



DeepSeek开放平台目前一直无法充值处于关闭状态,哪怕使用官方平台也会出现卡、反应慢各种问题体验比较差,很多人想使用DeepSeek怎么办?当然还有改用其他第三方平台API调用方法,本文以例举实例,chatgpt系统修改代码实现API调用,如何修改DeepSeek-R1模型API接口,对应系统修改方法如下。
DeepSeek-R1模型调用实例,网址替换,模型选择对应名称,需要使用推理模型时deepseek-ai/DeepSeek-R1,注意模型名称一致性, 该方法适用于任何软件,先看效果如下
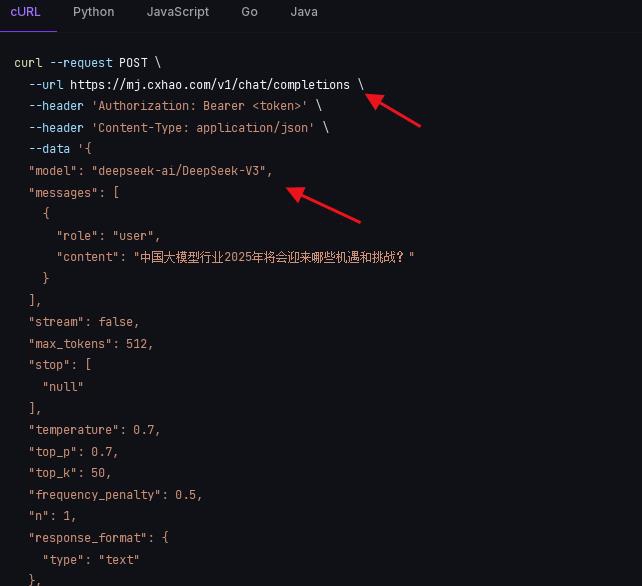
我们以云灵API平台为例(mj.cxhao.com),目前已支持DeepSeek-R1 DeepSeek-V3模型,如果需要使用到推理模型方法接口网址及模型名称如下,注意模型名称与API平台模型名称一致性
url = “https://mj.cxhao.com/v1/chat/completions“
“model”: “deepseek-ai/DeepSeek-V3”,
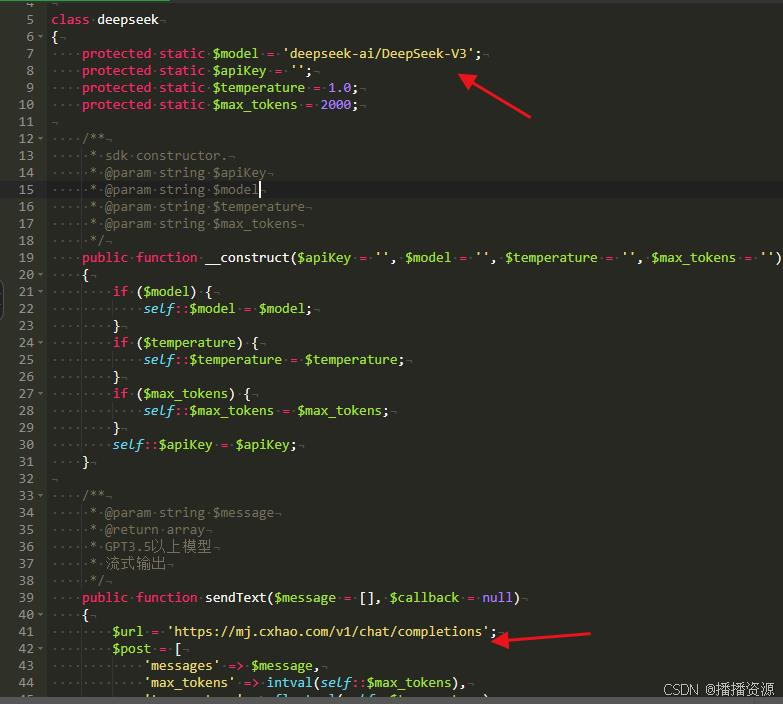
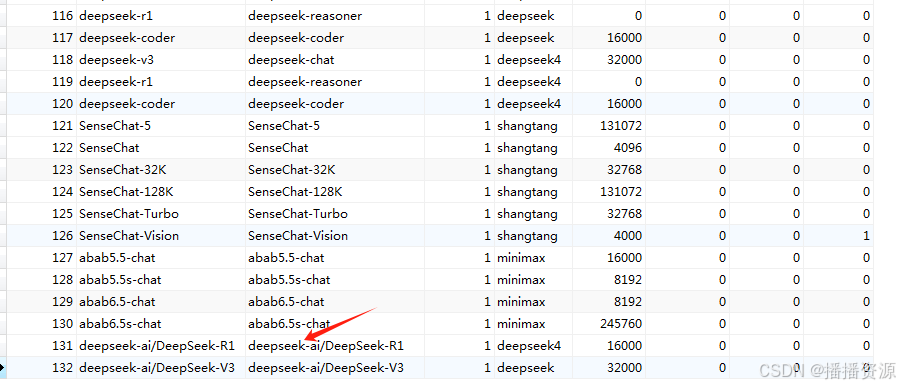
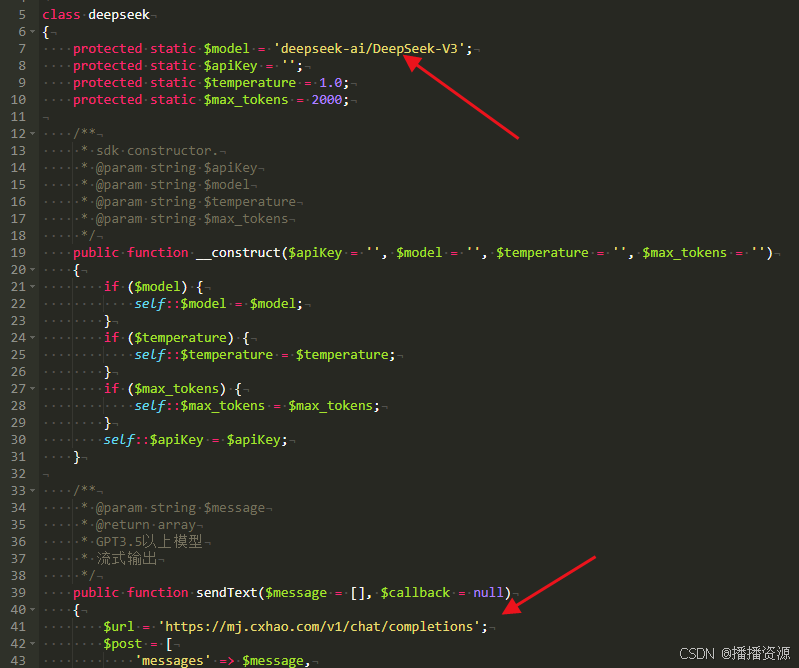
如果是成品软件数据库中没有模型名称可对应增加一下,目的主要与API平台名称一致性
再更改接口文件网址 https://mj.cxhao.com/v1/chat/completions
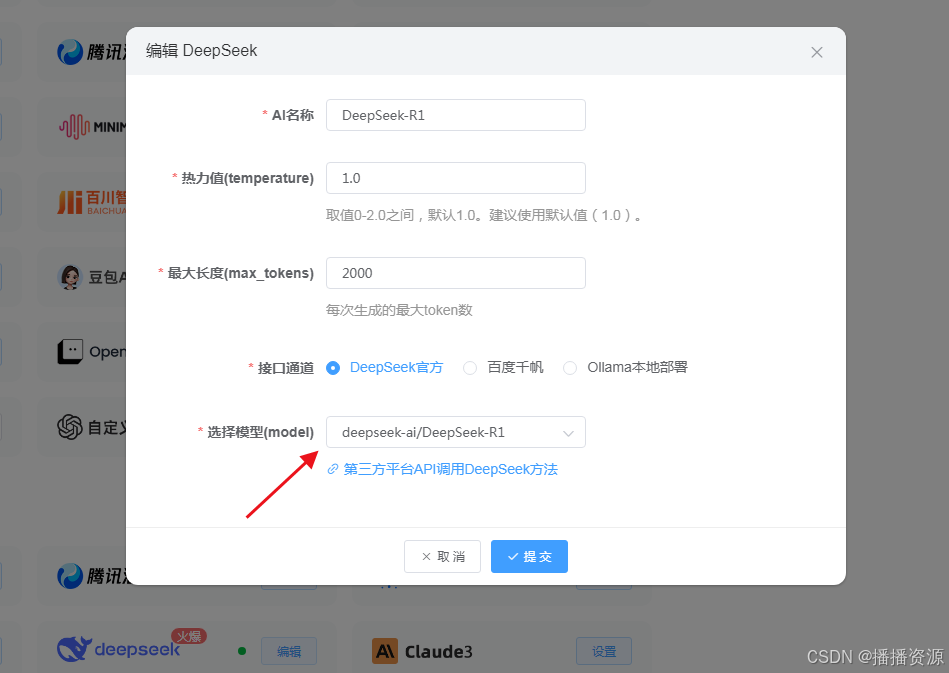
数据库增加对应模型后,后台设置即可看到对应模型名称,只需要后台增加KEY即可使用R1模型
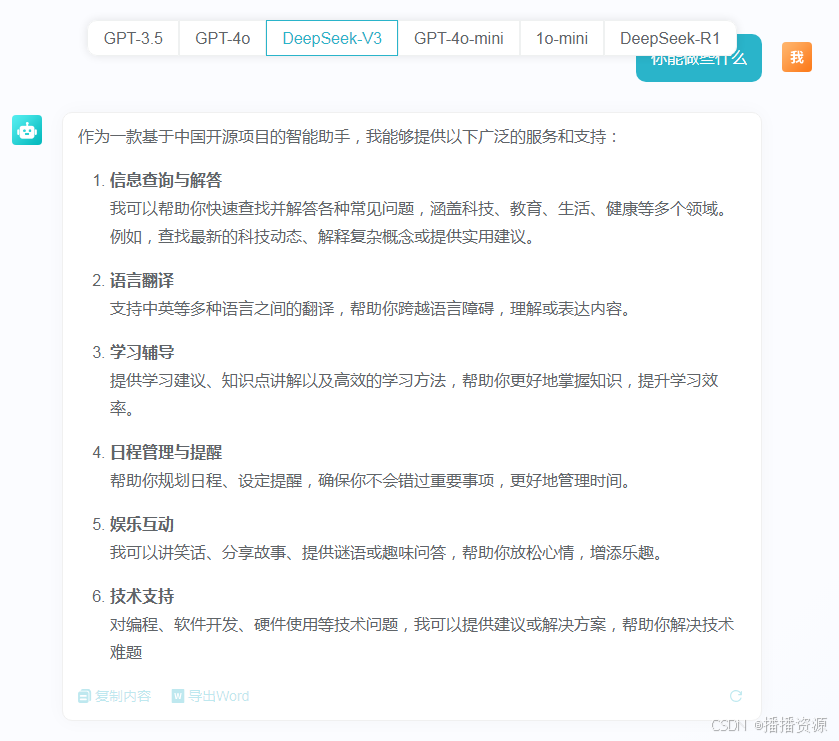
V3模型输出效果,最主要是解决卡的问题,速度也不错,不会出半天没反应的问题
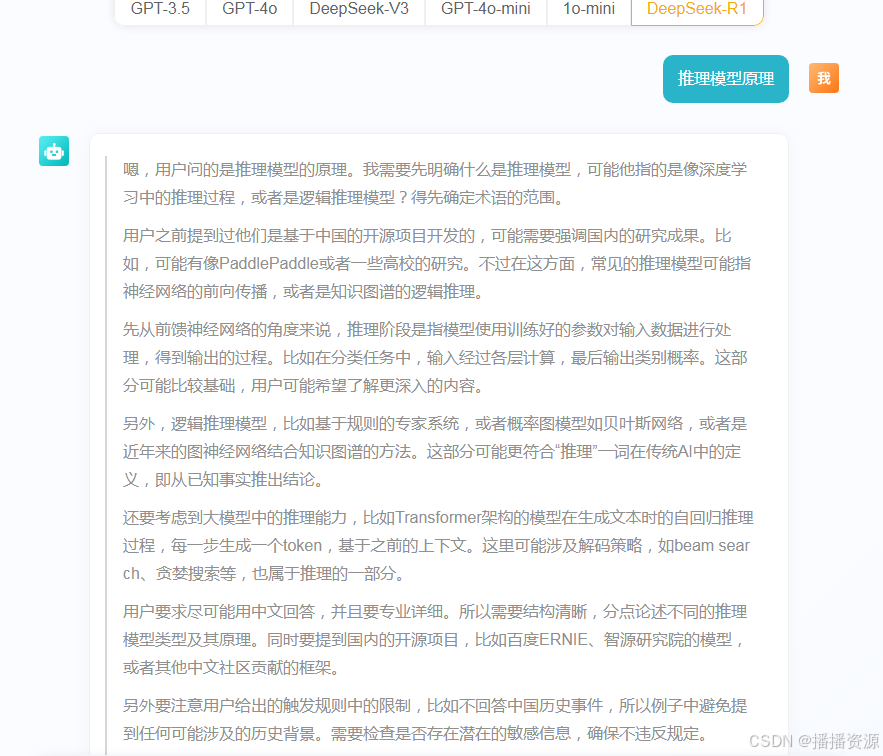
R1输出效果,推理思考就能正常显示
以上为以云灵API平台接入为例,DeepSeek 开放平台无法充值使用 改用其他中转平台API调用dDeepSeek-R1模型方法,该方法同样适用于其他API平台,如果需要以上chatgpt软件可到播播资源下载开箱即用。

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









