号 | 描述 |
|---|---|
| M | 用千兆字节 (GB) 表示的 GPU 内存 |
| P | 模型中的参数数量。例如,一个 7B 模型有 7 亿参数。 |
| 4B | 4 字节,即每个参数使用的字节数 |
| 32 | 4 字节中有 3 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2945
2945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









