




YOLOv1、YOLOv2和YOLOv3对比
YOLO深度卷积神经网络已经经过原作者Joseph Redmon已经经过了3代4个经典版本(含YOLOv2和YOLO9000),俄罗斯的AlexeyAB已经完成了第4版迭代,并获得了Joseph官方认可。本文主要对前3个经典版本进行分析。
YOLOv1是2015年提出,其基本原理和创新点可参考Ross Girshick的论文《You Only Look Once: Unified, Real-Time Object Detection》(https://arxiv.org/abs/1506.02640)。
R-CNN系列
YOLOv1在设计之初主要是和Fast R-CNN进行比较,主要是YOLO系列模型是在R-CNN系列模型基础上解决其存在缺点问题提出的。
先简单介绍一下R-CNN系列,R-CNN(Region with CNN feature)顾名思义就是区域卷积神经网络特征提取方法,强调区域和卷积,当然信号检测的最终实现还离不开分类和边界回归。
先说区域R(Region),就是把一幅图先切分为S×S个网格,将小的区域网格使用SS算法(Selective search)不断的合并,然后提取特征每个小的网格的特征。SS算法不进行详细介绍,参考下图进行直观理解。

再说卷积(CNN),不同的卷积核在犹如一个个窗口,在图片上滑动,求相关性,为便于理解,姑且认为是求出的“相关度”。将不同的“相关度”反复归纳合并,最后计算出一个整体相关度。数字识别的卷积核大概只需要5、6个就可以,因为数字无非就是一些曲线、直线、交叉线的组合,第一层计算这些特征,第二层计算这些特征的组合等等。复杂的图像如人、动物等具有更多的特征,所以需要的卷积核就会比较多,特征的组合就比较多,最终网络深度也会比较深。
再说区域+卷积,就是将候选区图像标准化,使用卷积对区域特征进行判断,最后再通过更深层次的卷积层合并特征,获得最终结果。
最后再说分类与边框回归,分类+边框回归合起来完成目标检测,就是不但知道检测的结果是什么,还知道位置和尺寸大小,这样就可以得到我们经常看到的结果输出图像:先画个小框框,再打个标签,有木有觉得马上就高大上了,哈哈!分类呢,简单来说就类似于数字识别,把不同的图分成不同的数字结果,再根据排序找到相应的标签,这个会在以后详细介绍。边框回归通常就是预测出(x,y,w,h),这个方法很多,本文也不详细介绍,先挖个坑,以后再补。
以上描述的这个过程可以参考论文中的示意图,进行直观的理解。
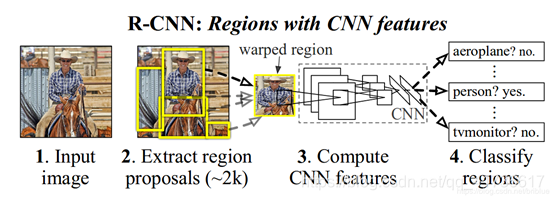
以上就是R-CNN的大体思路,可以说,合并选取的办法是符合科学的思考规律的,区域来源于“感受野”的概念,不同的感受野对应不同的区域。但是R-CNN就是因为这个感受野处理,首先需要消耗大量计算机资源进行候选区提取;其次图像归一化虽然人眼神经处理的很溜,计算机处理起来就会因为尺寸归一化问题导致计算量大大增加,同时因为分辨率的问题效果未必好;另外大量重叠的区域也会导致CNN过程重复计算。
那Fast R-CNN有什么好处呢?当然是“快”啦。和R-CNN最大的区别在于对于候选区的处理。
先来看R-CNN。尺度不同的候选区作为后续卷积网络的输入,为了与之兼容,如后续卷积网络采用 Alexnet(输入227×227), R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227×227的尺寸,然后进行分类,边框回归。注意哦,候选区确定的时候,其定位(x,y)已经最终确定了。那Fast R-CNN怎么处理呢?它使用了ROI Pooling层,哈哈,当然不是往RIO鸡尾酒池子放水啦。ROI是region of interest,它是根据我们感兴趣的区域将候选区图片非均匀的切分成固定的大小,每个元素的计算方法通过池化的方式,方法很简单,计算量大大减小。
Faster R-CNN速度更快,是在Fast R-CNN基础上,将选取候选区的SS算法改为RPN(region proposal net),RPN是一个全卷积神经网络。具体结构可以参考下图,这里不进行更加详细的讨论,希望了解可以参考相关文章。
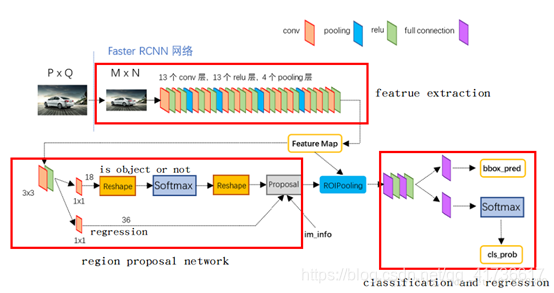
可以看出,R-CNN系列模型的结构就是在进行分类之前,就确定了候选区,然后再使用卷积神经网络完成最终分类和边框回归。需要特别说明的是,R-CNN系列模型通过softmax进行分类,Faster R-CNN在RPN网络中也使用了softmax进行候选框的分类,这样就使得整个模型进行了两次检测。第一次检测判断是不是能够对应上目标类的某一类,第二次检测是判断具体是哪个类型。
YOLOv1
了解了R-CNN系列方法,我们再看看YOLO系列方法。最大的区别就是不再提前确定候选区,也就是没有了R-CNN中的“R”,通过深度卷积神经网络进行处理,所有的结果都在YOLO层一次检测成型,这就是You Only Look Once的精髓吧?哈哈,虽然这个说法是强调一个字“快”但是我还是觉得他的意思在于前面不生成候选区,也不分类,所有工作都在最后成形,眼睛“感受野”中的内容直接一次检测成型。废话不多说,我们接着往下看。
结构
YOLOv1和R-CNN一样,开始也是先把图像分割成S×S个网格,只不过这个切分没有R-CNN那么密集,毕竟不需要提前合并候选框不是?YOLOv1结构如下图:
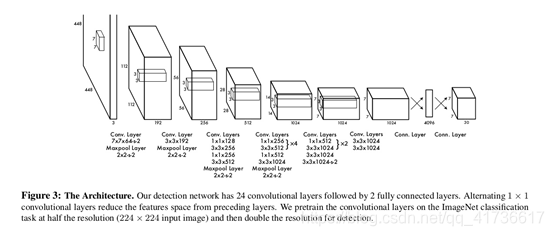
论文上说,前面的卷基层提取特征,后面的全连接层用于计算输出概率和坐标。网络主体采用24个卷基层+2个全连接层的结构。YOLOv1还有一个Fast YOLO版本,这个版本是将前面的24个卷基层裁剪为9个卷基层,其他都一样。
注意,这次我们要结合具体的模型进行讨论了。在YOLOv1的第一个模型中。输入图像都统一到448×448个像素的RGB三通道的图像上,方法嘛就是填充拉伸,长方形图像撑不满这个正方形图像的地方就用五十度灰涂上,这个具体方法以后有机会再说。根据上面的流程图,这个448(像素)×448(像素)×3(通道)的图像,进入网络后:
第一层:使用分辨率为7×7×64卷积核(步长为2),将448×448×3的图像先变为224×224×64图像;再使用分辨率为2×2(步长为2)的最大池化层,将图像变为112×112×64的图像。注意哦,卷积核的个数决定计算后图像的通道数,先挖个坑,后头专门讲darknet使用图像重排和通用矩阵乘法(GEMM,General Matrix Multiplication)方法求卷积。总之,记住卷积后的图像长宽等于原始长宽分别除以卷积步长、通道数等于卷积核个数就行了。
第二层:使用3×3×192的卷积核(步长为1),将112×112×64图像变为112×112×192图像;再使用分辨率为2×2(步长为2)的最大池化层,将图像变为56×56×192的图像。
第三层:使用1×1×128的卷积核(步长为1),将56×56×192图像变为56×56×128图像;使用3×3×256的卷积核(步长为1),将56×56×128图像变为56×56×256图像;使用1×1×256的卷积核(步长为1),56×56×256图像没有变化;使用3×3×512的卷积核(步长为1),将56×56×512图像变为56×56×512图像;再使用分辨率为2×2(步长为2)的最大池化层,将图像变为28×28×512的图像。
第四层:1×1×128的卷积核(步长为1)和3×3×256的卷积核(步长为1)先使用4次,再参考之前的方法,得到14×14×1024的图像。
第五层:得到7×7×1024的图像。
第六层:3×3×1024的两种卷积核使用后得到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6227
6227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











