



目录:
- Llama3.2与QLoRA介绍
- Llama3.2预训练模型参数获取
- 微调数据集准备
- 微调训练脚本搭建
- 低配置友好的调参心得
- 低配置微调的局限性
1.Llama3.2与QLoRA介绍
Llama3.2
Llama是Meta开发的大语言模型系列,其采用自回归架构,可以用于文本生成、对话、代码编写等功能,并且完全开源且免费。目前,Meta已经发布了其最新的Llama大模型系列——Llama-3.2系列。在HuggingFace上面已经可以从Meta的主页下载到以下模型的训练参数:
Llama-3.2-1B
Llama-3.2-1B-Instruct
Llama-3.2-1B-evals
Llama-3.2-1B-Instruct-evals
Llama-3.2-3B
Llama-3.2-3B-Instruct
Llama-3.2-3B-Instruct-evals
本文将介绍适合低配置本地环境微调Llama-3.2-3B的流程。
QLoRA
直接在低配置本地环境对大模型进行微调,即使只选用参数量最小的Llama-3.2-1B,要实现也是较为困难的。但是,当引入QLoRA算法后,微调参数较大的Llama-3.2-3B,也成为了可能。
【什么是LoRA?】
我们知道,不论是在大模型的训练中,还是在基于大模型的微调上,最核心的部分就是更新模型的权重矩阵,例如注意力机制中的Wq,Wk,Wv等等,下文统称为W。然而,对于B(十亿)数量级以上的模型,由于使用了海量数据进行训练,其权重矩阵的参数数量非常庞大。若直接对上述的大模型进行微调,意味着每一次都需要对其巨大的权重矩阵做出调整。
我们知道,对于形状为mr的矩阵B和rn的矩阵A,其秩都为r.现在令一个矩阵ΔW=BA,那么ΔW的大小为m*n,秩为r.
通过这个启发,我们可以令权重矩阵W(典型Transformer中的W形状为in_dim*out_dim)的更新方式从直接更新W所有参数(h=Wx),变为如下方法:
将原始权重矩阵W₀冻结。
设置一个可学习的矩阵B,大小为in_dim*r.
设置一个可学习的矩阵A,大小为r*out_dim.
ΔW=BA
h=W₀+α*ΔW
(其中,α为LoRA算法中预设好的权重)
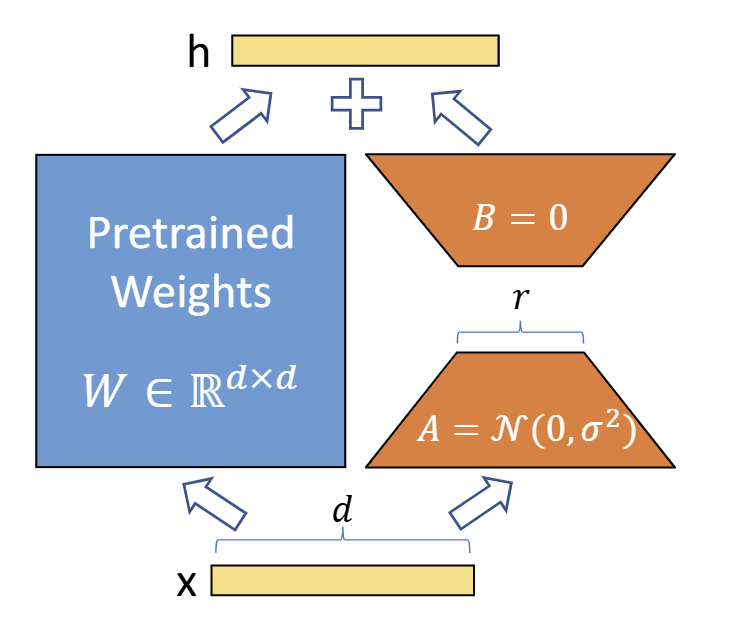
这样一来,在微调时只需更新低秩矩阵A和B(他们的秩r通常设置<=64),这极大减少了显存使用、加速了训练速度。
这样做可行的原因:
神经网络权重矩阵通常具有高度冗余、少数主要维度集中大部分信息、存在“内在低秩”的特点,而实验证明LoRA压缩方法能够有效地捕捉微调时低维子空间中的参数变化,即使使用较低的秩,LoRA也能逐步减少误差,使低秩矩阵适应性地学习最重要的变化方向。由此,LoRA看似“抛弃”了原权重矩阵中的大部分信息,实际上训练还是能够高效进行的。
【QLoRA方法】
QLoRA = 量化基础模型 + LoRA微调 + 内存优化
└─ NF4量化 └─ FP16参数 └─ 分页管理
QLoRA方法相比LoRA方法,不仅在训练过程中使用了低秩矩阵,还对基础模型的精度进行削减,使权重矩阵的数据大小得到大幅度减小,同时使用了分页管理、优化器状态管理的方法来进一步减少对显存的消耗。
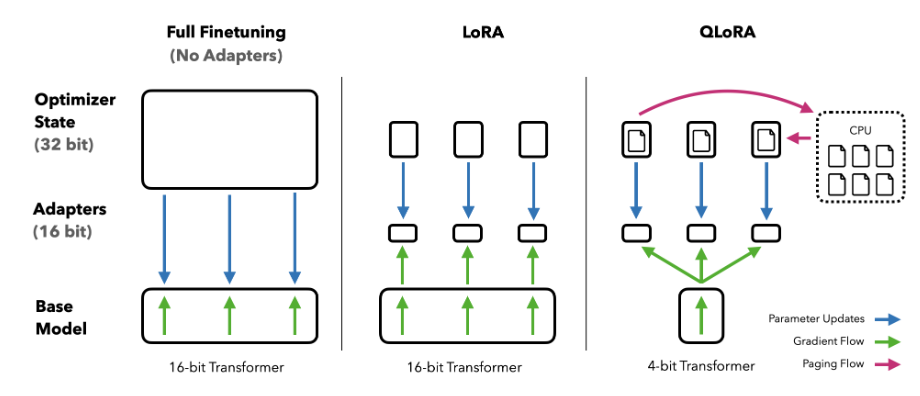
全量微调、LoRA方法、QLoRA方法对比
以下是大致流程:
<1>已知W₀为fp16(或者fp32)量化,QLoRA方法将其转化为nf4量化
W₀ = dequantize(W₀_nf4)
冻结通过nf4量化压缩得到的W₀,这个新的矩阵的数据量只有原先的1/4。
<2>对W₀添加LoRA层,开始训练,流程同之前提到的LoRA方法,使用低秩矩阵的更新来进行训练(精度为FP16量化)。训练过程中分页管理、优化器状态管理开始生效。
<3>模型微调完成后,可以将NF4量化存储的W₀16反量化为FP16存储,这样就可以正常使用这个权重矩阵来进行生成工作。
2.Llama3.2预训练模型参数获取
要使用Llama模型的预训练参数与分词器需要Meta授权,获得授权的步骤如下:
<1>登录HuggingFace,打开Meta团队页面,可以看到一系列的Llama模型资源
<2>选择需要的Llama版本,这里使用的是Llama-3.2-3B,在跳转出的页面中可以看到这个按钮

点击,完成填表
等待Meta团队审核通过后,刷新页面可以看到

这就说明已经获取了Meta的授权,可以使用这个版本的Llama模型的预训练参数和分词器了。
<3>接下来创建一个token,如下图勾选
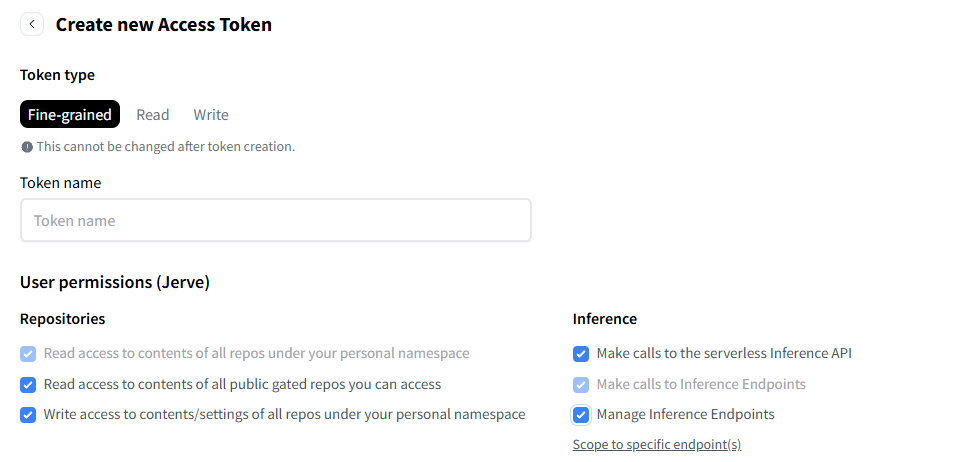
之后就可以通过这个token在代码中获取需要的文件。
3.微调数据集准备
在网络上可以找到丰富的微调用数据集,这里推荐从HuggingFace获取。
需要注意的是,对于Llama大模型的微调,其对数据集格式有所要求:
<1>数据集文件通常要为.json或者.jsonl后缀形式。
<2>若要有效地进行微调,使用的数据集最好按照特定的模式设置。数据集文件内容分为两种模式,分别为对话格式和Alpaca格式.当然,字段名不同,但大体形式相同的数据集也可以使用,并非严格限定。
<3>仅限本文微调的3B模型来说:由于显存紧张、要求训练轮数比较少,因此最好使用质量较高的数据集,数据文件控制在20MB以内,否则会出现欠拟合现象。
[对话格式]
必须包含“conversation”字段数组,“conversation”字段数组中必须包含多组“from”和“value”字段,from 字段值只能是 "assistant"等能表明身份的词。
例如:
{
"conversations": [ # 必需字段:对话数组
{
"from": "human", # 必需字段:说话者身份
"value": "问题内容" # 必需字段:具体内容
},
{
"from": "assistant", # 必需字段:说话者身份
"value": "回答内容" # 必需字段:具体内容
}
]
}
[Alpaca格式]
必须包含“instruction”和“output”字段,可以包含“input”和“message”字段。
例如:
{
"instruction": "任务指令", # 必需字段:指令/任务描述
"input": "输入内容", # 可选字段:补充输入
"output": "期望的输出内容" # 必需字段:任务的答案/输出
}
4.微调训练脚本搭建
HuggingFace为模型微调提供了一套非常好用的库,下面的训练脚本将用主要使用HuggingFace的核心库transformers和datasets,同时还会使用到启用QLoRA的peft库和大模型工作必需的torch库。
值得说明的是,HuggingFace和QLoRA对其库都有详细的使用手册,读者完全可以通过阅读手册尝试自行编写训练脚本,当然,也可以按照下面的流程快速搭建脚本(推荐使用Jupyter搭建,便于逐步检查代码可行性):
训练环境:12GB显存
python版本:3.9
<1>首先导入必要的库,登录HuggingFace,并启用GPU
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
import torch
from huggingface_hub import login
import os #导入os库以本地保存一些预处理好的数据、模型训练参数,方便下次使用
login("Token")#Tokens替换为从HuggingFace上面生成的Token
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
<2>获取需要的文件
在HuggingFace任意一个数据集页面中,都可以看到如何使用此数据集
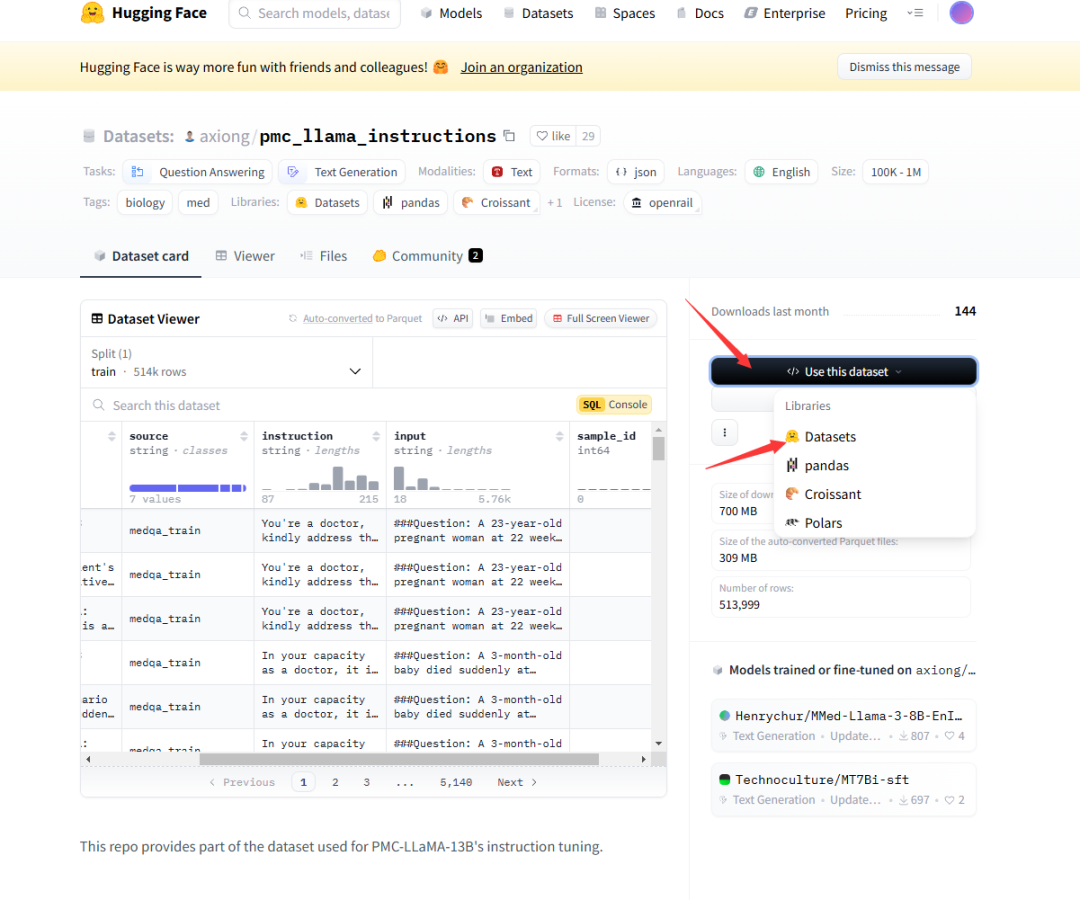
# 依照提示加载数据
dataset = load_dataset("bavest/fin-llama-dataset")
# 此处仅举例,可以换成任意所需的数据集
# 分割数据集为训练集和验证集
# 训练集和验证集的比例通常为9:1或者8:2
dataset = dataset["train"].train_test_split(test_size=0.1)
train_dataset = dataset["train"]
test_dataset = dataset["test"]
# 打印数据集以确认格式
print("测试集样本:", test_dataset[0])
print("训练集样本:", train_dataset[0])
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-3B")
# 设置pad_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
需要说明的是,由于Llama 等一些模型默认没有设置 pad_token(pad_token是用于填充序列的标记,保证一个批次(batch)中的所有序列长度相同),这可能会在批处理和训练时造成问题,因此可以将pad_token设置为eos_token。
<3>数据预处理
这里使用的数据集有三个字段"instruction"“output”"text"希望被使用,
使用Llama3.2-3B的tokenizer来对数据集进行token化。
一步一步编写下来即可
def preprocess_function(examples):
# 拼接 instruction 和 text 字段作为输入
inputs = [inst + "\n" + txt for inst, txt in zip(examples['instruction'], examples['text'])]
outputs = examples['output'] # 模型需要生成的内容
# 对输入进行分词
model_inputs = tokenizer(inputs, max_length=256, truncation=True, padding='max_length')
# 对输出进行分词,作为标签
with tokenizer.as_target_tokenizer():
labels = tokenizer(outputs, max_length=256, truncation=True, padding='max_length')
# 将分词后的标签添加到模型输入中
model_inputs['labels'] = labels['input_ids']
return model_inputs
# 检查预处理后的数据集是否存在
if os.path.exists(train_dataset_path) and os.path.exists(test_dataset_path):
# 加载预处理后的数据集
train_dataset = load_from_disk(train_dataset_path)
test_dataset = load_from_disk(test_dataset_path)
else:
# 将数据集映射到预处理函数
train_dataset = train_dataset.map(preprocess_function, batched=True)
test_dataset = test_dataset.map(preprocess_function, batched=True)
# 打印预处理后的数据集示例
print("预处理后的训练集样本:", train_dataset[0])
# 数据集文件路径
train_dataset_path = 'preprocessed_train_dataset'
test_dataset_path = 'preprocessed_test_dataset'
# 保存预处理后的数据集
train_dataset.save_to_disk(train_dataset_path)
test_dataset.save_to_disk(test_dataset_path)
<4>QLoRA配置,同样,手册给出了详细的配置方法
### 加载预训练模型并启用QLoRA
from peft import LoraConfig, get_peft_model
from transformers import BitsAndBytesConfig
# 配置4-bit量化
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.float16
)
# 加载预训练模型(启用4-bit量化)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-3B",
quantization_config=quantization_config,
device_map="auto",
)
# 配置QLoRA(LoRA参数)
lora_config = LoraConfig(
r=8, # LoRA 低秩参数
lora_alpha=16, # LoRA 权重因子
target_modules=["q_proj", "v_proj"], # 只在q_proj和v_proj上应用LoRA
lora_dropout=0.1, # LoRA dropout
bias="none", # 不训练偏置
task_type="CAUSAL_LM" # 自回归语言模型任务
)
# 将LoRA应用到模型
model = get_peft_model(model, lora_config)
# 检查LoRA参数
model.print_trainable_parameters()
<5>训练参数配置、优化器设置
以下参数设置仅供参考,要结合本地测试以及需求来调节参数
除此之外,还使用了torch优化器AdamW和Flash Attention(这两项可选)
# 按照手册配置训练参数
training_args = TrainingArguments(
output_dir="./results", # 保存模型的路径,可以自己指定
eval_strategy="epoch", # 每个epoch进行评估
learning_rate=2e-4, # QLoRA通常需要更高的学习率
warmup_ratio=0.03, # 学习率预热比例
per_device_train_batch_size=8,# 每个设备的训练batch大小
per_device_eval_batch_size=8, # 每个设备的评估batch大小
num_train_epochs=50, # 训练的epoch数量
weight_decay=0.01, # 权重衰减
logging_dir='./logs', # 日志保存路径
logging_steps=10, # 每10步记录一次日志
save_total_limit=2, # 最多保存2个检查点
save_steps=20, # 每500步保存一次检查点
fp16=True, # 启用混合精度训练
gradient_accumulation_steps=4, # 梯度累积
gradient_checkpointing=True, # 启用梯度检测
optim="adamw_torch" # 使用torch优化器,可选
)
from torch.optim import AdamW
# 初始化优化器 可选
optimizer = AdamW(model.parameters(), lr=5e-4, weight_decay=0.01)
# 按照手册初始化Trainer对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
optimizers=(optimizer, None)
)
# 使用flash attention (如果模型支持)可选
model.config.use_flash_attention = True
<6>开始训练
# 调用trainer对象的train方法来开始训练
trainer.train()
# 注意保存训练结果
model.save_pretrained("./results/finetuned_model")
tokenizer.save_pretrained("./results/finetuned_model")
5.低配置友好调参心得
在实际训练过程中,一些参数的配置对训练速度影响非常大,下面给出简要的调参心得:
<1>最大序列长度
在预处理函数preprocess_function中,max_length的设置会显著影响显存使用,max_length越大,训练步数越少,显存占用最大。通过实践,对于12GB的GPU,本文建议设置为256,因为3B预训练模型的微调通常上只能实现较为简单的推理问题,256的序列长度就足够。序列小于256会显著降低模型的性能,大于256,例如使用512的序列长度,会导致显存告急,一旦显存爆满,批处理将会变无比缓慢,训练几乎无法进行。
<2>批次长度
在training_args中,per_device_train_batch_size和per_device_eval_batch_size对显存占用的影响是最大的。
就调参方法本文给出两个建议:
(1)保证per_device_train_batch_size和per_device_eval_batch_size的大小不要小于8,如果小于8,过短的批次长度那么很可能会使loss值无法下降。若两个参数等于8仍然无法进行训练,可以考虑调整最大序列长度和QLoRA的低秩r的大小。
(2)调参时观察显存占用情况,确保显存被充分使用,加快训练过程。若发现显存爆满(若发现开始占用共享GPU内存,就说明显存爆满),即使只是很小程度地利用内存充当显存,也要及时停机调参。由于内存频率和带宽相较于显存非常低,加上GPU到内存的通信延时,即使是很小程度的显存爆满也会导致批处理变得异常缓慢。
<3>低秩r
在lora_config中,低秩r的大小也会显著影响显存占用,这很直观,因为其决定了低秩权重矩阵AB的大小,建议设置为4~64,r小于4可能会导致插入的低秩矩阵容量不足,无法有效捕获任务相关的特征,而大于64之后r增大的收益十分微小,并且会增大显存占用。
<4>应用QLoRA的目标矩阵
注意到lora_config中的config_modules,这决定了参与训练的权重矩阵有哪些,如如 q, k, v, o 或 FFN 的某些权重,对于低配置环境,指定q和k权重矩阵进行训练足够,并且对能够减少显存的占用。
6.低配置环境局限性
最后,如果在所有配置都达到最低限度的情况下仍不能实现对1B模型的微调,或者是微调效果很差,考虑此方法的局限性:
(1)无法有效利用太大或者质量不高的数据集。
(2)无法进行任务过于复杂的微调。例如微调出一个简单的法律问答模型这是可行的,但如果是利用CoT方法微调一个数学解题模型,7B以上的大模型+算力更高的云平台更加适合。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









