






1.现代终端设备一般都跟云端服务器相连,但只要可能,我们都希望计算可以在本地终端解决,这样做的好处是多方面的:既可以减小网络带宽的压力,又可以避免网络传输产生的时延,还可以让用户的数据更安全。现代终端设备一般用一个片上系统 (SoC)做计算,上面部署了通用的CPU和集成显卡。对于日益增多的卷积神经网络推理计算来说,在移动端的CPU(多数ARM,少数x86)上虽然优化实现相对简单(参见我们对CPU的优化),但此处它并非最佳选择,因为:1)移动端CPU算力一般弱于集成显卡(相差在2-6倍之间);2)更重要的是,已经有很多程序运行在CPU上,如果将模型推理也放在上面会导致CPU耗能过大或者CPU节流,造成耗电过快同时性能不稳定。所以在移动端进行模型计算,集成显卡是更好的选择,说起来很有道理,但用起来就不一样了。实际中我们发现移动设备上的集成显卡利用率很低,大家并不怎么用它来跑卷积神经网络推理。原因其实很简单:难用。在AWS,我们面对很多移动端机器,里面用到集成显卡多数来自Intel, ARM和Nvidia,编程模型一般是OpenCL和CUDA。虽然对于某些特定模型和算子,硬件厂商提供了高性能库(Intel的OpenVINO, ARM的ACL, Nvidia的CuDNN),但它们覆盖度有限,用起来不灵活,造成即使对单一硬件做多模型的优化,工程代价也很大,遑论我们面对的硬件类种类繁多。总之,要用传统方法在集成显卡上实现一个通用高效的模型推理并不容易。
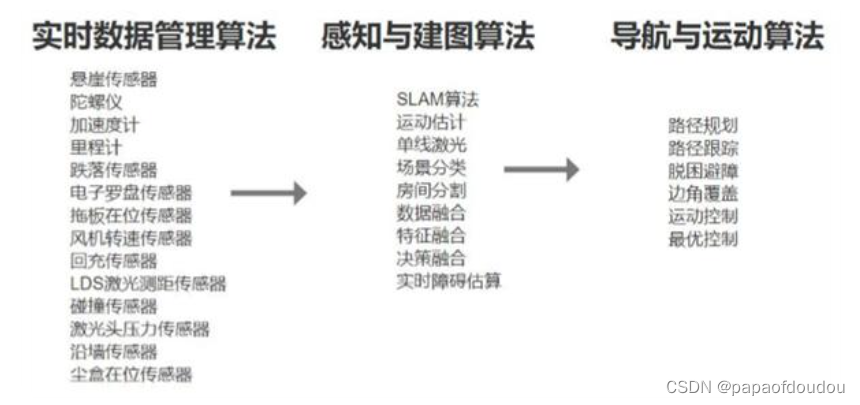
2.深度学习两大问题,图像分类目标检测(算法专家称是回归),图像分类用来判断物体是什么,目标检测(回归)用来画框。
在图像分类问题中,ResNet,VGG,GoogLeNet,AlexNet等网络呀识别出给定图片中的物体的类别,分类是非常有意义的基础研究问题,但是实际中难以直接发挥作用,因为实际中的图片往往有非常复杂的场景,可能包含几十甚至上百种物体,而图像分类算法处理的图片中只有一个物体,因此实际应用中,不但要检测出一个物体出来,还要框出来,定位,更进一步要把图片中所有的物体都检测出来并框出来,这就是目标检测的使命。
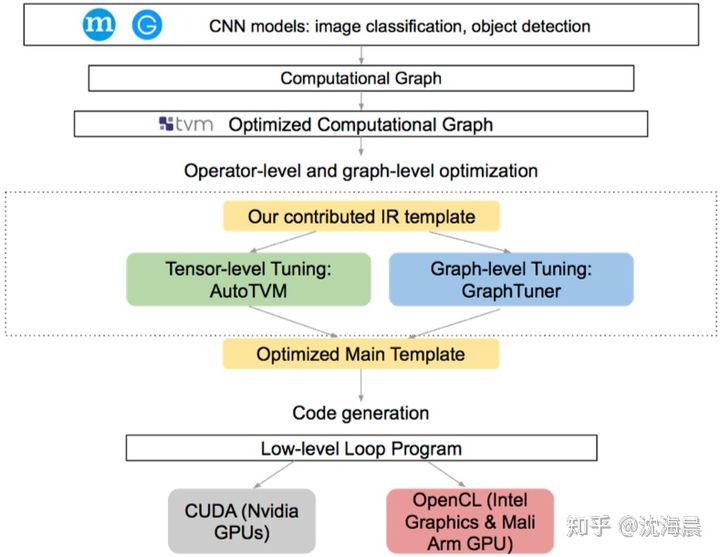
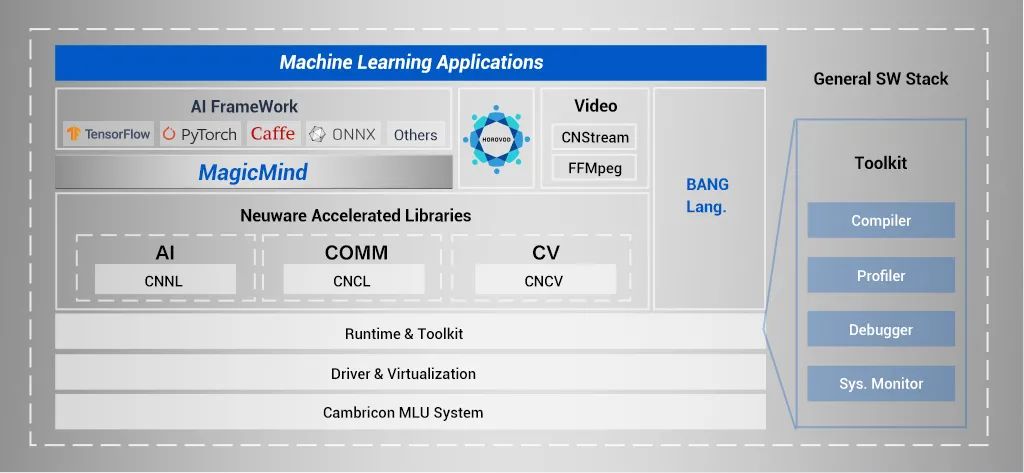
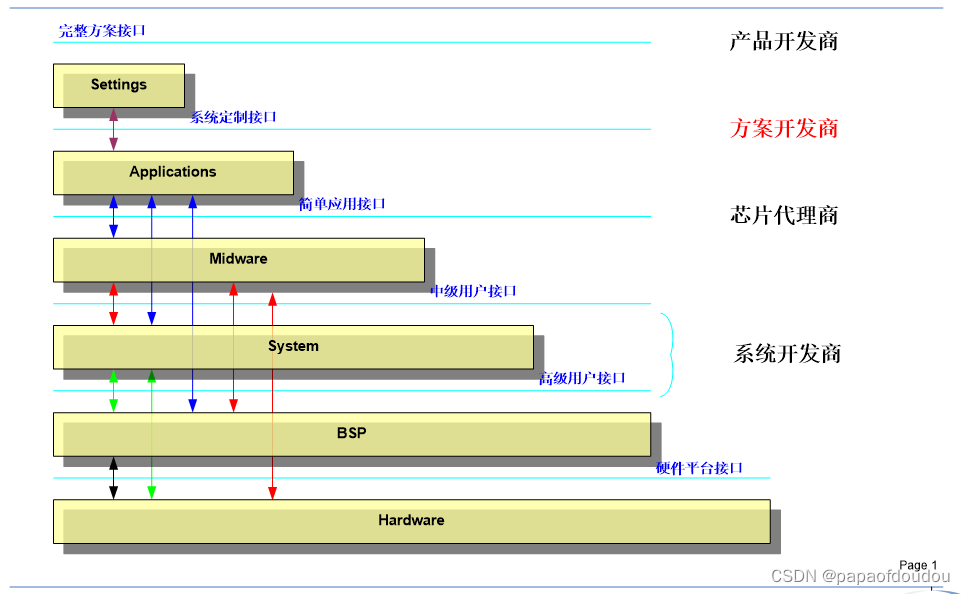
3.AI编译器架构图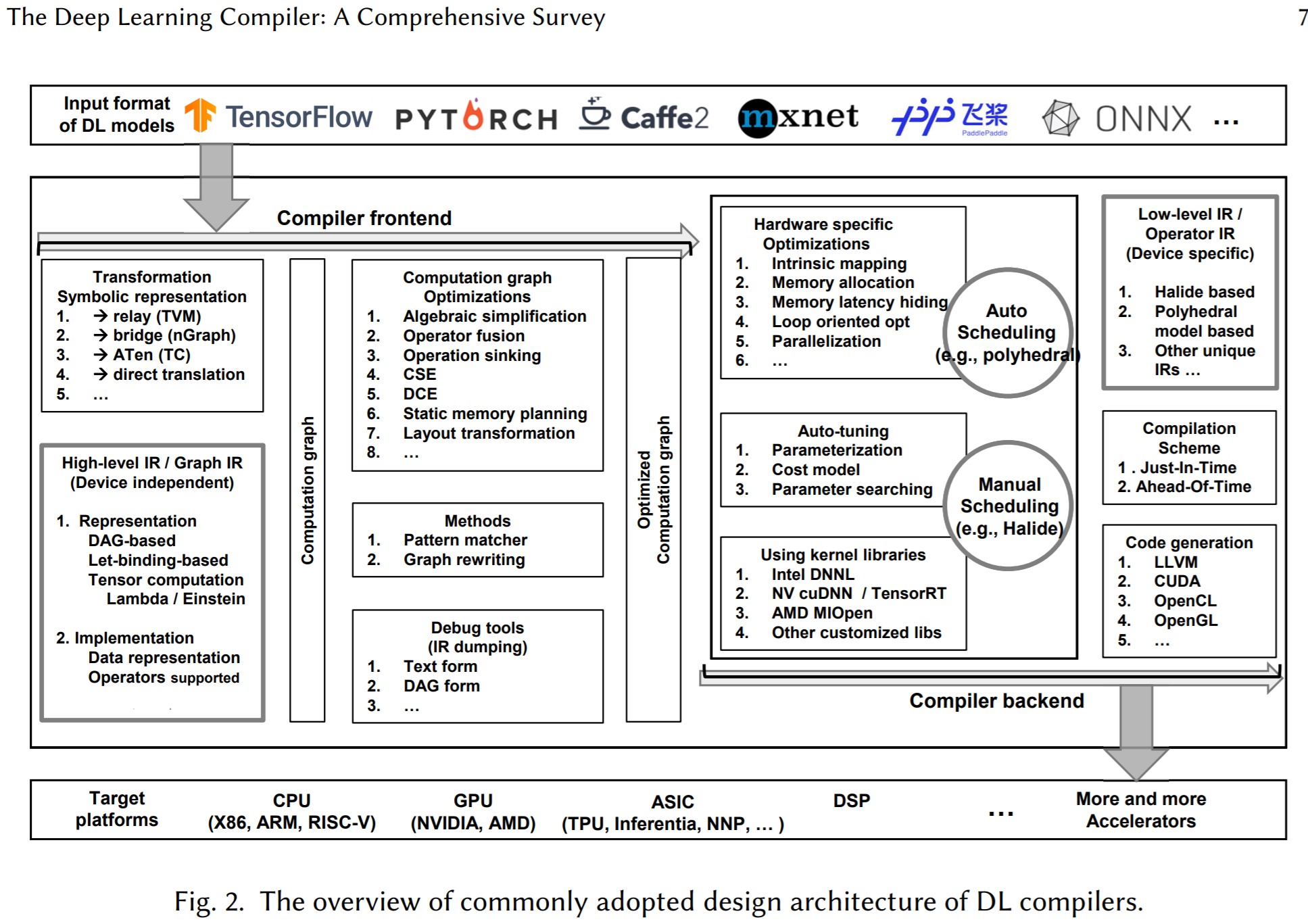
4:


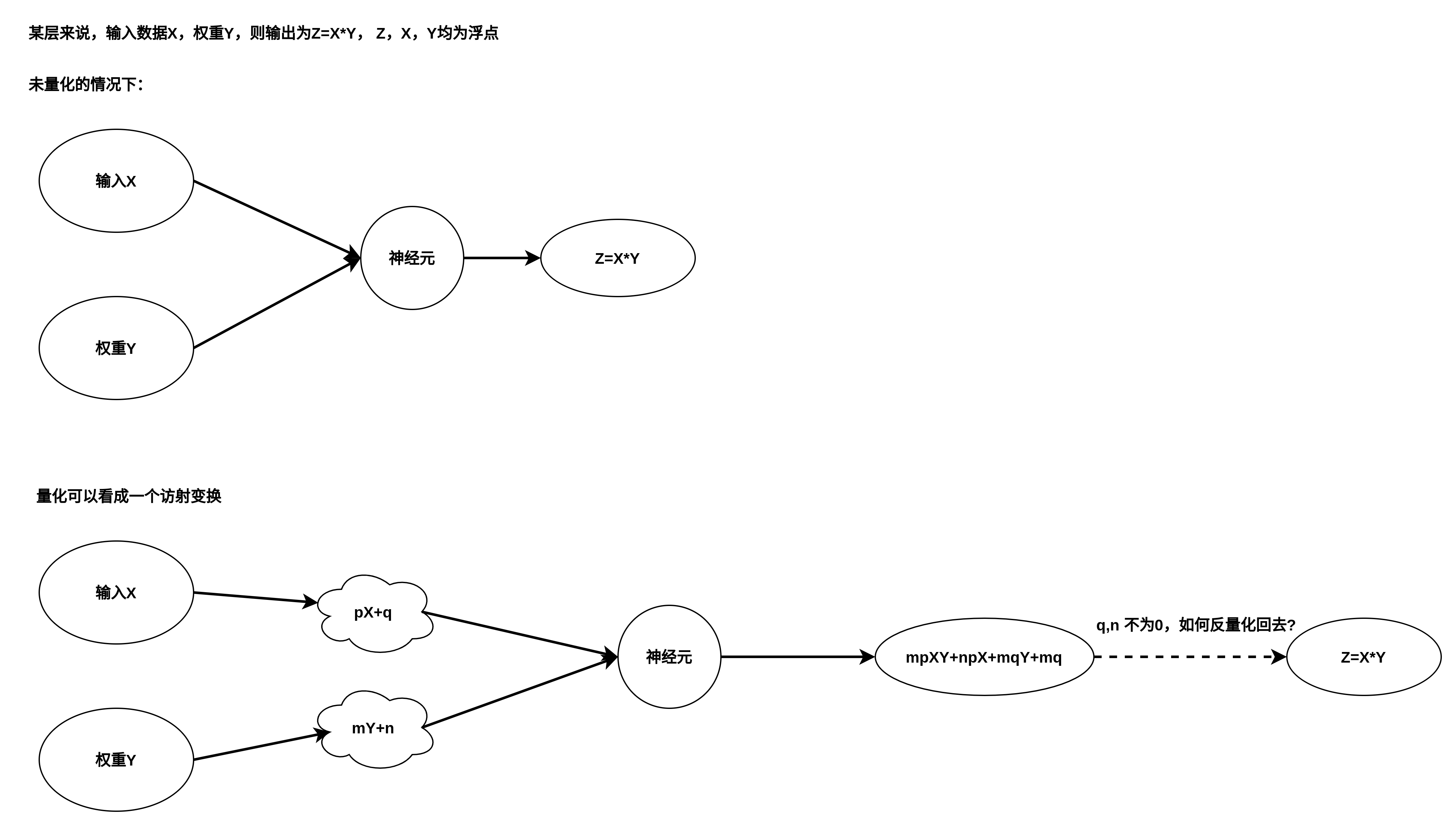
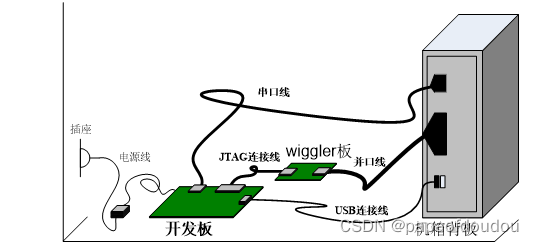
5.深度学习的技术方案:


6.Linux平台上,可以预见,算法跑的时候内核态占用不多,多的是用户态,内核中等NPU中断会睡眠在等待队列中,那么,既然有了NPU,为何还需要用户态算法库呢,为什么软件上还要做算法,答案是,软件上做算法是为NPU做数据前处理或者后处理,这部分算法要求的算力比重于NPU相比很小,主要是做格式转换,reshape之类,归一化操作,均值,方差类操作,以及浮点的像素操作,图片分辨率很小,一般300*200够用了。
7.NPU运行的结果是以什么形式给到用户的? 比如,一张图片做物体检测,那输出应该是坐标位置,这些坐标位置是存储在NPU的寄存器中吗还是哪里?
回答是,网络有个输出buffer,结果存放在里面。
8.卷积网络是指那些至少再网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
9:

10:CUDA和OpenCL以及硬件平台之间的关系。

11:内存级

12: 什么是IC数字设计中的数据反压?
以VIPP为例,就是VIPP模块从DDR 要参数, 发送请求后,DDR回数据,VIPP必须接收,如果不接收,数据就丢了,这叫不支持反压。
所谓支持反压,意思是说,别人给我数据,我可以告诉他我没有准备好,那么等我准备好后数据再给我,数据不会丢。
CPU 访问寄存器,我是可以晚些响应的,他会等我。 但是MBUS(就是和DDR交互的)的数据,是不等slave(下家)是否准备好的,他认为你问他要数据了,你一定是准备好的
就是说不支持反压,源端发送的数据必须要接受,不接受就丢了.反压的话,就是两家可以商量
一个是强买强卖,要给是友好协商.对吧?
当入口流量大于出口流量,这时候就需要反压,或者,当后级未准备好时,如果本级进行数据传递,那么它就需要反压前级,所以此时前级需要将数据保持不动,直到握手成功才能更新数据。而反压在多级流水线中就变得稍显复杂,原因在于,比如我们采用三级流水设计,如果我们收到后级反压信号,我们理所当然想反压本级输出信号的寄存器,但是如果只反压最后一级寄存器,那么会面临一个问题,就是最后一级寄存器数据会被前两级流水冲毁,导致数据丢失,引出数据安全问题,所以我们此时需要考虑反压设计。
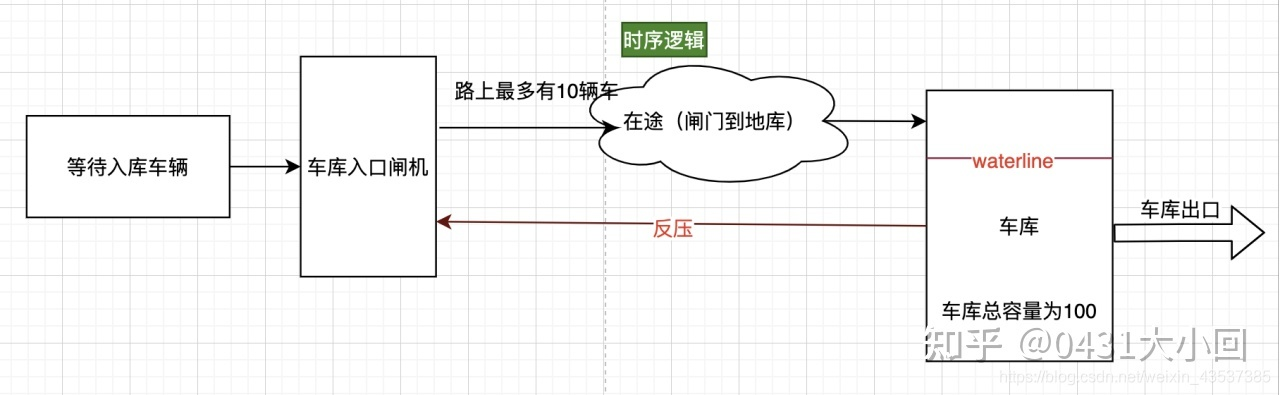
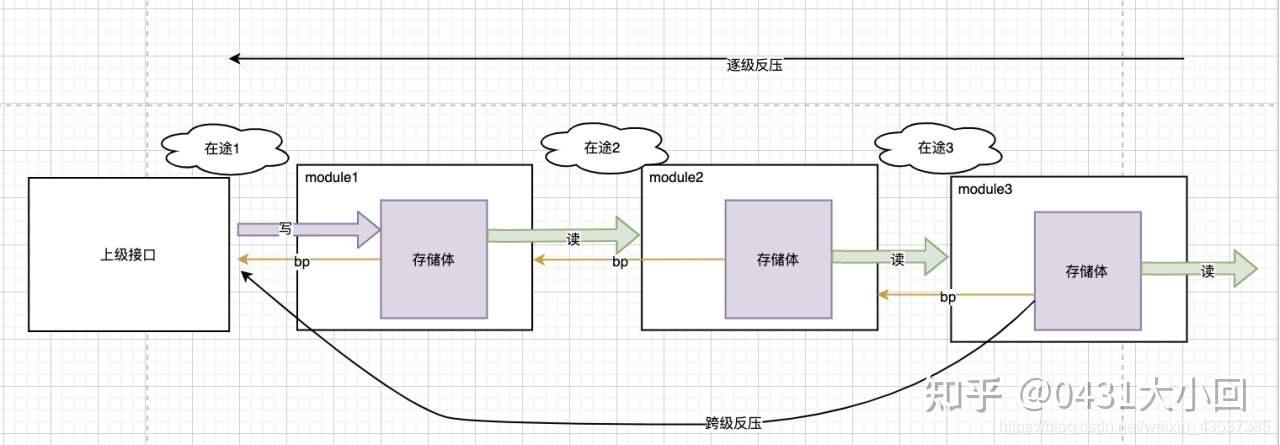
也可以参考这篇文章了解反压:
数字芯片设计——握手与反压 - 知乎
13: 卷积运算一个output channel(输出通道)一个bias.
14: OpenVX

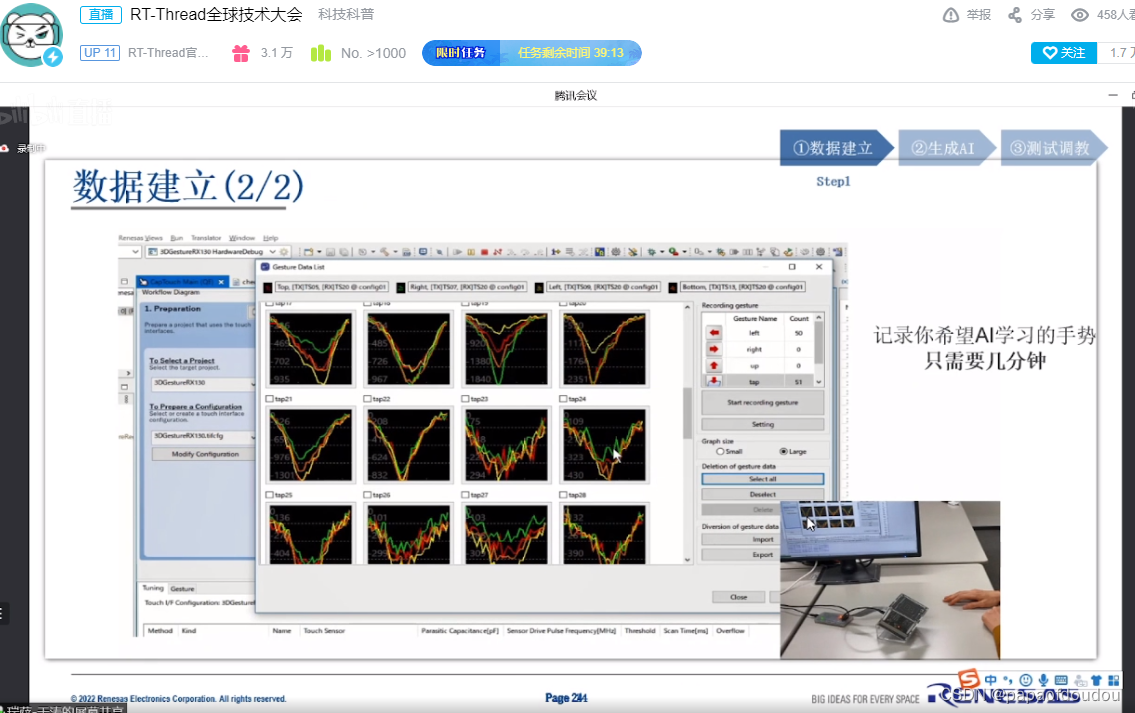
15:获取数据,清晰数据,训练模型,测试模型,投入使用.
16:机器人分类:
17:问:我看书上说,卷积神经网络缺乏可解释性,我的理解是运行结果有一些撞大运的味道,只是经过训练的网络,撞大运的概率高,可以这样理解吗?
答: 是的
再问:会没有有这种情况,对于一张识别准确率达到%99的图片,可能会存在一些暗点,如果将这些暗点的像素修改,即便是人眼看不出区别,网络的结果也会发生巨大变化?
回答:是的!
所以,总体看来,感觉AI这东西有点不靠谱,消费电子还好,如果涉及到人命关天的事情,还是靠不住,虽然Resnet的识别结果已经超越人类,但人类可以容忍自己的错误,却无法容忍机器犯错。不过生活中的应用足够了,至少,孩子问你路边的花花草草叫啥名啊,也不至于答不上来。
18.对NPU的一些认识:
一颗AI芯片的算力只是基础,再加上
1.算子支持的覆盖度
2.算法移植的友好度
3.量化反量化能力
4.编译器对网络的fuse及针对自身NPU优化
5.NPU和CPU之间数据共享能力
6.CPU对网络的前后处理性能
等因素结合起来才能真的称为更好的AI芯片。
19:一张有目标的图片和一张没有目标的图片,网络运行时间是一样的吗?每一层的计算都会执行的.
嗯,是一样的,除了后处理部分,检测不到目标就不用往后做后处理(分析出框的位置之类),
网络运行时间几乎是一样的,无论有没有目标,网络运行的时间都是一样的,区别在于后处理部分(检测的结果赋值到目标空间中),但是这块几乎不怎么耗时。
20:AlexNet学习出来的特征是什么样子的?
- 第一层:都是一些填充的块状物和边界等特征
- 中间层:学习一些纹理特征
- 更高层:接近于分类器的层级,可以明显的看到物体的形状特征
- 最后一层:分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
即无论对什么物体,学习过程都是:边缘→部分→整体,这个和我们人类的学习,认识过程是类似的,对于新鲜的事物,先拿起来,捧在手里看一看,有总体的轮廓上的认识,然后在敲一敲,拆一拆,分解一下,了解它的组成部门,每个部分的工作原理,最后在把东西拼成完整的整体,进而形成了一个统一的认识。
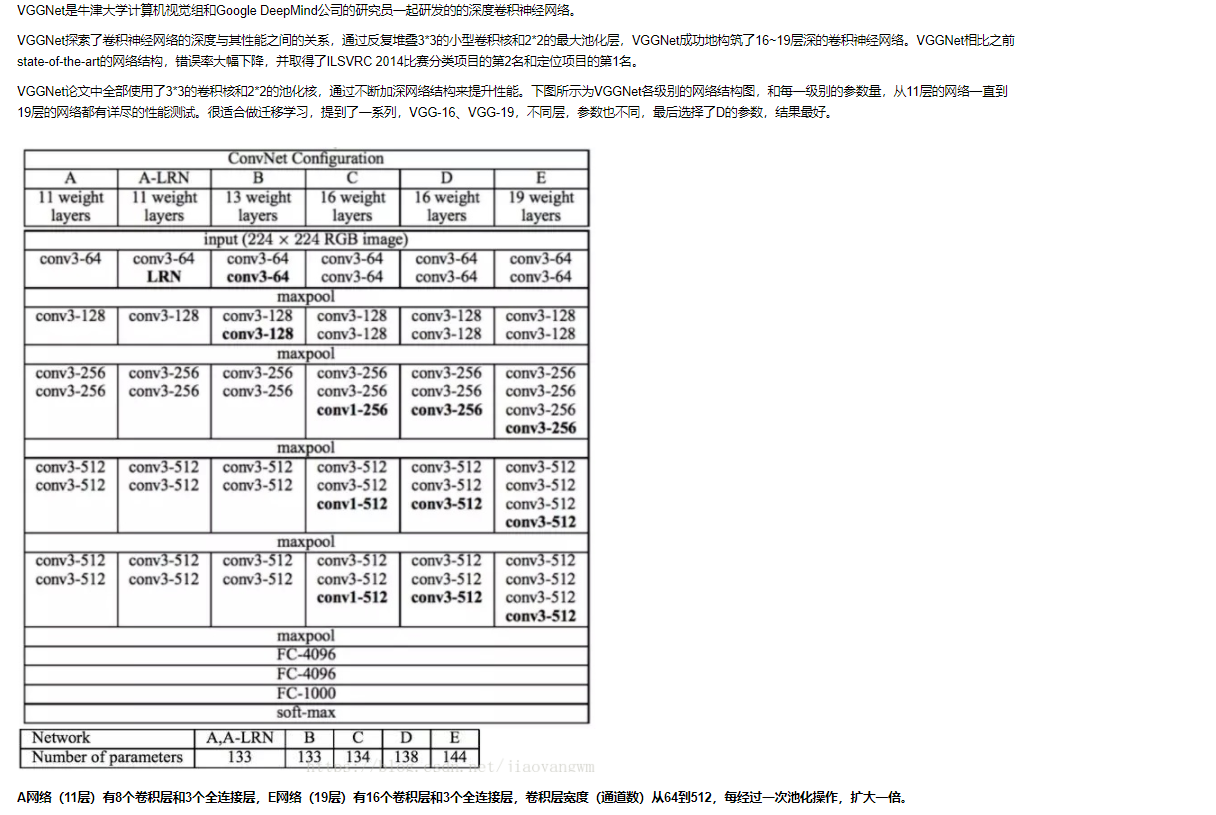
21:关于CONV3-512的表达解释,可以看下图:
22:神经网络学习过程本质就是为了学习数据分布.
23:
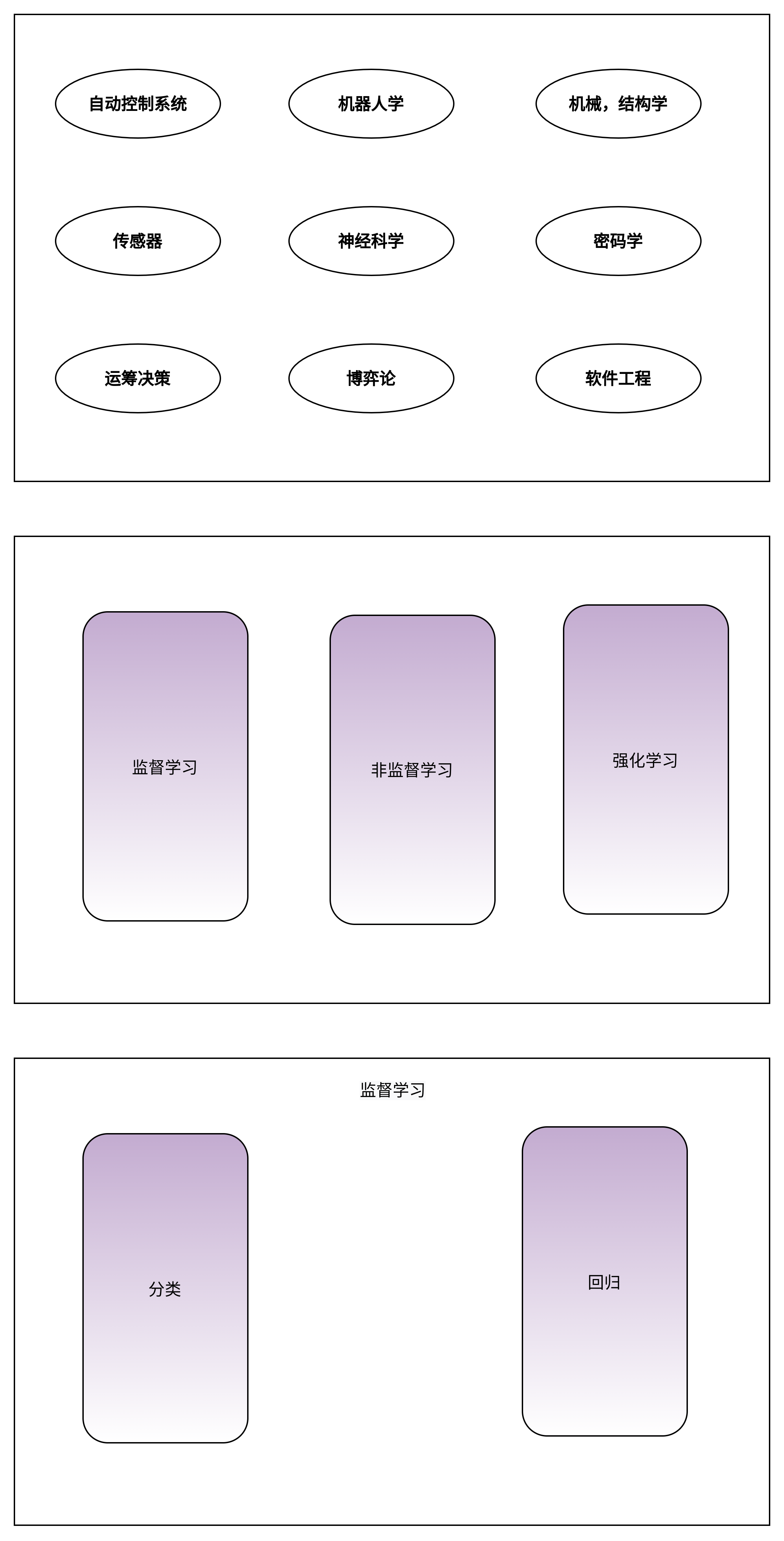
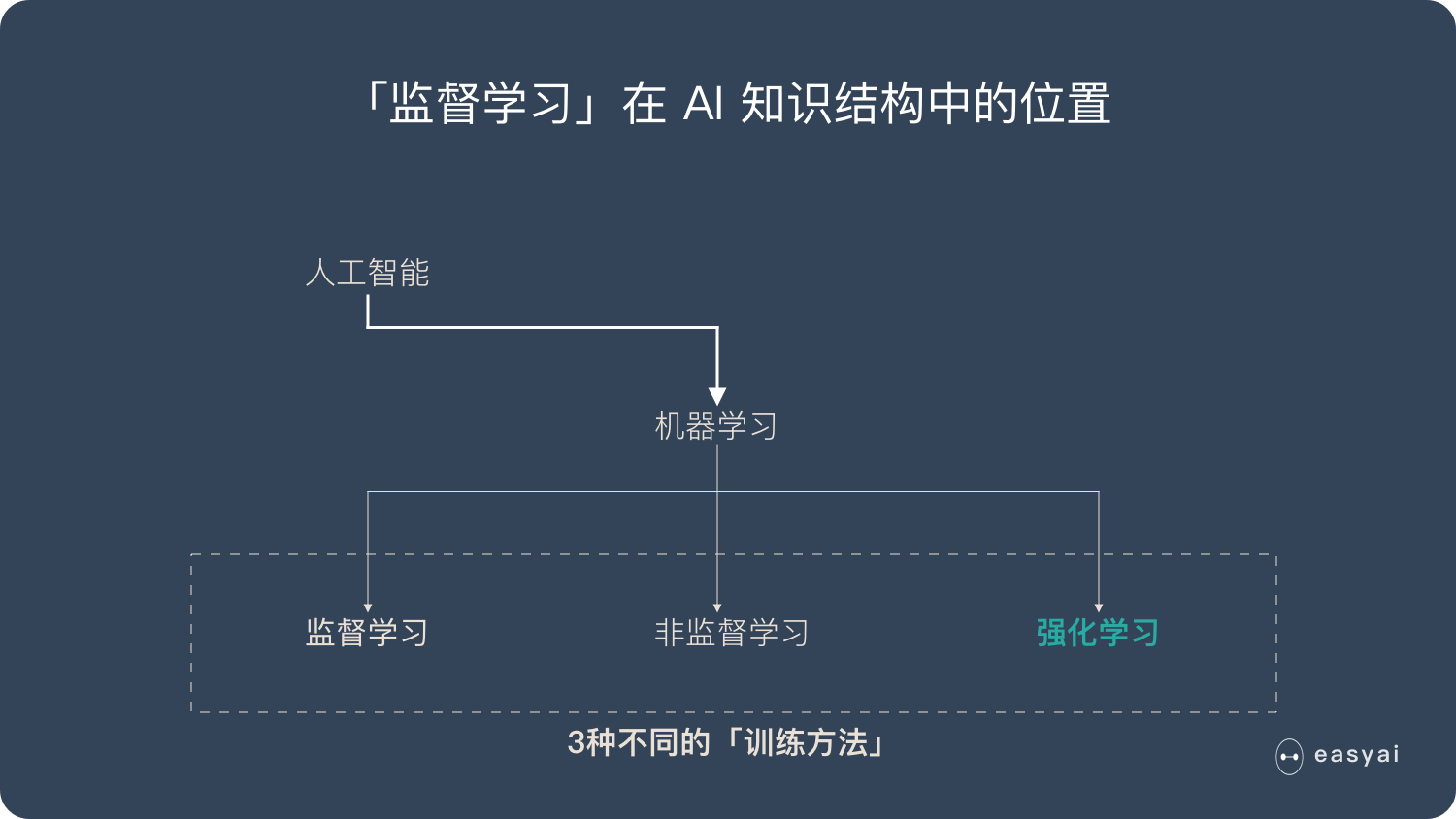
监督学习 (Supervised Learning): 这应当是应用最多的领域了,例如人脸识别,我提前先给你大量的图片,然后告诉你当中哪些包含了人脸,哪些不包含,你从我给的照片中总结出人脸的特征,这就是训练过程。最后我再提供一些从来没有见过的图片,如果算法训练得好的话,就能很好的区分一张图片中是否包含人脸。所以监督学习最大的特点就是有训练集,告诉模型什么是对的,什么是错的。
非监督学习 (Unsupervised Learning): 例如网上购物的推荐系统,模型会对我的浏览记录进行分类,然后自动向我推荐相关的商品。非监督学习最大的特点就是没有一个标准答案,比如水杯既可以分类为日用品,也可以分类为礼品,都没有问题。
强化学习 (Reinforcement Learnong): 强化学习应当是机器学习当中最吸引人的一个部分了,例如 Gym 上就有很多训练电脑自己玩游戏最后拿高分的例子。强化学习主要就是通过试错 (Action),找到能让自己收益最大的方法,这也是为什么很多都例子都是电脑玩游戏。
分类 (Classification): 例如手写体识别,这类问题的特点在于最后的结果是离散的,最后分类的数字只能是 0, 1, 2, 3 而不会是 1.414, 1.732 这样的小数。
回归 (Regression): 例如经典的房价预测,这类问题得到的结果是连续的,例如房价是会连续变化的,有无限多种可能,不像手写体识别那样只有 0-9 这 10 种类别。
这样看来,接下来介绍的手写体识别是一个 分类问题。但是做分类算法也非常多。
人工神经网络 (Artifitial Neural Network):这是个比较通用的方法,可以应用在各个领域做数据拟合,但是像图像和语音也有各自更适合的算法。
卷积神经网络 (Convolutional Neural Network):主要应用在图像领域,后面也会详细介绍。
循环神经网络 (Recurrent Neural Network):比较适用于像声音这样的序列输入,因此在语言识别领域应用比较多。
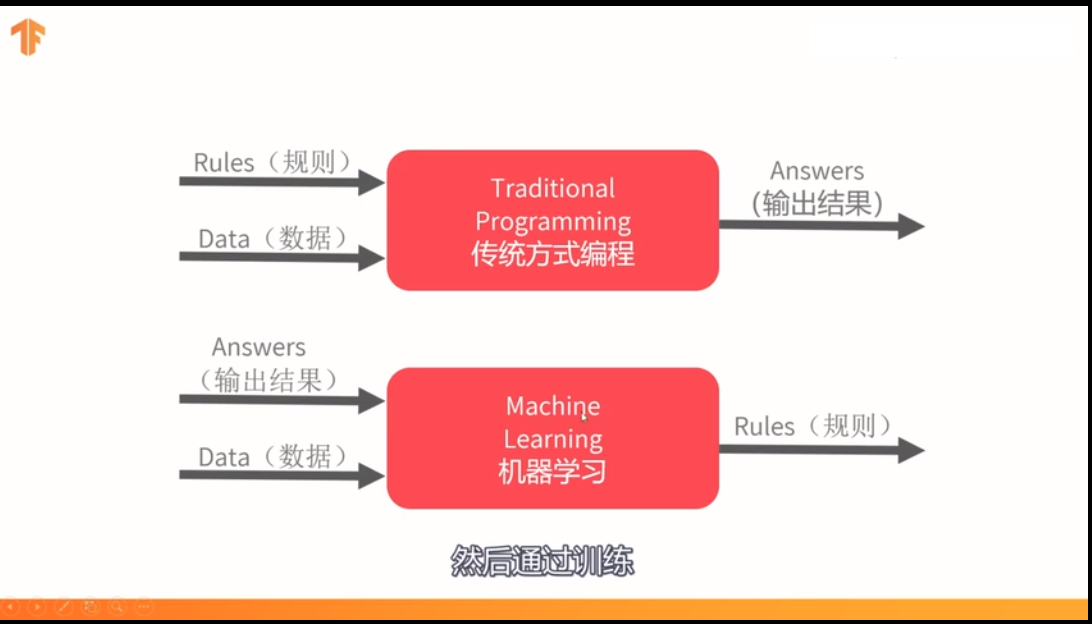
24:机器学习的原理/思路,让机器产生规则
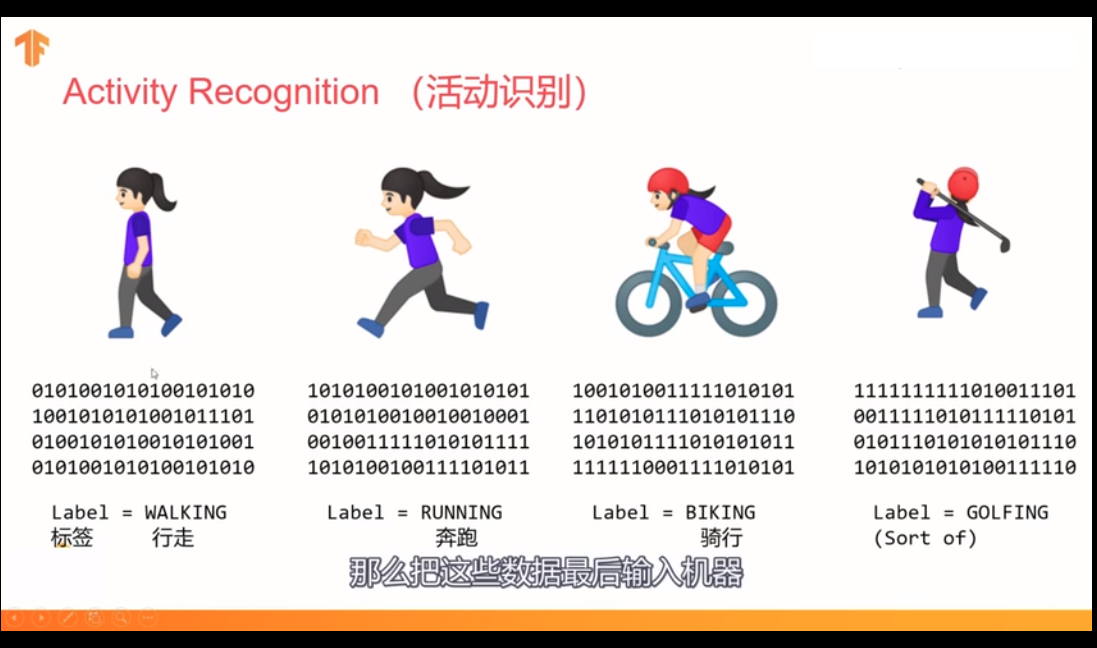
25:关于数据集的逻辑
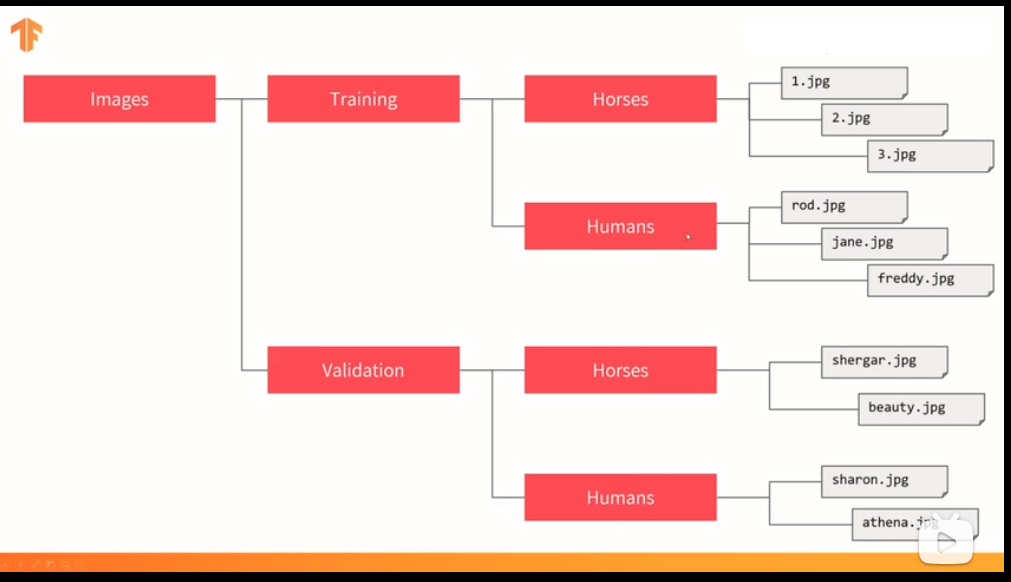
27:卷积神经网络结构
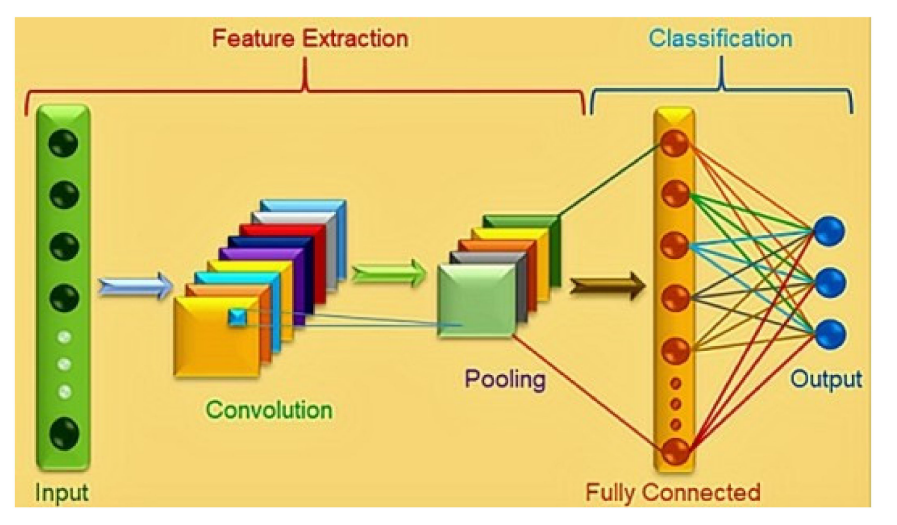
28:基因决定上限,读书决定下限. 模型决定了上限,数据决定下限.
人消化能力强,几张图片就训练好了,模型胃口大,吃成千上万张图片,才能训练好。
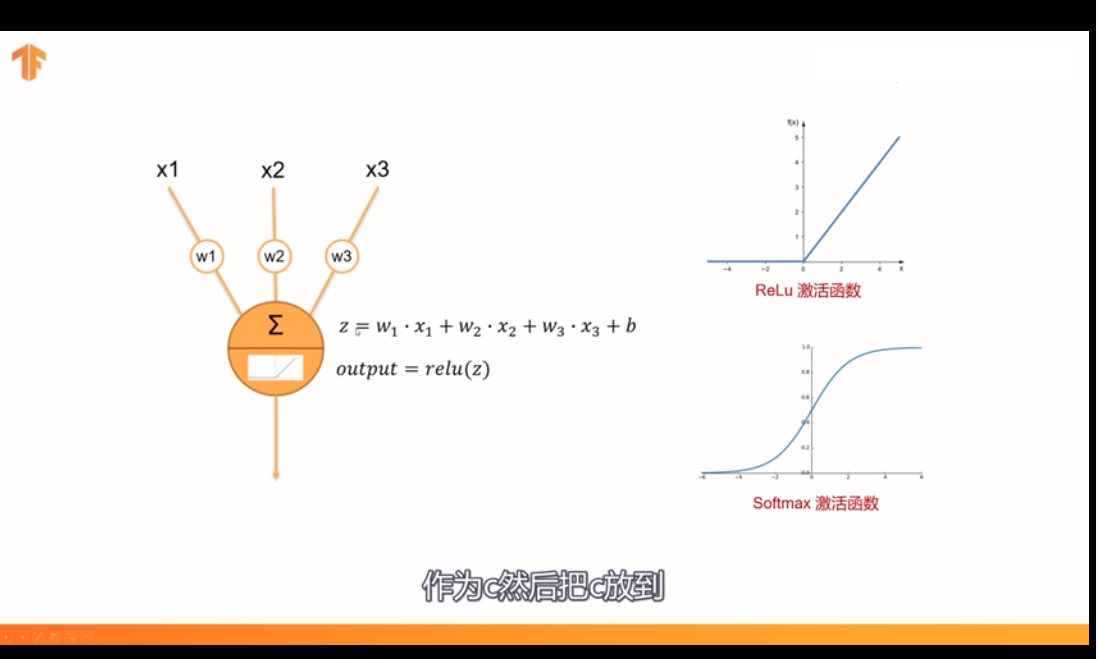
29:输出层所用的激活函数,要根据求解问题的性质决定,一般回归问题用恒等函数,二元分类问题可以使用sigmoid函数,多元分类问题问题可以使用softmax函数.
输出层神经元的数量,需要根据待解决的问题决定,对于分类问题,输出层神经元的数量一般为类别的数量,比如,对于某个图像,预测它是0到9中哪个的问题,10类别分类问题,可以设定输出神经元的数量为10个。
30:神经网络里面,算法即模型,模型即算法,算法训练好之后会保存为模型何权重,模型之外还会有一些前后处理。
31:饼的画法-商汤饼
32:TVM is what?
这是一个试图一统AI框架前端到不同NNA加速器的设计框架,原理和思想和GCC, LLVM等想通,可以参考,
 https://tvm.apache.org/docs/tutorial/introduction.html#sphx-glr-tutorial-introduction-py
https://tvm.apache.org/docs/tutorial/introduction.html#sphx-glr-tutorial-introduction-py
33:目标检测,物体检测,object detection, od
这几个概念是等价的,他们都等价于what and where?
what? 识别, recognition. 分类问题。
Where? 定位,localization.回归问题。
34:关于卷积核的形状,可以这样理解:
shape=[batch_size,width,height,channels]
35:方舟编译器的架构
36:强化学习.
37:卷积到底卷了啥
38:OCR
39:所有的机器学习模型都是错误的,但是它也是有用的,机器学习忽略了因果推理,由果推因。
40:归一化自适应滤波(NLMS)和自适应滤波(LMS)
自适应滤波:最小均方误差滤波器(LMS、NLMS) - 桂。 - 博客园
41:
问:有些手机芯片上,有ARM提供的很强大的通用算力,包括NEON指令集,VFP指令集对算法进行加速,可是为什么一般还会集成一个类似HIFI5这样的DSP,从算力角度来讲,ARM的应该是够的吧。DSP的浮点精度是不是比NEON这些要高一些,音频,音质对计算的精度可能会高.
答:很多都是异构结构,各自有自己的专长,dsp可以做语音的一系列业务,相对ARM来说功耗低算力不差arm,而且也不占用arm的处理器资源,arm处理器可以做其他的业务(arm的处理业务总量是有限的,别的处理器分担了一些,arm就能做更多其他的事,性能也能上去)。精度不会差吧,单精度,dsp可能比arm多双精度(我没注意),应该都是32位、16位浮点吧,只是整点mac arm较neon,处理能力会强,hifi5的mac能力比arm的强,ai性能是要更好的
问:嗯,那么手机上放HIFI5,是为了功耗? 算力其实AP已经能够cover了么
答:应该是的,hifi5的能效比是比arm的好的
问:嗯嗯,可能整体上,DSP的算力功耗比要比ARM强
我们现在其实还没有很好的用起来,方案上还没落地应该,之前hifi4也没有用起来?
答:用起来指的是哪方面?我记得HIFI4在linux & freertos 双系统上,是跑音频解码算法的,
而且也没有吧整个音频的业务交到dsp上去处理吧
答:嗯,这个是没有,框架设计没有吧DSP的优势凸显出来,而且双核通信业务这块,没有标准做法,我们的做法效率不是很高
是啊,就异构之间的通信效率提升你们有什么好的方法和途径不?这个未来应该是要研究的,xPU不是你们的专题吗
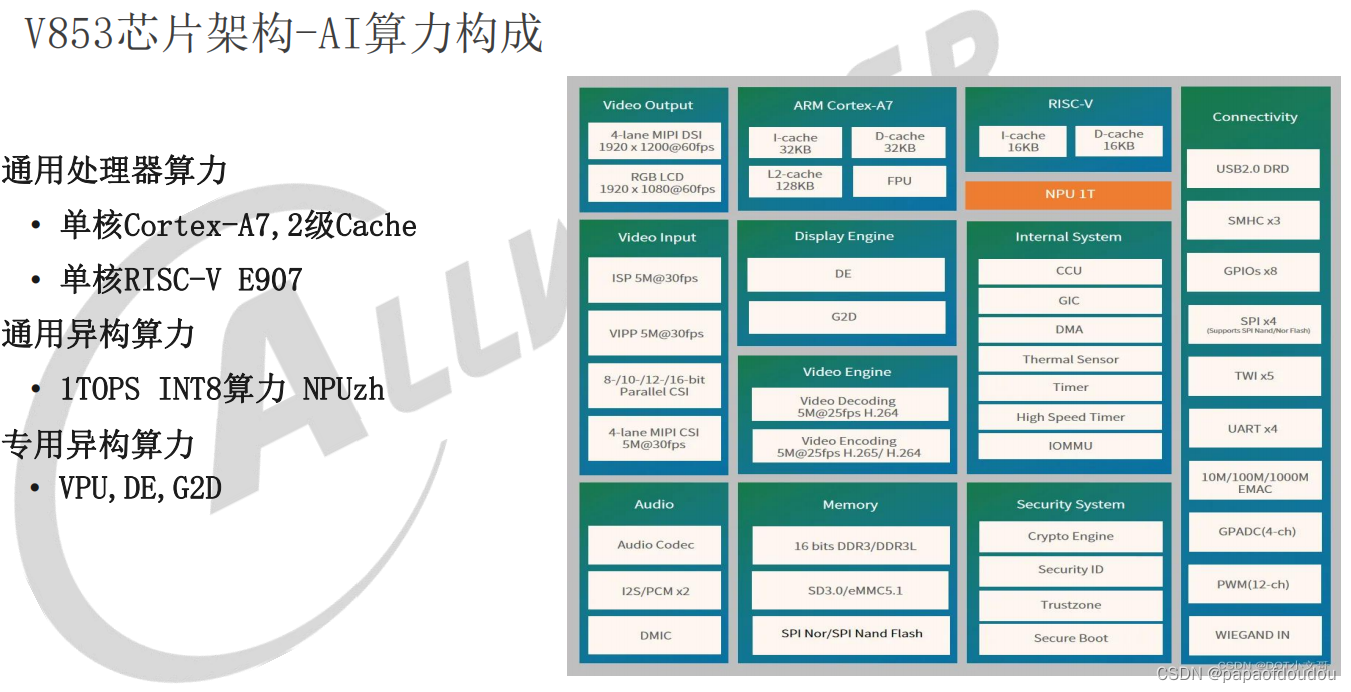
嗯,是有团队在负责专题,后面异构算力是趋势,绕不开,V853也是异构算例
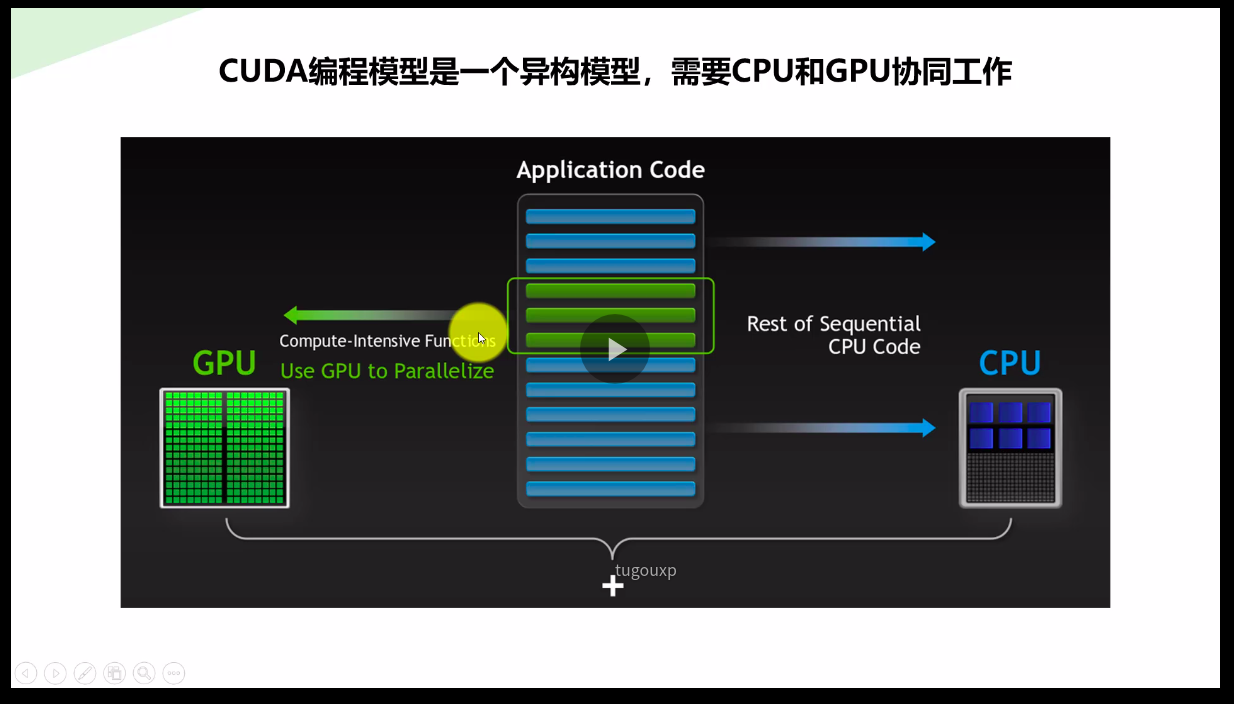
42:关于GPU的工作原理:
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。
但有一点需要强调,虽然GPU是为了图像处理而生的,但是我们通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
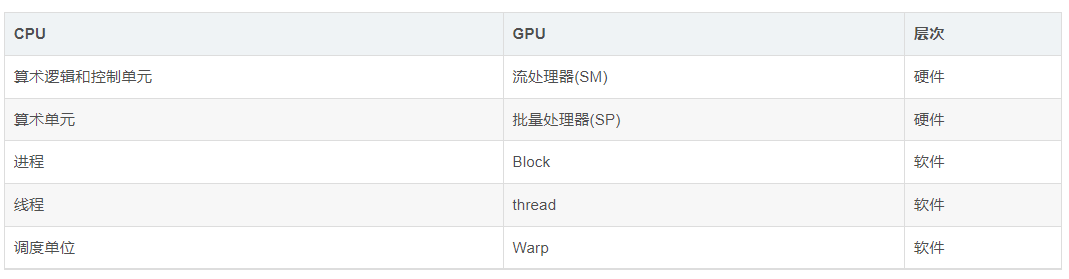
43:CPU和GPU的类比
44:inception的核心就是把google net的某一些大的卷积层换成1*1, 3*3, 5*5的小卷积,这样能够大大的减小权值参数数量。直接上一张完整的图片,比方说这一层本来是一个28*28大小的卷积核,一共输出224层,换成inception以后就是64层1*1, 128层3*3, 32层5*5。这样算到最后依然是224层,但是参数个数明显减少了,从28*28*224 = 9834496 变成了1*1*64+3*3*128+5*5*32 = 2089,减小了几个数量级。
再上一张形象的图:

为什么不直接使用1*1的,而还需要3*3和5*5的呢,其实这样还是为了适应更多的尺度,保证输入图像即使被缩放也还是可以正常工作,毕竟相当于有个金字塔去检测了嘛。
这样输入图片的分辨率大小发生变化,也不影响识别效果,对精确度的影响降到最低。
45:在半导体行业,只要批量足够大,芯片的价格都将趋向于沙子的价格。据传闻,正是由于该公司不肯给「沙子的价格」 ,才选择了另一家公司。当然现在数据中心领域用两家公司 FPGA 的都有。只要规模足够大,对 FPGA 价格过高的担心将是不必要的。
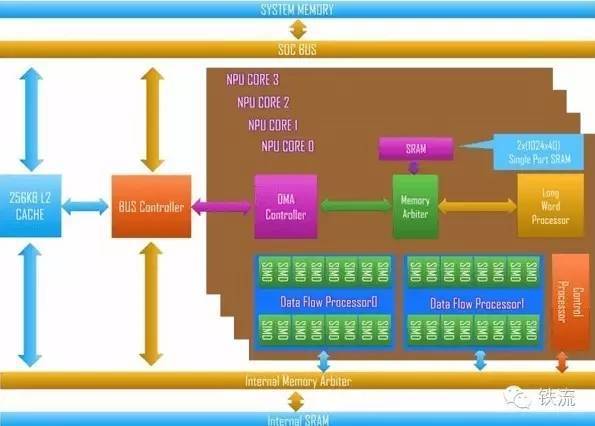
46:寒武纪架构
float32到uint8量化后,SIZE会变成原来的1/4,因为float32是4个字节,而UINT8一个字节。
47:量化选项一般支持: float / uint8 / int8 / int16 ,really?
48:技术上,前处理应该就是读图片,解码,tensor转置,然后缩放,最后归一化,后处理就是纯数学计算了,没啥道理.
49:微处理器内部的能耗和功率
对CMOS芯片,一次(0->1或1->0)的能耗:
动态能耗 = 1/2 * 容性负载 * 电压²
每个晶体管的功率:动态功率 = 1/2 * 容性负载 * 电压² * 开关频率
目前处理器已经达到了风冷散热极限。
根据上述公式,如果不能降低电压或者提高每个芯片的功率,那就要减缓时钟频率的增长速度(从2003年起).
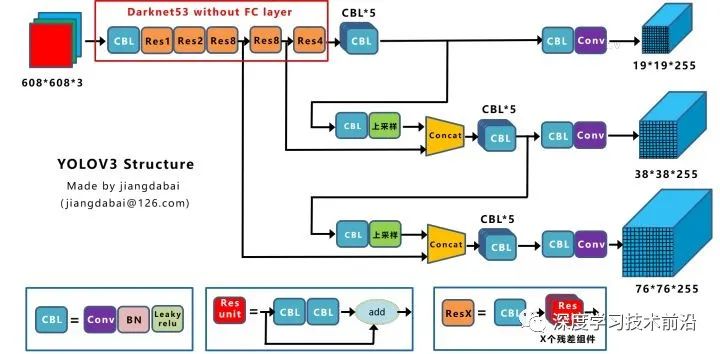
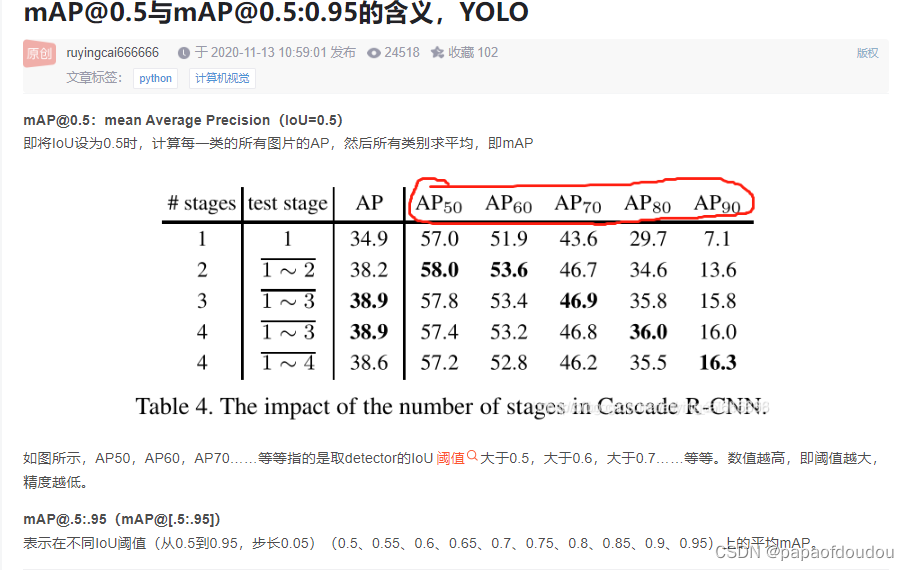
50:YOLOV3网络
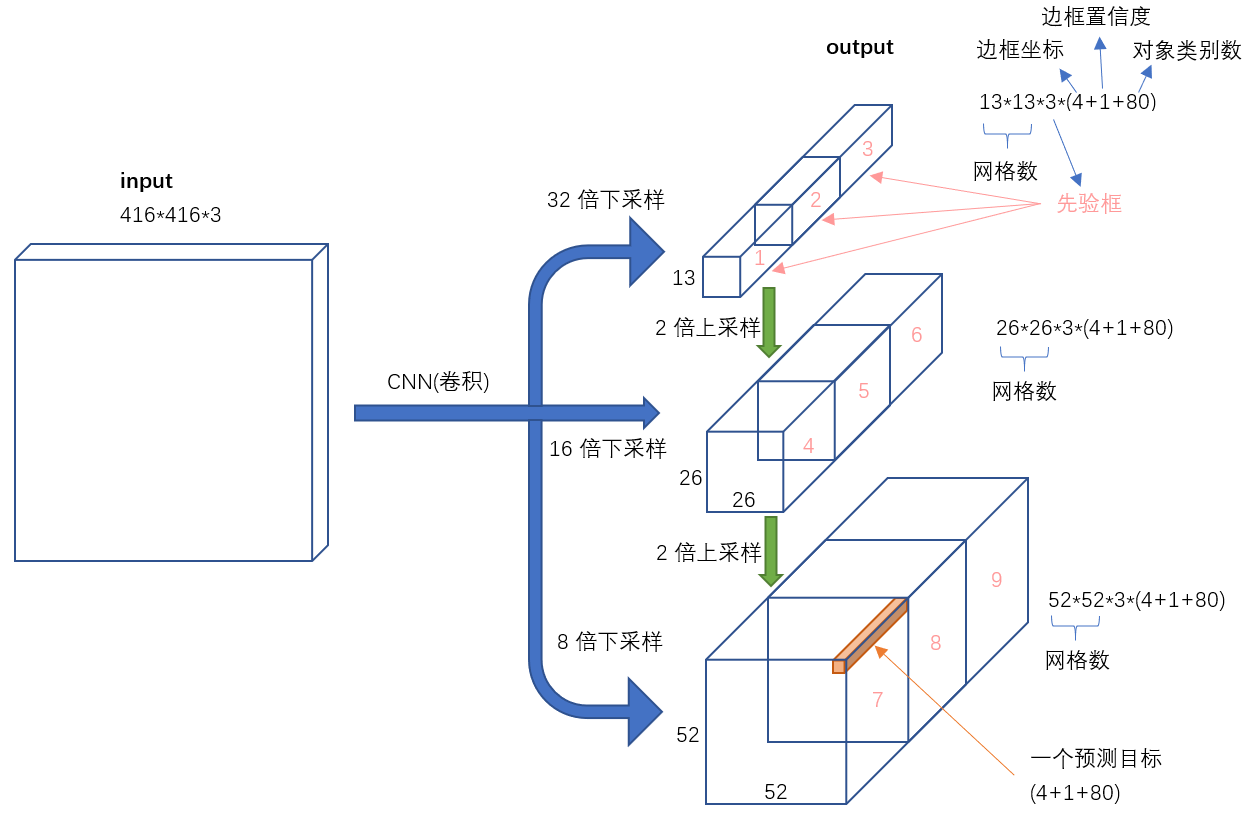

根据输出tensor的大小,分别是
13*13*255 = 13 * 13 * (3 * 85) = 13 * 13 * 3 * (1 + 4 + 80)
26*26*255 = 26 * 26 * (3 * 85) = 26 * 26 * 3 * (1 + 4 + 80)
52*52*255 = 52 * 52 * (3 * 85) = 52 * 52 * 3 * (1 + 4 + 80)

以416*416的输入图像尺寸为例,在13×13, 26×26, 52×52三種feature maps上進行預測(stride分別為32, 16, 8),每格搭配3個Anchor Boxes來預測Bounding Boxes。
YOLOV3在同一张图上的最大框个数是有上限的,还是以416*416图片为例,最多能在一张图像上画(13×13+26×26+52×52)x3 = 10647个框,也就是最多一张图片上检测处10647个物体。
YOLOV3没有全连接层
51:VIP的工具转换逻辑

52:三大特征提取器 - RNN、CNN和Transformer
三大特征提取器(RNN/CNN/Transformer) - 西多士NLP - 博客园
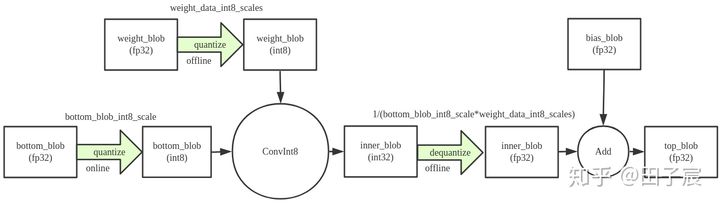
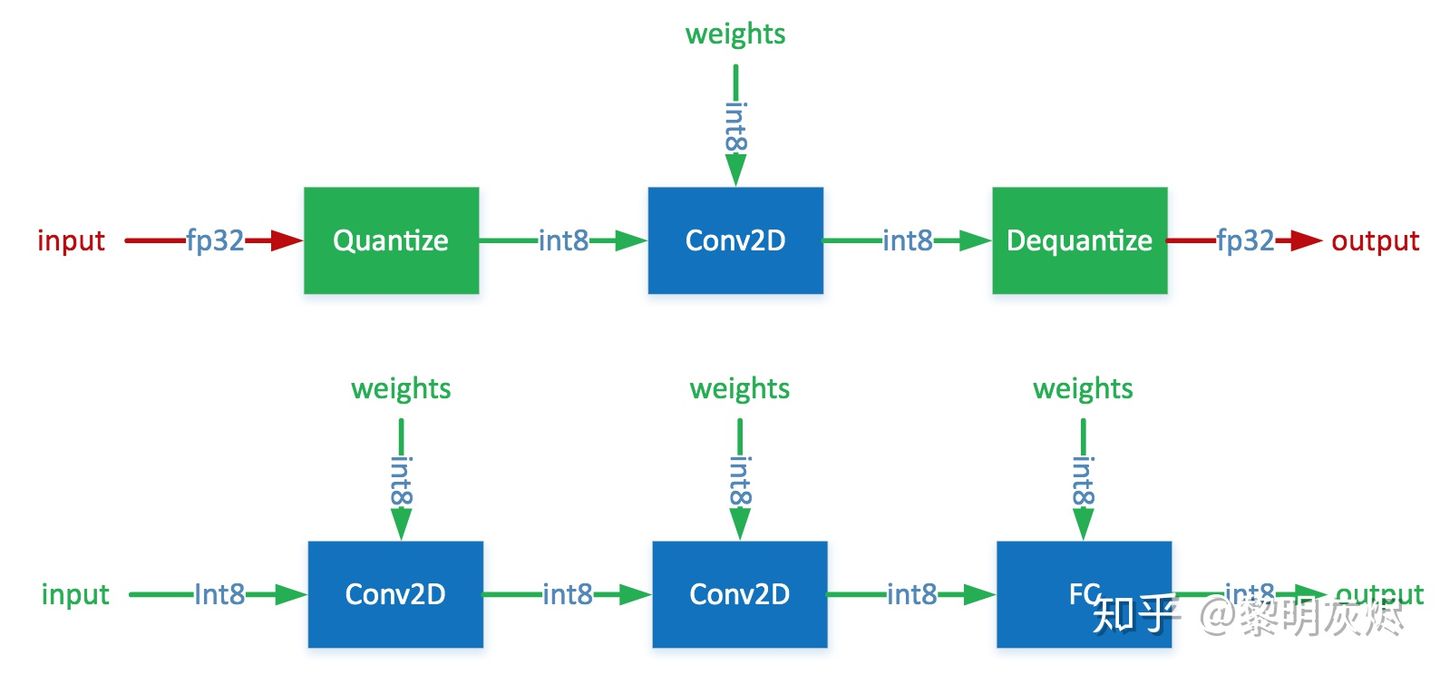
53:Quantization is primarily a technique to speed up inference and only the forward pass is supported for quantized operators.
量化一般用在推理中,用来加速推理过程,所以量化算子一般只用在前向路径中。
量化原理:
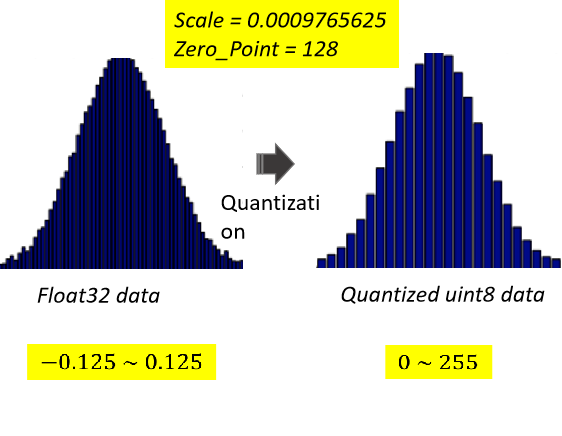
以量化后的255为例,反量化计算过程为:
(255-zeropoint)*scale = (255-128)*0.0009765625 = 0.1240234375
PPU算子实现:
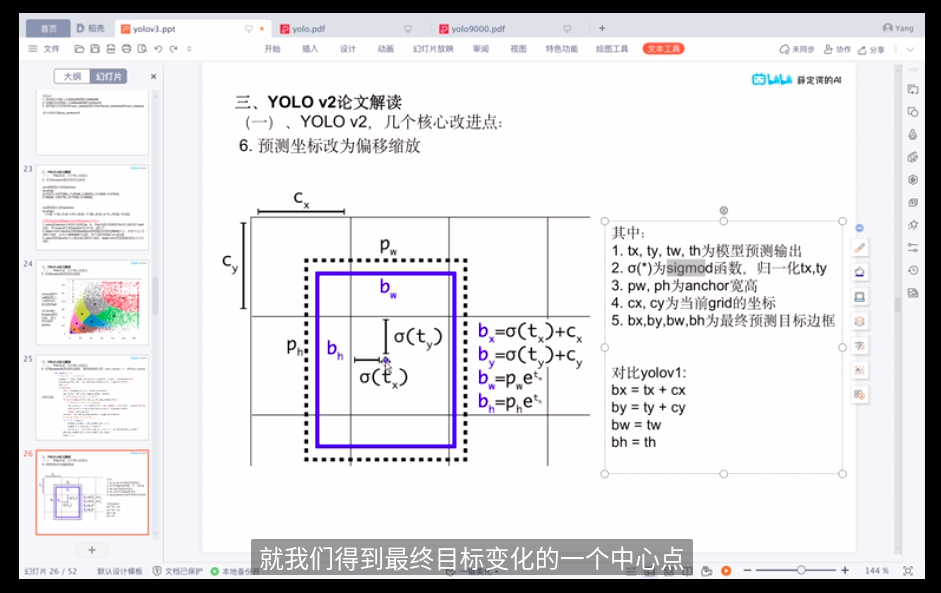
YOLOV2的结构

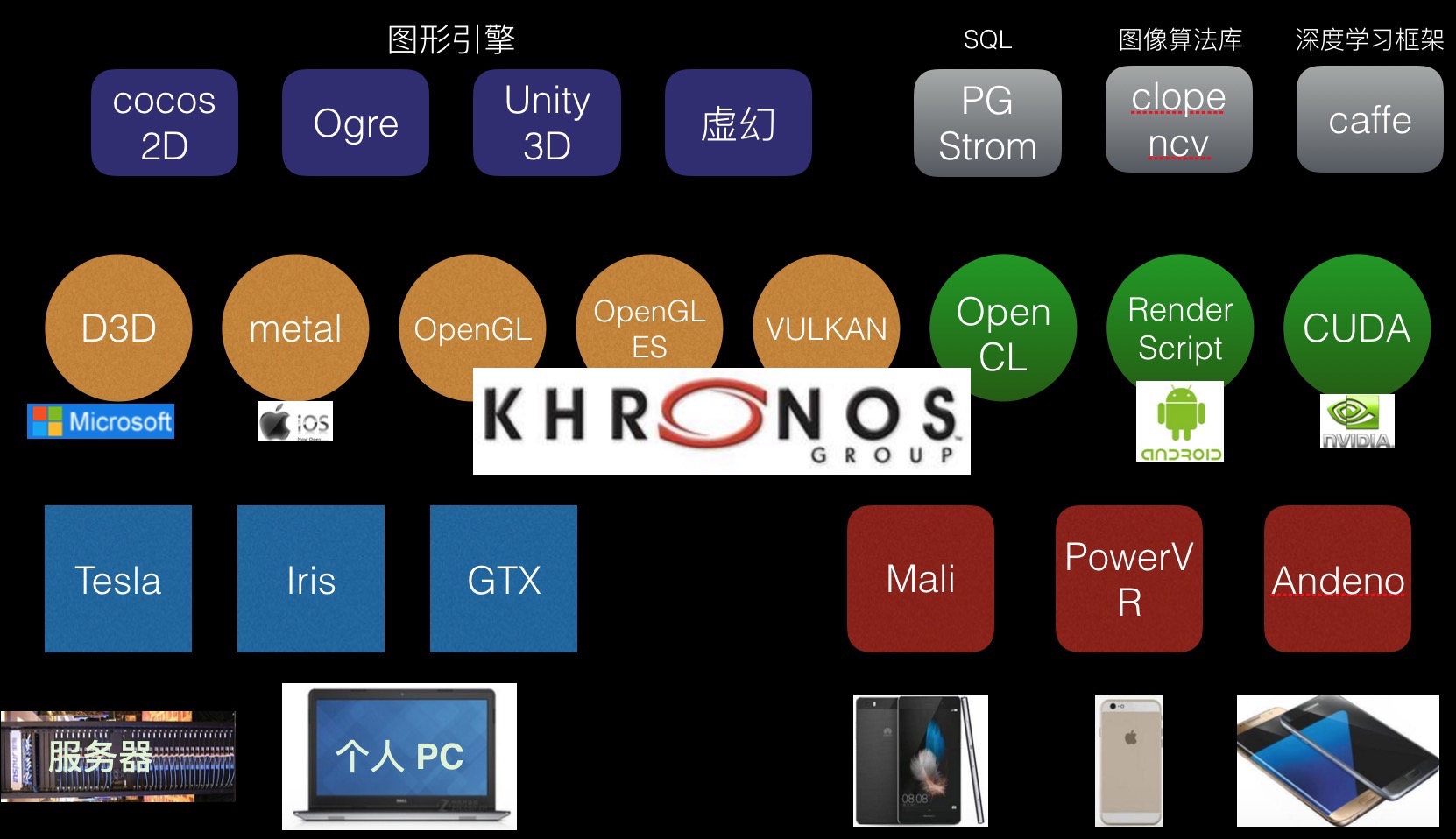
GPU的应用架构:
NPU:
消费类电子内的NPU一般都不带float型处理,而是支持uint8,int8,int16等整形,一方面缩小面积减小成本,另一方面减小存储,增加计算速度,但是量化毕竟有损失,一般量化前后的接近程度叫做相似度,相似度越高越好,理想情况下是1.
道听途说一个案例: 某工程师调试一个巨形网络,发现直到330层前面的forward,相似度都很好,但是就在第330层,模型出现了重大的相似度损失,这个时候怎么办? 他的办法是在330层执行反量化,由于后续NPU不支持浮点运算,所以后续推理不能再NPU上了,而是将330层后的forward放到了CPU上进行,完成模型的推理步骤。
边缘计算,边缘的特点
1 core per device: Rich EndPoint
4-IOT Core per Box,: IOT gateway.
10-IOT Cores per server: Edge Servers.
100-1000+ servers: Instruction edge.
geli NPU
geli AI芯片能处理视频么?做MCU,处理器处理能力和视频MCU也不搭。
做基本的,就是camera过来的数据然后送给AI核,处理慢的话中间帧就丢掉,做实时性要求不高的而还可以,后来也搞了一套类似于gstreamer的东西来做,MCU很呐难搞,带宽,算力不均衡。算力,带宽要相当。自己参考GST思路,写了一套GST框架,做视频处理。
如何教不懂高数的人理解梯度:
梯度就像斑马线,同一条斑马线上的点到对面路的距离都相同,这个时候你怎么过斑马线呢?肯定是垂直的方向,因为如果你斜着走,速度有一个分量会在平行的斑马线上,对你过斑马线没帮助。
杨立昆的一些观点:
自动驾驶本质上是一个 AI 完备问题,不能单靠计算机技术来解决,而是必须有人类介入。
“AI 需要人类的常识(common sense)才能解决这类问题,” 杨立昆表示,“知道了这一点,才能明白为什么无人驾驶不会普及得那么快。”
他还表示:“我认为如果你想在 AI 领域创造价值,计算机知识固然重要,但量子力学、运筹学和信息学的知识更加重要,尤其是它们背后的数学。”
杨立昆:自我监督学习模型是目前最有前景的 AI
对于大多数人而言,最好奇的问题可能是人工智能的未来是什么样子?何时才能实现?
杨立昆告诉 DeepTech:“我们希望 AI 具备接近人类的智能,那么它就需要具备常识,才能让所有期待成为可能。”
所谓常识,就是人类在与物理世界交互的过程中自然而然形成的观念和认知。比如两个月左右的婴儿就已经知道物体之间可以相互遮挡,被挡住的物体仍然存在,而非凭空消失;九个月大的婴儿,就已经知晓了重力和惯性等物理概念的存在。
如果有违背普遍规律的事情出现,不会说话的婴儿会睁大眼睛,做出一副不可思议的表情。
人类大脑的这种学习能力,是杨立昆等 AI 科学家想要复刻的。但目前在机器学习领域,无论是监督学习还是强化学习,都存在一定局限性,这给人工智能的进步设置了无形的天花板,结果就是人工智能对世界只有一个肤浅的理解,而不具备常识。
杨立昆认为,目前最有前景的实现方法是一种被称为 “自我监督学习(Self-supervised Learning)” 的模型。这是他近几年大力支持且深度参与的研究方向,多次将其称为 “智能世界的暗物质”。
CNN中基本概念:
关于NCNN量化:

RK AI应用


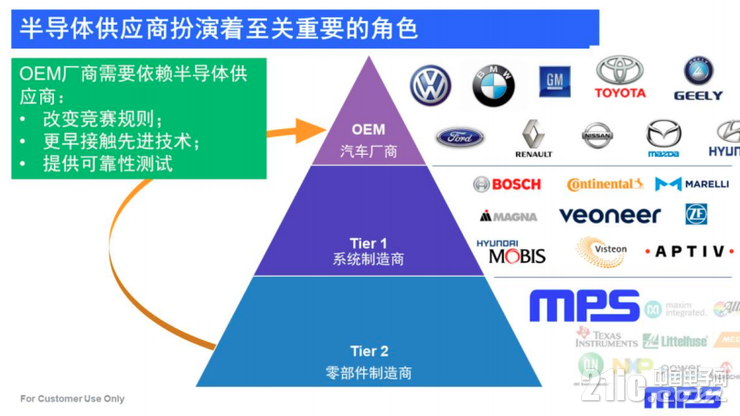
供应商与车厂之间的关系
移动端优化的难点

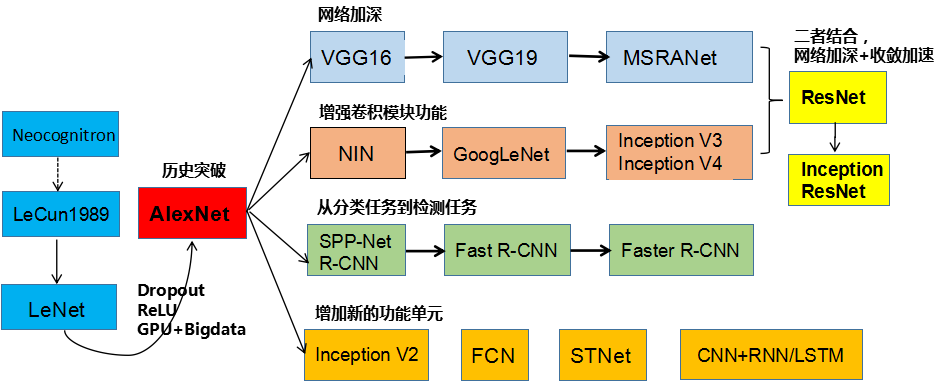
各类网络模型的发展线和渊源

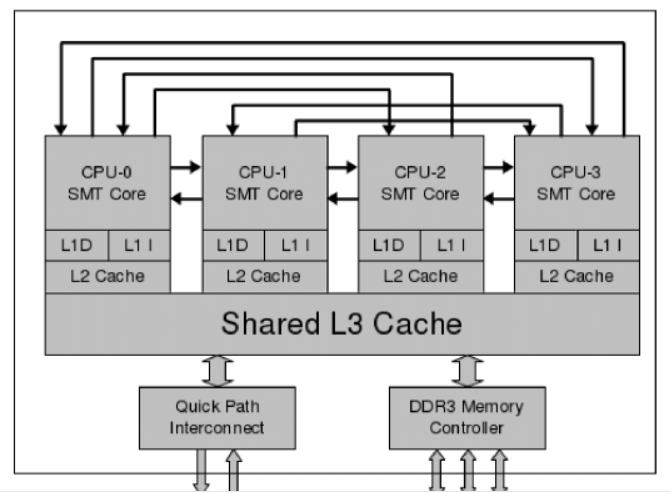
计算机体系结构,SMT:
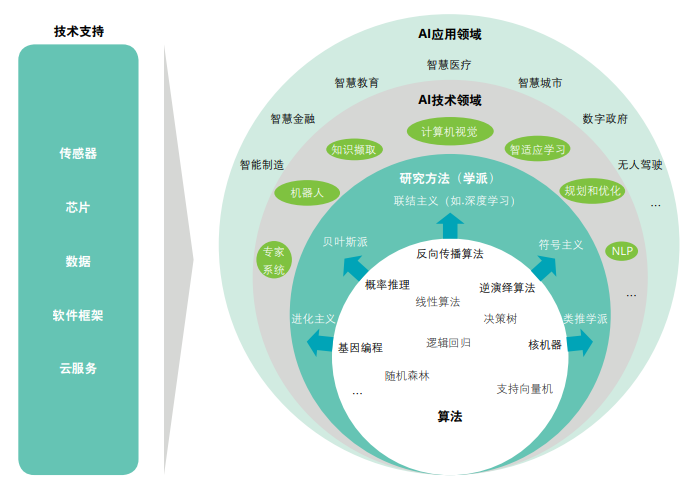
AI应用生态:
关于量化误差的问题:


可以看到,模型量化前后,总体精度变差,但是个别目标可能会出现精度变高的情况,所以,这种差别是概率性的,量化后,精度的统计概率会降低,但是个别目标精度可能会出现变高的情况
和中星微的洋工交流:
惊讶于它们的NPU能够同时检测到900张人头并框选,召回率和精确率达到%100.

咨询了洋工,它们的NPU跑网络也是出定点tensor,后处理也是在CPU完成,具体步骤是NPU出定点数据,CPU处理浮点运算,NMS算法去掉冗余框后计算出坐标,所以上层画框,也需要很长的时间,毕竟900个框要画出来。
这一点,流程我们是类似的。关于星光一号的报道,网上找到一篇技术分析值得学习
"中星微“星光智能一号”的主要应用是安防监控市场。报道中提到,“视频监控领域对智能识别有着强烈需求…此前的技术主要存在两方面局限,一是识别准确度不高;二是传统技术需要先把海量视频数据传到后台,再在后台进行识别,无法实时得到结果。而使用了深度学习的机器视觉,对人脸识别的准确率可达98%;在嵌入人工智能后,可以当场识别。”另外还举了周克华案的例子,“在几年前轰动全国的周克华案件中,案犯在南京被拍到,公安干警将视频信息拷贝分发给数千人的团队,对着每个摄像头进行比对,但周克华仍逃到重庆,直到再次作案后才被抓获。如果当时有‘星光智能一号’技术,罪犯走到哪里都会被智能识别,很快就会有线索传回来。”报道给人的感觉是,有了NPU就可以在摄像头内当场识别嫌疑人,当发现嫌疑人的时候立刻报警。
遗憾的是,目前的人工智能技术可以识别嫌疑人,但在嵌入式平台中基本不可能当场识别嫌疑人。我们先不谈人工智能,先谈谈“人工”。如果给我们的人民警察一张照片,让他辨别照片上面是不是有人,他一定能很快地辨别出来。然而,如果给他一张照片问他照片上是不是出现了目前正在通缉的犯人,那么他还需要把照片和通缉犯数据库里的所有照片都比对一遍才能下结论。人工智能也是一样,第一种“分辨照片上是不是有人”的工作在人工智能领域有个专门的名字叫做物体识别(object detection),目前使用深度学习已经可以把物体识别做到很高的正确率。几年前,Google做了一个项目是在Youtube识别含有猫的视频,就是在做物体识别。物体识别可以在嵌入式系统中实现,因为需要识别的物体种类往往是有限的而且是不变的,所以只需要一张固定的神经网络就可以实现。另一方面,人物识别(识别出相片中的人是谁)就要复杂一些。当使用人工智能去检测有没有发现嫌疑人时,需要首先提取画面中人物的特征,然后把这些特征和数据库中的各个嫌疑人一一比对,最后才能确定画面中有没有发现嫌疑人。由于嫌疑人数据库会随时更新,所以安防设备即使配备了NPU也必须连接到嫌疑人数据库后才能识别,当场识别嫌疑人并立刻报警在现阶段连人工都很难做到,更何况用人工智能实现”
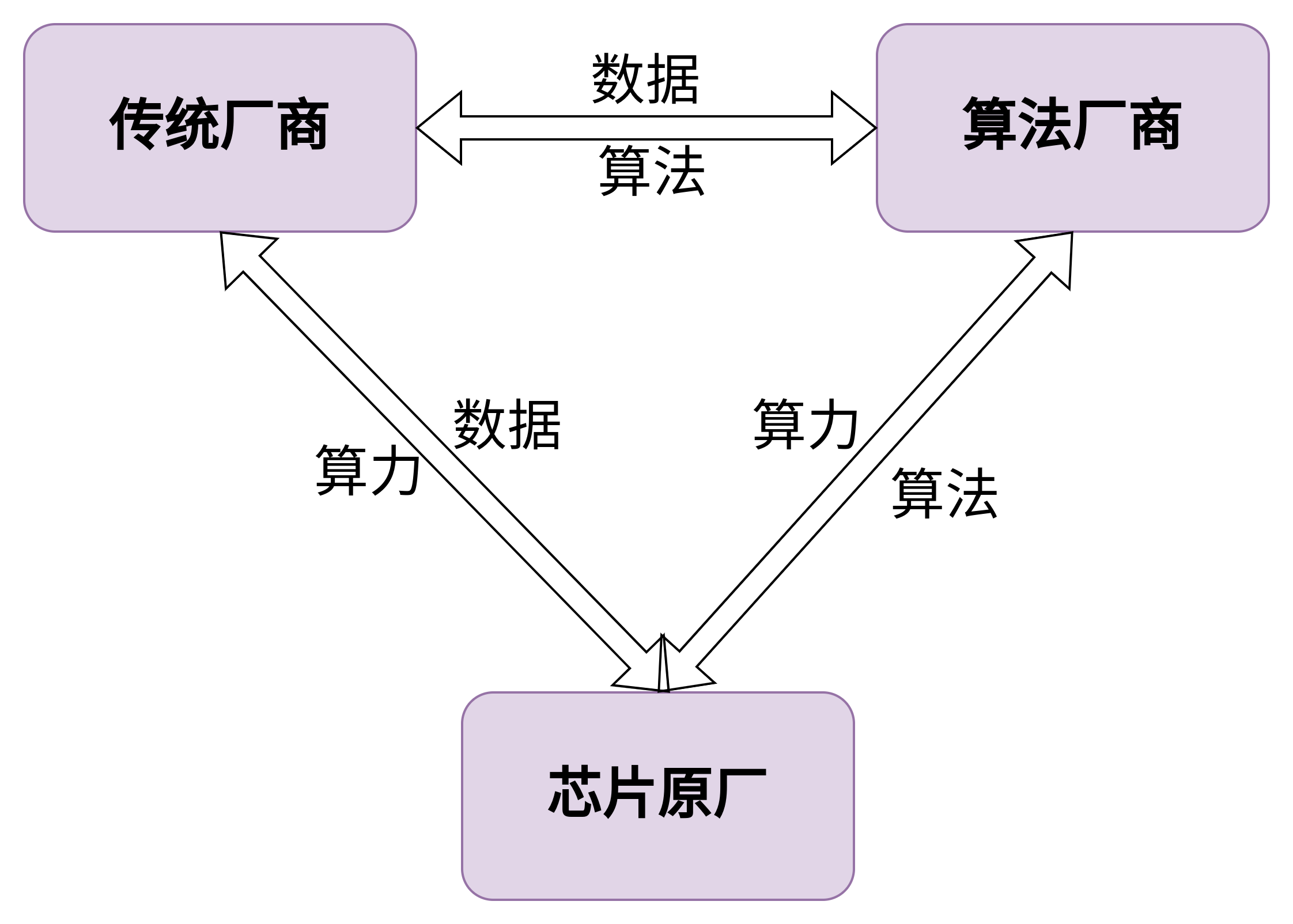
芯片原厂和AI算法公司的合作模式:
有两块业务有合作机会。
1.一个是算法公司做算法适配我们平台,可以理解为算法公司角色,芯片公司搭配成解决方案给没有算法能力的客户,另一个是他们有做人脸锁整体解决方案, 可以理解方案商角色,要对接各个厂商的主控自己做方案(QG也在基于QG2101系列在开案做);
2.证明我们芯片NPU性能还可以吧;
3.后续做和他们做算法对接,例如有客户有需要高空抛物算法,他适配过我们NPU平台,然后我就打通之前商务和技术问题并量产落地;

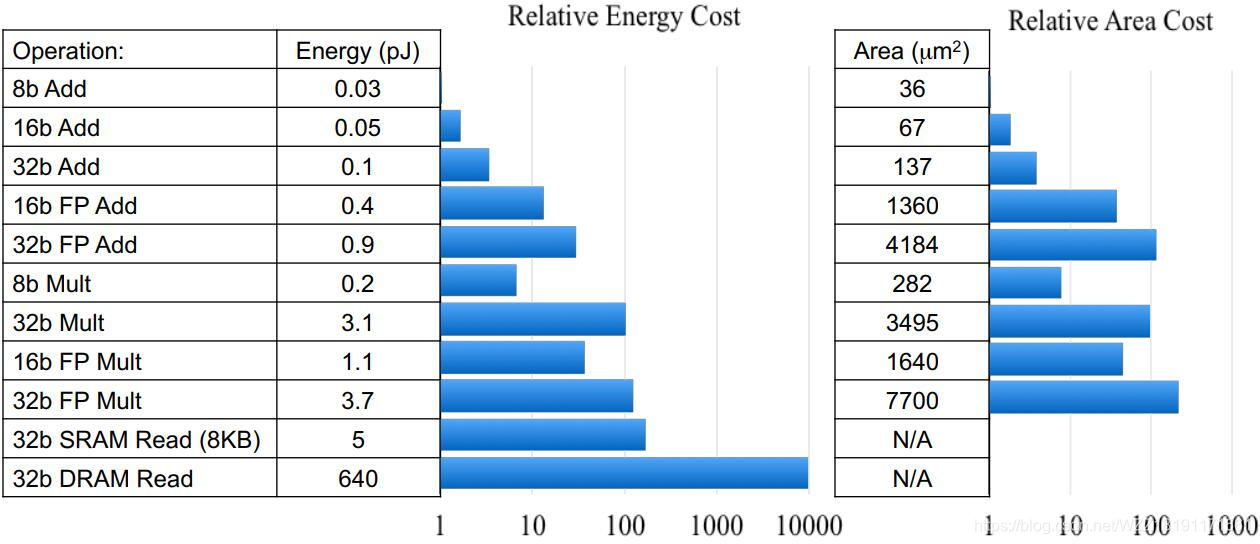
以下是不同类型的数据的运算的能耗和面积要求:
以32bit浮点加法和8bit顶点加法为例比较,可以看到,前者能耗是后者的30倍,而面积则是100多倍,可以得出,模型量化在CNN中的重要作用。
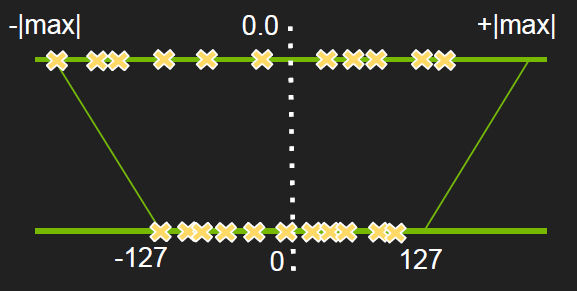
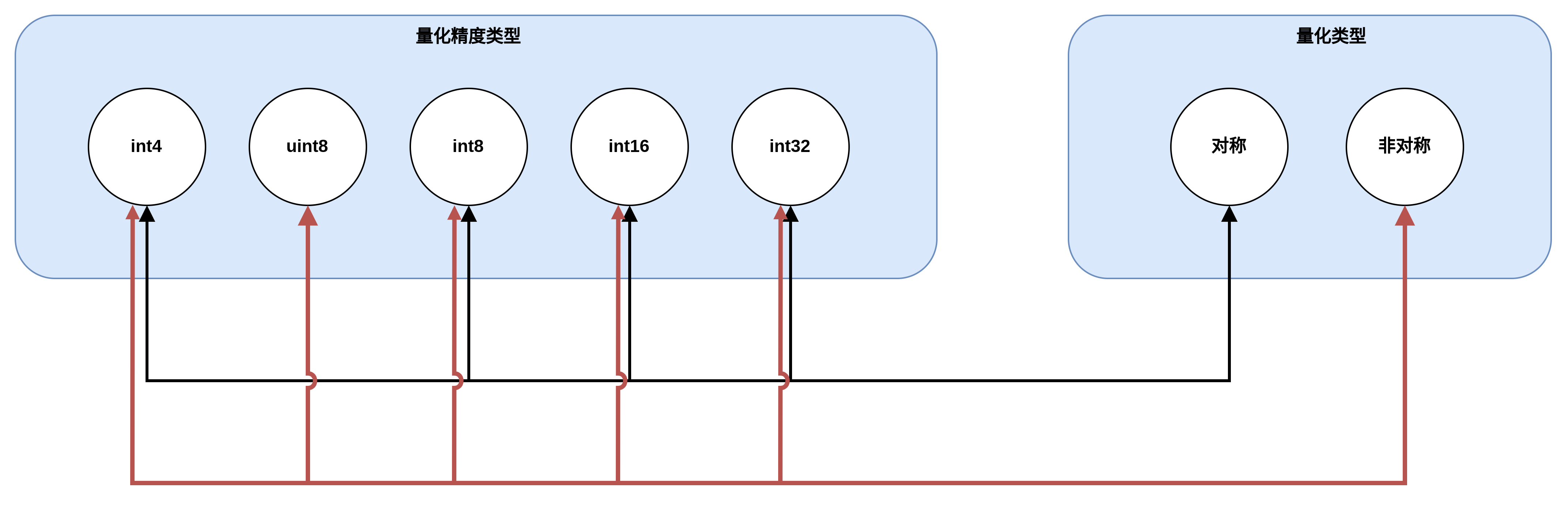
量化方式:
量化的精度和类型组合并不是任意的,对称量化只能和INT4,INT8,INT16,INT32等0为中心点的类型搭配,非对称量化智能和UINT8这种无符号的类型搭配。
混合量化是另外一个概念,准确的说,混合量化是指混合精度量化,是指在满足以上约束的前提下,不同精度类型的量化模式同时使用,比如对称INT16类型和非对称INT8类型,或者非对称INT16类型和对称INT8类型等等。
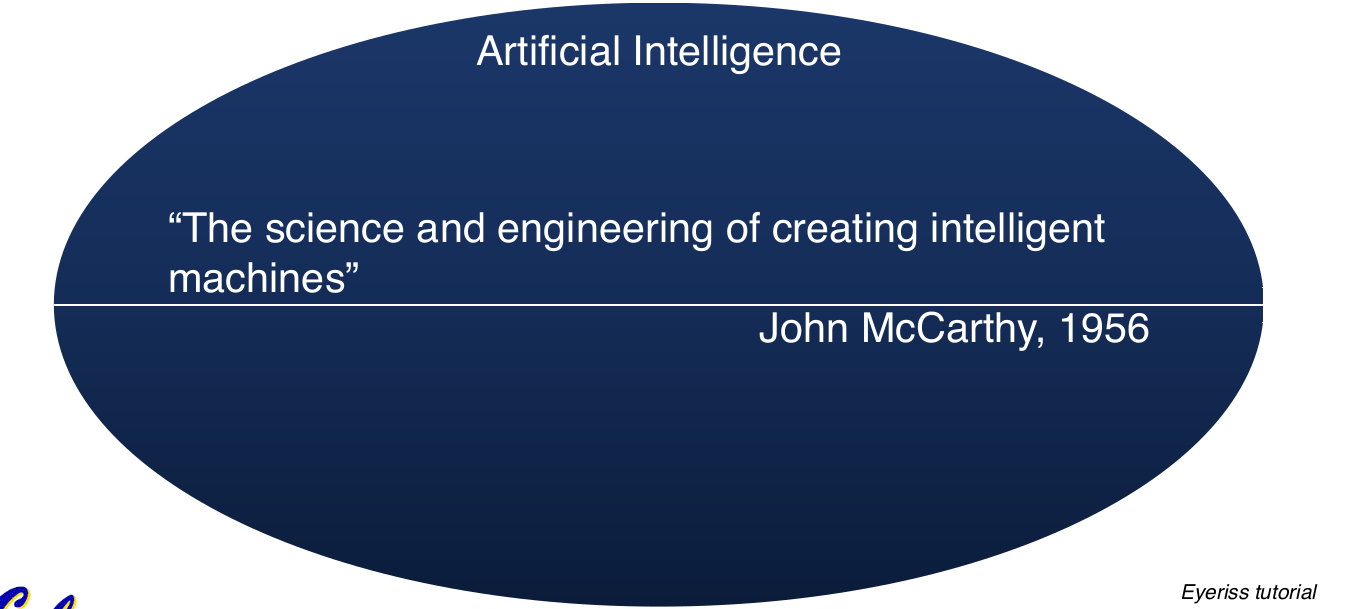
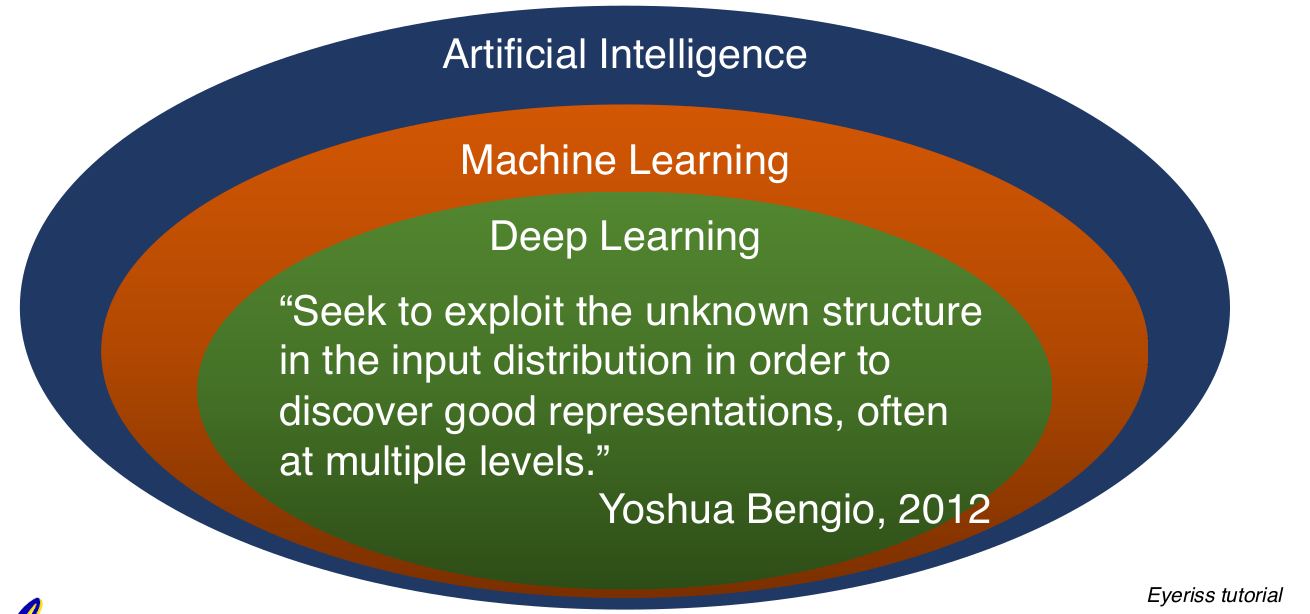
AI,ML,DL的发展路径:

TRAIN&INF
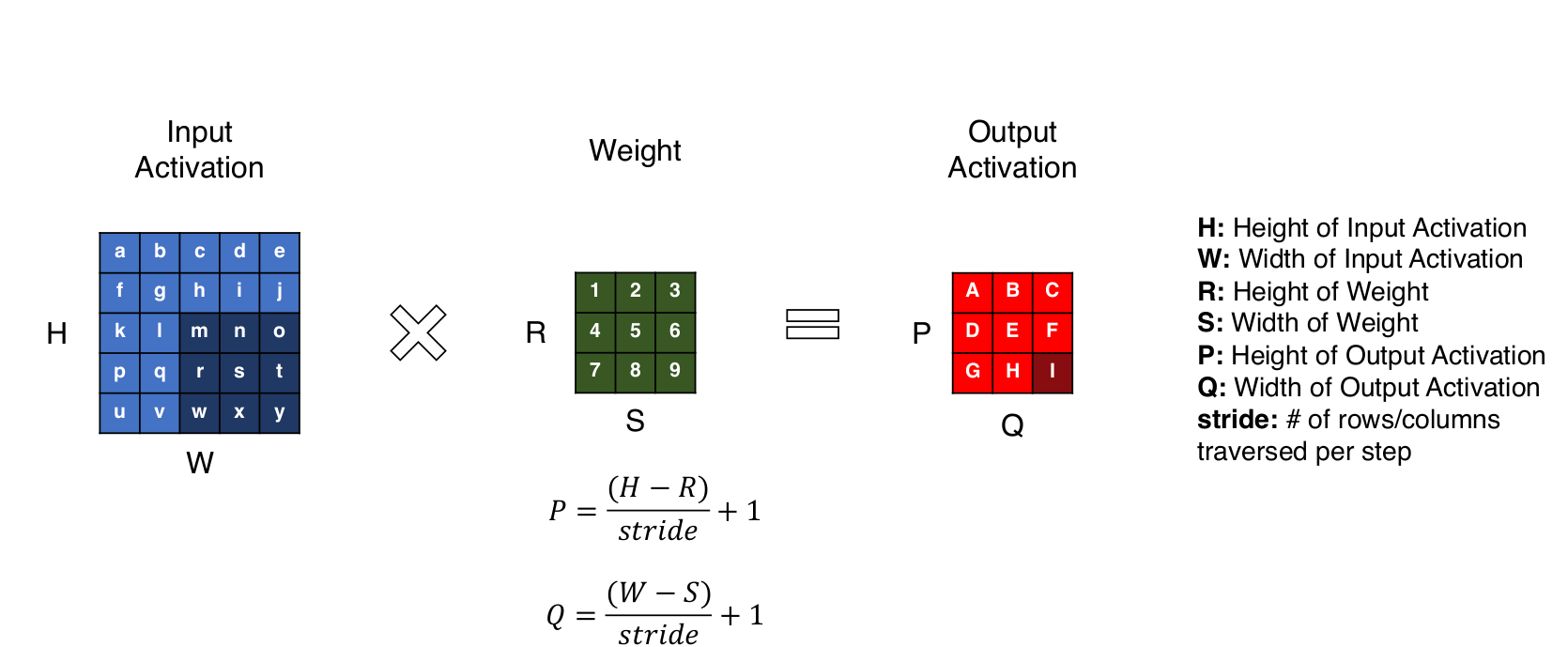
卷积尺寸:
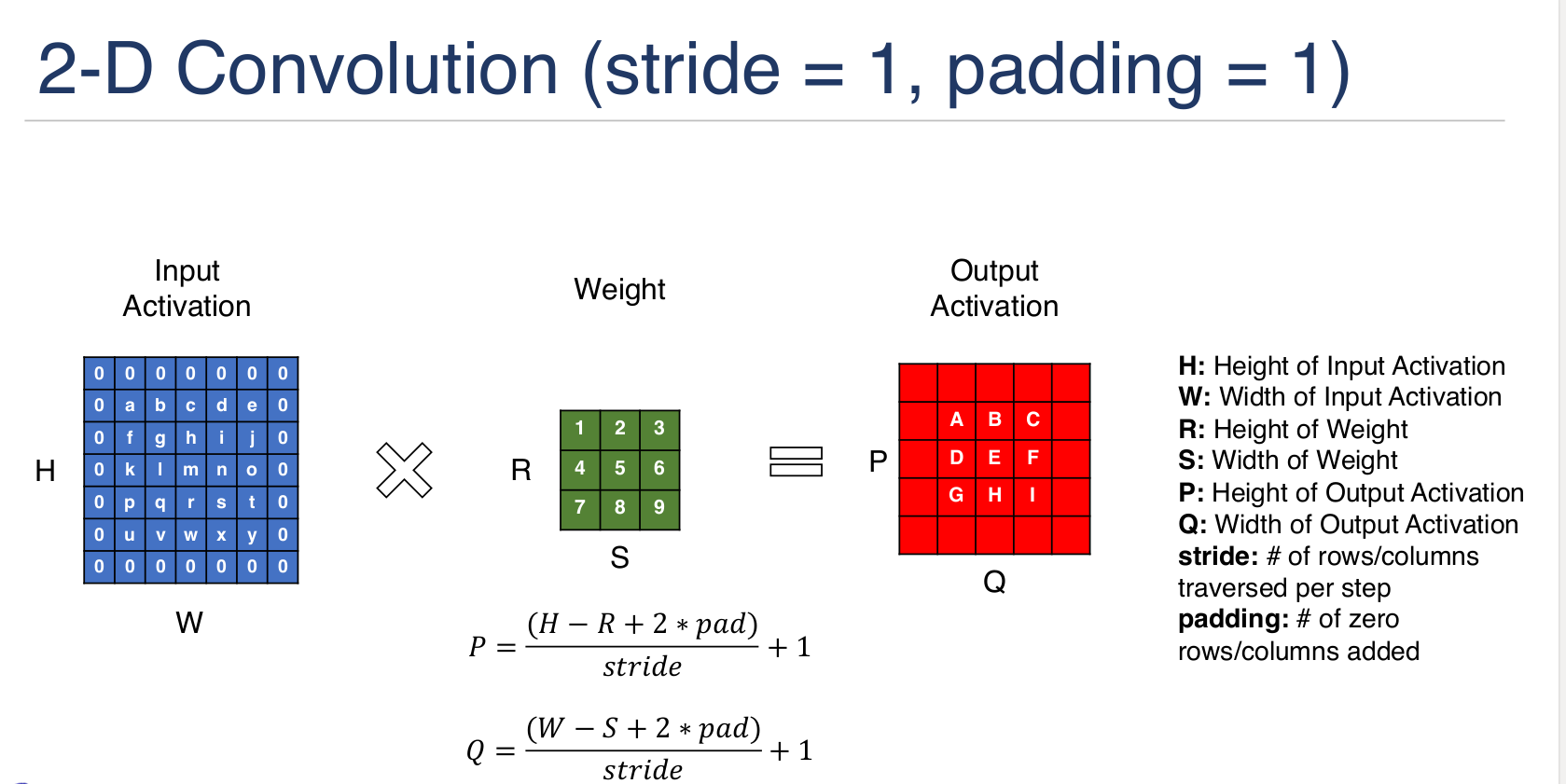
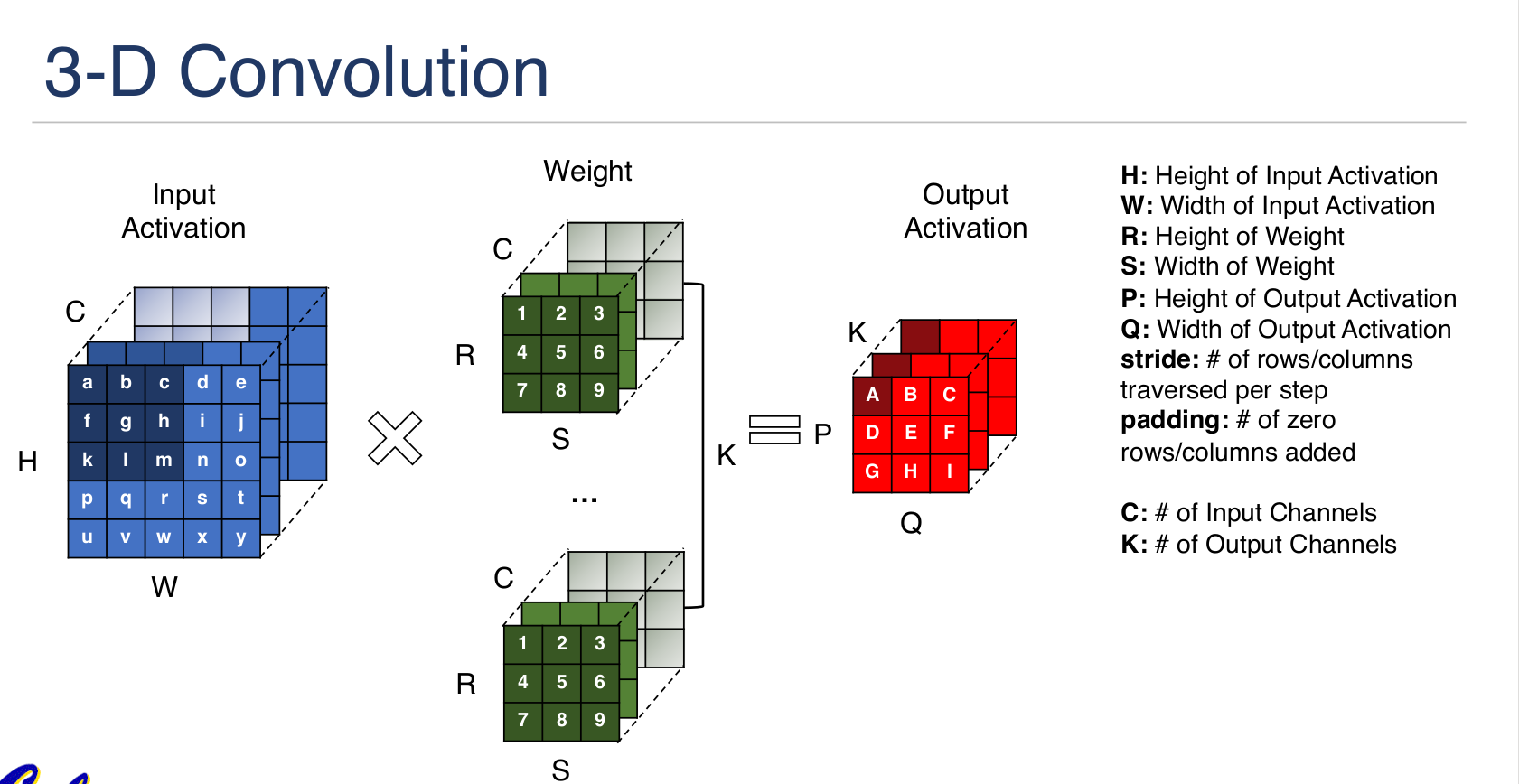
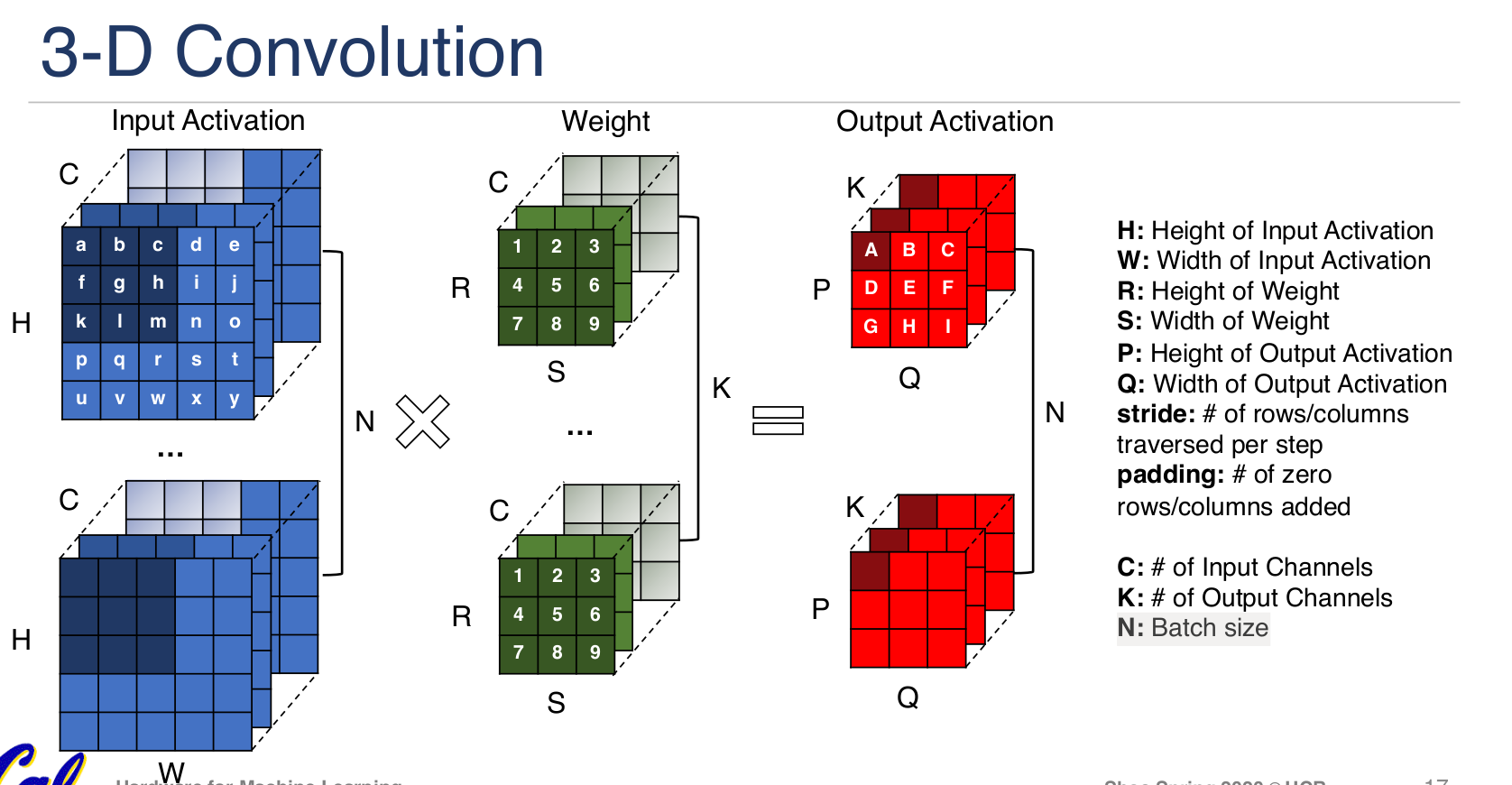

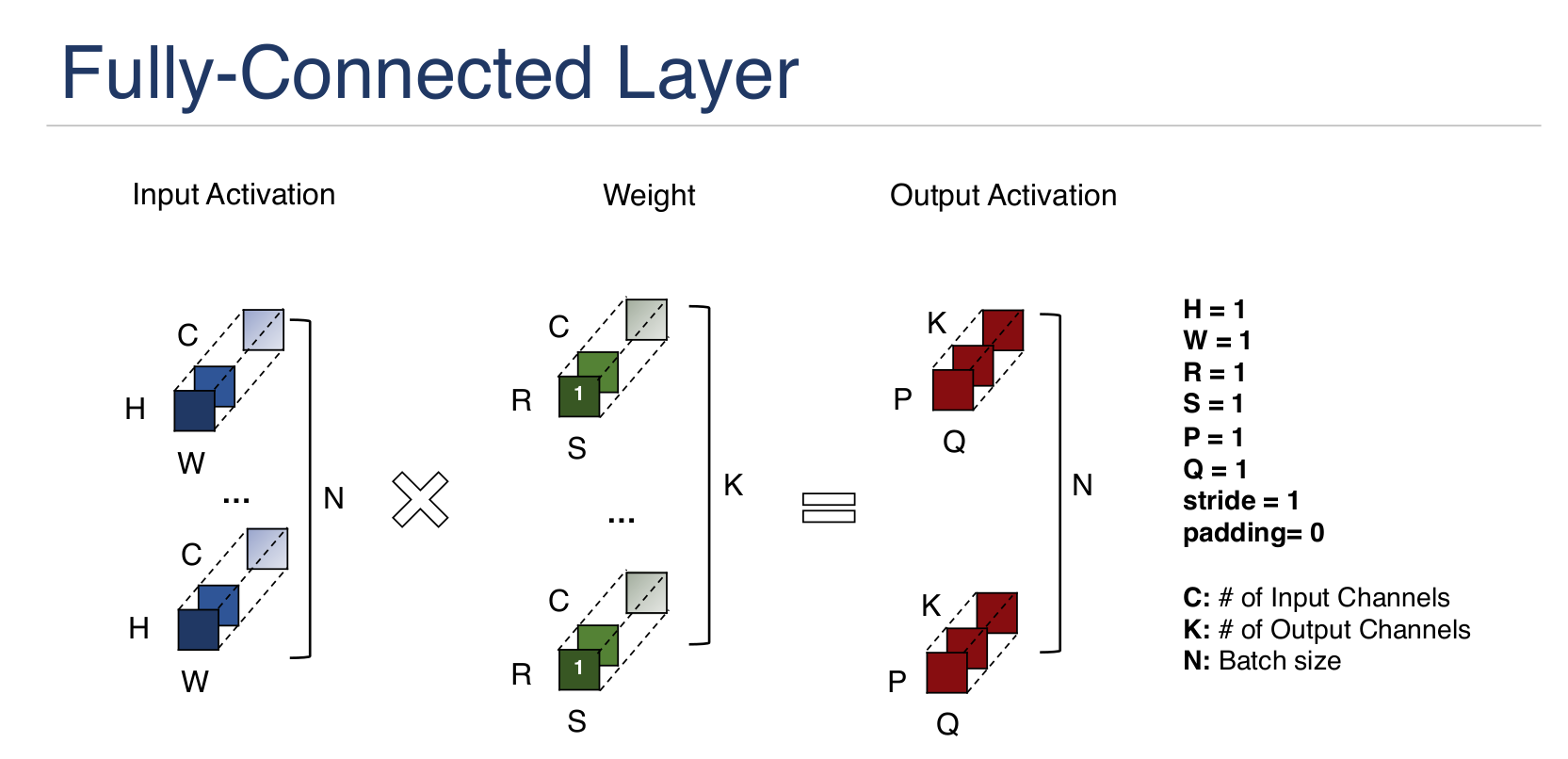
朱松纯的观点:
不知道朱松純屬於哪個學派,不过他一定不属于深度学习派,因为他字里行间透露着对DL的不屑与嘲讽,从下面这段话可以看出来。
深度学习是一门经验实践领先于理论的学科,很多现象无法用理论说明原因。

深度学习编译器
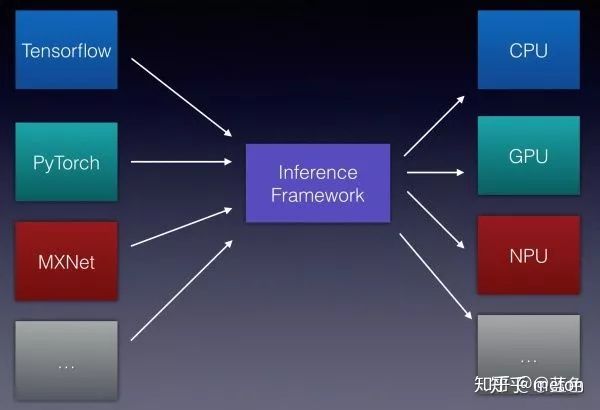
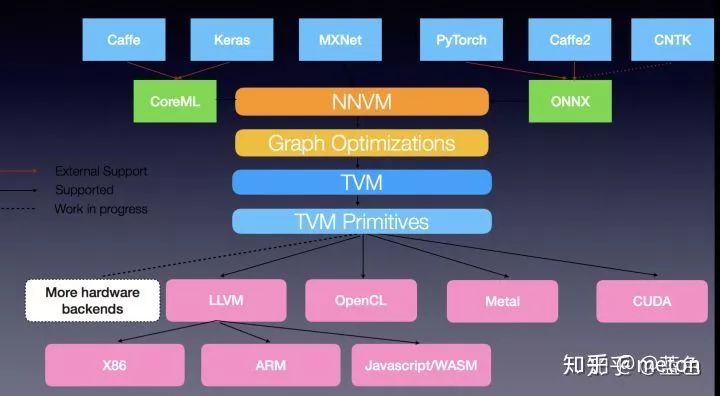
AI教育
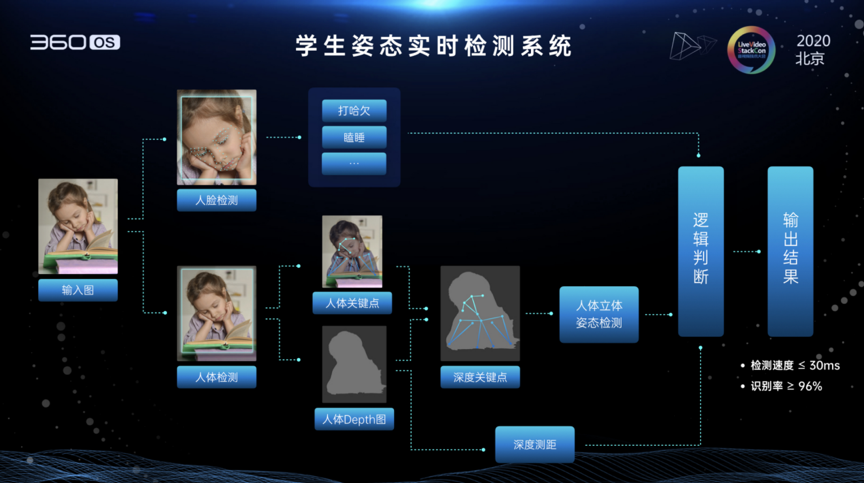

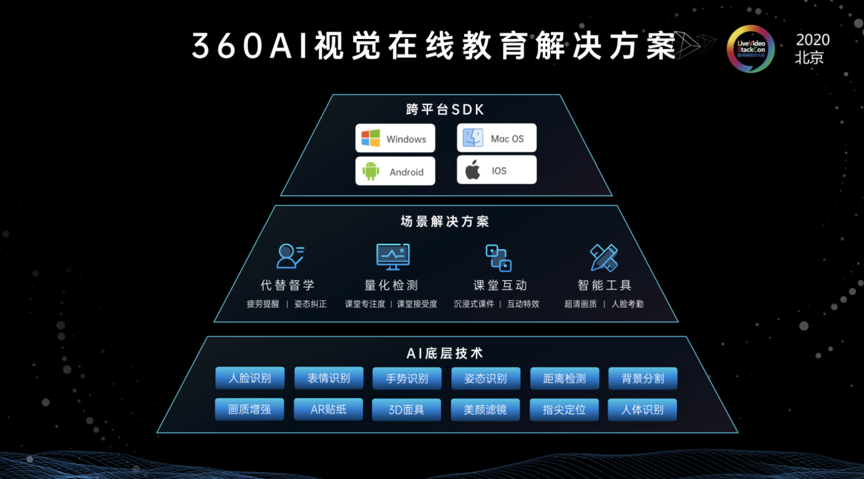
NCNN和TF的关系:
ncnn在手机上更快。实际上没有什么竞争关系,TensorFlow侧重训练,ncnn侧重部署。
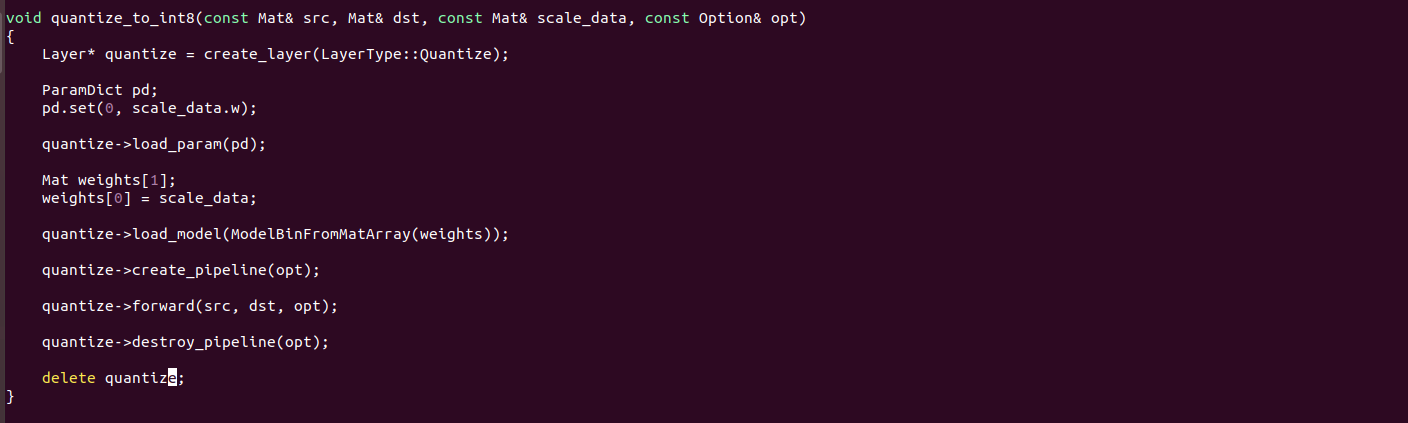
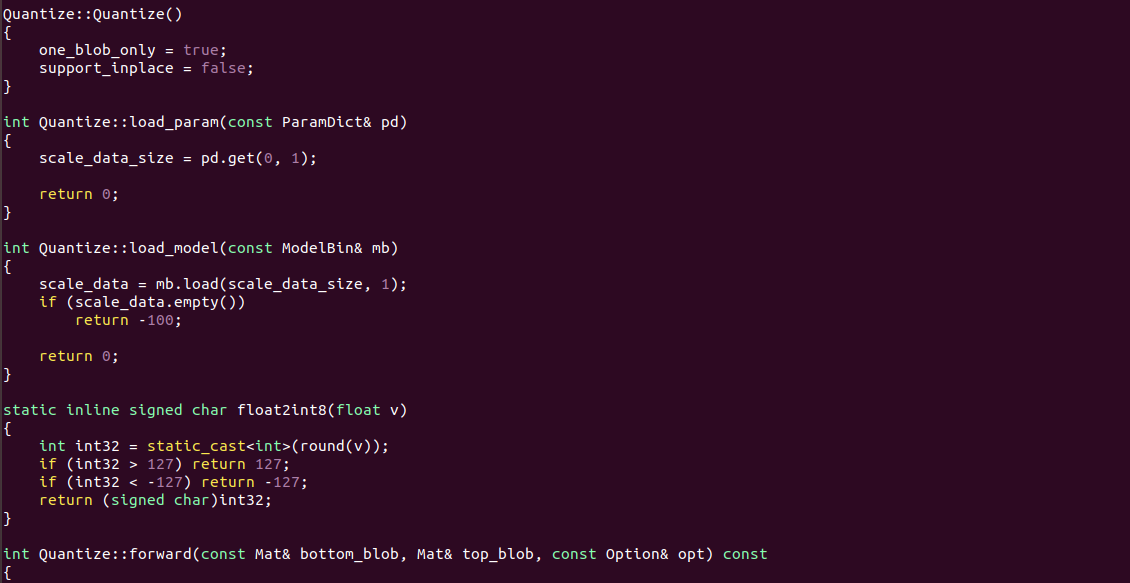
NCNN量化
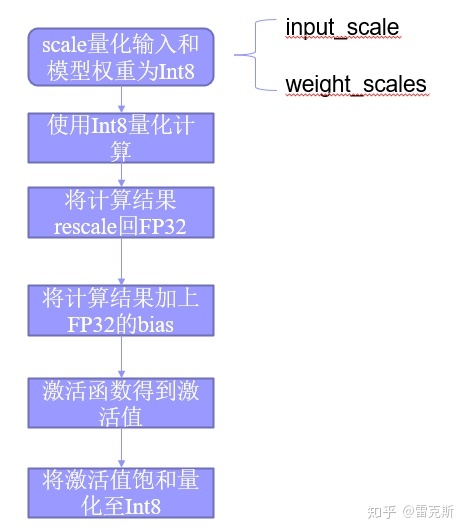
NCNN代码中,Layer层抽象基类将各种类型的CNN网络层纳入统一的模型进行管理,包括量化也抽象为Layer 层。

模型部署的逻辑:
IMX貌似有一款产品使用的是芯原的NPU
中文搜不到,线索来源于下面的日文报道:

T-FLOPS和T-OPS
衡量NPU算力是具体的,不是抽象的,比如FLOPS和OPS,相差一个FL,代表float,所以衡量的对象也存在差异,对于支持浮点处理的NPU,应该用FLOPS,而对于只支持量化类型的NPU,则需要注明INT8/UINT8/INT16等才比较严谨。具体可以看这篇文章对算例的表述:
 https://blog.youkuaiyun.com/cy413026/article/details/102931412?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.pc_relevant_default&utm_relevant_index=2
https://blog.youkuaiyun.com/cy413026/article/details/102931412?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.pc_relevant_default&utm_relevant_index=2
RK的NPU文档,用的也是TOPS的单位,所以量化类型的算力单位是TOPS。

NPU算力的计算
FOPS =MAC数*频率*2
SSD和YOLO的差异

RGB-BGR:
关于图像处理的网络,输入基本上不是RGB就是BGR,很少有例外,但这也不是死的,模型的输入也看模型设计人员的设计。基本常见的就都是GBR和RGB。其他的比如HSV,还有一些输入就是固定的某组数据。如果按照这个逻辑的化,对于输入节点是HSV的网络来说,就不能用VIP的前处理节点机制了。因为前处理的目标格式始终是RGB。
归一化:
YOLO的归一化很有意思,它的UINT8量化方式恰好是归一化的逆操作。所以量化后的值和RGB值完全一样,但是名义上是不同的数据。很多网络设置的时候,为了兼顾量化,前处理(归一化或者标准化)会直接除256。也有什么都不做就扔给网络的。因为RGB的时候也是UINT8,也不用量化了。所以啥都没有干。归一化也有很多种,[0 1] [-1 1] [-0.5 0.5] 等等。不做算法,不用理解这些,这些都有目的。就理解在训练的时候,数据通常不是直接喂给模型的,需要做一些前处理,导致在模型使用的时候也需要仿照训练的时候,做相同的处理。
训练神经网络中最基本的三个概念和区别:Epoch, Batch, Iteration
epoch:训练时,所有训练数据集都训练过一次。
batch_size:在训练集中选择一组样本用来更新权值。1个batch包含的样本的数目,通常设为2的n次幂,常用的包括64,128,256。 网络较小时选用256,较大时选用64,也是NCHW中的N。
iteration:训练时,1个batch训练图像通过网络训练一次(一次前向传播+一次后向传播),每迭代一次权重更新一次;测试时,1个batch测试图像通过网络一次(一次前向传播)。所谓iterations就是完成一次epoch所需的batch个数
三者之间的关系:iterations = epochs×(images / batch_size),所以1个epoch包含的iteration次数=样本数量/batch_size;
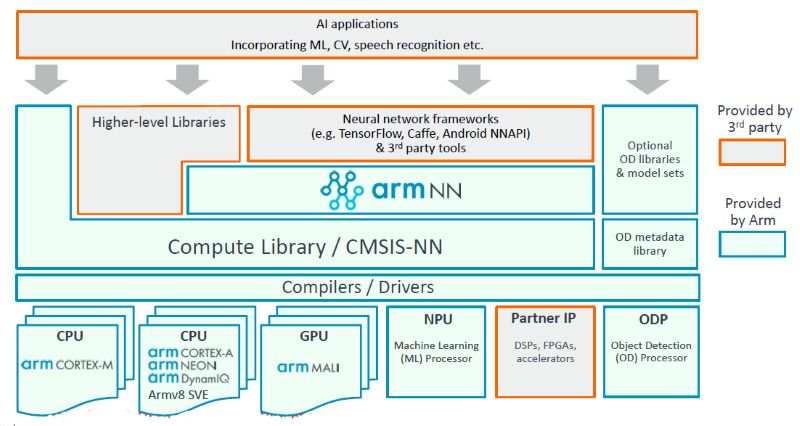
ARM NN生态:
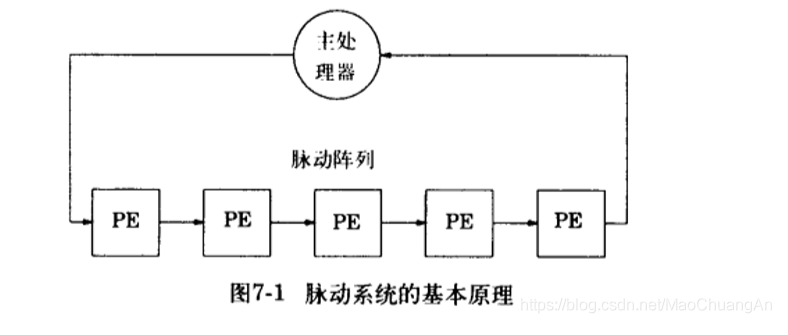
脉动阵列
脉动阵列是最早在1982年被提出的。它利用简单且规则的硬件结构,支持大规模并行,低功耗,高吞吐率的积分,卷积,数据排序,序列分析和矩阵乘法等运算。2016年,google公式的第一代张良处理器TPU中就基于脉动阵列结构加速卷积运算。

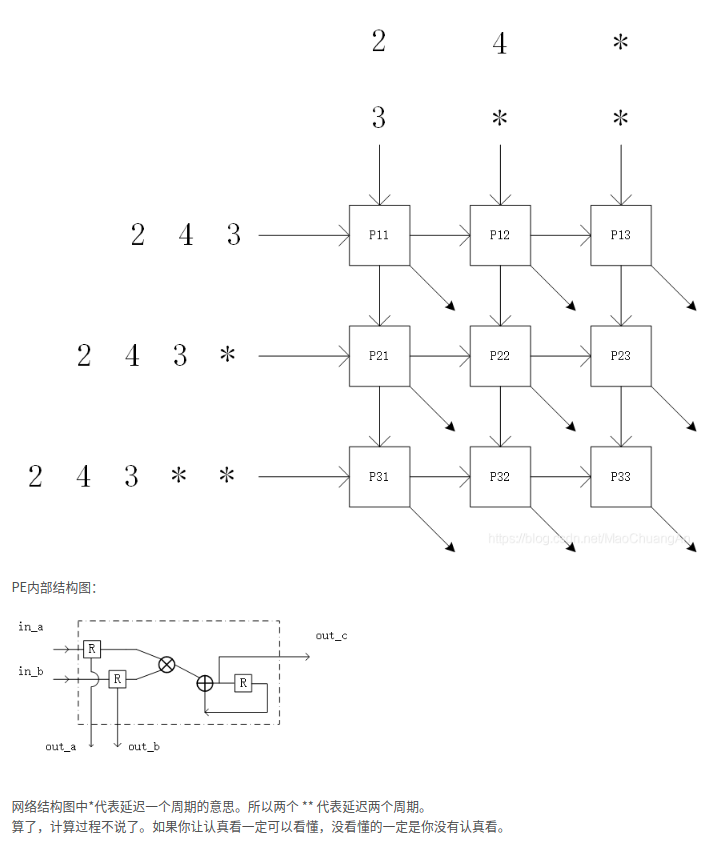
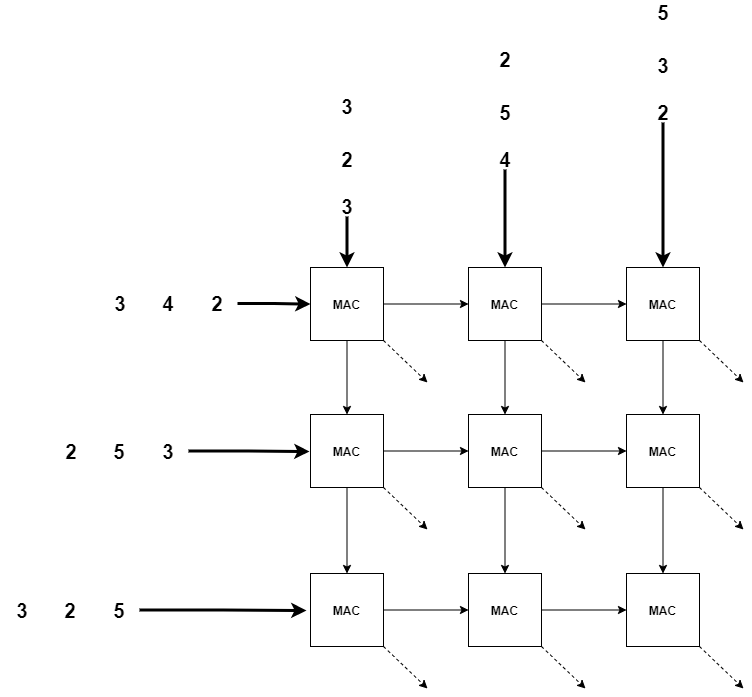
上面的PE实际上就是MAC,上面的图实际上是画错了,正确的如下,虚线是指向内部,这是一个三维的MAC阵列,不是平面的。下面的例子展示了一个用脉动阵列做GEMM的例子(GErnal Matrix Multiply).
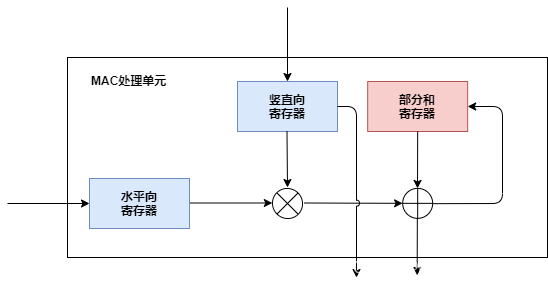
图中每个MAC阵列的结构:
把其中一个能力放入一个解决方案中,其实已经可以了,在通用性上其实并没有降低太多,人脸识别、车辆识别等应用虽然看起来不一样,但对芯片来说只是换一个模型而已
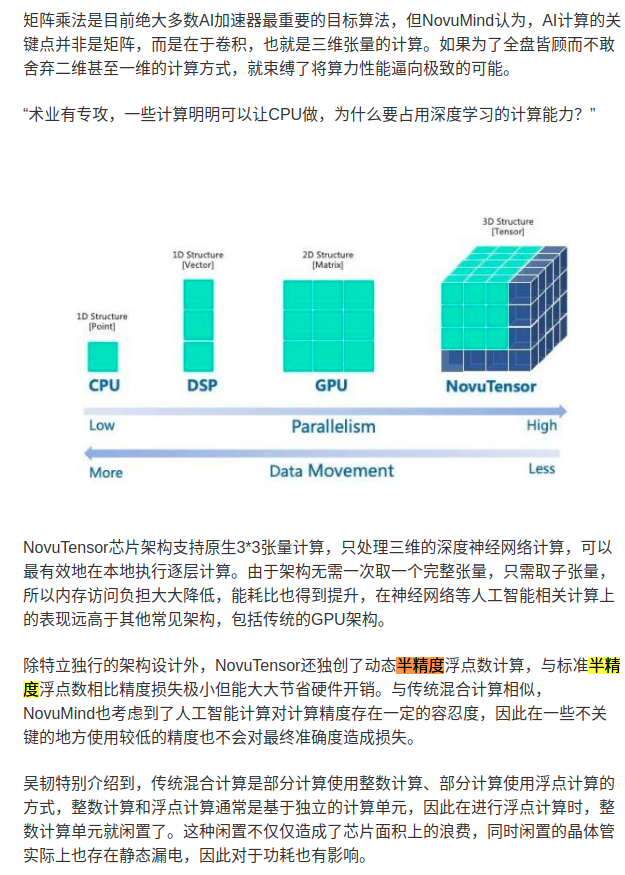
多网络并行执行:
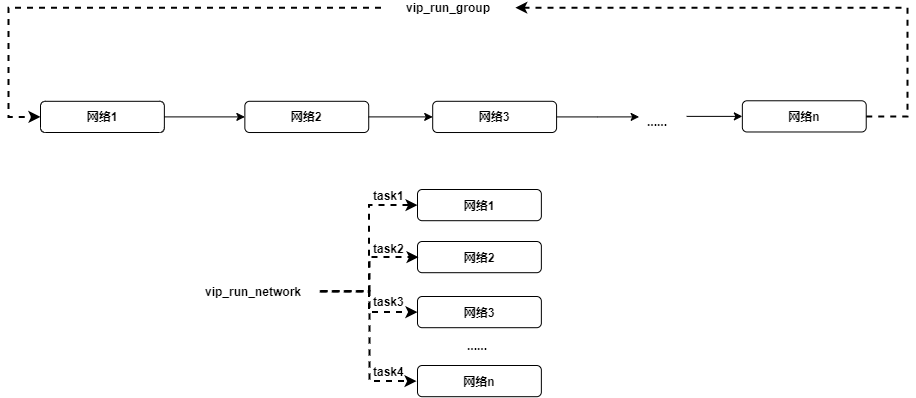
Versilicon 的TIM-VX开源项目架构:
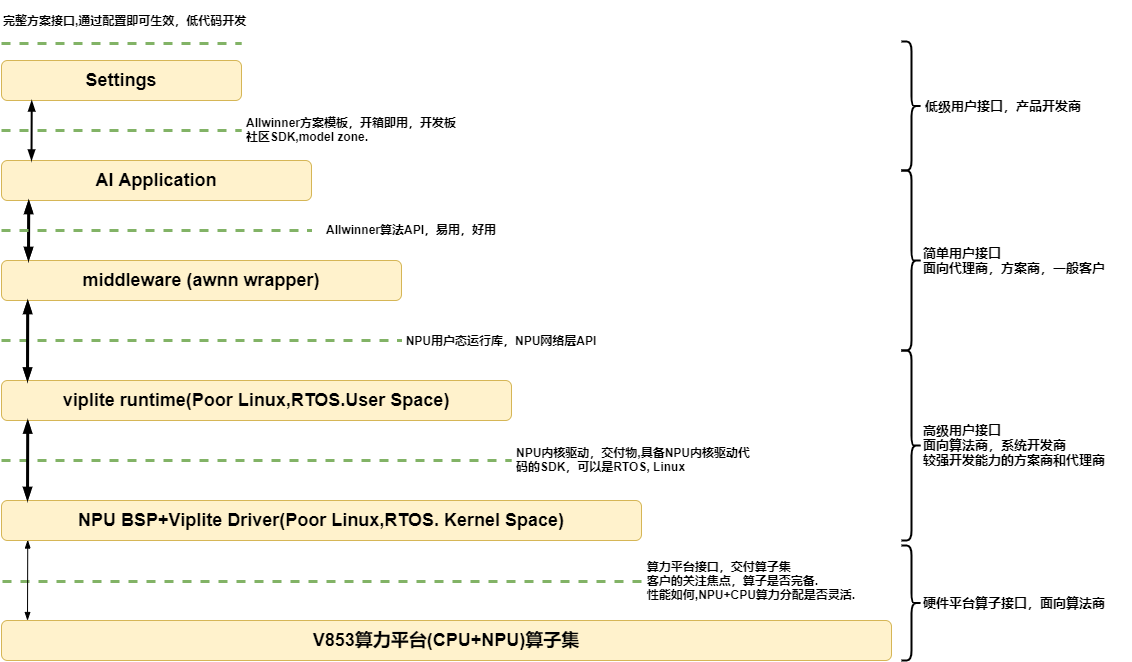
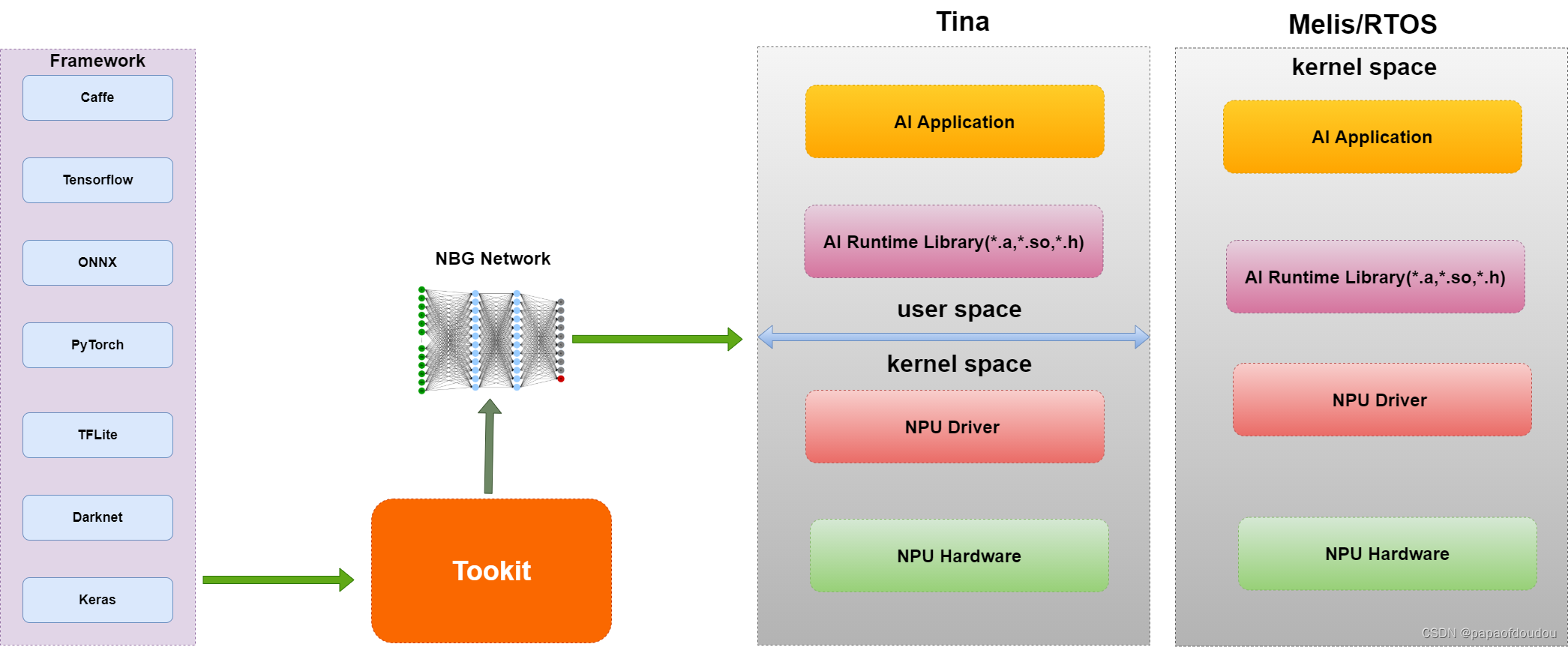
unified和viplite的区别,要看应用的要求,viplite适合应用能提前确定的场景,rtos/poor linux都可以,跑NBG,内存开销小.unified是适配rich linux/android, 内存占用大,支持在线编译,可以直接运行开源模型,所以也用于对接各种开源框架.
缺点:在线编译对于像ARM Cortex-A7这种32位的处理器来说,是一个大活儿,保守估计,一个差不多规模的网络从投入到编译完成,需要消耗几分钟的时间。同样的模型第二次执行可能会快一点儿,但是总之不会太乐观。
芯原 TIM-VX 部署示例 — Paddle-Lite 文档
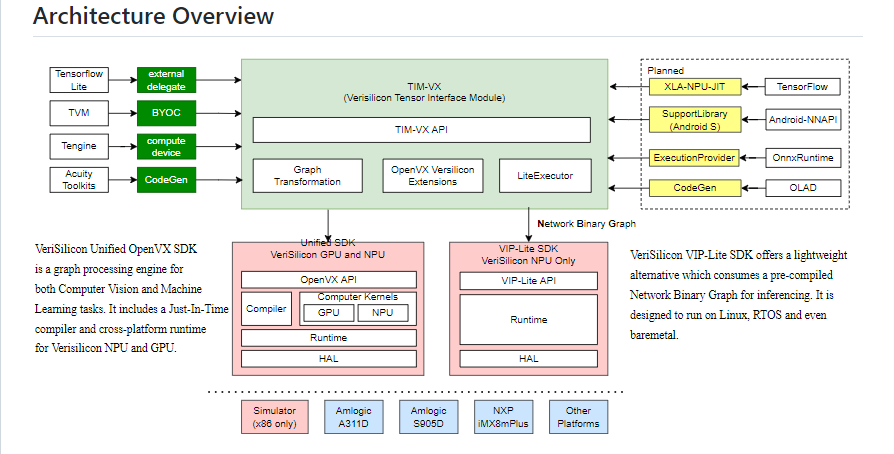
TVM也是模型编译器,两个编译器怎么对起来的?或许从BYOC关键字中可以找到答案:

OCR的应用场景,可以用深度学习网络,也可以用transformer类型的网络是么?
可以
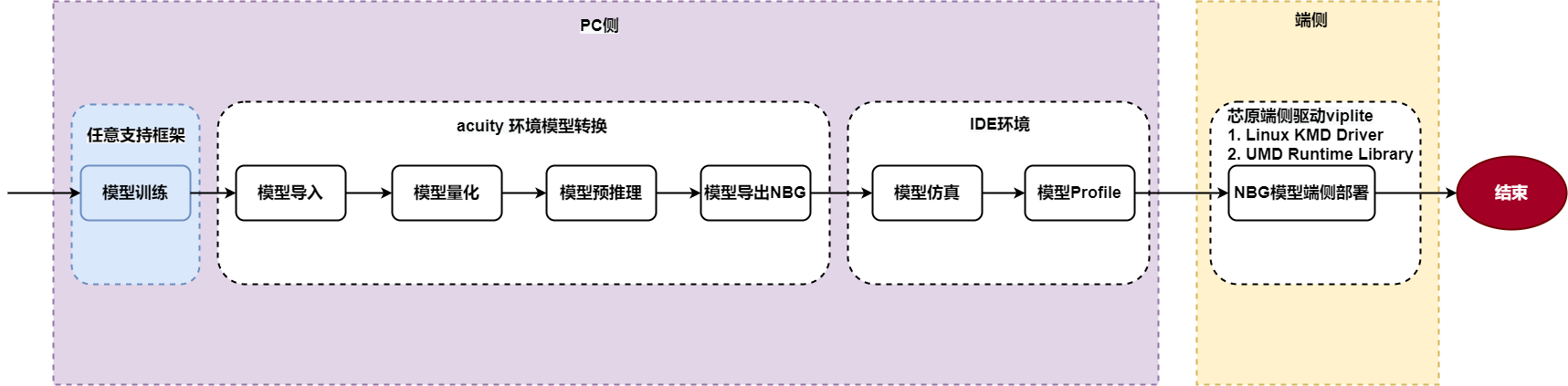
芯原的模型部署工具使用流程
Mobilenet :
Mobilenet原本是分类网络,可以加上ssd后,变成了mobilenet-ssd,就变成了检测网络了。
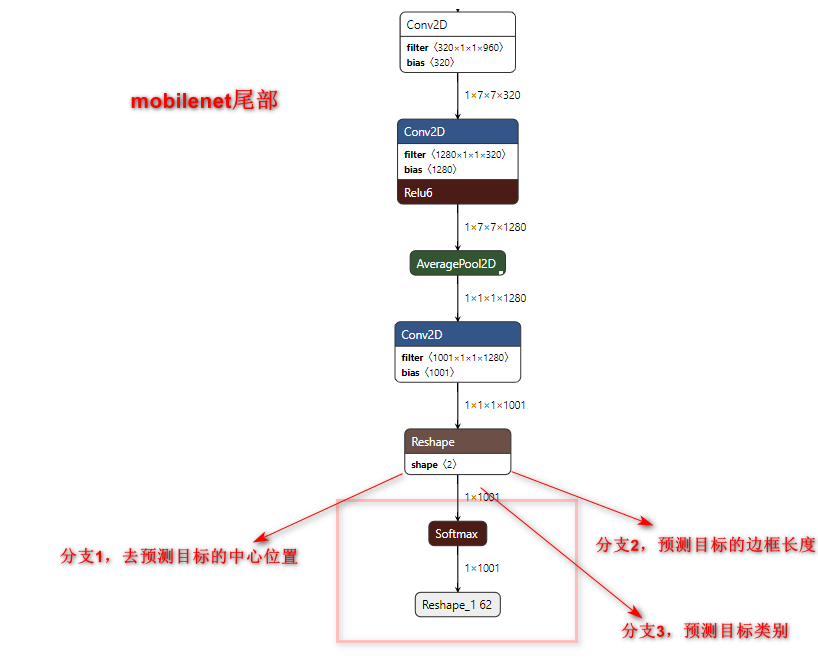
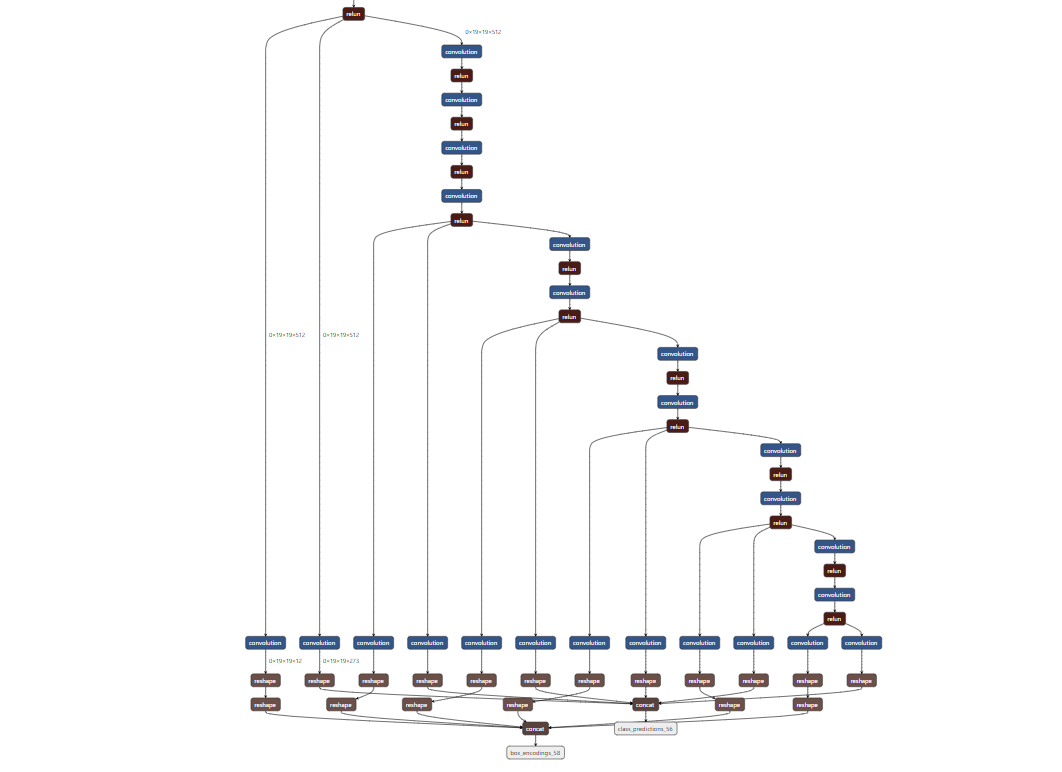
嫁接的SSD层:
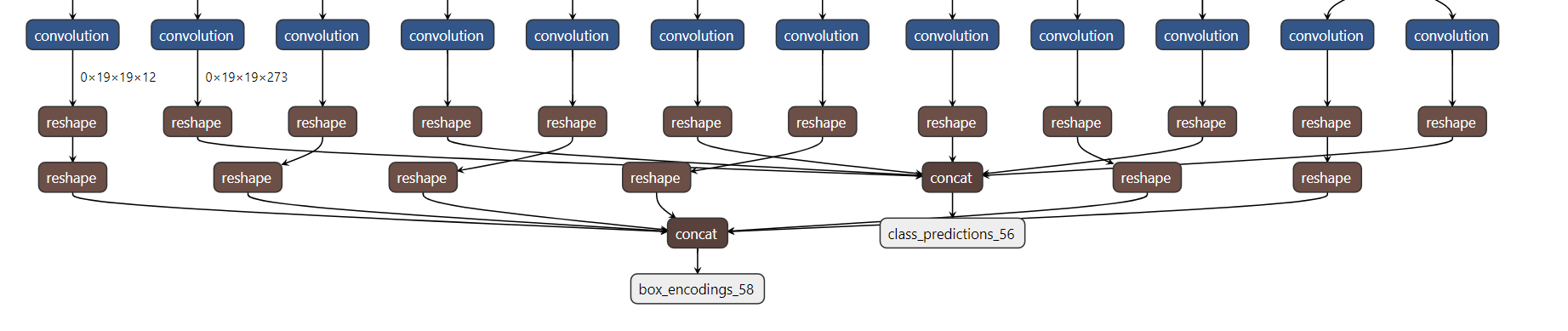
输出特写:
box_encoding_s58应该是1和2,class_prediction_56应该是3.
为什么减均值,除方差:
减均值,目的是将数据中心搬移到坐标原点,除方差(其实是标准差,方差的算数平方根),是将数据大部分都缩放进[-1,1]的区间内。
标准差是方差的算数平方根,归一化除以的是标准差,而非方差。比如,均匀分布的
均值是:
方差是:
标准差是方差的算数平方根:
所以,归一化后,右边最大值b归一化为:
同样道理,左边最小值a归一化为:
所以,减均值,除标准差之后,均匀分布的范围为:
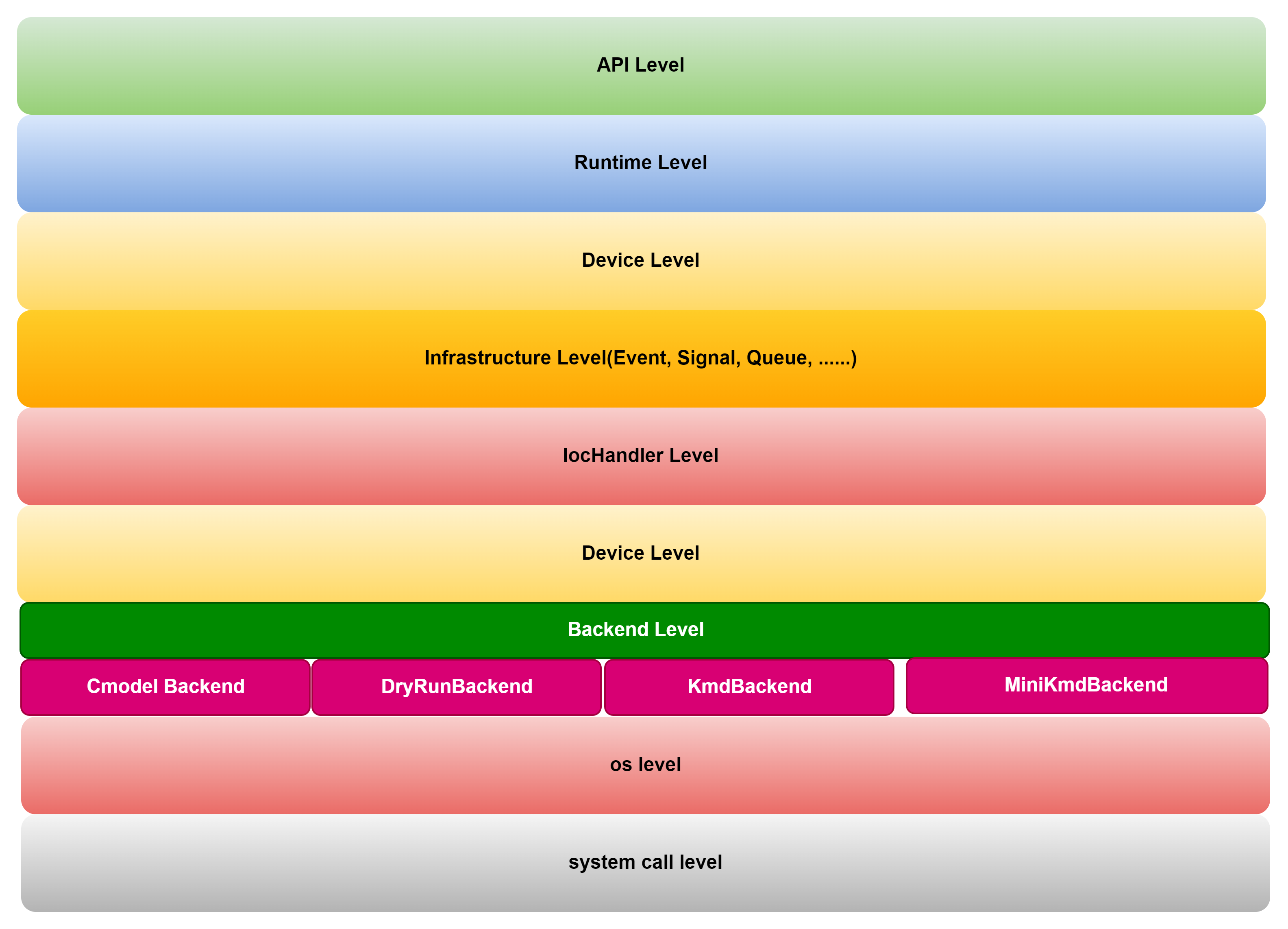
技术路径
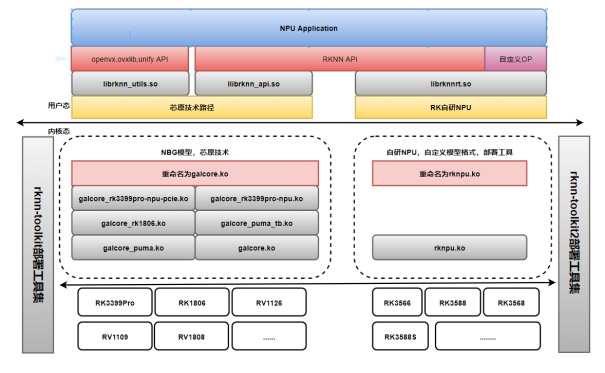
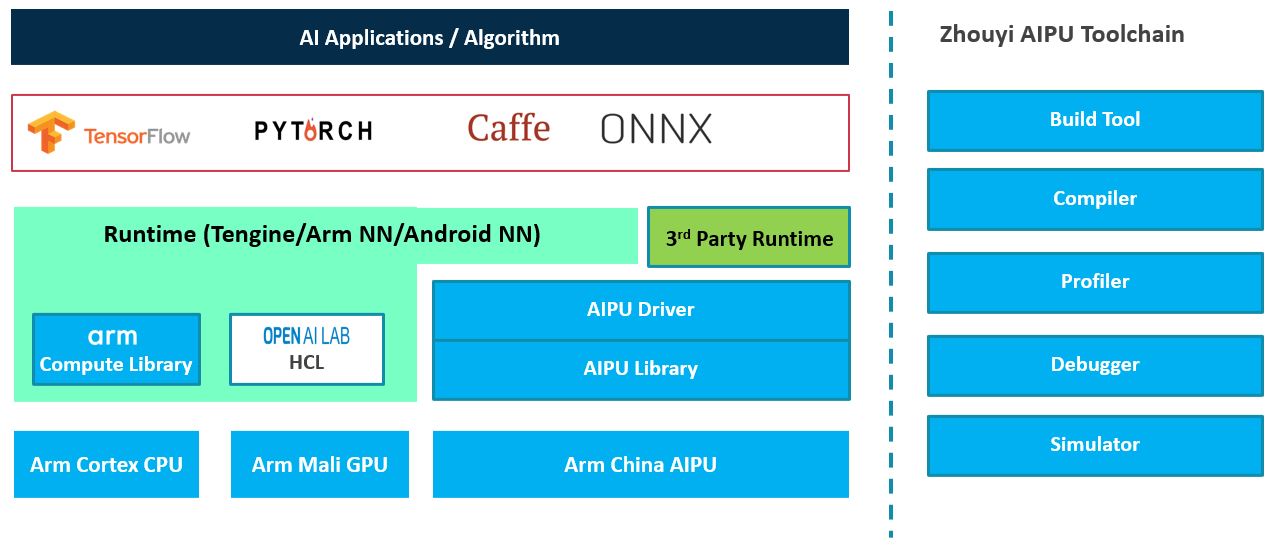
周易AIPU架构:
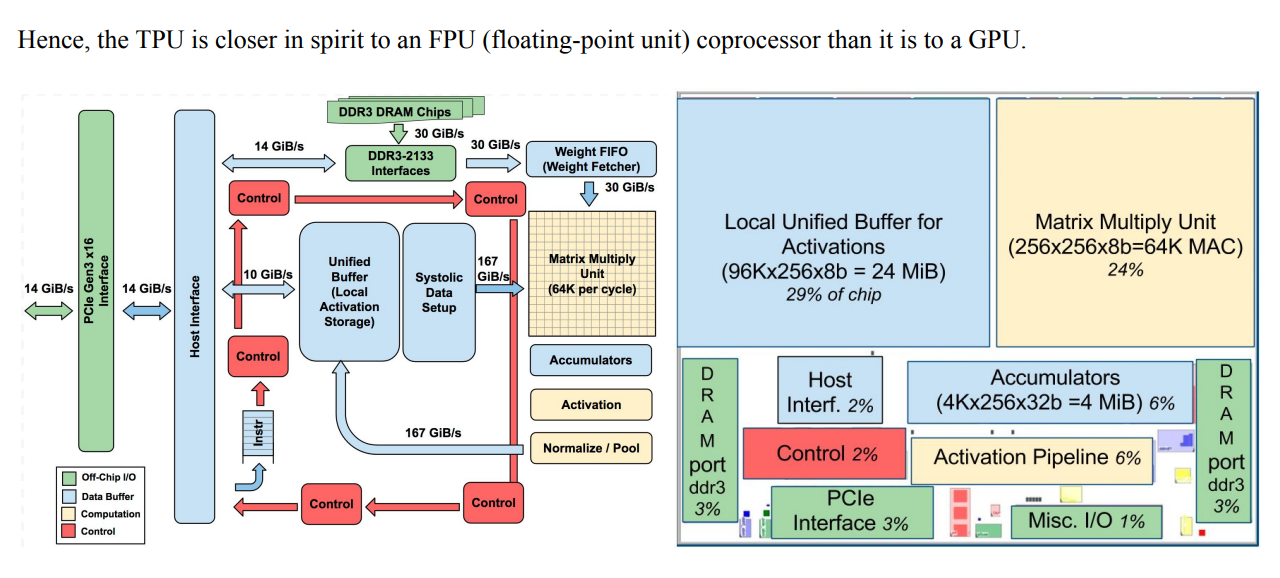
CPU送指令执行的方式更像是FPU,而不是GPU,这或许我是我一直想区分的NPU设计方式中的逻辑硬件化的,比如卷积算子,就真的去设计一个卷积电路,然后用过cpu发送CMD驱使它去工作.

神经网络加速器应用实例:图像分类 - 暗海风 - 博客园
YOLOV3结构:
寒光NPU架构: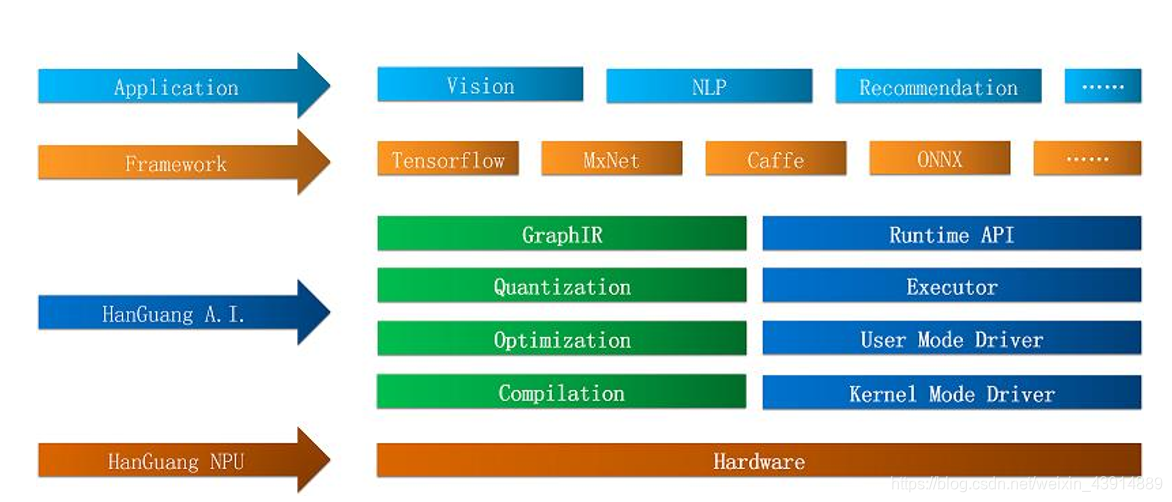
AI Benchmark
关于前量化和后量化的区别:

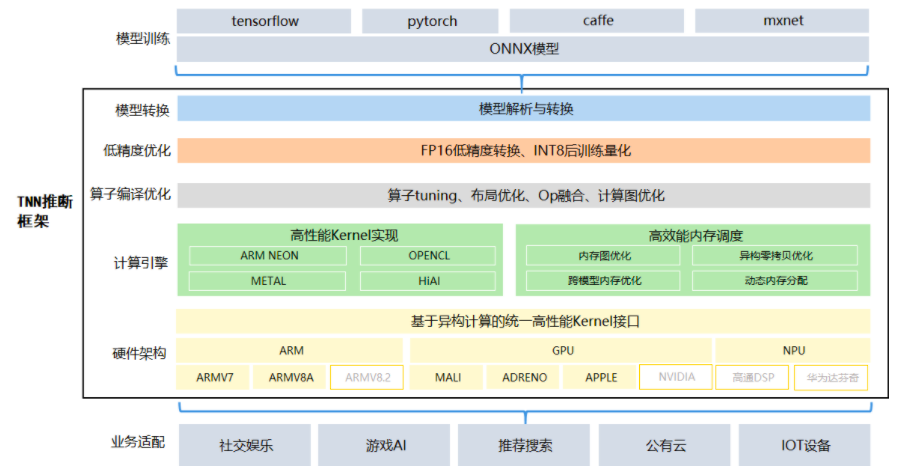
TNN架构:
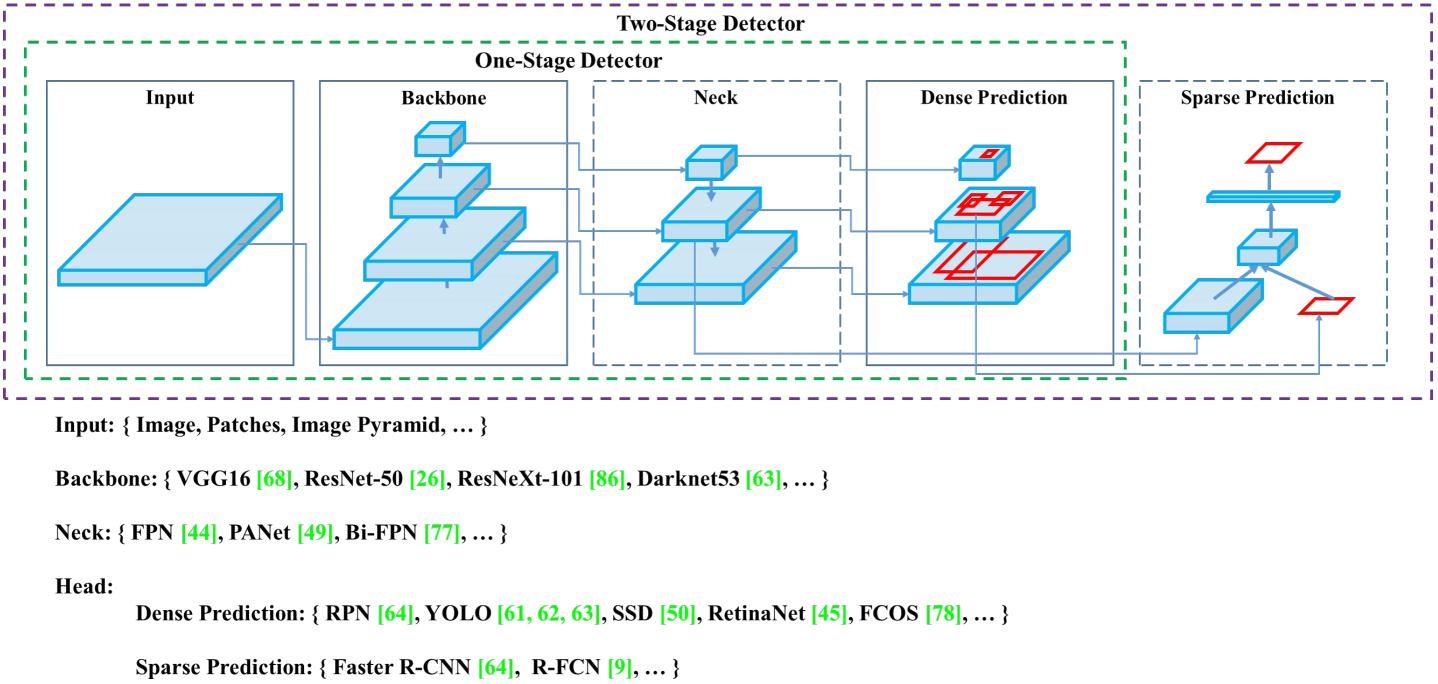
目标检测算法中的Backbone、Neck和Head
分类网络迁移过来,用作特征提取器(通过在OD数据集上进行微调,并且与后续的网络的共同训练,使得它提取出来的特征更适合OD任务),后续的网络负责从这些特征中,检测目标的位置和类别。那么,我们就将分类网络所在的环节称之为“Backbone”,后续连接的网络层称之为“Detection head"
基于深度学习的现在目标检测算法中有三个组件:Backbone、Neck和Head,乍一看很让人不理解:
- Backbone, 译作骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等
- Head,译作检测头,主要用于预测目标的种类和位置(bounding boxes)
- 在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层,通常称为Neck。
简而言之,基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出
如何理解分类,检测和分割?

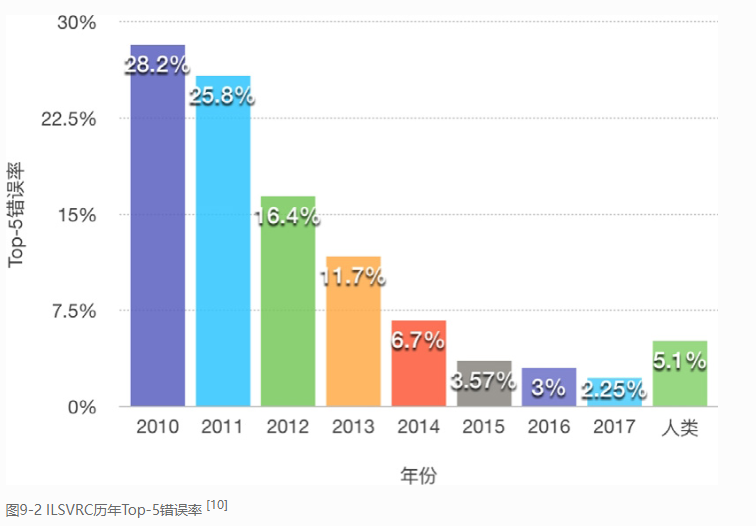
TOP5和TOP1的区别:
Top-5错误率
即对一个图片,如果概率前五中包含正确答案,即认为正确。
Top-1错误率
即对一个图片,如果概率最大的是正确答案,才认为正确。
top-5识别准确率相对比较简单,谷歌是不会把这当作卖点的。(注:top-5识别准确率指的是在测试图片的N个分类概率中,取前面5个最大的分类概率,这五个当中只要有一个预测正确即可,而top-1则最难,只取第一个预测输出结果,对就是对,错就是错。)
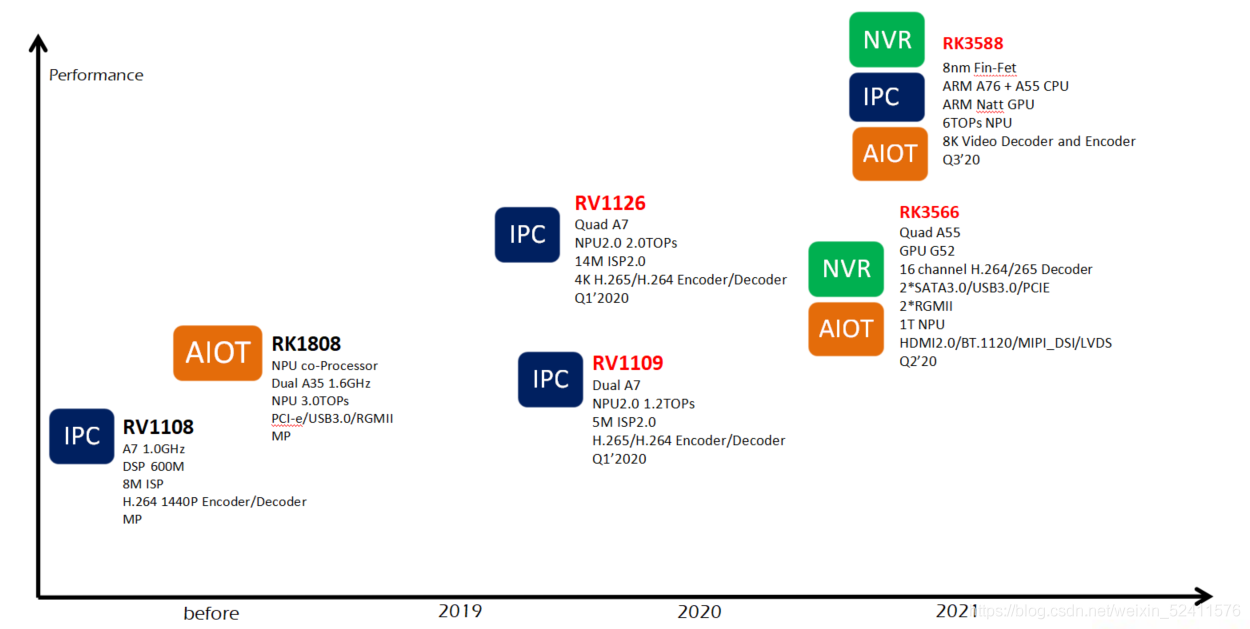
RK1109&RK1126
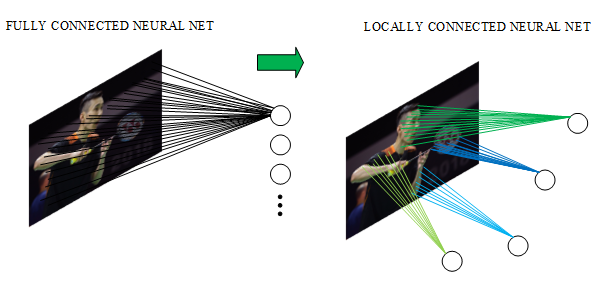
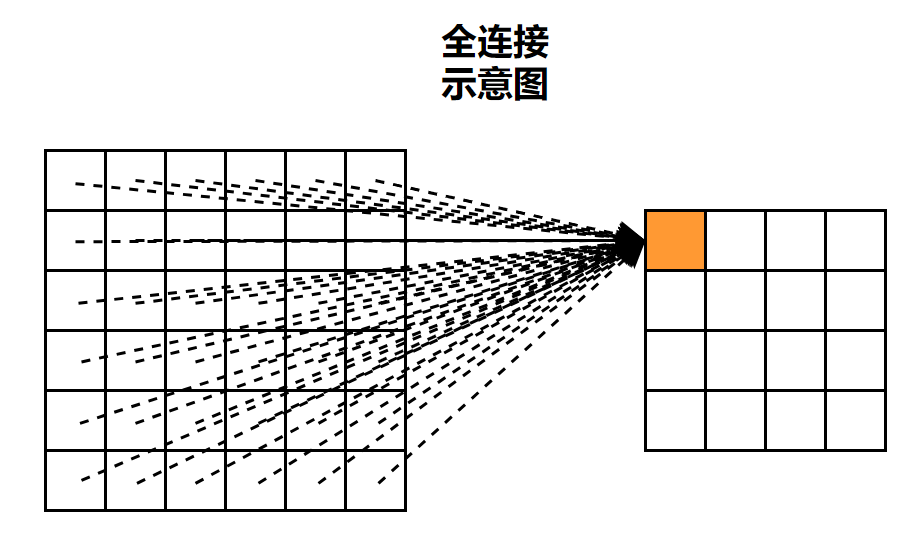
全连接示意图:
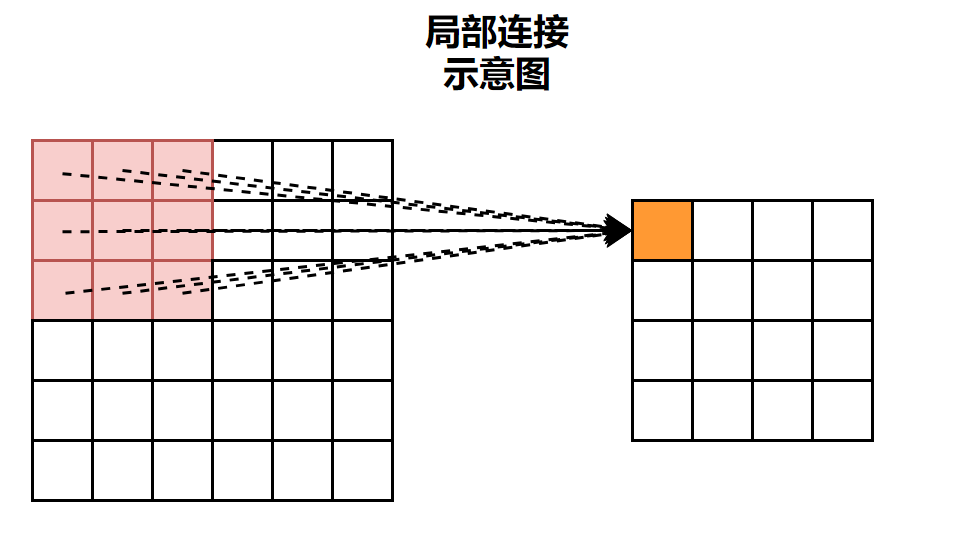
局部连接示意图:
通道卷积示意图:
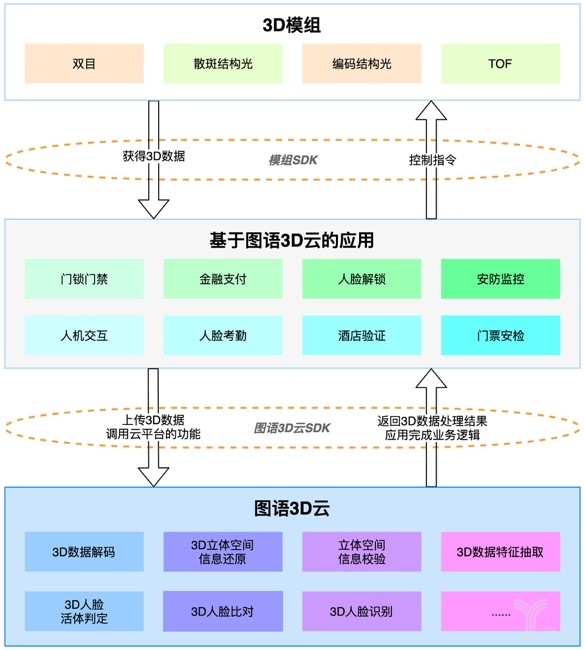
图语3D应用
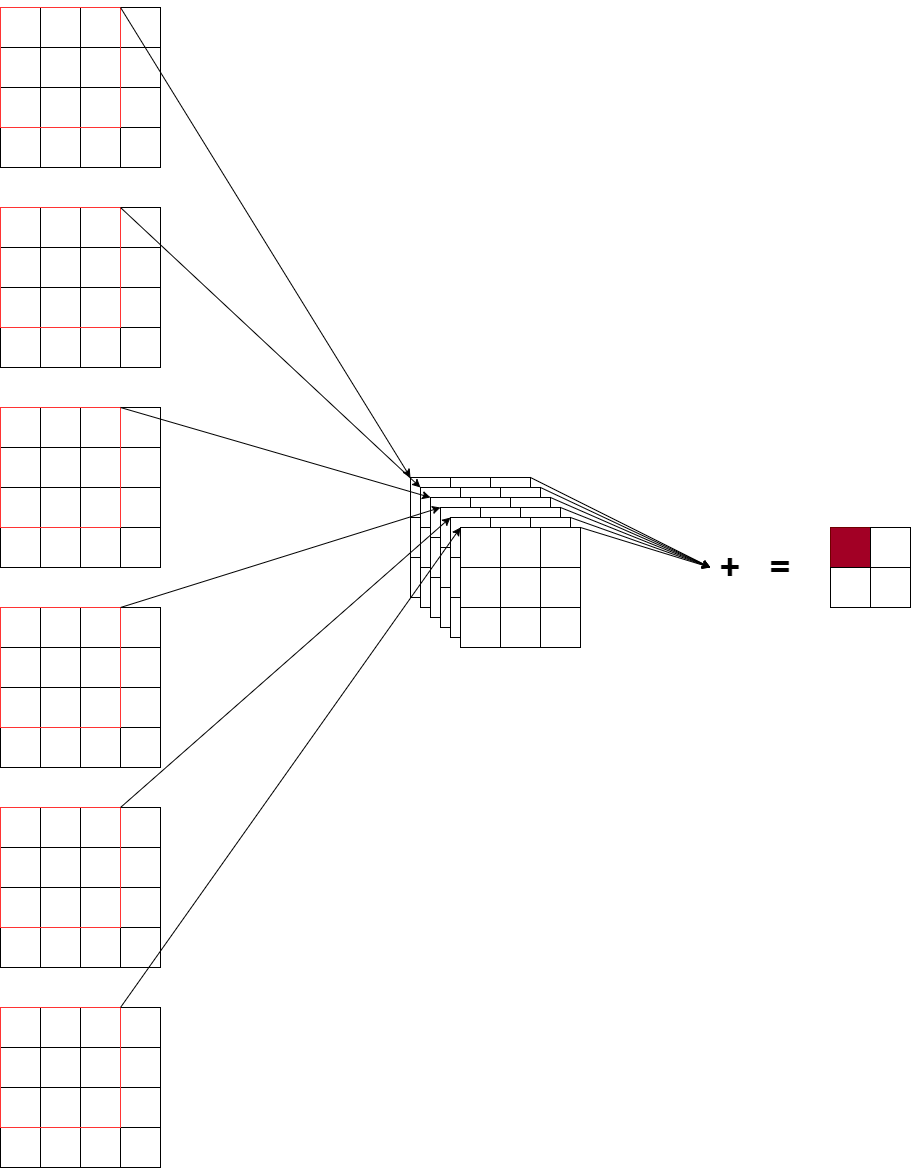
矩阵乘法计算单元:
从下图中其实也能看出矩阵乘法的结构,三层循环,内循环是MAC乘加法,外面两层循环枚举。

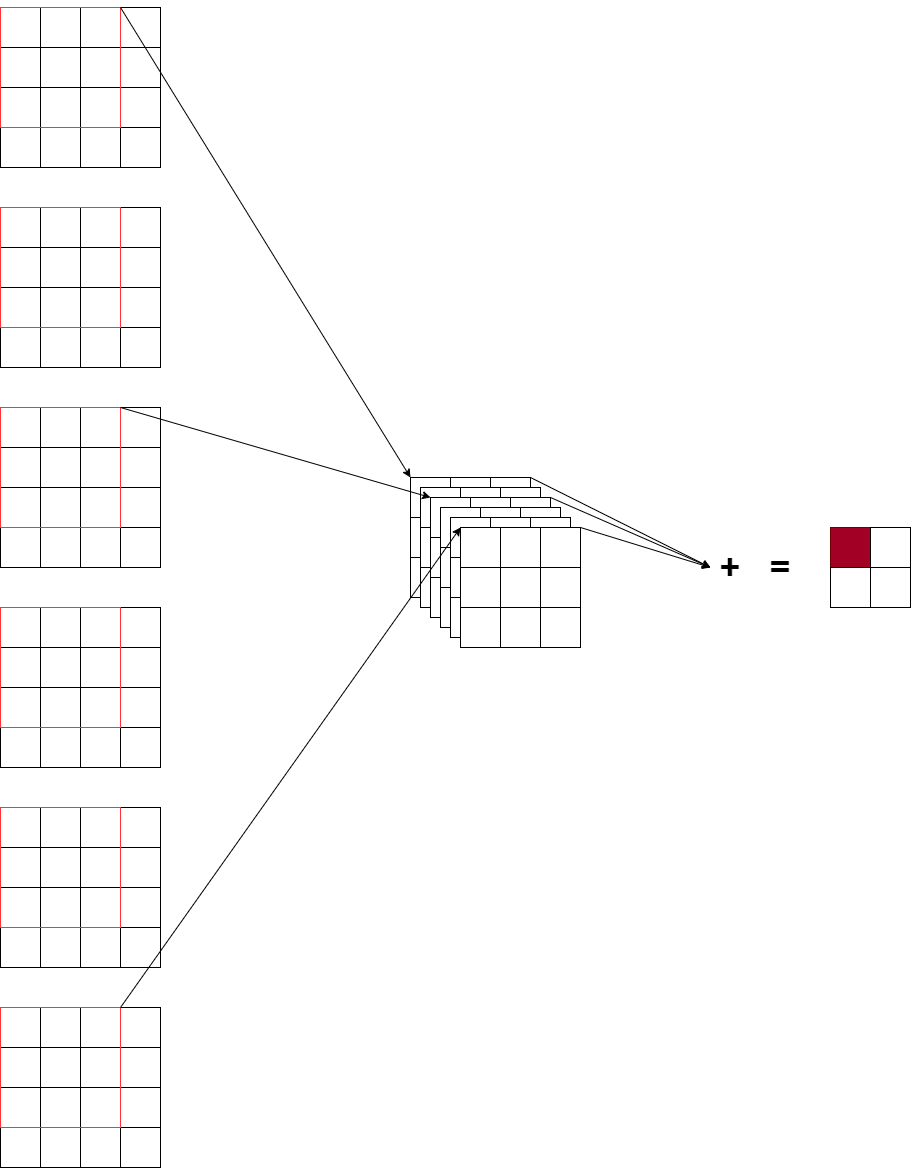
DP4A指令和NEON SIMD指令的差异在哪里?
被捧上天的Nvidia CUDA计算单元的DP4A指令。

同时,ARM NEON SIMD的向量乘法指令:
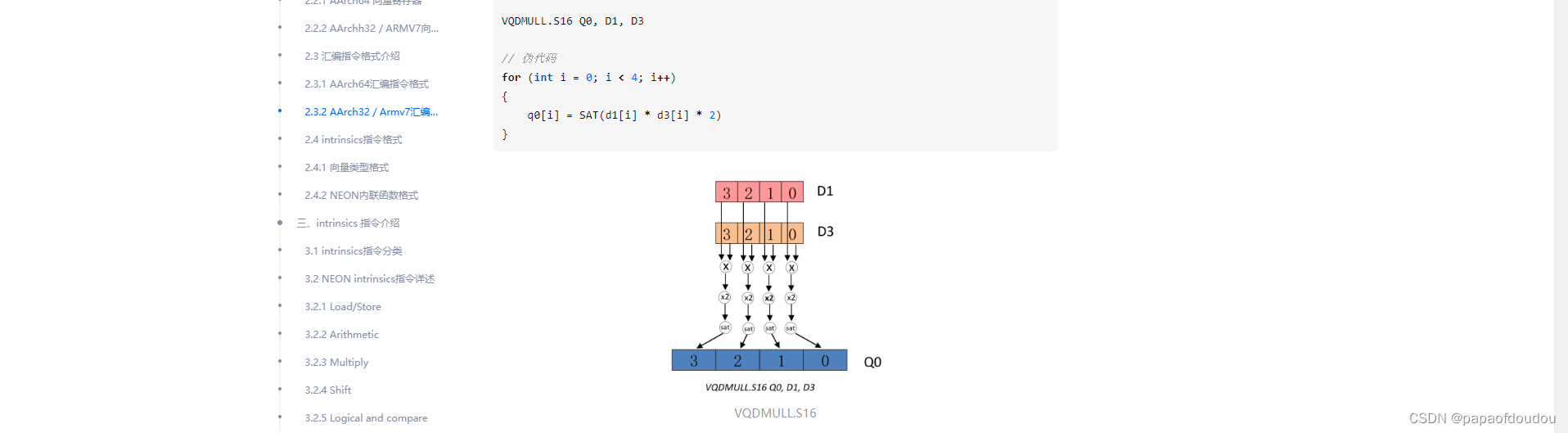
通过上面两张图,可以看出来明显差别,dp4a 会做加和,但是arm neon simd vqdmull指令却仅仅做了向量乘法,或许这就是本质差异。
SIMD的实现种类
低比特量化技术-INT4量化
DNN对噪声也具有鲁棒性。在权重或输入上添加噪声,有时候可以获得更好的性能。随机噪声充当正则化项,可以更好地泛化网络。量化DNN的低精度操作,也被看作是不会损害网络性能的噪声。参数冗余
神经网络模型的偏差项(bias terms)在线性方程中会引入了截距。它们通常被视为常量,帮助网络训练并适配给定数据。由于偏差占用最少的内存(例如,10进-12出的全联接网络即FCL,有12个偏差值,对应120个权重值),所以一般建议偏差保持满精度。如果做偏差量化,则可以乘上特征尺度和权重尺度。
在自动驾驶领域,NN模型量化必须要保证安全性的指标不能出现明显下滑,那么INT4精度显然承受的系统风险较大,估计在近几年的市场INT8仍然是自动驾驶NN模型量化的主流。
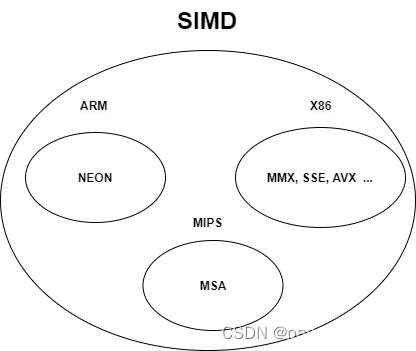
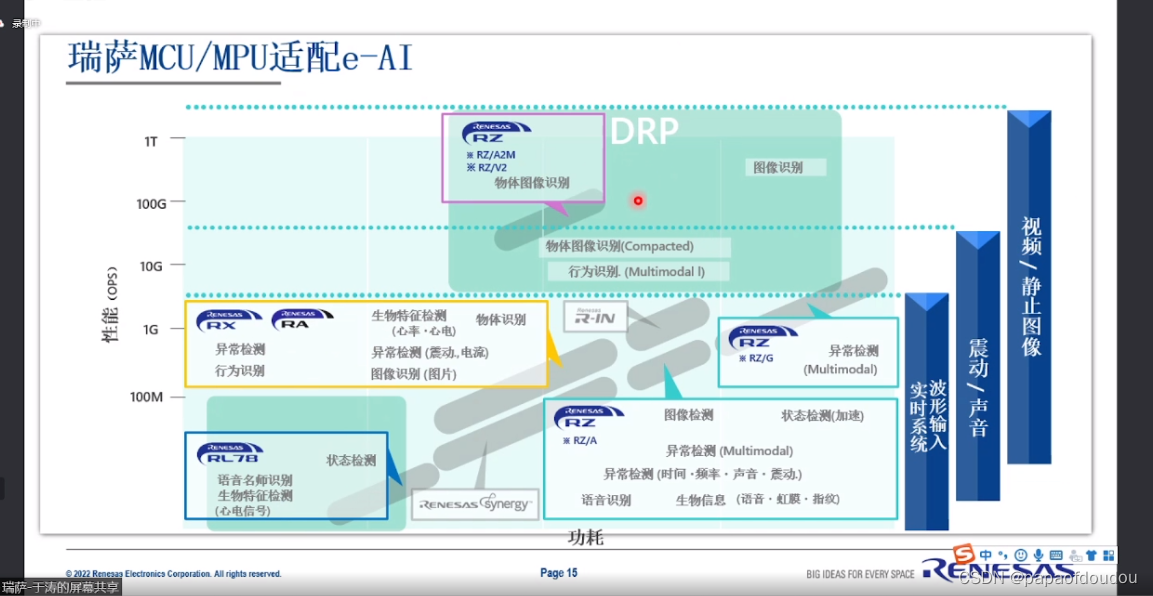
异构算力
算力分类:
| AI轻算力:0.5TOPs NPU算力 AI中算力:<1TOPs NPU算力 AI重算力: >2TOPs NPU算力 |
AI技术栈:
关于算子:
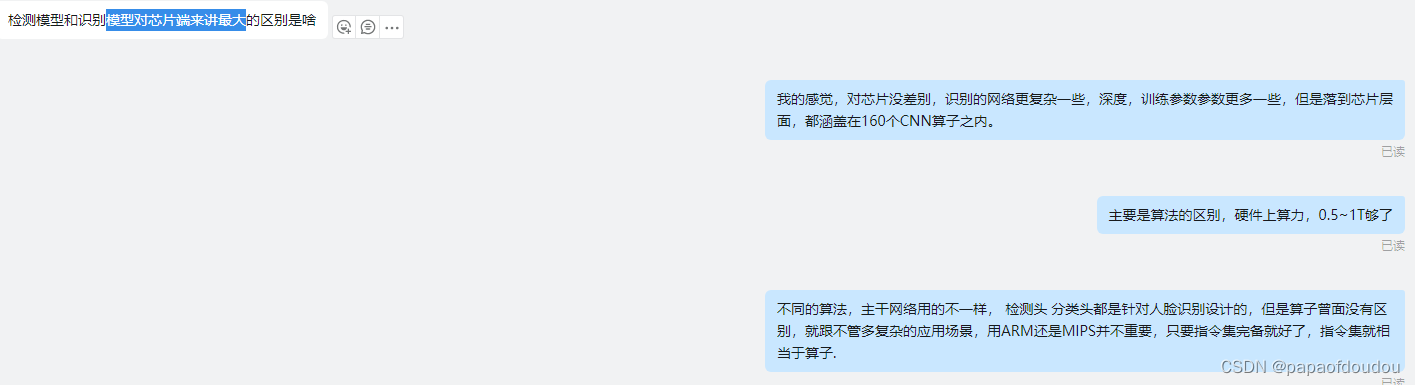
提到算子有一个新的思考维度,可以那它和CPU/DSP架构中的ISA 指令集做类比,就跟不管多复杂的应用场景,用ARM还是MIPS并不重要,都可以做,只要指令集完备就好了,指令集就相当于算子.算子目前位置大约160个,而ISA指令树木也是有限的。
人脸识别由三部分组成:人脸检测,人脸活检,人脸比对
AI服务器:


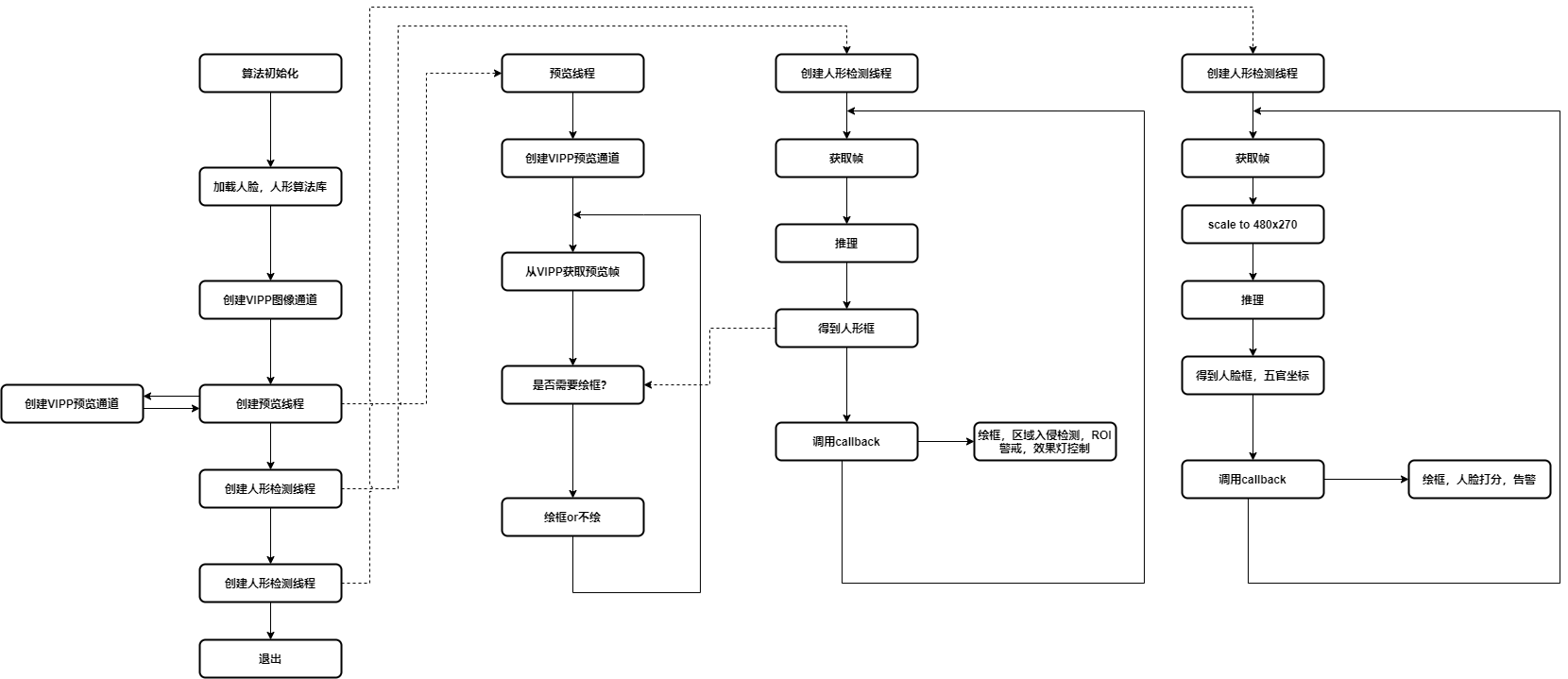
算法需求:


手势识别场景的内容:握拳、五指张开、竖食指、比心、点赞,比V,竖中指.
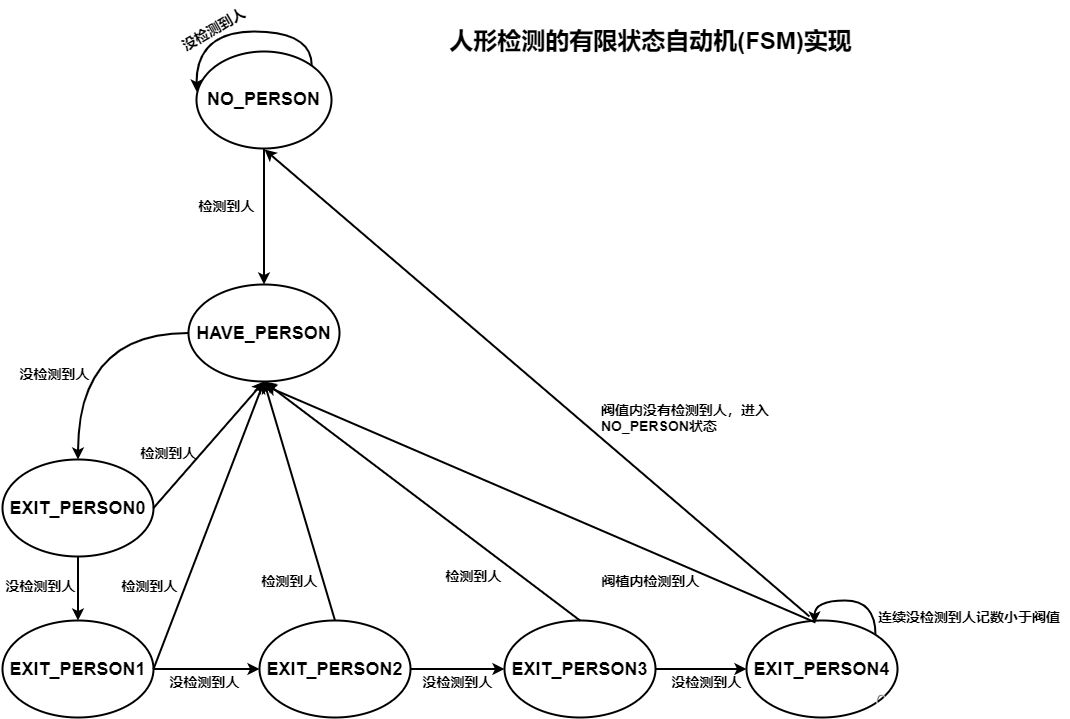
人形检测状态机:
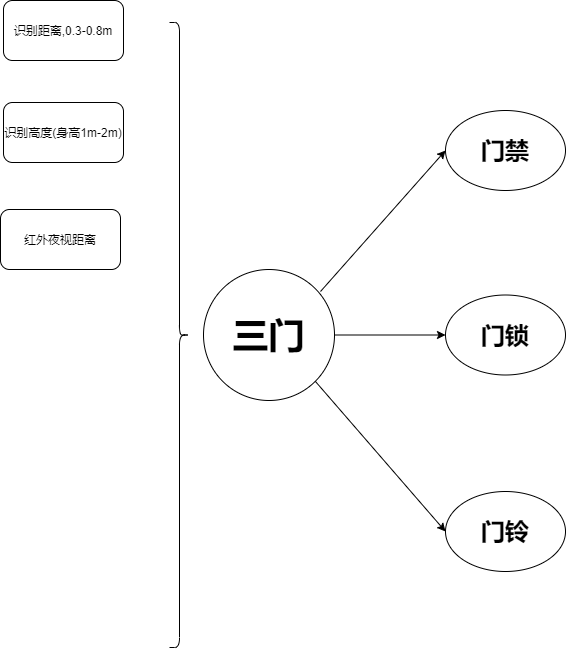
三门的规格
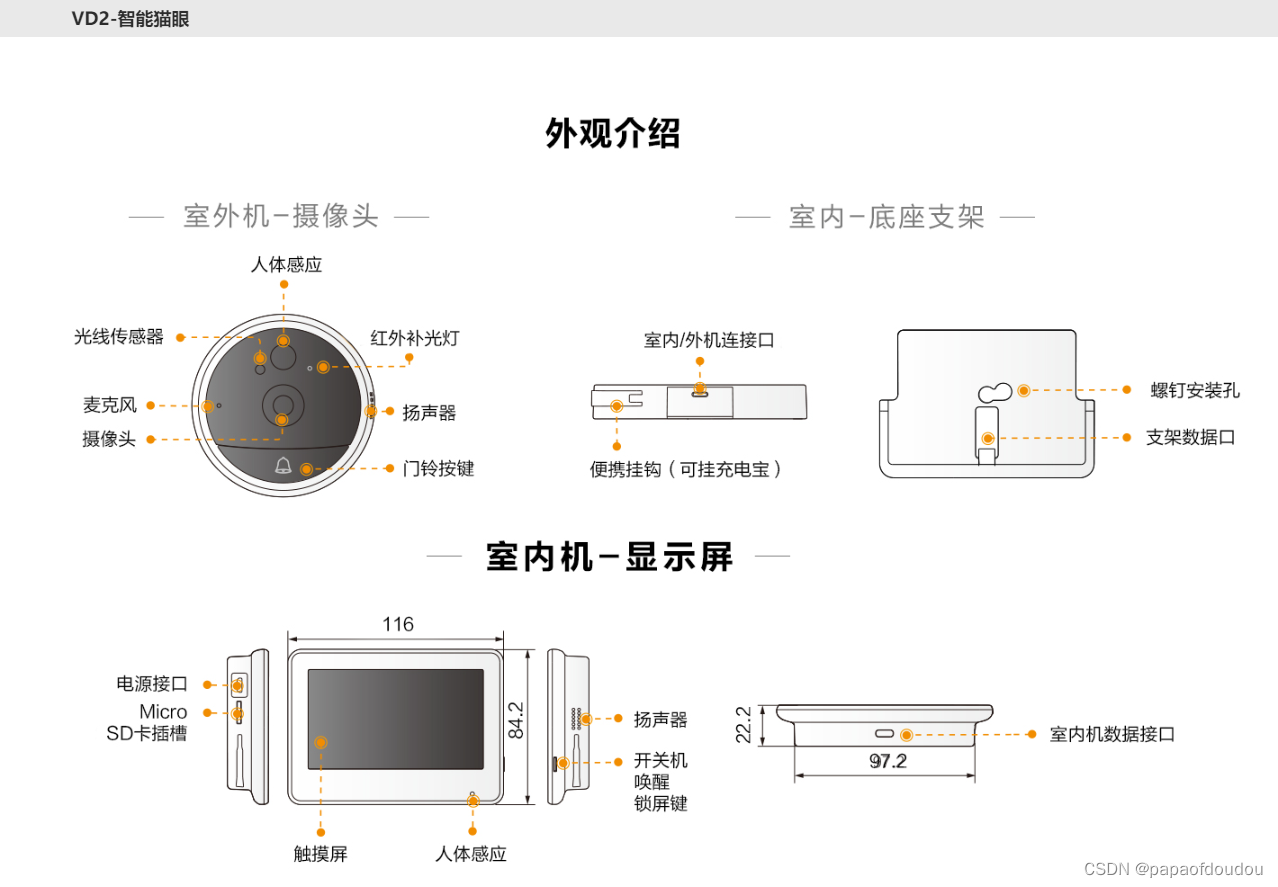
智能猫眼:
b226d9bfbcac82a6ed60eb86a444173820497c59
人脸识别的安全性:





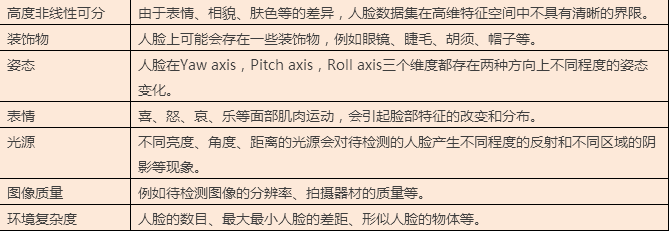
人脸检测adaboost算法:
AdaBoost法最早由viola等人在2001年提出,其中提出了一种称为“积分图像”的图像表示方法。利用AdaBoost算法对由积分图像表示的大量特征进行选择,选择出少量具有代表性的关键特征组合成强分类器,然后采用“级联”策略,每级的特征个数从少到多,在开始粗检的几级就可以排除许多非人脸区域。该方法构建了一个快速高效的人脸检测框架,可以满足实时需求,但当错误报警数目较少时,检测率不高。

人脸识别专题 | 浅析人脸检测方法
基于神经网络的人脸识别
神经网络法通过样本训练一个构建的网络模型,把人脸的统计特征隐含在网络模型的结构和参数中。神经网络方法进行人脸检测的优点是可以简便的构造出神经网络系统作为分类器,使用人脸和非人脸样本对该系统进行训练,让系统自动学习两类样本复杂的类条件密度,这样就避免了人为假设类条件密度函数所带来的问题。

深度学习是神经网络中的一种。在深度学习之前,主流的人脸检测算法主要是使用AdaBoost法,挑选出一些最能代表人脸的矩形特征(弱分类器),按照加权投票的方式将弱分类器构造为一个强分类器,再将训练得到的若干强分类器串联组成一个级联结构的层叠分类器,有效地提高分类器的检测速度。
深度学习的出现,使得人脸识别在这三、四年间取得飞跃的发展。在计算机视觉领域,深度学习中应用得最好、最成功的就是卷积神经网络(CNN)。
人脸识别流程:

认知刷新
CNBC
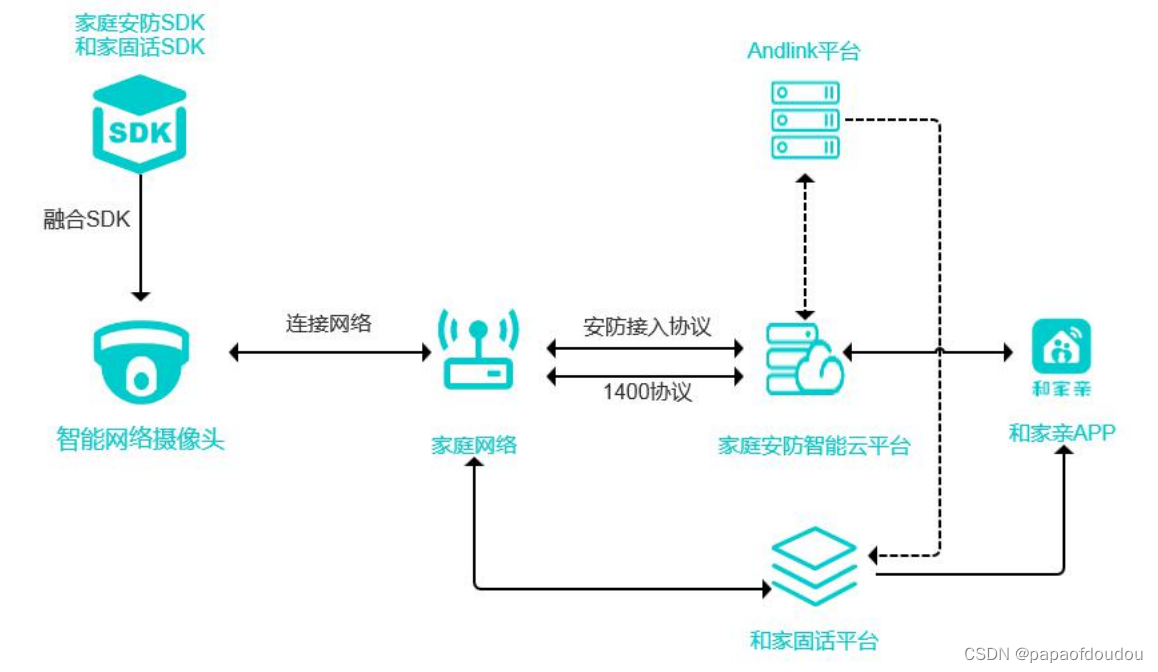
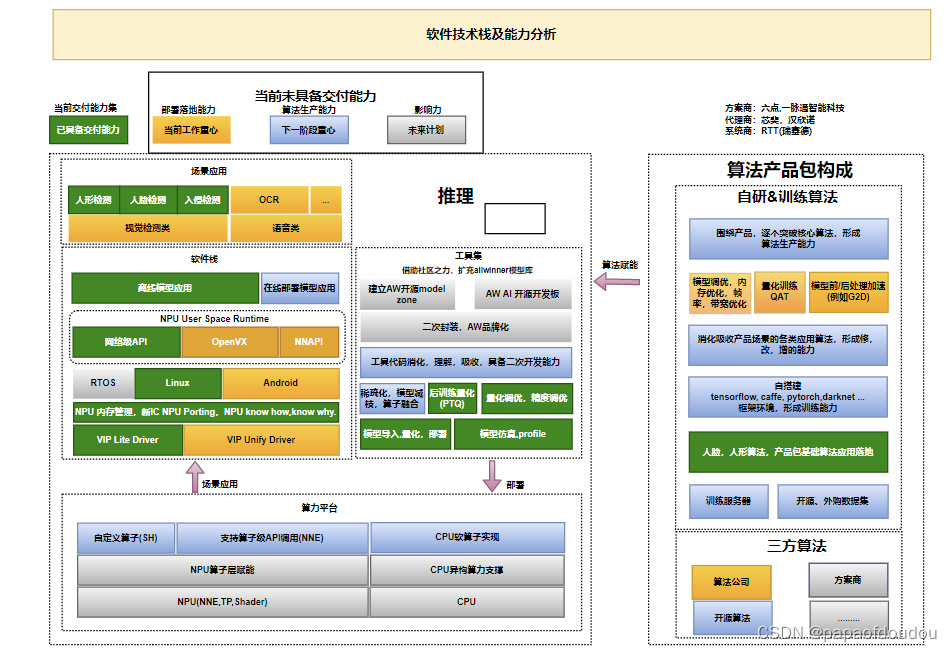
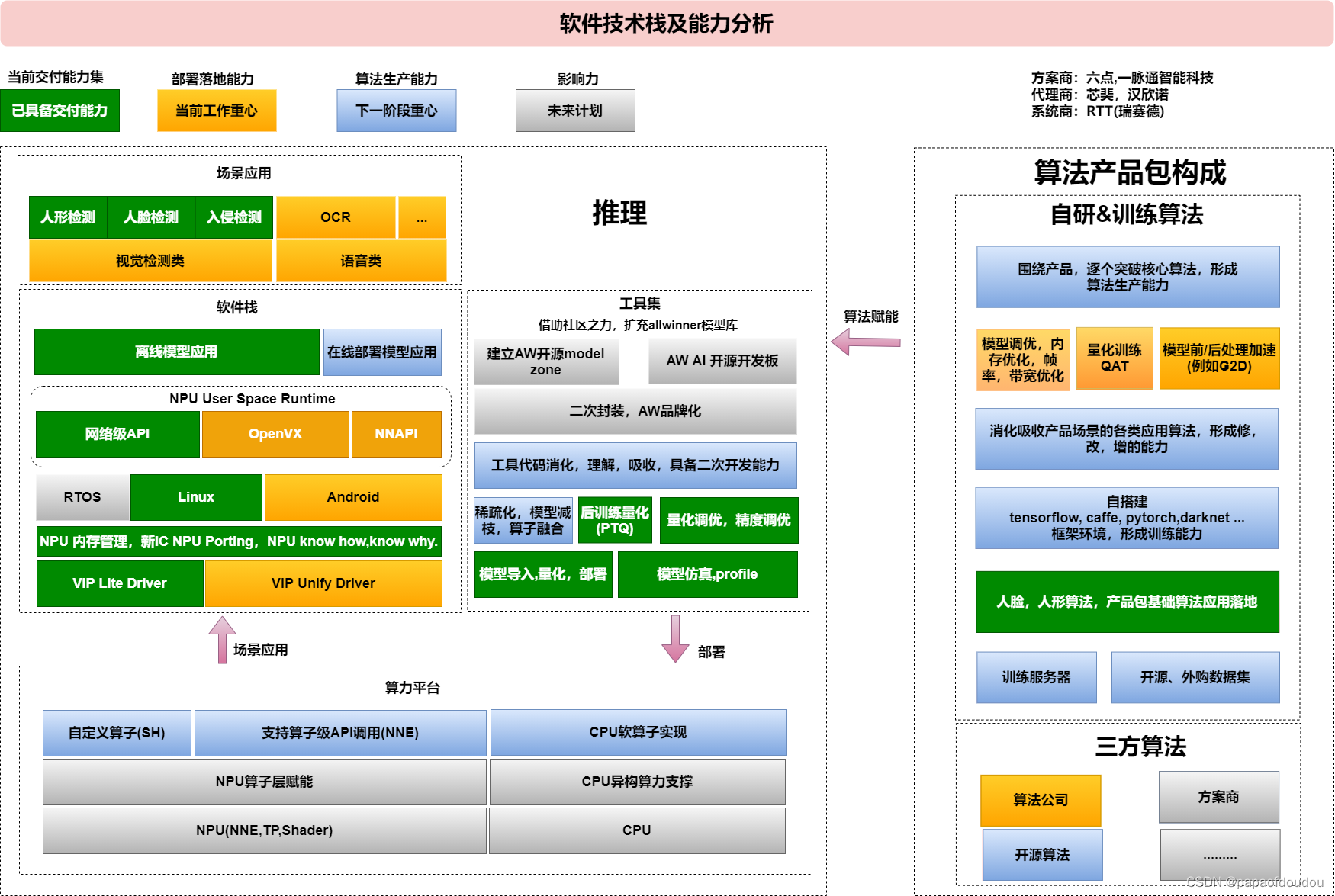
技术栈:
分类器的设计
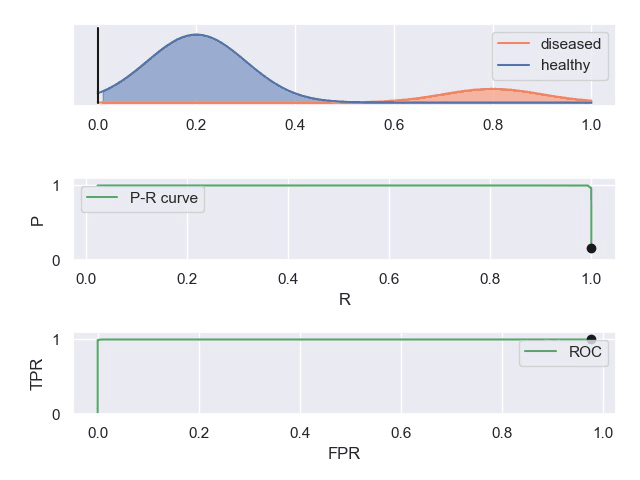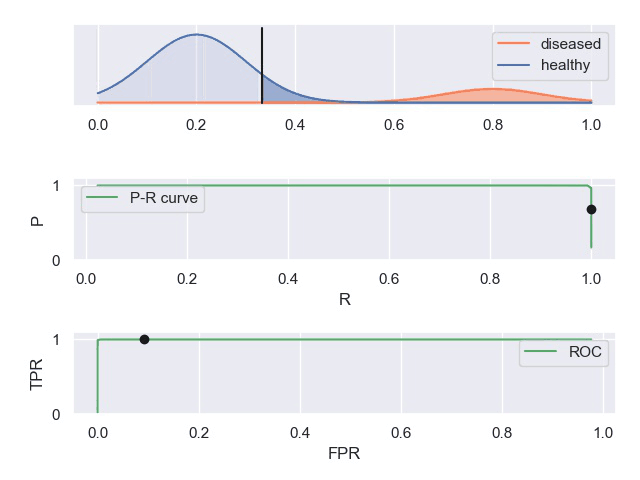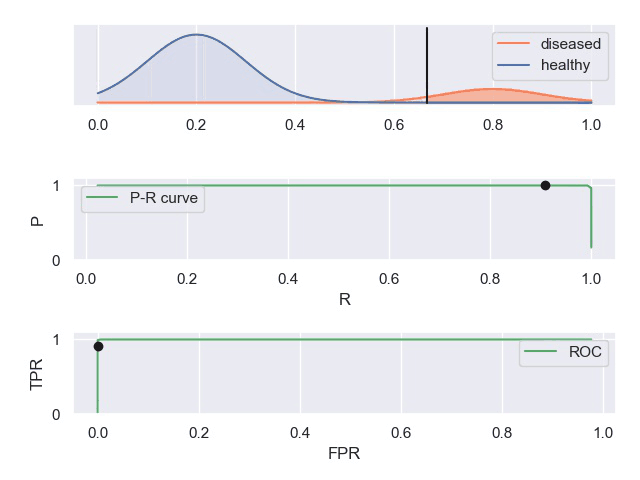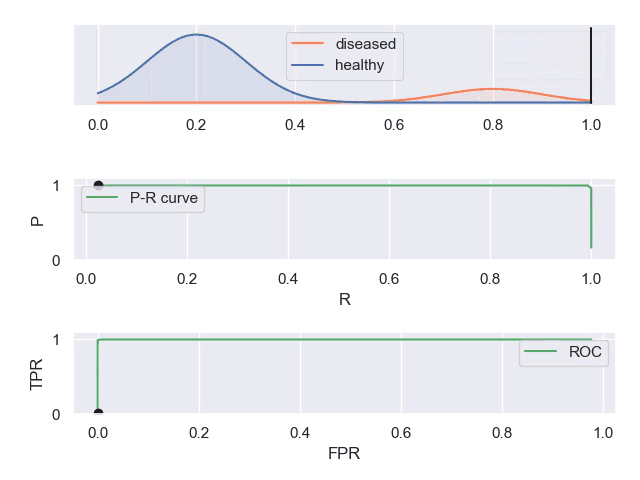
人工智能的难点

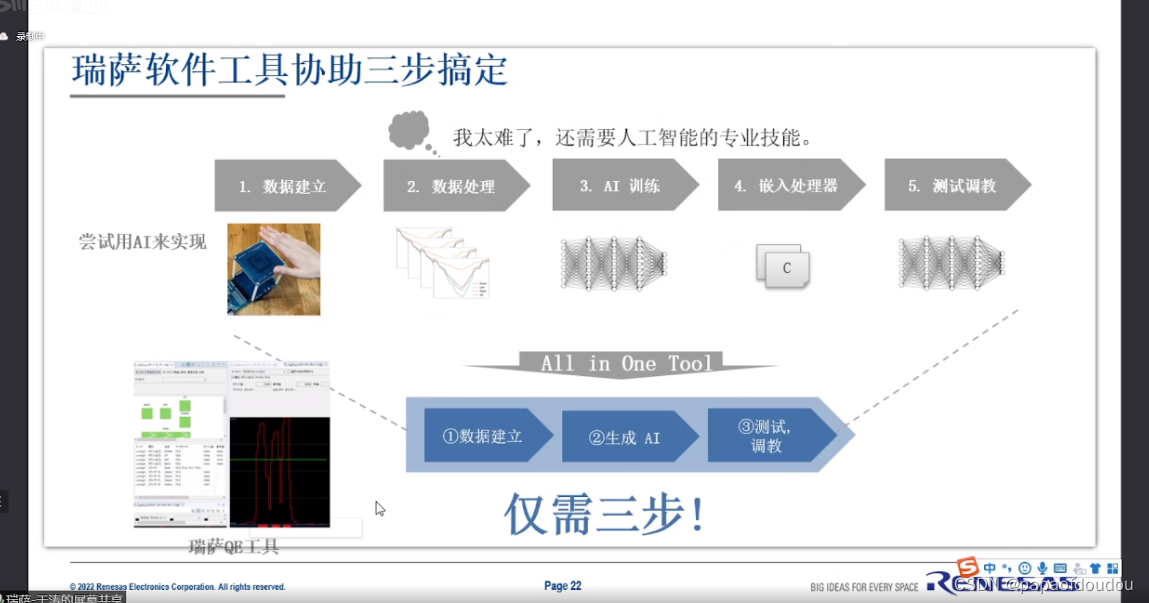
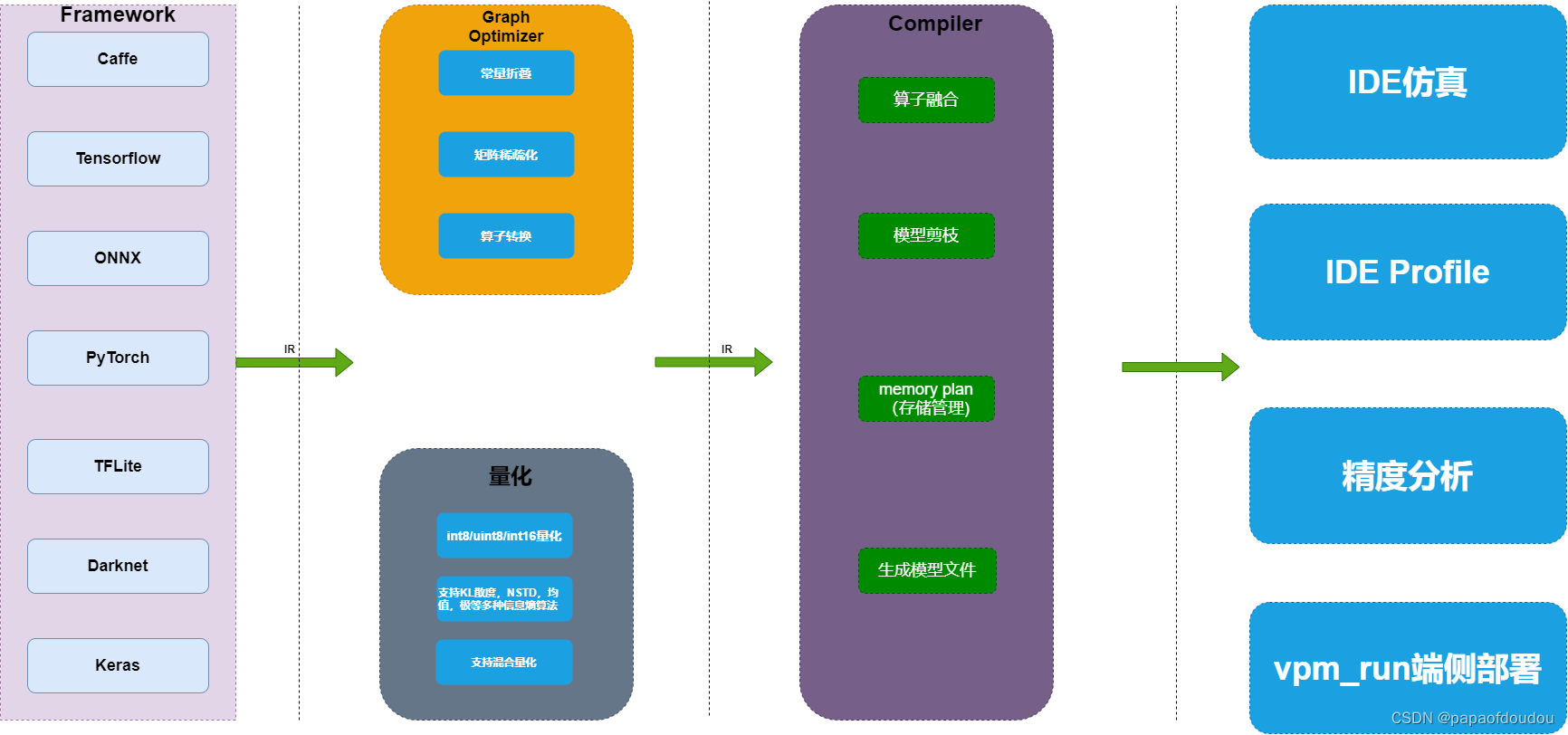
工具逻辑
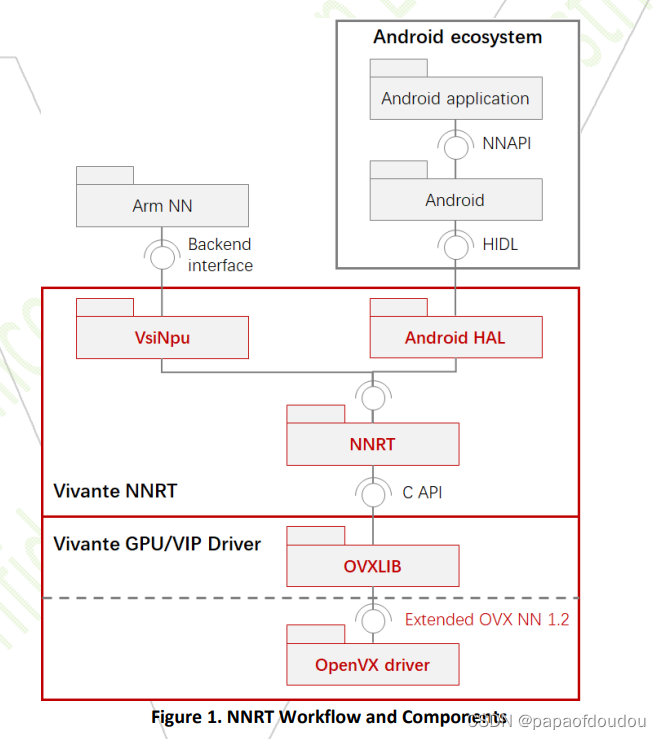
支持人、车,非,物识别,视频结构化,轨迹行为分析等等。
NN-DNN-CNN-RNN-LSTM系谱

常量折叠:


AI性能指标

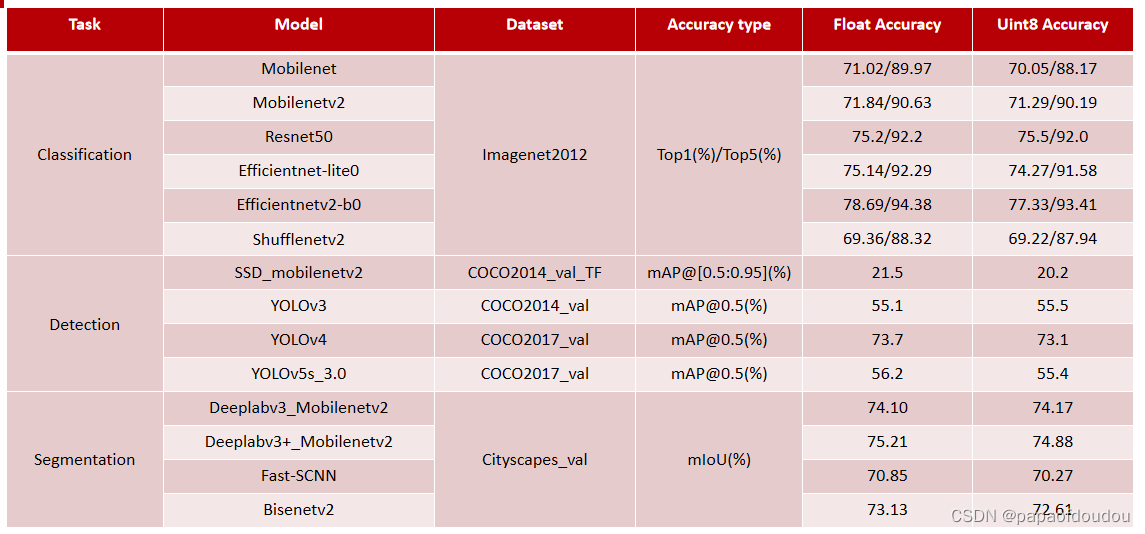
精度保持:

量化示意图:
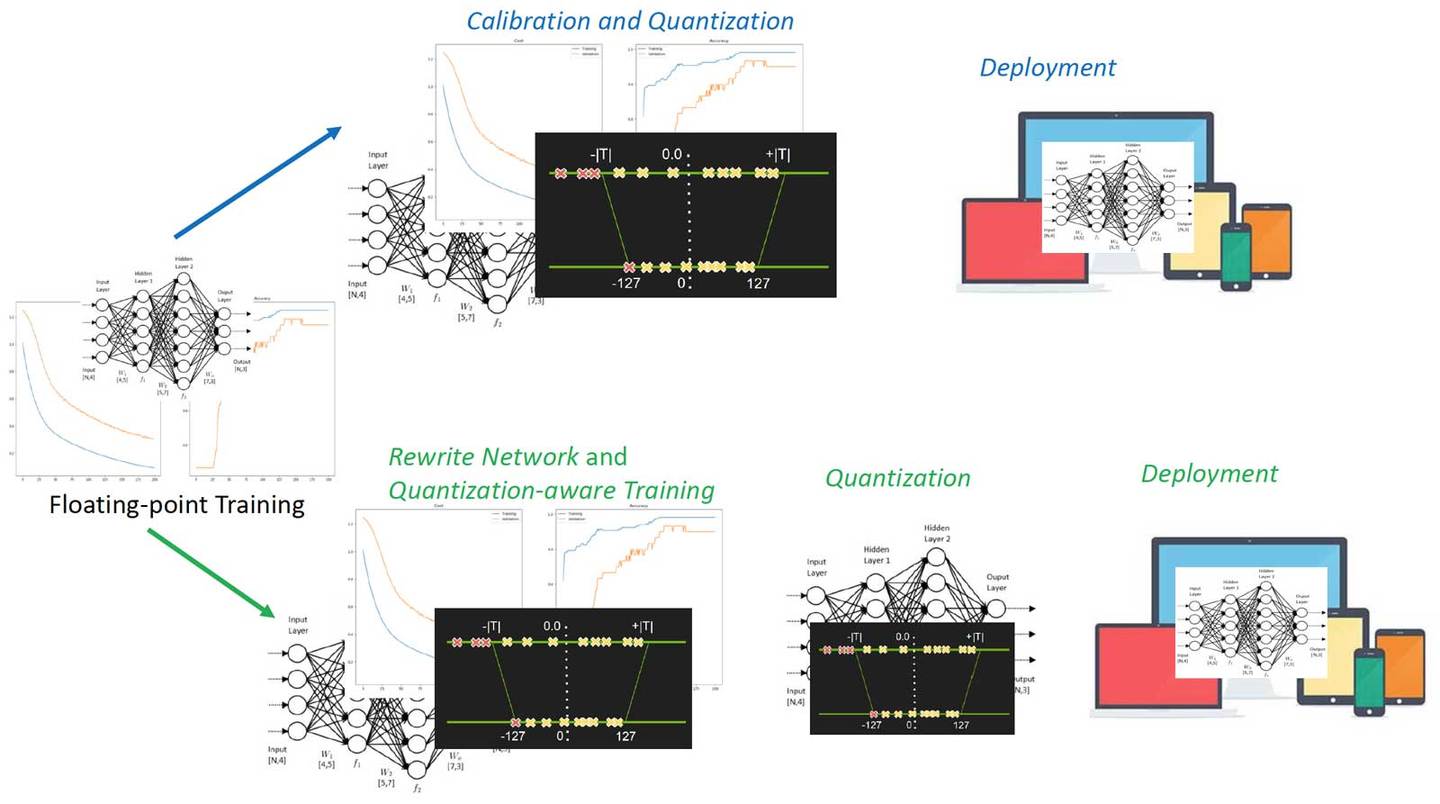
PTQ(post training quantilization)和QAT(quanlitization aware traing)区别:
BSD盲区检测系统

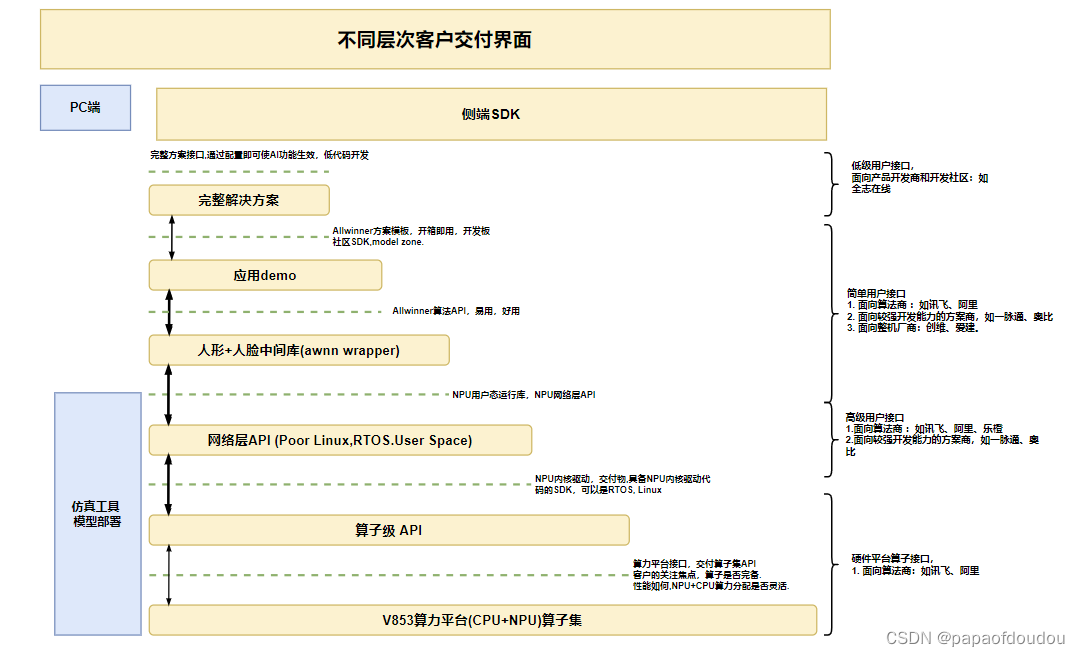
交付界面
汽车OEM是什么鬼?

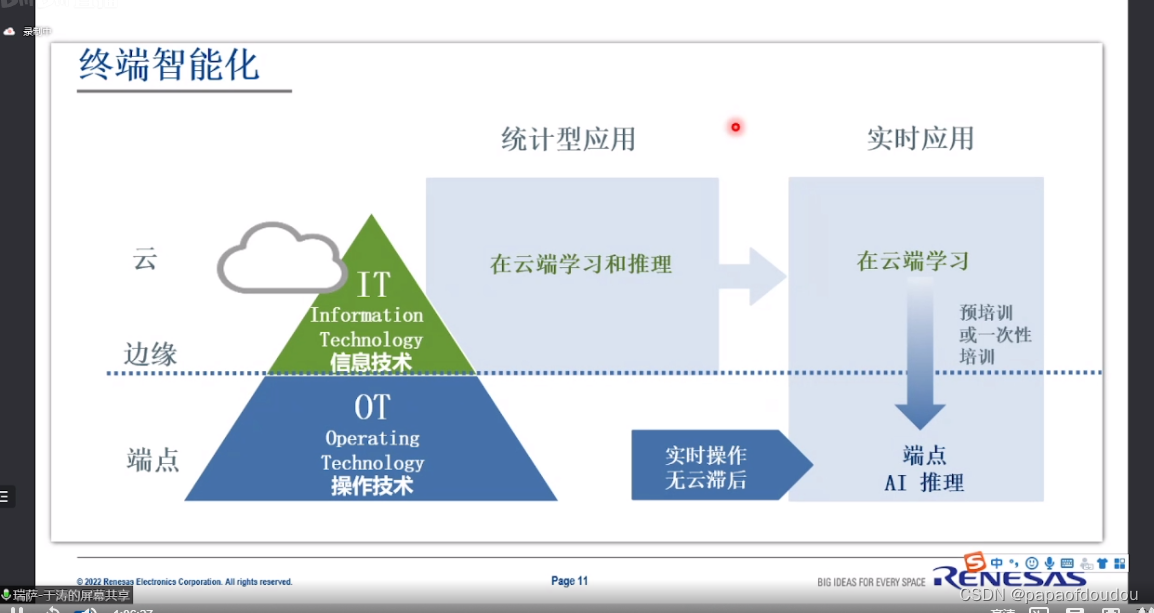
端侧和云端AI芯片的差异
由于端侧AI与云端AI芯片模式不一,云端更注重性能,终端则更注重成本和软硬一体化,更难落地,因而决定将端侧AI芯片业务拆分独立运作.
汽车体验的评价标准:
很细腻,自己想不到.


roofline模型:
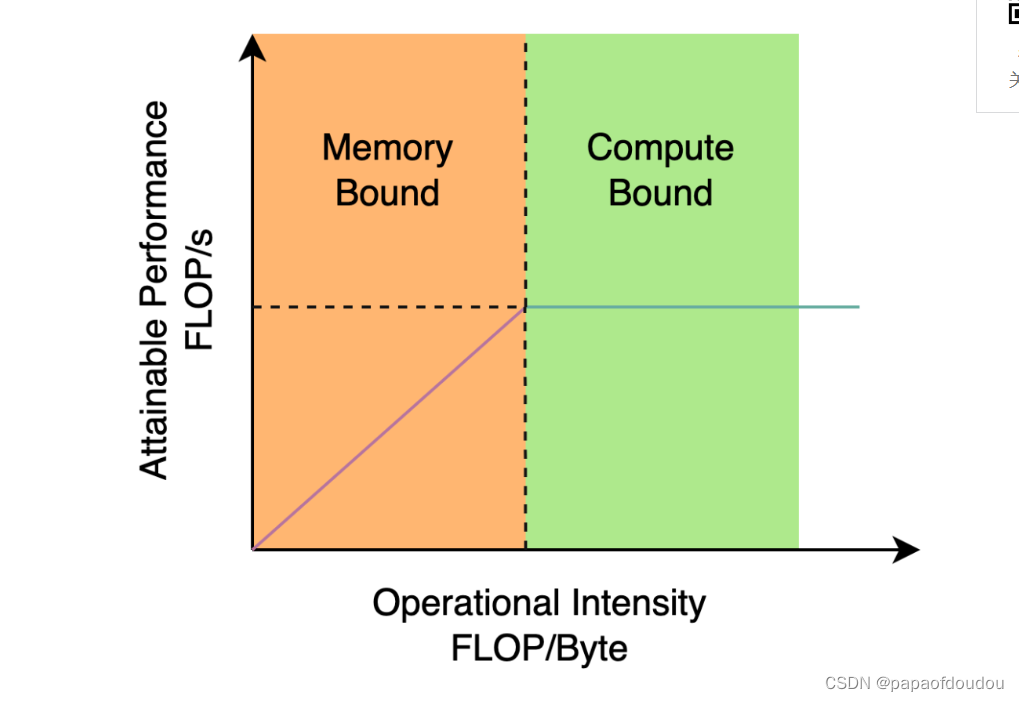
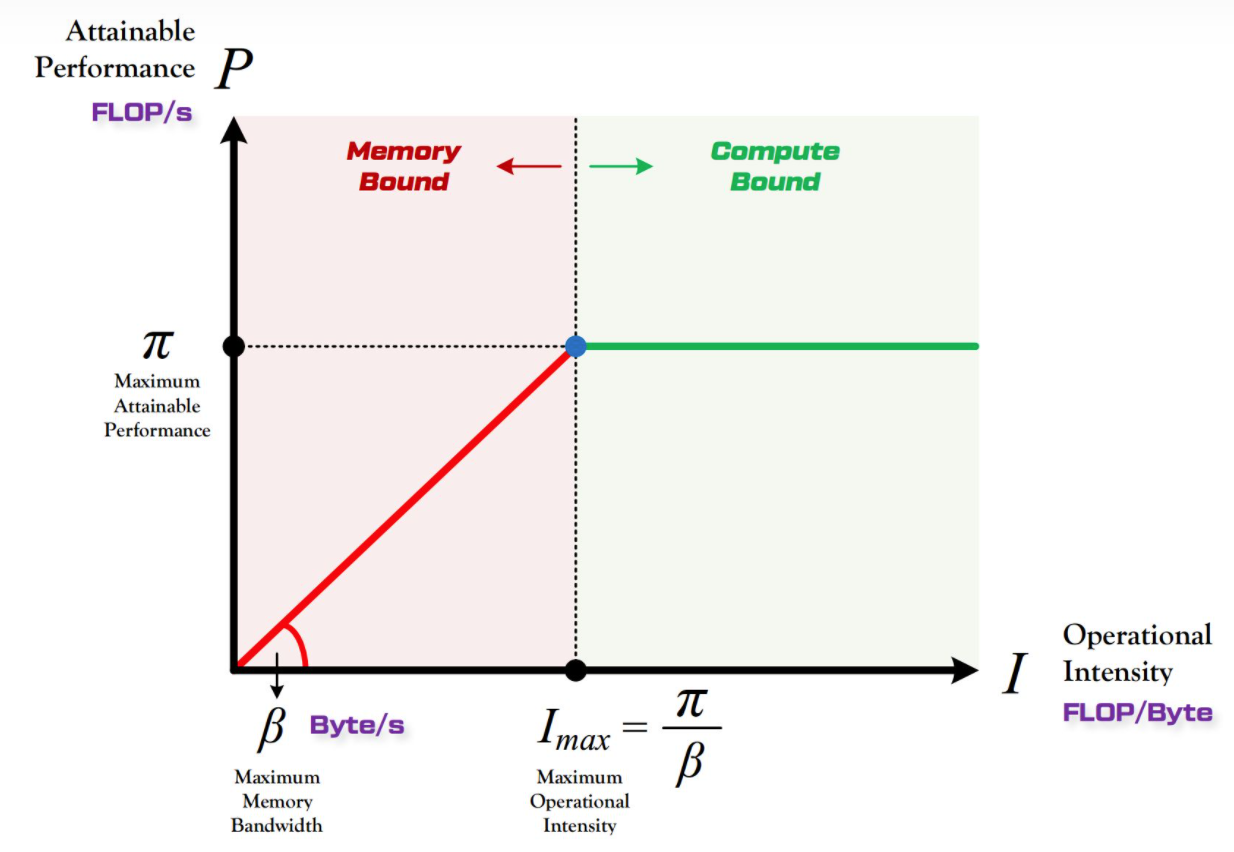
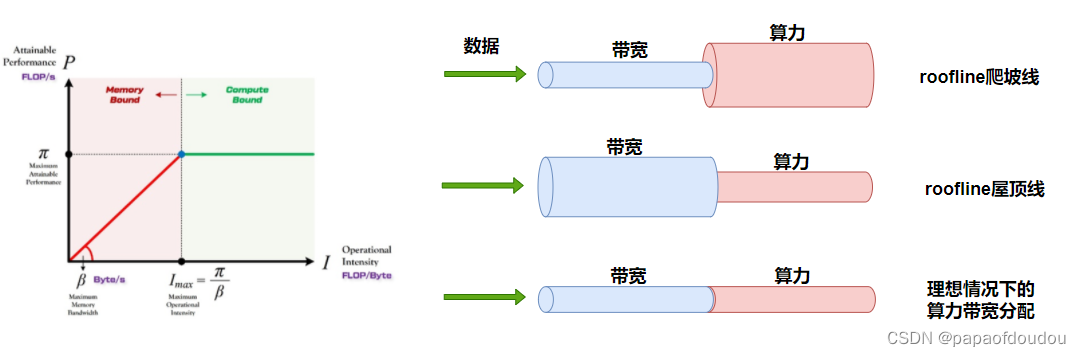
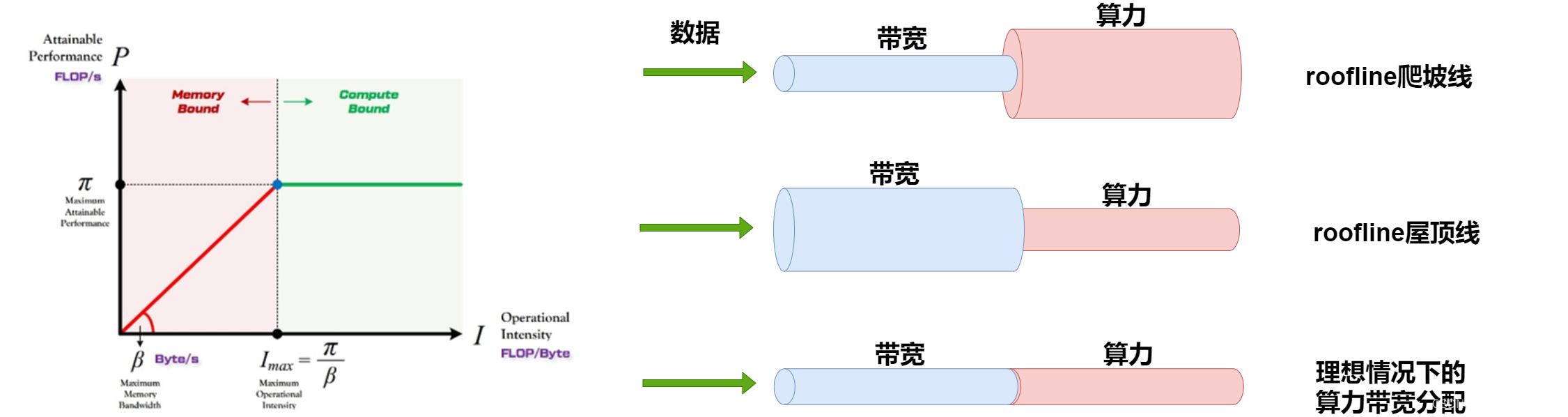
针对这种划分,我们大概可以将模型分为两类:
1.算力未发挥型的,对应爬坡图.
2.带宽未发挥型的,对应roof图.
3.在转折点处,既不浪费带宽,也不浪费算力,算是一个平衡,是不是纳什均衡?
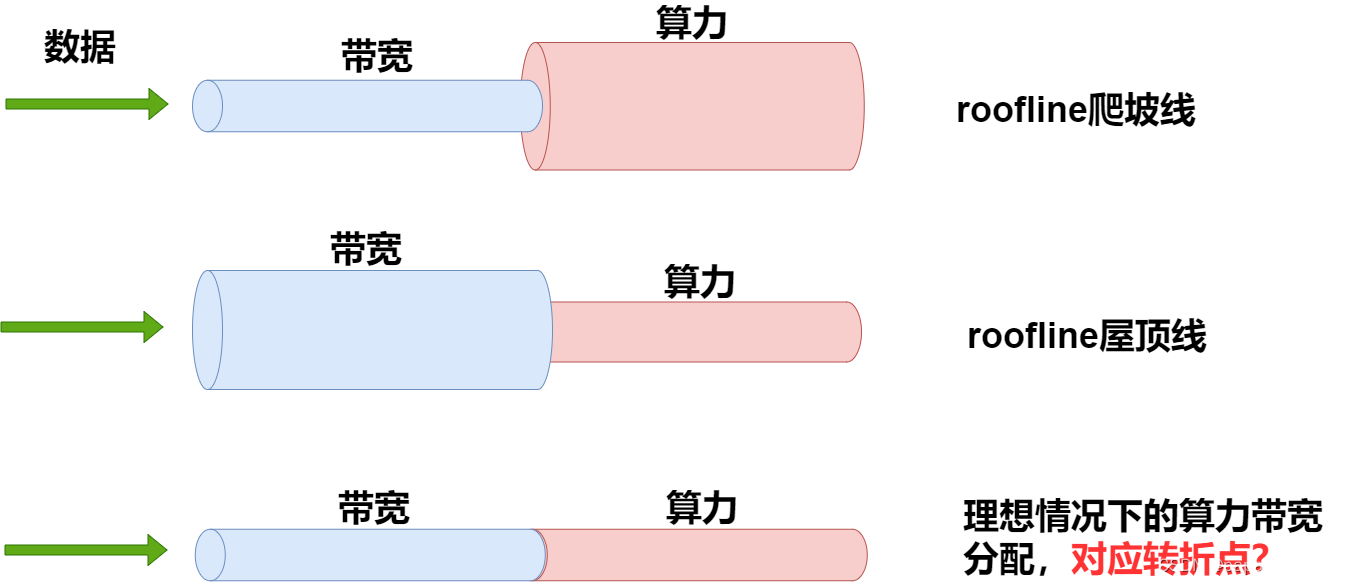

推理过程是撞大运么?
是的,推理是黑盒子,中间发生了什么没有人可以说清楚,状态空间太大了。
训练集,验证集和测试集有差异么?验证集和测试集会出现训练集没有的特征么?
训练集,验证集和测试集要遵守同样的分布,如果测试集出现明显特征偏差,是不合理的。


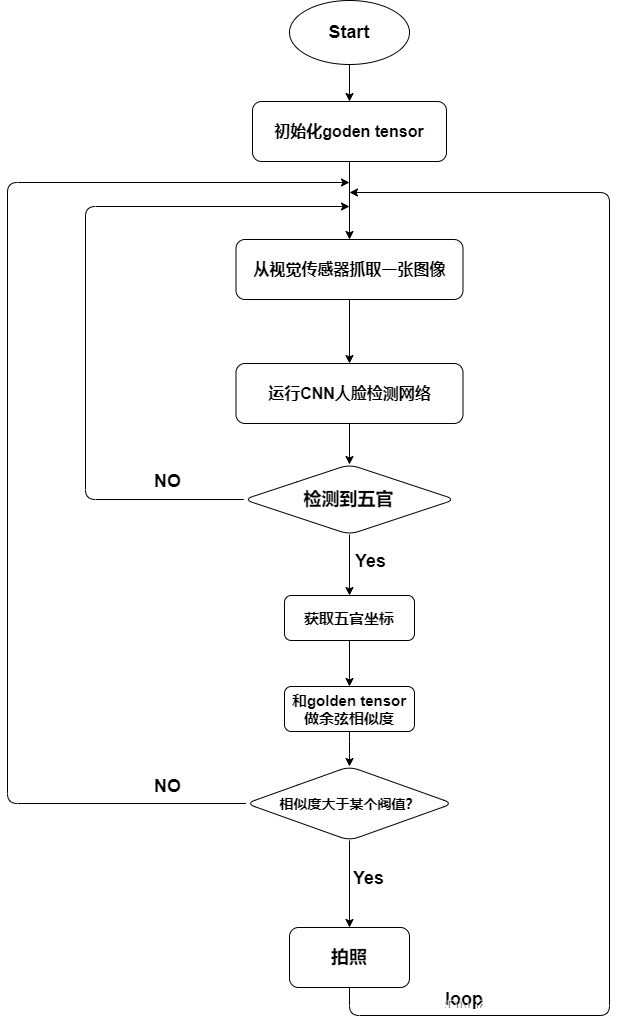
人脸检测模型:
中医和AI:
在AI训练集和结果中间发生的事情缺乏可解释性上,可以类比中医,如果把中医当作一个大的神经网络,它的训练及就是从古到今的病人,而网络的输出结果就是一个一个的药方,我们知道中医能治病,但是它的治病依据的是经验,而非科学结论,我们不知道中医重要治病的细节,就像不知道神经网络中间发生了什么一样。
语音类算法有哪些?
扫地机器人,智能汽车属于算法比较密集的产品.
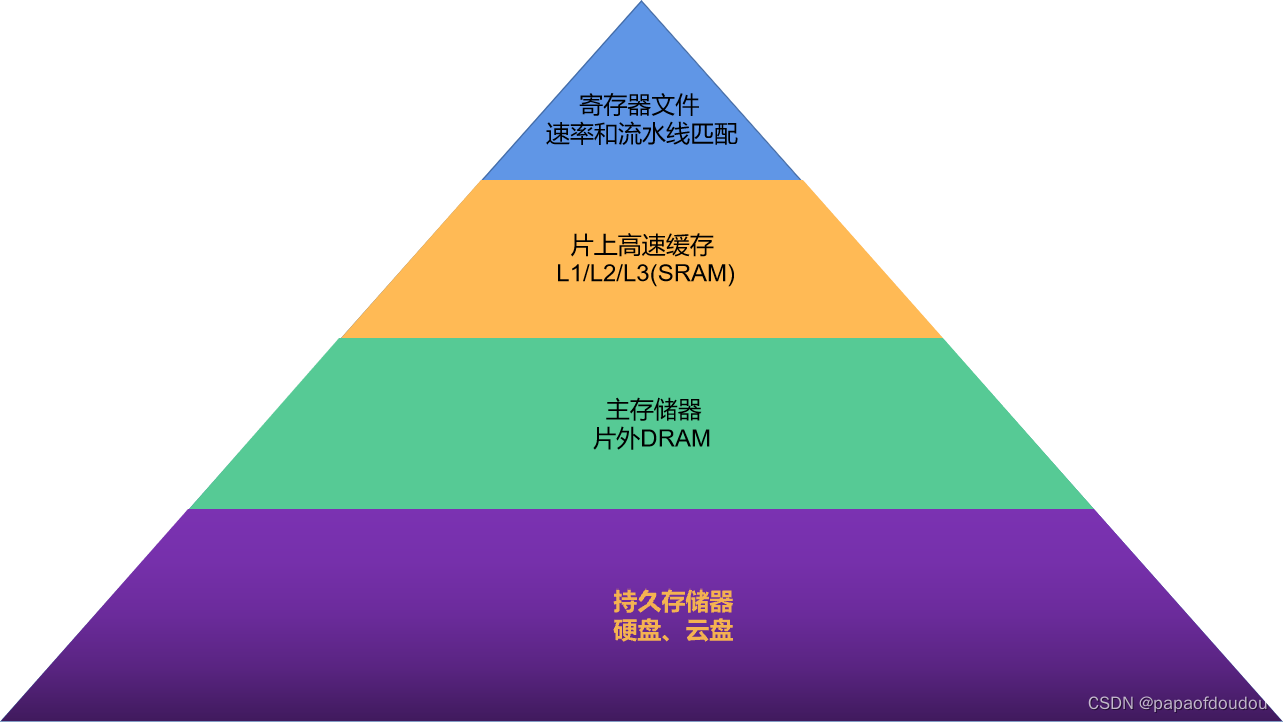
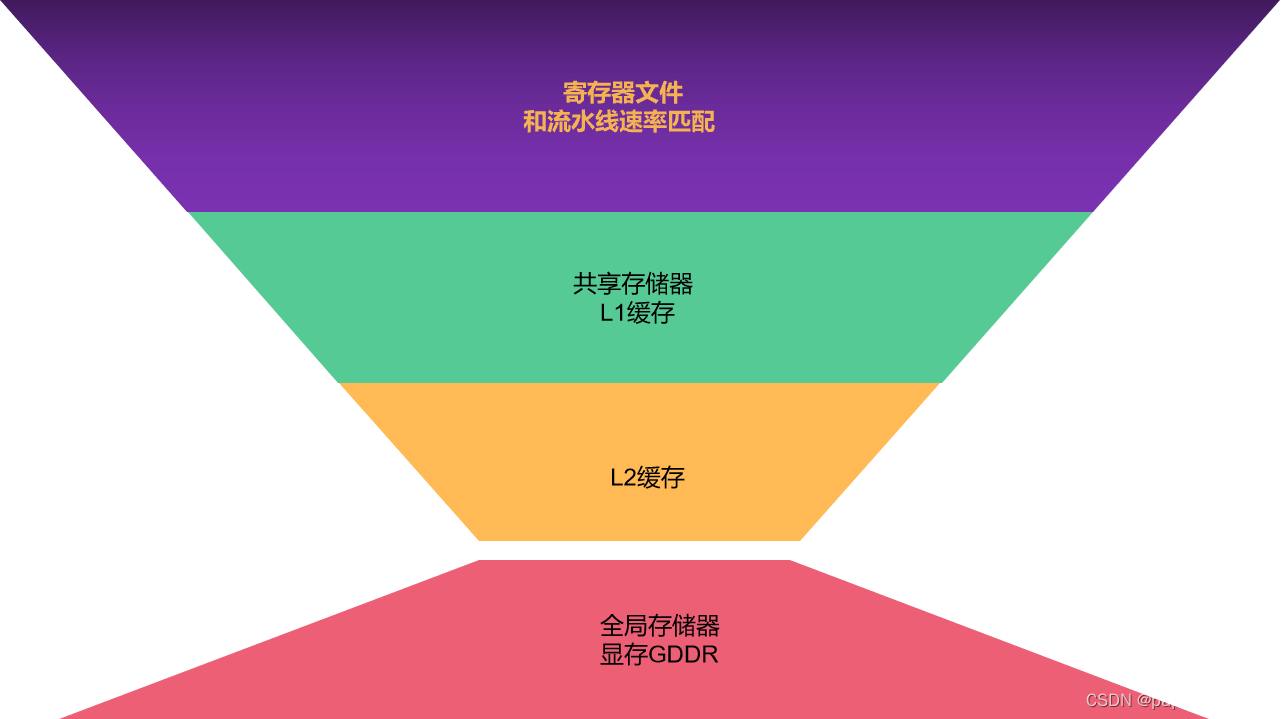
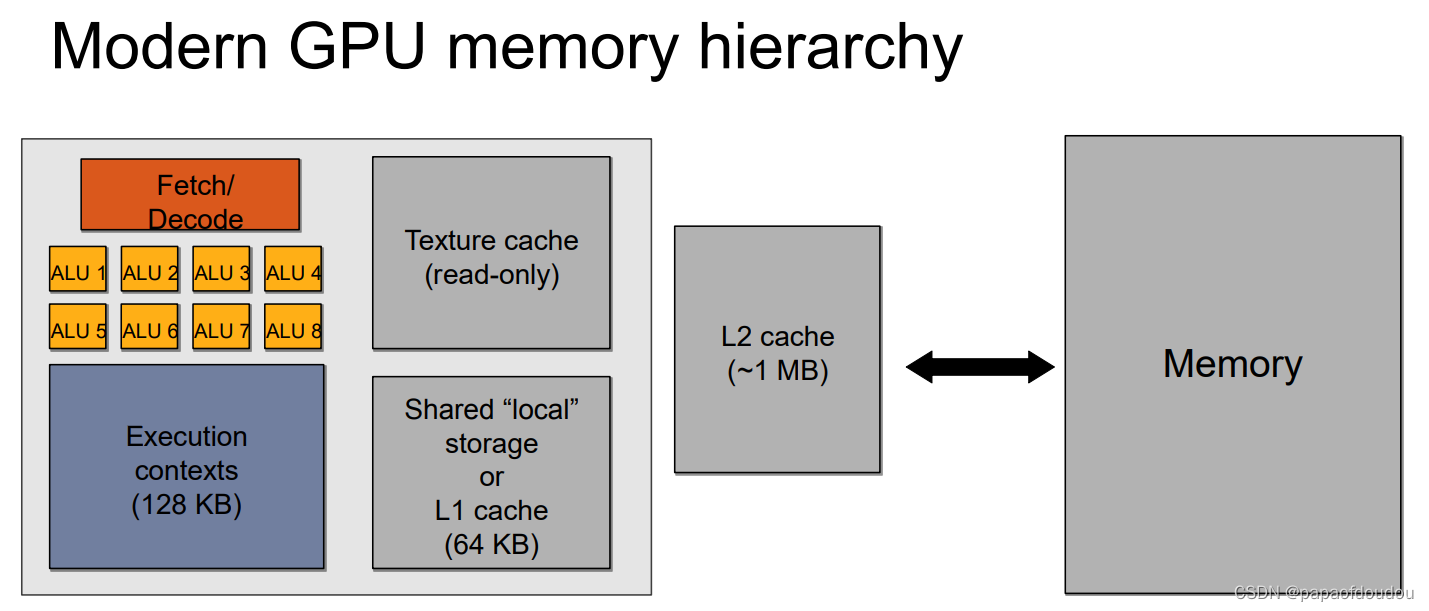
GPGPU存储金字塔和CPU存储金字塔区别
CPU存储金字塔:
GPGPU存储金字塔:
算子层API
晶视智能部署工具:
NPU&GPU&GPGPU



模型动态尺寸输入
模型动态尺寸的问题,从客户和芯原得到的信息总结如下:
- 动态尺寸输入模型需求主要应用于语音类的,包含transformer,lstm网络,语音具有流式输入的特征,比如你可以连续的讲1分钟,也可以只讲5秒钟,流式网络对输入要求比较灵活。视觉类的很少,因为视觉本身输入图像就是固定尺寸的。
- 根据明刚的说法,动态尺寸输入需要NPU和硬件都支持才行,当前的NPU和未来正在设计的NPU,都没有计划要支持流式变长尺寸的输入。它们也遇到过除了AW客户之外的针对此功能需求,但是都被VIP介绍的替代方案回绝了。
- 芯原的替代方案是,将变长输入网络切成固定尺寸网络,比如,对于一个滔滔不绝地讲者来说,可能选择固定数目的采样为一个分组,比如5S一个分组,调整网络支持此分组,为适应多中类型的长度,可以建立多种分组,比如5S,10S,20S各一个网络。这样做的劣势是:
- 浪费内存,对于单个网络来说,不满足输入尺寸的数据需要做padding填充到满足固定长度。
- 对于多个分组来讲,要生成多种支持不同输入尺寸的模型,重复占用内存。
- 不但有动态输入,还有动态输出,就是针对固定尺寸的输入,模型的输出长度不同,这种也多见于语音类网络,这种芯原的NPU更加无法处理,需要重新调整模型结构,支持固定尺寸输出。
当今世界AI领域的风云人物
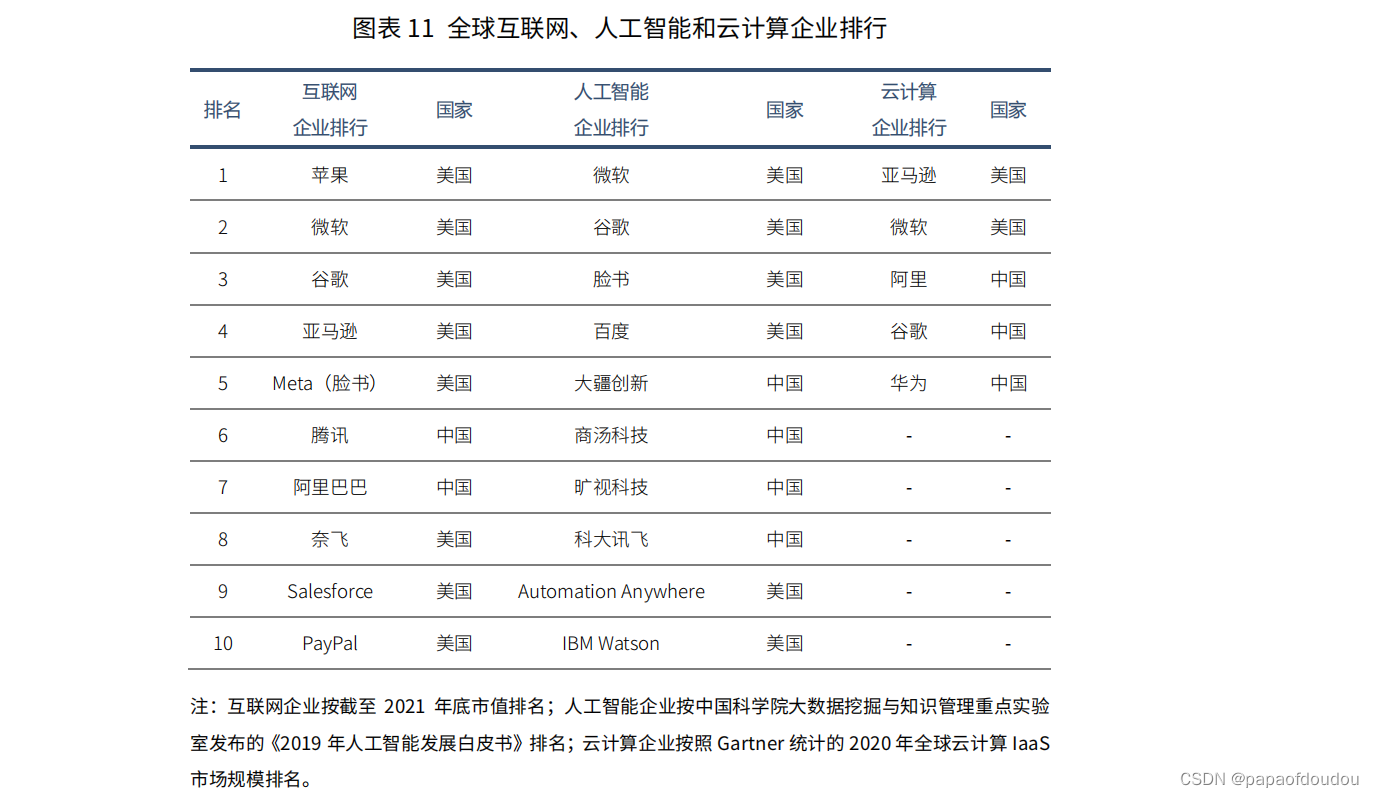
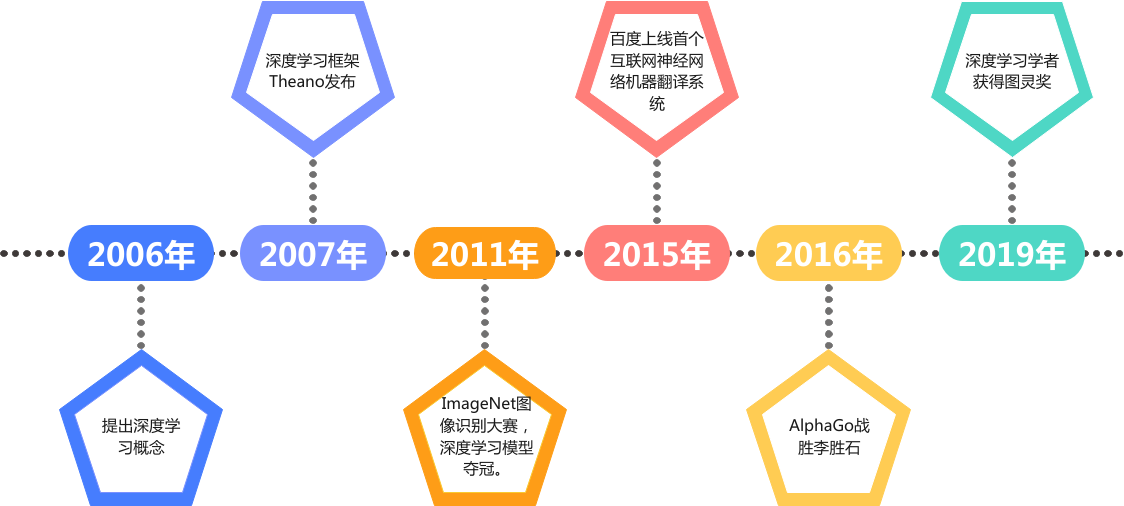
如前所述,当前人工智能繁荣离不开数据、算法和算力的共同发展,在算法层面,深度学习三巨头Geoffrey Hinton、Yann LeCun和Yoshua Bengio对AI领域的贡献无人不知、无人不晓,他们围绕神经网络重塑了AI;
数据层面,2007年李飞飞创建了世界上最大的图像识别数据库ImageNet,使人们认识到了数据对深度学习的重要性,也正是因为通过ImageNet识别大赛,才诞生了AlexNet, VggNet, GoogleNet, ResNet等经典的深度学习算法。
前几次人工智能繁荣后又陷入低谷,一个核心的原因就是算力难以支撑复杂的算法,而简单的算法效果又不佳。黄仁勋创办的NVIDIA公司推出的GPU,很好的缓解了深度学习算法的训练瓶颈,释放了人工智能的全新潜力。

金融思考,现在没有地方放,先放这里吧
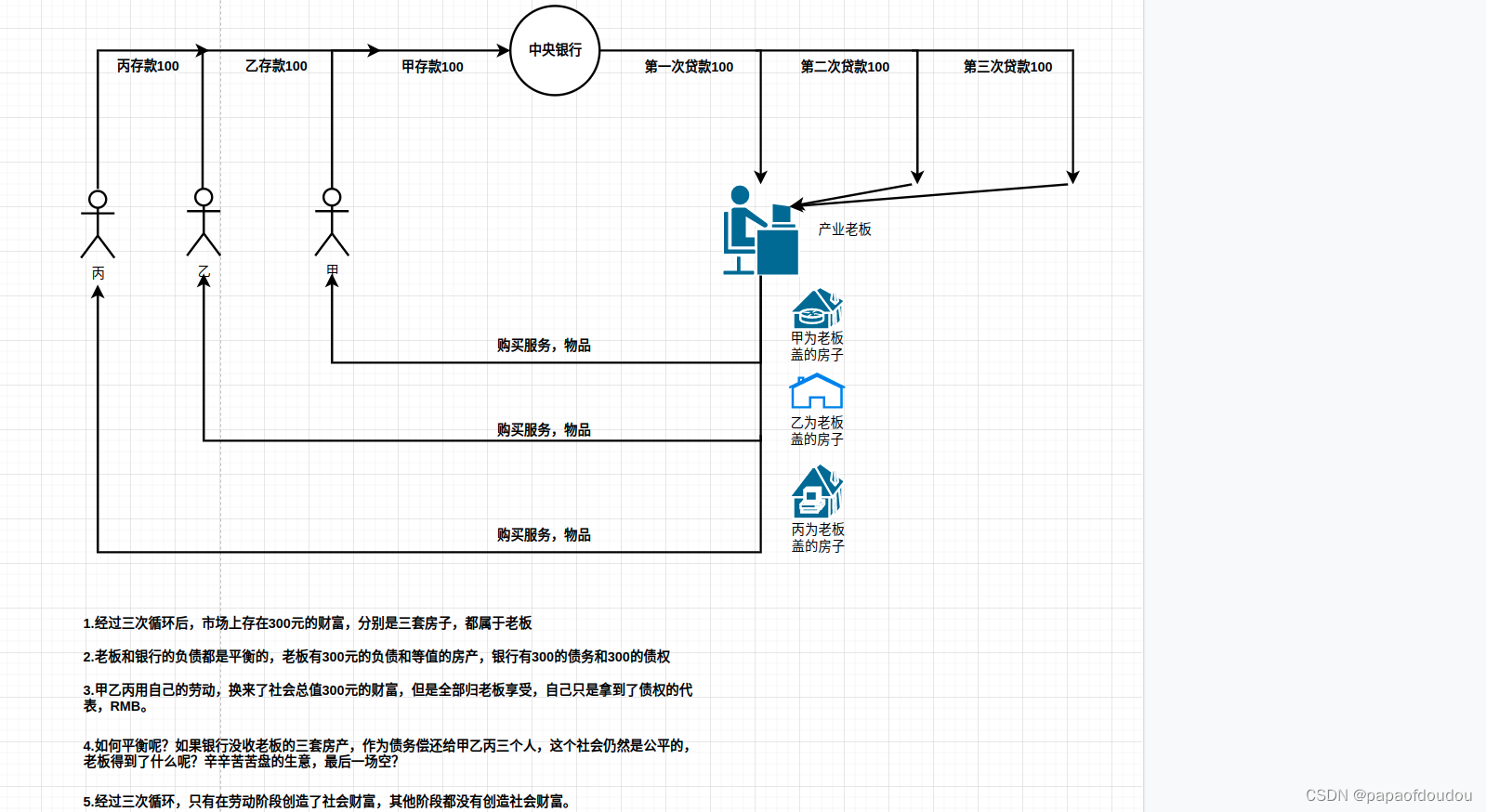
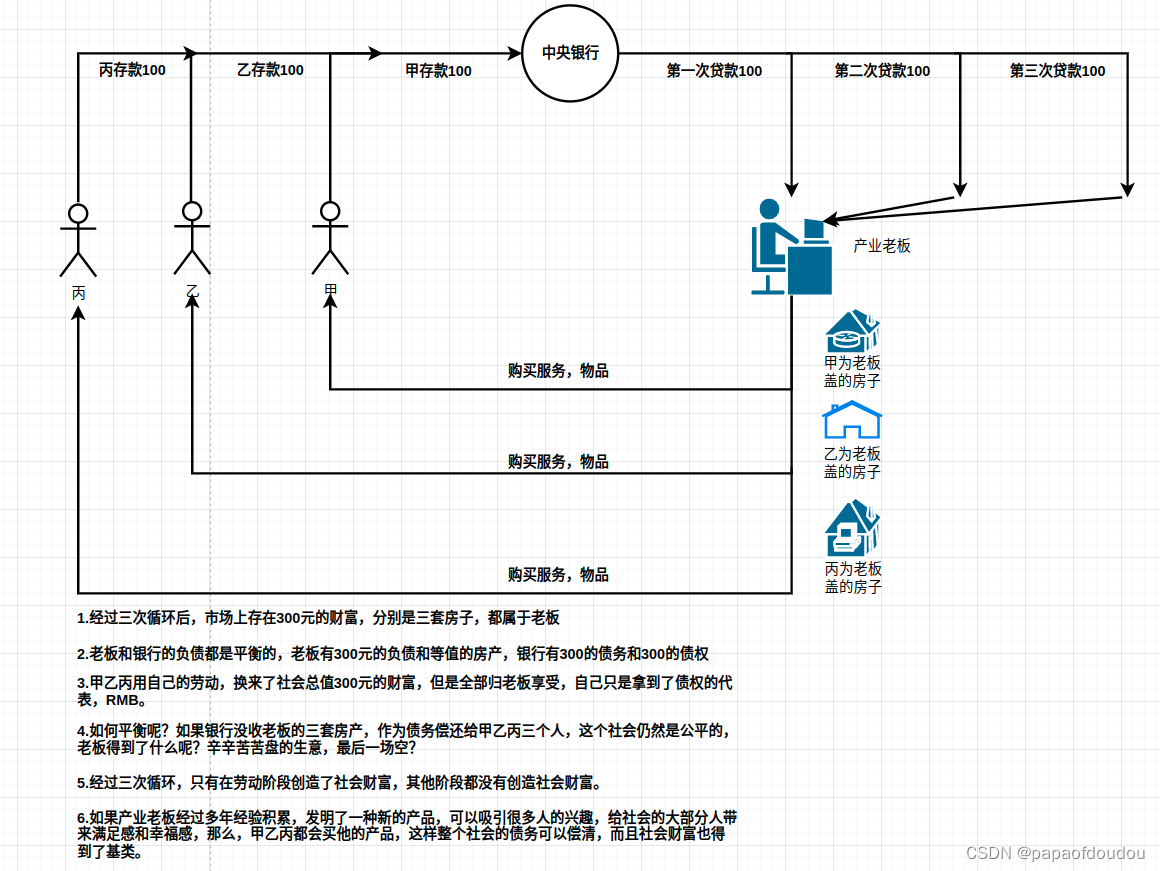
关于VIP的工具中权重的量化规则?
权重量化不需要dataset目录中的数据,因为权重已经确定了,分布是固定的,任何输入数据,任何场景下都不变,与之相反,每层的feature map tensor输出分布是和输入相关的,输入不同,数据都不同,所以依赖于真是场景中的图像数据来计算其分布规律,找到合适的FP和SCALE。
PPU支持浮点处理马?
PPU就是GPU的SHADER单元,GPU本身的强项就是做浮点处理,所以PPU也支持浮点处理。

VIP的API使用方式: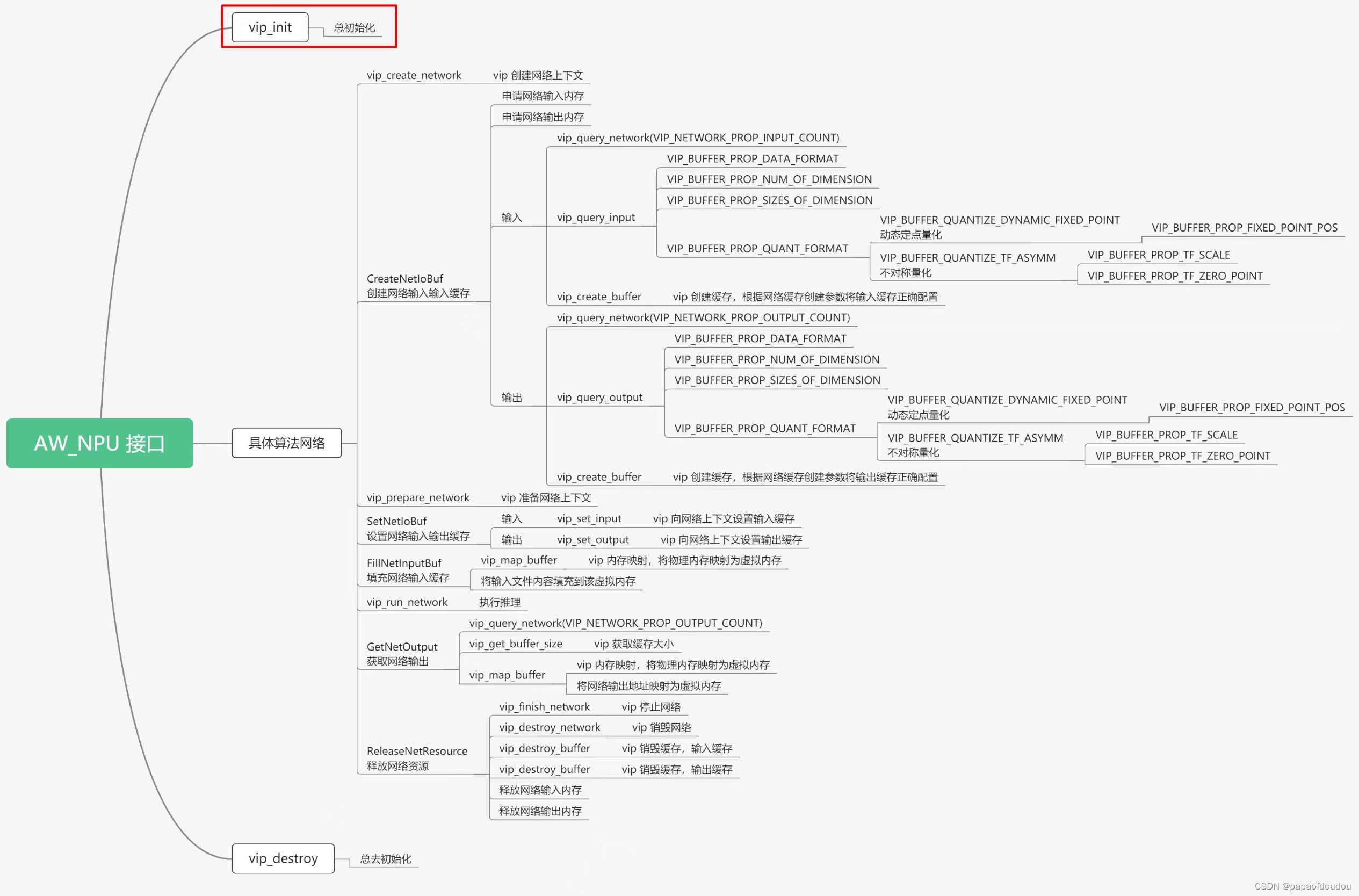

PID控制器
import matplotlib.pyplot as plt
class Pid():
def __init__(self, exp_val, kp, ki, kd):
self.KP = kp
self.KI = ki
self.KD = kd
self.exp_val = exp_val
self.now_val = 0
self.sum_err = 0
self.now_err = 0
self.last_err = 0
def cmd_pid(self):
self.last_err = self.now_err
self.now_err = self.exp_val - self.now_val
self.sum_err += self.now_err
# 这一块是严格按照公式来写的
self.now_val = self.KP * (self.exp_val - self.now_val) \
+ self.KI * self.sum_err + self.KD * (self.now_err - self.last_err)
return self.now_val
pid_val = []
#对pid进行初始化,目标值是1000 ,p=0.1 ,i=0.15, d=0.1
my_Pid = Pid(2000, 0.1, 0.15, 0.1)
# 然后循环100次把数存进数组中去
for i in range(0, 100):
pid_val.append(my_Pid.cmd_pid())
plt.plot(pid_val)
plt.show()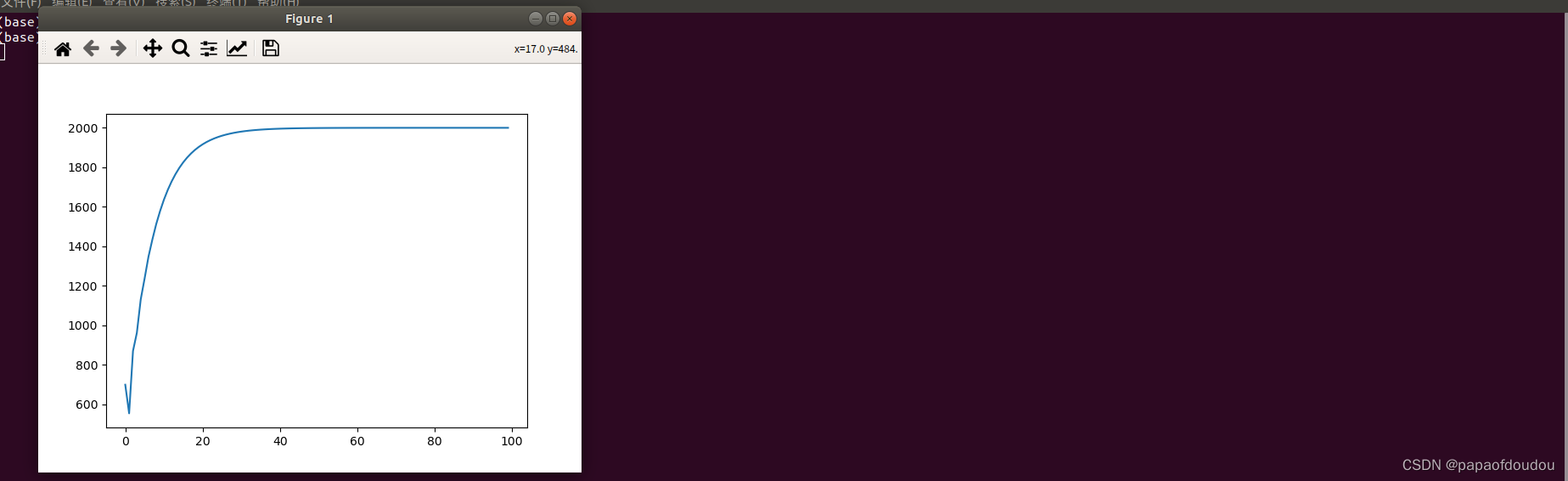
CPU和GPU能融合吗?
AI的三大应用领域,视觉,语音以及AI像素。

该怎么比喻芯片研发?
就像建造一座大楼,需要设计院,施工方(工程师)以及物业管理三方合作,才能建设好一座大楼,并投入运营。这里面设计院承担的就是芯片架构师的角色,施工方则代表硬件工程师,而软件年工程师承担的就是物业管理的角色。
开发一颗大芯片(GPU)需要考虑那些因素:
BR100/BR104
chiplet封装
芯片架构








GPU分类:
GPU分为渲染(图形)GPU和GPGPU,基本上,GPGPU可以作的,渲染GPU都可以作,但是渲染GPU能够作的GPGPU不一定能做,所以可以认为GPGPU是基类,而渲染GPU则是子类。在研究细一点,渲染GPU作GPGPU的事情不一定效率高,原因是渲染GPU的运算单元面向的是渲染PIPELINE,而并非是通用计算,另外,渲染GPU的运算单元的数量可能没有专用GPGPU的多,原因也是因为,他是为了渲染一个目的设计的。

IP VENDOR:
开放指令集标准
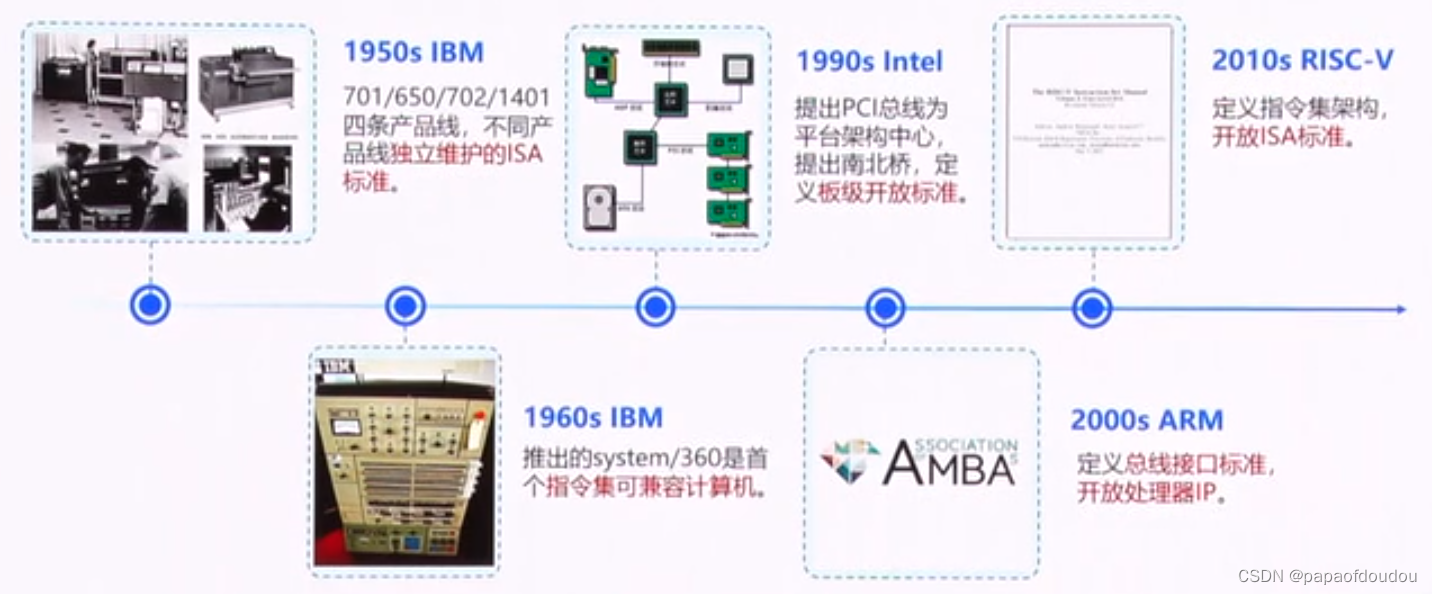
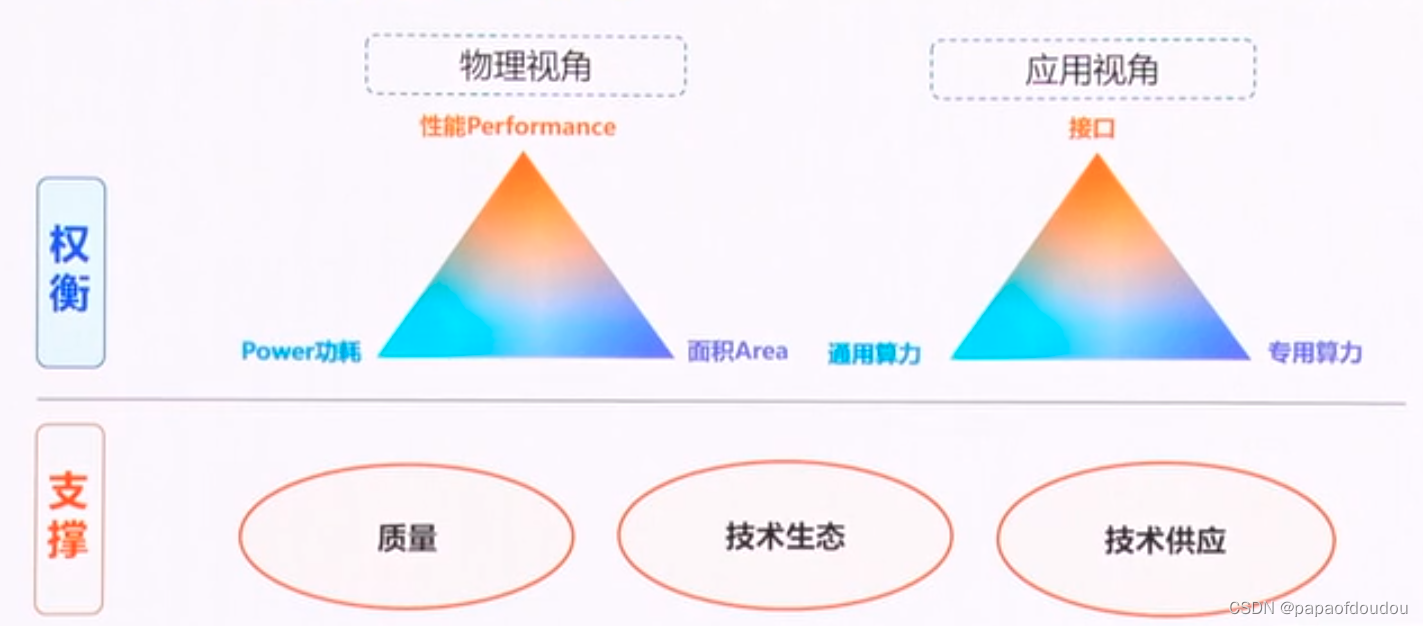

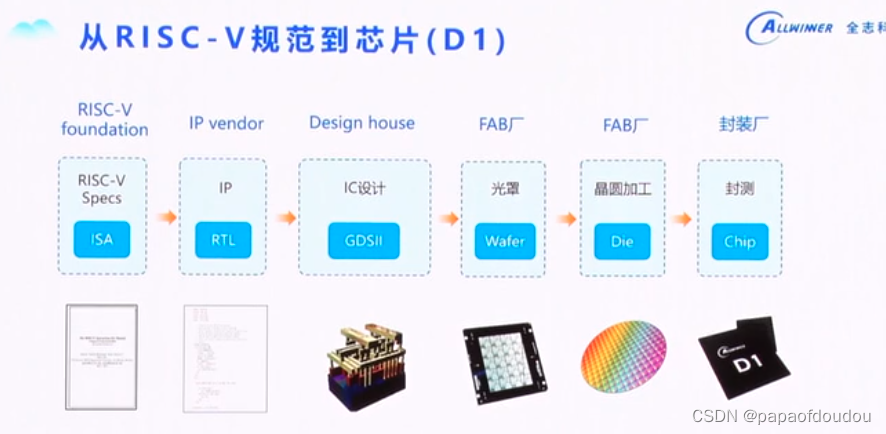
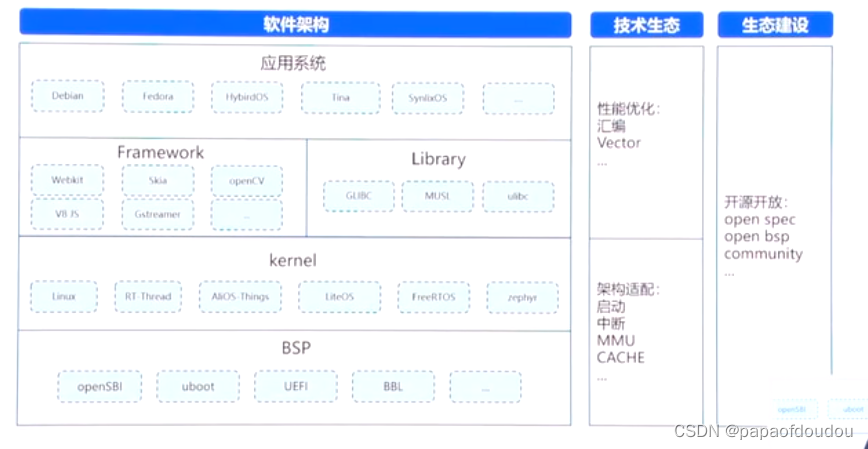
瀚海半导体:

暗硅效应:
举个例子,一栋大楼里面每个房间都有照明大灯,但是由于功耗的限制,不可能同时打开所有的照明灯。

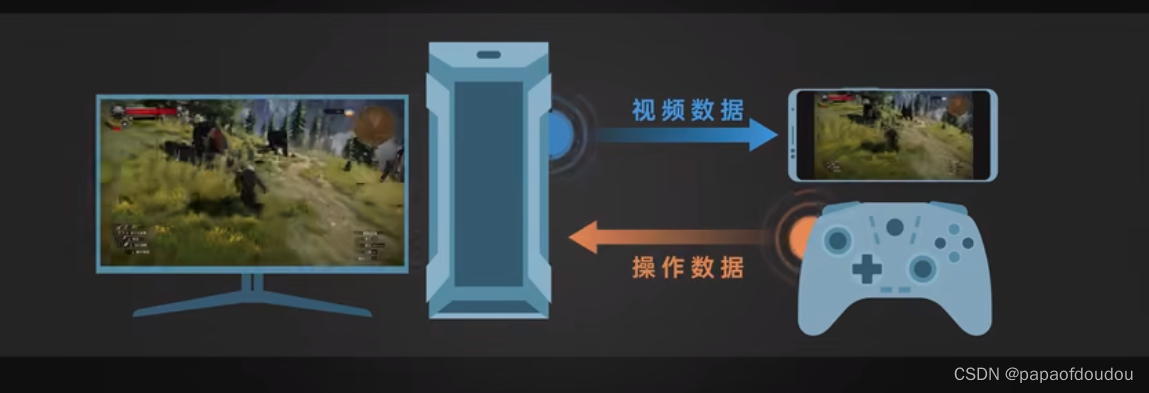
GPU远程游戏串流
用你的电脑跑游戏程序,然后把游戏画面压缩成视频流数据传输到其他的设备,在把其他设备的控制信息,例如手柄,键鼠等信息回传给你的电脑。这样你就可以在其他的设备上玩儿你电脑的游戏了。
GPU VS CPU

GPU工作模型
深度学习发展过程:

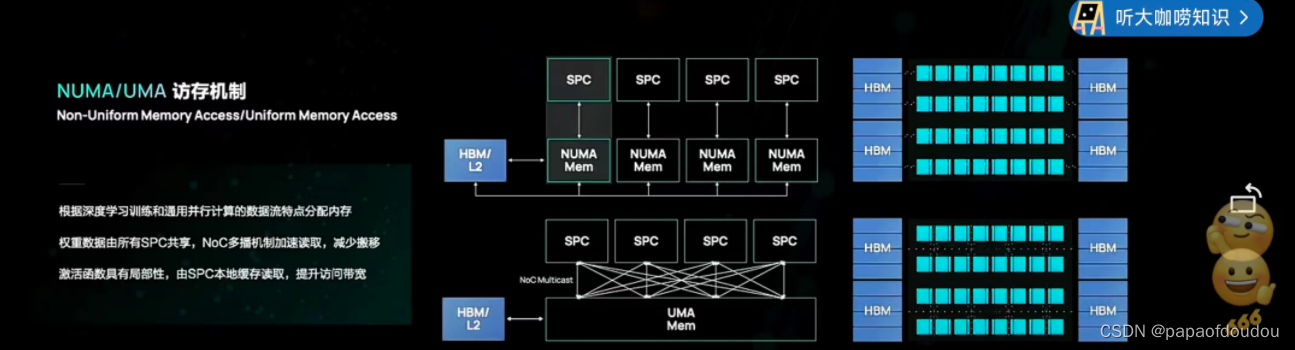
GPGPU结构
GPU 系统地址映射
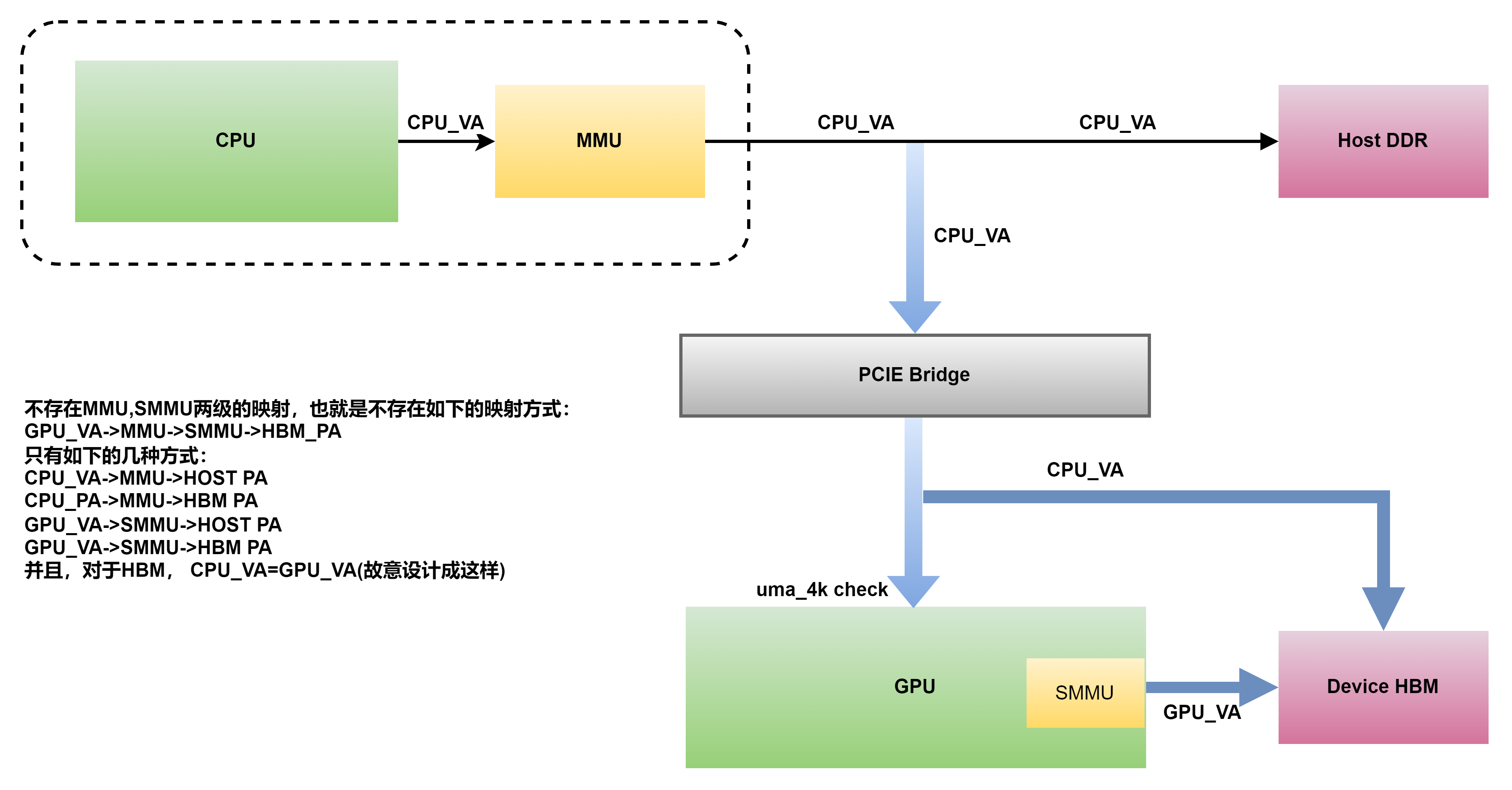
修正:
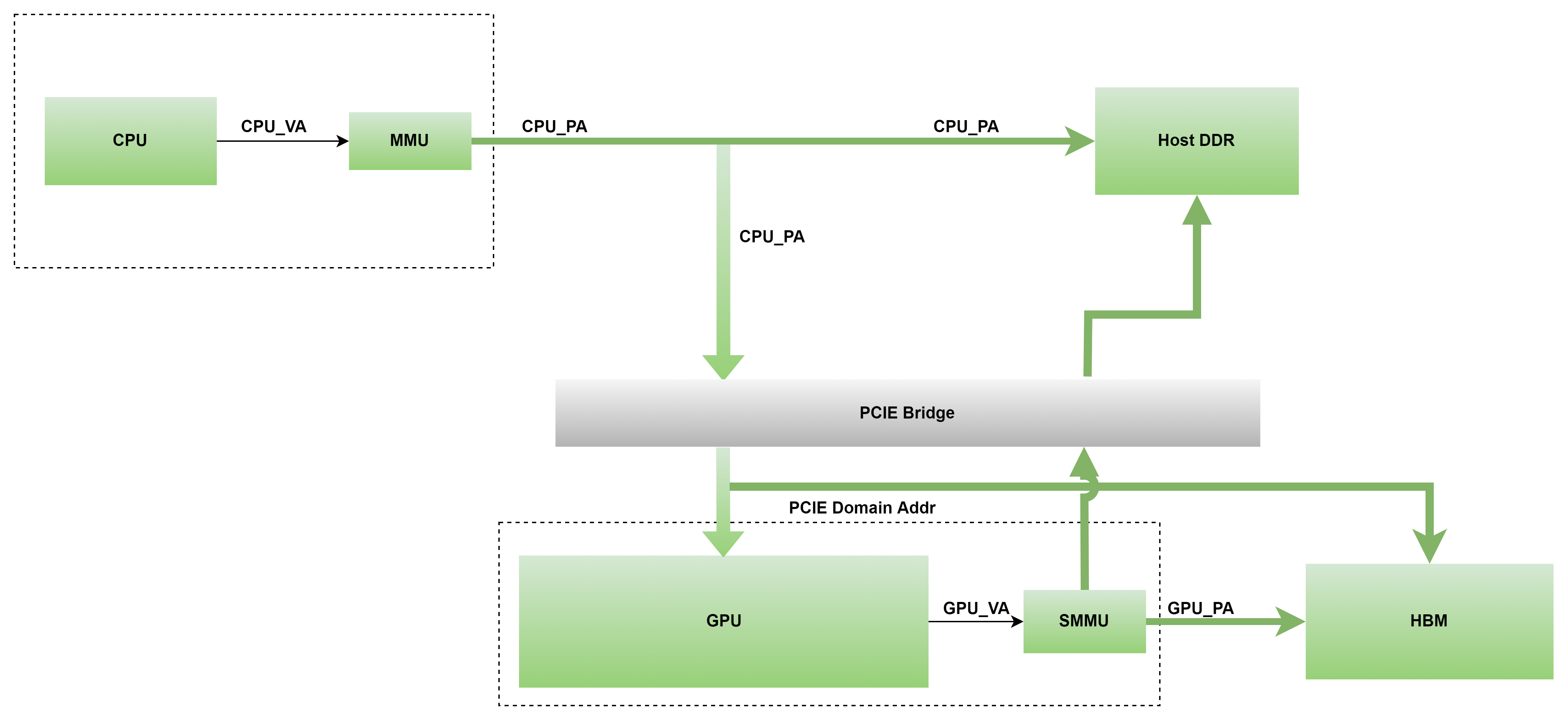
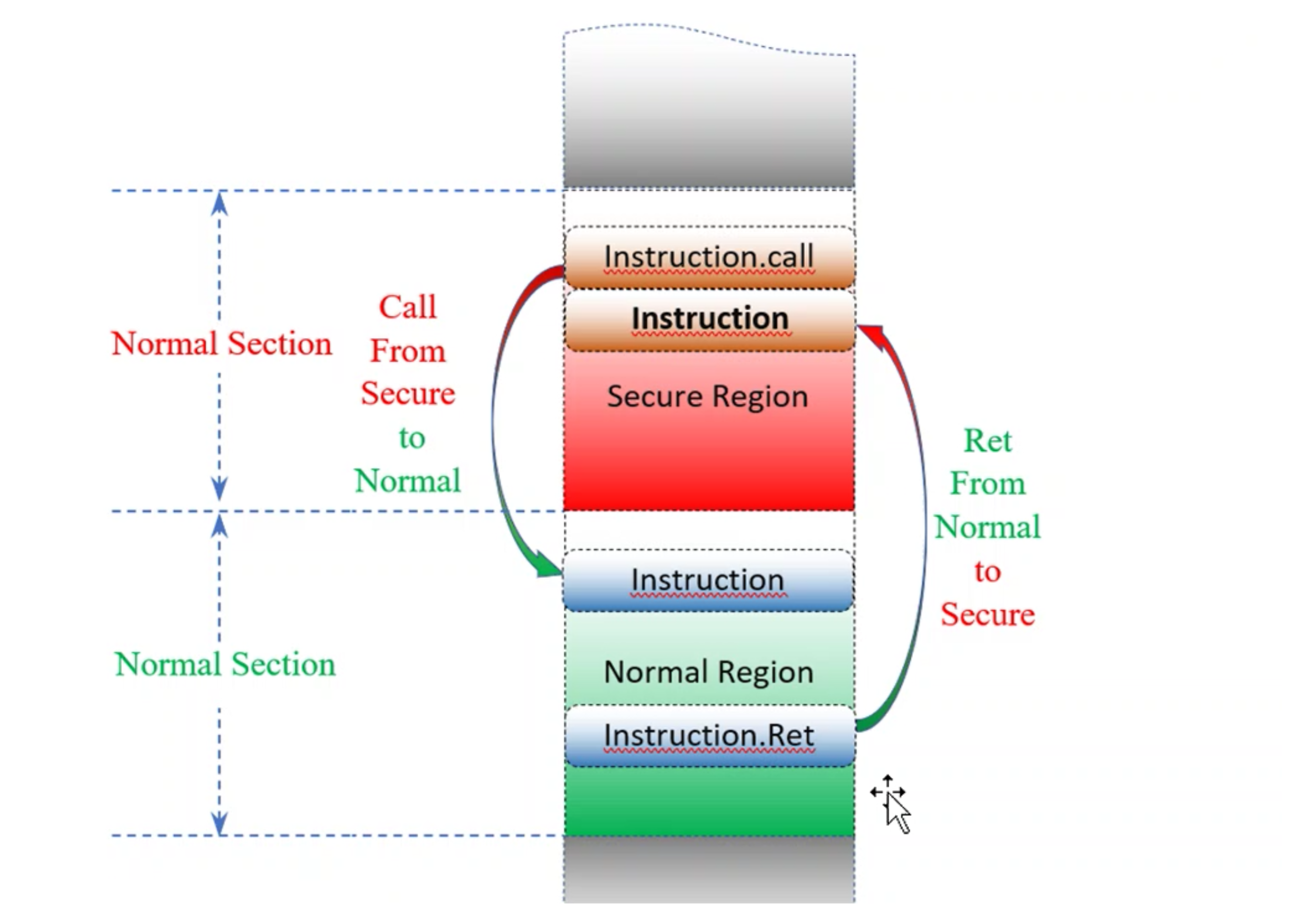
STACK:
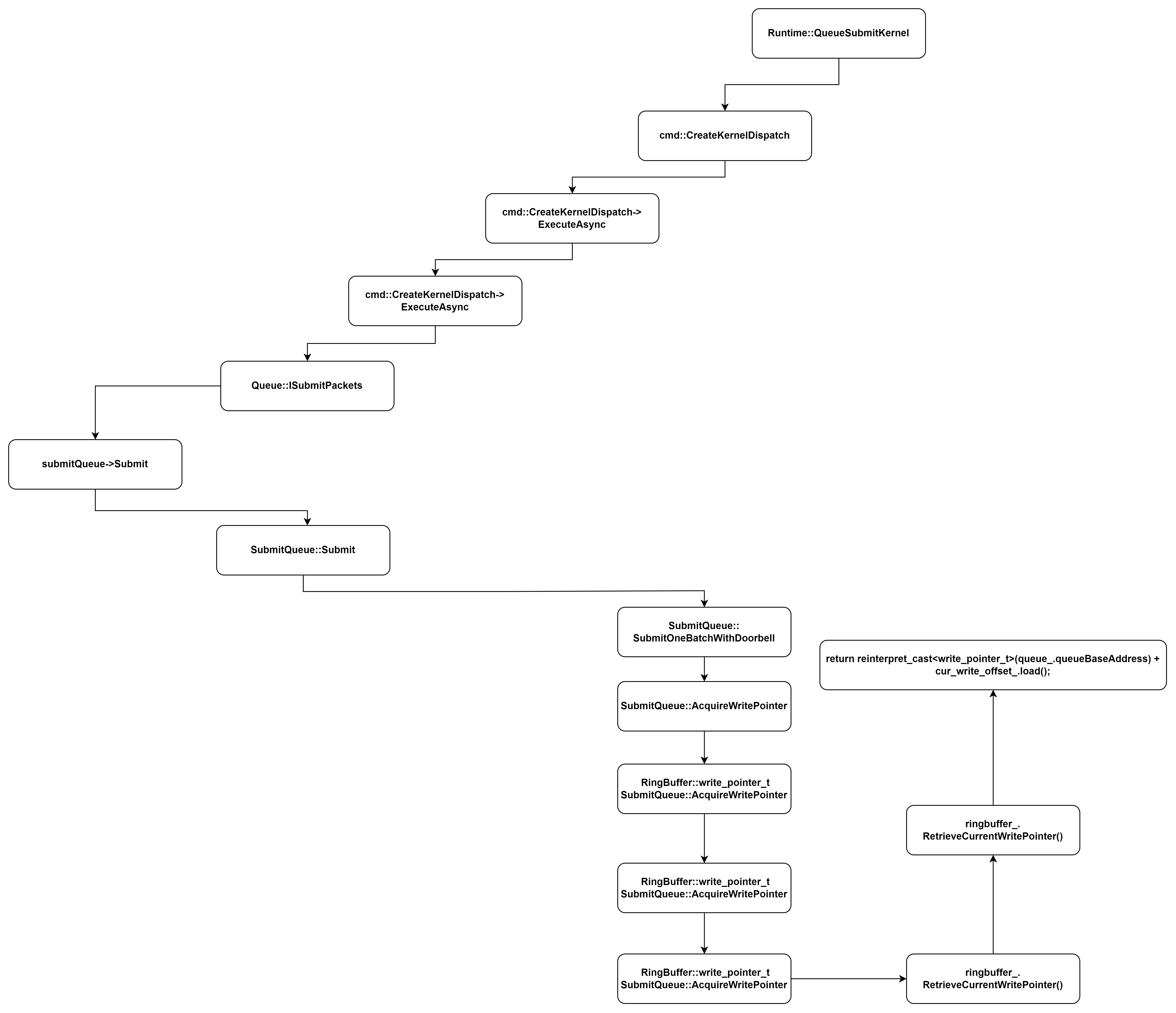
GPU DOORBELL 发送逻辑
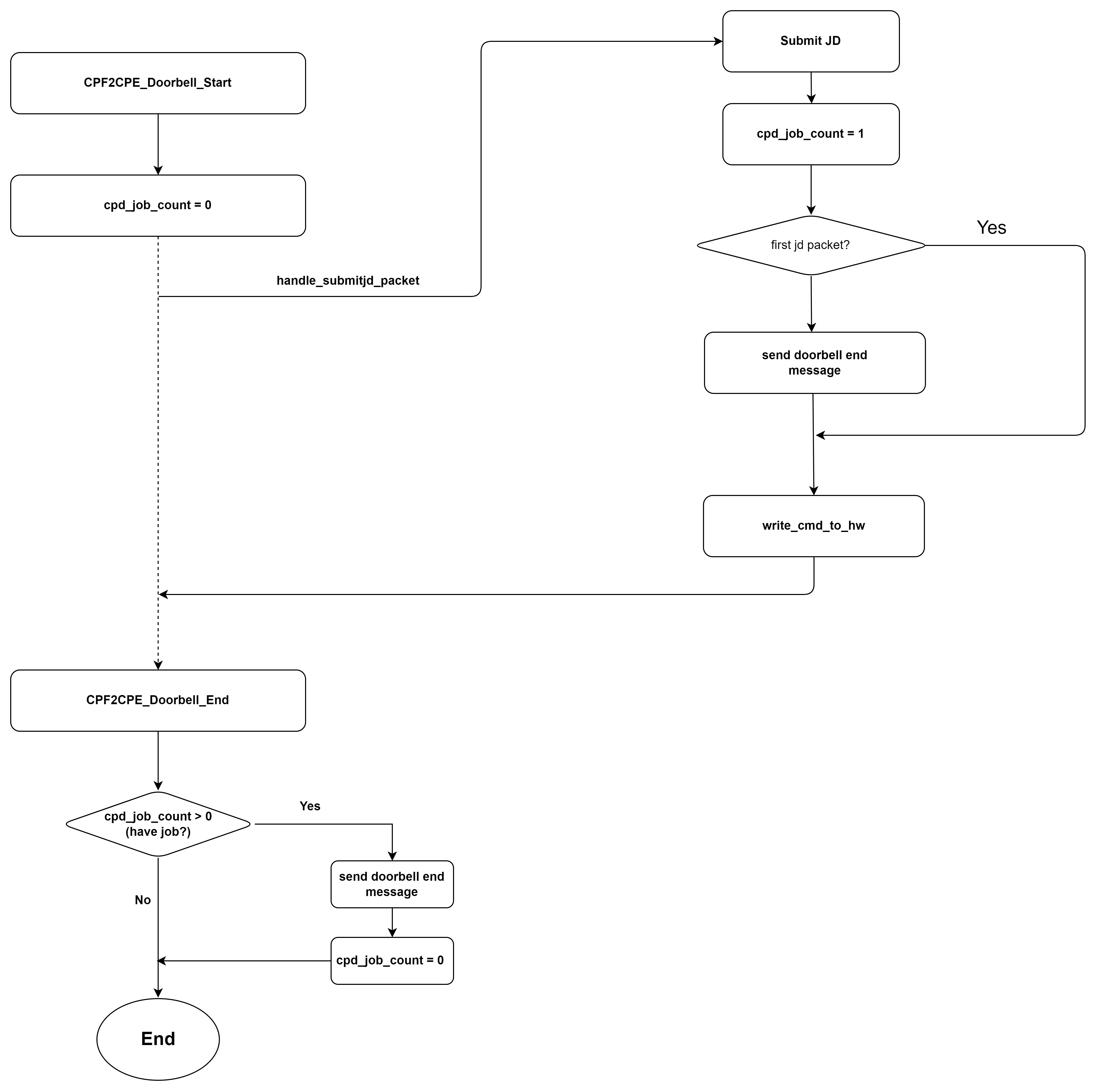
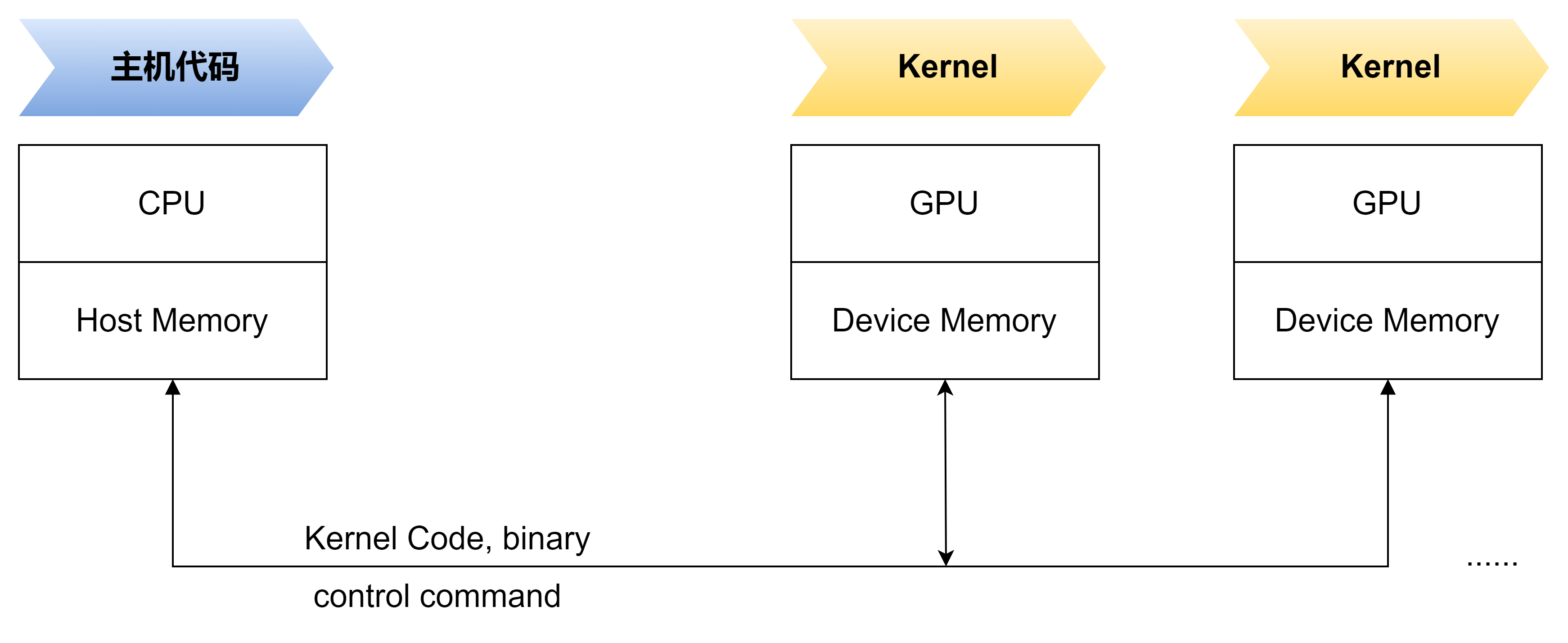
GPU HOST 和 Device 工作模型
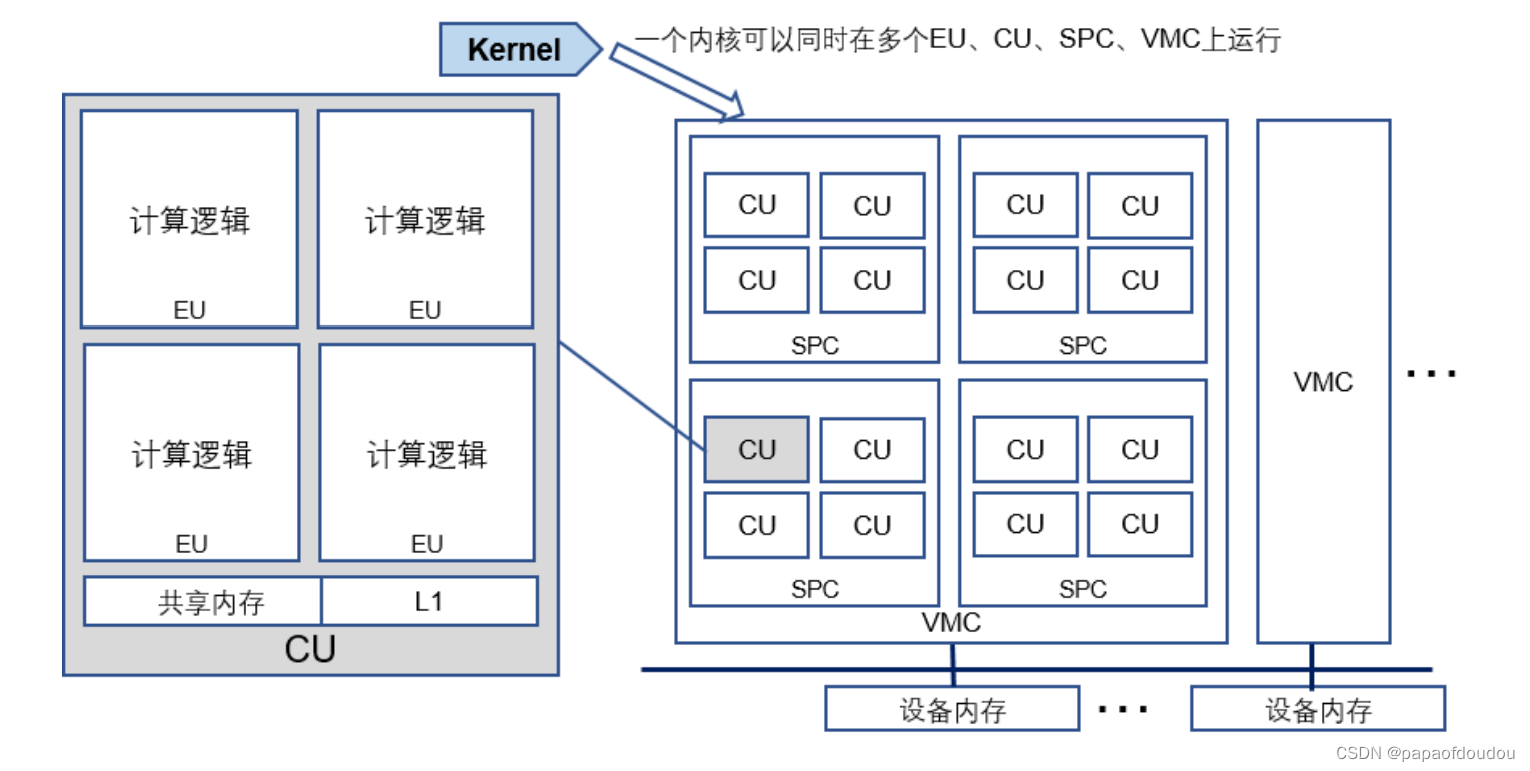
VMC:虚拟计算核簇
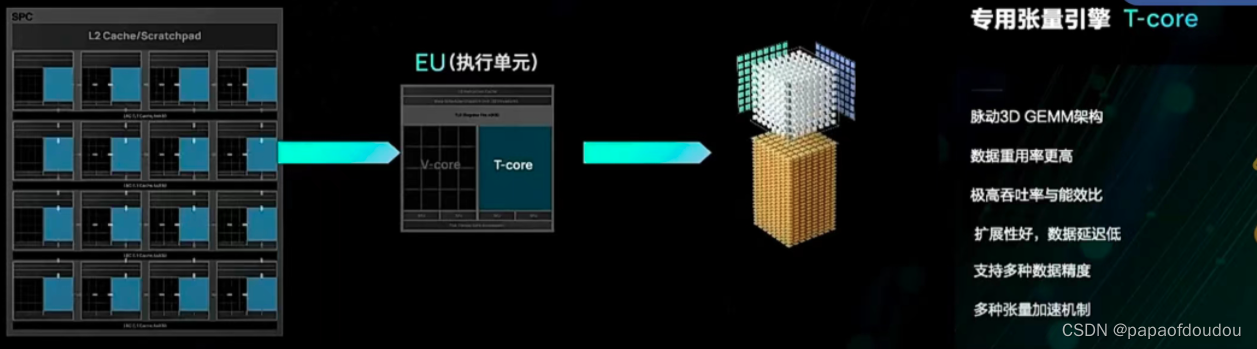
SPC: 流式处理器簇
CU:计算单元
EU:执行单元
核函数可以在多个执行单元、计算单元、流式处理器簇、虚拟计算核簇甚至多个设备 上同时运行
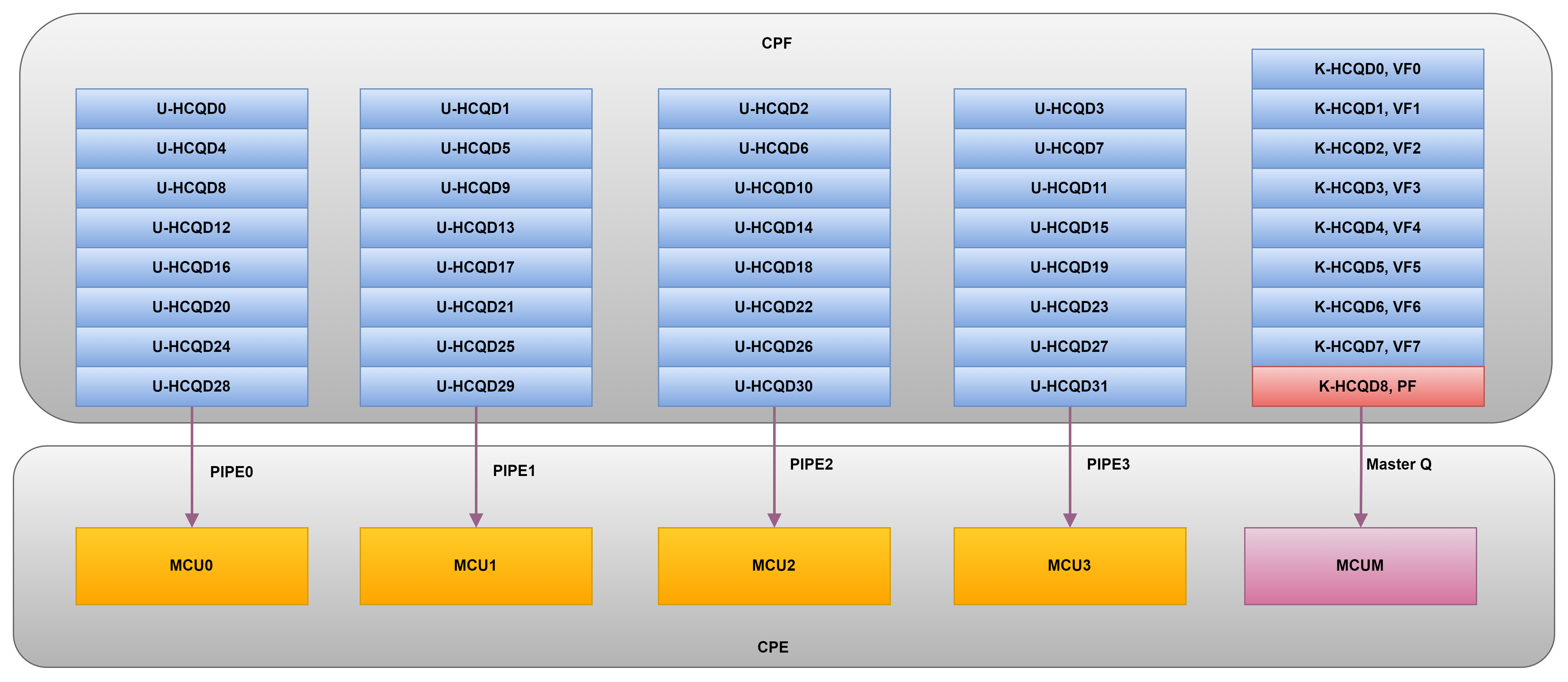
每个使用GPU的进程都可以有一个QUEUE
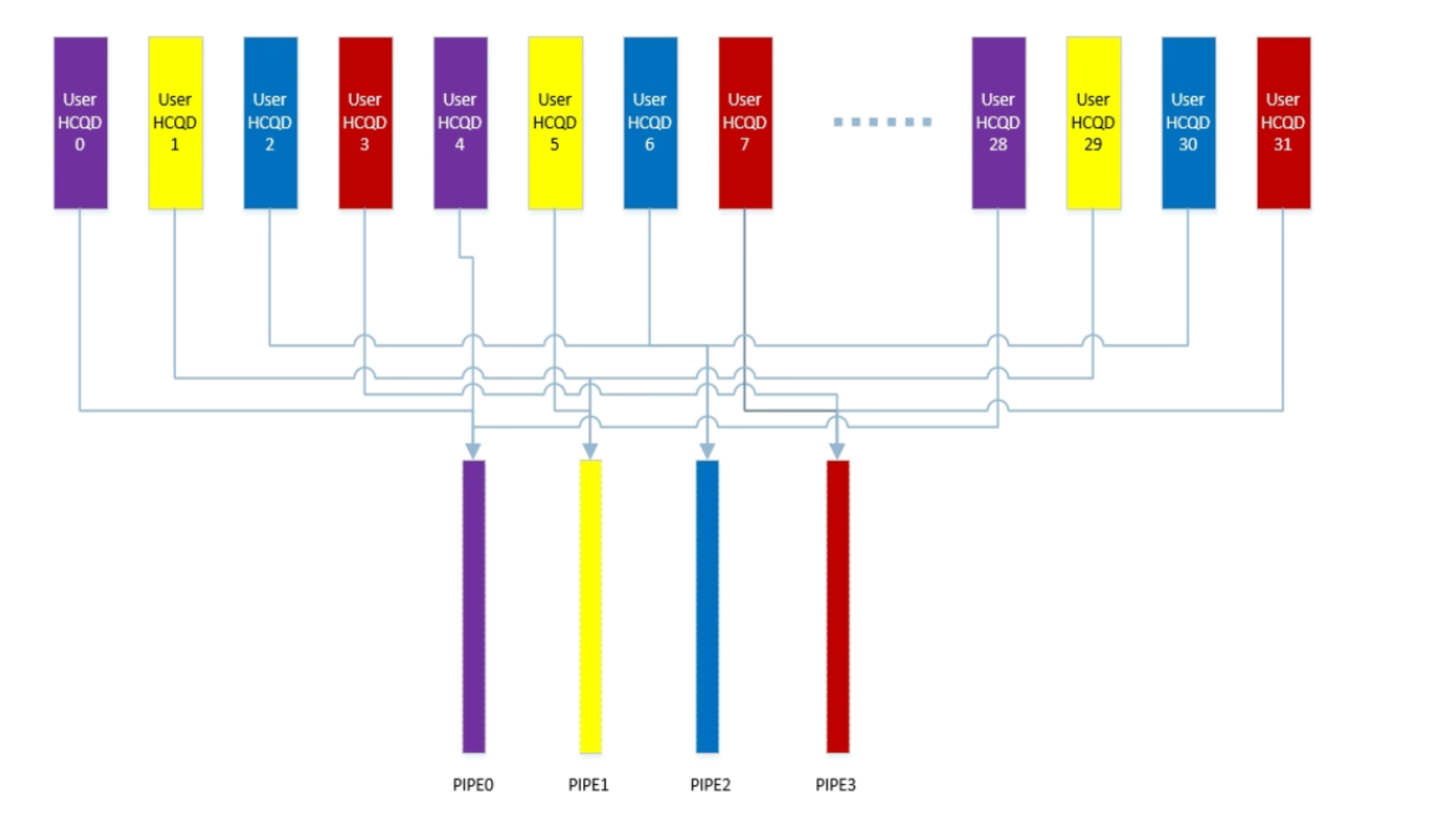
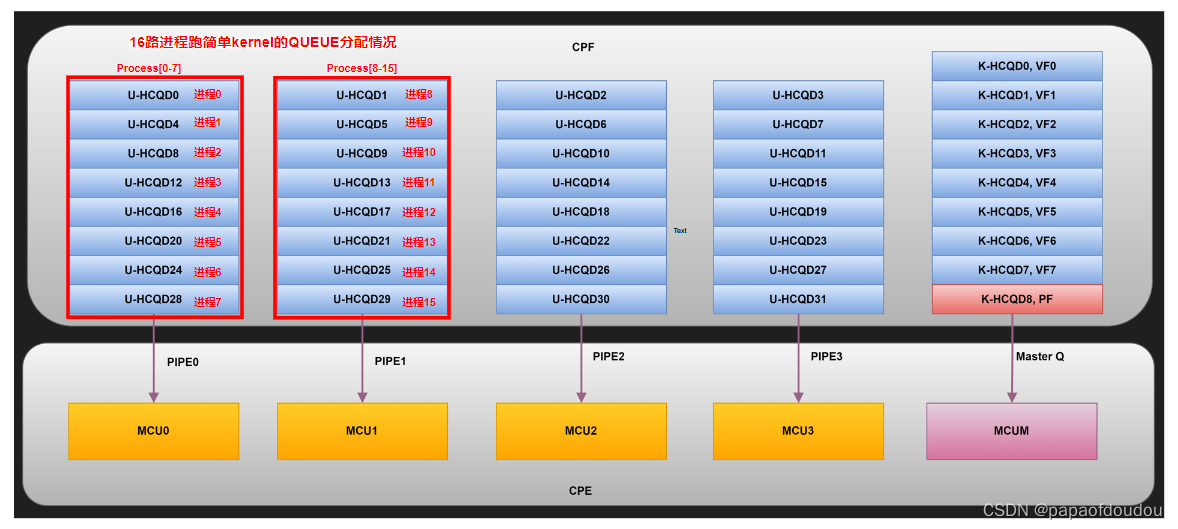
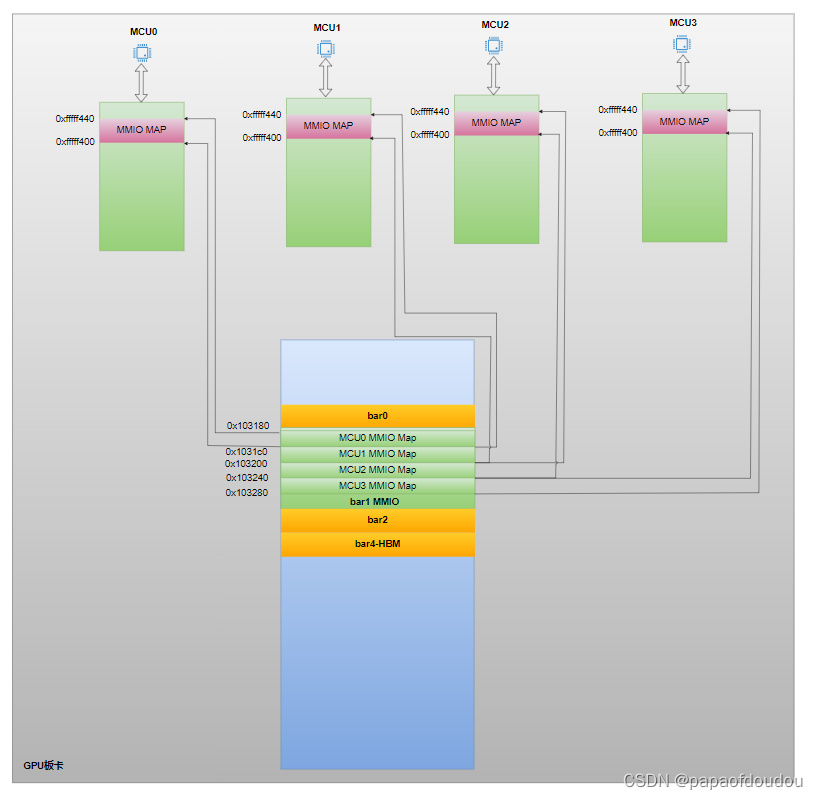
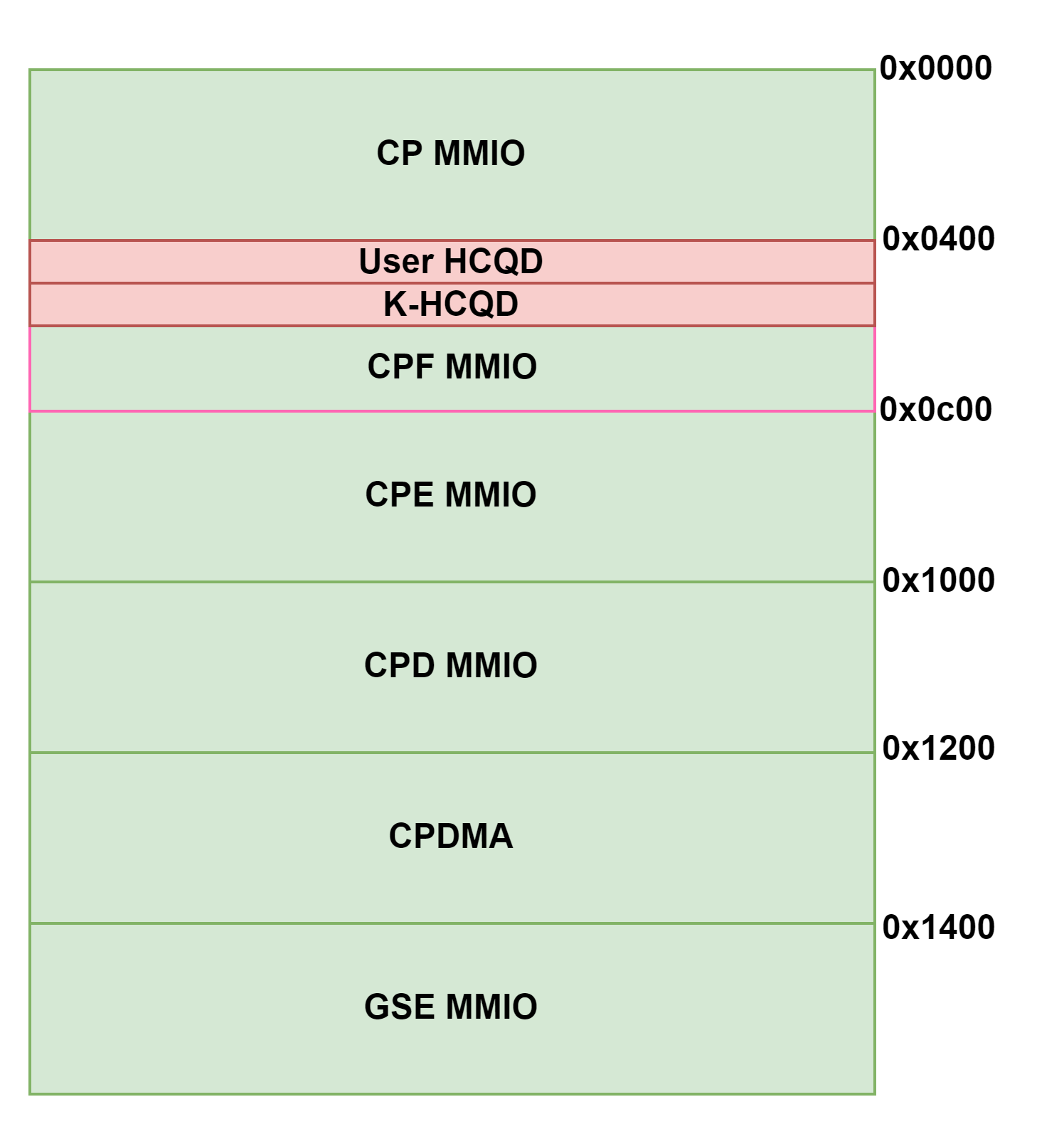

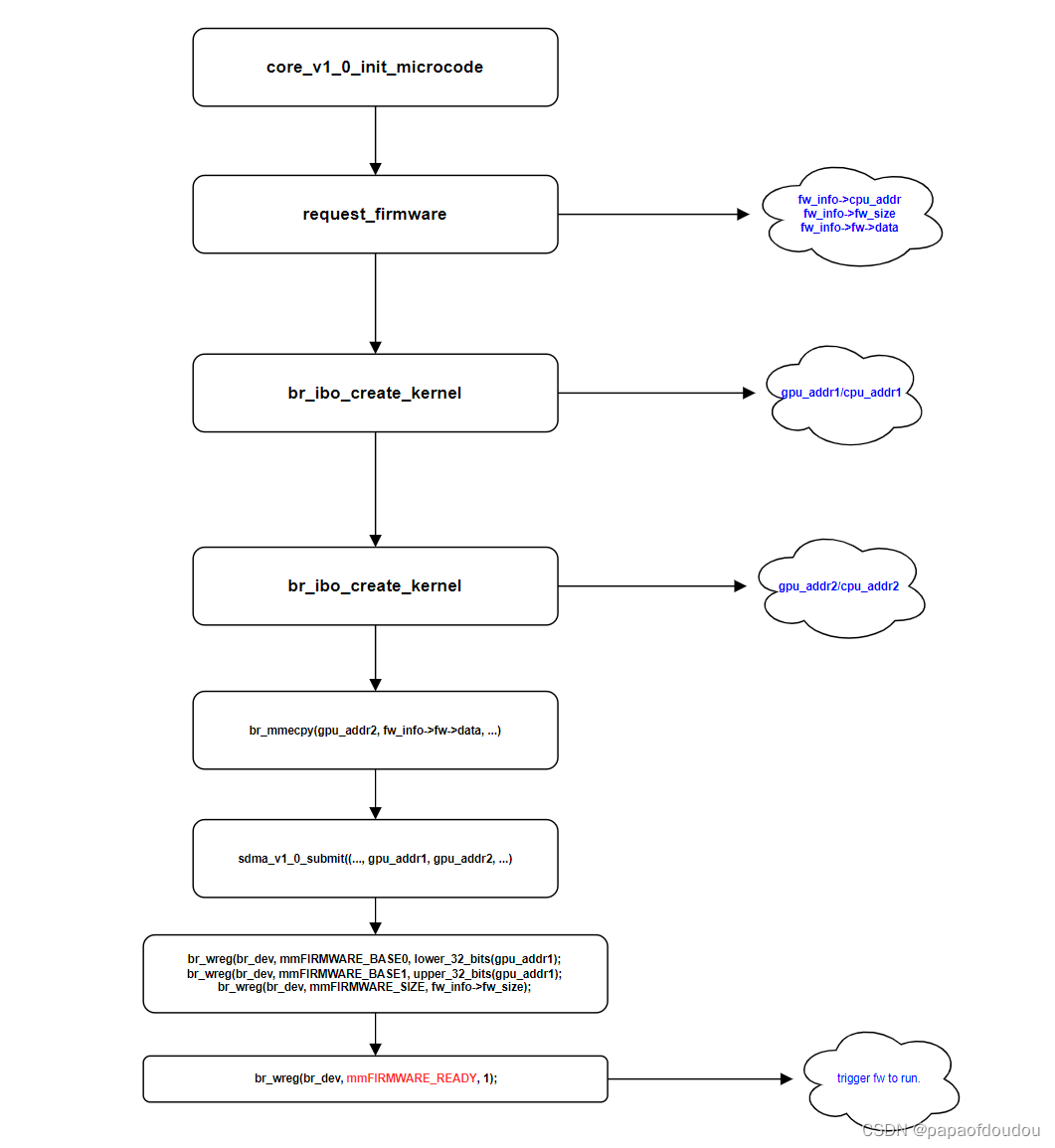
kmd和video fw的通信,fwtrace的实现基础
SVI的逻辑
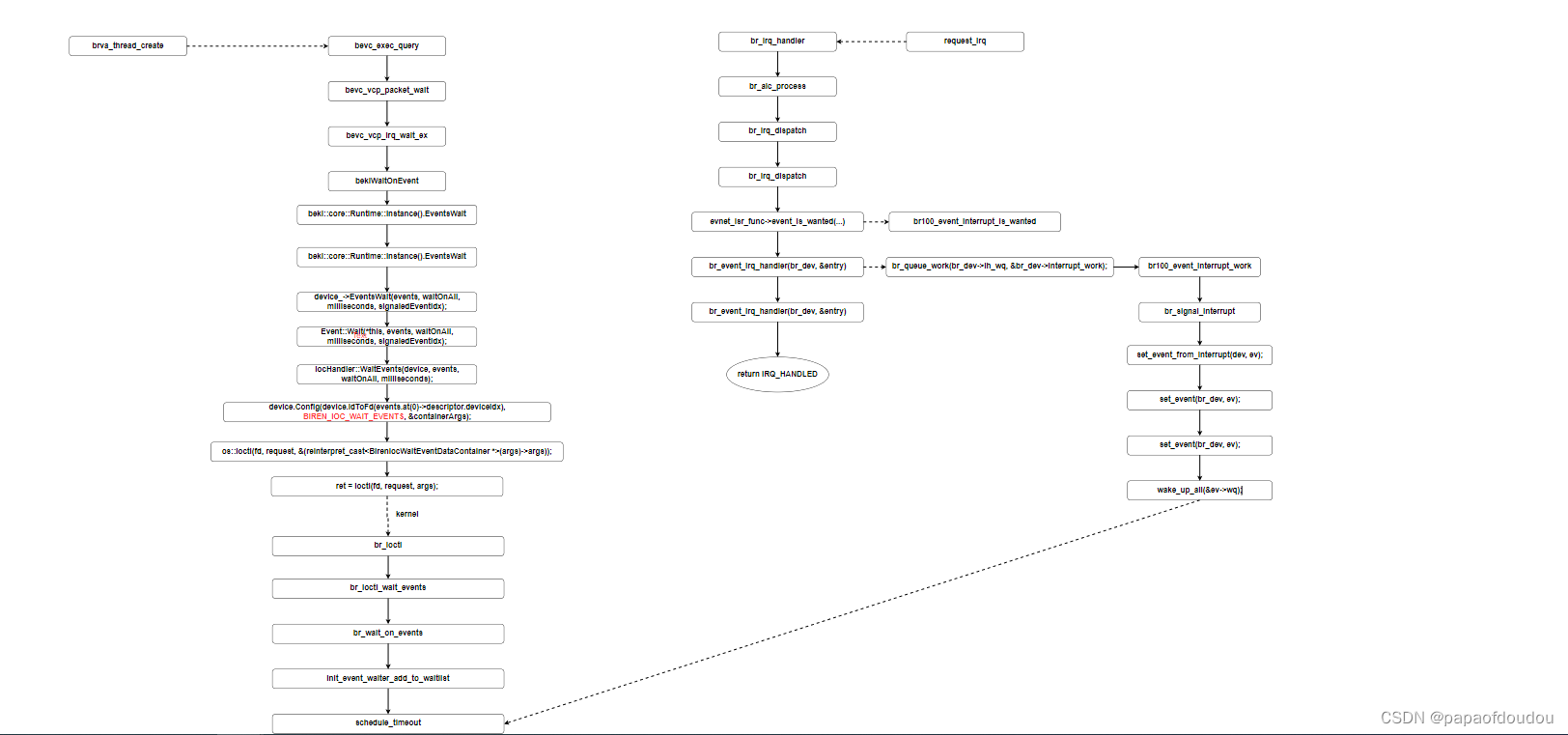

什么是ISSUE?
如果按照五级流水线,取指,译码,执行,访存,回写的提法,ISSUE发生在执行阶段。实际上是因为译码拆分成译码和发射两个阶段,发射是把操作队列的指令根据操作类型送到保留栈,并在ROB中指定一项座位临时保存该指令结果只用,发射过程中读寄存器的值和结果状态域,如果结果状态域指出结果寄存器已被重命名到ROB,则读ROB。
IPS:inference per second.
含光800软件栈架构
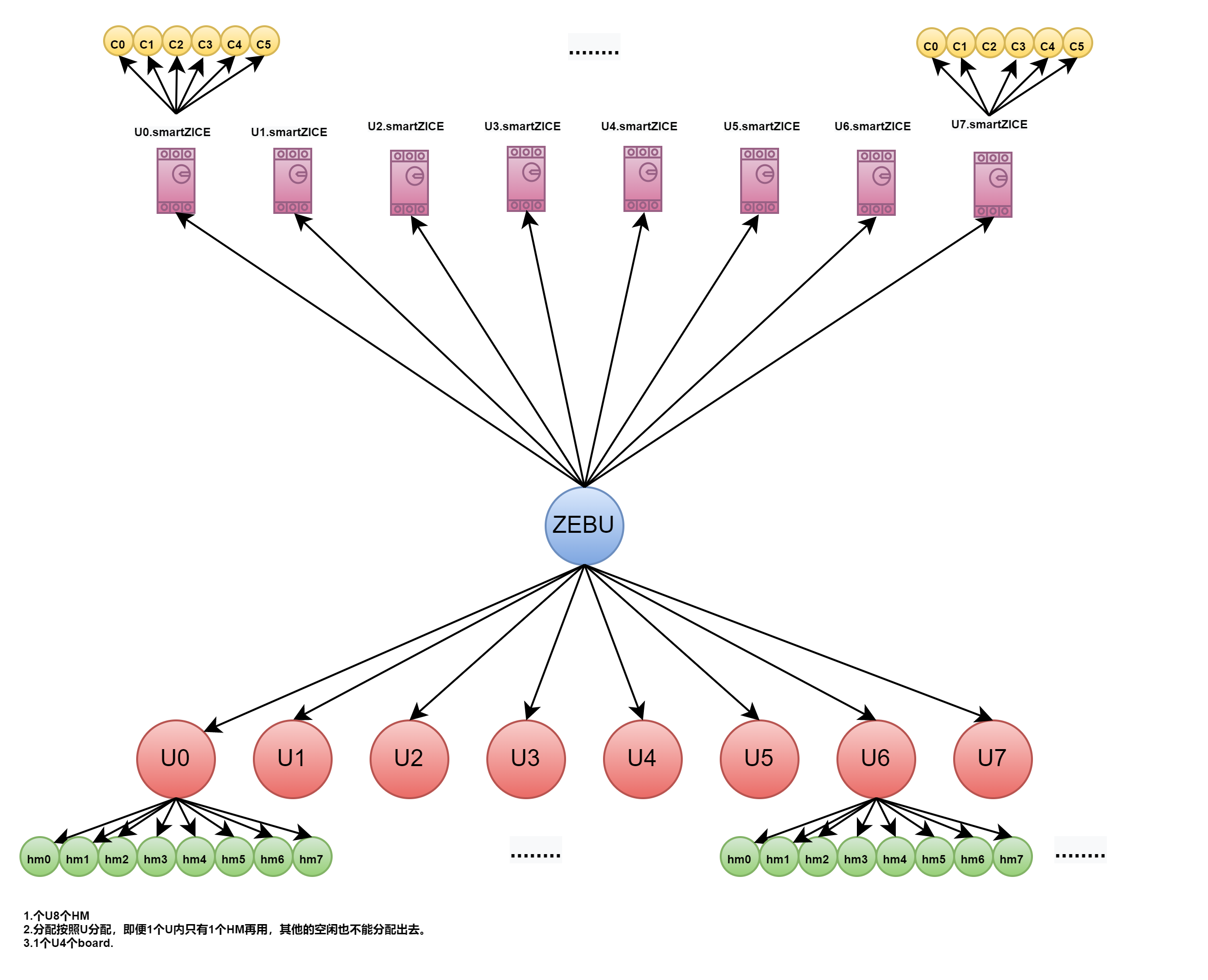
ZeBu(ZeroBug)
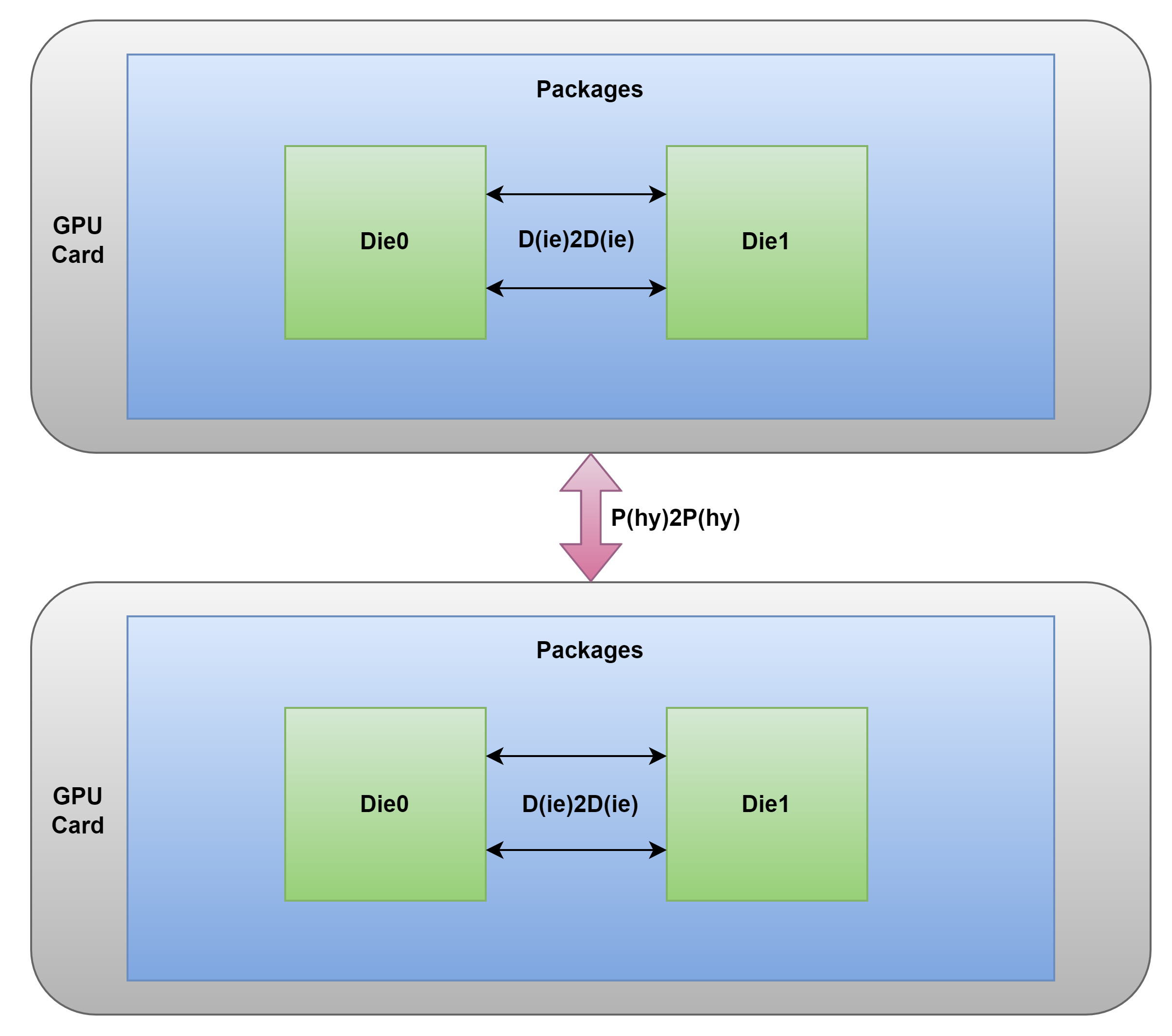
P2P就是BLINK,对等于NVLINK.
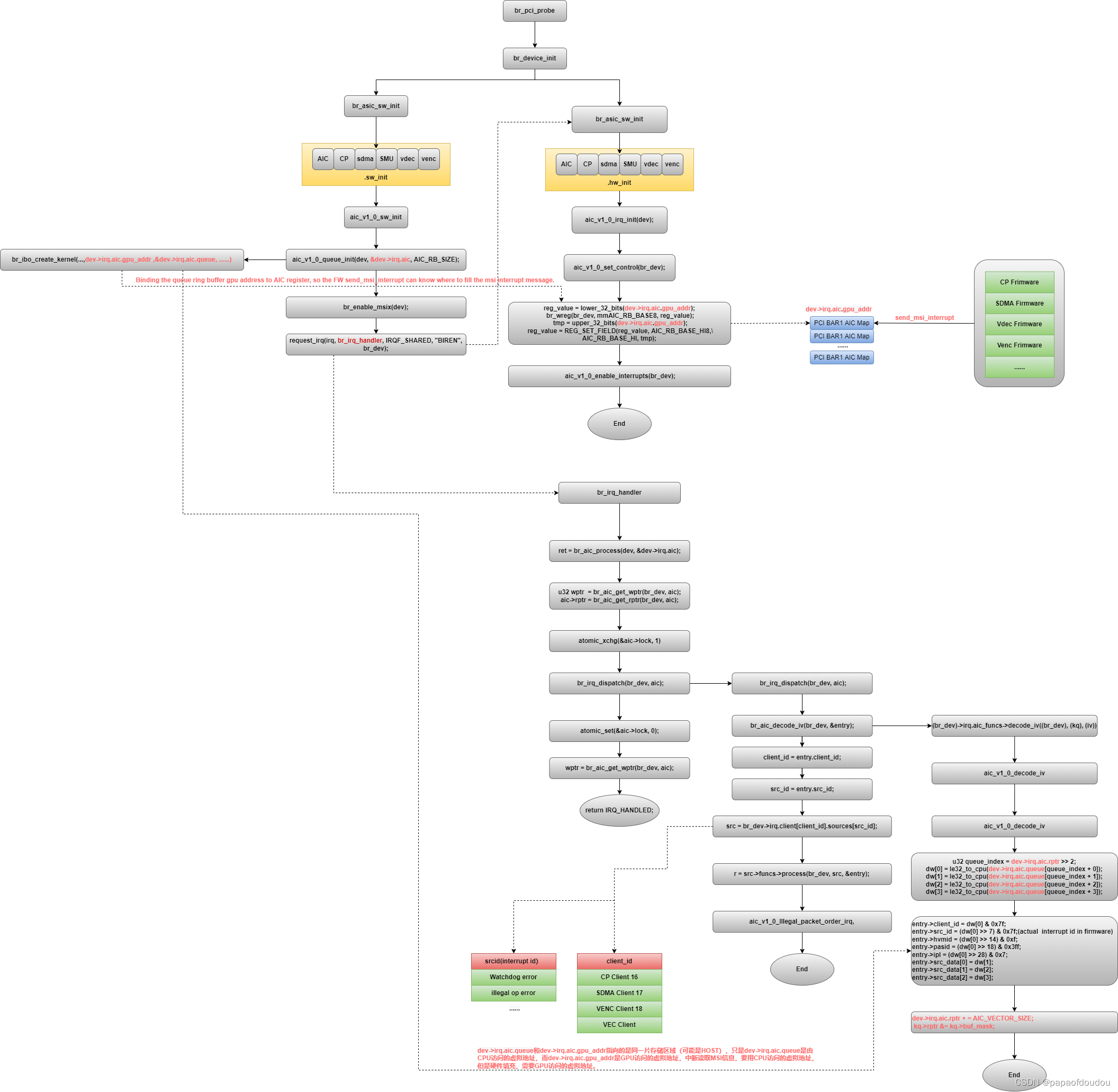
flow
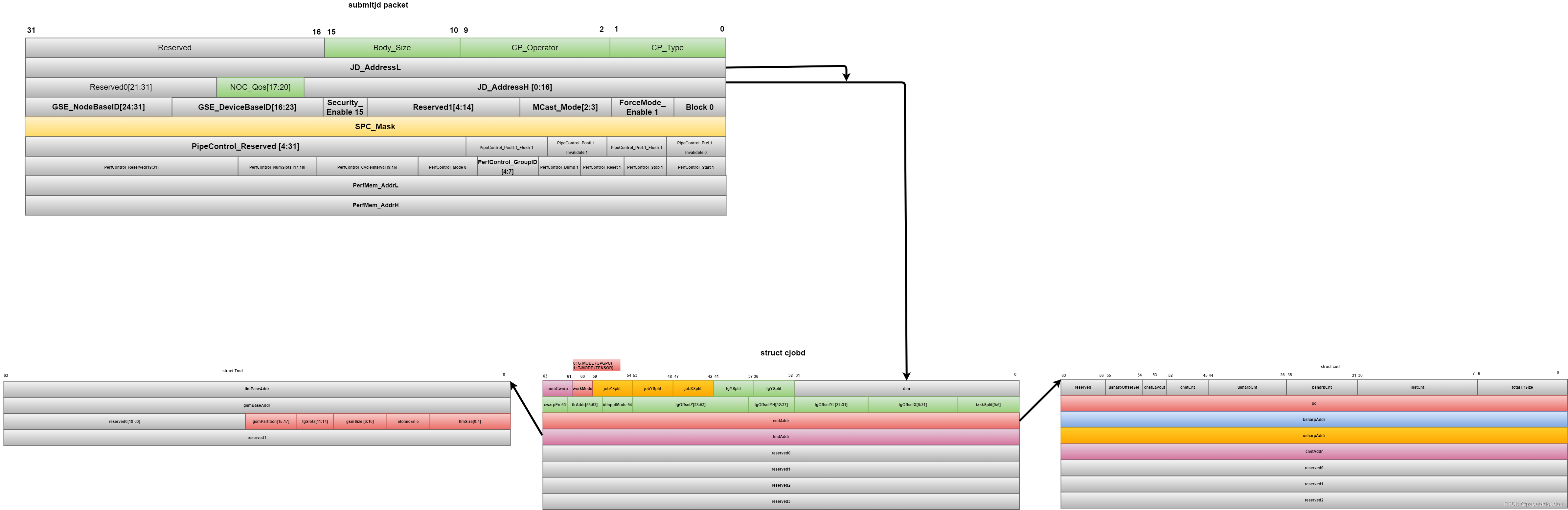
一个计算核任务在GPGPU中的描述:
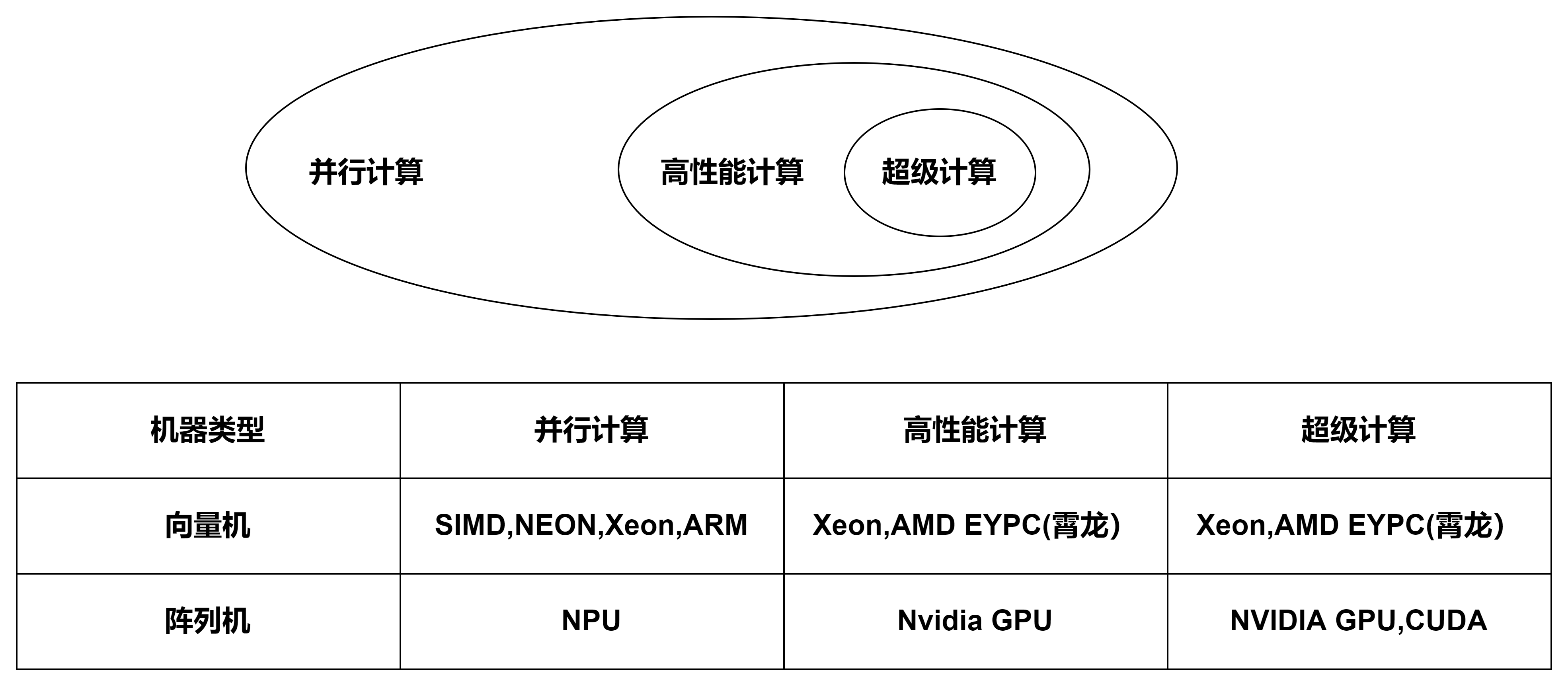
高性能计算的分类
并行计算机从本质上分仅有两种,阵列机和向量机,典型代表分别为GPU和带有SIMD的CPU。
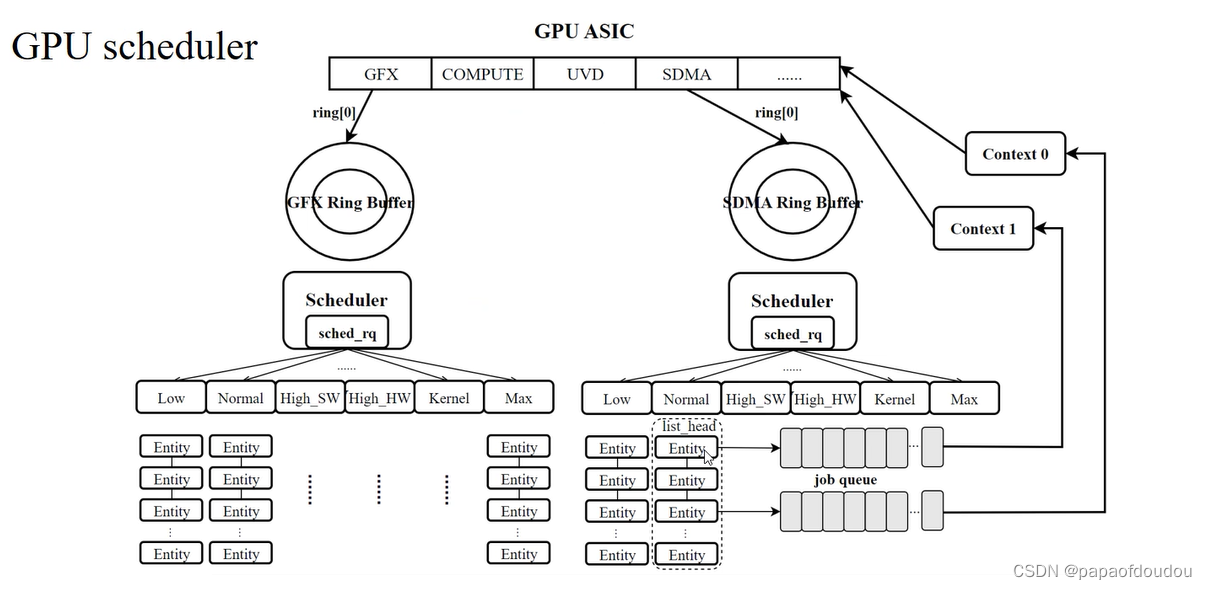
天数智芯软件站
注意池化层。
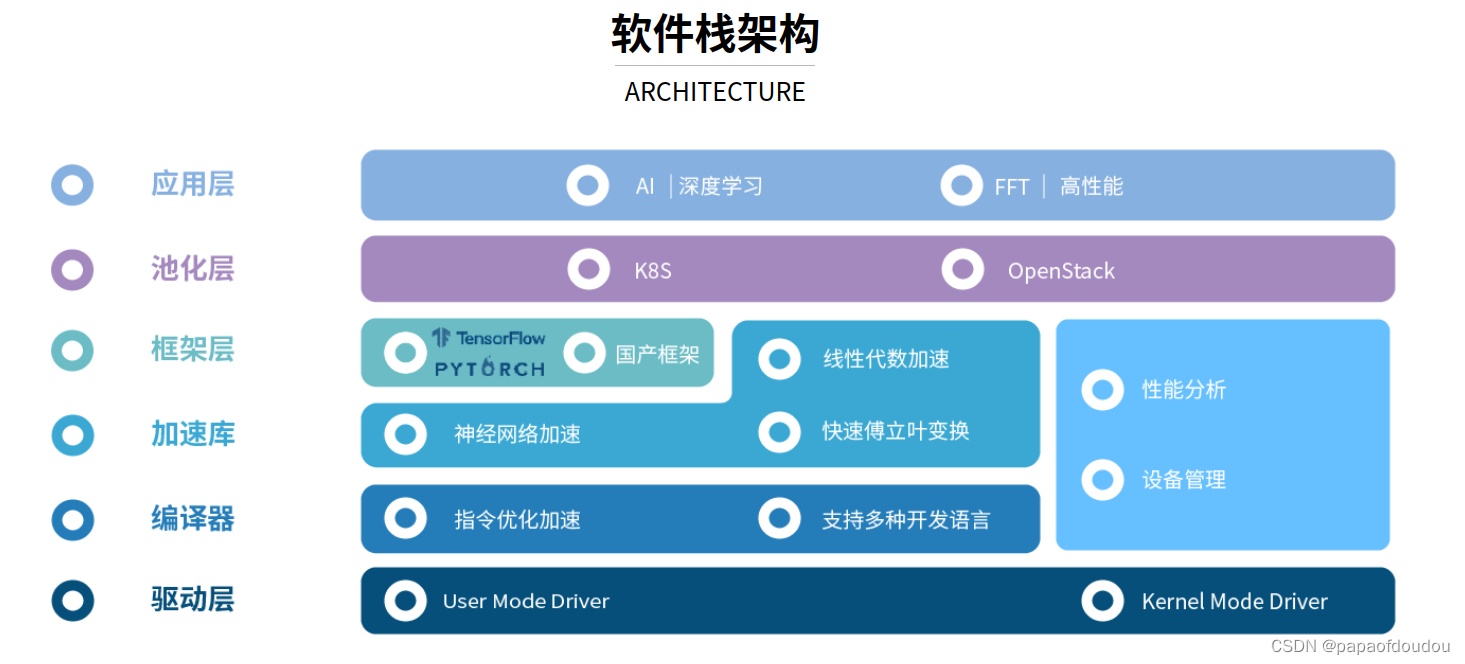
在线体验基于GPU卡加速AI的内容生成:
智星云 AI Galaxy | GPU云服务器 GPU服务器租用 远程GPU租用 深度学习服务器 | 免费GPU 便宜GPU
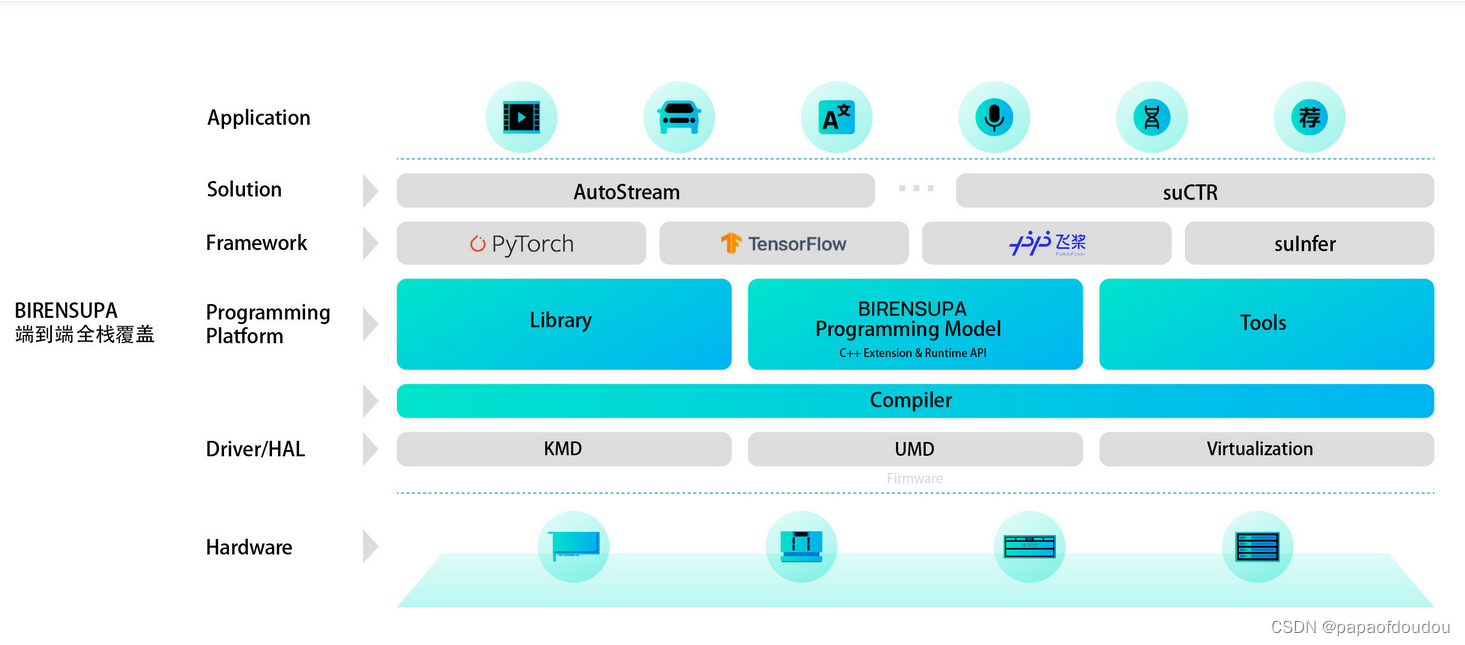
和 BIREN SUPA的软件栈非常相似,两者都是以解决方案为主线,并非平台为主线,所以可以看到编译器层。
本质上,两个都是芯片公司针对自家平台打造的一套软件方案,支持各种生态体系。
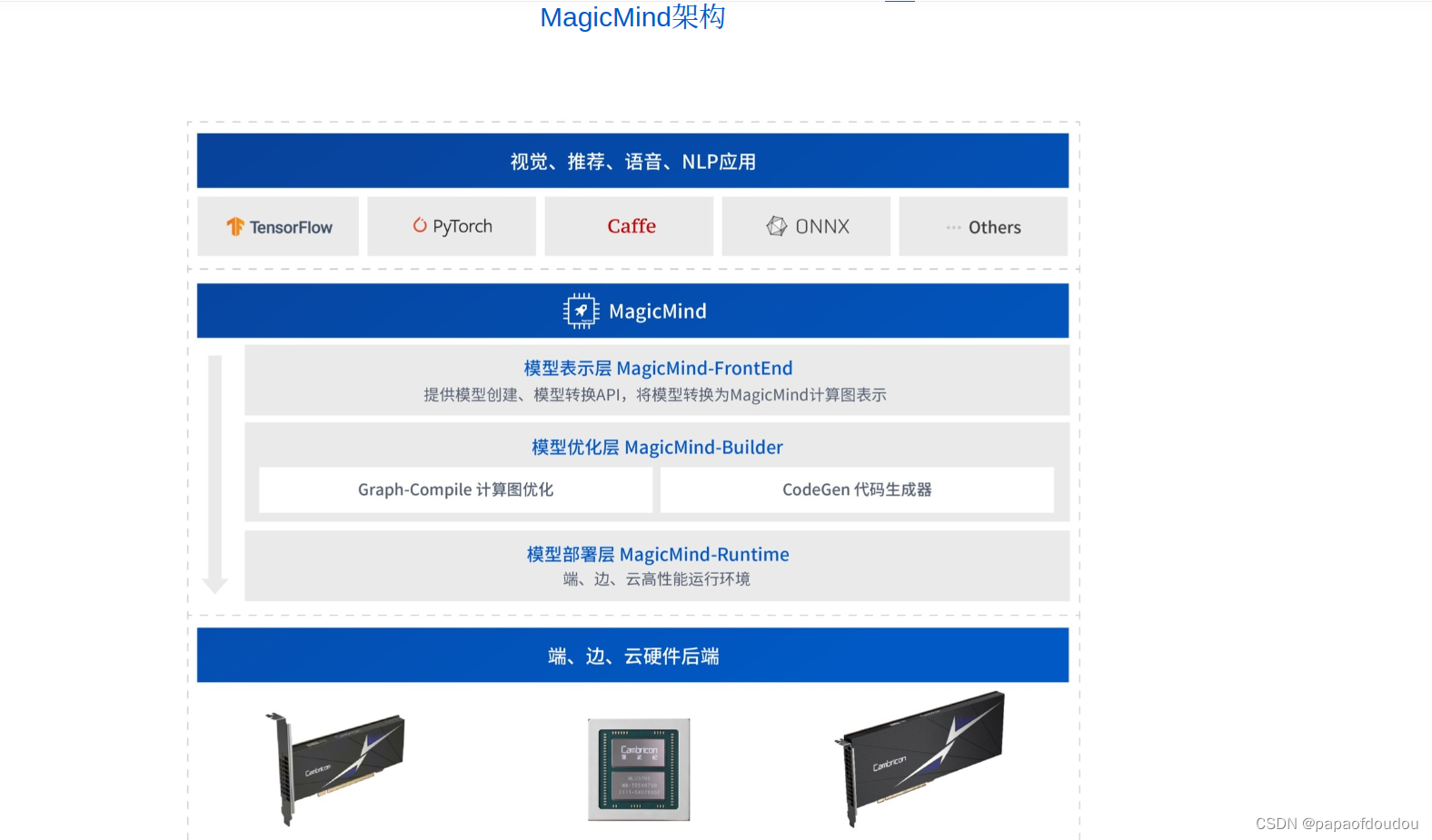
看看寒武纪magicmind推理加速引擎:
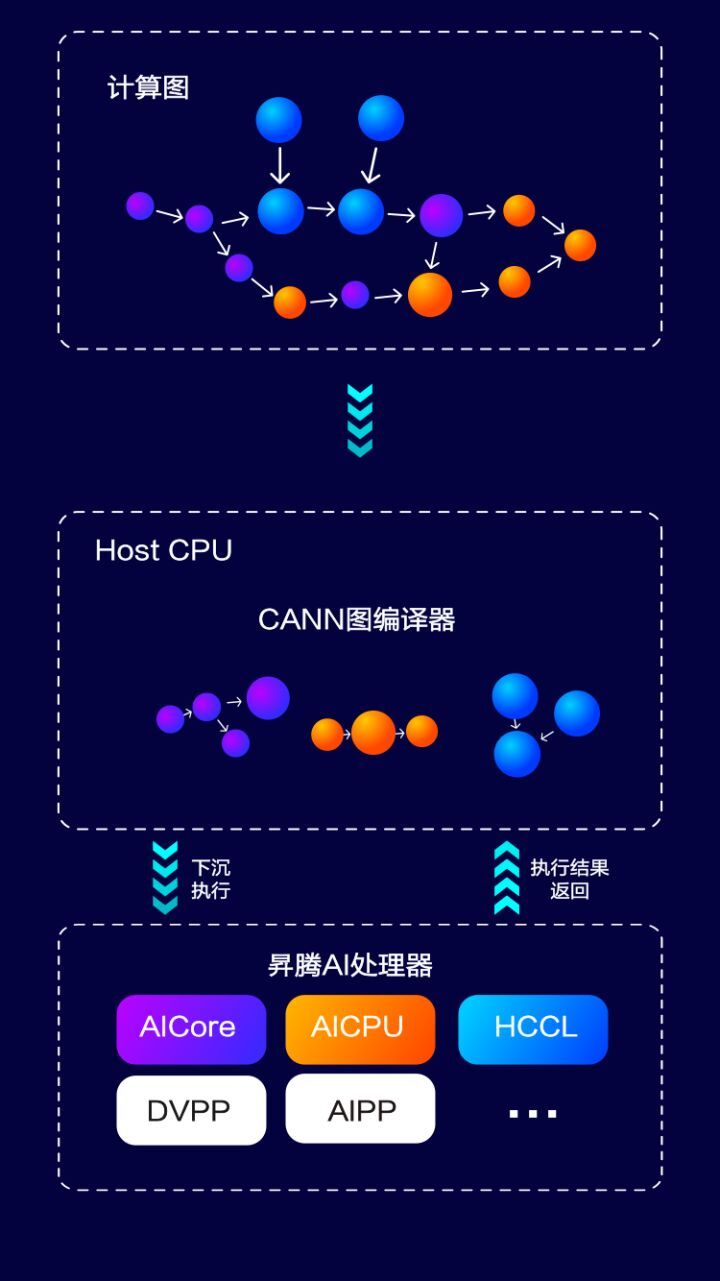
华为鲲鹏CPU(HOST)+升腾加速器(GPGPU)的组合:
全图下沉:昇腾 AI 处理器,集成了丰富的计算设备资源,比如 AICore/AICPU/DVPP/AIPP 等,正是得益于昇腾 AI 处理器上丰富的土壤,使得 CANN 不仅可以将计算部分下沉到昇腾 AI 处理器加速,还可以将控制流、DVPP、通信部分一并下沉执行。尤其在训练场景,这种把逻辑复杂计算图的全部闭环在 AI 处理器内执行的能力,能有效减少和 Host CPU 的交互时间,提升计算性能。
异构调度能力:当计算图中含有多类型的计算任务时,CANN 充分利用昇腾 AI 处理器丰富的异构计算资源,在满足图中依赖关系的前提下,将计算任务分配给不同的计算资源,实现并行计算,提升各计算单元的资源利用率,最终提升计算任务的整体效率。
fine tune是什么意思?
Fine-tune是指在已经预训练好的模型基础上,针对特定任务继续训练模型的过程,通常情况下,已经预训练好的模型是在大规模的通用数据上进行训练的,而fine-tune则是将这些通用数据应用到具体的任务中去,以获得更好的性能。
在机器学习领域,fine-tune是一种常见的技术,特别是在自然语言处理,计算机视觉等领域中,例如,在自然语言处理中,可以使用预训练好的语言模型(如BERT,GPT等)对某个特定的任务进行fine-tune,如文本分类,命令实体识别等等,在计算机视觉领域中,也可以使用预训练好的图像分类模型,比如ResNet,inception等,对某个特定的任务进行fine-tune,如目标检测,图像分割等等。
通过fine-tune技术,可以避免从头开始训练模型,节省大量的计算资源和时间,同时还能提高模型在特定任务上的性能。
业务流程
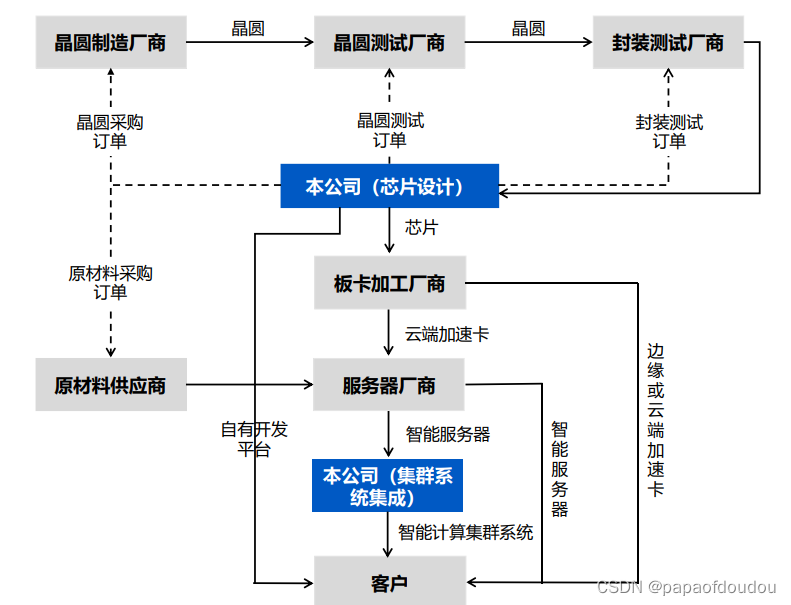
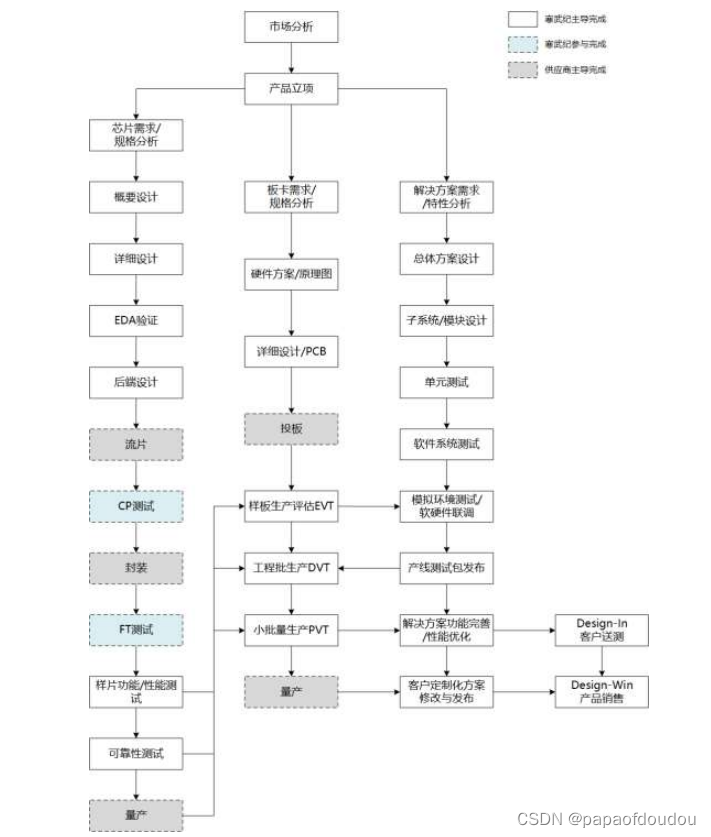
https://pdf.dfcfw.com/pdf/H2_AN202007131391420914_1.pdf?1670072306000.pdf


















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











