






 本文详细介绍了YOLOV3的预选框验证过程,每个输入图像对应10647个预测框,通过IOU最大化原则确定负责预测的对象。每个网格有3个先验框,最终选择与实际边框IOU最大的先验框进行预测。YOLOV3的预选框尺寸基于anchor框组合,实际推理时,预测框是经过anchor框微调得到的。此外,探讨了YOLOV3-tiny模型与大模型的预选框数量和后处理逻辑差异。
本文详细介绍了YOLOV3的预选框验证过程,每个输入图像对应10647个预测框,通过IOU最大化原则确定负责预测的对象。每个网格有3个先验框,最终选择与实际边框IOU最大的先验框进行预测。YOLOV3的预选框尺寸基于anchor框组合,实际推理时,预测框是经过anchor框微调得到的。此外,探讨了YOLOV3-tiny模型与大模型的预选框数量和后处理逻辑差异。
对于一个输入图像,比如416*416*3,相应的会输出 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测框。我们希望这些预测框的信息能够尽量准确的反应出哪些位置存在对象,是哪种对象,其边框位置在哪里。
在设置标签y(10647个预测框 * (4+1+类别数) 张量)的时候,YOLO的设计思路是,对于输入图像中的每个对象,该对象实际边框(groud truth)的中心落在哪个网格,就由该网格负责预测该对象。不过,由于设计了3种不同大小的尺度,每个网格又有3个先验框,所以对于一个对象中心点,可以对应9个先验框。但最终只选择与实际边框IOU最大的那个先验框负责预测该对象(该先验框的置信度=1),所有其它先验框都不负责预测该对象(置信度=0)。同时,该先验框所在的输出向量中,边框位置设置为对象实际边框,以及该对象类型设置为1。
YOLOV3预选框定义如下,来源于darknet网络模型定义文件yolov3.cfg,anchors框的组合方式为宽X高。

输出tensor尺寸预选框的对应关系为下图所示:

每类框的大小示意图如下:
前三个anchor框大小:

代码:

中间三个anchor框大小:

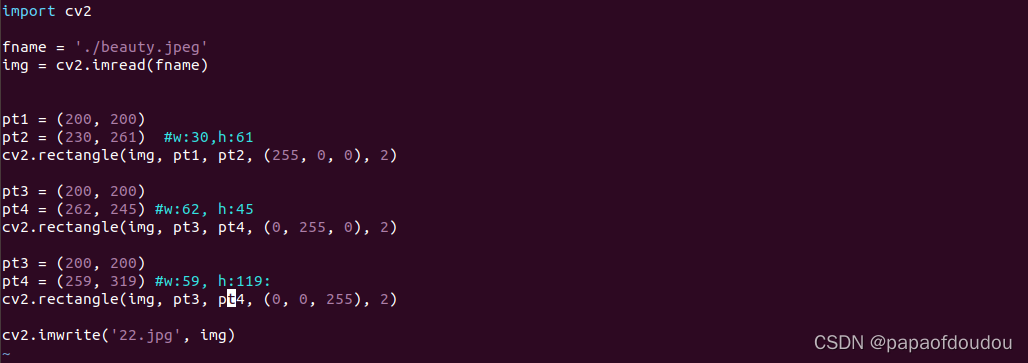
最后三个anchor框:


但是根据经验,好像我们实际推理得到的框,并不完全符合上面9类的尺寸,这是什么原因呢?
我们针对DARKNET代码中的逻辑来分析一下最后的预测框和与预选框之间的关系,浏览darknet代码,我们找到了使用anchor框的地方,就是下面的biases,初始化YOLO层的时候被赋值为 anchor数组中的宽和高。
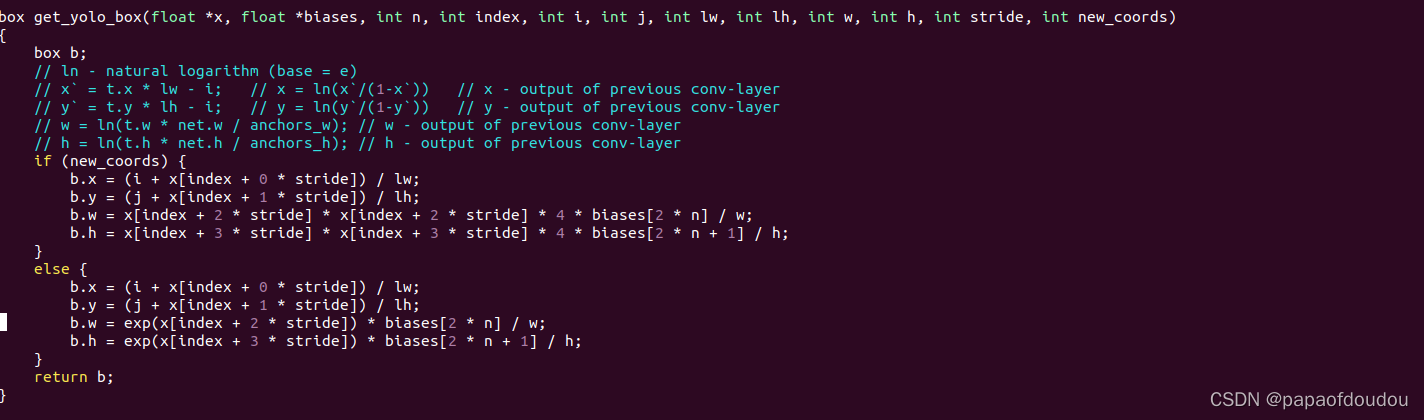
图中的new_coords我们不用理会,因为看模型,只有YOLOV4及以上的YOLO版本才使用新的坐标计算方式, 由于我们用YOLOV3做测试,这里一定是0,会走下面的分支。
我们按照如下方式修改代码,看预测框会发生何种变化:
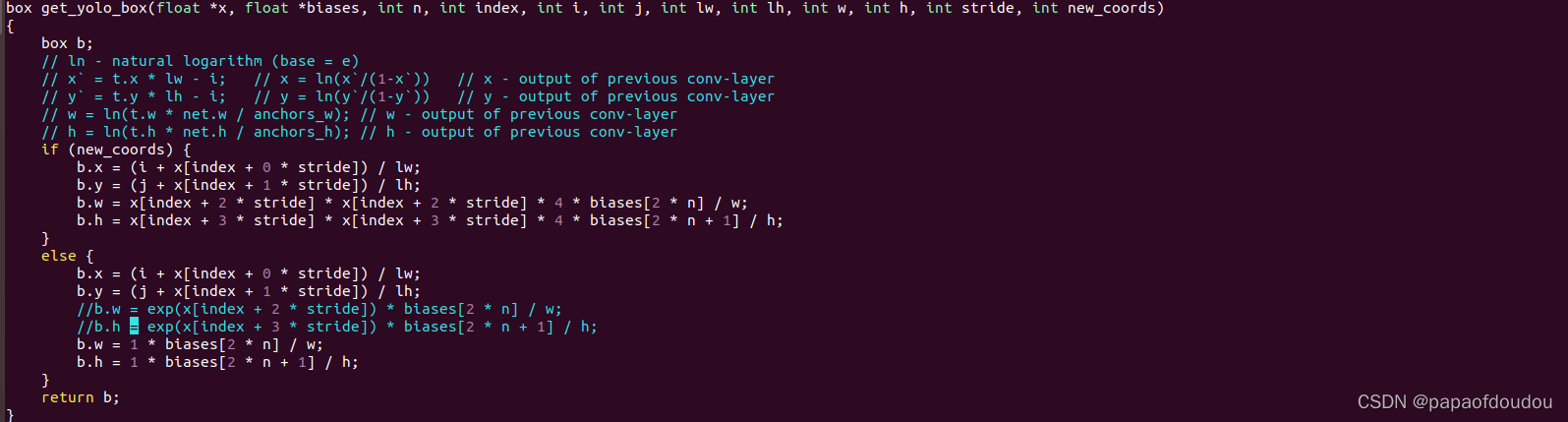
这样运行后,得到的坐标如下:

254-98= 156, 475-277=198 . 框尺寸为(156,198)
519-403=116, 176-86=90. 框尺寸为(116,90)
459-86=373, 464-138=326.框的尺寸为(373,326)
推理得到的三个框属于anchor框中的成员,所以,我们可以得到,推理框是anchor框经过微调后得到的,微调整系数就是e的某个推理系数为指数的值。
对比YOLOV3大模型的输出,会发现YOLOV3-tiny.cfg小模型输出只有两个tensor,它们的后处理逻辑相同,只是可以少处理一个tensor.
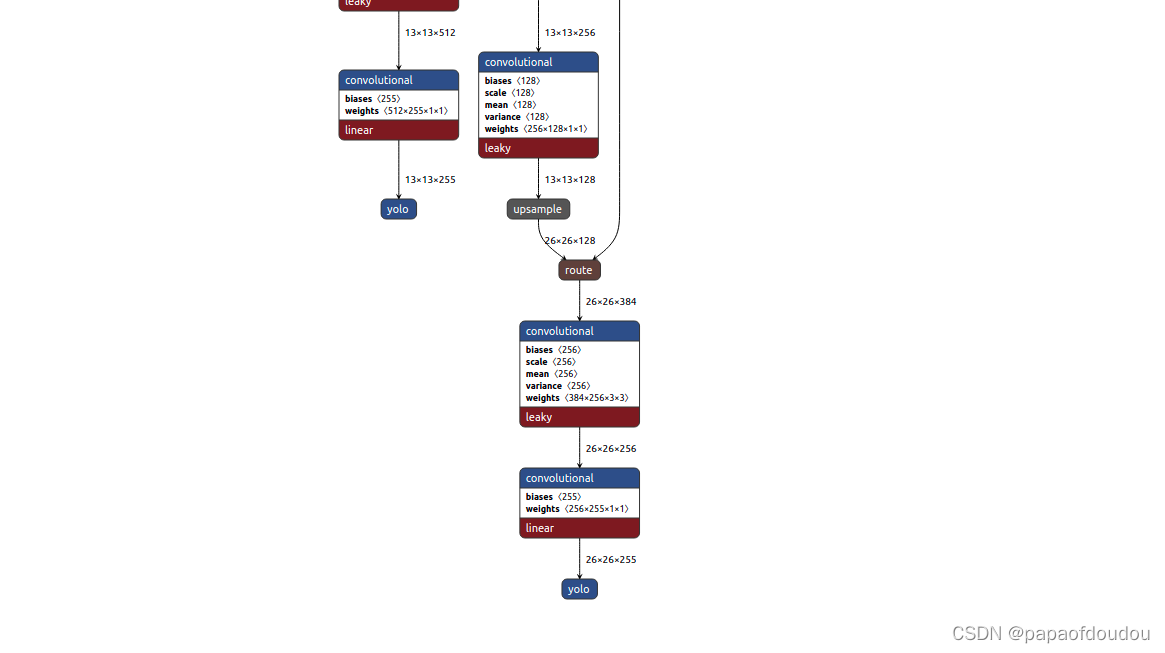

所以相应的,yolov3-tiny.cfg的预选框也只有6个,要比大模型的少三个,另外,还发现yolov3-tiny.cfg没有shortcut层,只有route和卷积层。



















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











