



 本文介绍了如何使用PyTorch的torchvision库进行图像预处理,包括ToTensor、Normalize、Resize、Compose和RandomCrop等变换,以及如何加载和展示CIFAR10数据集,同时展示了DataLoader的使用及其参数设置。
本文介绍了如何使用PyTorch的torchvision库进行图像预处理,包括ToTensor、Normalize、Resize、Compose和RandomCrop等变换,以及如何加载和展示CIFAR10数据集,同时展示了DataLoader的使用及其参数设置。
本文结合小土堆的教学视频PyTorch深度学习快速入门教程进行学习
一、torchvision.transforms 的使用
torchvision 是 pytorch 的一个图形库,主要用来构建计算机视觉模型。
Transforms 功能实现:主要是对一些特定格式的图片进行相应的变化,输出想要的图片结果
Transforms 库封装在 Transforms.py 文件中,相当于一个工具箱,含有有不同的 class 类,如Totensor、Resize 等。
Tensor 数据类型:该类型的数据包装了神经网络所需要的理论基础的参数,一般情况下需要将图片转化为 Tensor 类型再进行训练
1. ToTensor 类
功能实现:将数据类型为 PIL(通过 Image 函数库打开)或 numpy(通过 opencv 库打开)的图片数据转化为 Tensor 数据类型
具体代码实现如下(将 PIL 类型转化为 Tensor)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 输入图片路径
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
# 通过Image函数库打开图片,此时图片类型为 PIL
img = Image.open(img_path)
writer = SummaryWriter("logs") # 创建实例
# 将图片类型转化为tensor
tensor_trans = transforms.ToTensor() # 创建具体的工具
tensor_img = tensor_trans(img) # 使用工具,函数参数为图片数据
writer.add_image("Tensor_img",tensor_img) # 在tensorboard中显示图片
writer.close()具体代码实现如下(将 numpy 类型转化为 Tensor)
import cv2
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 输入图片路径
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
# 通过opencv库来打开图片,此时图片类型为numpy
img = cv2.imread(img_path)
writer = SummaryWriter("logs") # 创建实例
# 将图片类型转化为tensor
tensor_trans = transforms.ToTensor() # 创建具体的工具
tensor_img = tensor_trans(img) # 使用工具,函数参数为图片数据
writer.add_image("Tensor_img",tensor_img) # 在tensorboard中显示图片
writer.close()2. Normalize 类
功能实现:将传入的图片数据进行归一化处理
归一化计算公式: output[channel] = (input[channel] - mean[channel]) / std[channel] ,其中 mean 为均值,std 为标准差
具体代码实现如下
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
img = Image.open(img_path) # 打开图片
writer = SummaryWriter("logs") # 创建实例
trans_totensor = transforms.ToTensor() # 创建具体的工具
img_tensor = trans_totensor(img) # 使用工具,函数参数为图片数据
# 将图片进行归一化处理,传入均值和标准差两个参数(由于图片为RGB三信道,故需提供三个均值和三个标准差)
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor) # 参数必须为数据类型tensor的图片数据
writer.add_image("Normalize",img_norm) # 在tensorboard中显示图片
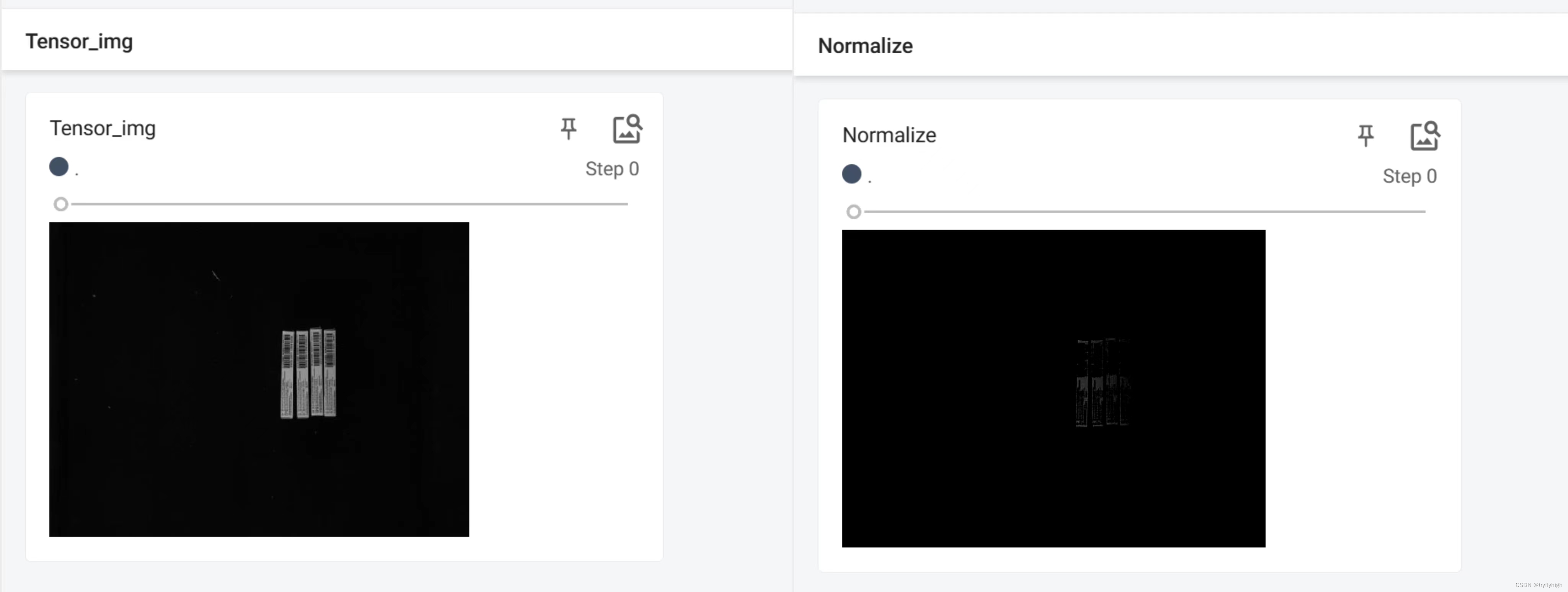
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,结果显示如下,左图为未进行标准化处理,右图为已进行标准化处理
3. Resize 类
功能实现:将输入图像的大小调整为给定的大小
创建类的函数传入参数 size 可以是序列,也可以是整数,表示期望输出的图片大小。如果 size 是像 (h, w) 这样的序列,则输出图片的大小将与之匹配。如果 size 为一个整数,则图像的较小边缘将与此数字匹配。也就是说,如果高度大于宽度,那么图像将被重新缩放为 (size * height / width, size)
在类中调用方法时,传入参数为图片数据,数据类型可以为 PIL 或 Tensor,输出的图片数据类型和输入的相同
具体代码实现如下(参数 size 为序列,传入的图片数据为 PIL)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
img = Image.open(img_path) # 打开图片
writer = SummaryWriter("logs") # 创建实例
trans_totensor = transforms.ToTensor() # 创建具体的工具
# 改变图片的大小,传入的参数为序列,表示将图片大小改为长为512,宽为512
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img) # 改变图片大小,传入图片类型为PIL,传出时也为PIL
img_resize = trans_totensor(img_resize) # 将图片的数据类型改为tensor
writer.add_image("Resize",img_resize,1) # 在tensorboard中显示图片
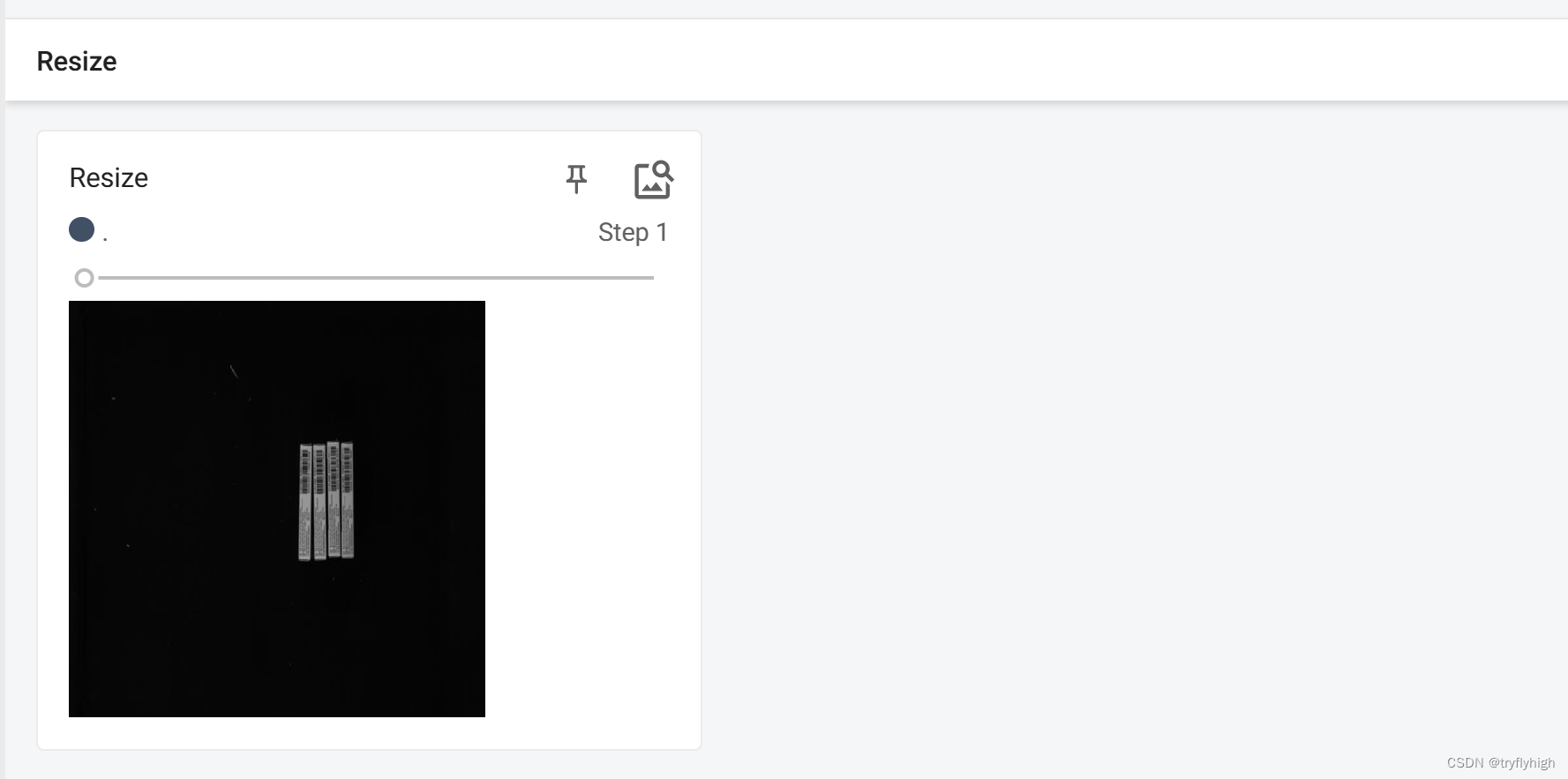
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,结果显示如下,此时图片大小为 512 × 512
具体代码实现如下(传入的图片数据为 Tensor)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
img = Image.open(img_path) # 打开图片
writer = SummaryWriter("logs") # 创建实例
trans_totensor = transforms.ToTensor() # 创建具体的工具
img_tensor = trans_totensor(img) # 使用工具,函数参数为图片数据
# 改变图片的大小,传入的参数为序列,表示将图片大小改为长为512,宽为512
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img_tensor) # 改变图片大小,传入图片类型为Tensor,传出时也为Tensor
writer.add_image("Resize",img_resize,1) # 在tensorboard中显示图片
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,出现了一条用户警告: The default value of the antialias parameter of all the resizing transforms (Resize(), RandomResizedCrop(), etc.) will change from None to True in v0.17, in order to be consistent across the PIL and Tensor backends. 经警告后面的提示,在 Resize 函数中添加参数 antialias=True 即可解除警告,结果显示和上述结果相同。
4. Compose 类
功能实现:串联多个图片变换的操作
函数传入的参数是一个列表,列表中的元素是想要执行的 transforms 操作,即将对图片的各个操作联结起来。Compose() 类会将该列表中的 transforms 操作进行遍历。
具体代码实现如下
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
img = Image.open(img_path) # 打开图片
writer = SummaryWriter("logs") # 创建实例
trans_totensor = transforms.ToTensor() # 创建具体的工具
img_tensor = trans_totensor(img) # 使用工具,函数参数为图片数据
# 改变图片的大小,传入的参数为一个整数,表示将最小边缘与之匹配
trans_resize_2 = transforms.Resize(512)
# 调用Compose()类,传入的列表表示第一步改变图片的大小,第二步将图片类型改为Tensor
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1) # 在tensorboard中显示图片
writer.close()5. RandomCrop 类
功能实现:对图片进行指定大小的裁剪
创建类的函数传入参数 size 可以是序列,也可以是整数,表示期望输出的图片大小。如果 size 是像 (h, w) 这样的序列,则输出图片的大小将与之匹配。如果 size 为一个整数,则输出图片大小为 size × size。
具体代码实现如下(参数 size 为一个整数)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = r"D:\pytorch_train\train\images\20240104_183616609.jpg"
img = Image.open(img_path) # 打开图片
writer = SummaryWriter("logs") # 创建实例
trans_totensor = transforms.ToTensor() # 创建具体的工具
img_tensor = trans_totensor(img) # 使用工具,函数参数为图片数据
# 随机裁剪图片,传入的参数为一个整数,表示裁剪的图片大小为100×100
trans_random = transforms.RandomCrop(100)
# 调用Compose()类,传入的列表表示第一步裁剪图片,第二步将图片类型改为Tensor
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
# 利用for循环来对图片裁剪10次
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("Resize",img_crop,i) # 在tensorboard中显示图片
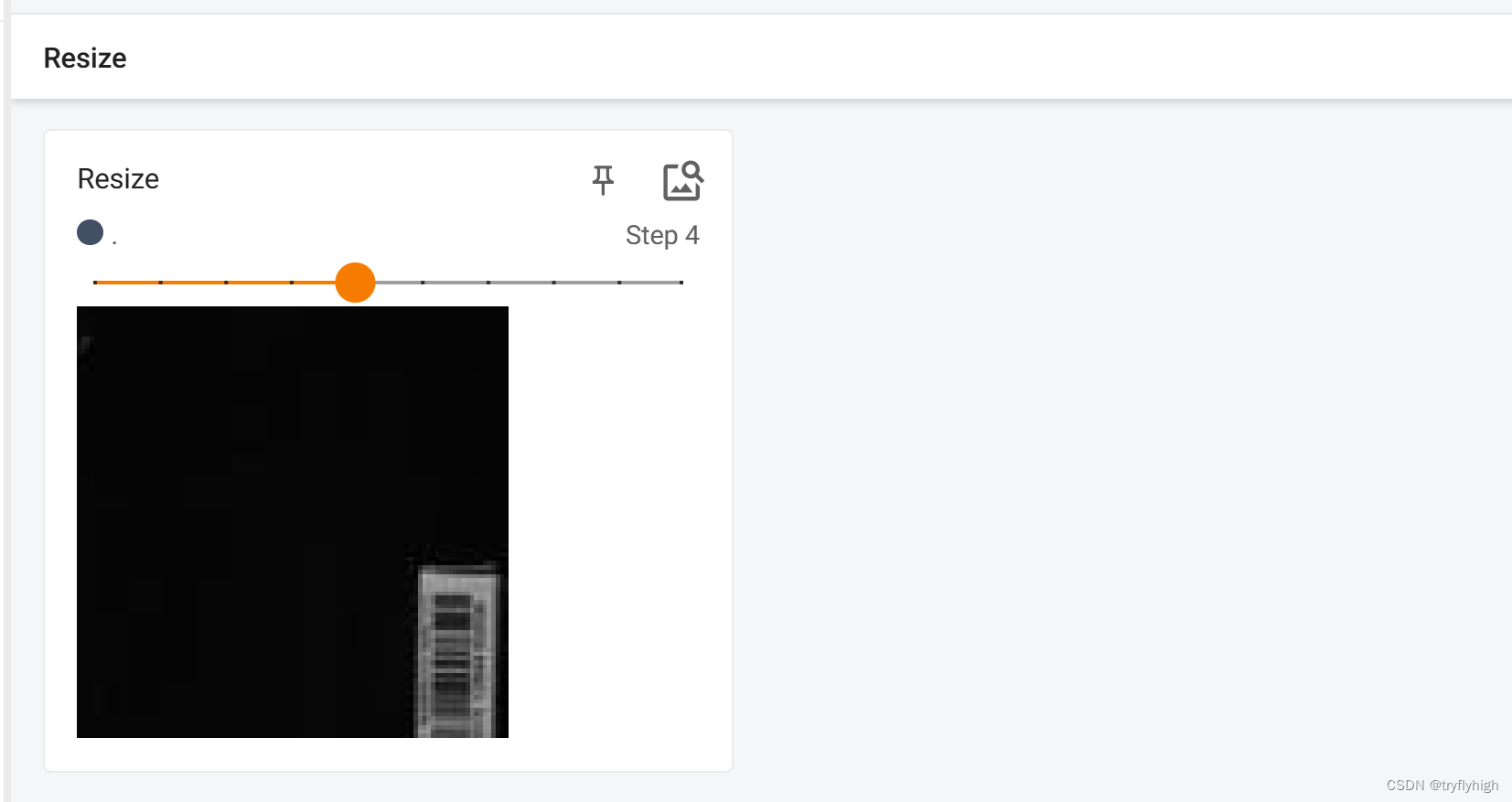
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,结果显示如下,此时显示共有10张图片,图片大小为 100 × 100
6. __call__ 函数
现在来对类中的 __call__ 函数进行分析。我们创建了一个类 Person,在类中有两个函数,一个__call__ 函数和一个call函数,两个函数均传入一个参数name,函数体内均打印输入的信息。然后创建一个 Person 类 p,分别调用两个函数,具体代码如下图所示
class Person:
def __call__(self, name):
print("__call__:"+name)
def call(self,name):
print("call:"+name)
p = Person()
p("zhangsan")
p.call("lisi")可以看到调用 __call__ 函数不需要写函数名,直接将参数传给类即可,而调用call函数则需写函数名,采用 p.call() 的方式调用。程序运行结果如下
__call__:zhangsan
call:lisi二、 torchvision.datasets 的使用
datasets功能实现:提供了常用的数据集加载,在设计上继承了 torch.utils.data.Dataset
具体代码实现如下(下载 CIFAR10 数据集)
import torchvision
# 通过torchvision.datasets下载数据集,train值为True表示训练集,False表示测试集
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0]) # 打印测试集中第一张图片的信息
print(test_set.classes) # 打印测试集中的classes属性
# 打印测试集中第一张图片的信息
img,target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show() # 显示图片
程序运行结果如下,前两行表示数据集已经下载了,第三行是测试集中第一张图片的信息,可以看到该图片类型为PIL,且为RGB三通道,大小为32 × 32,属于classes列表中下标值为3的那一类别。第四行是显示测试集中的所有类别。
Files already downloaded and verified
Files already downloaded and verified
(<PIL.Image.Image image mode=RGB size=32x32 at 0x2104B2542B0>, 3)
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
<PIL.Image.Image image mode=RGB size=32x32 at 0x2104B254280>
3
cat具体代码实现如下(与 transforms 的联合使用)
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 下载CIFAR10数据集
train_set = torchvision.datasets.CIFAR10(root="./dataset",transform=dataset_transform,train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",transform=dataset_transform,train=False,download=True)
writer = SummaryWriter("logs")
# 在for循环中展示数据集的前10张图片
for i in range(10):
img,target = test_set[i] #图片文件中第一个元素为图片,第二个元素为元素下标
writer.add_image("test_set",img,i) # 在tensorboard中显示图片
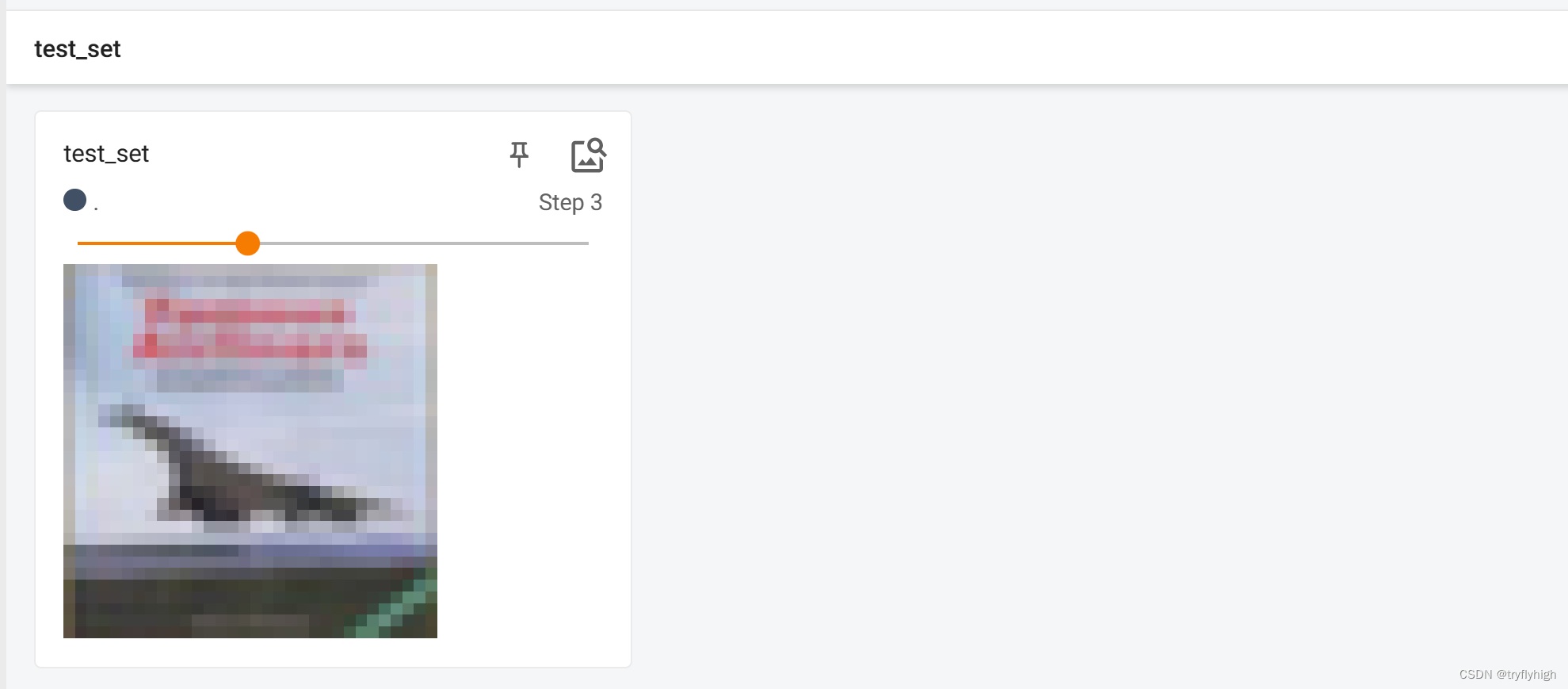
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,结果显示如下,此时显示测试集的前10张图片,图片大小为 32 × 32
三、DataLoader 的使用
功能实现:数据加载器,结合传入的数据集和采样器,提供在给定数据集上的可迭代对象,将数据加载到神经网络中
函数参数的含义:
dataset:表示要加载的数据集;batch_size:每批要加载样本的数量(默认值为1);shuffle:设置为 True 表示在每一轮重新将数据进行洗牌(默认值为 False);num_workers:要使用多少子进程来加载数据(默认值为0,表示数据将在主进程中加载);drop_last:设置为 True 表示如果数据集大小不能被批处理大小整除,则删除最后一个不完整的批处理,若设置为 False 且数据集的大小不能被批处理大小整除,则最后一批处理将保持不变(默认值为 False)
具体代码实现如下(batch_size 设置为64,drop_last 设置为 False)
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备测试数据集
test_set = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 在tensorboard中显示图片
writer = SummaryWriter("logs")
step=0
for data in test_loader:
imgs, targets = data
writer.add_images("test_loader",imgs,step)
step += 1
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,结果显示如下,此时共有156步,前155步均为64张图片,最后一步只有16张图片,这是因为 drop_last 设置为 False 的缘故,若设置为 True,则共显示155步,把最后一步不足64张的删除
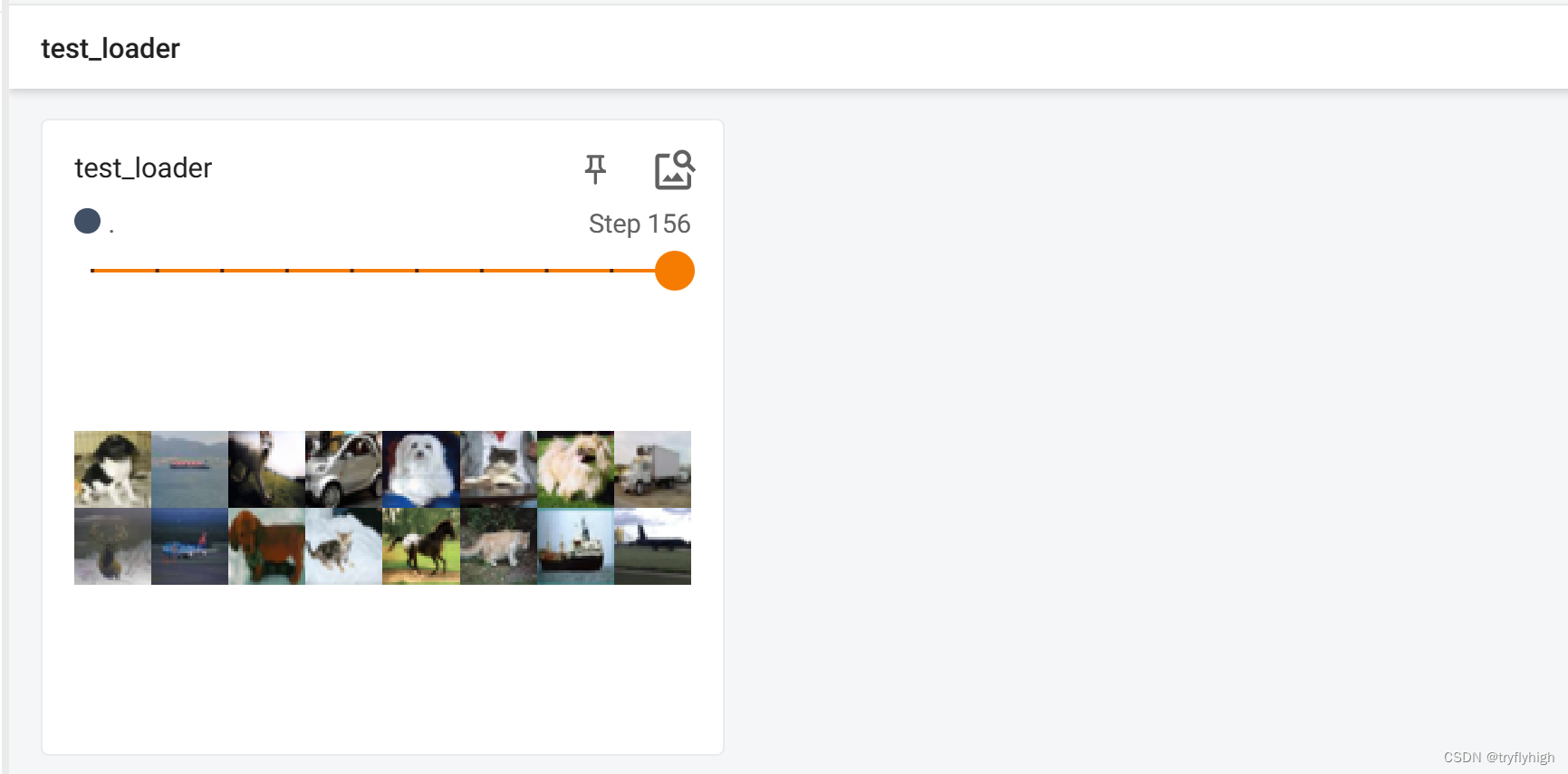
在程序运行的过程中出现了两个报错:
ValueError: batch_sampler option is mutually exclusive with batch_size, shuffle, sampler, and drop_last :经查询发现,在编写程序的时候把batch_size写成了batch_samlper,而一旦设置了batch_sampler这个参数,batch_size, shuffle, sampler 和 drop_last 就不能再指定了,他们之间是互斥的
AssertionError: size of input tensor and input format are different. :经查询发现,在编写程序的时候把 add_images 写成了 add_image,导致函数只能显示单一图片,而不能显示batch数据
具体代码实现如下(shuffle 设置为 True)
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备测试数据集
test_set = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
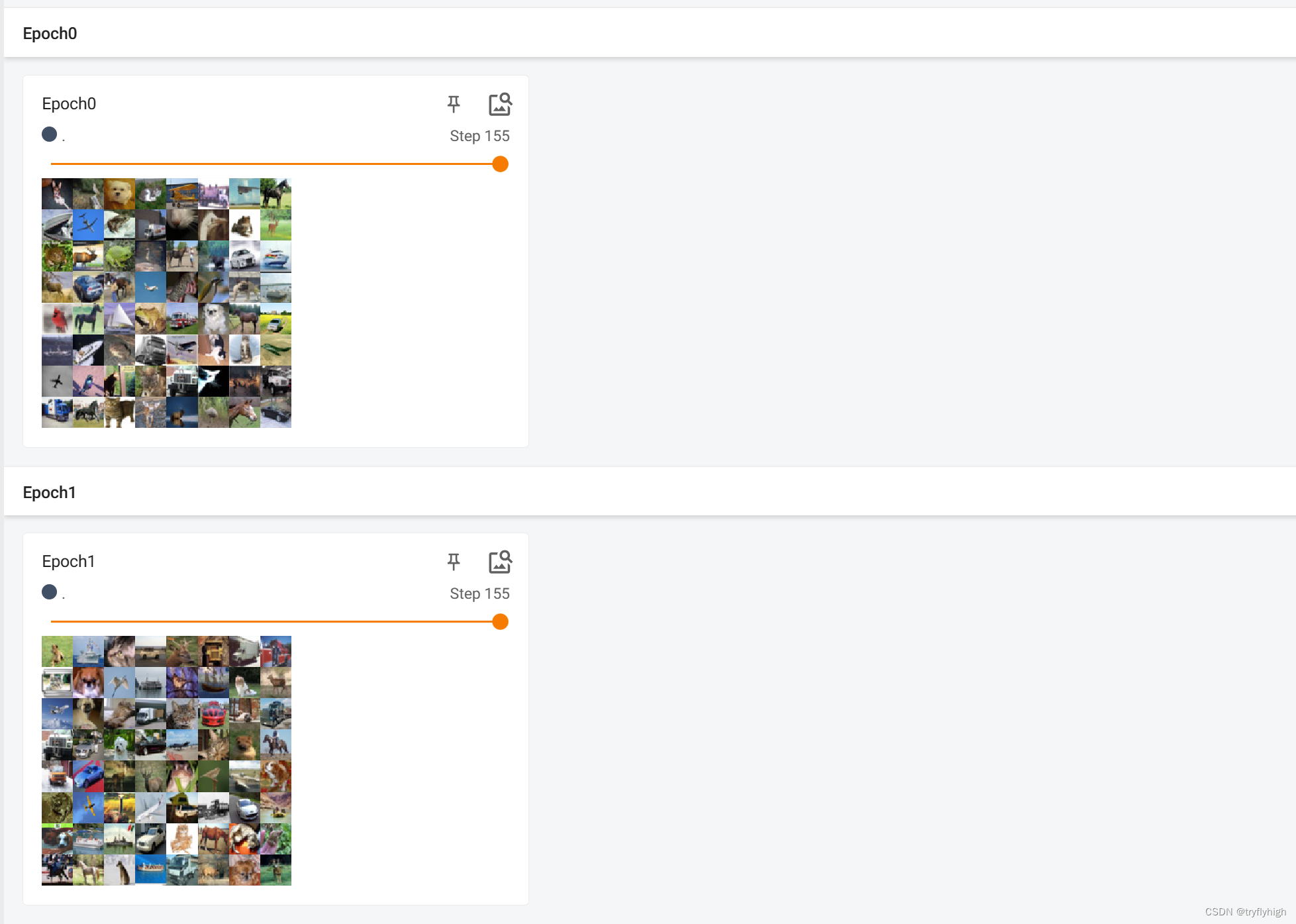
# 进行两轮显示图片
writer = SummaryWriter("logs")
for epoch in range(2):
step=0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch{}".format(epoch),imgs,step)
step += 1
writer.close()将程序运行后,在终端输入 tensorboard --logdir=logs --port=6007 ,结果显示如下,两轮显示均有155步,并且可以发现同一步的同一位置上的图片是不相同的,是因为 shuffle 参数设置为了 True


















 8073
8073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









