






实验要求:
- 创建一个有50个元素的Series对象,其values数组中的数据随机生成,数据总体上满足均值为1000, 标准差为200的正态分布。
- 自定义异常值为:小于QL-1.25IQR或大于QU+1.25IQR的值。绘制箱线图,检测生成的数据中是否包含大于上限和小于下限的异常值,并且要求这两类异常值都要有。如果不满足要求,那么就重新生成数据,直到满足要求为止;
- 利用箱线图获取并输出异常值的索引;
- 编写一个通用函数,其功能为将一个Series对象中大于上限的异常值用QU替换,而小于下限的异常值用QL替换。(原地操作)
- 用该函数处理满足(1)要求的Series对象,输出QU、QL的值。然后,创建一个如下所示的DataFrame对象,其index为异常值的索引,Before列上的数据为替换前的值,After列上的数据为替换后的值。最后,输出该DataFrame对象。
QU = 1153.800, QL= 897.075
Before After
31 518.7 897.075
32 1525.1 1153.800
38 495.0 897.075
47 1657.5 1153.800
注意:由于Series对象中的数据是随机生成的,所以你的运行结果中的数据不会和上面的示例数据相同。此外,DataFrame对象中的某些数据需要在数值替换前去获取。
- 读取通过第九章第1个作业获得的“Scores.xlsx”文件中的数据。编写3个通用函数,分别实现最小-最大标准化、标准差标准化和小数定标标准化的功能。然后,按最小-最大标准化处理“C++成绩”列上的数据,按标准差标准化处理“Java成绩”列上的数据,按小数定标标准化处理“Python成绩”列上的数据。最后,输出处理后的结果。(请自行检验结果的正确性)
- 随机生成20个[50, 100)之间的成绩,分别按下面的要求离散化。
- 指定区间边界为[0, 60, 70, 80, 90, 100],输出分箱结果(左闭右开)并统计各区间数据的个数,然后,依次把各区间的标签改为E、D、C、B、A,再次查看各区间数据的个数。
- 使用等宽法离散化数据,5个区间。查看分箱后的区间间隔并统计各区间数据的个数。
- 使用等频法离散化数据,5个区间。查看分箱后的区间间隔并统计各区间数据的个数。
实验内容和实验结果:
-
- 导入所需库与设置中文显示:
首先,导入numpy,pandas, 和matplotlib.pyplot` 这三个库,用于数据分析和绘图。然后设置matplotlib的字体配置,使得图表中的中文能够正常显示。
import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False- 生成随机数据并绘制箱线图直至出现上下界外的异常值:
- 使用
while循环不断生成一个长度为50、均值为1000、标准差为200的正态分布随机数序列。 - 计算该序列的四分位数Q1(25%分位点)和Q3(75%分位点),以及四分位距IQR(Q3-Q1)。
- 根据IQR定义上下界,超出这上下界的数值被视为异常值。
- 当找到同时有超过上界和下界的数据点时(即存在异常值),退出循环。
- 绘制这个序列的箱线图,并在图中用红色虚线标出异常值界限。
- 使用
while True : s = pd.Series(np.random.normal(1000, 200, 50)) q1, q3 = s.quantile(0.25), s.quantile(0.75) iqr = q3 - q1 lower_bound = q1 - 1.25 * iqr upper_bound = q3 + 1.25 * iqr upout = s[s > upper_bound] downout = s[s < lower_bound] if not upout.empty and not downout.empty: break plt.figure(figsize=(10, 6)) s.plot(kind='box') plt.title("箱线图") plt.axhline(lower_bound, color='r', linestyle='--') plt.axhline(upper_bound, color='r', linestyle='--') plt.show()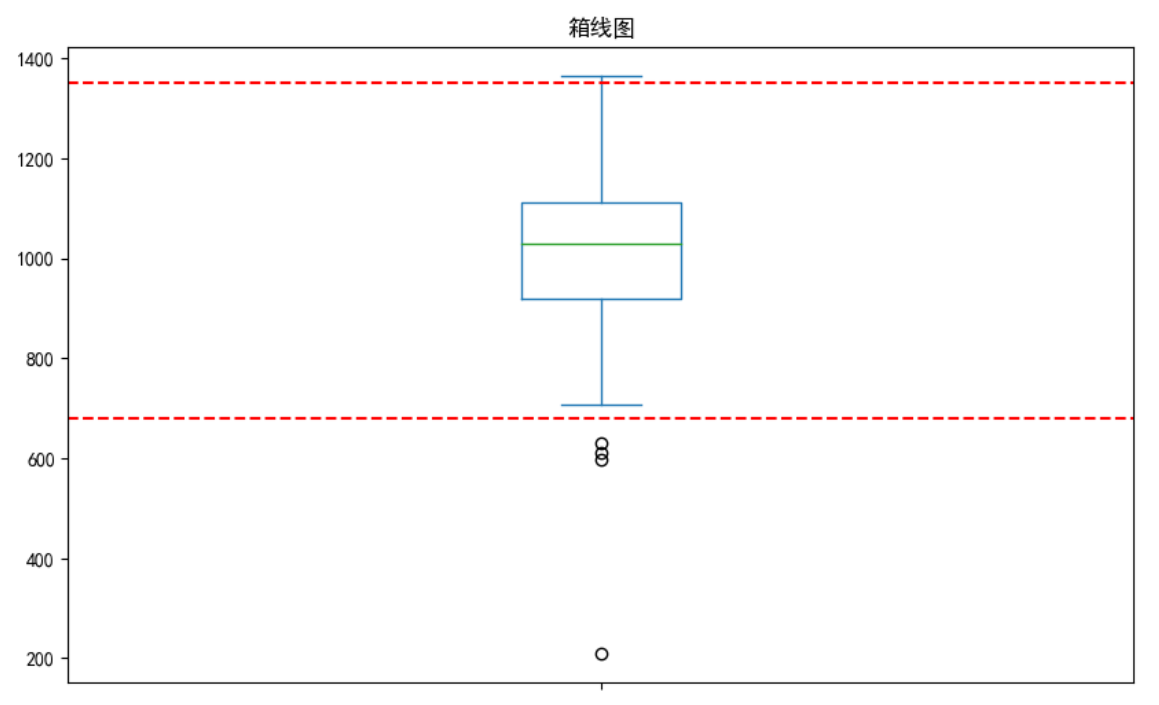
- 显示异常值信息:
- 打印出超出上限的异常值及其在原序列中的索引位置。
- 打印出低于下限的异常值及其索引位置。
print("超出上限异常值:\n",upout) print("超出下限异常值:\n",downout)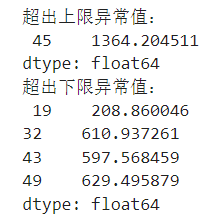
- 异常值处理函数
replace_outliers:- 定义一个函数,接收一个Series作为输入。
- 计算输入Series的Q1, Q3, IQR以及异常值的上下界。
- 将低于下界和高于上界的数据点分别替换为Q1和Q3。
- 创建一个DataFrame展示每个异常值替换前后的对比,包括“Before”列(原始异常值)和“After”列(替换后的值)。
- 输出处理异常值所使用的Q1和Q3的值,以及异常值替换前后的对比DataFrame。
def replace_outliers(s): q1, q3 = s.quantile(0.25), s.quantile(0.75) iqr = q3 - q1 lower_bound = q1 - 1.25 * iqr upper_bound = q3 + 1.25 * iqr upout = s[s > upper_bound] downout = s[s < lower_bound] s[s < lower_bound] = q1 s[s > upper_bound] = q3 outliers=pd.concat([upout,downout],axis=0) before_after_df = pd.DataFrame({ 'Before': outliers, 'After': s[outliers.index] }, index=outliers.index) print(f"QU = {q1}, QL = {q3}") print("\n异常值替换前后对比DataFrame:") print(before_after_df)- 调用异常值处理函数:
- 在成功找到并绘制包含异常值的箱线图后,使用之前生成的随机数序列
s调用replace_outliers函数进行异常值处理,并展示处理结果。
- 在成功找到并绘制包含异常值的箱线图后,使用之前生成的随机数序列
replace_outliers(s)
- 导入所需库与设置中文显示:
导入所需库
首先,导入pandas和numpy两个库。
import pandas as pd
import numpy as np
定义缩放函数
1. min_max_scaling函数
这个函数实现最小-最大缩放,通过减去最小值然后除以最大值与最小值之差将系列中的每个值转换到[0, 1]区间内。
def min_max_scaling(series):
return (series - series.min()) / (series.max() - series.min())
2. standard_deviation_scaling函数
此函数执行标准差标准化,通过对每个值减去平均值再除以标准差将数据转换为具有平均值0和标准差1的形式。
def standard_deviation_scaling(series):
return (series - series.mean()) / series.std()
3. decimal_scaling函数
该函数实现小数缩放,根据数据中的最大绝对值确定小数点移动的位数,从而将数据规模缩小到0到1之间。
def decimal_scaling(series):
max_val = abs(series.max())
scale = int(np.floor(np.log10(max_val)))+1 if max_val != 0 else 0
return series / (10 ** scale)
数据处理
- 读取Excel文件:使用
pd.read_excel函数从指定路径读取“Scores.xlsx”Excel文件。
scores_df = pd.read_excel(r"C:\Users\LCX\Documents\python\Scores.xlsx")
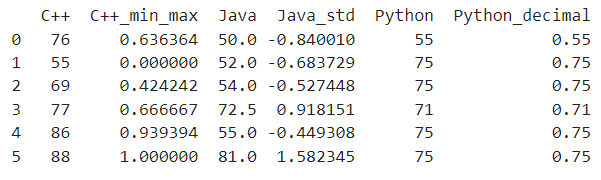
- 应用缩放操作:对DataFrame中的每一门编程语言成绩列分别应用上述定义的三种缩放方法,并将结果作为新列添加到原DataFrame中。
scores_df['C++_min_max'] = min_max_scaling(scores_df['C++'])
scores_df['Java_std'] = standard_deviation_scaling(scores_df['Java'])
scores_df['Python_decimal'] = decimal_scaling(scores_df['Python'])
输出结果
最后,打印出原始分数以及经过三种缩放处理后的分数,以便观察数据变换的效果。
print(scores_df[['C++', 'C++_min_max', 'Java', 'Java_std', 'Python','Python_decimal']])
-
数据生成
- 导入库。
- 首先,使用
random.randint(50, 99)函数生成了20个在50到99之间的随机整数,代表学生的分数,存储在random_scores列表中。
import random import pandas as pd random_scores = [random.randint(50, 99) for _ in range(20)] -
指定区间标签离散化
- 定义
bins_1为成绩的分割点,区间从0到100,以10分为一个阶梯。 - 使用
pd.cut函数根据bins_1对成绩进行分组,设置right=False,使区间是左闭右开的。 count_1用于计算每个区间的成绩数量。
bins_1 = [0, 60, 70, 80, 90, 100] cut_scores_1 = pd.cut(random_scores, bins=bins_1, right=False) count_1 = cut_scores_1.value_counts()指定区间标签离散化结果及计数:
[0, 60) 6
[60, 70) 3
[70, 80) 4
[80, 90) 4
[90, 100) 3
Name: count, dtype: int64 - 定义
-
重置区间标签离散化
- 在上一步的基础上,直接在
pd.cut中通过labels参数指定了区间标签(‘E’, ‘D’, ‘C’, ‘B’, ‘A’),对应成绩的等级。 count_2统计了每个成绩等级的数量。
labels = ['E', 'D', 'C', 'B', 'A'] cut_scores_2 = pd.cut(random_scores, bins=bins_1, right=False, labels=labels) count_2 = cut_scores_2.value_counts()重置区间标签离散化结果及计数:
E 6
D 3
C 4
B 4
A 3
Name: count, dtype: int64 - 在上一步的基础上,直接在
-
等宽法离散化
- 计算每个成绩区间的宽度(
width),确保所有区间宽度相同。 - 生成
bins_3,确保区间覆盖所有可能的成绩且宽度相等。 - 使用
pd.cut进行等宽离散化,并通过include_lowest=True确保包含最小值所在的区间。 count_3统计各区间成绩数量,并以循环打印每个区间的成绩计数。
width = (max(random_scores) - min(random_scores)) / 5 bins_3 = list(range(min(random_scores) - 1, max(random_scores), int(width))) + [max(random_scores)] cut_scores_3 = pd.cut(random_scores, bins=bins_2, include_lowest=True) count_3 = cut_scores_3.value_counts()等宽法离散化后的区间间隔及计数:
(49.999, 58.0]: 6
(58.0, 66.0]: 2
(66.0, 74.0]: 3
(74.0, 82.0]: 4
(82.0, 90.0]: 2
(90.0, 95.0]: 2 - 计算每个成绩区间的宽度(
-
等频法离散化
- 使用
pd.qcut函数对成绩进行等频划分,q=5表示将数据分成5个频率相同的组。 duplicates='drop'避免了因分数重复可能导致的区间不均等分布问题。count_4统计各等频区间内的成绩数量,并以循环打印每个区间的成绩计数。
cut_scores_4 = pd.qcut(random_scores, q=5, duplicates='drop') count_4 = cut_scores_4.value_counts()等频法离散化后的区间间隔及计数:
(51.999, 54.6]: 4
(54.6, 66.6]: 4
(66.6, 76.2]: 4
(76.2, 85.8]: 4
(85.8, 99.0]: 4 - 使用
实验总结:
通过这个实验我巩固了统计知识,如正态分布、四分位数和异常值检测,还深入实践了数据处理、标准化和离散化的核心技术,提升了解决实际数据分析问题的能力。


















 2967
2967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









