







 本文介绍了操作系统中的死锁问题,通过进度图分析死锁发生的原因及避免方法。还阐述了信号量和互斥锁使用不当会引发死锁,给出单锁和多锁情况下避免死锁的策略。此外,介绍了PASS/NZPASS、Sync等同步方式,以及可重入和线程安全的概念。
本文介绍了操作系统中的死锁问题,通过进度图分析死锁发生的原因及避免方法。还阐述了信号量和互斥锁使用不当会引发死锁,给出单锁和多锁情况下避免死锁的策略。此外,介绍了PASS/NZPASS、Sync等同步方式,以及可重入和线程安全的概念。
大家都见过交通阻塞,大量车辆因为争夺路口的行使权,互不想让而造成交通阻塞,又或者因为车辆发生故障抛锚或两量车相撞而造成道路阻塞,在这种情况下,所有的车都停了下来,谁也无法前行,这就是死锁。
生活中其实有很多死锁的例子,比如当我们的手机没电时却遇到了一箱子的共享充电宝,亦或者你饿到没有吃饭的力气时却遇到一顿大餐,或者两个人过独木桥,如下图,他们有一个共同点,彼此都占用对方那部分的资源:

或者繁忙的十字路口恰好遇到交通灯瘫痪,如下图,你认为最开始堵的是哪个方向的车流?

而下图车流这种情况却不属于死锁,由于一辆车不负责任的占有路权(可以认为是资源),而导致后面的车辆等待,但是这种等待状态是可以改变的,只要白色车辆继续前进,系统状态就会更新。

操作系统中有很多独占资源,信号量和互斥锁是在RTOS或者Linux系统中提供多线程资源保护和同步的工具,如果正确使用,会保证我们的程序安全稳定可靠的运行,但是如果使用方式不正确,也会引起死锁,操作系统中的死锁指的是一组线程被阻塞了,等待一个永远也不会为真的条件。进入死锁后,死锁的参与各方状态无法发生变化。下面我们用进度图来分析一下死锁的时候发生了什么,为什么会发生,以及如何避免。
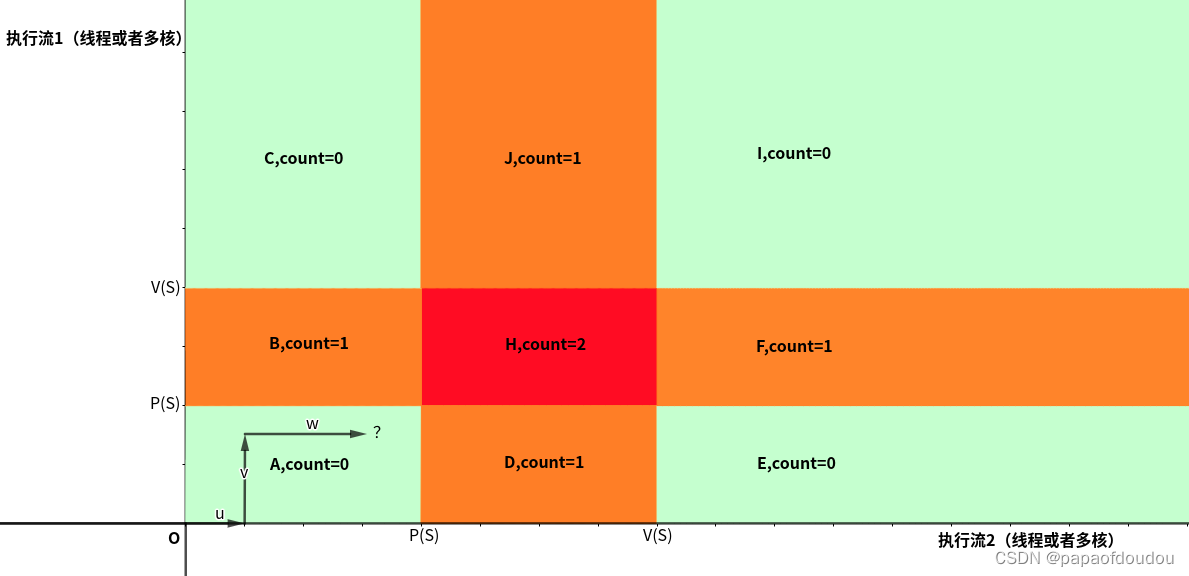
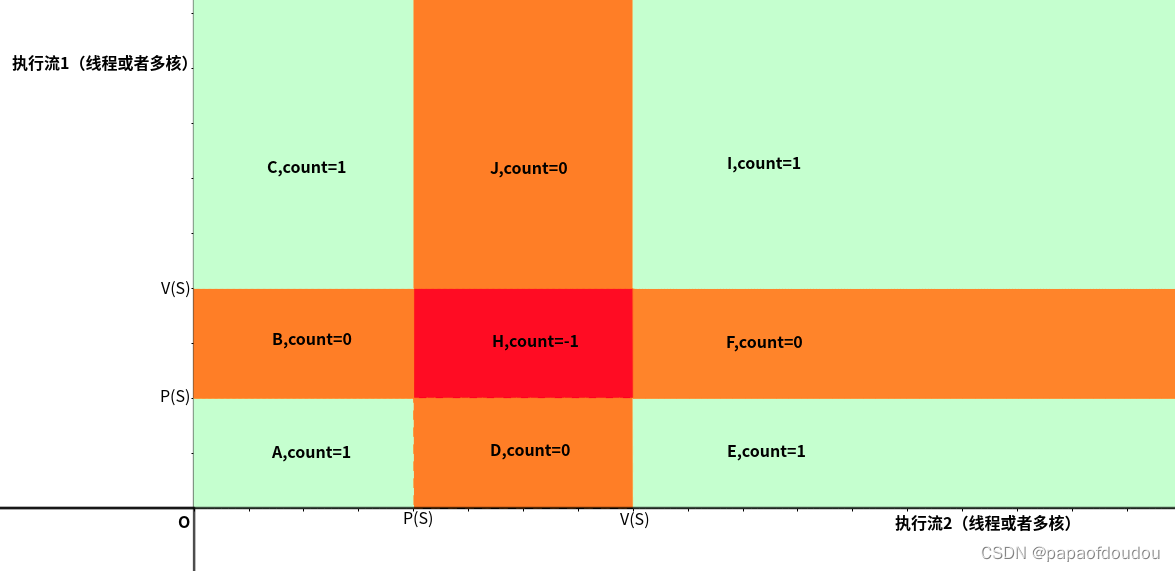
假设有资源S,它的初始资源量为1,根据P,V操作观察存在两个执行流的情况下的情况,你可以把执行流看是两个并行流向的时间,时间是不会折返的,所以执行流永远指向坐标轴的正向。
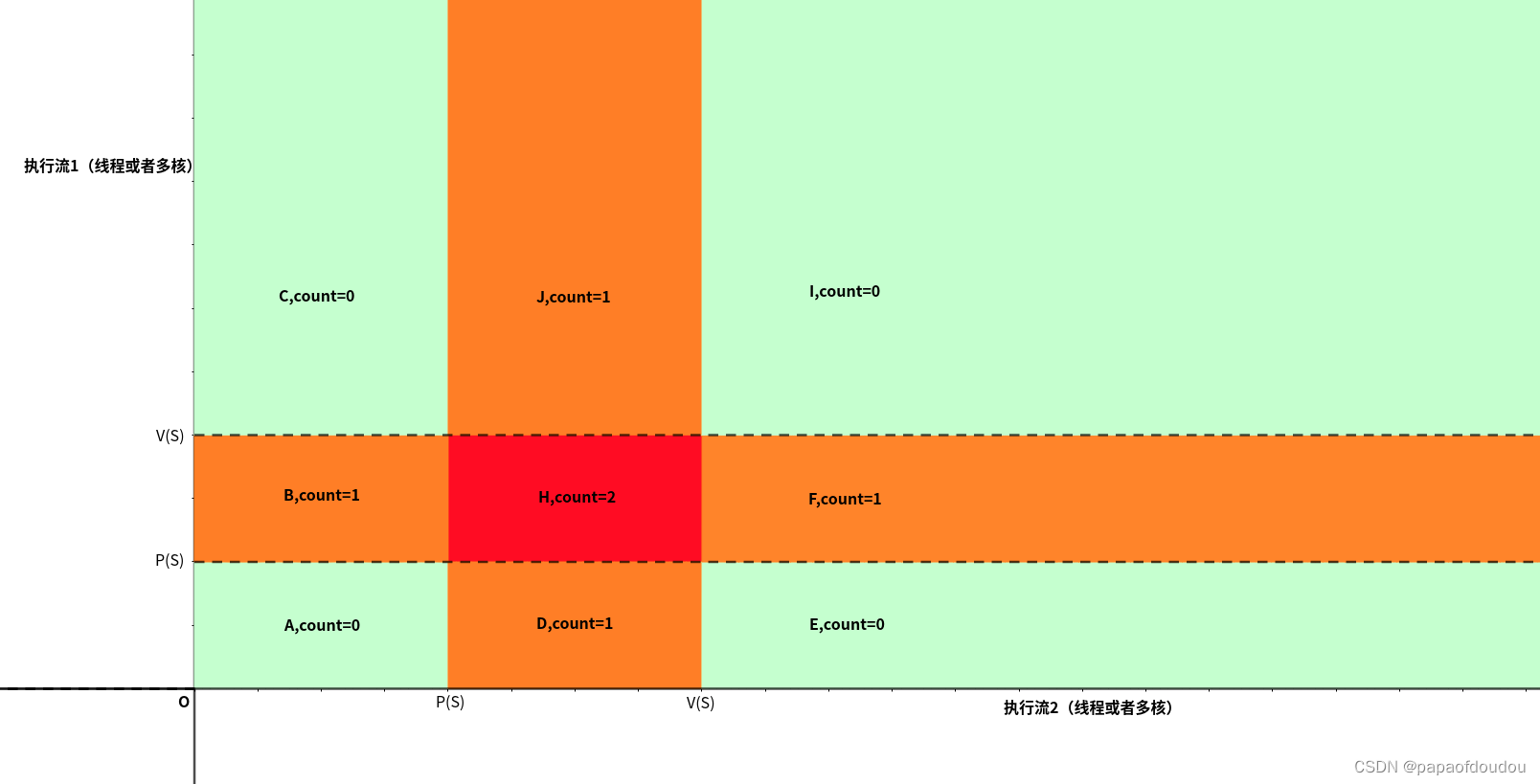
上图说明了在带颜色区域的任意一点下,需要的资源数的情况,这里我们尤其要注意H区,在这个区域内,两个执行流都执行了P操作,但是没有执行释放的V操作,也就是说,在H区内,两个线程都占有了锁,所以需要锁的数量为2。但我们给出的大前提是,锁的资源数只有1个,也就是同时最多只有一个线程能够持有锁,所以,红区的情况是不可能存在的,其他的两种情况count为0对应两个执行流都没有拿到锁的情况,而count为1对应任何一个线程持有锁的情况。
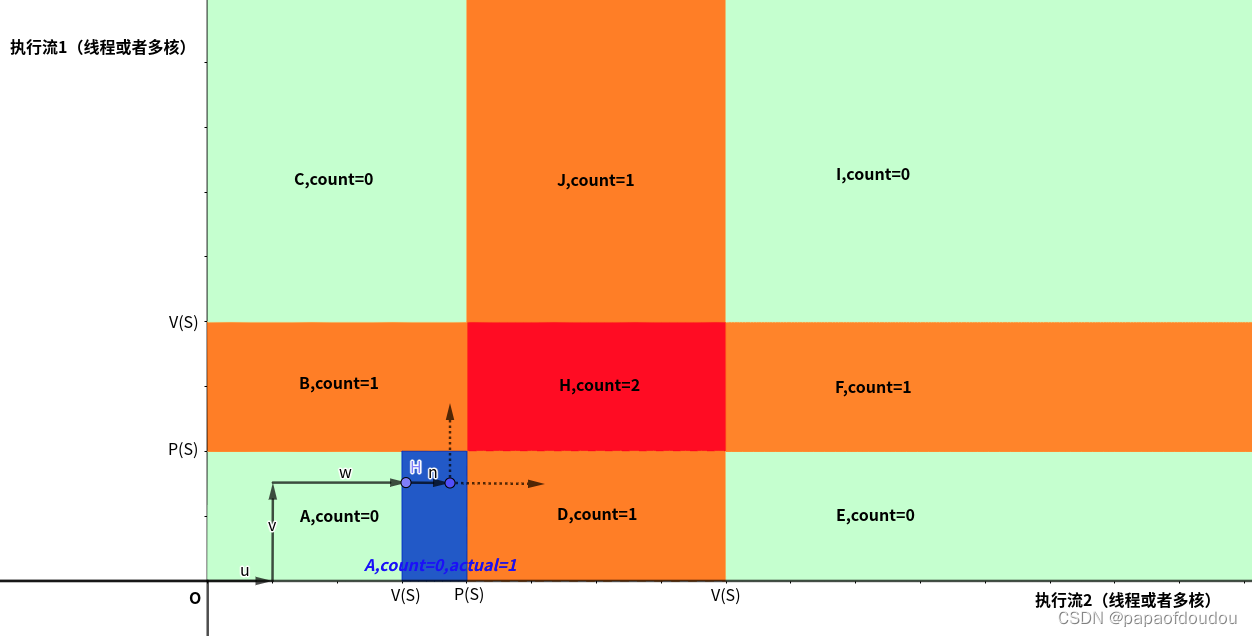
也就是说,上图中两个线程执行PV操作的情况下,除了红区是不可达的情况外,其他区域都是可以达到的。如下图所示,无论程序实际执行的情况多么复杂,执行流多么多样,都可以通过人物调度或者任务之间的同步等待(对应执行流中的转折)来安全的绕开红色区域,即便执行流贴近红色的边界也没有关系(不断的调度给另一个执行流,但另一个执行流只能等待,然后又将执行全交还)。所以,在单锁清情况下 ,执行流都是活的,不存在死锁的可能性。
图中的每一次转折代表发生了一次执行流的切换(比如任务切换或者多核同步和视角切换).
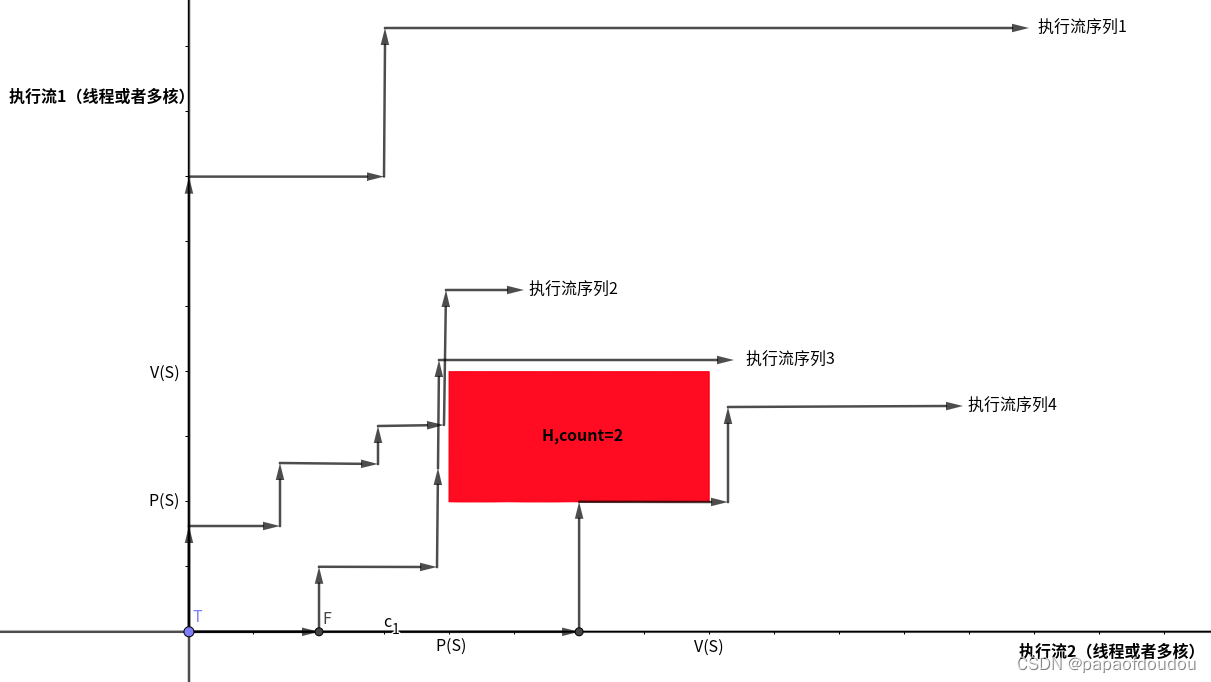
另外,由于时间和执行流是单向的,不存在折返的可能,所以,红色禁区中,只有区域的左侧的和下册两个方向才会受到执行流的“攻击”。
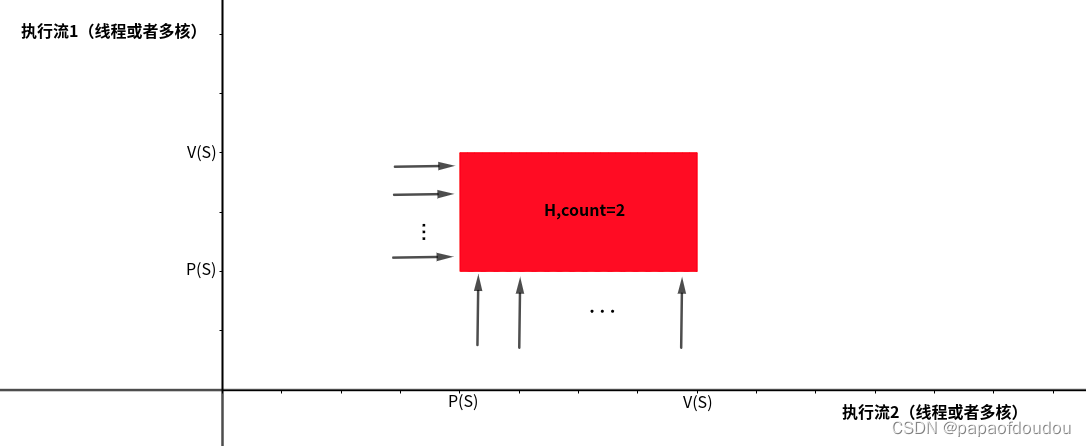
根据以上特点,我们可以把上面的红色区域叫做某个信号量或者互斥锁的“禁区”,如下图所示:
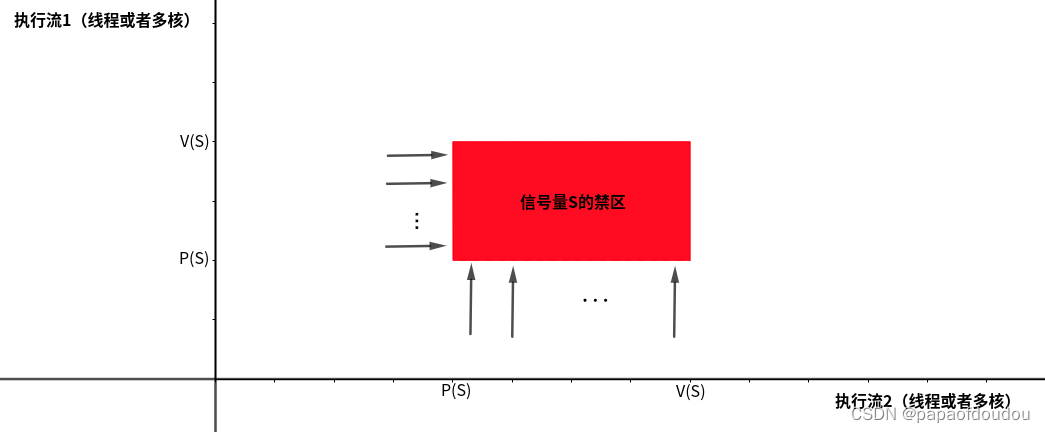
而死锁的情况,就和多个信号梁的禁区组合有关,下面我们看一下
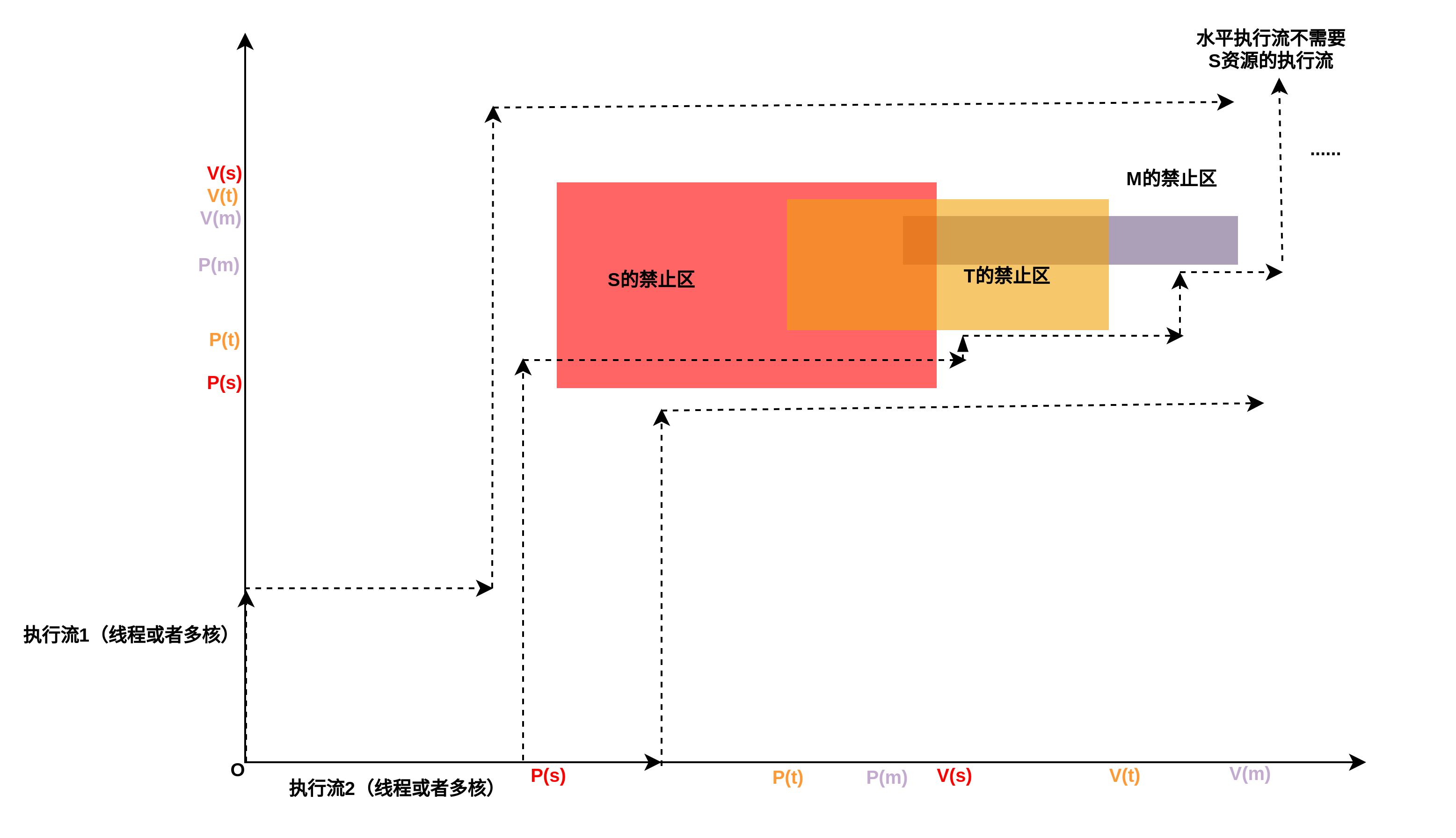
现在假设有两个信号量S,T,资源数都是1,他们的禁区如下所示:
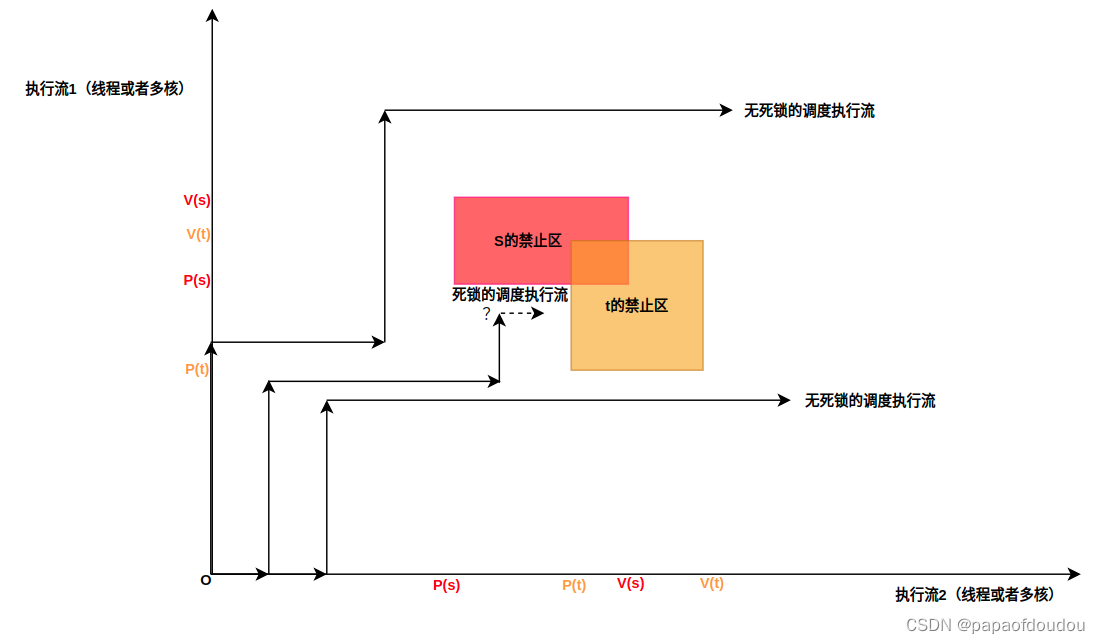
可以看到,如果信号量的禁止区分布,在流程的方向上同时存在左侧和下册的攻击面,这个时候,的执行路径,死锁已经无法避免,死锁区如下图所示:
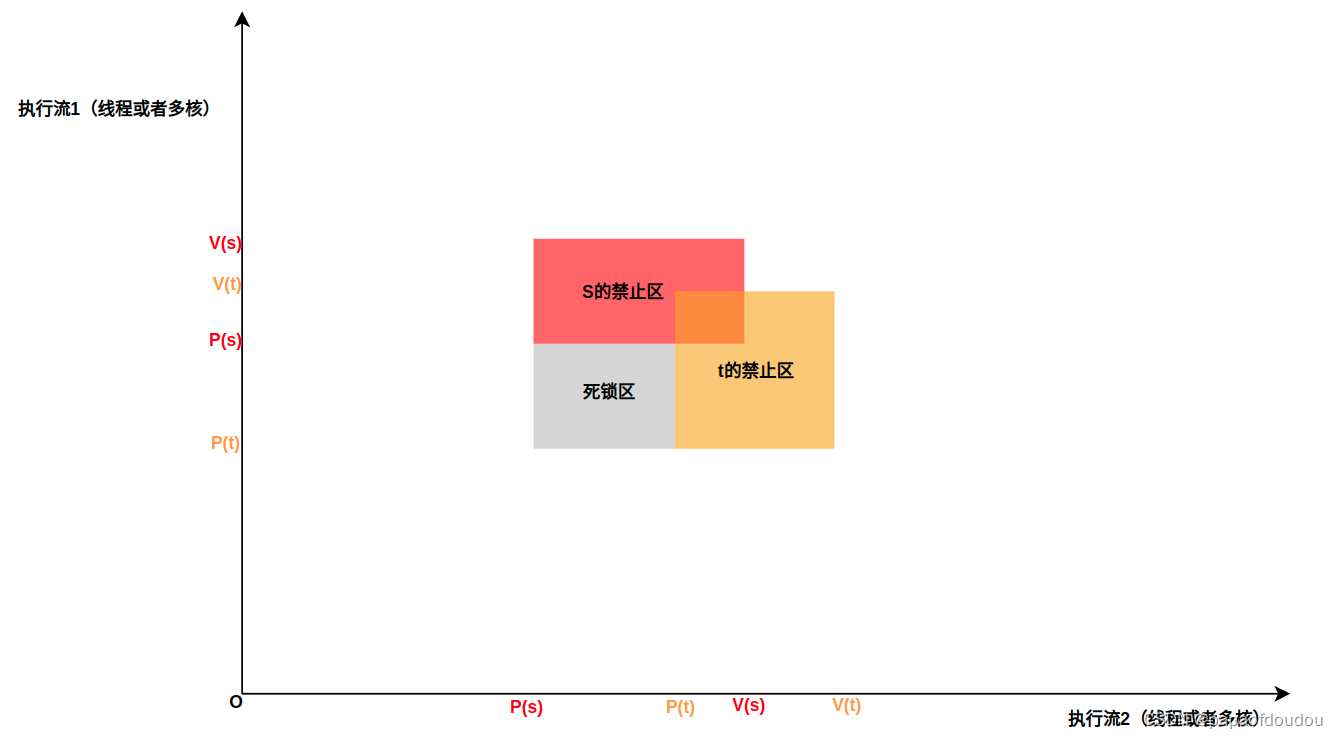
死锁检测是一个相当困难的问题,因为它不总是可预测的,一些幸运的执行轨迹线将绕开死锁区域,而其它的将会陷入这个区域,所以,实际情况可能是这样,你可以运行一个程序1000次没有问题,但是下一次它就死锁了(因为相当于活区,死锁区面积是有限的),最最糟糕的情况无非是这种了,错误常常不可重复,因为不同的执行期次有不同的轨迹线。
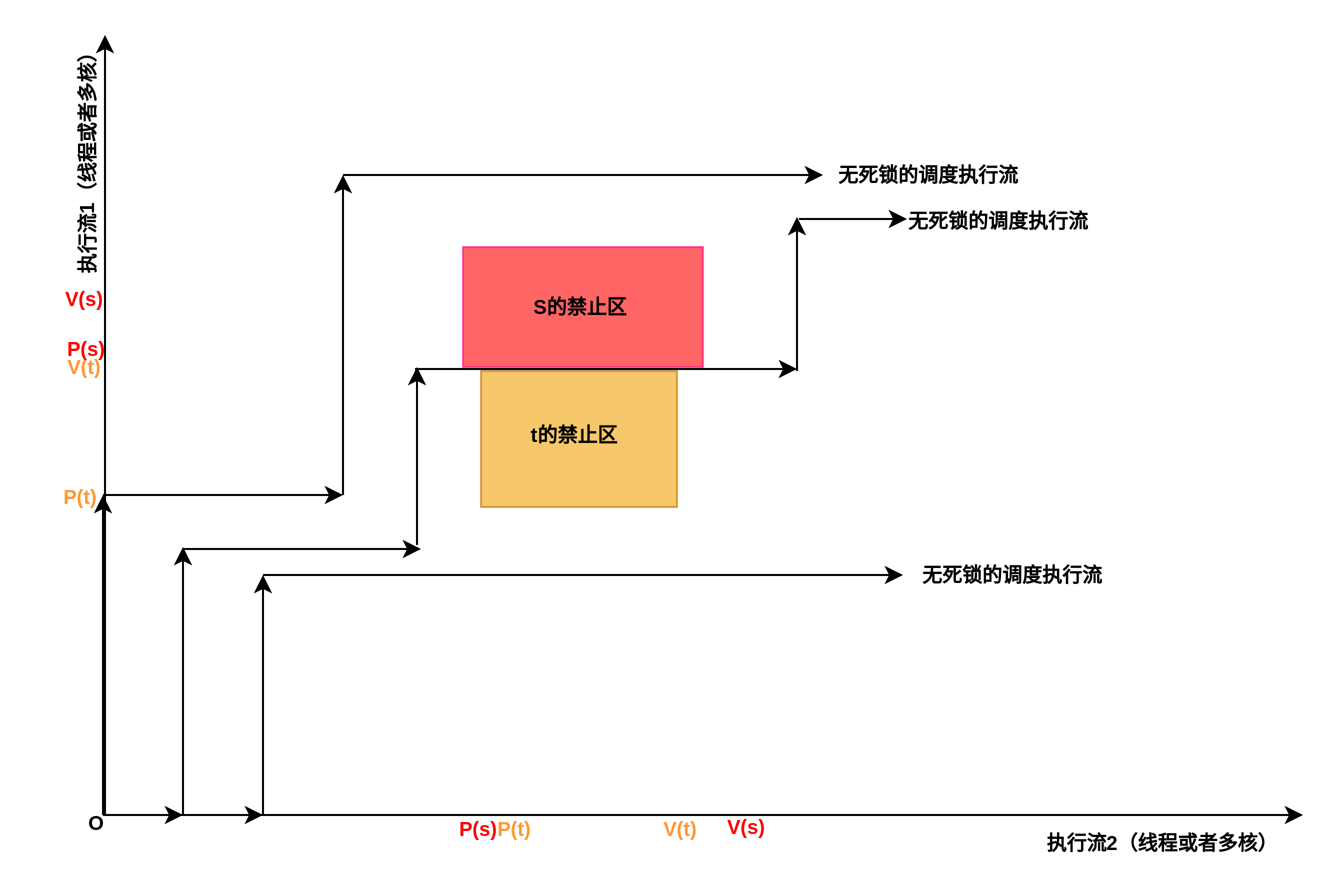
如何避免锁呢?从上面图中分析可以得出,死锁区存在的充分必要条件是,执行路径可能会在前进的所有方向上遇到不同资源的攻击面,如果避免出现这种情况,无论执行流要申请多少把锁,都是安全的,如下图:
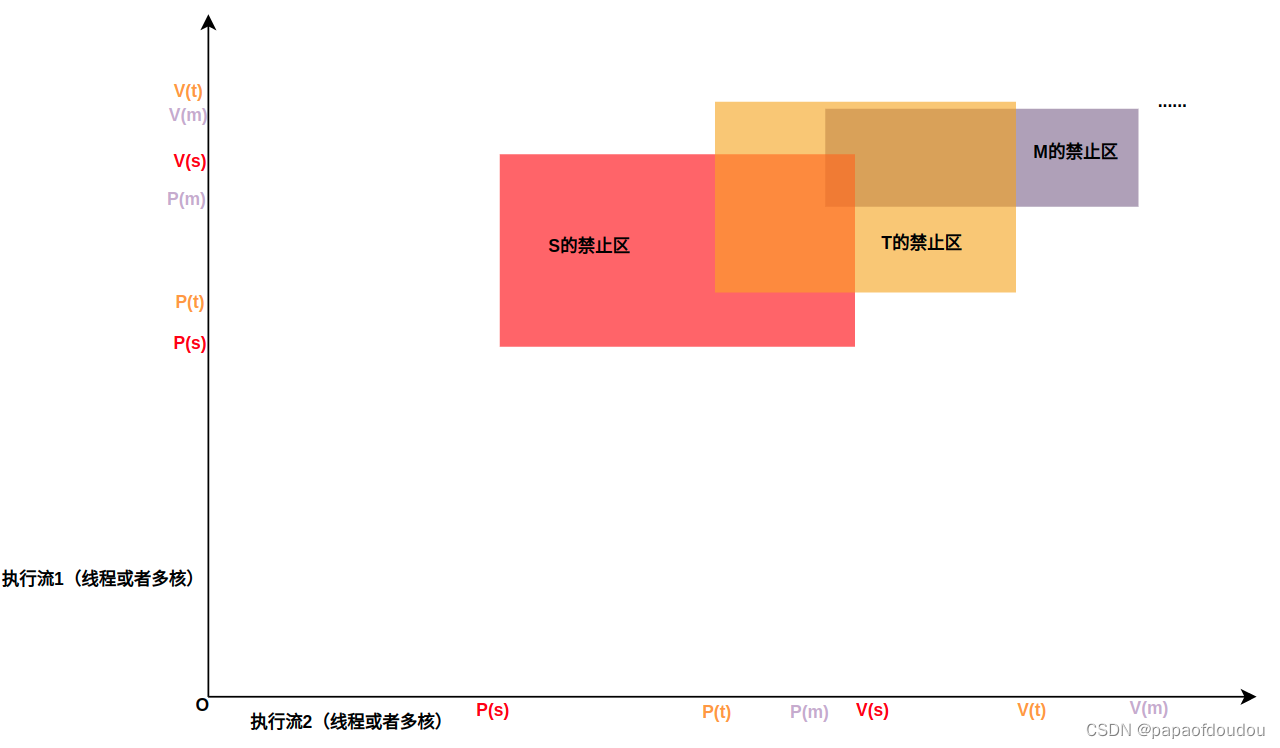
下图是执行流的例子,即便有些线程不需要其中的某把锁,也可以正确处理,如下图中标识出的中间执行流。
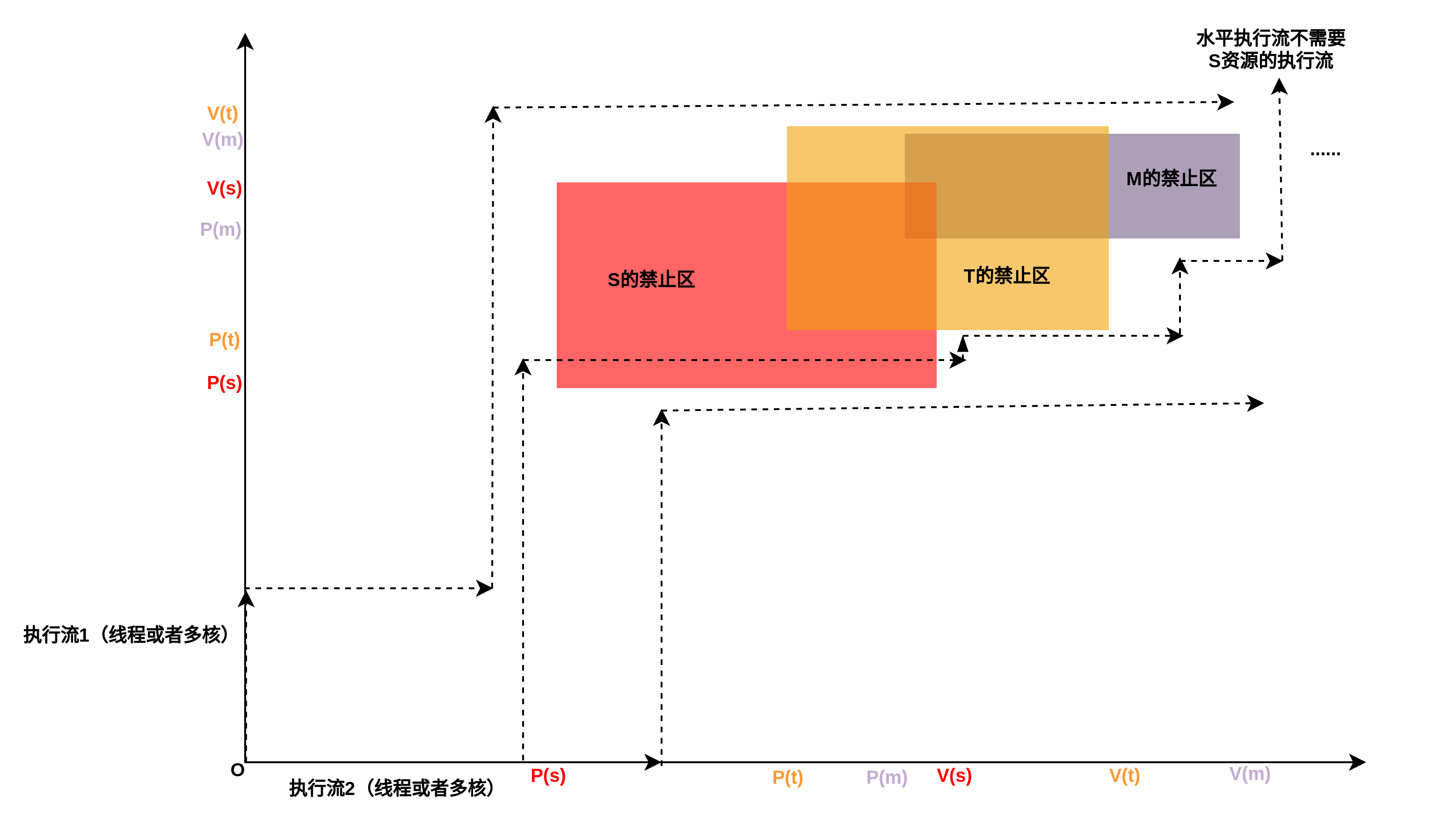
不过,虽然释放顺序不会造成问题,但是最好保证释放按照获取相反的顺序执行,也就是保持获取和释放是对称的顺序,如下图所示:
另一种安全的锁获取流程:
线程1:P(t)->V(t)->P(s)->V(s)
线程2:P(s)->P(t)->V(t)->V(s)
下图可以看到,虽然S和T的禁止区构造了类似于前图那样的死锁区,但是有所不同的是,S和T之间是没有交集的,所以执行流可以通过S和T之间的“夹缝”安全的流出去而不会产生死锁。只是可能会对效率产生影响,原因是在“夹缝”中会不断的尝试调度出去然后获取S锁,但是S锁已经被占有,所以只能再次调度回去,产生无效调度,这种尝试失败后又不断尝试的场景,就是活锁,活锁可以自我救赎,回到正常状态。
另外可以看出,禁止区是由X方向和Y方向两个方向(对于多维竞态,可能是超立方体)的平面决定了禁止区范围,如果仅仅一个方向获取两把锁,而另一个方向只获取一把,无论另一个方向获取这两把中的哪一把,最终两个方向上仅仅会形成一个禁止区,而只有一个禁止区的情况下,是不可能发生死锁的,所以,扩展开来,对于N个线程M把锁的情况,如如果N个线程都在按照约定顺序获取M把锁,自然不会死锁,但是如果有一个或者几个线程少拿几把锁,但是剩余的拿锁顺序仍然确保和其他拿到所有锁的线程顺序一致,仍然不可能发生死锁,因为在二维空间下,一把没有拿掉的锁不会造成禁止区(一维的线),同样,在高维空间下,即便拿锁的线程构成一个体,但是这个体是缺少维度的,当然不会造成死锁。
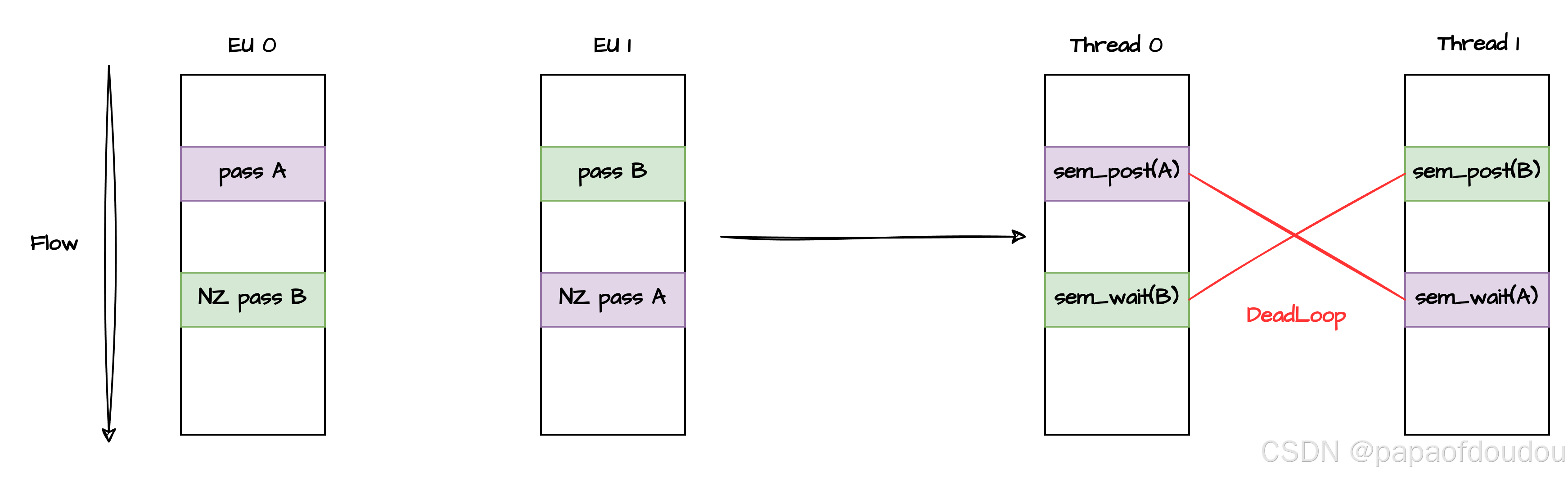
初始资源数小于等于0怎么办?
对于信号量来说,出始资源数不一定是1,也可以是任意整数值,包括负数,这一点和互斥锁不同,那么针对:
线程1:P(S)->V(S)
线程2:P(S)->V(S)
它一定是死锁的么?从下图可以看出,它一定会死锁:
怎么办呢?这个时候,一定要建立一个区域进行释放操作,也就是执行一次V(S),如下图所示:
此前的进度图是按照资源需求量绘制的,下图是按照资源剩余量绘制的进度图,可以看到,同样的位置,两张图对应资源量加合为1,也就是资源量。
同步方式
PASS/NZPASS
1.生产/消费模型,也叫PASS/NZPASS模型,消费者可能会等待,生产者不会等待。
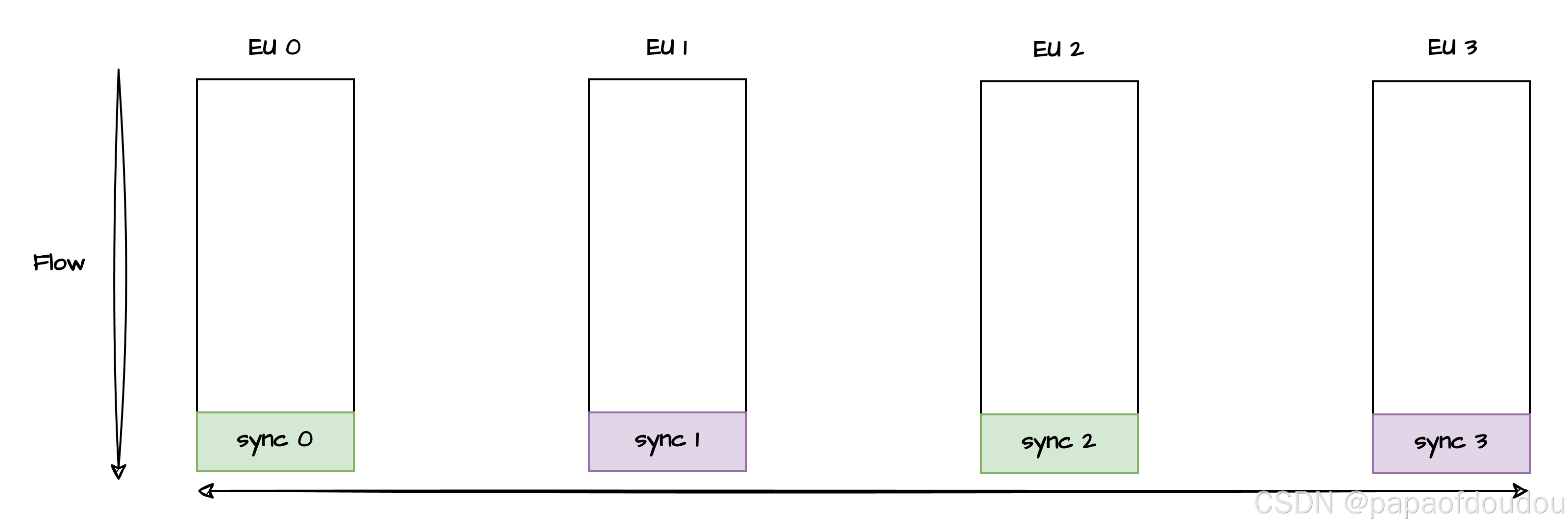
2.同步模型,参与同步各方自成生产消费于一体,执行体为全体贡献一个信号,但是也要等待全部执行流执行到指定位置,才可以齐步走继续往下。举个同步模型的例子,比如你有对双胞胎儿子,他们在同一个班,每天结伴上下学,那么任何一个人在出发或者放学的时刻,必须的等待另一个人也准备好了才能一起行动。
PASS/NZPASS 同步举例
用CMODE实现上图中的模型
#define _GNU_SOURCE
#include <semaphore.h>
#include <stdlib.h>
#include <pthread.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
static sem_t sync_sem1;
static sem_t sync_sem2;
int pass(sem_t *gse_sync)
{
// send pass signal(producer).
sem_post(gse_sync);
return 0;
}
int nzpass(sem_t *gse_sync)
{
// wait pass signal(consumer).
sem_wait(gse_sync);
return 0;
}
void job_sdma(void)
{
sleep(1);
printf("%s line %d, job done.\n", __func__, __LINE__);
}
void job_cp(void)
{
sleep(1);
printf("%s line %d, job done.\n", __func__, __LINE__);
}
void cp_job(int step)
{
nzpass(&sync_sem1);
printf("======new coming cp job %d start========\n", step);
printf("%s line %d, step %d wait pass.\n", __func__, __LINE__, step);
job_cp();
pass(&sync_sem2);
printf("%s line %d, step %d send pass.\n", __func__, __LINE__, step);
printf("======new coming cp job %d end =========\n", step);
}
void sdma_job(int step)
{
nzpass(&sync_sem2);
printf("=====new coming sdma job %d start=======\n", step);
printf("%s line %d, step %d wait pass.\n", __func__, __LINE__, step);
job_sdma();
pass(&sync_sem1);
printf("%s line %d, step %d send pass.\n", __func__, __LINE__, step);
printf("=====new coming sdma job %d end ========\n", step);
}
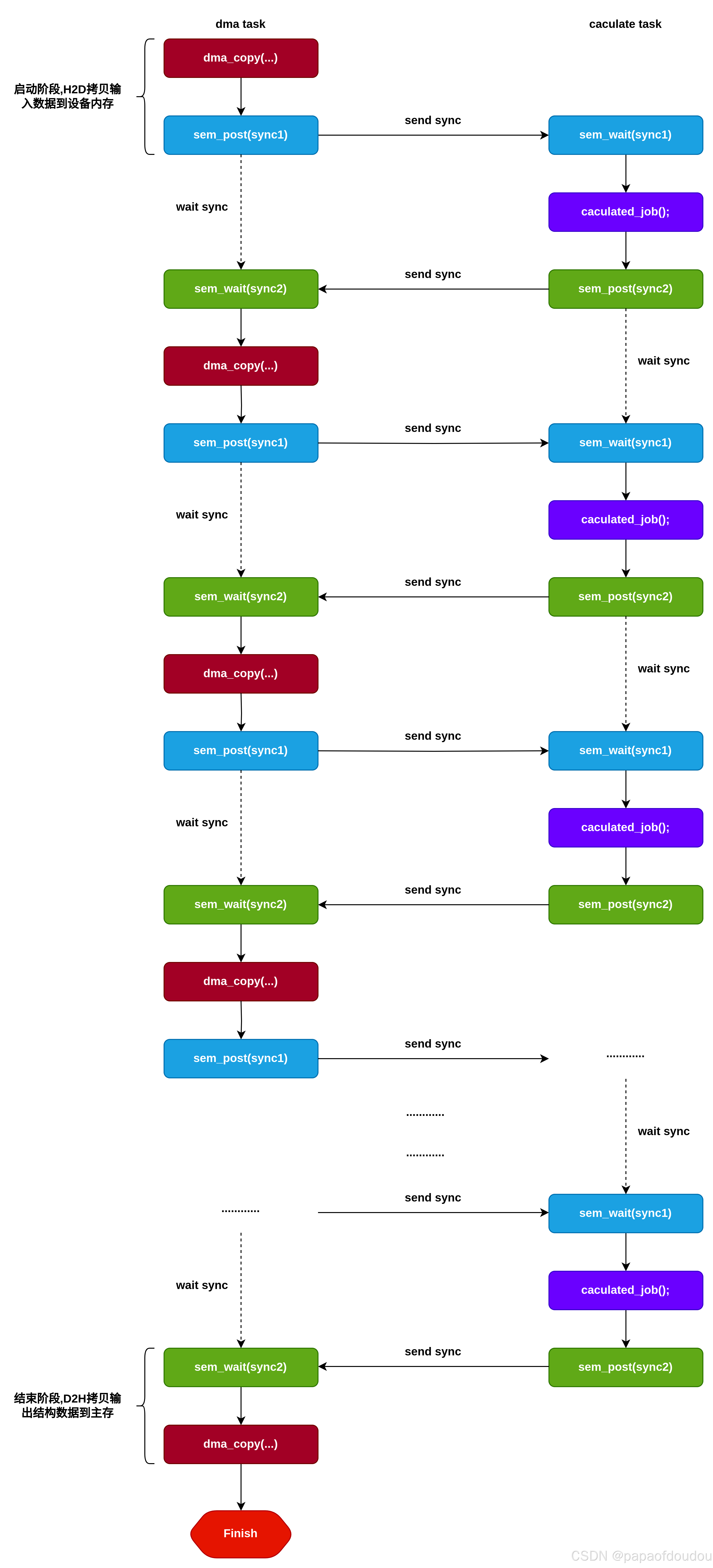
void h2d(void)
{
job_sdma();
pass(&sync_sem1);
printf("%s line %d, step 1 send pass.\n", __func__, __LINE__);
}
void d2h(void)
{
nzpass(&sync_sem2);
printf("%s line %d, step 4 wait pass.\n", __func__, __LINE__);
job_sdma();
}
void *pipe1_task_sdma(void *param)
{
h2d();
sdma_job(1);
sdma_job(2);
sdma_job(3);
d2h();
return NULL;
}
void *pipe2_task_cp(void *param)
{
cp_job(0);
cp_job(1);
cp_job(2);
cp_job(3);
return NULL;
}
int main(void)
{
pthread_t thread1, thread2;
pthread_attr_t attr1, attr2;
cpu_set_t mask1, mask2;
pthread_attr_init(&attr1);
pthread_attr_init(&attr2);
CPU_ZERO(&mask1);
CPU_ZERO(&mask2);
CPU_SET(1, &mask1);
CPU_SET(2, &mask2);
pthread_attr_setaffinity_np(&attr1, sizeof(mask1), &mask1);
pthread_attr_setaffinity_np(&attr2, sizeof(mask2), &mask2);
// initialize the semaphores
sem_init(&sync_sem1, 0, 0);
sem_init(&sync_sem2, 0, 0);
// spawn the threads
pthread_create(&thread1, &attr1, pipe1_task_sdma, NULL);
pthread_create(&thread2, &attr2, pipe2_task_cp, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}model输出如下:

Sync模型
和pass/nzpass模型不同,Sync的参与方既是生产者,也是消费者:
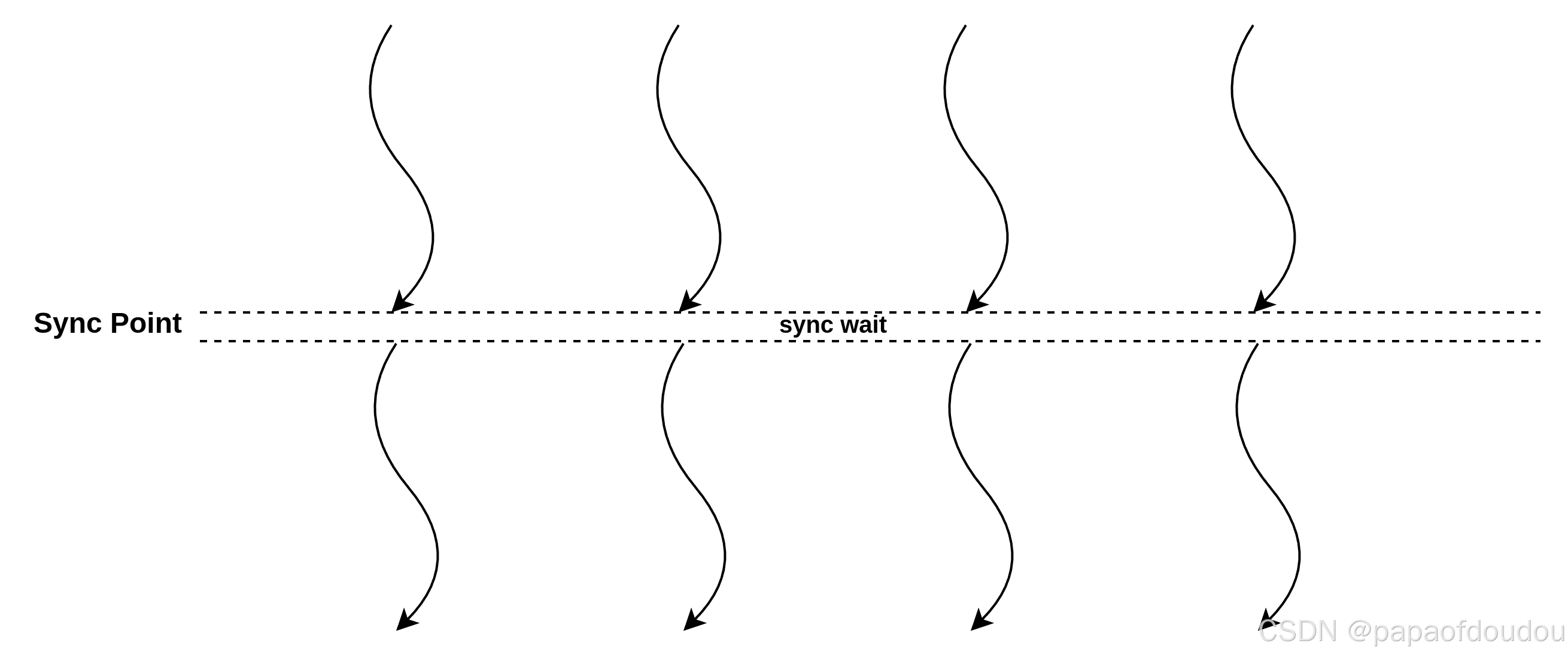
cmodel如下:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
typedef struct {
volatile long sync_count;
pthread_mutex_t sync_lock;
pthread_cond_t sync_cond;
} sync_handle_t;
static sync_handle_t sync_handle;
void sync_init(sync_handle_t *sync, long init_cnt)
{
sync->sync_count = init_cnt;
}
int do_sync(sync_handle_t *sync)
{
pthread_mutex_lock(&sync->sync_lock);
sync->sync_count --;
if (sync->sync_count < 0) {
pthread_mutex_unlock(&sync->sync_lock);
return -1;
}
if (sync->sync_count == 0) {
// pthread_cond_signal(&sync->sync_cond);
pthread_cond_broadcast(&sync->sync_cond);
}
while (sync->sync_count != 0) {
pthread_cond_wait(&sync->sync_cond, &sync->sync_lock);
if (sync->sync_count < 0) {
pthread_mutex_unlock(&sync->sync_lock);
return -1;
}
}
pthread_mutex_unlock(&sync->sync_lock);
return 0;
}
void *sync_exec1(void *p)
{
sleep(10);
printf("%s line %d sync begin.\n", __func__, __LINE__);
do_sync(&sync_handle);
printf("%s line %d sync end.\n", __func__, __LINE__);
return NULL;
}
void *sync_exec2(void *p)
{
printf("%s line %d sync begin.\n", __func__, __LINE__);
do_sync(&sync_handle);
printf("%s line %d sync end.\n", __func__, __LINE__);
return NULL;
}
void *sync_exec3(void *p)
{
printf("%s line %d sync begin.\n", __func__, __LINE__);
do_sync(&sync_handle);
printf("%s line %d sync end.\n", __func__, __LINE__);
return NULL;
}
void *sync_exec4(void *p)
{
printf("%s line %d sync begin.\n", __func__, __LINE__);
do_sync(&sync_handle);
printf("%s line %d sync end.\n", __func__, __LINE__);
return NULL;
}
int main(void)
{
int err;
pthread_t pthread1;
pthread_t pthread2;
pthread_t pthread3;
pthread_t pthread4;
//there are 4 threads do the sync.
pthread_mutex_init(&sync_handle.sync_lock, NULL);
pthread_cond_init(&sync_handle.sync_cond, NULL);
retry:
sync_init(&sync_handle, 4);
err = pthread_create(&pthread1, NULL, sync_exec1, NULL);
if (err != 0) {
perror("create pthread failure.");
return -1;
}
err = pthread_create(&pthread2, NULL, sync_exec2, NULL);
if (err != 0) {
perror("create pthread failure.");
return -1;
}
err = pthread_create(&pthread3, NULL, sync_exec3, NULL);
if (err != 0) {
perror("create pthread failure.");
return -1;
}
err = pthread_create(&pthread4, NULL, sync_exec4, NULL);
if (err != 0) {
perror("create pthread failure.");
return -1;
}
pthread_join(pthread1, NULL);
pthread_join(pthread2, NULL);
pthread_join(pthread3, NULL);
pthread_join(pthread4, NULL);
goto retry;
pthread_cond_destroy(&sync_handle.sync_cond);
return 0;
}运行结果

总结:
预防死锁的规则,给定所有互斥操作一个全序(至于什么是全序可以去查看集合论教材),用人话说就是所有的锁按照一个类似于自然数那样的严格顺序去获取。这样的获取方式就是安全的。
扩展到三个执行流的情况,执行流超过三个涉及到高维空间就很难想象了,就以三个执行流1把锁为例说明问题,它的禁止区域是一个长方体。
程序按照执行流的多寡可以按照如下图进行划分:
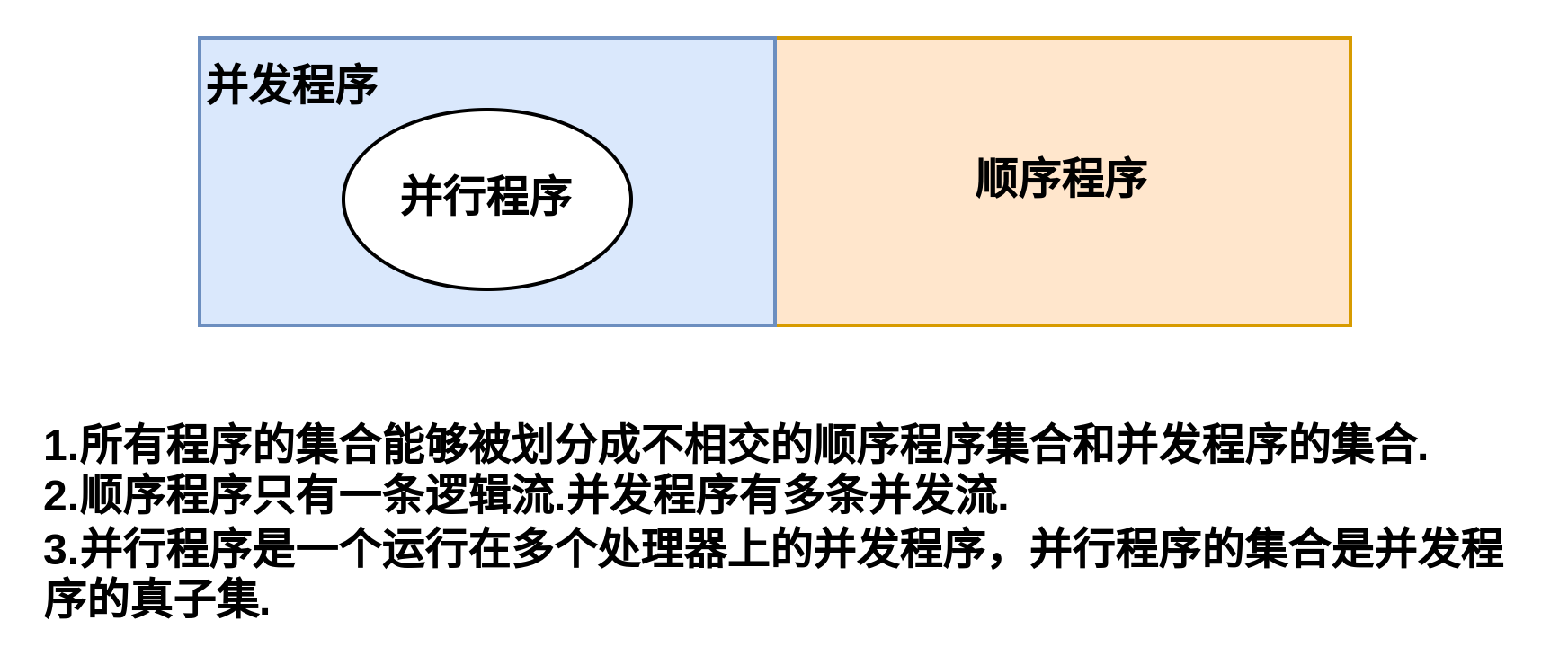
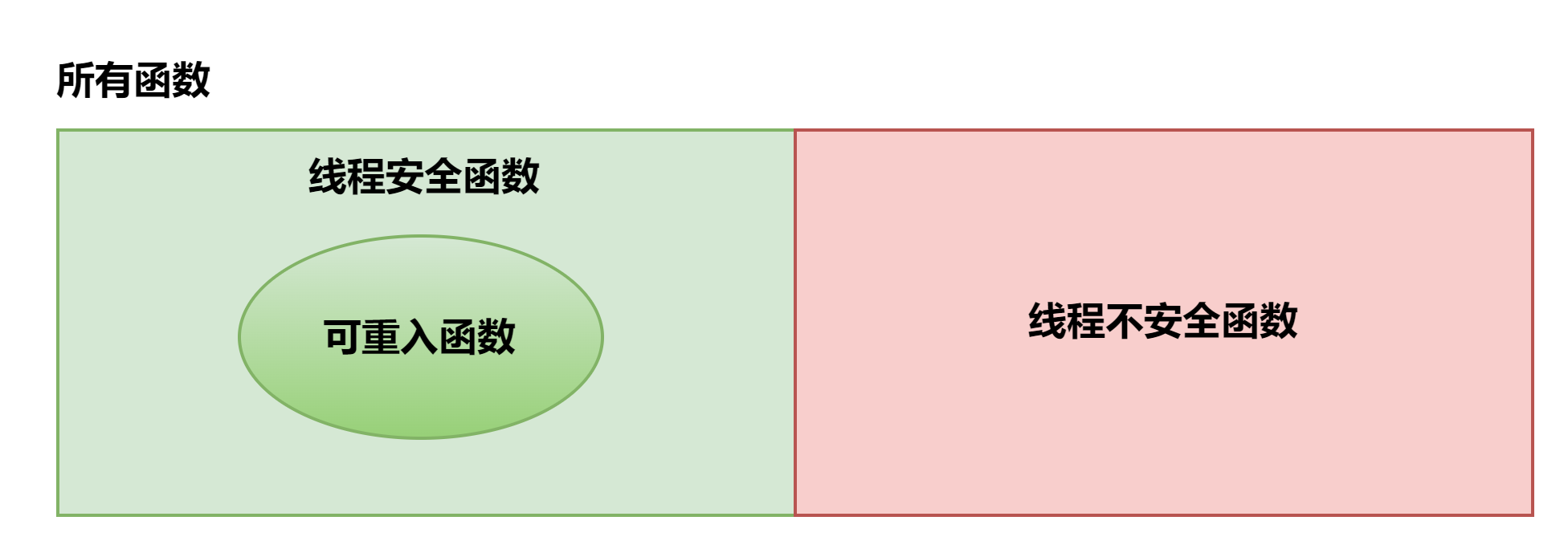
给与多个独立的硬件执行流,有些并发程序可以变成并行程序,但并不是所有的并发程序都可以变成并行程序。这里就涉及到可重入和线程安全的概念了:
可重入函数满足两个条件,1,函数是线程安全的,二,函数是可软中断的,执行了软中断处理历程后(比如被信号打断),再回过头来继续执行函数,结果仍然是正确的。
如果一个函数中官涌到了全局或者静态变量而没有保护,那么它不是线程安全的,也不是可重入的,而是归属于下图中的右边部分(线程不安全函数)。但是如果我们对这个函数加以改进,再访问全局或者静态变量时使用互斥量或则信号量等方式加锁保护,则可以使它变成线程安全的,但此时它仍然是不可重入的,因为通常加锁方式是针对不同线程的访问,而对同一个线程,加锁后的实现,重入后仍然有可能破坏之前的上下文。如果再进一步,将函数中的全局或静态变量去掉,改成函数参数等其它形式,则有可能使函数变成既线程安全,又可重入。
对比上下两幅图会发现他们非常相似,其实,某种程度上两幅图讲的是一个问题,对于可从如函数来说,无论硬件线程有多少个,都可以做到真正意义上的并行执行,而对于除此之外的情况,无法做到这一点。可以对照GPGPU编程来理解这一点。
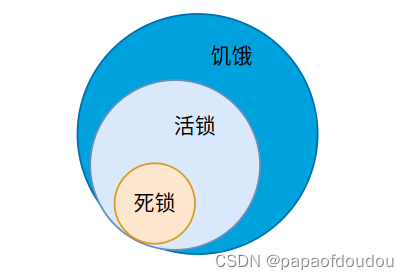
死锁只会发生在并发程序上面。其实除了死锁,操作系统中经非遇到的情况还有活锁和饥饿,不同的是死锁表现为永久等待无法解开,而活锁和饥饿可以解开。某种程度上,活锁和饥饿是死锁的通例,而死锁则是特例,它们的关系用欧拉图表示如下,欧拉图解是从外延的方面考虑两个概念,概念的内涵越大,外延越少,死锁的内涵最丰富,所以死锁的外延最小,属于其他两种情况的特例。活锁会导致频繁尝试拿锁的进程饥饿,但是饥饿不一定都是因为活锁。
百度百科对活锁的描述:


死锁是一般是局部的,并不是系统中的所有线程都参与到了死锁,至少IDLE线程一般不参与线程间的资源争用,不会参与死锁不是么?比如,下图的左边车道不受右边死锁的影响。

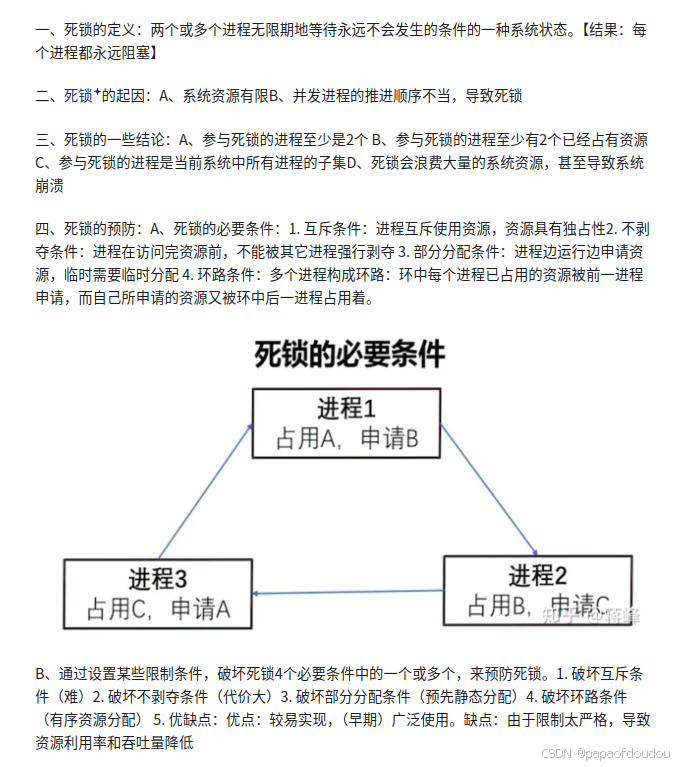
下面这段描述介绍了造成死锁的四个必要条件(充分条件是什么,那就是四个必要条件+恰当的timing).其中前三个条件和操作系统的设计有关,无法改变,第四个条件则可以通过软件设计破坏掉,这里所谓的环就是指的等待环。锁的等待关系构成一个循环群。
相关参考
https://zhuanlan.zhihu.com/p/158913156



















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











