






 本次实验涉及创建一个8行5列的DataFrame,填充随机成绩,处理缺失值,进行数据连接操作,包括内连接、外连接、左连接、右连接,并使用concat进行并联和交联。实验还包括数据清洗、重置索引、查找不及格成绩及导出到Excel文件。手动计算与编程结果一致,证明掌握Pandas关键功能。
本次实验涉及创建一个8行5列的DataFrame,填充随机成绩,处理缺失值,进行数据连接操作,包括内连接、外连接、左连接、右连接,并使用concat进行并联和交联。实验还包括数据清洗、重置索引、查找不及格成绩及导出到Excel文件。手动计算与编程结果一致,证明掌握Pandas关键功能。
实验要求:
- 创建一个8行5列的DataFrame对象,列名为[‘Num’, ‘Name’,‘C++’, ‘Java’, ‘Python’],分别代表学号,姓名,C++成绩,Java成绩,Python成绩。所有成绩要求分布在[50,100)区间,是随机生成的整数。(以下所述的行号和列号均代表行列索引的默认编号。请使用本章所学的知识按顺序解决这些问题,不要投机取巧!)
- 复制第4个(从0开始)学生的全部信息,把它作为新行追加到表尾;
- 将(3, 4)、(6, 3)、(5, 2)、(2, 3)、(1, 0)这几个位置上的元素置为NaN;
- 输出所有包含缺失值的行;
- 删除学号为缺失值的行;
- 将成绩列上的所有缺失值用其同列上的前一个和后一个成绩的平均值替换;
- 检测是否存在重复行;如果存在,保留最后一行,删除其余行;
- 重置行索引;
- 在2,3,4列上分别找到大于60的最小值,然后把这些值用55替换(如果某列上有多个最小值,则全部替换);
- 输出Java成绩不及格的学生的信息(学号,姓名,Java成绩);
- 输出“挂科”学生的全部信息。
- 自己人工仔细检查以上每一道小题的操作结果是否正确。如果确认无误,用DataFrame的to_excel方法将数据存储到“Scores.xlsx”文件中,用Excel打开并查看数据是否正确。如果以上都正确,最后输出 :“我做对了!”
- 创建2个行、列大小均不相同的DataFrame对象(要求有部分行索引名和列索引名相同)。
- 手工计算按某个列索引(或列索引的组合)内连接、外连接、左连接和右连接的结果;然后通过编程验证计算结果的正确性。(用merge函数验证)
- 手工计算在0轴和1轴分别并联和交联的结果;然后通过编程验证计算结果的正确性。(用concat函数验证)
- 手工计算按行索引作为连接键左连接的结果;然后通过编程验证计算结果的正确性。(用join函数验证)
实验内容和实验结果:
-
- 导入必要的库:pandas 用于数据处理,random 用于生成随机数,numpy 用于数值计算。
import pandas as pd import random import numpy as np- 创建一个空的DataFrame pds,包含8行和5列,分别是’Num’, ‘Name’, ‘C++’, ‘Java’, ‘Python’。
pds = pd.DataFrame(index=list(range(8)), columns=['Num', 'Name', 'C++', 'Java', 'Python'])- 填充 ‘Num’ 和 ‘Name’ 列。
pds['Num'] = [1, 2, 3, 4, 5, np.nan, 7, 8] pds['Name'] = ['特朗普', '拜登', '康熙', '雍正', '乾隆', '和珅', '张廷玉', '姚启圣']- 使用随机数填充 ‘C++’, ‘Java’, ‘Python’ 列。
for i in range(8): pds.loc[i, 'C++'] = random.randint(50, 100) pds.loc[i, 'Java'] = random.randint(50, 100) pds.loc[i, 'Python'] = random.randint(50, 100)Num Name C++ Java Python 1.0 特朗普 67 98 74 2.0 拜登 65 70 60 3.0 康熙 77 83 92 4.0 雍正 72 70 97 5.0 乾隆 93 79 93 NaN 和珅 97 94 81 7.0 张廷玉 55 78 95 8.0 姚启圣 52 69 71 - 将第8行设置为第5行的复制。
pds.loc[8] = pds.loc[4]Num Name C++ Java Python 1.0 特朗普 67 98 74 NaN 拜登 65 70 60 3.0 康熙 77 NaN 92 4.0 雍正 72 70 NaN 5.0 乾隆 93 79 93 NaN 和珅 NaN 94 81 7.0 张廷玉 55 NaN 95 8.0 姚启圣 52 69 71 5.0 乾隆 93 79 93 - 对几行数据进行NaN值填充。
pds.loc[3, 'Python'] = np.nan pds.loc[6, 'Java'] = np.nan pds.loc[5, 'C++'] = np.nan pds.loc[2, 'Java'] = np.nan pds.loc[1, 'Num'] = np.nanNum Name C++ Java Python 1.0 特朗普 67 98 74 NaN 拜登 65 70 60 3.0 康熙 77 NaN 92 4.0 雍正 72 70 NaN 5.0 乾隆 93 79 93 NaN 和珅 NaN 94 81 7.0 张廷玉 55 NaN 95 8.0 姚启圣 52 69 71 5.0 乾隆 93 79 93 - 打印包含NaN值的行。
print('\n', pds[pds.isnull().any(axis=1)])Num Name C++ Java Python NaN 拜登 65 70 60 3.0 康熙 77 NaN 92 4.0 雍正 72 70 NaN NaN 和珅 NaN 94 81 7.0 张廷玉 55 NaN 95 - 删除学号含有NaN值的行。
pds = pds.dropna(subset=['Num'])Num Name C++ Java Python 1.0 特朗普 67 98 74.0 3.0 康熙 77 84 92.0 4.0 雍正 72 70 92.5 5.0 乾隆 93 79 93.0 7.0 张廷玉 55 74 95.0 8.0 姚启圣 52 69 71.0 5.0 乾隆 93 79 93.0 - 使用插值法填充NaN值,直到Java、C++和Python列中不再含有Nan值
while (pds['Java'].isnull().values.any() or pds['Python'].isnull().values.any() or pds['C++'].isnull().values.any()): pds['Java'].fillna(pds['Java'].interpolate(), inplace=True) pds['Python'].fillna(pds['Python'].interpolate(), inplace=True) pds['C++'].fillna(pds['C++'].interpolate(), inplace=True)Num Name C++ Java Python 0 1.0 特朗普 76 50 70 2 3.0 康熙 67 52 75 3 4.0 雍正 69 54 75 4 5.0 乾隆 88 81 75 6 7.0 张廷玉 77 72.5 71 7 8.0 姚启圣 86 64 75 8 5.0 乾隆 88 81 75 - 删除重复行。
pds = pds.drop_duplicates(keep='last')Num Name C++ Java Python 0 1.0 特朗普 76 50 70 2 3.0 康熙 67 52 75 3 4.0 雍正 69 54 75 6 7.0 张廷玉 77 72.5 71 7 8.0 姚启圣 86 64 75 8 5.0 乾隆 88 81 75 - 重置索引。
pds = pds.reset_index(drop=True)Num Name C++ Java Python 0 1.0 特朗普 76 50.0 70.0 1 3.0 康熙 67 52.0 75.0 2 4.0 雍正 69 54.0 75.0 3 7.0 张廷玉 77 72.5 71.0 4 8.0 姚启圣 86 64.0 75.0 5 5.0 乾隆 88 81.0 75.0 - 将低于60分的成绩替换为55分。
min_vals = pds.iloc[:, 2:5][pds.iloc[:, 2:5] > 60].min() for col in min_vals.index: pds[col][pds[col] == min_vals[col]] = 55Num Name C++ Java Python 0 1.0 特朗普 76 50.0 1 3.0 康熙 55 52.0 2 4.0 雍正 69 54.0 3 7.0 张廷玉 77 72.5 4 8.0 姚启圣 86 55.0 5 5.0 乾隆 88 81.0 - 打印Java成绩不及格的学生信息。
print("\nJava成绩不及格的学生信息:") print(pds[pds['Java'] < 60][['Num', 'Name', 'Java']])Num Name Java 1.0 特朗普 50.0 3.0 康熙 52.0 4.0 雍正 54.0 8.0 姚启圣 55.0 - 打印挂科学生的全部信息。
print("\n挂科学生的全部信息:") print(pds[(pds['C++'] < 60) | (pds['Java'] < 60) | (pds['Python'] < 60)])Num Name C++ Java Python 0 1.0 特朗普 76 50.0 55.0 1 3.0 康熙 55 52.0 75.0 2 4.0 雍正 69 54.0 75.0 3 8.0 姚启圣 86 55.0 75.0 - 将DataFrame写入Excel文件。
pds.to_excel("Scores.xlsx", index=False)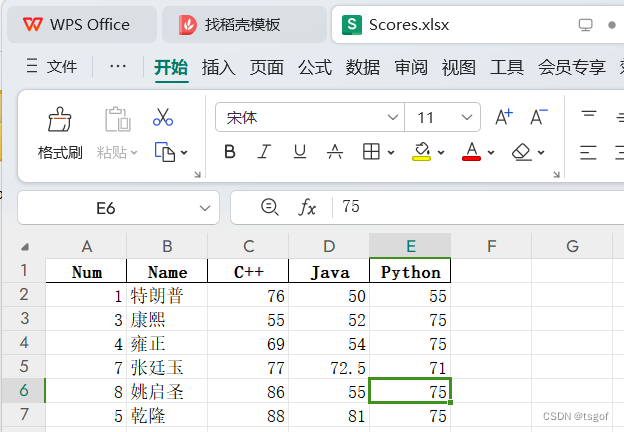
- 输出成功信息。
print("\n我做对了!") -
-
手工计算按某个列索引(或列索引的组合)内连接、外连接、左连接和右连接的结果;然后通过编程验证计算结果的正确性。(用merge函数验证)
- 首先 创建两个Dataframe对象
import pandas as pd # 创建DataFrame1和DataFrame2 df1 = pd.DataFrame({'A': [1, 4, 7], 'B': [2, 5, 8], 'C': [3, 6, 9]}) df2 = pd.DataFrame({'B': [10, 13], 'C': [11, 14], 'D': [12, 15]})A B C 0 1 2 3 1 4 5 6 2 7 8 9 B C D 0 10 11 12 1 13 14 15 - 内连接(按B、C列索引,下同)
inner_join = pd.merge(df1, df2, on=['B', 'C'], how='inner') print("内连接:") print(inner_join)内连接: Empty DataFrame Columns: [A, B, C, D] Index: []- 外连接
outer_join = pd.merge(df1, df2, on=['B', 'C'], how='outer') print(")\n外连接:") print(outer_joinA B C D 0 1.0 2 3 NaN 1 4.0 5 6 NaN 2 7.0 8 9 NaN 3 NaN 10 11 12.0 4 NaN 13 14 15.0 - 左连接
left_join = pd.merge(df1, df2, on=['B', 'C'], how='left') print("\n左连接:") print(left_join)A B C D 0 1 2 3 NaN 1 4 5 6 NaN 2 7 8 9 NaN - 右连接
right_join = pd.merge(df1, df2, on=['B', 'C'], how='right') print("\n右连接:") print(right_join)A B C D 0 NaN 10 11 12 1 NaN 13 14 15 
程序计算与手动计算相符。 -
手工计算在0轴和1轴分别并联和交联的结果;然后通过编程验证计算结果的正确性。(用concat函数验证)
- 0轴并联
concat_axis0 = pd.concat([df1, df2], axis=0) print("0轴并联:") print(concat_axis0)A B C D 0 1.0 2 3 NaN 1 4.0 5 6 NaN 2 7.0 8 9 NaN 0 NaN 10 11 12.0 1 NaN 13 14 15.0 - 1轴并联
concat_axis1 = pd.concat([df1, df2], axis=1) print("\n1轴并联:") print(concat_axis1)A B C B C D 0 1 2 3 10.0 11.0 12.0 1 4 5 6 13.0 14.0 15.0 2 7 8 9 NaN NaN NaN - 0轴交联
concat_axis0_inner = pd.concat([df1, df2], axis=0, join='inner') print("\n0轴交联:") print(concat_axis0_inner)B C 0 2 3 1 5 6 2 8 9 0 10 11 1 13 14 - 1轴交联
concat_axis1_inner = pd.concat([df1, df2], axis=1, join='inner') print("\n1轴交联:") print(concat_axis1_inner)A B C B C D 0 1 2 3 10 11 12 1 4 5 6 13 14 15 
程序计算与手动计算相符。 -
按行索引作为连接键左连接
result = pd.merge(df1, df2, how='left') print('\n按行索引左连接:') print(result)A B C D 0 1 2 3 NaN 1 4 5 6 NaN 2 7 8 9 NaN 
程序计算与手动计算相符。
-
实验总结:
通过这个实验,我深入掌握了Pandas库中DataFrame的创建、数据处理技巧、索引操作、连接与合并、以及数据导出等关键功能。我学会了如何处理缺失值、筛选特定条件的数据、重置索引、导出到Excel,并理解了不同类型的数据连接操作。


















 2815
2815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









