






 本文探讨了神经网络为何需要激活函数,指出没有激活函数的网络仅能实现线性变换,等价于单层网络。通过数学证明,阐述了激活函数引入的非线性特性对提升网络能力的重要性。
本文探讨了神经网络为何需要激活函数,指出没有激活函数的网络仅能实现线性变换,等价于单层网络。通过数学证明,阐述了激活函数引入的非线性特性对提升网络能力的重要性。
这个问题的原因,很多教材上讲是为了引入非线性,也就是说只有引入激活函数层建立的网络才具有非线性特征,那疑问就来了,没有激活函数层就没有非线性了吗?如果答案是肯定的话,是否存在严谨的理论证明?
以为下面的网络为例,它的每一层都是全连接层,并且没有激活函数层,我们列出各层之间的数据关系公式:
第一层输出:
第二层输出:
...
最后一层:
逐层代入得到:
由于Wn,Bn都为常函数,所以,根据上式可以看出,输出是输入的线性函数,所以网络一定是线性的,不具备非线性特征。
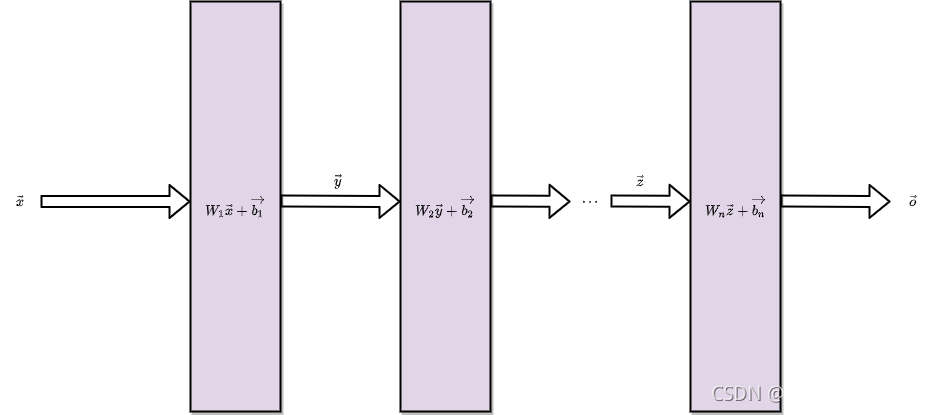
从联立后的式子可以看出,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络,输入和输出依然是线性关系。
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数,在代码中,全连接层经常被叫做affine layer(仿射层),也是这个意思。
上面的证明过程依赖于数形结合,下面用解析的方式,用更加数学的语言来证明这个结论:
对于一个没有激活函数的网络,假设
是第k层网络的第j个神经元输出,是这层网络的输入,所以,
可以表示为输入的线性函数:
然后,另g为下一层的网络输出,则针对下一层来说,为这一层的输入,所以:
从而我们证明了,为什么一定要引入激活函数来给网络增加非线性。
附:
这是一篇论文中的证明,形式更加优雅:



















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











